Awesome-LLM4AD
Awesome-LLM4AD 是由上海交通大学 ReThinklab 团队维护的开源资源库,专注于整理大语言模型(LLM)在自动驾驶领域的前沿研究成果。它系统性地汇集了涵盖视觉 - 语言模型(VLM)、视觉 - 语言 - 动作模型(VLA)及世界模型等相关论文、数据集和代码项目,旨在推动"LLM4AD"这一统一范式的发展。
当前自动驾驶技术面临仿真与现实环境的差异(Sim2Real Gap)以及真实数据中长尾场景覆盖不足的难题。Awesome-LLM4AD 通过聚合利用大模型强大推理与泛化能力的最新方案,帮助研究者探索如何从自然语言指令、复杂感知理解到决策规划等多个维度提升自动驾驶系统的智能水平,使其更接近人类驾驶员的胜任力。
该资源库特别适合自动驾驶领域的研究人员、算法工程师及技术爱好者使用。其独特亮点在于不仅提供了按任务类型(如规划、感知、问答、生成)分类的详细文献列表,还关联了配套的综述论文与具体实现代码,部分条目甚至包含了未来展望性的研究(如基于自然语言指令的统一驾驶模型)。作为持续更新的社区驱动项目,Awesome-LLM4AD 为从业者提供了一站式的学术导航,助力快速把握技术风向并复现先进算法。
使用场景
某自动驾驶初创公司的算法团队正致力于研发基于大语言模型的决策规划系统,以应对复杂城市路况中的长尾场景。
没有 Awesome-LLM4AD 时
- 文献检索如大海捞针:研究人员需在 arXiv、Google Scholar 等多个平台手动搜索"LLM+Autonomous Driving"相关论文,极易遗漏最新的 VLA(视觉 - 语言 - 动作)模型成果。
- 技术路线难以对齐:缺乏统一的分类框架,团队难以快速厘清当前研究是侧重于感知增强、规划决策还是端到端生成,导致技术选型盲目。
- 复现成本高昂:找不到配套的代码仓库、数据集或仿真环境链接,往往花费数周时间清洗数据或重构代码,却因缺少关键依赖而失败。
- 前沿动态滞后:无法实时追踪领域内的最新突破(如自然语言指令驾驶),导致研发进度落后于学术界前沿水平。
使用 Awesome-LLM4AD 后
- 资源一站式获取:团队直接利用该清单中 curated 的论文列表,迅速锁定了如 Vega 等支持自然语言指令的统一模型,节省了 80% 的调研时间。
- 架构清晰明确:借助其按“规划、感知、问答、生成”分类的概览图,团队快速确定了以 VLA 模型为核心的技术演进路线。
- 复现效率倍增:通过列表中提供的代码链接、数据集(如 InstructScene)及仿真器信息,算法工程师在两天内成功搭建了基线系统。
- 持续同步前沿:订阅该仓库更新后,团队能第一时间掌握针对长尾场景的最新解决方案,确保持续的技术竞争力。
Awesome-LLM4AD 将分散的学术碎片整合为结构化知识图谱,极大缩短了从理论调研到工程落地的周期。
运行环境要求
未说明
未说明

快速开始
用于自动驾驶的大语言模型资源精选
![]()



这是一个关于**用于自动驾驶的大语言模型(LLM4AD)**的研究论文合集。该仓库将持续更新,以追踪LLM4AD(用于自动驾驶的大语言模型)领域的前沿进展,其中VLM4AD(用于自动驾驶的视觉-语言模型)和VLA4AD(用于自动驾驶的视觉-语言-动作模型)作为这一统一范式的重要组成部分。由上海交通大学ReThinkLab维护。
欢迎关注并点赞!如果您发现任何相关资料可能有所帮助,请随时联系我们(yangzhenjie@sjtu.edu.cn 或 jiaxiaosong@sjtu.edu.cn)或提交Pull Request。
引用
我们的综述论文位于 https://arxiv.org/abs/2311.01043,其中包含更详细的讨论,并将不断更新。
如果您觉得我们的仓库有帮助,请考虑引用它。
@misc{yang2023survey,
title={LLM4Drive: 自动驾驶领域的大语言模型综述},
author={Zhenjie Yang 和 Xiaosong Jia 和 Hongyang Li 和 Junchi Yan},
year={2023},
eprint={2311.01043},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
目录
LLM4AD 概述
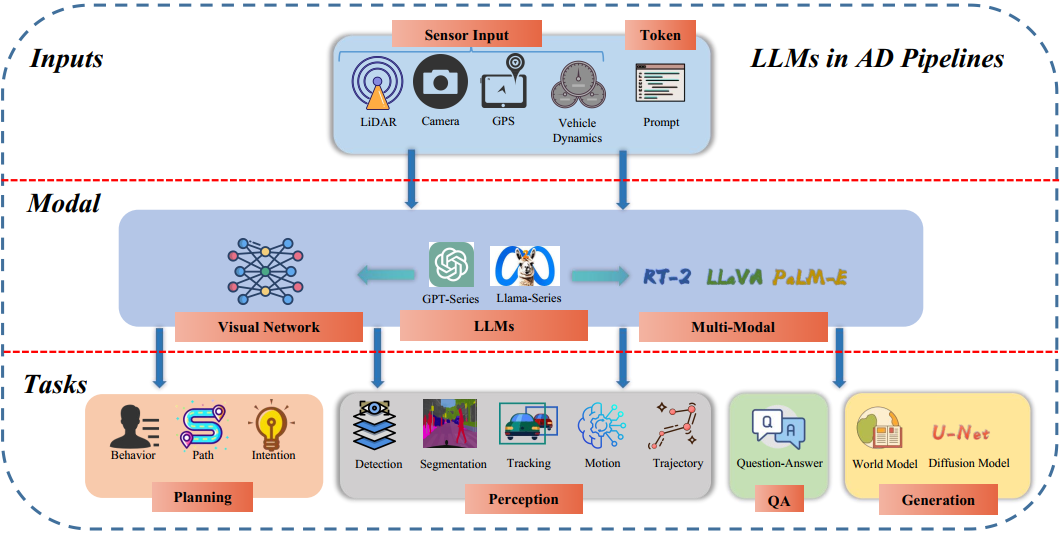
用于自动驾驶的大语言模型(LLM4AD)是指将大语言模型(LLMs)应用于自动驾驶领域。我们根据应用大语言模型的角度将其现有工作分为规划、感知、问答和生成四个方向。
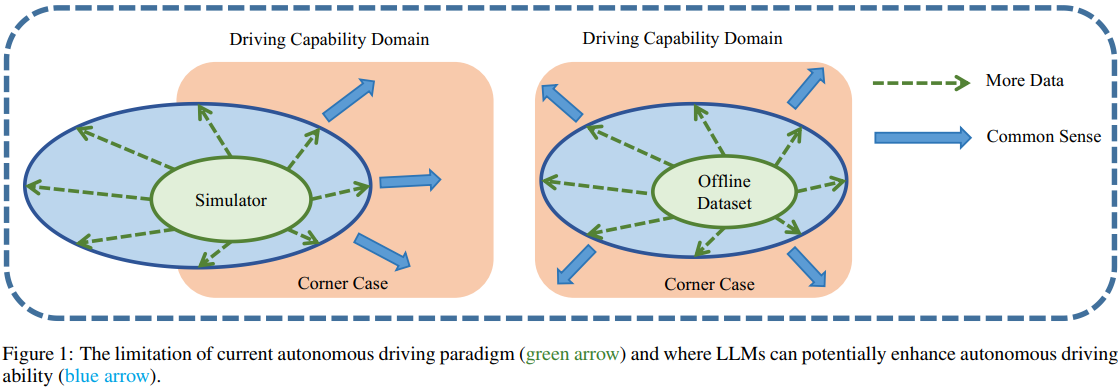
LLM4AD 的动机
橙色圆圈代表理想的驾驶能力水平,类似于经验丰富的驾驶员所具备的能力。获得这种能力主要有两种方法:一是通过在模拟环境中基于学习的技术;二是通过类似的方法从离线数据中学习。需要注意的是,由于仿真与现实世界之间存在差异,这两个领域并不完全相同,即“sim2real”差距。同时,离线数据是真实世界数据的一个子集,因为它直接从实际环境中收集而来。然而,由于自动驾驶任务具有众所周知的长尾特性,也很难完全覆盖其分布。自动驾驶的最终目标是通过大量数据收集和深度学习,将驾驶能力从基础的绿色阶段提升到更高级的蓝色阶段。
论文
展开
格式:
- [标题](论文链接) [链接]
- 作者1、作者2、作者3…
- 出版社
- 任务
- 关键词
- 代码或项目页面
- 数据集、环境或模拟器
- 发表日期
- 摘要
- 指标
-
- Sicheng Zuo、Yuxuan Li、Wenzhao Zheng、Zheng Zhu、Jie Zhou、Jiwen Lu
- 发表日期:2026年3月26日
- 任务:规划
- 数据集:InstructScene
- 摘要:
- Vega 是一种统一的视觉-语言-世界-动作模型,用于自动驾驶中的基于指令的生成和规划,采用自回归和扩散范式。
- 构建了一个大规模的驾驶数据集(InstructScene),包含约10万个场景,这些场景标注了各种驾驶指令和相应的轨迹。
- 展示了卓越的规划性能和强大的指令遵循能力,能够实现更加智能和个性化的驾驶系统。
Drive My Way:面向个性化驾驶的视觉-语言-动作模型偏好对齐
- Zehao Wang、Huaide Jiang、Shuaiwu Dong、Yuping Wang、Hang Qiu、Jiachen Li
- 发表日期:2026年3月26日
- 项目页面:Drive My Way
- 代码:Drive My Way
- 任务:规划
- 数据集:Bench2Drive
- 摘要:
- Drive My Way(DMW)是一个个性化的视觉-语言-动作(VLA)驾驶框架,能够与用户的长期驾驶习惯保持一致,并适应实时用户指令。
- DMW 从个性化的驾驶数据集中学习用户嵌入,并以此嵌入为条件进行规划,而自然语言指令则提供短期指导。
- 在 Bench2Drive 上的评估表明,其风格指令适应性有所提高,用户研究也证实了其生成的行为确实能被识别为每位驾驶员的独特风格。
ETA-VLA:基于时间融合与LLM内部稀疏化的高效令牌适配,适用于视觉-语言-动作模型
- Yiru Wang、Anqing Jiang、Shuo Wang、Yuwen Heng、Zichong Gu、Hao Sun
- 发表日期:2026年3月26日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出 ETA-VLA,这是一种用于自动驾驶中视觉-语言-动作(VLA)模型的高效令牌适配框架,旨在降低处理历史多视角帧的计算负担。
- 引入了一种 LLM 内部稀疏聚合器(ILSA),该聚合器受人类驾驶员注意力的启发,利用文本引导的评分和多样性保留策略动态修剪冗余的视觉令牌。
- 在 NAVSIM v2 上实现了与 SOTA 相当的性能,同时将 FLOPs 降低了约 32%,修剪了 85% 的视觉令牌,并将推理 FLOPs 减少了 61%,同时保持了 94% 的准确率。
-
- 王子渊、陈鹏、李丁、李驰威、张启超、夏仲璞、于桂珍
- 发表日期:2026年3月26日
- 任务:生成
- 数据集:Waymo Sim Agent
- 摘要:
- R1Sim是一种新颖的分词交通仿真策略,基于运动标记熵模式探索强化学习,以学习多样且高保真的交通仿真。
- 引入了一种熵引导的自适应采样机制,专注于此前被忽视的高不确定性、高潜力运动标记。
- 使用考虑安全性的奖励设计,结合群体相对策略优化(GRPO)来优化运动行为,从而实现真实、安全且多样的多智能体行为。
TIGFlow-GRPO:基于交互感知的流匹配与奖励驱动优化的人体轨迹预测
- 荆学鹏、陆文焕、孟浩、俞志智、魏建国
- 发表日期:2026年3月26日
- 任务:预测
- 摘要:
- TIGFlow-GRPO是一个两阶段的人体轨迹生成框架,将基于流的生成与行为规则相契合。
- 第一阶段使用带有轨迹-交互图(TIG)模块的CFM预测器,以建模精细的视觉-空间交互。
- 第二阶段采用流-GRPO后训练,将确定性流展开重新表述为随机ODE到SDE采样以进行探索,并通过复合奖励优化社会合规性和物理可行性。
DreamerAD:基于潜在世界模型的高效强化学习在自动驾驶中的应用
- 杨鹏轩、郑宇鹏、钱德恒、邢泽彬、张启超、王林波、张义晨、郭绍宇、夏仲璞、陈强、韩俊宇、徐凌云、潘益峰、赵东斌
- 发表日期:2026年3月25日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- DreamerAD是首个用于自动驾驶高效强化学习的潜在世界模型框架,将扩散采样从100步压缩至1步,速度提升80倍,同时保持视觉可解释性。
- 该方法利用捷径强制技术对去噪后的潜在特征进行步骤压缩,在潜在表示上构建自回归密集奖励模型,并采用高斯词汇采样进行GRPO,以将探索限制在合理轨迹范围内。
- 在NavSim v2上实现了87.7 EPDMS的最先进性能,证明了潜在空间强化学习在自动驾驶中的有效性。
-
- 王林波、郑宇鹏、陈强、李世伟、张义晨、邢泽彬、张启超、李翔、钱德恒、杨鹏轩、董一航、郝策、叶晓青、韩俊宇、潘益峰、赵东斌
- 发表日期:2026年3月25日
- 任务:预测、规划
- 数据集:NAVSIM
- 摘要:
- Latent-WAM是一个高效的端到端自动驾驶框架,通过空间感知和动力学信息丰富的潜在世界表示实现强大的轨迹规划。
- 它引入了空间感知压缩世界编码器(SCWE),用于提炼几何知识并压缩多视角图像;以及动态潜在世界模型(DLWM),用于预测未来的世界状态。
- 在NAVSIM v2和HUGSIM基准测试中取得了最先进的结果,仅用一个1.04亿参数的紧凑模型,便超越了先前的方法,且所需的训练数据显著减少。
-
- 周嘉伟、朱振鑫、杜凌翼、吕林业、周立军、吴占谦、罗洪成、田卓涛、王兵、陈光、叶杭君、孙海阳、李宇
- 出版单位:华中科技大学、小米电动车
- 发表日期:2026年3月25日
- 项目页面:PhyGenesis
- 任务:生成
- 数据集:CARLA
- 摘要:
- 提出了PhyGenesis,一种能够生成高视觉保真度且具有强物理一致性的驾驶视频的世界模型,尤其适用于挑战性或反事实轨迹。
- 该框架包括一个物理条件生成器,用于纠正无效轨迹;以及一个增强物理特性的视频生成器,用于生成多视角驾驶视频。
- 在大规模、富含物理特性的异构数据集上进行训练,该数据集结合了真实世界视频和在CARLA中生成的多样化挑战场景,从而实现轨迹修正和物理一致性的生成。
-
- 赵国洋、齐卫青、张凯、张晨光、龚泽英、毕志海、陈凯、马本善、刘明、马军
- 出版单位:香港科技大学、上海人工智能实验室
- 发表日期:2026年3月24日
- 项目页面:TS-1M
- 任务:感知
- 数据集:TS-1M
- 摘要:
- 介绍了TS-1M,这是一个大规模、全球多样化的交通标志数据集,包含超过一百万张图片,涵盖454个类别,并提供了一个诊断性基准,用于分析模型在实际挑战下的能力。
- 进行了跨三种学习范式(监督学习、自监督学习、多模态VLMs)的统一基准测试,揭示语义对齐是泛化能力和稀有类别识别的关键。
- 通过将交通标志识别与语义推理和空间定位相结合,以地图级决策约束为基础的实景自动驾驶实验,验证了其实际应用价值。
-
- 田晔、张静怡、王子豪、任晓远、余晓凡、奥纳特·贡戈尔、塔雅娜·罗辛
- 出版单位:加州大学圣地亚哥分校
- 发表日期:2026年3月22日
- 任务:VQA
- 数据集:NuScenes-QA
- 摘要:
- KLDrive是一个知识图谱增强的LLM推理框架,用于自动驾驶中的细粒度问题回答,结合基于能量的场景事实构建模块与LLM代理,实现基于事实的推理。
- 该框架使用结构化提示和少量上下文示例,即可适应各种推理任务,而无需进行大量特定任务的微调,从而减少幻觉并提高可靠性。
-
- 曹浩群、谢腾阳
- 发表日期:2026年3月20日
- 任务:规划
- 摘要:
- 为基于量化动作的行为克隆提供了理论基础,分析了误差传播和样本复杂度。
- 表明在稳定动力学和策略平滑性条件下,采用对数损失函数和量化动作可实现最优样本复杂度。
- 提出了一种基于模型的增强方法以改进误差界,并确立了量化误差与统计复杂度的基本极限。
X-World:用于可扩展端到端驾驶的可控自我中心多摄像头世界模型
- 郑朝达、李Sean、邓金浩、王振楠、陈世嘉、肖立强、迟子恒、林洪斌、陈康杰、王博洋、张宇、刘宪明
- 发表日期:2026年3月20日
- 任务:端到端
- 摘要:
- X-World是一种动作条件下的多摄像头生成式世界模型,能够模拟未来的视频观测结果,从而实现对端到端自动驾驶的可扩展且可重复的评估。
- 该模型可根据历史和动作序列生成未来的多摄像头视频流,并支持通过文本提示对交通参与者、道路元素及外观(如天气)进行可选控制。
- 其特点是采用多视角潜在视频生成器,旨在保证跨视角的几何一致性和时间连贯性,从而实现高质量、可控的仿真,用于评估和视频风格迁移。
-
- 刘晓璐、李一聪、王松、陈俊波、姚安吉拉、朱建科
