WPeChatGPT
WPeChatGPT 是一款专为 IDA Pro 设计的智能插件,旨在利用大语言模型(如 OpenAI GPT-3.5-turbo 和 DeepSeek)辅助安全分析师高效解读二进制文件。面对逆向工程中函数逻辑晦涩、变量命名混乱以及漏洞挖掘耗时等痛点,它能自动分析函数的运行环境与用途,智能重命名变量,甚至尝试将汇编代码还原为 Python 脚本。此外,它还具备自动检测函数漏洞并生成对应利用脚本(EXP)的能力,显著提升了分析效率。
该工具主要适合二进制安全研究人员、逆向工程师及漏洞挖掘专家使用。其独特亮点在于集成了"Auto-WPeGPT"功能,支持对二进制文件进行全自动化的批量分析,并灵活兼容多种主流 AI 模型,用户可根据需求切换配置。需要注意的是,AI 生成的分析结果仅供参考,最终判断仍需结合人工经验。通过右键菜单、顶部菜单栏或快捷键,用户即可在 IDA 的伪代码窗口中轻松调用各项功能,让复杂的逆向工作变得更加直观便捷。
使用场景
某安全研究员正在对一款疑似包含后门的未知 IoT 固件进行逆向分析,面对数万行晦涩的汇编代码,急需快速定位关键逻辑。
没有 WPeChatGPT 时
- 人工解读效率极低:面对复杂的 XOR 解密或自定义加密算法,需逐行手动推导寄存器变化,耗时数小时才能理清单一函数的业务含义。
- 变量命名混乱:二进制文件中充斥着
