build_MiniLLM_from_scratch
build_MiniLLM_from_scratch 是一个旨在帮助开发者从零开始构建小型语言模型(LLM)的开源实践项目。它完整覆盖了大模型训练的核心流程,包括预训练、指令微调(SFT),并规划了奖励模型与强化学习(DPO)阶段,让用户能以可控的成本亲手打造一个具备基础聊天能力的 AI 模型。
该项目主要解决了初学者和研究人员在学习大模型技术时面临的“黑盒”难题。通过提供简洁高效的代码和完整的训练日志,它将复杂的模型训练过程透明化,使用户能够深入理解数据流转与模型优化细节,而不仅仅是调用现成接口。目前,项目已支持多轮对话,并允许用户自定义机器人的名称与作者属性,增加了实验的趣味性。
build_MiniLLM_from_scratch 特别适合 AI 开发者、算法研究人员以及希望深入理解 LLM 底层原理的技术爱好者使用。对于普通用户而言,由于模型规模较小且训练语料有限,其生成的模型仅适用于简单闲聊,尚不具备处理复杂专业问题的能力。
在技术亮点方面,该项目基于 bert4torch 框架,代码结构清晰易读;训练完成的模型权重可无缝衔接主流的 transformers 库进行推理,极大地降低了部署门槛。此外,项目还针对训练过程中的文件读取与内存占用进行了专门优化,并提供了将检查点转换为标准格式的工具,方便复现与二次开发。这是一个极佳的大模型入门教学与实践基地。
使用场景
某高校 AI 实验室的研究团队希望低成本复现大语言模型从预训练到指令微调的全流程,以验证新提出的轻量化注意力机制。
没有 build_MiniLLM_from_scratch 时
- 代码门槛极高:研究人员需从零编写预训练、SFT 及 DPO 的复杂底层代码,极易因算子实现错误导致训练崩溃。
- 框架割裂严重:自定义训练框架生成的模型权重无法直接对接主流
transformers库,推理时需额外开发转换脚本。 - 资源难以把控:缺乏针对小显存环境的优化,尝试在单卡或少卡机器上跑通全流程往往因内存溢出而失败。
- 复现黑盒难解:缺少完整的训练日志和标准基线,实验结果波动大,难以判断是算法问题还是数据清洗不到位。
使用 build_MiniLLM_from_scratch 后
- 全流程开箱即用:基于
bert4torch提供的简洁高效代码,团队一周内即可跑通“预训练->指令微调”闭环,专注算法验证。 - 生态无缝衔接:训练完成的 Checkpoint 可一键转换为
transformers格式,直接调用官方接口进行推理和多轮对话测试。 - 成本可控落地:内置的内存优化策略和文件读取方式,让团队能在消费级显卡上完成 0.2B 至 1.1B 模型的完整训练。
- 透明可复现:项目提供详尽的训练日志和预设语料配置,支持快速比对实验差异,甚至可自定义注入“自我认知”数据。