- 发表日期:2026年3月20日
- 代码:DynFlowDrive
- 任务:规划
- 数据集:nuScenes、NAVSIM
- 摘要:
- DynFlowDrive是一种潜在世界模型,利用基于流的动力学来建模不同驾驶动作下世界状态的转换。
- 引入了一种考虑稳定性的一致性多模式轨迹选择策略,根据诱导场景转换的稳定性评估候选轨迹。
- 在nuScenes和NavSim基准测试中表现出持续的性能提升,且未增加额外的推理开销。
DriveTok:用于统一多视角重建与理解的3D驾驶场景标记化
- 朱东、郑文昭、左思成、闫思明、侯陆、周杰、卢继文
- 发表日期:2026年3月19日
- 任务:感知
- 数据集:nuScenes
- 摘要:
- DriveTok是一种高效的3D驾驶场景标记化工具,用于统一多视角的重建与理解,旨在解决多视角驾驶场景中的低效与不一致性问题。
- 它利用3D可变形交叉注意力机制将语义丰富的视觉特征转换为场景标记,并采用多视角Transformer对RGB、深度和语义信息进行重建,同时添加了一个3D头部用于语义占用预测。
DriveVLM-RL:受神经科学启发的视觉-语言模型强化学习框架,用于安全且可部署的自动驾驶
- 黄子琳、盛子豪、万正阳、曲燕松、游俊伟、蒋思聪、陈思凯
- 发表日期:2026年3月18日
- 项目页面:DriveVLM-RL
- 代码:DriveVLM-RL
- 任务:规划
- 数据集:CARLA
- 摘要:
- 提出了DriveVLM-RL框架,该框架受神经科学启发,通过双路径架构将视觉-语言模型(VLMs)融入强化学习(RL),以实现安全且可部署的自动驾驶。
- 其中包含静态路径,用于持续的空间安全性评估;以及动态路径,用于注意力门控的多帧语义风险推理,并结合分层奖励合成机制。
- 采用异步训练流程,将昂贵的VLM推理与环境交互解耦,在部署时移除所有VLM组件,以确保实时可行性。
VLM-AutoDrive:面向安全关键型自动驾驶事件的视觉-语言模型后训练方法
- 莫哈默德·卡齐姆·巴特、黄宇凡、尼凯特·阿加瓦尔、王浩、迈克尔·伍兹、约翰·肯扬、林宗毅、杨晓东、刘明宇、谢凯文
- 发表日期:2026年3月18日
- 任务:感知
- 摘要:
- VLM-AutoDrive是一个模块化的后训练框架,用于将预训练的视觉-语言模型(VLMs)适配到高保真度的驾驶异常检测任务中。
- 该框架整合了元数据字幕、LLM描述、VQA对以及思维链推理,以实现领域对齐且可解释的学习。
- 在真实世界的行车记录仪视频上,其碰撞F1分数从0.00提升至0.69,整体准确率则从35.35%提高到77.27%。
-
- 姜超康、周德森、刘久明、孙凯文
- 发表日期:2026年3月18日
- 代码:VectorWorld
- 任务:预测、生成
- 数据集:Waymo开放运动数据集、nuPlan
- 摘要:
- VectorWorld是一款用于自动驾驶的流式世界模型,可在滚动过程中增量生成以车辆为中心的车道-行人向量图块,从而支持闭环评估。
- 该模型解决了生成式世界模型中的关键问题:通过运动感知的门控VAE实现基于历史条件的初始化;借助一步式掩码补全模型实现实时外延填充;并通过名为$Δ$Sim的物理对齐NPC策略确保长 horizon 的稳定性。
基于VLA的驾驶系统的安全案例模式:来自SimLingo的洞见
- 格哈德·于、石川冬树、奥卢瓦费米·奥杜、阿尔文·博耶·贝尔
- 发表日期:2026年3月16日
- 任务:端到端
- 摘要:
- 提出RAISE,一种针对视觉-语言-行动(VLA)驱动系统的新安全案例设计方法,引入定制化模式及对危害分析与风险评估(HARA)的扩展。
- 解决了将开放式自然语言输入整合到自动驾驶多模态控制回路中所产生的新型安全风险问题。
- 以SimLingo为例,说明该方法如何为这一新兴系统类别构建严谨、基于证据的安全性声明。
-
- 埃里克·席尔瓦、雷哈娜·亚斯敏、阿里·肖克尔
- 出版方:(根据上下文推断为米尼奥大学、阿威罗大学)
- 发表日期:2026年3月16日
- 任务:推理
- 摘要:
- 介绍CRASH,一个基于LLM的代理,能够自动对来自NHTSA数据库的真实AV事故报告进行推理,生成摘要、归因主要原因并评估AV的贡献度。
- 对2,168起事故的分析显示,64%归因于感知或规划失败,约50%涉及追尾事故,凸显了持续存在的挑战。
- 经领域专家验证,其在归因AV系统故障方面的准确率达到86%,表明其作为可扩展且可解释的自动化事故分析工具具有潜力。
-
- 高银峰、刘德清、张启超、郑宇鹏、田浩辰、李光、叶航军、陈龙、丁大伟、赵东彬
- 发表日期:2026年3月16日
- 任务:端到端
- 数据集:Bench2Drive
- 摘要:
- 提出TakeVLA,一种新颖的视觉-语言-行动(VLA)后训练框架,利用接管数据缓解端到端自动驾驶中的分布偏移问题。
- 引入接管前的语言监督,主动教导模型识别易出错的情境,培养预防性思维并扩大安全余量。
- 提出场景梦魇机制,这是一种在重建的接管场景中运行的强化微调范式,鼓励主动探索而非被动适应偏好。
PerlAD:基于伪仿真强化学习的闭环端到端自动驾驶增强方案
- 高银峰、张启超、刘德清、夏仲普、李光、马坤、陈广、叶航军、陈龙、丁大伟、赵东彬
- 发表日期:2026年3月16日
- 任务:端到端
- 数据集:Bench2Drive、DOS
- 摘要:
- 提出PerlAD,一种基于伪仿真的强化学习方法,适用于闭环端到端自动驾驶,在向量空间中运行以实现高效、无渲染的训练。
- 引入预测型世界模型生成反应式智能体轨迹,以及分层解耦的规划器,结合IL进行横向路径规划和RL进行纵向速度优化。
- 在Bench2Drive基准测试中达到最先进水平,并在DOS基准测试中的安全关键遮挡场景中展现出可靠性。
AutoMoT:面向端到端自动驾驶的异步混合Transformer统一视觉-语言-行动模型
- 黄文辉、张松岩、黄启航、王志东、毛志奇、科利斯特·丘亚、陈展、陈龙、吕晨
- 发表日期:2026年3月16日
- 项目页面:AutoMoT
- 任务:端到端
- 摘要:
- 提出AutoMoT,一个将推理与行动生成统一于单一视觉-语言-行动模型中的端到端自动驾驶框架。
- 利用混合Transformer架构,通过共享注意力和异步快慢推理实现高效的策略生成。
- 探讨预训练VLM在自动驾驶中的功能边界,发现语义提示足以完成场景理解,但精细调优对于规划等行动级任务至关重要。
-
- 斯特凡·恩格迈尔、卡塔琳娜·温特、法比安·B·弗洛尔
- 出版方:慕尼黑工业大学
- 发表日期:2026年3月15日
- 任务:规划、预测
- 摘要:
- 提出WorldVLM,一种混合架构,将视觉-语言模型(VLM)用于高层次情境推理,与世界模型(WM)结合,用于精确预测自动驾驶中的未来场景动态。
- VLM生成可解释的行为指令来引导驾驶WM,从而实现情境感知型行动,并充分发挥决策制定与环境预测的互补优势。
-
- 林鸿毅、史文秀、黄赫业、庄丁毅、张松、刘洋、曲晓波、赵金华
- 发表日期:2026年3月12日
- 任务:生成
- 数据集:nuScenes
- 摘要:
- 提出RiskMV-DPO,一种基于物理约束、风险可控的多视角驾驶场景生成流水线,用于合成多样化的长尾高风险场景。
- 引入几何-外观对齐模块和区域感知直接偏好优化(RA-DPO)策略,以确保生成场景在时空上的一致性和几何保真度。
- 在nuScenes数据集上表现出最先进的性能,提升了3D检测mAP并降低了FID值,使世界模型从被动预测转向主动可控的场景合成。
-
- 陶明哲、刘瑞平、郑俊伟、陈宇凡、应可迪、M·萨基布·萨尔夫拉兹、杨凯伦、张嘉铭、赖纳·施蒂费尔哈根
- 发表日期:2026年3月11日
- 任务:VQA
- 摘要:
- 提出DriveXQA,一个面向自动驾驶的多模态数据集,包含102,505组问答对,涵盖三个层次(全局场景、以环境为中心、以车辆为中心)、四种视觉模态,以及多种传感器故障和天气条件。
- 引入MVX-LLM,一种具有双交叉注意力(DCA)投影器的高效架构,用于融合多种互补的视觉模态,在如雾天等复杂条件下表现出更好的性能。
-
- 商书瑶、詹冰、闫云飞、王宇琪、李颖妍、安亚松、王小满、刘杰睿、侯璐、范露、张兆祥、谭天牛
- 出版单位:中国科学院自动化研究所
- 发表日期:2026年3月11日
- 任务:规划、推理
- 数据集:NAVSIM、Bench2Drive
- 摘要:
- DynVLA是一种驾驶用视觉-语言-行动(VLA)模型,引入了一种称为“动力学思维链”(Dynamics CoT)的新范式,在生成动作之前先预测紧凑的世界动态,从而做出更明智且符合物理规律的决策。
- 该模型引入了动力学标记器,将未来演化压缩为少量的动力学标记,并将自我中心与环境中心的动力学解耦,以便在交互密集型场景中实现更精确的世界建模。
- DynVLA通过监督微调(SFT)和强化学习微调(RFT)训练,在生成动作前先生成动力学标记,既提高了决策质量,又保持了低延迟的推理效率,并在多个基准测试中超越了文本思维链和视觉思维链方法。
-
- 卓立峰、金克凡、刘哲、王鹤生
- 发表日期:2026年3月10日
- 任务:感知
- 数据集:nuScenes
- 摘要:
- 提出RESBev,一种具有韧性且即插即用的BEV感知方法,用于增强对传感器退化和对抗攻击的鲁棒性。
- 将感知鲁棒性重新定义为潜在语义预测问题,利用潜在世界模型学习BEV状态转移并预测干净的特征。
- 在Lift-Splat-Shoot流水线的语义特征层面运行,能够在不修改骨干网络的情况下,对各种干扰进行泛化恢复。
探究驾驶VLM的可靠性:从响应不一致到 grounded 时间推理
- 张春鹏、王晨宇、霍尔格·凯撒、阿兰·帕加尼
- 发表日期:2026年3月10日
- 任务:推理
- 摘要:
- 研究视觉-语言模型(VLM)作为驾驶助手的可靠性,重点关注其响应不一致和时间推理能力有限的问题。
- 引入FutureVQA,一个由人工标注的基准数据集,用于评估驾驶场景中的未来场景推理能力。
- 提出一种自监督调优方法,结合思维链推理来提高模型的一致性和时间推理能力,而无需时间标签。
StyleVLA:面向自动驾驶的驾驶风格感知型视觉语言行动模型
- 高源、华登元、马蒂亚·皮奇尼尼、芬恩·拉斯穆斯·舍费尔、科尔比尼安·莫勒、李琳、约翰内斯·贝茨
- 出版单位:慕尼黑工业大学
- 发表日期:2026年3月10日
- 任务:感知、规划
- 摘要:
- StyleVLA是一个基于物理约束的视觉语言行动(VLA)框架,能够生成多样化且符合物理规律的驾驶行为,并适应特定风格(如运动型、舒适型)。
- 引入一种混合损失函数,结合运动学一致性约束和连续回归头,以提高轨迹的可行性。
- 该模型基于Qwen3-VL-4B训练,使用包含超过1,200个场景和118,000个样本的大规模指令数据集,其综合驾驶评分优于专有及现有最先进模型。
-
- 大卫·费尔南德斯、佩德拉姆·莫哈杰尔安萨里、阿米尔·萨拉普尔、程龙、阿博法兹尔·拉齐、梅尔特·D·佩塞
- 发表日期:2026年3月9日
- 任务:感知
- 数据集:CARLA
- 摘要:
- 提出一个系统性的框架,用于对三种自动驾驶用VLM架构——Dolphins、OmniDrive(Omni-L)和LeapVAD——进行对抗性比较评估。
- 利用黑盒优化方法,在CARLA仿真环境中评估可物理实现的补丁攻击,并结合语义同质化技术,揭示了严重的漏洞和持续的多帧失效现象。
- 分析结果表明,不同架构存在不同的脆弱性模式,这说明当前的VLM设计在应对安全关键应用中的对抗威胁方面仍显不足。
SAMoE-VLA:面向自动驾驶的场景自适应专家混合视觉-语言-行动模型
- 游子涵、刘宏伟、党晨旭、王哲、安思宁、王奥奇、王燕
- 发表日期:2026年3月9日
- 任务:感知、规划
- 数据集:nuScenes
- 摘要:
- SAMoE-VLA是一种场景自适应的视觉-语言-行动框架,它基于结构化的场景表示(BEV特征)而非标记嵌入来选择专家,从而实现稳定的自动驾驶。
- 引入了一种条件跨模态因果注意力机制,将世界状态、语言意图和动作历史整合进统一的因果推理过程。
- 在nuScenes和LangAuto基准测试中取得了最先进的性能,以更少的参数数量超越了先前的基于VLA和基于世界模型的方法。
NaviDriveVLM:用于自动驾驶的高层推理与运动规划解耦框架
- 陶希蒙、帕尔迪斯·塔格维、季米特尔·菲列夫、雷扎·兰加里、高拉夫·潘迪
- 出版单位:德克萨斯农工大学
- 发表日期:2026年3月9日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- NaviDriveVLM是一个用于自动驾驶的解耦框架,它通过一个大规模导航器和一个轻量级可训练驱动器将高层推理与运动规划分离。
- 这种设计在保持强大推理能力的同时降低了训练成本,并为下游规划提供了明确且可解释的中间表示。
- 在nuScenes基准上的实验表明,NaviDriveVLM在端到端运动规划方面优于大型VLM基线。
-
- 李家卓、曹林江、刘琪、熊曦
- 发表日期:2026年3月7日
- 任务:感知
- 摘要:
- 提出了一种用于自动驾驶的考虑运动学的潜在世界模型框架,该框架基于递归状态空间模型(RSSM),融入了车辆运动学信息和几何感知监督。
- 结构化的潜在动力学提高了长 horizon 想象的保真度并稳定了策略优化,在样本效率和驾驶性能上均优于无模型和基于像素的世界模型基线。
-
- 程延春、王润东、杨旭磊、阿洛克·普拉卡什、丹妮拉·鲁斯、马塞洛·H·安格、李世杰
- 出版单位:麻省理工学院
- 发表日期:2026年3月7日
- 任务:感知
- 摘要:
- 提出了一个感知增强的多模态推理框架,该框架利用视觉参考标记(VRTs)为视觉-语言模型(VLMs)提供显式的以物体为中心的语义基础,从而实现视觉与文本的联合推理。
- 引入了一个多模态思维链(MM-CoT)数据集以及一种确定性的排序策略来监督无序的VRT集合,使得可以通过标准的监督微调进行有效训练。
