Bench2Drive
Bench2Drive 是一个专为自动驾驶端到端规划设计的闭环基准测试平台,由上海交通大学 ThinkLab 团队开发并入选 NeurIPS 2024。它旨在解决传统自动驾驶评估中“开环测试无法反映真实交互”的痛点,通过在高保真仿真环境 CARLA 中构建包含复杂交通场景的测试路线,让算法在动态环境中实时决策,从而更真实地衡量驾驶安全性与流畅度。
该工具特别适合自动驾驶领域的研究人员与开发者使用,尤其是从事端到端模型训练、强化学习策略优化及世界模型探索的团队。Bench2Drive 的独特亮点在于引入了基于世界模型的强化学习专家作为增强参照,并新增了“驾驶效率”与“驾驶平滑度”两项关键指标,避免了以往仅依赖轨迹误差(如 L2 错误)导致的误导性结论。此外,项目还贴心提供了小型验证集 Dev10,帮助开发者快速进行消融实验而无需过度拟合全套数据。无论是想要复现前沿算法,还是希望公正评估新模型性能,Bench2Drive 都提供了一个严谨、透明且社区活跃的评估标准。
使用场景
某自动驾驶初创团队正在研发端到端驾驶模型,急需在真实复杂的动态交通流中验证算法的闭环决策能力与安全性。
没有 Bench2Drive 时
- 评估指标失真:团队依赖 nuScenes 等数据集的开环规划指标(如 L2 误差),导致模型在静态数据上表现优异,但实车部署时因无法处理动态交互而频繁接管。
- 测试场景单一:自建仿真测试用例覆盖度低,难以复现极端长尾场景(如突发加塞、复杂路口博弈),无法全面暴露模型缺陷。
- 开发迭代低效:缺乏统一的标准评测协议和基线对比,每次调整架构后需耗费数周重新搭建测试环境,且结果难以与学术界前沿工作横向对齐。
- 过度拟合风险:在没有小型高方差验证集的情况下,直接在大规模路线上调试,极易导致模型过拟合特定路线特征,泛化能力差。
使用 Bench2Drive 后
- 闭环真实反馈:利用基于世界模型强化学习专家构建的闭环基准,直接评估模型在动态交互中的驾驶分数与成功率,提前发现并修复决策逻辑漏洞。
- 场景覆盖全面:通过官方提供的 220 条精心设计的复杂路线及新增的“驾驶效率”与“平滑度”指标,全方位压力测试模型在各类博弈场景下的表现。
- 研发加速标准化:借助 Dev10 小型验证集快速进行消融实验,避免全量测试的资源浪费,同时利用统一的 Leaderboard 实时对标 UniAD、VAD 等主流基线。
- 结论科学可靠:摒弃了无意义的开环指标,专注于闭环驾驶表现,确保每一次模型迭代都指向实际路测能力的提升,而非刷榜数字游戏。
Bench2Drive 通过提供高保真的闭环评测体系,帮助团队将研发重心从“刷数据指标”真正回归到“解决复杂驾驶难题”,大幅缩短了从算法训练到安全落地的路径。
运行环境要求
- Linux
- 必需 NVIDIA GPU(用于并行评估),具体型号未说明
- 需通过 CARLA 的 `-graphicsadapter` 参数指定显卡索引而非 CUDA_VISIBLE_DEVICES
- 显存大小未说明
未说明(但数据集最大达 4TB,建议大容量内存)
快速开始

NeurIPS 2024 数据集与基准测试赛道
官网 | Hugging Face | arXiv | 模型 | Discord
Think2Drive + Bench2Drive 能够提供什么?请点击观看视频。
↓↓↓

目录:
新闻
- [2026年3月27日] 查看 Bench2Drive-Speed,它评估了自动驾驶系统的一项全新且实用的功能——速度自定义!