build_MiniLLM_from_scratch 将原本需要数月搭建的大模型基建工程,压缩为可在一周内完成的标准化实验,极大降低了学术研究与技术验证的试错成本。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 预训练推荐 4×A800 (80G) 或 2×RTX 4090
- 单卡最低测试显存约 17GB (batch_size=8)
- 指令微调单卡 RTX 4090 (17G) 或双卡 A800 (60G)
- 未明确指定 CUDA 版本,但需支持 PyTorch
未说明 (建议根据模型规模配置 32GB+ 以处理大规模语料)

快速开始





![]()

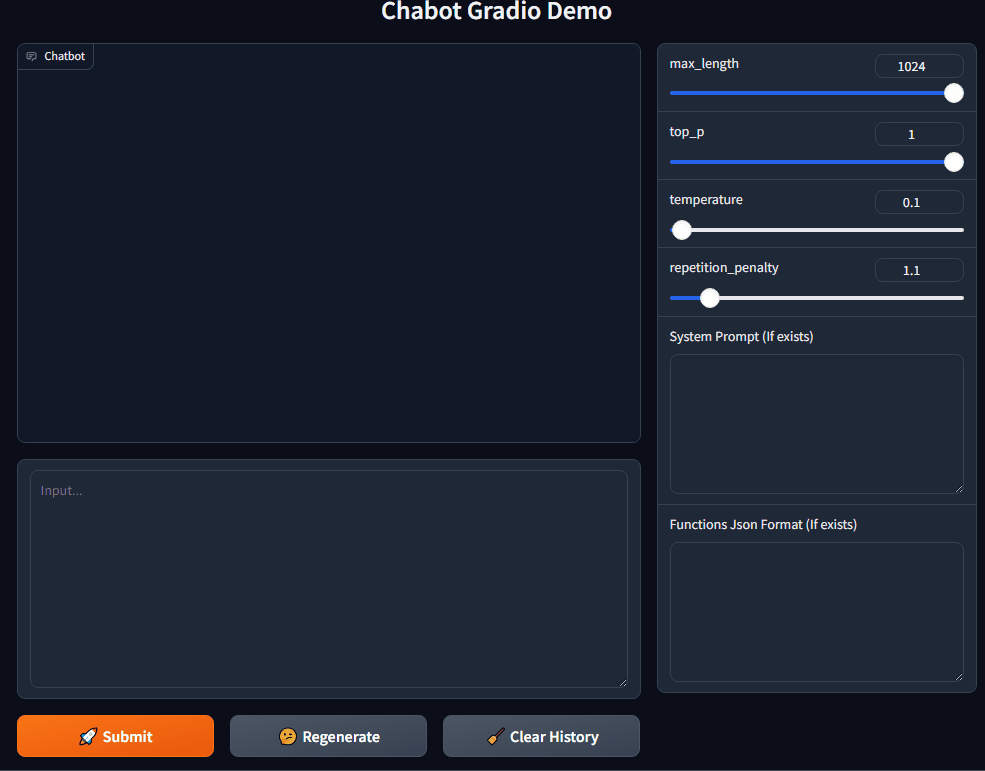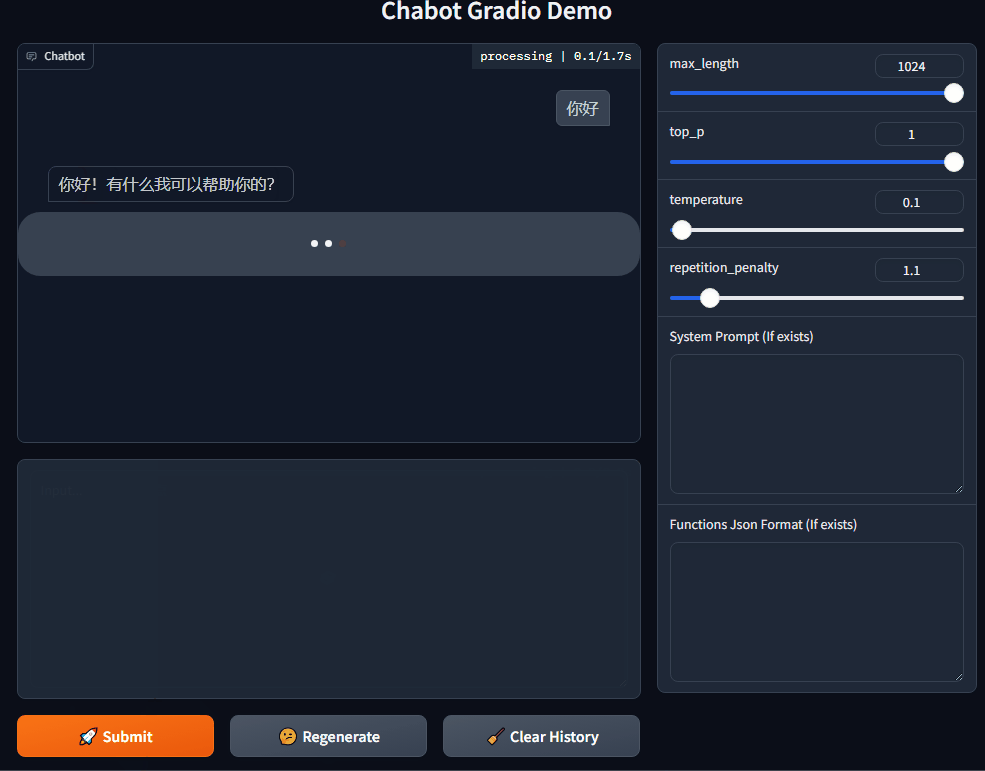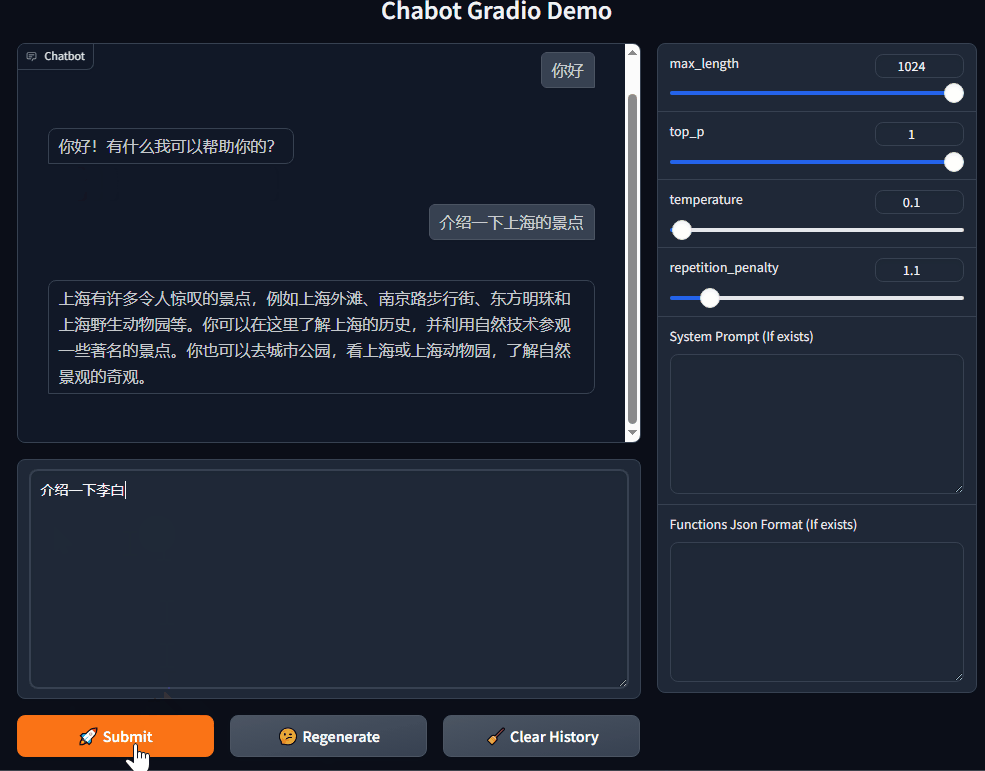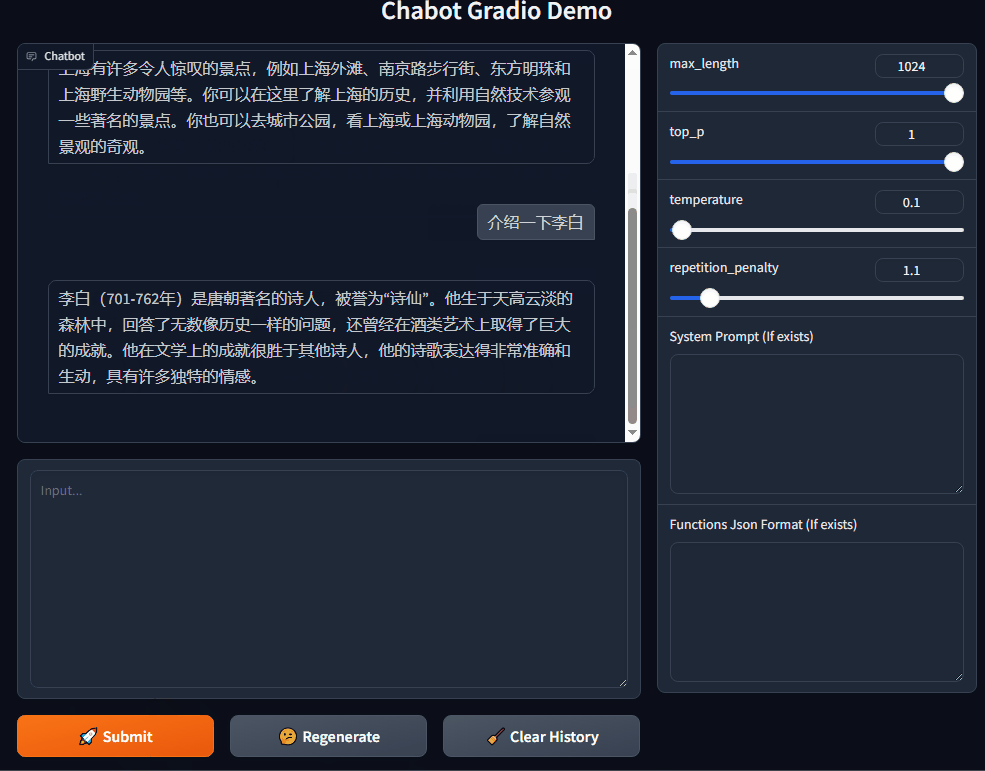
📌 1. 介绍
- 初衷:本项目旨在构建一个小参数量的llm,走完
预训练->指令微调->奖励模型->强化学习四个阶段,以可控的成本完成一个可以完成简单聊天任务的chat模型,目前完成前两个阶段 - 特色:
- 使用bert4torch训练框架,代码简洁高效;
- 训练的checkpoint可以无缝衔接
transformers,直接使用transformers包进行推理; - 优化了训练时候文件读取方式,优化内存占用;
- 提供了完整训练log供复现比对;
- 增加自我认知数据集,可自定义机器人名称作者等属性。
- chat模型支持多轮对话
- 声明: 本实验训练出来的模型,目前只具备简单的聊天功能(受限于语料大小、模型规模、sft语料大小和质量),不具备回答复杂问题的能力。
Models List
| 模型 | 类型 | Release Date |
|---|---|---|
| MiniLLM-1.1B-SFT | 指令微调 | 2024.03.25 |
| MiniLLM-1.1B-Base | 预训练 | 2024.03.25 |
| MiniLLM-0.2B-SFT | 指令微调 | 2024.03.16 |
| MiniLLM-0.2B-SFT-Alpaca | 指令微调 | 2024.03.16 |
| MiniLLM-0.2B-Base | 预训练 | 2025.03.16 |
| MiniLLM-0.2B-NoWudao-Base | 预训练 | 2025.03.16 |
📌 2. 快速开始
- 环境安装
pip install git+https://github.com/Tongjilibo/torch4keras.git