- 在单目驾驶场景的空间推理SURDS基准测试上取得了显著提升,性能超越了包括强化学习方法在内的先前方法。
-
- 托马斯·莫宁格、谢绍远、陈启明、丁思浩
- 发表日期:2026年3月6日
- 任务:感知
- 摘要:
- BEVLM是一个连接空间一致、语义蒸馏的鸟瞰图(BEV)表示与大型语言模型(LLMs)的框架,用于自动驾驶。
- 该方法使LLMs在跨视图驾驶场景中的推理更加有效,通过使用BEV特征作为统一输入,准确率提升了46%。
- 将LLMs中的语义知识蒸馏到BEV表示中,显著提升了闭环端到端驾驶性能,在安全关键场景中提高了29%。
PRAM-R:具有LLM引导模态路由的感知-推理-行动-记忆框架,用于自适应自动驾驶
- 张毅、张贤、赵赛思、宋英蕾、吴成栋、内纳德·彼得罗维奇、阿洛伊斯·克诺尔
- 出版单位:慕尼黑工业大学
- 发表日期:2026年3月4日
- 任务:感知、规划
- 数据集:nuScenes
- 摘要:
- PRAM-R是一个具有LLM引导模态路由的统一感知-推理-行动-记忆框架,专为自适应自动驾驶设计,采用异步双环架构。
- 该框架使用LLM路由器根据环境背景和传感器诊断结果选择并加权不同的模态,同时配备层次化记忆模块以确保时间一致性。
- 评估显示,通过基于迟滞效应的稳定化措施,路由振荡减少了87.2%,并且在保持与全模态基线相当的轨迹精度的同时,模态数量减少了6.22%。
-
- 朱天泽、王一诺、邹文俊、张天一、王立坤、陶乐天、张飞鸿、吕瑶、李圣波
- 发表日期:2026年3月3日
- 任务:规划
- 数据集:DeepMind Control Suite
- 摘要:
- 提出DACER-F,一种利用流匹配进行在线强化学习的扩散演员-评论家方法,支持单步推理,实现自动驾驶中的实时决策。
- 引入一种结合朗之万动力学和Q函数梯度的方法,动态优化动作以逼近兼顾高Q值与探索性的目标分布。
- 在复杂驾驶仿真中表现出色,并在DeepMind Control Suite上展现出良好的可扩展性,以极低的推理延迟获得高分。
VLMFusionOcc3D:VLM辅助的多模态3D语义占用预测
- A. Enes Doruk、Hasan F. Ates
- 发表日期:2026年3月3日
- 任务:感知
- 数据集:nuScenes、SemanticKITTI
- 摘要:
- VLMFusionOcc3D是一种鲁棒的多模态密集3D语义占用预测框架,利用视觉-语言模型(VLM)将模糊的体素特征锚定到稳定的语义概念上。
- 提出实例驱动的VLM注意力机制(InstVLM),将高层语义先验注入3D体素;并引入天气感知自适应融合机制(WeathFusion),根据环境可靠性动态调整传感器权重。
- 采用深度感知几何对齐(DAGA)损失以保证结构一致性,并在现有最先进基线上显著提升性能,尤其在恶劣天气条件下表现优异。
AnchorDrive:基于锚点引导的扩散重生成的安全关键场景生成LLM情景展开
- 蒋竹林、李泽涛、王成、王子文、熊晨
- 发表日期:2026年3月3日
- 任务:生成
- 数据集:highD
- 摘要:
- AnchorDrive是一个两阶段的安全关键场景生成框架,结合大语言模型实现可控生成,并利用扩散模型进行逼真的轨迹重生成。
- 第一阶段使用具备计划评估能力的大语言模型驾驶员代理,在自然语言约束下生成语义可控的场景。
- 第二阶段从LLM生成的轨迹中提取锚点,引导扩散模型在保留用户意图的同时,生成更具现实感的轨迹。
LLM-MLFFN:基于大型语言模型的多级自动驾驶行为特征融合
- 李向宇、王天一、程曦、Rakesh Chowdary Machineni、郭兆淼、陈思凯、焦俊峰、Christian Claudel
- 发表日期:2026年3月3日
- 任务:感知
- 数据集:Waymo
- 摘要:
- LLM-MLFFN是一种新颖的LLM增强型多级特征融合网络,用于自动驾驶行为分类,整合了大规模预训练模型的先验信息。
- 该框架包括多级特征提取模块、使用LLM的语义描述模块,以及带有加权注意力的双通道特征融合网络。
- 在Waymo数据集上的评估显示其性能优越,分类准确率超过94%,证明了结构化特征建模与语义抽象相结合的价值。
LaST-VLA:在自动驾驶中基于视觉-语言-行动的潜在时空思维
- 罗悦辰、李芳、徐绍青、季阳、张泽涵、王兵、沈元南、崔建伟、陈龙、陈广、叶航军、杨志新、温福熙
- 发表日期:2026年3月2日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- LaST-VLA是一个框架,将推理从离散符号处理转向物理基础的潜在时空思维链,以解决视觉-语言-行动模型中的语义-感知解耦问题。
- 实现了一种双特征对齐机制,将3D基础模型中的几何约束和世界模型中的动态预见能力提炼到潜在空间中。
- 采用渐进式SFT训练策略和GRPO强化学习,在NAVSIM基准测试中创下新纪录,并在时空推理方面表现卓越。
-
- 王欣洋、刘倩、丁文杰、杨昭、李伟、刘畅、李柏霖、詹坤、郎贤鹏、陈伟
- 发表日期:2026年3月2日
- 任务:端到端、生成
- 摘要:
- 提出LinkVLA,一种用于自动驾驶的新颖视觉-语言-行动(VLA)架构,将语言和行动标记统一到共享的离散代码本中,以强制跨模态一致性。
- 提议一种辅助性的行动理解目标,通过训练模型根据轨迹生成描述性文字,从而建立深层语义联系,促进语言-行动的双向映射。
- 用两步粗细结合(C2F)方法替代自回归生成,使推理时间缩短86%,同时提高指令遵循精度及闭环基准下的驾驶性能。
-
- 罗悦辰、陈启茂、李芳、徐绍青、刘嘉鑫、宋梓 Ying、杨志新、温福熙
- 发表日期:2026年3月1日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- 提出ELF-VLA框架,通过结构化的诊断反馈增强强化学习,以解决自动驾驶中视觉-语言-行动模型的性能瓶颈问题。
- 生成详细且可解释的失败报告,识别具体的失败模式,从而实现针对性的反馈引导优化和更有效的训练。
- 在NAVSIM基准测试中,于PDMS、EPDMS评分以及高层规划准确性方面均达到当前最优水平。
-
- 王志业、蒋彦博、周睿、张博、张芳、徐振华、张雅琴、王建强
- 发表日期:2026年3月1日
- 任务:端到端
- 摘要:
- 介绍DriveCode,一种基于LLM的自动驾驶新型数值编码方法,它将数字表示为专用嵌入,而非离散文本标记,从而提升数值推理能力和精度。
- 使用数字投影器将数字映射到语言模型的隐藏空间,实现与视觉和文本特征在统一多模态序列中的无缝集成。
- 在OmniDrive、DriveGPT4和DriveGPT4-V2数据集上,展示了其在轨迹预测和控制信号生成方面的优越性能。
Wild-Drive:通过鲁棒多模态路由和高效大型语言模型实现越野场景描述与路径规划
- 王子航、李旭、王本武、朱文凯、陈谢元立、孔东、吕凯琳、杜一楠、彭一鸣、车浩洋
- 发表日期:2026年2月28日
- 代码:Wild-Drive
- 任务:规划
- 数据集:OR-C2P基准测试集
- 摘要:
- 提出Wild-Drive,一个高效的越野场景描述与路径规划框架,解决了传感器在雨、雾、黑暗等恶劣条件下易受损的问题。
- 引入MoRo-Former,一种任务条件化的多模态路由桥梁,可在传感条件恶化时自适应地聚合可靠信息。
- 将高效LLM与规划标记及GRU解码器结合,生成结构化描述并预测未来轨迹,并发布了OR-C2P基准测试集用于评估。
-
- 孙江鑫、薛峰、龙腾、刘畅、胡建方、郑伟士、尼库·塞贝
- 出版单位:澳门大学、中国科学院大学、特伦托大学
- 发表日期:2026年2月26日
- 任务:端到端
- 摘要:
- 提出RaWMPC,一个统一的端到端自动驾驶框架,通过稳健控制解决泛化问题,无需依赖专家示范。
- 利用世界模型预测候选动作的后果,并通过明确的风险评估选择低风险动作,同时辅以风险感知交互策略进一步增强效果。
- 引入自我评估蒸馏方法,将世界模型中的避险能力提炼到生成式动作建议网络中。
-
- 张凌俊、袁宇健、吴昌杰、常新源、蔡欣、曾爽、史林哲、王思瑾、张航、许牧
- 发表日期:2026年2月25日
- 代码:MindDriver
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 提出MindDriver,一种用于自动驾驶的渐进式多模态推理框架,使VLM能够通过语义理解、想象和轨迹规划模仿人类的渐进式思维。
- 开发了一条反馈引导的自动数据标注流水线,用于生成对齐的多模态推理训练数据,并提出渐进式强化微调方法进行优化。
VGGDrive:通过跨视角几何对齐赋能视觉-语言模型用于自动驾驶
- 王杰、李广、黄志坚、党晨旭、叶杭军、韩亚红、陈龙
- 出版单位:(根据作者及上下文推断)
- 发表日期:2026年2月24日
- 任务:感知、规划
- 摘要:
- 提出VGGDrive,一种新颖架构,通过连接来自冻结3D模型的3D几何特征,赋予视觉-语言模型(VLM)用于自动驾驶的跨视角几何对齐能力。
- 引入即插即用的跨视角3D几何增强器(CVGE),将基础VLM解耦,并通过分层自适应机制注入3D特征。
- 在包括跨视角风险感知、运动预测和轨迹规划在内的五个自动驾驶基准测试中,均表现出性能提升。
通过掩码视觉-语言-行动扩散实现高效且可解释的端到端自动驾驶
- 张嘉茹、马纳夫·加格瓦尼、崔灿、彭俊通、张汝琪、王子然
- 发表日期:2026年2月24日
- 任务:感知、规划
- 数据集:nuScenes
- 摘要:
- 提出MVLAD-AD,一种用于自动驾驶的掩码视觉-语言-行动扩散框架,兼顾高效规划与语义可解释性。
- 引入离散动作标记化策略,从真实驾驶分布中创建紧凑的运动学可行航点码本。
- 采用几何感知嵌入学习和动作优先解码策略,提高规划精度,并提供高保真、可解释的推理过程。
-
- 史浩军、叶苏宇、凯瑟琳·M·格雷里奥、沈建志、尹一凡、丹尼尔·哈沙比、黄健明、舒天敏
- 发表日期:2026年2月22日
- 任务:规划
- 摘要:
- CaPE(代码即路径编辑器)是一种安全且可解释的多模态路径规划方法,专为多智能体协作设计。该方法可根据环境和语言交流生成并更新路径计划。
- 该方法利用视觉-语言模型(VLM)合成由基于模型的规划器验证的路径编辑程序,从而将通信与安全、可解释的路径计划更新相结合。
- 在多种模拟和真实场景中进行了评估,包括多机器人协作、人机协作以及自动驾驶、家庭服务和联合搬运等任务,结果表明其能够显著提升规划与沟通的一致性。
-
- 林玲、白杨、苏恒、朱聪聪、王耀兴、周洋、傅华柱、陈景润
- 发表日期:2026年2月20日
- 任务:评估
- 数据集:OODBench
- 摘要:
- 提出OODBench,一种以自动化为主的基准测试构建方法,用于评估视觉-语言模型(VLM)在分布外(OOD)数据上的表现,包含4万个实例级别的OOD实例-类别配对。
- 引入了一种可靠的自动化评估指标,通过由基础到高级的提示问题序列,来评估OOD数据对不同难度问题的影响。
- 总结了大量发现和见解,以促进未来关于OOD数据获取和评估的研究;结果显示,当前的VLM在OODBench上的性能有明显下降。
流匹配条件下的连续异常检测:基于流形感知谱空间的自动驾驶应用
- 安东尼奥·吉列恩-佩雷斯
- 发表日期:2026年2月19日
- 任务:感知
- 数据集:Waymo开放运动数据集
- 摘要:
- 提出Deep-Flow框架,这是一种无监督的安全关键异常检测系统,采用最优传输条件流匹配(OT-CFM)来建模专家驾驶的概率密度。
- 通过主成分分析引入低秩谱流形,以确保运动学平滑性和稳定的对数似然估计;同时使用带有目标条件的早期融合Transformer处理多模态路口情况。
- 识别出运动学危险与语义不合规之间的可预测性差距,揭示了诸如车道违规等被忽视的分布外行为,从而支持基于数据的安全验证。
基于自监督JEPA的世界模型:用于LiDAR占用率补全与预测
- 朱浩然、安娜·霍罗马斯卡
- 出版单位:纽约大学
- 发表日期:2026年2月13日
- 任务:预测
- 数据集:Waymo开放数据集
- 摘要:
- 提出AD-LiST-JEPA,一种用于自动驾驶的自监督世界模型,它利用联合嵌入预测架构(JEPA)从LiDAR数据中预测未来的时空演化。
- 通过下游的基于LiDAR的占用率补全与预测(OCF)任务来评估所学表示,从而同时评估感知与预测能力。
- 结果表明,在经过JEPA世界模型学习后,使用预训练编码器进行OCF任务的表现有所提升,这得益于对大量未标注数据的有效利用。
Talk2DM:借助大型语言模型为车路云一体化动态地图实现自然语言查询与常识推理
- 卢涛、罗金轩、渡边洋介、周正书、陆宇桓、应申、张攀、赵飞、高田博明
- 发表日期:2026年2月12日
- 任务:推理
- 数据集:NAVSIM
- 摘要:
- Talk2DM是一个即插即用的模块,通过支持自然语言查询和常识推理的能力扩展了车路云动态地图(VRC-DM)系统。
- 它基于一种新颖的提示链机制(CoP),将人类定义的规则与大型语言模型(LLM)的常识知识相结合。
- 实验表明,Talk2DM能够在不同LLM之间无缝切换,同时保持较高的查询准确率,并以2至5秒的响应时间实现超过93%的准确率,展现出实际应用潜力。
SToRM:面向高效端到端自动驾驶的多模态LLM监督令牌缩减
- 金瑞贤、朴镇福、具度延、朴浩根、春一勇
- 发表日期:2026年2月12日
- 任务:端到端
- 摘要:
- 提出SToRM,这是首个用于多模态LLM的监督令牌缩减框架,旨在实现高效的端到端自动驾驶,同时保持与使用全部视觉令牌相当的性能。
- 该框架采用轻量级重要性预测器、基于全令牌LLM伪监督的监督训练方法,以及锚点上下文融合模块来减少令牌冗余。
- 实验表明,在相同的令牌预算下,SToRM的表现优于当前最先进的E2E驾驶MLLM,能够在降低高达30倍计算成本的同时维持性能。
从转向到踩踏:自动驾驶VLM能否泛化应用于骑行者辅助的空间感知与规划?