- [2025年10月13日] 查看 Bench2Drive-VL,该版本实现了针对 VLM4AD 的闭环问答。同时,它还提供了 VLM 环境(Python 3.9 或更高版本)与 CARLA(Python 3.7 和 3.7)之间的高效通信接口。
- [2025年2月18日] 在我们最新的工作 DriveTransformer (ICLR25) 中,提出了一组小型验证集 Dev10,用于快速开发模型。 这10段视频是从官方的220条路线中精心挑选出来的,既具有挑战性又具代表性,且方差较小。建议将其用于消融实验,以避免对整个 bench2drive220 条路线过拟合。
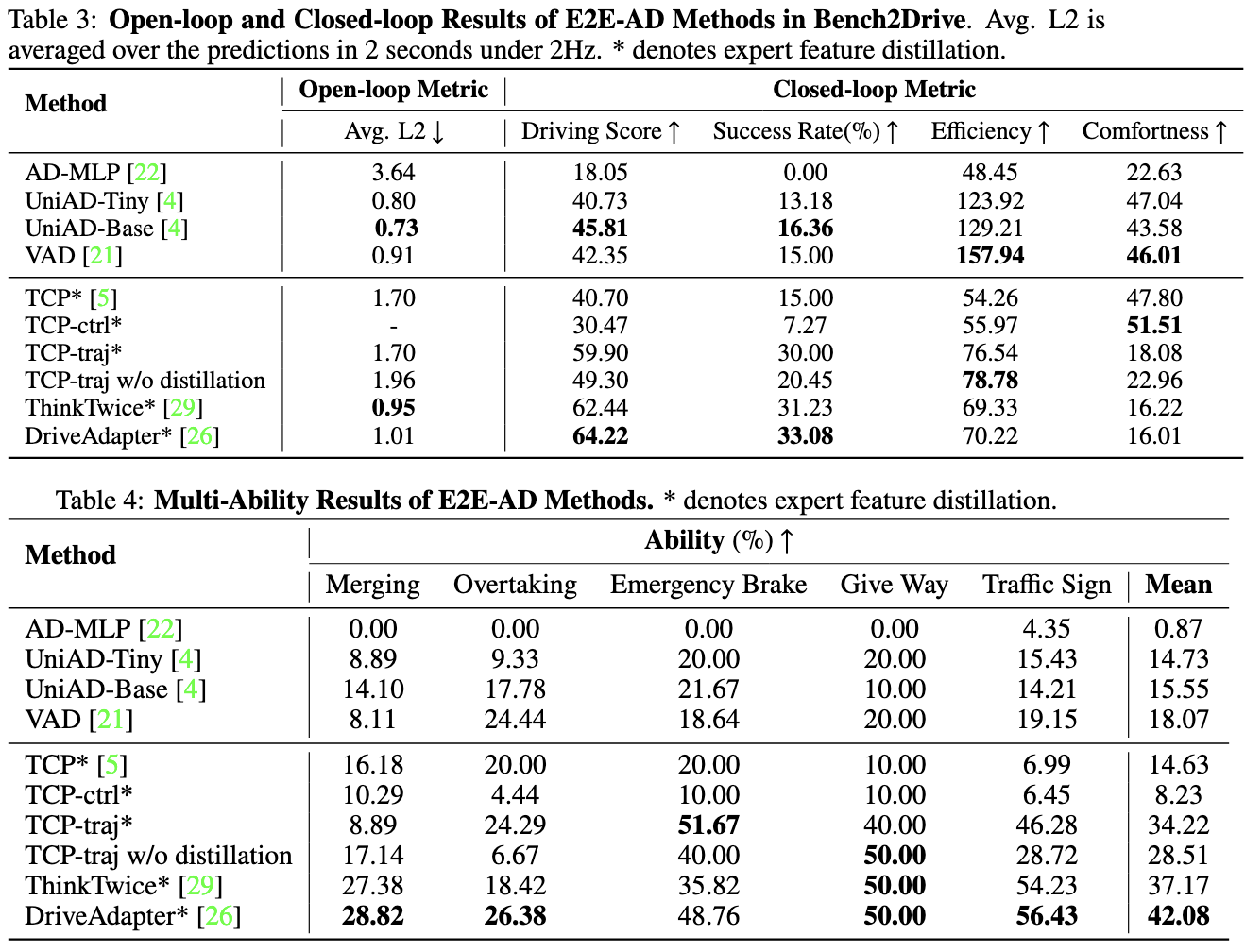
- [2025年2月5日] 正如 CARLA_GARGE 中详细描述的那样,L2 误差根本不是一个有意义的指标。我们同意 作者应停止报告 nuScenes 开环规划的结果,评审者也不应再要求提交此类结果。nuScenes 开环规划的数据毫无说服力,只会导致不公正和错误的结论,进而阻碍该领域的发展。作为社区的一员,我们也呼吁停止使用 nuScenes 开环规划作为评估标准。
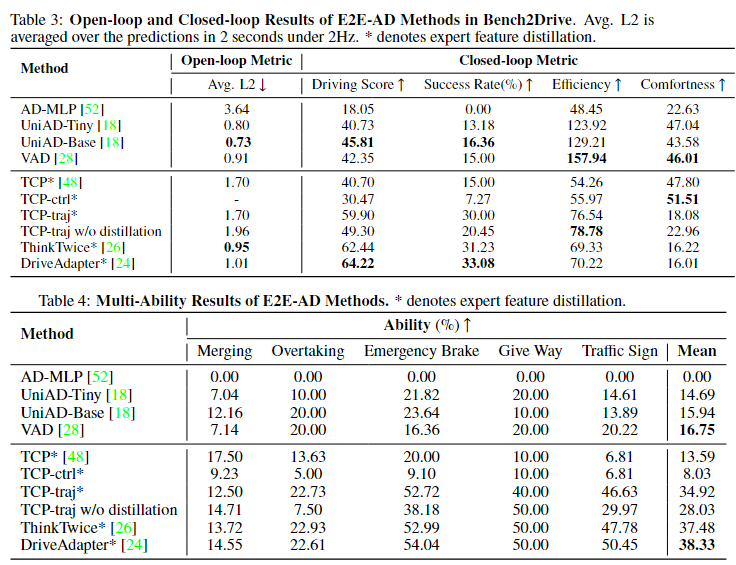
- [2024年10月14日] 如 issue 中善意指出的,能力计算中存在错别字。我们已修正这些错误并更新了多能力结果。此次更新 不会影响驾驶得分和成功率。
- [2024年10月14日] 同样在 issue 中提到,B2D_vad_dataset 中发现了一个 bug。我们暂时保留该问题,以保持与现有结果的一致性。预计此 bug 不会造成重大影响。用户可根据自身需求自行修复。
- [2024年9月26日] Bench2Drive 被 NeurIPS 2024 数据集与基准测试赛道接收。
- [2024年8月27日] 我们根据新协议更新了最新结果,引入了 两项新指标并修复了若干 bug。
- [2024年8月19日] [重大更新] 为更好地评估驾驶性能,我们新增了两项指标:驾驶效率和驾驶平顺性。因此,在计算驾驶得分时取消了最低速度惩罚,并将 TickRunTime 从 2000 延长至 4000,以便更宽松地评估驾驶表现。目前我们正在重新评估所有基线模型。
- [2024年8月10日] 我们更新了 UniAD 和 VAD 的 team_code 代理,以修复 2024年7月29日提到的相机投影 bug。它们的相应分数将很快随新指标一同发布。
- [2024年7月29日] 如 issue 中善意建议的,UniAD 和 VAD 的 team_code 代理在评估过程中存在一个 bug,即 后视摄像头的外参设置错误。训练过程本身是正确的。为保持与已公布结果的一致性,我们暂不修改代码。强烈建议用户使用正确的外参设置。
- [2024年7月22日] 我们在评估代码中增加了更多提醒,以避免日志丢失。根据 Haochen 的好建议,我们在评估工具包中添加了自动清理代码。用户可以在自己的 bash 脚本中设置无限重启评估,直到完成为止,因为 CARLA 容易崩溃。
- [2024年7月10日] 我们进一步清理并增加了完整数据集(13638 条片段)。由于 HuggingFace 每个仓库最多只能存储 10000 个文件,我们使用两个仓库来存放完整数据集。根据此 issue issue 的建议,我们为每个子集添加了片段列表和 SHA256 校验值。