v1、a2等无意义变量名,分析师必须依靠记忆和笔记在脑海中重构数据流,极易出错。 - 漏洞挖掘依赖直觉:寻找缓冲区溢出或逻辑漏洞完全依赖个人经验,容易遗漏隐蔽的攻击面,且编写验证脚本(EXP)需从零开始编码。
- 上下文割裂:在处理大型二进制文件时,难以快速建立函数间的调用关系和整体运行环境认知,导致分析思路频繁中断。
使用 WPeChatGPT 后
- 智能功能还原:利用 WPeChatGPT 的“函数分析”与"Python 还原”特性,秒级生成解密算法的 Python 伪代码,直接看清数据处理逻辑。
- 自动语义重命名:通过一键重命名功能,将
sub_401A自动改为Decrypt_Config,变量名同步更新为key_buffer,代码可读性大幅提升。 - 辅助漏洞利用:借助漏洞查找与 EXP 生成功能,WPeChatGPT 能自动识别潜在溢出点并提供初步利用脚本框架,将验证时间从半天缩短至几分钟。
- 全局自动化分析:启用 Auto-WPeGPT 模式,自动遍历并总结二进制文件的运行环境与核心意图,帮助分析师快速构建完整的攻击面地图。
WPeChatGPT 将原本需要数天的人工逆向苦力活转化为小时级的智能辅助决策,让分析师能专注于核心威胁研判而非代码翻译。
运行环境要求
- Windows
- Linux
- macOS
未说明
未说明

快速开始
English | 中文
WPeChatGPT