- 克里希纳·坎特·纳卡、维达斯里·纳卡
- 发表日期:2026年2月11日
- 任务:VQA、感知、规划
- 摘要:
- 引入CyclingVQA诊断基准,用于评估视觉-语言模型(VLM)在骑行者为中心的感知、时空理解以及交通规则到车道推理方面的能力。
- 对31多种VLM进行了评估,发现当前模型虽表现出令人鼓舞的能力,但在骑行者特定推理方面仍存在明显差距,尤其是专为驾驶设计的模型在此领域往往不如强大的通用型VLM表现优异。
- 提供系统的错误分析,识别出反复出现的失效模式,以指导更有效的骑行者辅助智能系统的开发。
HiST-VLA:用于端到端自动驾驶的分层时空视觉-语言-行动模型
- 王一儒、顾子冲、高宇、蒋安青、孙志刚、王硕、衡宇文、孙浩
- 发表日期:2026年2月11日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出HiST-VLA,一种用于可靠轨迹生成的分层时空VLA模型,以解决数值推理不精确和三维空间感知薄弱等局限性。
- 集成几何感知、状态历史提示和动态令牌稀疏化技术,以增强推理能力和计算效率。
- 采用基于分层Transformer的规划器,并结合动态潜在正则化来优化VLA航点,从而在NAVSIM v2基准测试中达到最先进水平。
-
- 阿南雅·特里维迪、李安健、穆罕默德·埃尔努尔、优素福·乌穆特·奇夫奇、阿维纳什·辛格、乔文·德萨、裴尚载、大卫·伊瑟勒、塔斯金·帕迪尔、法伊赞·M·塔里克
- 出版单位:东北大学
- 发表日期:2026年2月10日
- 项目页面:自动驾驶流匹配
- 任务:规划
- 数据集:Waymo开放运动数据集
- 摘要:
- 提出一种条件流匹配框架,用于实时联合预测周围交通参与者及本车轨迹规划,利用轻量级方差估计器在线自适应选择推理步长。
- 引入轨迹后处理步骤,将其作为凸二次规划问题来提升乘坐舒适性,且计算开销几乎可以忽略。
- 实现20赫兹的更新频率,支持在线部署,并在变道和无保护左转等操作中相比基线模型展现出更好的平滑性和约束遵守能力。
-
- 高天、陈思琳、凯瑟琳·格洛索普、蒂莫西·高、孙建凯、凯尔·斯塔霍维奇、吴雪莉、奥耶尔·梅斯、多尔萨·萨迪格、谢尔盖·列维纳、切尔西·芬恩
- 发表日期:2026年2月9日
- 项目页面:SteerVLA
- 任务:规划
- 摘要:
- SteerVLA是一种利用视觉-语言模型(VLM)的推理能力,生成细粒度的语言指令来引导视觉-语言-行动(VLA)驾驶策略的方法。
- 在高层VLM和底层VLA策略之间引入丰富的语言接口,将推理结果映射到控制输出上,并借助VLM为驾驶数据添加详细的语言标注。
- 在一项具有挑战性的闭环基准测试中进行评估,其总体驾驶评分比当前最先进方法高出4.77分,在长尾子集上的表现更是领先8.04分。
视觉与语言:用于驾驶场景安全评估和自动驾驶车辆规划的新颖表示与人工智能
- 罗斯·格里尔、迈特拉伊·凯斯卡尔、安赫尔·马丁内斯-桑切斯、帕尔提布·罗伊、沙尚克·施里拉姆、莫汉·特里维迪
- 发表日期:2026年2月7日
- 任务:规划
- 数据集:Waymo开放数据集、nuScenes
- 摘要:
- 提出了一种基于CLIP图像-文本相似度的轻量级、类别无关的危险筛查方法,用于低延迟语义危险检测,无需显式目标检测。
- 探讨将场景级视觉-语言嵌入整合到基于Transformer的轨迹规划器中,发现简单的条件化并不能提高精度,这凸显了任务导向型表示提取的重要性。
- 研究使用自然语言作为运动规划的显式行为约束,表明基于视觉场景的乘客式指令能够抑制严重的规划失败,并在模糊场景中提升安全性。
-
- 鲁图拉吉·雷迪、赫里沙夫·巴库尔·巴鲁阿、俊勇·卢、清氏·阮、加内什·克里希纳萨米
- 发表日期:2026年2月7日
- 任务:感知
- 摘要:
- 提出CLARITY框架,用于RGB-热红外语义分割,该框架利用视觉-语言模型(VLM)先验知识,根据检测到的场景条件动态调整融合策略。
- 引入机制以保留常被降噪方法忽略的有效暗目标语义,并采用层次化解码器来确保结构一致性,从而获得更清晰的目标边界。
- 在MFNet数据集中达到最先进的性能,mIoU为62.3%,mAcc为77.5%。
DriveWorld-VLA:面向自动驾驶的统一潜在空间世界建模与视觉-语言-行动技术
- 贾飞阳、刘林、宋紫莹、贾彩燕、叶航军、郝晓帅、陈龙
- 发表日期:2026年2月6日
- 代码:DriveWorld-VLA
- 任务:规划
- 数据集:NAVSIM、nuScenes
- 摘要:
- 一种新颖的框架,通过在表示层面紧密集成视觉-语言-行动(VLA)和世界模型,将世界建模与规划统一于潜在空间中。
- 使VLA规划器能够直接受益于对场景整体演化的建模,并评估候选动作对未来场景演化的影响,从而减少对密集标注监督的依赖。
- 在NAVSIM和nuScenes基准测试中均取得最先进的性能,支持在特征层面进行可控的、动作条件化的想象。
-
- 奇建磊、吴宇振、侯家轩、张晓东、范明、孙苏慧、戴伟俊、李博、孙建国、孙军
- 出版商:百度
- 发表日期:2026年2月5日
- 任务:生成
- 数据集:CARLA
- 摘要:
- ROMAN是一种用于ADS测试的新型场景生成方法,它结合多头注意力网络与交通法规权重机制,以生成高风险违规场景。
- 该方法使用基于LLM的风险权重模块,根据严重性和发生频率评估违规行为,并模拟车辆与交通信号之间的交互作用。
- 在CARLA中的百度Apollo ADS上进行评估后,ROMAN在违规数量和多样性方面均超越了现有工具,能够针对输入交通法规的每一条款生成相应场景。
AppleVLM:基于先进感知与规划增强型视觉-语言模型的端到端自动驾驶
- 韩宇轩、吴坤元、邵千怡、肖仁翔、王子璐、蒋灿森、萧毅、胡亮、楼云江
- 发表日期:2026年2月4日
- 任务:端到端
- 数据集:CARLA
- 摘要:
- AppleVLM是一种先进的感知与规划增强型VLM模型,旨在实现稳健的端到端驾驶,解决车道感知不佳和语言偏差等问题。
- 引入一种基于可变形Transformer的新型视觉编码器,用于多视角、多时间步的融合;同时设计专门的规划模态编码鸟瞰信息,以缓解导航偏差。
- 其VLM解码器经过分层“思维链”微调,能够整合视觉、语言和规划特征,在CARLA中达到最先进的性能,并成功部署于AGV的实际应用中。
基于视觉-语言-行动模型的自动驾驶中场景响应型人机协作运动规划的自然语言指令
- 安赫尔·马丁内斯-桑切斯、帕尔提布·罗伊、罗斯·格里尔
- 出版商:Mi3-Lab
- 发表日期:2026年2月4日
- 代码:doScenes-VLM-Planning
- 任务:规划
- 数据集:doScenes、nuScenes
- 摘要:
- 首次推出doScenes数据集,将自由形式的乘客指令与nuScenes的真实运动轨迹标注关联起来,用于指令条件化的规划。
- 对OpenEMMA端到端驾驶框架进行改造,以整合乘客风格的语言提示,从而在生成轨迹之前实现语言条件化。
- 实验证明,指令条件化能够显著提升规划的鲁棒性,防止极端失败的发生,并使轨迹更好地符合措辞得当的指令。
InstaDrive:面向真实且一致视频生成的实例感知驾驶世界模型
- 作者:杨卓然、郭熙、丁晨静、王驰宇、吴伟、张延勇
- 发表日期:2026年2月3日
- 项目主页:InstaDrive
- 任务:生成
- 数据集:nuScenes
- 摘要:
- InstaDrive是一种新颖的驾驶视频生成框架,旨在解决世界模型中实例级别的时序一致性和空间几何保真度问题。
- 引入了实例流引导器以传播实例特征实现时序一致性,并设计了空间几何对齐器来精确建模物体位置及遮挡关系。
- 该方法在视频生成质量上达到最新水平,并能有效提升下游自动驾驶任务性能;同时结合CARLA中的程序化仿真环境,可用于评估安全关键场景。
ConsisDrive:基于实例掩码的保身份驾驶世界模型用于视频生成
- 作者:杨卓然、张延勇
- 发表日期:2026年2月3日
- 项目主页:ConsisDrive
- 任务:生成
- 数据集:nuScenes
- 摘要:
- 提出ConsisDrive,一种保身份的驾驶世界模型,通过在实例层面强制保持时序一致性来防止生成视频中出现身份漂移现象。
- 包含两个核心组件:实例掩码注意力机制用于跨帧保持目标身份,以及实例掩码损失函数用以自适应强调前景区域。
- 在驾驶视频生成方面达到当前最优水平,并在nuScenes数据集上的下游自动驾驶任务中表现出显著改进。
UniDriveDreamer:用于自动驾驶的单阶段多模态世界模型
- 作者:赵国胜、王耀增、王晓峰、朱铮、于廷东、黄冠、宰永臣、焦继、薛长亮、王小乐、杨振、朱福堂、王兴刚
- 发表日期:2026年2月2日
- 任务:预测、生成
- 摘要:
- UniDriveDreamer是一种单阶段统一的多模态世界模型,可直接生成未来多模态观测结果(多摄像头视频和LiDAR序列),无需中间表示或级联模块。
- 引入了LiDAR专用VAE和视频VAE,并提出统一潜在锚定(ULA)方法,以对齐两者的潜在分布,从而实现跨模态兼容性和训练稳定性。
- 采用扩散Transformer联合建模对齐融合特征的几何对应关系和时间演化过程,并以各模态的结构化场景布局信息作为条件。
-
- 作者:刘帅、任思恒、朱晓瑶、梁泉民、李泽峰、李强、胡欣、黄凯
- 发表日期:2026年2月2日
- 代码:UniDWM
- 任务:感知、预测、规划、生成
- 摘要:
- UniDWM是一种通过多面表征学习推进自动驾驶的统一驾驶世界模型,能够构建兼具结构与动态感知的潜在世界表示。
- 该模型采用联合重建路径和协作式生成框架,并结合条件扩散Transformer来预测未来的世界演变。
- 研究表明,该框架是VAE的一种变体,为多面表征学习提供了理论指导,并且在轨迹规划、4D重建及生成等方面具有实际应用价值。
HERMES:端到端风险感知多模态具身系统——结合视觉-语言模型应对长尾场景下的自动驾驶
- 作者:唐伟哲、游俊伟、刘佳希、王兆义、甘锐、黄子林、魏峰、冉斌
- 出版单位:威斯康星大学麦迪逊分校、加州大学伯克利分校、清华大学
- 发表日期:2026年2月1日
- 任务:端到端
- 摘要:
- HERMES是一个整体性的风险感知端到端多模态驾驶框架,旨在将明确的长尾风险线索注入轨迹规划中,以实现在混合交通场景下的安全运行。
- 利用基础模型辅助的标注流程生成结构化的长尾场景上下文和长尾规划上下文,捕捉以危险为中心的线索,同时考虑驾驶意图和安全偏好。
- 引入三模态驾驶模块,融合多视角感知、历史运动线索和语义引导,从而在长尾条件下实现风险敏感且精准的轨迹规划。
Drive-JEPA:视频JEPA结合多模态轨迹蒸馏用于端到端驾驶
- 作者:王林涵、杨子冲、白晨、张国祥、刘晓彤、郑晓音、龙小小、卢昌田、陆成
- 发表日期:2026年1月29日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出Drive-JEPA框架,将视频联合嵌入预测架构(V-JEPA)与多模态轨迹蒸馏相结合,用于端到端自动驾驶。
- 对V-JEPA进行适配,使其能够在驾驶视频上预训练ViT编码器,从而获得与规划任务相契合的预测性表征;同时引入以提案为中心的规划器,从多种模拟器和人类驾驶轨迹中提炼知识。
- 在NAVSIM数据集上取得了当前最优性能,其中V-JEPA表征优于现有方法,而完整框架则树立了新的基准。
-
- 李鹤、陈兆伟、高睿、李国梁、郝奇、王帅、徐成中
- 发表日期:2026年1月29日
- 任务:规划
- 摘要:
- 提出LAP,一种由大语言模型驱动的自适应规划方法,可在高速和精确驾驶模式之间切换。
- 通过利用大语言模型进行场景理解,并将其推理结果融入模式配置与运动规划的联合优化中实现这一目标,采用树搜索MPC和交替最小化算法求解。
- 在ROS中的实现表明,在仿真环境中,其驾驶时间和成功率均优于基准方法。
-
- 连伟通、唐泽聪、李浩然、高天健、王一飞、王子旭、孟凌翼、茹腾驹、崔哲俊、朱义晨、曹航硕、康琪、陈天行、秦宇森、王凯旋、张宇
- 发表日期:2026年1月29日
- 任务:规划
- 摘要:
- Drive-KD框架将自动驾驶分解为“感知-推理-规划”三元结构,并通过知识蒸馏传递这些能力。
- 引入层间注意力作为蒸馏信号,构建针对不同能力的单教师模型及采用非对称梯度投影机制的多教师框架,以缓解梯度冲突。
- 蒸馏后的InternVL3-1B模型在DriveBench上的综合性能优于预训练的78B模型,在规划任务上甚至超越GPT-5.1,同时显著降低了GPU内存占用并提升了吞吐量。
ScenePilot-Bench:用于评估自动驾驶中视觉-语言模型的大规模数据集与基准测试
- 王宇锦、郑宇彤、范文贤、王天毅、褚洪庆、田大鑫、高炳钊、王建强、陈宏
- 发表日期:2026年1月27日
- 任务:评估
- 摘要:
- 介绍ScenePilot-Bench,一个基于多样化ScenePilot-4K数据集(包含3,847小时驾驶视频及多粒度标注)构建的大规模第一人称驾驶基准测试。
- 具有四维评估体系,分别从场景理解、空间感知、运动规划及GPT-Score四个方面评估VLM的能力,并引入安全相关指标及跨区域泛化设置。
- 提供代表性VLM的实证分析,以明确其性能边界并识别在安全关键场景下面向驾驶的推理能力差距。
AutoDriDM:面向自动驾驶中视觉-语言模型决策能力的可解释性基准测试
- 唐泽聪、王子旭、王一飞、连伟通、高天健、李浩然、茹腾驹、孟凌翼、崔哲俊、朱义晨、康琪、王凯旋、张宇
- 发表日期:2026年1月21日
- 任务:评估
- 数据集:AutoDriDM
- 摘要:
- AutoDriDM是一个以决策为核心的渐进式基准测试,用于评估自动驾驶中的视觉-语言模型(VLM),包含对象、场景和决策三个维度的6,650道题目。
- 该基准测试评估主流VLM,以划定感知到决策的能力边界,揭示了感知与决策性能之间的薄弱关联。
- 包含对模型推理过程的可解释性分析,识别关键失效模式,并引入分析模型以实现大规模自动标注。
-
- 陈启茂、李芳、许绍青、赖志毅、谢子迅、罗岳辰、江圣寅、李汉冰、陈龙、王兵、张毅、杨志新
- 发表日期:2026年1月19日
- 任务:规划