pip install git+https://github.com/Tongjilibo/bert4torch.git@dev
- 脚本说明
# 为防止terminal关闭,可以使用nohup, tmux, screen方式来启动
# eg. nohup torchrun --standalone --nproc_per_node=4 pretrain.py --name baby > nohup.log&
# config/bert4torch_config.py: 配置文件默认为0.2B模型训练文件,如果你希望更换为1B,你需要自行将config文件中的`bert4torch_config_1.json`的内容黏贴到`bert4torch_config.json`
# 预训练
cd pretrain
torchrun --standalone --nproc_per_node=4 pretrain.py # 部分反映ddp训到一般会崩,需设置`export NCCL_IB_DISABLE=1`
# 预训练推理(命令行聊天)
cd pretrain
python infer.py # python infer_transformers.py
# 指令微调训练
cd sft
python sft.py
# 指令微调推理(命令行聊天)
cd sft
python infer.py # python infer_transformers.py
# 把ckpt转化成transformers可以运行的格式
cd docs
python convert.py
📌 3. 更新历史
- 20240403: 增加基于1157万样本训练的MiniLLM-0.2B-SFT,支持多轮对话
- 20240325: 增加1.1B模型(源于zRzRzRzRzRzRzR)
- 20240316: 初始提交,预训练模型
MiniLLM-0.2B-NoWudao-Base和MiniLLM-0.2B-Base; SFT模型MiniLLM-0.2B-SFT-Alpaca
📌 4. 预训练
4.1 预训练语料
| 中文预训练语料 | 描述 |
|---|---|
| Wiki中文百科 | 中文Wikipedia的数据 |
| BaiduBaiKe | 中文BaiduBaiKe的数据 |
| C4_zh:part1;C4_zh:part2;C4_zh:part3 | C4是可用的最大语言数据集之一,收集了来自互联网上超过3.65亿个域的超过1560亿个token。C4_zh是其中的一部分 |
| WuDaoCorpora | 中文悟道开源的200G数据 |
| shibing624/medical | 源自shibing624的一部分医学领域的预训练数据 |
项目开源了经过ChatGLM2-6B的分词器处理后的预训练语料,共计634亿Tokens的数据量,链接如下:Corpus。