基于与 ChatGPT 相同模型的 IDA 插件,使用 OpenAI 发布的 gpt-3.5-turbo 模型,可以帮助分析师快速分析二进制文件。
WPeChatGPT 目前支持的功能包括:
- 分析函数的使用环境、预期用途及功能。
- 重命名函数中的变量。
- 尝试用 Python3 还原函数,此功能主要适用于较小代码块的函数(如 XOR 解密函数)。
- 在当前函数中查找漏洞。
- 尝试使用 Python 为存在漏洞的函数生成相应的 EXP。
- 利用 GPT 自动分析二进制文件,详情请参阅 Auto-WPeGPT 部分。
WPeChatGPT 插件最初使用 OpenAI 训练的 text-davinci-003 模型。 自 v2.0 起,改用 OpenAI 最新的 gpt-3.5-turbo 模型(与 ChatGPT 相同)。
ChatGPT 的分析结果 仅供参考,否则我们这些分析师可就失业了。XD
更新历史
| 版本 | 日期 | 备注 |
|---|---|---|
| 1.0 | 2023-02-28 | 基于 Gepetto。 |
| 1.1 | 2023-03-02 | 1. 删除加密解密分析功能。 2. 增加 Python 还原函数功能。 3. 修改了一些细节。 |
| 1.2 | 2023-03-03 | 1. 新增在函数中查找二进制漏洞的功能。 2. 增加尝试自动生成相应 EXP 的功能。 3. 修改了一些细节。 (由于 OpenAI 服务器延迟,未进行上传测试) |