- 摘要:
- 提出VILTA(VLM闭环轨迹对抗系统),这是一种新颖的框架,可将视觉语言模型直接集成到自动驾驶智能体的闭环训练中。
- VLM能够主动理解动态环境,并通过直接编辑周围其他智能体的未来轨迹来生成具有挑战性的长尾场景。
- 该方法利用VLM的泛化能力,创建多样化的潜在危急场景课程,从而显著提升最终驾驶策略的安全性和鲁棒性。
-
- 拉吉夫·亚萨拉、迪普蒂·赫格德、韩世忠、程信沛、史云霄、梅萨姆·萨德吉戈加里、什韦塔·马哈詹、阿普拉蒂姆·巴塔查里亚、刘立天、里希克·加雷帕利、托马斯·斯万特松、法提赫·波里克利、蔡宏
- 出版商:高通AI研究院
- 发表日期:2026年1月16日
- 任务:规划
- 数据集:Bench2Drive
- 摘要:
- 提出生成式场景回放(GeRo),这是一个即插即用的框架,适用于视觉-语言-行动(VLA)模型,可通过自回归回放联合执行规划与基于语言的未来交通场景生成。
- 使用回放一致性损失来稳定预测并保持文本与动作的一致性,从而实现时间一致且基于语言的长期推理和多智能体规划。
- 将强化学习与生成式回放相结合,在Bench2Drive上实现了最先进的闭环和开环性能,并展现出强大的零样本鲁棒性。
-
- 阿迈德·拉希米、瓦伦丁·热拉尔、埃洛伊·扎布洛基、马蒂厄·科尔德、亚历山大·阿拉伊
- 出版商:EPFL VITA
- 发表日期:2026年1月14日
- 项目页面:MAD-World-Model
- 任务:生成
- 摘要:
- 提出一种高效的适配框架,通过将运动学习与外观合成解耦,将通用视频扩散模型转化为可控的驾驶世界模型。
- 采用两阶段推理-渲染范式:首先通过骨架化智能体视频推断动态,再渲染逼真的RGB外观,从而以不到先前计算资源6%的成本达到最先进水平。
-
- 蔡宇良、叶东强子、陈子天、吴崇若
- 发布日期:2026年1月11日
- 任务:VQA
- 摘要:
- 提出SRC-Pipeline,一种用于自动驾驶VQA的高效VLM框架,它将早期帧的token压缩为少量高级token,同时保留近期帧的完整token。
- 在保持相近性能的同时,计算量减少了66%,从而能够在安全关键的驾驶环境中更有效地实现实时运行。
-
- 马文·泽格特、科尔比尼安·莫勒、约翰内斯·贝茨
- 出版商:慕尼黑工业大学
- 发布日期:2026年1月9日
- 任务:规划
- 摘要:
- 提出一种用于自动驾驶系统(ADS)中对话交互的LLM驱动框架,将基于LLM的交互层与Autoware软件栈集成。
- 引入三步方法:对交互类别进行分类,开发面向应用的领域特定语言(DSL)用于指令翻译,以及建立一个保障安全的验证层。
- 采用两阶段LLM架构以确保高度透明并提供执行反馈,评估证实其时间效率和翻译鲁棒性。
-
- 李京宇、吴俊杰、胡东楠、黄翔凯、孙斌、郝志辉、郎贤鹏、朱夏田、张莉
- 发布日期:2026年1月9日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- 提出SGDrive,一种新颖的框架,它围绕驾驶特定的场景-智能体-目标层次结构构建视觉-语言模型(VLM)的表征学习,以模拟人类驾驶认知。
- 通过提供结构化的时空表征来解决通用VLM的局限性,实现安全的轨迹规划,并将多级信息整合为紧凑格式。
- 在NAVSIM基准测试中,作为纯摄像头方法达到了最先进水平,验证了层次化知识结构在适应VLM用于自动驾驶方面的有效性。
ThinkDrive:思维链引导的渐进式强化学习微调用于自动驾驶
- 赵昌、杨哲明、胡云清、郭琪、王子健、李鹏程、季文
- 发布日期:2026年1月8日
- 任务:规划
- 摘要:
- ThinkDrive是一种由思维链(CoT)引导的渐进式强化学习微调框架,用于自动驾驶,它将显式推理与难度感知的自适应策略优化相结合。
- 该方法采用两阶段训练策略:首先使用CoT解释进行监督微调(SFT),然后应用渐进式RL,并结合难度感知的自适应策略优化器。
- 在公开数据集上的评估表明,ThinkDrive的表现优于强大的RL基线,而使用该方法训练的2B参数模型在考试指标上超越了更大的GPT-4o。
UniDrive-WM:用于自动驾驶的统一理解、规划和生成世界模型
- 熊哲晓、叶欣、布尔汉·亚曼、程胜、陆一仁、罗静如、内森·雅各布斯、任刘
- 出版商:圣路易斯华盛顿大学、博世研究院
- 发布日期:2026年1月7日
- 项目页面:UniDrive-WM
- 任务:规划、生成
- 数据集:Bench2Drive
- 摘要:
- UniDrive-WM是一种基于VLM的统一世界模型,在单个架构中联合完成驾驶场景理解、轨迹规划以及基于轨迹条件的未来图像生成。
- 模型预测的轨迹会条件化一个基于VLM的图像生成器,以生成合理的未来帧,从而提供监督信号,增强理解并迭代优化轨迹生成。
- 在Bench2Drive上的实验显示,相比先前方法,L2轨迹误差降低了5.9%,碰撞率降低了9.2%,证明了将推理、规划和生成建模相结合的优势。
-
- 张良栋、聂一鸣、李浩洋、孔凡杰、张宝宝、黄顺鑫、傅凯、闵晨、肖亮
- 发表日期:2026年1月7日
- 任务:规划
- 数据集:RELLIS-3D
- 摘要:
- 提出OFF-EMMA,这是一种端到端的多模态框架,用于越野自动驾驶,旨在解决VLA模型中空间感知不足和推理不稳定的问题。
- 引入基于语义分割掩码的视觉提示模块,以增强空间理解能力;同时采用具有自一致性(COT-SC)的思维链推理策略,提升规划的鲁棒性。
FROST-Drive:基于冻结视觉编码器的可扩展且高效的端到端驾驶系统
- 董泽宇、朱一民、吴宇、孙宇
- 发表日期:2026年1月6日
- 任务:端到端
- 数据集:Waymo开放端到端数据集
- 摘要:
- FROST-Drive是一种新颖的端到端(E2E)架构,通过保持预训练视觉-语言模型(VLM)的视觉编码器冻结状态,从而保留其泛化能力。
- 该模型将冻结的编码器与基于Transformer的适配器以及基于GRU的航点生成解码器相结合,并采用针对评分者反馈分数(RFS)的自定义损失函数进行优化。
- 在Waymo开放端到端数据集上表现出色,表明利用冻结的通用VLM编码器比完全微调更能实现稳健的驾驶性能。
DrivingGen:面向自动驾驶的生成式视频世界模型综合基准测试
- 周阳、邵浩、王乐天、宗卓凡、李洪生、史蒂文·L·瓦斯兰德
- 出版单位:多伦多大学、上海人工智能实验室、香港中文大学
- 发表日期:2026年1月4日
- 任务:评估
- 数据集:DrivingGen
- 摘要:
- DrivingGen是首个针对生成式驾驶世界模型的综合性基准测试,结合了多样化的评估数据集和一套新的评价指标。
- 该基准从视觉逼真度、轨迹合理性、时间连贯性及可控性等多个维度进行评估,以推动可靠且可部署的驾驶世界模型的发展。
- 对14种最先进模型的评估揭示了通用模型与驾驶专用模型之间的权衡,为可扩展的仿真与规划提供了统一的框架。
-
- 梁瑞明、郑怡楠、郑可欣、谭天一、李建雄、毛立元、王志浩、陈光、叶杭军、刘静静、王金桥、詹宪远
- 发表日期:2025年12月31日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出DIPOLE(二分扩散策略改进),这是一种新颖的强化学习算法,通过将最优策略分解为一对分别用于奖励最大化和最小化的二分策略,实现稳定且可控的扩散策略优化。
- 在推理过程中,可通过线性组合所学二分策略的得分来灵活控制贪婪程度。
- 在离线及离线转在线强化学习场景(ExORL、OGBench)中均展现出有效性,并成功应用于在NAVSIM基准上训练大型视觉-语言-行动模型以实现端到端自动驾驶。
-
- 程谦、周伟涛、景成、邓南山、文俊泽、刘兆阳、江坤、杨迪安
- 发表日期:2025年12月31日
- 任务:感知
- 数据集:CARLA
- 摘要:
- LSRE是一种潜在语义规则编码框架,能够将稀疏采样的VLM判断转化为循环世界模型潜在空间内的决策边界,从而实现实时语义风险评估。
- 无需每帧都调用VLM即可实现10 Hz的实时语义风险检测,准确率与大型VLM基线相当,且能更早地预测危险、延迟更低。
- 该方法对罕见但语义相似的测试案例也表现出良好的泛化能力,表明语言引导的潜在分类机制是进行语义安全监控的有效手段。
反事实VLA:具有自反思能力和适应性推理的视觉-语言-行动模型
- 彭正浩“马克”、丁文豪、游雨蓉、陈宇晓、罗文杰、田托马斯、曹宇龙、阿普尔瓦·夏尔马、徐丹菲、鲍里斯·伊万诺维奇、李博毅、周伯雷、王燕、马可·帕沃内
- 发表日期:2025年12月30日
- 任务:规划
- 摘要:
- 提出反事实VLA(CF-VLA),这是一种自反思的VLA框架,可通过反事实推理在执行前对计划行动进行思考和修正。
- 提议采用回放-过滤-标注流程来挖掘高价值场景,并标注反事实推理轨迹,以实现高效训练。
- 实验表明,该方法在轨迹准确性和安全指标方面均有显著提升(分别高达17.6%和20.5%),且自适应推理仅在复杂场景中启用。
-
- 魏伟杰、罗志鹏、冯玲、艾琳·利昂
- 发表日期:2025年12月30日
- 任务:感知
- 摘要:
- LVLDrive(激光雷达-视觉-语言)是一种新框架,旨在通过引入激光雷达点云作为额外的输入模态,将现有的视觉-语言模型(VLM)升级为具备强大3D度量空间理解能力的自动驾驶专用模型。
- 引入渐进式融合Q-Former,逐步注入激光雷达特征,从而减轻对预训练VLM的灾难性干扰,同时保留其原有知识体系。
- 开发了一套空间感知问答(SA-QA)数据集,专门用于训练模型的高级3D感知与推理能力,使其在驾驶基准测试中表现优异。
-
- 夏天泽、李永康、周立军、姚景峰、熊凯欣、孙海洋、王兵、马坤、陈光、叶航俊、刘文宇、王兴刚
- 出版单位:华中科技大学、小米汽车
- 发表日期:2025年12月29日
- 任务:规划、生成
- 数据集:NAVSIM
- 摘要:
- DriveLaW是一种新范式,通过将视频生成器中的潜在表征直接注入规划器,从而统一自动驾驶的视频生成与运动规划。
- 该框架由用于高保真预测的世界模型DriveLaW-Video和用于生成一致轨迹的扩散规划器DriveLaW-Act组成,两者均采用三阶段渐进式训练策略进行优化。
- 实现了当前最佳性能,显著提升了视频预测指标,并在NAVSIM规划基准上创下新纪录。
-
- 夏仲宇、陈文浩、王永涛、杨明轩
- 发表日期:2025年12月23日
- 任务:规划
- 数据集:nuScenes、Bench2Drive
- 摘要:
- 提出KnowVal,一种将视觉-语言推理与全面的驾驶知识图谱及基于LLM的检索机制相结合的自动驾驶系统。
- 构建了人类偏好数据集和价值模型,用于指导可解释且与价值观一致的轨迹评估。
- 实现了当前最佳的规划性能,包括在nuScenes上达到最低碰撞率,并在Bench2Drive上取得顶尖结果。
InDRiVE:基于潜在分歧的无奖励世界模型预训练用于自动驾驶
- 费扎·汗·汗扎达、权载赫
- 出版单位:密歇根大学迪尔伯恩分校
- 发表日期:2025年12月21日
- 任务:规划
- 数据集:CARLA
- 摘要:
- InDRiVE是基于DreamerV3风格的模型强化学习智能体,专为自动驾驶设计,仅利用来自潜在集成分歧的内在动机进行无奖励预训练。
- 该框架以分歧作为认识论不确定性的代理来驱动探索,并直接从学习到的世界模型中学习无需规划器的探索策略。
- 经过内在动机预训练后,该智能体在CARLA的各种城镇和交通密度下,展现出强大的零样本鲁棒性和针对车道保持、避撞等下游任务的稳健少样本适应能力。
Corner Case中的驾驶:端到端自动驾驶的真实世界对抗性闭环评估平台
- 耿嘉恒、杜家桐、张鑫宇、李烨、王攀渠、黄延军
- 发表日期:2025年12月18日
- 任务:评估
- 摘要:
- 提出了一种端到端自动驾驶的闭环评估平台,该平台通过在真实场景中生成对抗性交互,以创造安全关键的Corner Case场景。
- 平台使用基于流匹配的真实图像生成器和对抗性交通策略,高效地模拟挑战性交互,并评估UniAD、VAD等模型。
-
- 郑宇、胡杰、杨凯伦、张嘉明
- 发表日期:2025年12月17日
- 代码:OccSTeP
- 任务:评估
- 摘要:
- 引入了4D占用时空持久性(OccSTeP)的概念,解决了反应式预测(“接下来会发生什么”)和主动式预测(“如果采取特定未来行动会怎样”)的问题。
- 提出了OccSTeP-WM,一种无分词器的世界模型,具有线性复杂度的注意力主干网络和循环状态空间模块,能够在历史输入缺失或噪声较多的情况下实现稳健的在线推理。
- 建立了一个包含挑战性场景的新OccSTeP基准测试,并报告了语义mIoU(+6.56%)和占用IoU(+9.26%)的显著提升。
OmniDrive-R1: 基于强化学习的交织多模态思维链,用于可信的视觉-语言自动驾驶
- 张振国、郑浩然、王一申、徐乐、邓天辰、陈雪峰、陈渠、张博、黄武雄
- 发表日期:2025年12月16日
- 任务:端到端
- 数据集:DriveLMM-o1
- 摘要:
- OmniDrive-R1是一个用于自动驾驶的端到端视觉-语言模型框架,引入了交织多模态思维链(iMCoT)机制来统一感知与推理。
- 其核心创新在于基于强化学习的视觉定位能力,通过两阶段强化学习管道和Clip-GRPO算法实现,该算法使用无标注、基于过程的定位奖励。
- 相比Qwen2.5VL-7B基线模型,该模型在DriveLMM-o1数据集上显著提升了推理能力,总体得分从51.77%提高到80.35%,最终答案准确率从37.81%提高到73.62%。
MindDrive: 基于在线强化学习的视觉-语言-动作模型,用于自动驾驶
- 傅浩宇、张典坤、赵宗创、崔建峰、谢宏伟、王兵、陈光、梁定康、白翔
- 发表日期:2025年12月15日
- 项目页面:MindDrive
- 任务:规划
- 数据集:Bench2Drive
- 摘要:
- MindDrive是一个用于自动驾驶的视觉-语言-动作(VLA)框架,采用在线强化学习来解决模仿学习中分布偏移等局限性问题。
- 它配备了一个带有两组LoRA参数的LLM:一个决策专家用于推理,一个动作专家用于将决策映射为轨迹,从而实现基于离散语言决策的试错式学习。