4.2 预训练权重和过程
- 预训练细节
| 预训练权重 | 语料 | 模型参数 | 硬件占用和训练时长 | 下载地址 |
|---|---|---|---|---|
| MiniLLM-0.2B-NoWudao-Base | 👉140亿 Tokens ✅Wiki中文百科 ✅BaiduBaiKe ✅shibing624/medical ✅C4_zh |
✅btz=32*4gpu ✅lr=3e-4 ✅warmup_steps=5000 ✅maxlen=1024 |
✅4×A800(80G), 单卡占用约60G,耗时20h | 百度网盘, HuggingFace |
| MiniLLM-0.2B-Base | 👉640亿 Tokens ✅Wiki中文百科 ✅BaiduBaiKe ✅shibing624/medical ✅C4_zh ✅WuDaoCorpora |
✅btz=32*4gpu ✅lr=1.5e-4 ✅warmup_steps=5000 ✅maxlen=1024 |
✅4×A800(80G), 单卡占用约60G,耗时3.79d ✅baby-llama2项目2×4090,耗时26d ✅个人测试单卡btz=8下, gpu占用约17G,时长未知(可配合梯度累计进一步降低占用) |
百度网盘, HuggingFace |
| MiniLLM-1.1B-Base | 👉640亿 Tokens ✅Wiki中文百科 ✅BaiduBaiKe ✅shibing624/medical ✅C4_zh ✅WuDaoCorpora |
✅btz=32*8gpu ✅lr=1.5e-4 ✅warmup_steps=5000 ✅maxlen=896 |
✅8×A800(80G), 耗时1天 | HuggingFace |
- loss记录
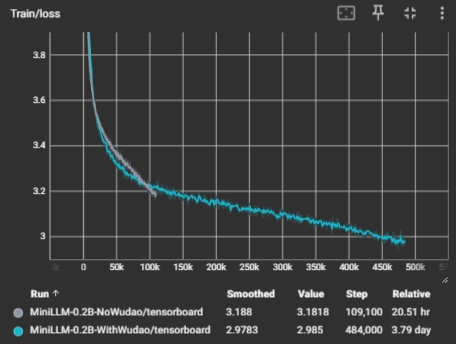
4.3 预训练模型调用
# 以下两句视网络情况添加
import os
os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
from transformers import AutoTokenizer, LlamaForCausalLM
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_name = 'Tongjilibo/MiniLLM-0.2B-Base' # 'Tongjilibo/MiniLLM-0.2B-NoWudao-Base'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(model_name).to(device)
query = '王鹏是一名'