- [2024年6月19日] 由于上传到 HuggingFace 的脚本中存在一个错别字,HuggingFace 版本中的 VehicleTurningRoutePedestrian 场景的所有片段都为空。我们已经修复了这个问题。请检查您的数据,确保它们不为空。
- [2024年6月5日] Bench2Drive 发布了完整数据集(10000 条片段)、评估工具、基线代码以及基准测试结果。
- [2024年4月27日] Bench2Drive 发布了官方训练数据的 Mini(10 条片段)和 Base(1000 条片段)划分。
数据集
- 该数据集包含3个子集,由我们强大的基于强化学习的世界模型专家团队Think2Drive收集,分别为Mini(10段视频)、Base(1000段视频)和Full(10000段视频),以适应不同计算资源的需求。
- 数据集结构、标注信息及数据可视化 详细说明。
| 子集 | Hugging Face |
百度云 |
大约大小 | 文件列表 |
|---|---|---|---|---|
| Mini | 下载脚本 | - | 4G | Mini Json文件 |
| Base | Hugging Face链接 | 百度云链接 | 400G | Base Json文件 |
| Full | Full HF链接 - 9888个文件/Sup HF链接 - 3814个文件 | - | 4T | Full/Sup Json文件 |
请注意,Mini数据集包含10个具有代表性的场景。您可以从Base数据集中手动选择文件名来下载这些场景。
使用命令行:huggingface-cli download --repo-type dataset --resume-download rethinklab/Bench2Drive --local-dir Bench2Drive-Base 从HuggingFace下载数据集。如果HuggingFace被屏蔽,用户可以考虑使用 镜像站点。使用 BaiduPCS-Go 从百度云下载数据集。这两个命令行都支持断点续传。
学生模型代码(以Think2Drive为教师模型)
设置
- 下载并设置CARLA 0.9.15
mkdir carla cd carla wget https://carla-releases.s3.us-east-005.backblazeb2.com/Linux/CARLA_0.9.15.tar.gz tar -xvf CARLA_0.9.15.tar.gz cd Import && wget https://carla-releases.s3.us-east-005.backblazeb2.com/Linux/AdditionalMaps_0.9.15.tar.gz cd .. && bash ImportAssets.sh export CARLA_ROOT=YOUR_CARLA_PATH echo "$CARLA_ROOT/PythonAPI/carla/dist/carla-0.9.15-py3.7-linux-x86_64.egg" >> YOUR_CONDA_PATH/envs/YOUR_CONDA_ENV_NAME/lib/python3.7/site-packages/carla.pth # python 3.8也适用,请设置YOUR_CONDA_PATH和YOUR_CONDA_ENV_NAME
评估工具
- 将您的智能体添加到排行榜/team_code/your_agent.py,并将您的模型文件夹链接到Bench2Drive目录下。