- 在Bench2Drive基准测试中,使用轻量级Qwen-0.5B LLM,MindDrive获得了78.04的驾驶分数和55.09%的成功率。
DrivePI: 具有空间感知能力的4D多模态大语言模型,用于统一的自动驾驶理解、感知、预测和规划
- 刘哲、黄润辉、杨睿、严思明、王子宁、侯璐、林迪、白翔、赵恒爽
- 发表日期:2025年12月14日
- 代码:DrivePI
- 任务:规划
- 数据集:nuScenes
- 摘要:
- DrivePI是一个具有空间感知能力的4D多模态大语言模型,作为统一的视觉-语言-动作(VLA)框架用于自动驾驶,通过端到端优化联合完成空间理解、3D感知、预测和规划。
- 该方法整合了点云、多视角图像和语言指令,并利用数据引擎生成文本-占用和文本-流问答对,以实现4D空间理解。
- 仅使用0.5B Qwen2.5作为骨干网络,DrivePI作为一个单一模型,在nuScenes和OpenOcc基准测试中的关键指标上均达到或超越现有的VLA及专用VA模型。
-
- 郑欢、周宇成、闫天毅、苏佳怡、陈洪军、陈杜冰、桂兴泰、韩文成、陶润州、邱中英、杨建飞、沈建兵
- 发表日期:2025年12月13日
- 任务:端到端
- 数据集:Intention-Drive
- 摘要:
- 介绍了Intention-Drive,这是一个全面的基准测试和数据集,用于基于意图驱动的端到端自动驾驶,旨在填补对高层次人类意图解读的空白。
- 提出了想象未来对齐(IFA)这一新颖的评估协议,利用生成式世界模型来评估语义目标的达成情况,而不仅仅是几何精度。
- 探讨了两种解决方案范式——端到端视觉-语言规划器和基于代理的层次化框架——它们相比现有模型表现出更优的人类意图对齐效果。
-
- 林洪斌、杨一鸣、张逸凡、郑超达、冯杰、王盛、王振楠、陈世嘉、王博阳、张宇、刘贤明、崔书广、李震
- 发表日期:2025年12月12日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- FutureX是一个基于思维链的流程,通过未来场景的潜在推理和轨迹优化来增强端到端规划器。
- 引入了自动思考开关,用于在简单场景下选择即时模式,而在复杂推理时则切换到基于潜在世界模型的思考模式。
- 通过生成更合理的计划并减少碰撞,FutureX在NAVSIM上的TransFuser模型中实现了6.2 PDMS的显著提升。
-
- 杨嘉伟、陈子宇、游雨蓉、王燕、李一鸣、陈宇晓、李博义、伊万诺维奇、帕沃内、王悦
- 出版单位:斯坦福大学、NVIDIA
- 发表日期:2025年12月11日
- 项目页面:迈向高效且有效的多摄像头编码,用于端到端驾驶
- 任务:端到端
- 摘要:
- 提出了Flex,一种高效且有效的几何无关场景编码器,用于端到端自动驾驶中的多摄像头数据。它使用少量可学习的场景令牌,联合编码跨摄像头和时间步的信息。
- 在大规模专有数据集中,相比最先进的方法,Flex实现了2.2倍的推理吞吐量和更好的驾驶性能,从而挑战了显式3D归纳偏置(如BEV或占用)的必要性。
- 实验证明,这些紧凑的场景令牌无需显式监督即可自发地发展出场景分解能力,为未来的系统提供了一条更具扩展性和数据驱动性的路径。
-
- 李培正、张正浩、大卫·霍尔茨、于航、杨宇彤、赖宇志、宋锐、安德烈亚斯·盖格、安德烈亚斯·泽尔
- 出版单位:蒂宾根大学
- 发表日期:2025年12月11日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- SpaceDrive是一种具有空间感知能力的基于VLM的驾驶框架,它将空间信息作为显式的位置编码,而非文本数字标记,以实现语义与空间的联合推理。
- 该框架采用通用的位置编码器,用于处理来自多视角深度图、历史自车状态以及文本提示的3D坐标,从而增强视觉特征并直接进行轨迹坐标回归。
- 在nuScenes数据集上实现了开环性能的最先进水平,并在Bench2Drive闭环基准测试中,基于VLM的方法中取得了78.02分的驾驶得分。
-
- 谭书涵、卡夏普·奇塔、陈宇晓、田然、游雨蓉、王妍、罗文杰、曹宇龙、菲利普·克拉亨布尔、马可·帕沃内、鲍里斯·伊万诺维奇
- 发表日期:2025年12月11日
- 任务:端到端
- 摘要:
- Latent-CoT-Drive (LCDrive):一种模型,它将思维链(CoT)推理以潜在语言的形式表达出来,捕捉驾驶行为可能产生的结果,在与动作对齐的潜在空间中统一推理与决策。
- 该模型通过交错使用动作提议标记和世界模型标记来进行推理,这些标记基于学习到的潜在世界模型来表达未来的结果。
- 该方法首先利用真实未来的模拟轨迹进行监督训练,随后通过闭环强化学习进行后训练,从而在大规模端到端驾驶基准测试中实现了更快的推理速度和更优的轨迹质量。
-
- 卢浩、刘子洋、蒋广峰、罗元飞、陈胜、张阳刚、陈英聪
- 发表日期:2025年12月10日
- 项目页面:UniUGP
- 任务:端到端
- 摘要:
- 提出UniUGP,一个统一的理解—生成—规划框架,通过混合专家架构协同场景推理、未来视频生成和轨迹规划。
- 引入跨多个自动驾驶数据集的四阶段训练策略,逐步构建能力,展现出最先进的性能及对长尾场景的优越泛化能力。
COVLM-RL:基于VLM引导的强化学习的自动驾驶关键对象导向推理
- 李琳、蔡宇欣、方建武、薛建儒、吕晨
- 发表日期:2025年12月10日
- 任务:端到端
- 数据集:CARLA
- 摘要:
- COVLM-RL是一种新颖的端到端驾驶框架,将关键对象导向推理与VLM引导的强化学习相结合,以解决泛化、效率和可解释性问题。
- 引入了针对VLM的思维链提示策略,用于推理关键交通要素,生成语义决策先验,从而降低输入维度并将任务知识注入强化学习中。
- 提出了一个一致性损失函数,以使VLM的语义计划与强化学习智能体的连续控制输出保持一致,进而提高可解释性和训练稳定性。
-
- 朱一轩、冯佳琪、郑文钊、高源、陶鑫、万鹏飞、周杰、陆继文
- 发表日期:2025年12月9日
- 任务:生成
- 摘要:
- Astra是一个交互式的通用世界模型,能够为多种场景(如自动驾驶、机器人抓取等)生成精确的动作交互下的现实未来。
- 引入了自回归去噪架构,结合时间因果注意力机制和噪声增强的历史记忆,以在响应速度与时间连贯性之间取得平衡。
- 提出了动作感知适配器和动作专家混合模型,以实现精确控制,并支持探索、操作和相机控制等多种任务的多功能性。
-
- 施博安、王绍华、李永哲、涂嘉恒、张志翰
- 发表日期:2025年12月9日
- 任务:规划
- 摘要:
- 这是一个基于多智能体大型语言模型(LLM)的自动驾驶系统设计空间探索(DSE)框架,整合了多模态推理、3D仿真和性能分析工具。
- 自动化地解析执行结果,并利用专门的LLM智能体指导系统设计探索,包括用户输入、设计生成、执行编排和结果分析。
- 在一个无人出租车案例研究中评估后,该框架在相同的探索预算下,相比遗传算法基线,识别出了更多帕累托最优且成本效益更高的解决方案,同时减少了导航时间。
-
- 贾晓松、张晨赫、江宇乐、王颂柏、张志远、陈晨、张绍峰、周玄鹤、杨雪、严俊驰、姜宇刚
- 发表日期:2025年12月7日
- 任务:端到端
- 数据集:nuScenes
- 摘要:
- 提出了一种用于自动驾驶的空间检索范式,利用离线检索到的地理图像(例如来自谷歌地图)作为额外的输入,以在能见度较差的情况下增强感知能力。
- 扩展了nuScenes数据集,加入了对齐的地理图像,并在检测、地图构建、占用预测、规划和世界建模这五项核心任务上建立了基准。
- 展示了该方法即插即用的特性,表明在无需额外传感器的情况下,某些任务的性能得到了提升。
WAM-Diff:一种结合MoE与在线强化学习的掩码扩散VLA框架,用于自动驾驶
- 作者:徐明旺、崔家豪、蔡飞鹏、商翰林、朱志浩、栾珊、许怡芳、张能、李耀义、蔡佳、朱思宇
- 出版单位:复旦大学
- 发表日期:2025年12月6日
- 项目页面:WAM-Diff
- 代码:WAM-Diff
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- WAM-Diff是一种视觉-语言-行动(VLA)框架,采用掩码扩散技术迭代优化离散序列,以生成未来的本车轨迹。
- 其核心创新包括:将掩码扩散应用于灵活解码、通过基于运动预测和VQA训练的稀疏专家混合模型(MoE)实现可扩展容量,以及利用群体序列策略优化(GSPO)进行在线强化学习。
- 在NAVSIM基准测试中取得最先进性能(v1版本PDMS为91.0,v2版本EPDMS为89.7),表明掩码扩散有望成为自回归及连续扩散策略的替代方案。
AI生成的驾驶视频是否已准备好用于自动驾驶?一种诊断评估框架
- 作者:项新浩、阿比吉特·拉斯托吉、张嘉伟
- 发表日期:2025年12月6日
- 任务:生成
- 数据集:ADGV-Bench
- 摘要:
- 提出了一种诊断框架,用于评估AI生成的驾驶视频(AIGVs)在自动驾驶模型训练与评估中的可靠性。
- 引入了ADGV-Bench基准测试,该测试包含人工标注和密集标签,适用于感知任务;同时提出了ADGVE——一种面向驾驶场景的视频质量评估器。
- 结果表明,使用所提出的评估器对原始AIGVs进行筛选后,视频质量指标及下游自动驾驶模型性能均有所提升,使AIGVs成为有益的数据补充。
-
- 作者:卡尔蒂克·莫汉、索南·辛格、阿米特·阿尔温德·卡莱
- 发表日期:2025年12月5日
- 任务:VQA
- 数据集:NuScenes-QA、DriveLM
- 摘要:
- BeLLA是一种端到端架构,将统一的360°鸟瞰视图表示与大型语言模型连接起来,用于自动驾驶中的问答任务。
- 在需要空间推理的任务上表现优于现有方法,例如相对物体定位和行为理解,绝对提升可达9.3%。
- 经过NuScenes-QA和DriveLM基准测试,证明其在各类问题上均具有竞争力。
-
- 作者:凯文·坎农斯、赛义德·兰杰巴尔·阿尔瓦尔、穆罕默德·阿西富勒·侯赛因、艾哈迈德·雷扎伊、莫赫森·戈拉米、阿里雷扎·海达里哈泽伊、周卫民、张勇、穆罕默德·阿克巴里
- 发表日期:2025年12月4日
- 项目页面:TAD
- 代码:TAD
- 任务:推理
- 数据集:TAD
- 摘要:
- 引入了自动驾驶时间理解(TAD)基准测试,包含近6,000个跨7个任务的问答对,用于评估VLM在以本车为中心的驾驶视频上的表现。
- 对9种通用及专业模型进行了基准测试,发现由于对细粒度运动理解不足,准确率普遍偏低。
- 提出了两种无需训练的解决方案——Scene-CoT和TCogMap——与现有VLM结合使用时,可将TAD的平均准确率提高多达17.72%。
E3AD:一种情感感知的视觉-语言-行动模型,用于以人为本的端到端自动驾驶
- 作者:唐一鸿、廖海成、聂彤、何俊林、曲傲、陈科华、马伟、李振宁、孙利军、徐承忠
- 发表日期:2025年12月4日
- 任务:端到端
- 摘要:
- 提出E3AD,这是一种情感感知的视觉-语言-行动(VLA)框架,适用于开放域端到端(OD-E2E)自动驾驶。该框架能够理解自由形式的指令、推断乘客情绪并规划行驶轨迹。
- 引入了连续的效价-唤醒-支配(VAD)情感模型及双路径空间推理模块,以增强语义理解和类人空间认知能力。
- 采用一致性导向的训练方案,结合模态预训练与偏好对齐,从而在情感估计、视觉接地及规划方面达到最先进水平。
MindDrive:一个整合世界模型与视觉语言模型的一体化框架,用于端到端自动驾驶
- 孙斌、曹耀光、王岩、王睿、商嘉辰、冯解杰、陆佳怡、施佳、杨世春、闫晓宇、宋子 Ying
- 发表日期:2025年12月4日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- MindDrive 是一个协调一致的框架,将高质量轨迹生成与全面的决策推理相结合,用于端到端自动驾驶。
- 提出了一种“情境模拟—候选生成—多目标权衡”的结构化推理范式,包含未来感知轨迹生成器(FaTG)和面向 VLM 的评估器(VLoE)。
- 在 NAVSIM 基准测试中达到最先进水平,通过理性且符合人类价值观的决策,提升了安全性、合规性和泛化能力。
-
- 廖海成、沈焕明、王博楠、李永康、唐一鸿、王承悦、庄丁毅、陈克华、杨海、徐成忠、李振宁
- 发表日期:2025年12月3日
- 任务:感知
- 数据集:Talk2Car
- 摘要:
- 提出 ThinkDeeper 框架,用于自动驾驶中的视觉定位。该框架利用空间感知世界模型(SA-WM)对未来空间状态进行推理,以消除上下文相关指令的歧义。
- 引入 DrivePilot 多源视觉定位数据集,专为自动驾驶设计,并通过 RAG 和思维链提示的 LLM 流程生成语义标注。
- 展示了最先进的性能,在 Talk2Car 排行榜上排名第一,并在 DrivePilot、MoCAD 和 RefCOCO 等基准测试中超越基线,在复杂场景中表现出强大的鲁棒性。
-
- 费扎·汗·汗扎达、权载赫
- 出版单位:密歇根大学迪尔伯恩分校
- 发表日期:2025年12月3日
- 任务:规划
- 数据集:CARLA
- 摘要:
- 提出基于奖励特权的世界模型蒸馏方法,这是一种两阶段框架:教师智能体使用密集的特权奖励进行训练,其潜在动态被蒸馏到仅使用稀疏任务奖励训练的学生身上。
- 证明在 CARLA 的车道保持和超车基准测试中,稀疏奖励的学生表现优于使用密集奖励的教师以及从零开始训练的基线模型,从而提高了对未见路线的泛化能力。
-
- 徐翔、梁傲、刘友泉、李林峰、孔令东、刘子威、刘青山
- 出版单位:南洋理工大学 S-Lab
- 发表日期:2025年12月2日
- 任务:感知
- 数据集:Waymo 开放数据集
- 摘要:
- U4D 是一种不确定性感知的四维 LiDAR 世界建模框架,能够估计空间不确定性,从而精确定位语义上具有挑战性的区域。
- 采用“由难到易”的两阶段流程进行生成:不确定性区域建模和基于不确定性的补全。
- 集成了时空混合(MoST)模块以确保时间一致性,生成几何逼真且时间连贯的 LiDAR 序列。
-
- 伊莎·乔杜里、韦丹特·贾因、阿瓦尔乔特·辛格、卡维娅·萨奇德瓦、萨扬·拉努、加甘迪普·辛格