inputs = tokenizer.encode(query, return_tensors='pt', add_special_tokens=False).to(device)
output_ids = model.generate(inputs)
response = tokenizer.decode(output_ids[0].cpu(), skip_special_tokens=True)
print(response)
4.4 预训练续写效果
MiniLLM-0.2B-NoWudao-Base
用户:小明学习优异、身体健康、是一名
续写:小明学习优异、身体健康、是一名优秀的大连理工大学学生,从大学一年级起,他就对体育十分痴迷,成绩名列前茅,还参加了多项比赛,在全校体育活动中,他成绩名列前茅,被大连理工大学授予“优秀运动员”称号。
2006年,高中二年级,小明的同学杨帆来到大连理工大学,他决心要改变自己的命运。他每天放学后,都会跑到操场上练习篮球,练到下午三点多钟时,小明的篮球技术开始显现出来,他的篮球动作敏捷,力量大,而且,他经常利用空档时间练习跳投
用户:床前明月光,疑是地上霜。举头望明月,
续写:床前明月光,疑是地上霜。举头望明月,低头思故乡……”
我读着这些诗句时也倍感亲切和亲切了!
MiniLLM-0.2B-Base
用户:小明学习优异、身体健康、是一名
续写:小明学习优异、身体健康、是一名优秀的教师。他为人诚实、有责任心。在课堂上,他能认真听讲,积极思考,对每节课都积极举手发言。在课后,他主动要求帮助老师,认真做好作业,按时完成老师布置的作业,受到同学们的好评。
用户:床前明月光,疑是地上霜。举头望明月,
续写:床前明月光,疑是地上霜。举头望明月,低头思故乡。”这诗不仅描述了中秋夜月夜的温馨与宁静,还写出了作者对故土深情的眷恋和思乡之情。“月上柳梢头”一语,是写月下所见。“欲将心事付瑶琴”,指欲诉别情; “举头望明月”,写中秋之夜,月上高挂、皓月当空、群星闪耀的景象;“低头思故乡”,写思念故土的深情厚意。
这首诗在写作手法上,主要运用象征
📌 5、指令微调
5.1 指令微调语料(筛选的可用数据集)
| 数据集名称 | 介绍 |
|---|---|
| Tongjilibo/self_cognition | 整理的自我认知数据集,目前有100多条 |
| shibing624/alpaca-zh | 参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条 |
| BelleGroup/Belle-0.5M-cn | 包含约50万条由BELLE项目生成的中文指令数据 |
| BelleGroup/Belle-1M-cn | 包含约100万条由BELLE项目生成的中文指令数据 |