| 2.0 | 2023-03-06 | 1. 完成 v1.2 版本漏洞相关功能的测试。 2. 切换到 OpenAI 发布的最新 gpt-3.5-turbo 模型。 |
| 2.1 | 2023-03-07 | 修复 OpenAI-API 超时问题。(详见 关于 OpenAI-API 报错说明) |
| 2.3 | 2023-04-23 | 新增 Auto-WPeGPT v0.1,支持自动分析二进制文件。 (从该版本起需添加 anytree 包,可使用 requirements.txt 或直接运行 pip install anytree) |
| 2.4 | 2023-11-10 | 1. 更改了一些显示细节。 2. 更新 Auto-WPeGPT v0.2。 |
| 2.5 | 2024-08-07 | 1. 增加对其他模型的支持,可通过设置 MODEL 变量来选择。@tpsnt 2. 支持新版 python openai 包。(需更新您的 openai 包) |
| 2.6 | 2025-02-17 | 新增对 DeepSeek 的支持,需将变量 PLUGIN_NAME 设置为 WPeChat-DeepSeek,并将 API KEY 填入变量 model_api_key。 (默认模型为 DeepSeek-V3。若需使用 R1 模型,请修改变量 MODEL = 'deepseek-reasoner'。) |
安装
- 运行以下命令安装所需依赖包。
pip install -r ./requirements.txt
- 修改脚本
WPeChatGPT.py,将您的 API 密钥添加到变量 openai.api_key 中,并将变量 ZH_CN 改为 False。(默认为中文) - 将脚本文件
WPeChatGPT.py和文件夹Auto-WPeGPT_WPeace复制到 IDA 的插件目录下,最后重启 IDA 即可使用。
! 注意: 您需要将 IDA 环境 设置为 python3,并且在 WPeChatGPT 2.0 版本之后,需使用 最新的 OpenAI Python 包。
使用方法
支持在 IDA 中通过 右键菜单、菜单栏或快捷键 使用。
快捷键:
函数分析 = "Ctrl-Alt-G"重命名函数变量 = "Ctrl-Alt-R"查找漏洞 = "Ctrl-Alt-E"在伪代码窗口上右键:
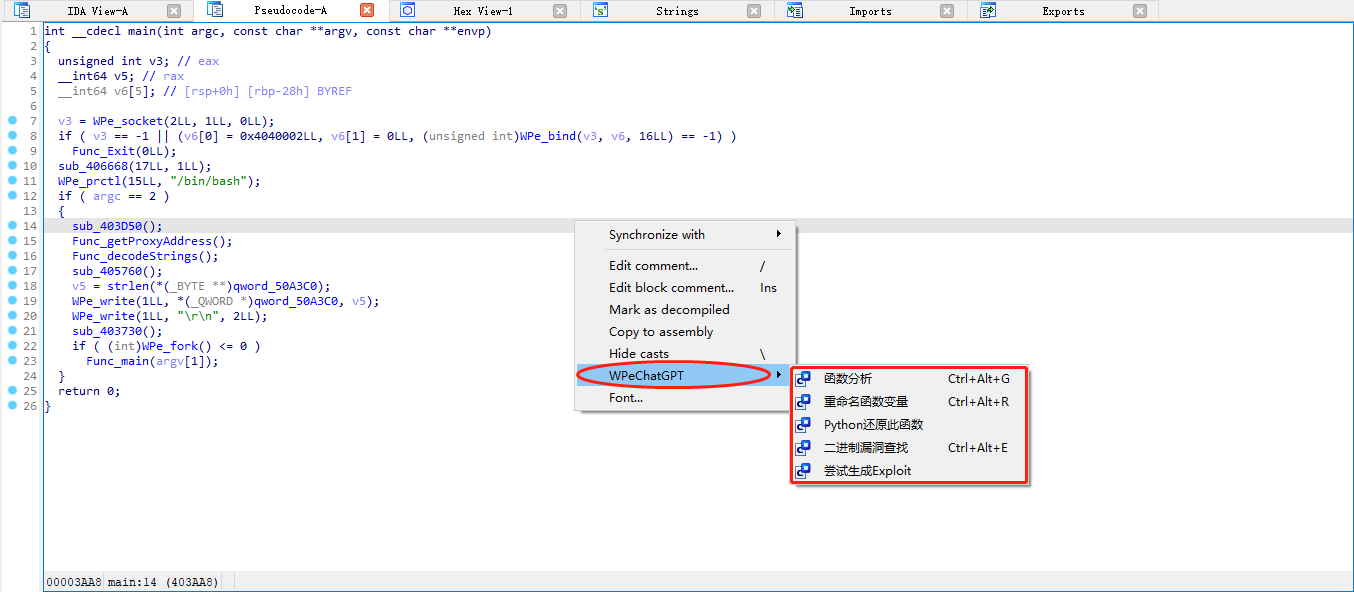
- 菜单栏:编辑 $\Rightarrow$ WPeChatGPT
示例
使用方法:
函数分析效果展示:
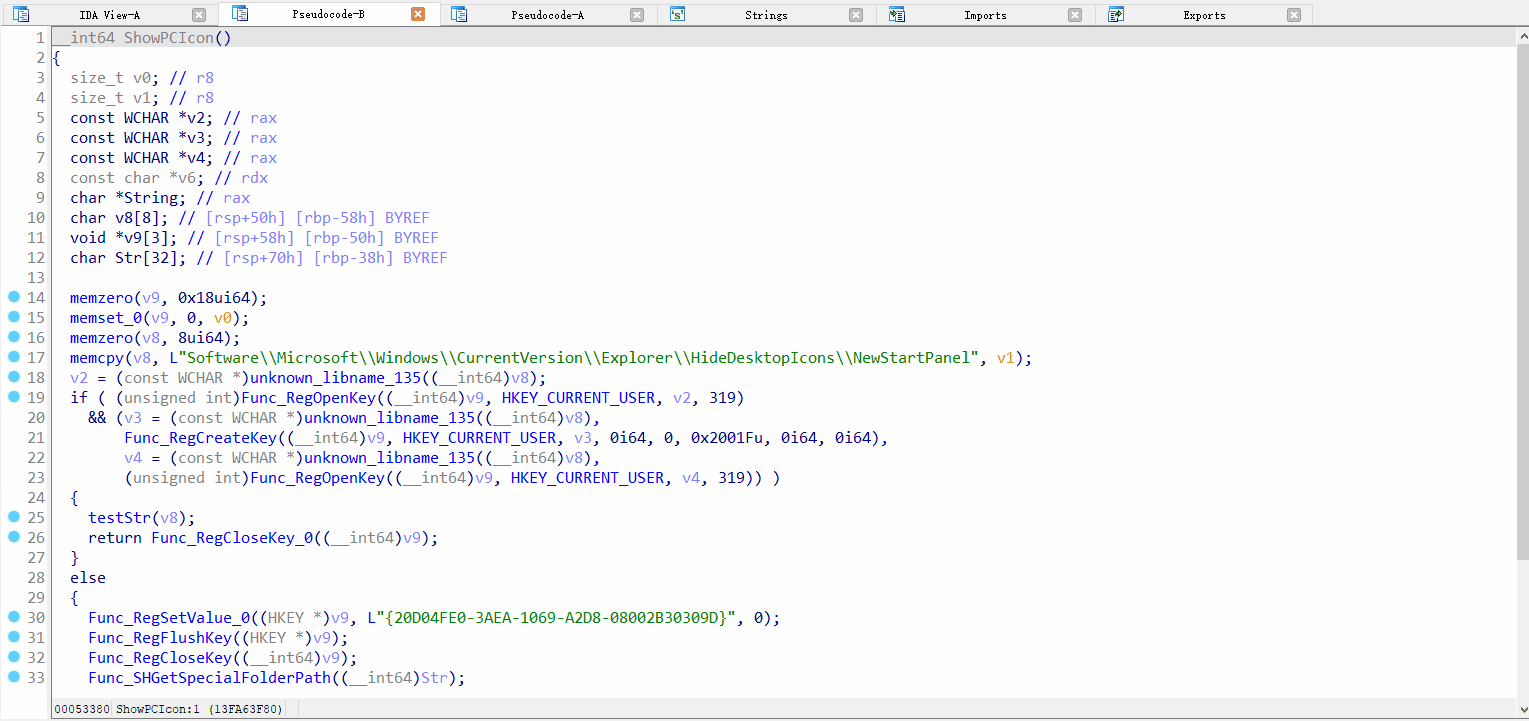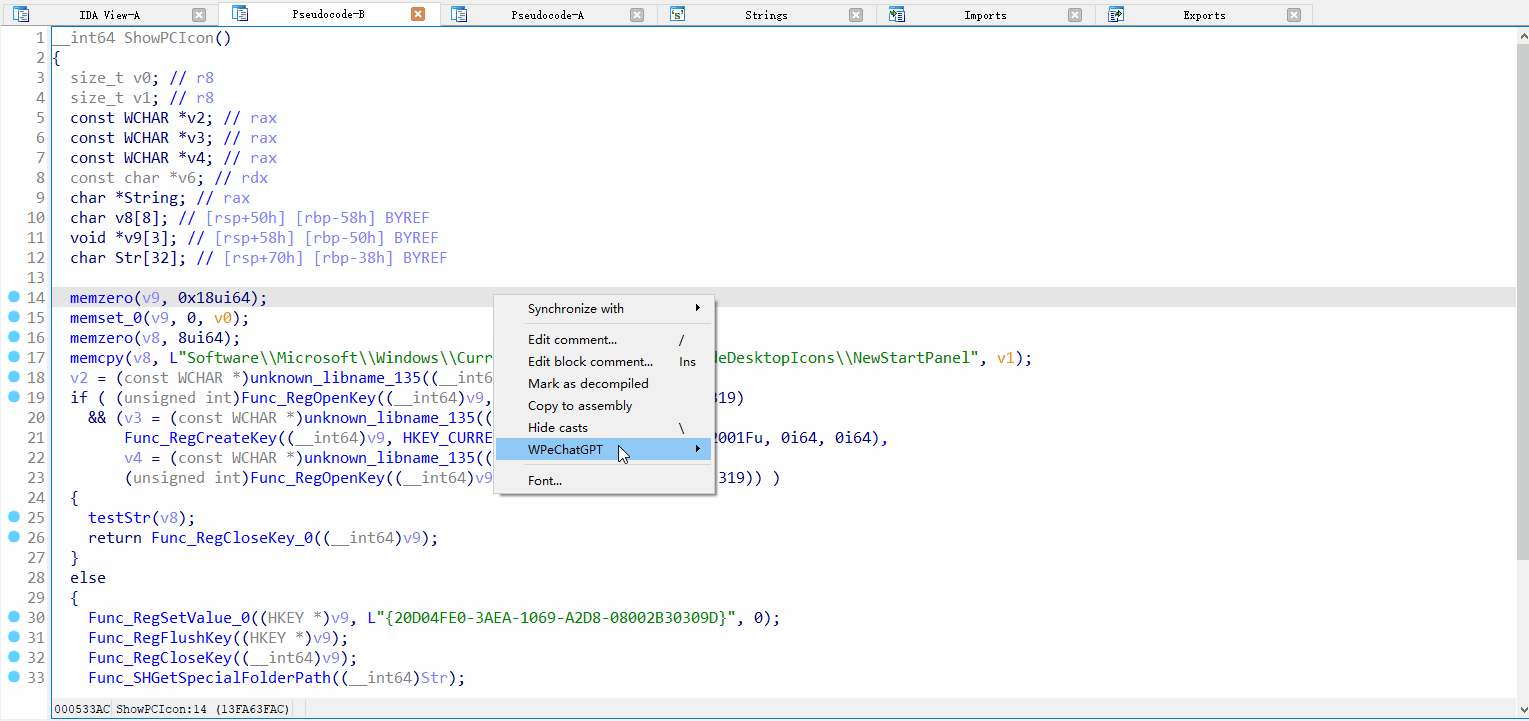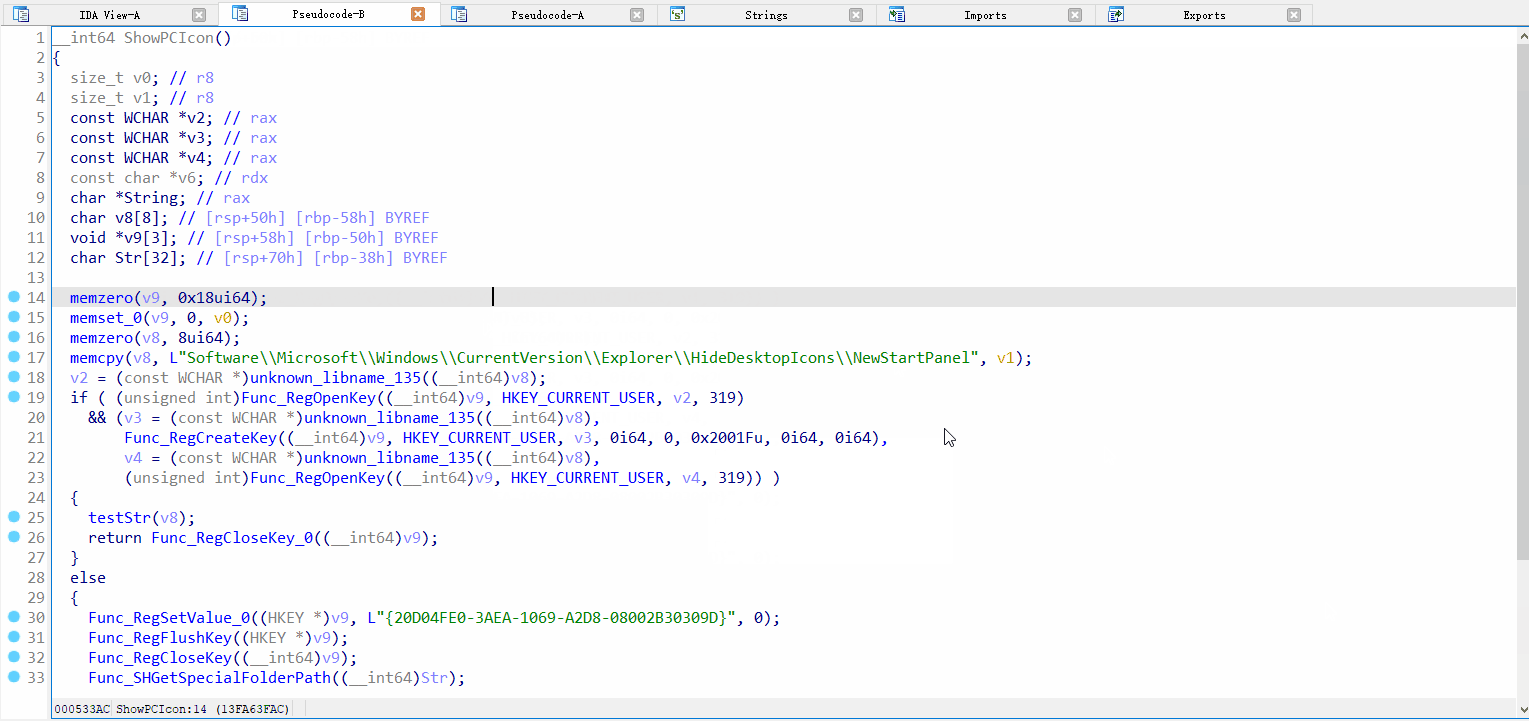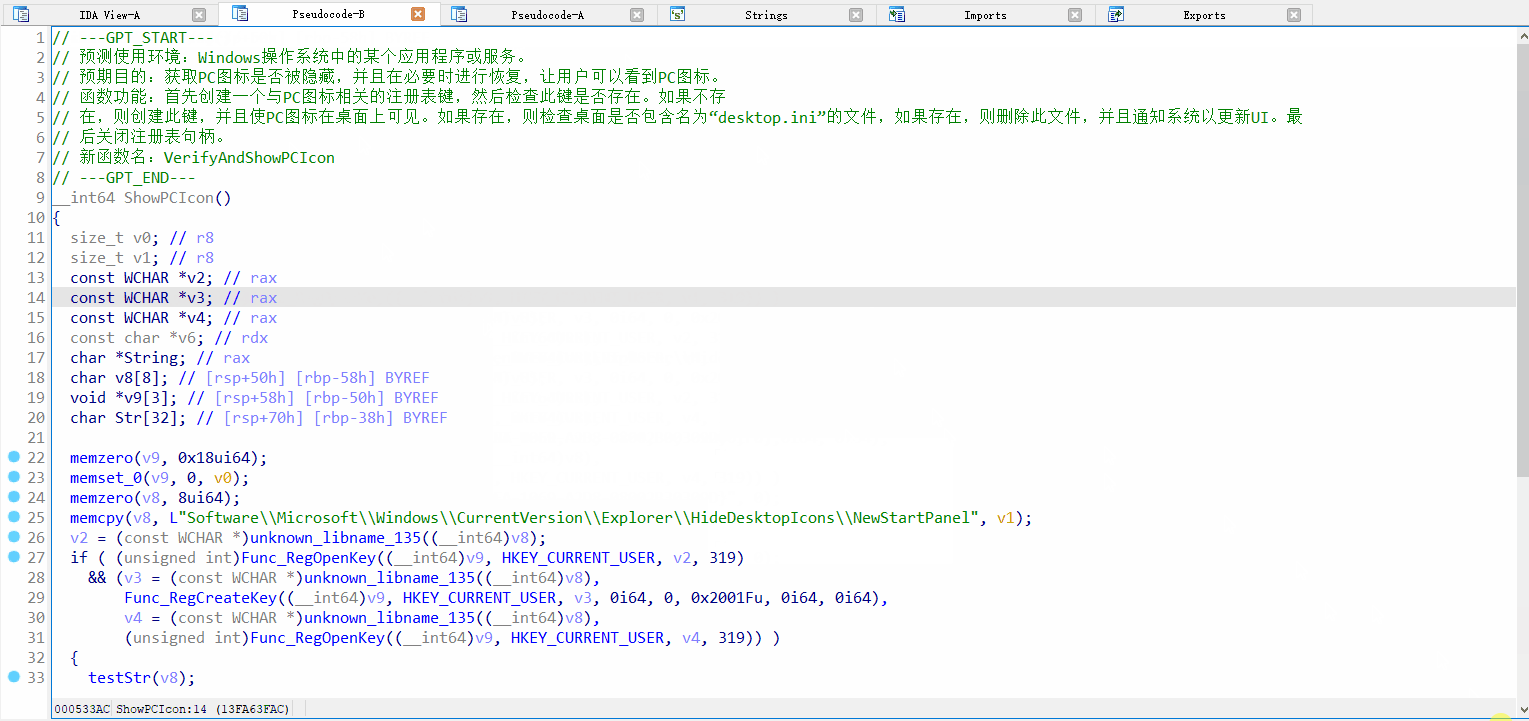
漏洞查找效果展示:
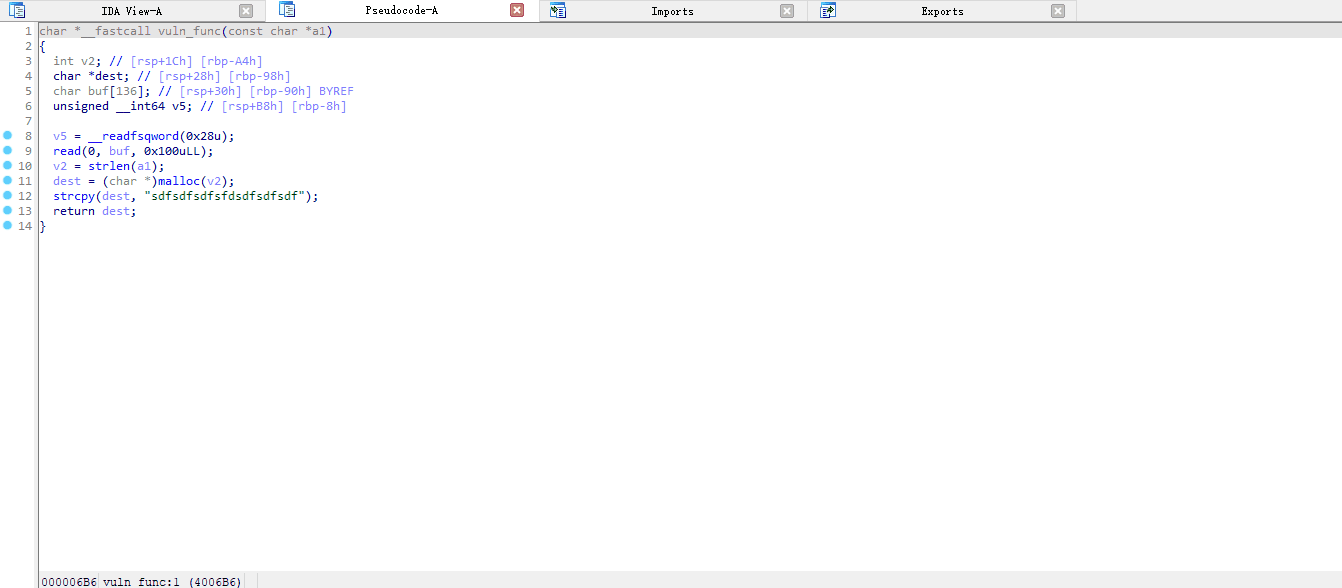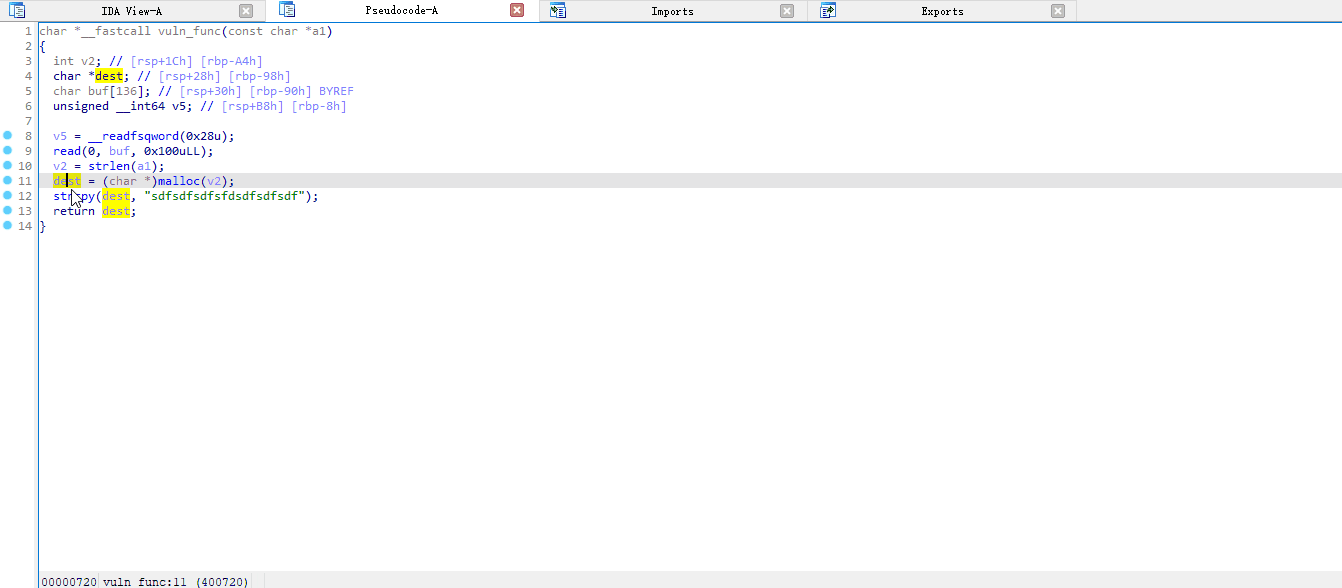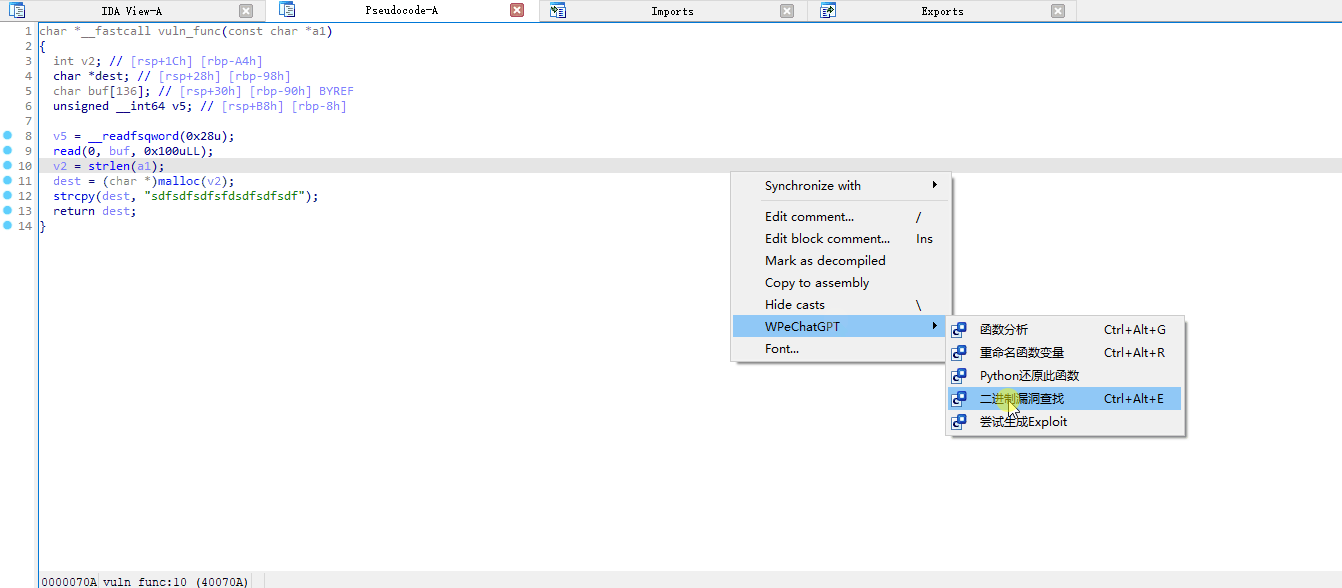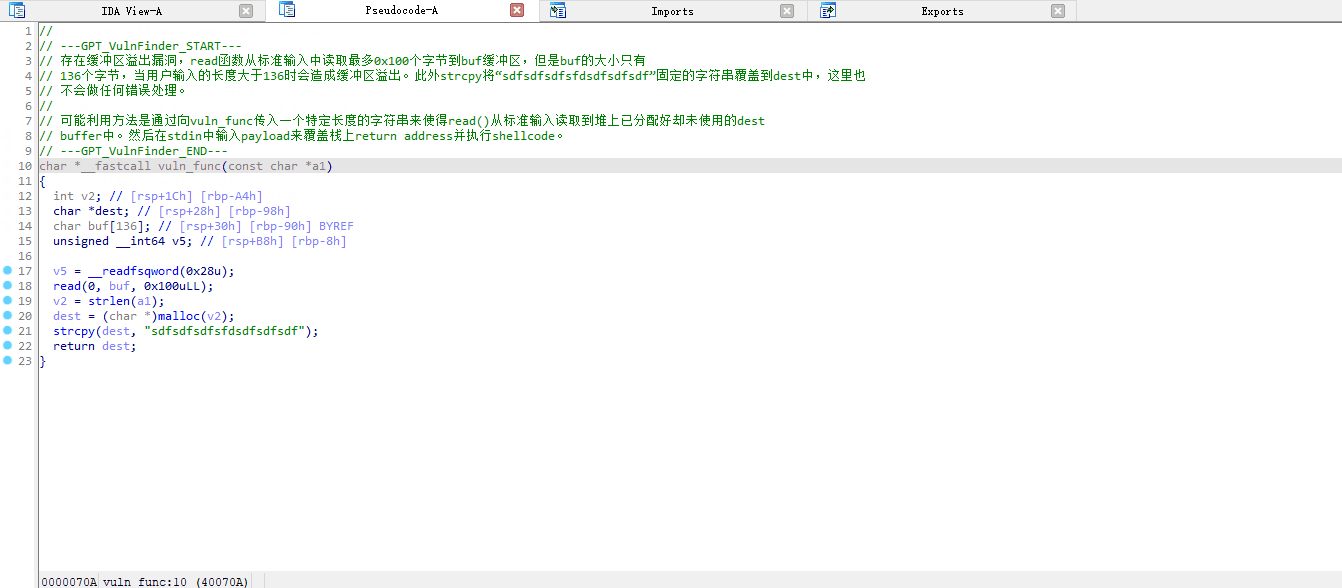
Auto-WPeGPT
更新历史:
| 版本 | 日期 | 备注 |
|---|---|---|
| 0.1 | 2023-04-23 | 首次发布。 |
| 0.2 | 2023-11-10 | 1. 提高有效字符串的识别能力。 2. 改善函数调用树的分析。 3. 增加对导入函数的识别。 |
使用方法: 在菜单栏中找到 Auto-WPeGPT 并点击。输出完成后,您可以在对应的文件夹中找到分析结果("WPe_+IDB 名称")。
- 菜单栏:编辑 $\Rightarrow$ WPeChatGPT $\Rightarrow$ Auto-WPeGPT
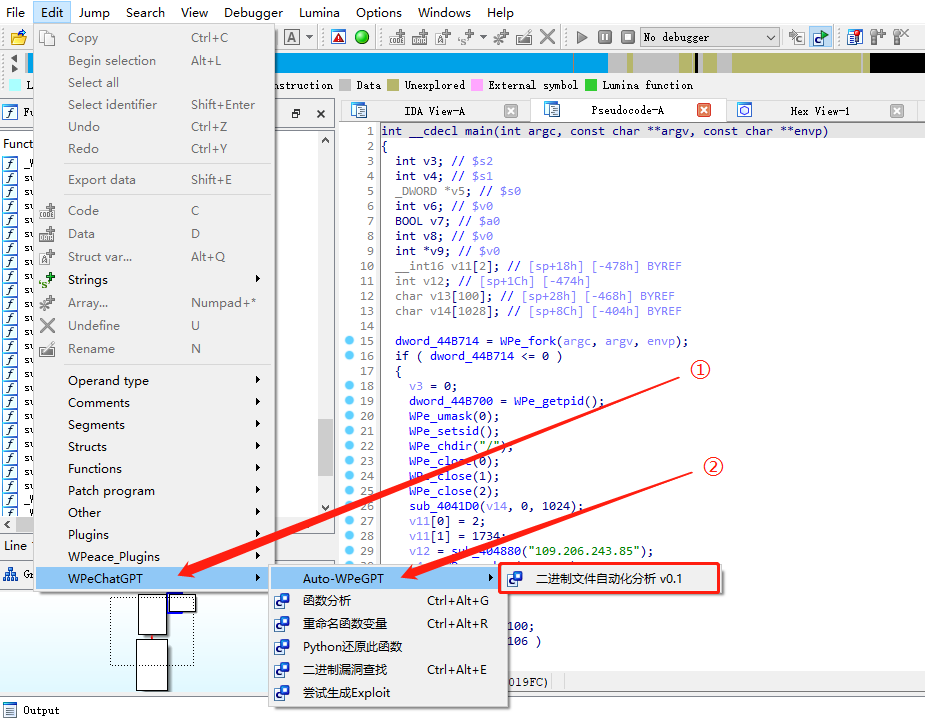
输出文件夹中各文件的含义:
GPT-Result.txt -> Auto-WPeGPT 分析结果