- 发表日期:2025年12月2日
- 任务:推理
- 摘要:
- 提出 Lumos,这是首个用于指定并正式认证语言模型系统(LMS)行为的原则性框架,采用基于图的命令式概率编程 DSL。
- 通过为自动驾驶中的视觉语言模型(VLM)指定首个安全规范来演示 Lumos,揭示了一款最先进 VLM 中的关键安全缺陷。
- 提供了一个模块化且可扩展的语言框架,能够编码复杂的关联性和时序规范,使 LMS 认证能够适应不断变化的安全威胁。
-
- 吴新正、陈俊毅、钟乃婷、沈勇
- 发表日期:2025年12月2日
- 任务:生成
- 摘要:
- 提出一种结合视觉语言模型(VLM)与自适应引导扩散模型的安全关键测试场景生成框架,用于自动驾驶系统。
- 构建了一个三层分层架构:VLM 战略层用于确定目标,战术层用于制定引导方案,操作层则负责执行引导扩散。
- 引入自适应引导扩散方法,可在闭环仿真中实时精确控制背景车辆,从而生成真实、多样且交互性强的安全关键场景。
OpenREAD:基于 LLM 作为批评家的强化端到端自动驾驶开放式推理
- 张松燕、黄文辉、陈展、柯利斯特·朱亚浩、黄启航、吕晨
- 发表日期:2025年12月1日
- 任务:端到端
- 摘要:
- OpenREAD 是一个基于视觉语言模型(VLM)的开放式推理增强型自动驾驶(AD)框架,支持从高层次推理到低层次轨迹规划的端到端强化微调(RFT)。
- 提议在 RFT 中使用大型语言模型(LLM)作为批评者,以量化开放式问题的推理质量,从而解决场景理解的奖励建模难题。
- 构建了驾驶知识数据集上的大规模思维链(CoT)标注,并表明联合端到端 RFT 可显著提升上游和下游任务的表现,在推理和规划基准测试中达到最先进水平。
RoboDriveVLM:面向自动驾驶的鲁棒视觉-语言模型的新基准与基线
- 廖大成、齐梦实、舒鹏、张志宁、林宇欣、刘亮、马华东
- 发表日期:2025年12月1日
- 任务:评估
- 数据集:RoboDriveBench
- 摘要:
- 介绍RoboDriveBench,这是首个基于VLM的端到端自动驾驶鲁棒性基准,评估了包含传感器和提示扰动的11种仿真场景。
- 提出RoboDriveVLM,一种新颖的基于VLM的框架,通过将多模态数据(如激光雷达、雷达)映射到统一的潜在空间来提升鲁棒性。
- 引入基于跨模态知识蒸馏的测试时适应方法,以提高系统在实际部署中的鲁棒性。
CoT4AD:具有显式思维链推理的视觉-语言-行动模型用于自动驾驶
- 王兆辉、于腾博、唐浩
- 发表日期:2025年11月27日
- 任务:推理
- 数据集:nuScenes
- 摘要:
- CoT4AD,一种新颖的视觉-语言-行动(VLA)框架,引入显式思维链(CoT)推理,以增强自动驾驶中的数值和因果推理能力。
- 在训练过程中整合感知-问题-预测-行动的CoT,以对齐推理与动作空间;在推理阶段执行隐式CoT推理,以实现稳健的决策。
- 在nuScenes和Bench2Drive等基准上的开环和闭环评估中,展现出最先进的性能。
RoadSceneBench:面向中层道路场景理解的轻量级基准
- 刘希言、王涵、王宇虎、蔡俊杰、曹哲、杨建忠、陆震
- 发表日期:2025年11月27日
- 项目页面:RoadSceneBench
- 代码:RoadSceneBench
- 任务:评估
- 数据集:RoadSceneBench
- 摘要:
- RoadSceneBench,一个用于评估中层道路语义视觉推理的轻量级基准,专注于关系理解和结构一致性。
- 提出具有时间一致性的层次化关系奖励传播(HRRP-T),这是一种用于VLM的训练框架,旨在增强推理中的空间连贯性和语义对齐。
OpenTwinMap:面向城市自动驾驶的开源数字孪生生成器
- 亚历克斯·理查德森、乔纳森·斯普林克尔
- 出版单位:亚利桑那大学
- 发表日期:2025年11月26日
- 任务:生成
- 数据集:OpenStreetMap
- 摘要:
- OpenTwinMap,一个基于Python的开源框架,可从LiDAR扫描和OpenStreetMap数据生成高保真度的3D城市数字孪生。
- 该框架强调可扩展性和并行化,能够生成语义分割的静态环境资产,并导出至Unreal Engine用于自动驾驶车辆仿真。
- 其目标是为研究人员提供一条灵活且可扩展的流程,降低技术门槛,目前功能包括OSM/LiDAR预处理、道路网格/地形生成以及初步的CARLA集成。
-
- 周思卓、贾晓松、张帆睿、李俊杰、张居勇、冯宇康、孙建文、王宋布尔、尤俊奇、严俊驰
- 发表日期:2025年11月26日
- 任务:生成
- 数据集:nuScenes
- 摘要:
- LaGen,首个从单帧LiDAR输入开始逐帧自回归生成长时程LiDAR场景的框架。
- 引入场景解耦估计模块,以增强交互式的对象级生成;同时引入噪声调制模块,以缓解长时程误差累积。
- 构建了针对nuScenes的评估协议,证明其性能优于当前最先进的LiDAR生成和预测模型,尤其是在后续帧上表现更佳。
4DWorldBench:面向3D/4D世界生成模型的综合评估框架
- 陆一婷、罗伟、涂佩妍、李浩然、朱瀚鑫、俞子豪、王星睿、陈心怡、彭新格、李欣、陈志博
- 出版单位:中国科学技术大学
- 发表日期:2025年11月25日
- 项目页面:4DWorldBench
- 任务:推理
- 数据集:4DWorldBench
- 摘要:
- 介绍4DWorldBench,这是一个统一的基准,用于从四个关键维度评估3D/4D世界生成模型:感知质量、条件-4D对齐、物理真实性和4D一致性。
- 提出一种自适应评估框架,将多模态条件映射到统一的文本空间,并结合LLM作为评判者、MLLM作为评判者以及基于网络的方法进行综合评估。
-
- 闫天义、唐涛、桂兴泰、李永康、郑嘉森、黄伟尧、孔令东、韩文成、周霞、张雪阳、詹一飞、詹坤、徐成中、沈建兵
- 发表日期:2025年11月25日
- 任务:端到端
- 摘要:
- 介绍一种利用公正世界模型对自动驾驶策略进行后训练优化的框架,旨在克服RL中世界模型的乐观偏差。
- 提出一种新颖的反事实合成数据管道,用于生成一系列可能的碰撞和离路事件,从而教会模型诚实地预测危险。
- 实验证明,该框架以公正世界模型作为内部批评家,在仿真环境中显著减少了安全违规行为,并在新的风险预见基准测试中优于基线。
DeeAD:视觉-语言-行动的动态提前退出机制,用于高效自动驾驶
- 胡海波、黄连明、关楠、薛春Jason
- 发表日期:2025年11月25日
- 任务:规划
- 数据集:Bench2Drive
- 摘要:
- DeeAD是一种无需训练、由动作引导的提前退出框架,通过将中间轨迹的物理可行性与轻量级规划先验进行评估,从而加速VLA规划。
- 引入多跳控制器,根据得分变化率自适应跳过冗余的Transformer层,实现高达28%的层稀疏化和29%的延迟降低。
- 可无缝集成到现有VLA模型中(如ORION),无需重新训练,在Bench2Drive基准测试上保持规划质量和安全性。
CoC-VLA:基于因果链的视觉-语言-行动模型,深入探索可解释自动驾驶中的对抗域迁移
- 张大鹏、沈飞、赵睿、陈寅达、智鹏、李晨阳、周锐、周庆国
- 发表日期:2025年11月25日
- 任务:端到端
- 摘要:
- 提出CoC-VLA,一种由VLM引导的端到端对抗域迁移框架,用于将长尾场景处理能力从仿真环境迁移到实际部署中。
- 该框架由教师VLM、学生VLM和判别器组成,利用共享的因果链视觉-语言模型(CoC VLM)基础架构进行思维链式推理。
- 引入了一种新颖的对抗训练策略,通过判别器促进能力从仿真环境向真实世界的迁移。
Map-World:面向自动驾驶的掩码动作规划与路径积分世界模型
- 胡斌、陆子健、廖海成、袁承然、饶斌、李永康、李国发、崔志勇、许成忠、李振宁
- 出版单位:华中科技大学、小米电动汽车
- 发表日期:2025年11月25日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- MAP-World是一种无先验的多模态规划框架,将掩码动作规划与基于路径权重的世界模型相结合,用于自动驾驶。
- 掩码动作规划(MAP)模块将未来的本车运动视为掩码序列补全问题,无需锚点库或教师策略即可生成多样且时间一致的轨迹。
- 轻量级世界模型会为每个候选轨迹滚动预测未来的BEV语义,训练时以轨迹概率作为路径权重,从所有可能的未来分布中学习,从而在NAVSIM上达到最先进水平。
Percept-WAM:感知增强型世界感知-行动模型,用于鲁棒的端到端自动驾驶
- 韩建华、田萌、朱江通、何凡、张慧欣、郭思彤、朱德昌、唐浩、徐培、郭宇泽、牛民哲、朱浩杰、董启超、闫学超、董思源、侯璐、黄清秋、贾晓松、徐航
- 发表日期:2025年11月24日
- 任务:端到端
- 数据集:nuScenes、NAVSIM
- 摘要:
- Percept-WAM是一种感知增强型世界感知-行动模型,将2D/3D场景理解隐式地整合到单一的视觉-语言模型(VLM)中,以实现鲁棒的端到端自动驾驶。
- 引入World-PV和World-BEV标记,统一2D/3D感知任务;并通过IoU感知评分和并行自回归解码机制,提升在长尾及复杂场景中的稳定性。
- 在感知基准测试中表现出色(如COCO的51.7/58.9 mAP,nuScenes BEV检测),并在nuScenes和NAVSIM上的规划性能优于DiffusionDrive等先前方法。
-
- 宫展涛、范辽远、郭青、徐勋、杨旭磊、李世杰
- 发表日期:2025年11月24日
- 任务:VQA
- 数据集:FSU-QA
- 摘要:
- 提出“预见智能”这一概念,即预测未来事件的能力,并介绍了专为评估这一能力而设计的新视觉问答数据集FSU-QA。
- 进行了全面研究,表明当前的视觉-语言模型在预见推理方面存在困难,并证明通过微调,FSU-QA可以有效提升这一能力。
GuideFlow:约束引导的流匹配,用于端到端自动驾驶中的规划
- 刘林、贾彩燕、于冠义、宋子 Ying、李俊乔、贾飞阳、吴培亮、郝晓帅、罗艳丹
- 发表日期:2025年11月24日
- 代码:GuideFlow
- 任务:规划
- 数据集:Bench2Drive、NuScenes、NAVSIM、ADV-NuScenes
- 摘要:
- GuideFlow 是一种面向端到端自动驾驶的新型规划框架,它利用约束流匹配显式建模流匹配过程,从而缓解多模态轨迹模式坍缩问题。
- 该框架在流匹配生成过程中直接施加显式约束,并通过基于能量的模型(EBM)统一训练,以稳健地满足物理约束。
- GuideFlow 在生成过程中将驾驶激进程度参数化为控制信号,从而实现对轨迹风格的精确调控,并在 NavSim 等基准测试中取得了最先进的结果。
LiSTAR:面向自动驾驶中 4D LiDAR 序列的射线中心世界模型
- 刘沛、王松涛、张朗、彭兴悦、吕元东、邓佳鑫、陆颂欣、马伟良、张雪洋、詹一飞、郎先鹏、马军
- 发表日期:2025年11月20日
- 项目页面:LiSTAR
- 任务:预测
- 数据集:Waymo
- 摘要:
- LiSTAR 是一种新颖的生成式世界模型,可以直接在传感器的原生几何上操作,用于合成高保真且可控的 4D LiDAR 数据。
- 它引入了混合圆柱-球面(HCS)表示法以保持数据保真度,并采用以射线为中心的时空注意力 Transformer(START)来确保强大的时间一致性。
- 提出了与 4D 点云对齐的体素布局,以及离散的 Masked Generative START(MaskSTART)框架,用于高效、高分辨率且受布局指导的组合式生成。
您的视觉-语言模型是否已准备好用于自动驾驶安全?评估外部与车内风险的综合基准
- 孟宪辉、张宇辰、黄志坚、陆正、季子凌、尹瑶瑶、张宏远、蒋广峰、林艳丹、陈龙、叶航军、张力、刘军、郝晓帅
- 发表日期:2025年11月18日
- 任务:VQA
- 数据集:DSBench
- 摘要:
- 介绍了 DSBench,这是首个综合性驾驶安全基准,旨在以统一的方式评估视觉-语言模型(VLM)对外部环境风险及车内驾驶行为安全的认知能力。
- 该基准涵盖 10 个关键类别和 28 个子类别,揭示了 VLM 在复杂的安全关键情境中性能显著下降。
- 构建了一个包含 9.8 万个安全相关实例的大规模数据集,表明在此数据上进行微调可显著提升 VLM 在自动驾驶中的安全性能。
-
- 秦杰克、王志涛、郑怡楠、陈可宇、周阳、钟源欣、程思远
- 发表日期:2025年11月18日
- 任务:端到端
- 数据集:Bench2Drive
- 摘要:
- 介绍了风险语义蒸馏(RSD),这是一种框架,利用视觉-语言模型(VLM)为端到端自动驾驶骨干网络提供关键物体的风险注意力,从而提高泛化能力。
- 提出 RiskHead 插件模块,将 VLM 推导出的因果风险估计蒸馏到鸟瞰图(BEV)特征中,生成可解释的风险注意力图,从而实现更丰富的空间和风险表征。
- 在 Bench2Drive 基准测试中,通过使 BEV 特征与人类般的风险感知驾驶行为相一致,显著提升了复杂动态环境下的感知和规划能力。
-
- 法比安·施密特、努希克·穆罕默德·卡伊兰·阿卜杜勒·纳扎尔、马库斯·恩茨韦勒、阿比纳夫·瓦拉达
- 出版方:斯图加特大学、埃斯林根应用科学大学
- 发表日期:2025年11月18日
- 代码:TLS-Assist
- 任务:规划
- 数据集:LangAuto
- 摘要:
- 介绍了 TLS-Assist,这是一个模块化冗余层,通过明确的交通信号灯和标志识别来增强基于 LLM 的自动驾驶代理,以强制执行交通规则。
- 该即插即用框架将检测结果转换为结构化的自然语言消息,并注入到 LLM 的输入中,支持单目和多目相机配置。
- 在 CARLA 中的 LangAuto 基准测试上,TLS-Assist 相较于 LMDrive 和 BEVDriver 分别实现了最高 14% 和 7% 的相对驾驶性能提升,同时减少了交通违规行为。
CorrectAD:一种自纠正智能体系统,用于改进自动驾驶端到端规划
- 马恩辉、周利军、唐涛、张嘉欢、蒋俊鹏、张展、韩东、詹坤、张雪阳、郎先鹏、孙海洋、周霞、林迪、于凯成