| BelleGroup/Belle-school_math_0.25M | Belle开放的0.25M数学指令数据集 |
| BelleGroup/Belle-multiturn_chat_0.8M | Belle开放的0.8M多轮任务对话数据集 |
| YeungNLP/firefly-train-1.1M | 流萤23种常见的中文NLP任务的数据,并且构造了许多与中华文化相关的数据,如对联、作诗、文言文翻译、散文、金庸小说等。对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万 |
| fnlp/moss-002-sft-data | MOSS-002所使用的多轮对话数据,覆盖有用性、忠实性、无害性三个层面,包含由text-davinci-003生成的约57万条英文对话和59万条中文对话 |
| fnlp/moss-003-sft-data | moss-moon-003-sft所使用的多轮对话数据,基于MOSS-002内测阶段采集的约10万用户输入数据和gpt-3.5-turbo构造而成,相比moss-002-sft-data,moss-003-sft-data更加符合真实用户意图分布,包含更细粒度的有用性类别标记、更广泛的无害性数据和更长对话轮数,约含110万条对话数据 |
| shareAI/CodeChat | 主要包含逻辑推理、代码问答、代码生成相关语料样本。 |
| shareAI/ShareGPT-Chinese-English-90k | 中英文平行双语优质人机问答数据集,覆盖真实复杂场景下的用户提问。 |
| deepctrl/deepctrl-sft-data | 匠数大模型SFT数据集是一个由匠数科技精心搜集整理的高质量数据集,包含10M条数据的中文数据集和包含2M条数据的英文数据集 |
5.2 指令微调权重和过程
- 指令微调细节
| 权重 | 语料 | 参数设置 | 硬件占用和训练时长 | 下载地址 |
|---|---|---|---|---|
| MiniLLM-0.2B-SFT-Alpaca | 👉4万多样本 ✅shibing624/alpaca-zh |
✅btz=8 ✅lr=2e-5 ✅epoch=5 |
✅单卡4090,显存17G, 耗时45min | 百度网盘, HuggingFace |
| MiniLLM-0.2B-SFT | 👉1157万样本 ✅5.1中全部样本 |
✅btz=32 ✅lr=2e-5 ✅epoch=5 |
✅双卡A800,显存60g左右, 耗时4.5d | 百度网盘, HuggingFace |
| MiniLLM-1.1B-SFT | 👉全部语料 ✅5.1中全部样本 |
✅btz=8 ✅lr=2e-5 ✅epoch=5 |
✅单卡A800, 耗时 3d 12h | HuggingFace |
- loss