Bench2Drive\ assets\ docs\ leaderboard\ team_code\ --> 请在此处添加您的智能体 scenario_runner\ tools\ --> 请在此处链接您的模型文件夹 - 调试模式
# 验证团队智能体的正确性,需设置GPU_RANK、TEAM_AGENT、TEAM_CONFIG bash leaderboard/scripts/run_evaluation_debug.sh - 多进程多GPU并行评估。如果您的team_agent保存了任何用于调试的图像,可能会占用大量磁盘空间。
# 请设置TASK_NUM、GPU_RANK_LIST、TASK_LIST、TEAM_AGENT、TEAM_CONFIG,建议GPU数量与任务数比例为1:2。 # 某些模型无法完成某些路线是正常现象,无论我们重启多少次评估。这种情况应被视为失败,通常发生在智能体表现不佳的路线上。 bash leaderboard/scripts/run_evaluation_multi_uniad.sh - 可视化——制作带有CAN总线信息打印在序列图像上的调试视频。
python tools/generate_video.py -f your_rgb_folder/ - 评价指标:请确保您的json文件中恰好包含220条路线。失败或崩溃状态同样可接受。否则,评价指标将不准确。
# 合并评估结果json文件,获取驾驶得分和成功率 # 该脚本将假定共有220条有结果的路线。若不足,则缺失的路线将被视为0分。 python tools/merge_route_json.py -f your_json_folder/ # 获取多能力评估结果 python tools/ability_benchmark.py -r merge.json # 获取驾驶效率和驾驶平顺性评估结果 python tools/efficiency_smoothness_benchmark.py -f merge.json -m your_metric_folder/
处理 CARLA
- CARLA 的依赖关系复杂且不够稳定。请非常仔细地查看 CARLA 的问题列表。
- 经常并多次使用 tools/clean_carla.sh 脚本。某些 CARLA 进程难以终止,务必确保运行 clean_carla.sh 以避免大量错误。
- 在我们的评估工具中,CARLA 的启动是自动化的:https://github.com/Thinklab-SJTU/Bench2Drive/tree/main/leaderboard/leaderboard/leaderboard_evaluator.py#L203。不过,您也可以始终通过单条命令行启动 CARLA 来进行调试。
- CARLA 并不受 CUDA_VISIBLE_DEVICES 环境变量控制!它是由命令行中的 -graphicsadapter 参数来控制的。有趣的是,在某些机器上,由于未知原因,-graphicsadapter=1 可能不可用。 例如,如果有 4 块 GPU,可能是:GPU0 使用 -graphicsadapter=0,GPU1 使用 -graphicsadapter=2,GPU2 使用 -graphicsadapter=3,GPU3 使用 -graphicsadapter=4。
- 端口冲突经常发生。请经常使用 lsof-i:YOUR_PORT 命令来避免端口冲突。尽量避免使用较小的端口号(小于 10000 的端口可能不安全)。