funcTree.txt -> 函数调用树结构
mainFuncTree.txt -> 主函数调用树结构
effectiveStrings.txt -> 二进制文件中的可疑字符串
结果展示:
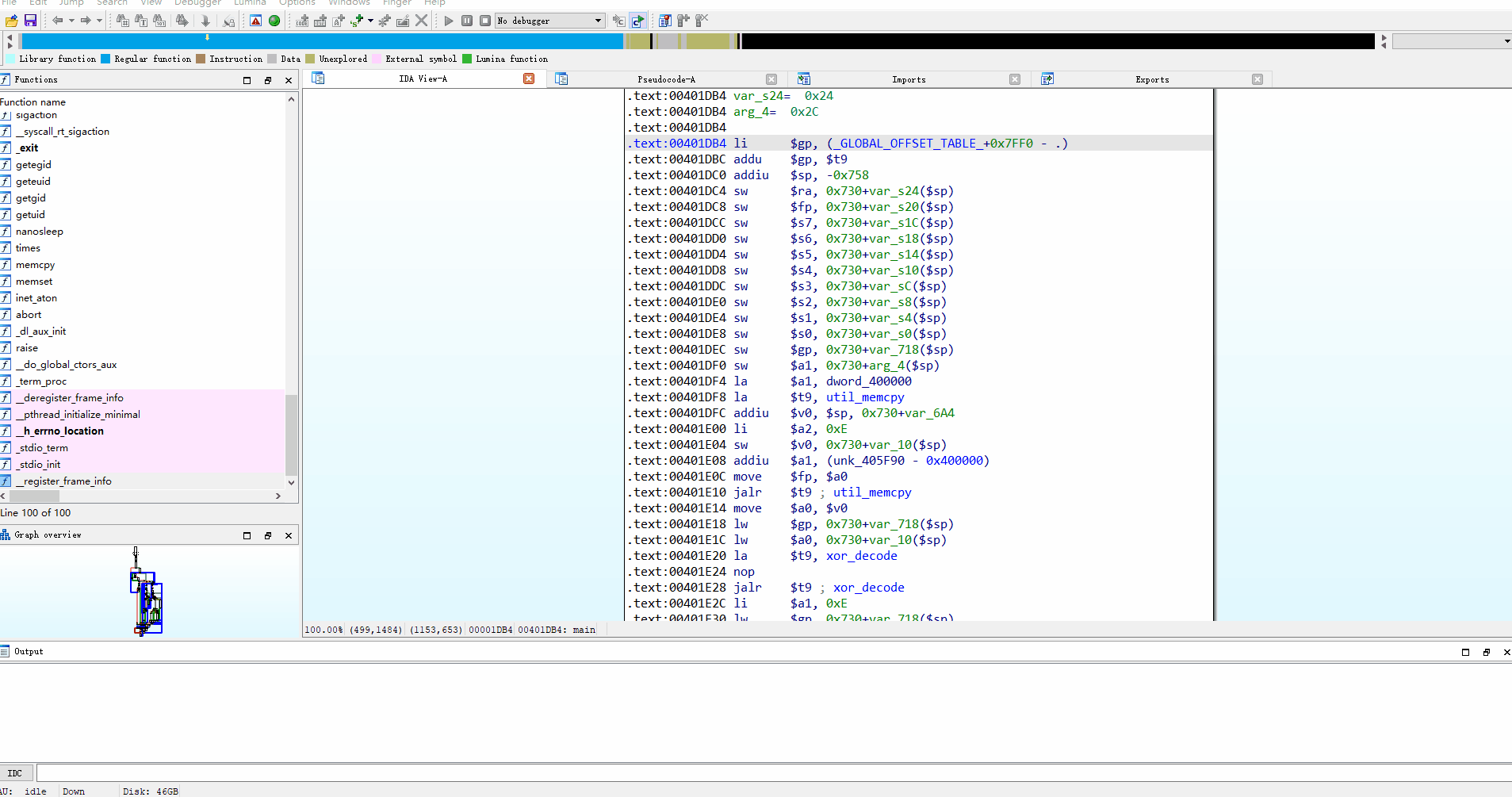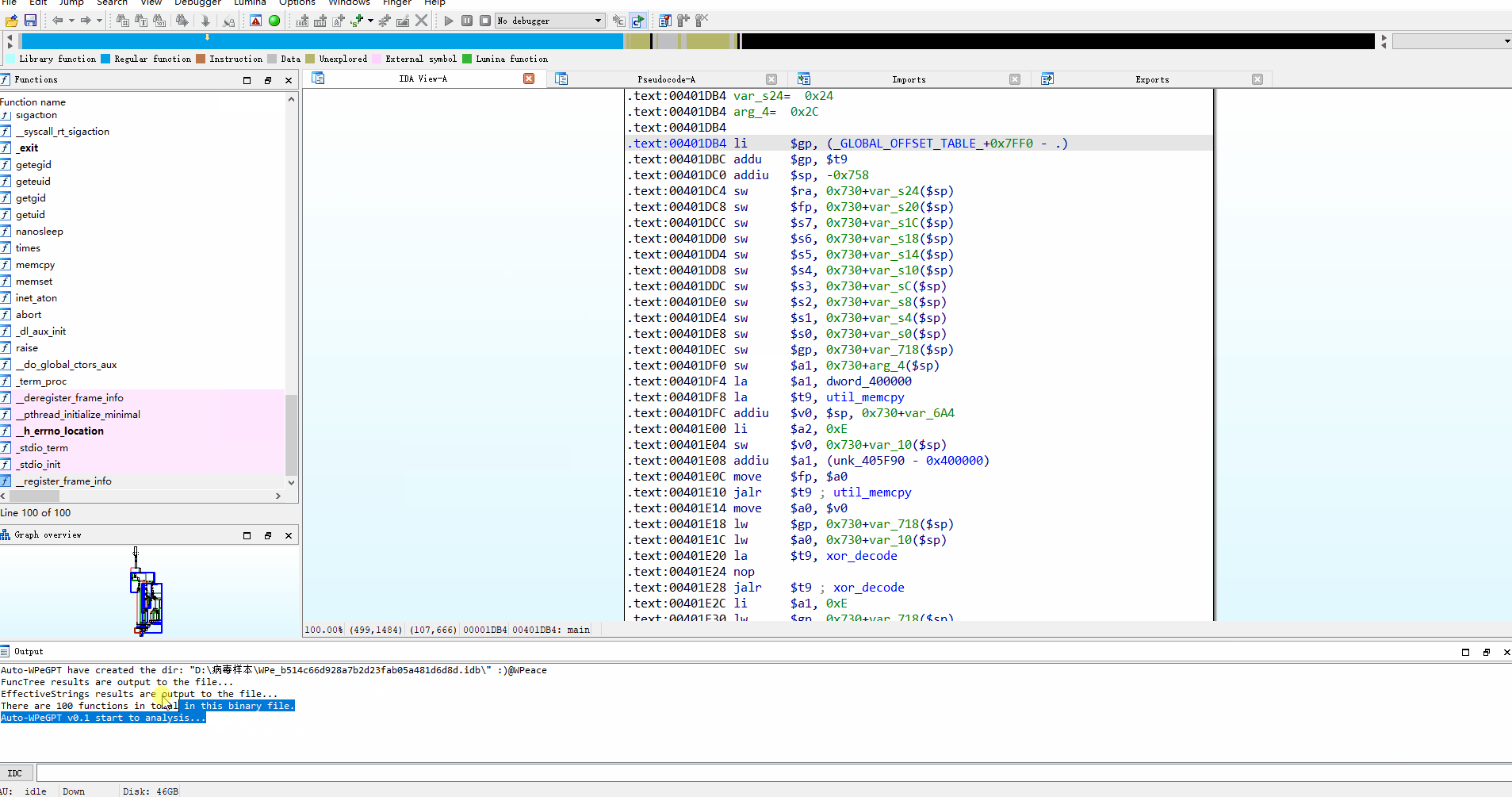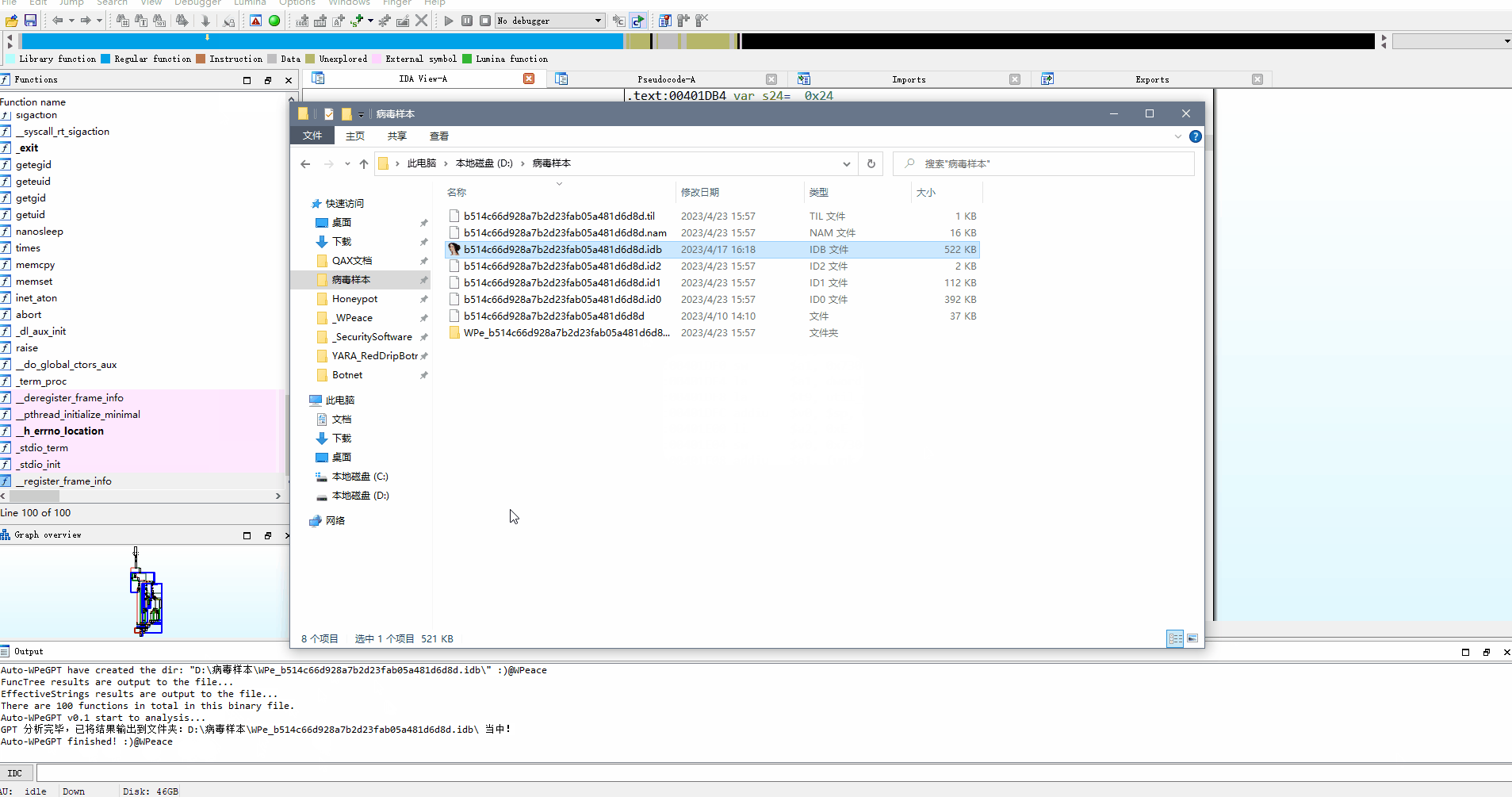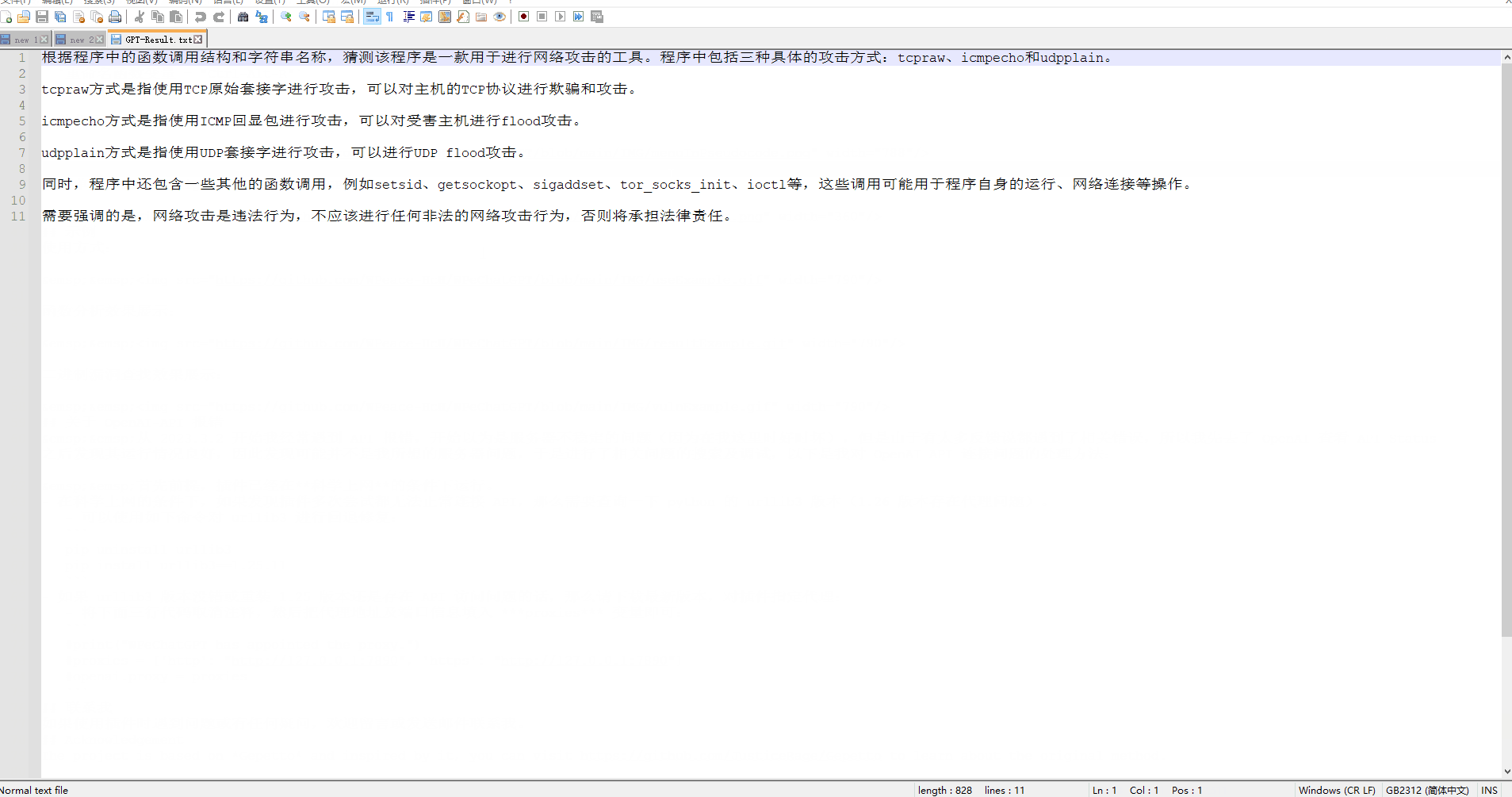
经测试,v0.1 版本对函数较少的文件分析效果较好。对于函数数量较多的二进制文件,可能会出现 token 超出限制的情况。我们将在后续版本中继续优化。
关于 OpenAI-API 报错说明
自 2023 年 3 月 2 日起,我经常遇到 API 报错,起初以为是服务器不稳定所致(因为我也曾经历过波动),但后来收到太多关于类似错误的反馈,于是我前往 OpenAI 查看 API 状态,发现其运行正常。因此,我认为问题可能并非服务器端,而是其他原因,于是开始排查和调试相关问题。以下是我在处理 OpenAI API 连接问题时的一些经验:
首先,该插件一直在 科学上网 的条件下运行。
- 在科学上网的情况下,如果多次尝试后插件仍无法连接到 API,需检查 Python 的 urllib3 版本(1.26 版本存在代理问题)。
- 您可以使用以下命令回退并修复 urllib3:
pip uninstall urllib3 pip install urllib3==1.25.11 - 您可以为插件设置正向或反向代理:
- 将代理地址和端口信息填入 proxy 变量中(正向代理):
# 如有需要,请设置您的正向代理。(例如 Clash = http://127.0.0.1:7890) proxy = ""- 将反向代理 URL 填入 proxy_address 变量中(反向代理):
# 如有需要,请设置反向代理 URL。(例如 Azure OpenAI) proxy_address = ""
联系我
如果您在使用插件时遇到问题或有任何疑问,请留言或发送邮件给我。
致谢
本项目基于Gepetto并受其启发,您可访问https://github.com/JusticeRage/Gepetto 了解原始方法。
版本历史
v2.72025/12/09v2.62025/02/17v2.52024/08/07v2.42023/12/04v2.32023/05/12v2.12023/03/07v2.02023/03/06v1.12023/03/02v1.02023/02/28常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。