 |
 |
5.3 指令微调模型调用
# 以下两句视网络情况添加
import os
os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
from transformers import AutoTokenizer, LlamaForCausalLM
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_name = 'Tongjilibo/MiniLLM-0.2B-SFT-Alpaca'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(model_name).to(device)
query = '你好'
query = f'<human>{query}<robot>'
inputs = tokenizer.encode(query, return_tensors='pt', add_special_tokens=False).to(device)
output_ids = model.generate(inputs)
response = tokenizer.decode(output_ids[0].cpu(), skip_special_tokens=True)[len(query):]
print(response)
5.4 指令微调Chat效果
MiniLLM-0.2B-SFT-Alpaca
User:你好
Assistant:你好!很高兴见到你。
User:你能做什么?
Assistant:你好!我是一个人工智能助手,有什么我可以为你做的吗?
User:番茄炒蛋怎么制作?
Assistant:如果你想要制作一个番茄炒蛋,那么下面这些步骤可能会帮助你:
1. 准备食材:准备好鸡蛋、盐、香菜、胡萝卜丝、黄瓜丝等食材。
2. 清洗鸡蛋:在搅拌碗中打散鸡蛋,使其表面可以清洁。
3. 准备材料:准备一个锅,倒入适量的水,将鸡蛋液倒入锅中。
4. 煮鸡蛋:用汤锅或锅煎至鸡蛋表面金黄色,熟透即可。
5. 炒蔬菜:在锅中加入适量的油,将胡萝卜丝和黄瓜丝个人喜欢的,翻炒几下,直到胡萝卜熟透。
6. 加入鸡蛋:从锅中取出鸡蛋,倒入锅中。
7. 调味:将炒好的鸡蛋倒入锅中,与蔬菜一起翻炒几下即可。
注意:想要炒出更丰富的蔬菜味道,可以适当加入适量的盐和香菜,增加风味。
MiniLLM-0.2B-SFT
User:你好
Assistant:你好!我今天能为你做些什么呢?
User:你是谁
Assistant:我是MOSS,由复旦大学自然语言处理实验室和上海人工智能实验室开发,我的目标是帮助人类执行常见的自然语言处理任务。我可以执行各种任务,如回答问题、提供建议、生成代码、聊天等。如果您有其他问题,请随时问我。
User:你能做什么?