- 4.26.2-0+++UE4+Release-4.26 522 0 禁用核心转储文件。如果这两行信息出现且程序没有终止,通常是没有问题的。警告:lavapipe 并非符合规范的 Vulkan 实现,仅供测试使用。 这样的提示有时会出现,但偶尔也会有 bug。
- 如果您遇到问题,请始终尝试通过一条命令行启动 CARLA,以确保 CARLA 能够正常运行。 如果 CARLA 启动后立即退出,很可能是与 Vulkan 相关的问题。可以尝试运行 /usr/bin/vulkaninfo | head -n 5
- 重新安装 Vulkan 可能会有帮助:sudo apt install vulkan-tools; sudo apt install vulkan-utils。最终,您需要确保您的 Vulkan 配置正确。我们已经测试过 Vulkan 实例版本:1.x 警告:lavapipe 并非符合规范的 Vulkan 实现,仅供测试使用。 以及版本 1.1/1.2/1.3 都能正常工作。
- 使用
sleep命令对于避免 CARLA 崩溃非常重要。例如,在 https://github.com/Thinklab-SJTU/Bench2Drive/blob/main/leaderboard/leaderboard/leaderboard_evaluator.py#L207 中,对于较慢的机器,应适当延长睡眠时间。在进行多 GPU 评估时,如 https://github.com/Thinklab-SJTU/Bench2Drive/blob/main/leaderboard/scripts/run_evaluation_multi_uniad.sh#L58 所示,同样也需要为较慢的机器增加睡眠时间。
基准测试
V0.0.3(当前使用)
- 修复了能力计算中的拼写错误。(Issue #112)
- 修复了能力计算中的拼写错误。(Issue #112)
V0.0.2(已弃用)
- 修复了后视摄像头的外参错误。(Issue #36)
- 提高了 tickruntime 时间(2000 -> 4000)。
- Drive Score 移除了最低速度惩罚。
- 代码版本:
V0.0.1(已弃用)
- 初始版本
- 代码版本:
许可证
除非另有说明,所有资产和代码均采用 CC-BY-NC-ND 许可协议。
引用
如果本项目对您的研究有所帮助,请考虑引用我们的论文,引用格式如下:
@inproceedings{jia2024bench,
title={Bench2Drive:迈向闭环端到端自动驾驶的多能力基准测试},
author={Xiaosong Jia 和 Zhenjie Yang 和 Qifeng Li 和 Zhiyuan Zhang 和 Junchi Yan},
booktitle={NeurIPS 2024 数据集与基准测试赛道},
year={2024}
}
@inproceedings{li2024think,
title={Think2Drive:基于潜在世界模型的高效强化学习,用于准真实场景下的自动驾驶(在 CARLA-v2 中)},
author={Qifeng Li 和 Xiaosong Jia 和 Shaobo Wang 和 Junchi Yan},
booktitle={ECCV},
year={2024}
}
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。