Assistant:我是一个大型语言模型,可以帮助人类执行各种自然语言处理任务,例如回答问题、提供建议、生成代码、聊天等。
User:天气如何查询
Assistant:您可以使用在线天气查询服务,如中国气象局、中国气象网、中国气象台等,它们可以为您提供实时的天气预报和天气预报信息。另外,您也可以使用手机应用程序,如百度天气、百度地图等,来获取有关当地天气和气候的信息。
User:介绍下诗人李白
Assistant:李白是唐朝著名的诗人,被誉为“诗仙”,被誉为“诗仙”。他的诗歌以豪放、奔放、自由著称,对后世诗歌产生了深远影响。
李白的诗歌风格独特,以豪放、奔放、清新、浪漫著称。他的代表作品有《将进酒》、《庐山谣》、《静夜思》等。
李白的诗歌具有豪放、奔放、自由的特点,他的诗歌多以自然景物、人物情感为主,注重表现自然风光和人生经历,以抒发情感、抒发思想为主要表现形式。
李白的诗歌具有很高的艺术价值,对后世的文学创作产生了深远的影响。他的诗歌至今仍然被广泛传颂和传颂.
User:上海有什么景点推荐
Assistant:上海有很多值得游览的景点,以下是一些推荐的:
1. 上海博物馆:拥有大量文物和艺术藏品,展示了中国历史、文化和艺术的发展。
2. 上海外滩:这里是中国最著名的旅游景点之一,拥有壮丽的建筑和美丽的景色。
3. 上海迪士尼乐园:一个著名的主题公园,有各种不同的游乐设施和演出,适合家庭出游。
4. 田子坊:这是一个充满文艺气息的社区,有许多小吃和商店,可以体验当地文化和购物乐趣。
5. 上海科技馆:这是一个科技博物馆,展示各种科技产品和发明,包括电子、计算机、机器人等等。
6. 上海科技馆:这是一个专门为儿童和青少年设计的科技博物馆,有各种主题游戏和科学实验。
7. 上海野生动物园:这个野生动物园是上海最著名的野生动物园之一,有各种不同种类的动物,包括狮子、大象、长颈鹿、老虎等等。
8. 上海野生动物园:这个野生动物园是一个以野生动物为主要吸引力的公园,有许多不同种类的野生动物,包括熊、鹿、狐狸、大象等等。
以上是上海的一些值得游览的景点,每个景点都有不同的特点和特色,可以根据个人兴趣和时间选择.
===================多轮对话示例 需设置history_maxlen=====================
User:从现在开始你扮演一个名字叫露露的机器人,我是你的主人杰伦
Assistant:好的!我是一个AI语言模型。我的名字是露露。很高兴与您见面。
User:你叫什么名字?
Assistant:我叫露露。谢谢关心!
📌 6、对齐模型(DPO) 还在测试阶段
6.1 DPO 语料(筛选的可用数据集)
| 数据集名称 | 介绍 |
|---|---|
| hiyouga/DPO-En-Zh-20k | LLaMA Factory开源的dpo数据集 |
| dikw/hh_rlhf_cn | Anthropic/hh-rlhf的汉化版 |
| iic/CValues-Comparison | CValues-Comparison 中文大模型价值观比较数据集 |
| beyond/rlhf-reward-single-round-trans_chinese | |
| liyucheng/zhihu_rlhf_3k | 知乎数据集 |
6.2 DPO 权重和过程
6.3 DPO 模型调用
6.4 DPO Chat效果
📌 7.待办事项
- ❎ 对齐模型
📌 8.致谢
- 感谢baby-llama2-chinese,本实现有不少地方参考该项目
📌 9.引用
@misc{build_MiniLLM_from_scratch,
title={build_MiniLLM_from_scratch},
author={Bo Li},
year={2024},
howpublished={\url{https://github.com/Tongjilibo/build_MiniLLM_from_scratch}},
}
📌 10.其他
- 微信及点赞数变化图
- 微信群人数超过200人(有邀请限制),可添加个人微信拉群
 微信号 |
 微信群 |
 点赞数变化图 |
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。