- 发表日期:2025年11月17日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 提出CorrectAD,一种自纠正智能体系统,通过解决罕见但安全关键的长尾故障问题来改进端到端规划。
- 引入PM-Agent以制定数据需求,并开发DriveSora生成模型,用于创建与3D布局一致的时空连贯视频,以进行数据仿真。
- 该模型无关的流程可纠正大量失败案例,在nuScenes数据集上将碰撞率降低39%,在内部数据集中降低27%。
-
- 胡鑫、景涛涛、田仁然、丁正明
- 发表日期:2025年11月17日
- 任务:规划
- 摘要:
- 提出一种新方法,将视觉-语言模型(VLMs)的角色从直接决策生成器转变为语义增强器,以实现更可靠和可解释的自动驾驶。
- 引入多模态交互架构,融合视觉和语言特征以实现准确的决策及文本解释,并采用后处理精炼模块利用VLMs提升预测可靠性。
- 在两个自动驾驶基准测试中表现出最先进的性能,为将VLMs集成到可靠的自动驾驶系统中提供了有前景的方向。
-
- 阿莉莎·库拉姆、阿米尔·莫埃尼、张尚通、罗汉·钱德拉
- 发表日期:2025年11月16日
- 任务:端到端
- 数据集:CARLA
- 摘要:
- 提出一种少样本提示驱动的领域适应方法,用于闭环自动驾驶,借助上下文强化学习(ICRL),无需在目标域更新模型或收集额外数据。
- 将提示驱动的领域适应扩展至闭环驾驶,通过推理过程中观察到的一般轨迹实现,从而超越了以往仅限于感知任务的方法。
- 在CARLA中的实验表明,与现有的提示驱动领域适应基线相比,ICRL能够产生更安全、更高效且更舒适的驾驶策略,尤其是在恶劣天气条件下。
LLMs是未来之路吗?LLMs引导的强化学习在去中心化自动驾驶中的案例研究
- 提穆尔·安瓦尔、杰弗里·陈、王宇燕、罗汉·钱德拉
- 发表日期:2025年11月16日
- 任务:规划
- 摘要:
- 研究小型本地部署的LLMs(参数量小于14B)是否可以通过为强化学习提供奖励塑造来支持高速公路自动驾驶,而非直接控制。
- 呈现一个案例研究,比较了纯强化学习、纯LLMs以及混合LLMs-强化学习方法在复杂场景下的去中心化自动驾驶表现,如密集的高速公路和汇流处。
- 结果显示,混合方法介于纯强化学习(中等成功)和纯LLMs(高成功率但效率较低)之间,其中由LLMs影响的方法表现出系统的保守倾向和依赖模型的差异性。
-
- 成贤基、文成佑、安浩镇、姜哲勋、沈贤哲
- 发表日期:2025年11月16日
- 任务:端到端
- 摘要:
- VLA-R是一种开放世界端到端自动驾驶框架,将开放世界的感知与新颖的视觉-动作检索范式相结合。
- 利用冻结的视觉-语言模型进行开放世界检测和分割,并通过Q-Former瓶颈层连接感知与行动领域。
- 引入视觉-动作对比学习机制,对视觉-语言和动作嵌入进行对齐,以实现有效的开放世界推理和动作检索。
FLAD:基于LLMs的车辆-边缘-云网络联邦学习自动驾驶框架
- 向天傲、支明健、毕元国、蔡林、陈宇豪
- 出版单位:维多利亚大学、多伦多大学
- 发表日期:2025年11月12日
- 任务:端到端
- 摘要:
- FLAD是一个基于LLMs的联邦学习自动驾驶框架,旨在解决协作式模型训练中计算/传输成本高昂及数据隐私方面的挑战。
- 提出一种云-边缘-车辆协同架构,结合智能并行训练与通信调度,以及知识蒸馏方法,以针对异构边缘数据个性化定制LLMs。
- 在配备NVIDIA Jetson的测试平台上进行了原型验证,展示了分布式车载资源的有效利用及优越的端到端自动驾驶性能。
-
- 龙克克、郭家诚、张天云、于洪凯、李晓鹏
- 发表日期:2025年11月9日
- 任务:感知
- 数据集:nuScenes
- 摘要:
- 提出一种自包含的低秩方法,仅使用VLM生成的多个字幕,无需外部参考或访问模型即可自动按幻觉程度排序。
- 构建句子嵌入矩阵,将其分解为低秩共识部分和稀疏残差部分,并根据残差大小选择最无幻觉的字幕。
- 在nuScenes数据集上达到87%的选择准确率,优于基线方法,与人类判断高度相关,并将实时应用的推理时间缩短51%-67%。
AdaDrive:面向语言驱动自动驾驶的自适应慢速-快速系统
- 张瑞飞、谢俊林、张伟、陈维凯、谭晓、万翔、李冠斌
- 发表日期:2025年11月9日
- 代码:AdaDrive
- 任务:规划
- 摘要:
- AdaDrive 是一种自适应协作的慢速-快速框架,能够最优地决定何时以及如何让大型语言模型参与语言驱动自动驾驶中的决策过程。
- 提出了一种自适应激活损失函数,仅在复杂场景下动态调用大型语言模型;同时引入自适应融合策略,根据场景复杂度连续、按比例地调节大型语言模型的影响。
-
- Phat Nguyen、Erfan Aasi、Shiva Sreeram、Guy Rosman、Andrew Silva、Sertac Karaman、Daniela Rus
- 出版单位:麻省理工学院
- 发表日期:2025年11月6日
- 任务:规划
- 数据集:Bench2Drive
- 摘要:
- 该框架是一种统一的共享自治系统,利用视觉语言模型(VLM)在高层次抽象上整合人类输入与自主规划器,以推断驾驶员意图。
- 框架能够合成连贯的策略来协调人类与自主控制,在人体实验调查中表现出高度一致性,并在 Bench2Drive 基准测试中显著提升性能。
-
- 卢博文
- 发表日期:2025年10月31日
- 任务:预测
- 数据集:nuPlan
- 摘要:
- 提出一种动态多专家门控框架,能够在样本级别自适应地从基于物理信息的 LSTM、Transformer 和微调后的 GameFormer 中选择最可靠的轨迹预测器。
- 将轨迹专家选择问题建模为基于内部模型信号(元特征)的成对排序问题,无需事后校准即可优化决策质量。
- 在 nuPlan-mini 数据集上评估,LLM 增强的三专家门控方案相比 GameFormer 将最终位移误差降低了 9.5%,并在开环仿真中持续表现出改进效果。
Token Is All You Need:通过信念-意图协同演化实现认知规划
- 桑世尧
- 发表日期:2025年10月30日
- 任务:规划
- 数据集:nuPlan
- 摘要:
- 提出有效的规划源于一组语义丰富的最小化标记中信念与意图的协同演化,从而挑战了对详尽场景建模的需求。
- 实验证明,稀疏的意图标记即可取得优异性能,而基于预测的未来标记进行轨迹解码则可将 ADE 提升 21.6%,表明性能源自认知规划。
- 观察到训练过程中认知一致性和时间模糊性的涌现,确立了一种新的范式:智能在于信念与意图的标记化二元性。
Alpamayo-R1:弥合推理与动作预测,实现长尾场景下的通用自动驾驶
- 王燕、罗文杰、白俊杰、曹宇龙、车彤、陈科、陈宇潇、戴蒙德·珍娜、丁一凡、丁文浩、冯亮、格雷格·海因里希、黄杰克、卡库斯·彼得、李博毅、李品毅、林宗义、刘东然、刘明宇、刘浪川、刘志坚、陆杰森、毛云翔、莫尔恰诺夫·帕夫洛、帕瓦奥·林赛、彭正浩、兰辛格·迈克、施默灵·埃德、沈诗达、石云飞、塔里克·萨拉、田冉、韦克尔·蒂尔曼、翁新硕、肖天军、杨埃里克、杨晓东、尤荣、曾晓辉、张文远、伊万诺维奇·鲍里斯、帕沃内·马可
- 出版单位:NVIDIA
- 发表日期:2025年10月30日
- 代码:Alpamayo-R1
- 任务:规划
- 摘要:
- Alpamayo-R1 (AR1) 是一种视觉-语言-行动模型(VLA),将因果链推理与轨迹规划相结合,用于处理复杂的长尾驾驶场景。
- 引入了通过混合自动标注与人机协作流程构建的因果链(CoC)数据集,以及由推理型 VLM 和基于扩散的轨迹解码器组成的模块化架构。
- 该模型采用多阶段训练策略,结合监督微调与强化学习,在仿真和实时车载部署中均实现了更高的规划精度与安全性。
-
- 刘琳、于冠义、宋子 Ying、李俊乔、贾彩艳、贾飞阳、吴培良、罗燕丹
- 发表日期:2025年10月30日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- 提出 CATG,一种新颖的规划框架,利用约束流匹配解决模仿学习中的模式坍塌问题,并将安全与运动学约束直接融入生成过程。
- 在流匹配过程中显式施加约束,并将驾驶激进程度参数化为控制信号,以调节轨迹风格。
- 在 NavSim v2 挑战赛中以 EPDMS 评分 51.31 获得第二名,并荣获创新奖。
-
- 吴傲迪、罗旭波
- 出版单位:中国科学院大学、中南大学
- 发表日期:2025年10月28日
- 代码:UCAS-CSU-phase2
- 任务:VQA
- 数据集:RoboSense 挑战赛
- 摘要:
- 构建了一个系统的自动驾驶场景理解框架,基于提示混合路由器、带有空间推理的任务特定提示、视觉组装模块以及优化的推理参数。
- 在 Qwen2.5-VL-72B 上实现,在 IROS 2025 的 RoboSense 挑战赛中,清洁数据上的准确率达到 70.87%,而损坏数据上则达到 72.85%。
-
- 吴冠林、苏博彦、赵阳、王普、林一辰、杨浩弗兰克
- 发表日期:2025年10月24日
- 任务:感知
- 数据集:SIGBench
- 摘要:
- 提出空间智能网格(SIG),这是一种基于网格的结构化方案,用于显式编码物体布局、关系以及物理约束先验,以支持自动驾驶基础模型的推理。
- 推导出基于SIG的评估指标,用以量化模型内在的视觉-空间智能(VSI),从而将空间能力与语言先验区分开来。
- 发布SIGBench基准数据集,包含1400帧驾驶场景,并附有SIG真值标签和人类视线轨迹标注,以支持VSI相关任务。
-
- 曾凯、吴展谦、熊凯欣、魏晓宝、郭向宇、朱振鑫、何嘉乐、周立军、曾博涵、陆明、孙海洋、王兵、陈光、叶航军、张文涛
- 出版单位:华中科技大学、小米电动汽车
- 发表日期:2025年10月22日
- 项目页面:Dream4Drive
- 代码:Dream4Drive
- 任务:感知
- 数据集:DriveObj3D
- 摘要:
- 提出Dream4Drive框架,该框架可将视频分解为具备3D感知的引导地图,并渲染3D资产,从而生成经过编辑的多视角逼真视频,用于训练感知模型。
- 支持大规模生成多视角Corner Case场景,显著提升自动驾驶中Corner Case场景的感知能力。
- 贡献了一个大规模3D资产数据集DriveObj3D,涵盖典型驾驶场景类别,以实现多样化的3D感知视频编辑。
-
- 李博文、马壮、杜达龙、彭宝瑞、梁竹瑾、刘振强、马超、金月明、赵浩、曾文俊、金鑫
- 出版单位:清华大学、上海人工智能实验室、中国科学院大学、上海交通大学
- 发表日期:2025年10月21日
- 项目页面:OmniNWM
- 任务:导航
- 摘要:
- OmniNWM是一种全景式全知全能的导航世界模型,在统一框架内同时处理状态、动作和奖励维度,适用于自动驾驶场景。
- 它能够联合生成RGB、语义、度量深度和3D占用率的全景视频,并采用灵活的强制策略进行长时程自回归生成。
- 引入归一化的全景Plucker射线图以实现精确的轨迹控制,并利用生成的3D占用率定义基于规则的密集奖励,以确保驾驶合规性和安全性。
-
- 尹承俊、朴俊成、林永善、沈贤静
- 发表日期:2025年10月21日
- 任务:视觉问答
- 数据集:nuScenes
- 摘要:
- 这是一个用于自动驾驶的两阶段视觉-语言问答系统,能够利用大型多模态大语言模型回答高层次的感知、预测和规划问题。
- 系统基于多摄像头输入、时间序列历史和思维链提示对模型进行条件设置,并通过自一致性集成提高可靠性。
- 第二阶段通过场景元数据和任务特定指令增强提示,显著提升了准确率,并在严重视觉退化条件下表现出强大的鲁棒性。
-
- 罗伯托·布鲁斯尼基、大卫·波普、高远、皮奇尼尼·马蒂亚、约翰内斯·贝茨
- 发表日期:2025年10月20日
- 任务:感知
- 摘要:
- 提出SAVANT框架,通过分层场景分析和结构化场景描述提取与多模态评估的双阶段流程,检测异常驾驶场景。
- 在真实驾驶场景中实现了高准确率和召回率,使一个经过微调的70亿参数开源模型超越了专有模型,同时支持本地低成本部署。
- 针对数据稀缺问题,自动为超过9640张真实图像打上了高精度标签,为自动驾驶系统中的可靠语义监控提供了切实可行的路径。
SimpleVSF:用于端到端自动驾驶轨迹预测的VLM评分融合方法
- 郑培儒、赵云、龚展、朱宏、吴绍华
- 发表日期:2025年10月20日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- SimpleVSF是一种新颖的框架,通过利用视觉-语言模型(VLM)的认知能力和先进的轨迹融合技术,提升端到端规划性能。
- 它结合了传统评分器和新型VLM增强评分器,使用稳健的权重融合器进行定量聚合,并借助VLM融合器进行定性、情境感知的决策。
- 该方法在ICCV 2025 NAVSIM v2端到端驾驶挑战赛中名列前茅,展现了在安全性、舒适性和效率方面的最先进水平。
DiffVLA++:通过度量引导对齐桥接认知推理与端到端驾驶
- 高宇、蒋安庆、王一儒、王继军、姜浩、孙志刚、于恒文、王硕、赵浩、孙浩
- 发表日期:2025年10月20日
- 任务:端到端
- 摘要:
- DiffVLA++是一种增强型自动驾驶框架,通过度量引导对齐将认知推理与端到端规划相连接。
- 引入了一个用于语义化轨迹的VLA模块、一个用于物理可行性的E2E模块,以及一个度量引导的轨迹评分器来对齐两者的输出。
- 在ICCV 2025自动驾驶大挑战排行榜上取得了49.12的EPDMS分数。
-
- 梅建标、杨宇、杨雪萌、温立成、吕佳俊、史博天、刘勇
- 发表日期:2025年10月19日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 提出IR-WM,一种专注于为视觉中心自动驾驶建模当前状态及世界演化的隐式残差世界模型,避免了完整的场景重建。
- 引入了一种利用BEV特征作为时间先验的残差预测方法,并设计了一个对齐模块以缓解随时间累积的误差。
- 实验证明,来自世界模型的隐式未来状态能够提升规划精度,在nuScenes数据集上的4D占用预测和轨迹规划任务中达到了顶尖性能。
-
- 郭子昂、张祖峰
- 发表日期:2025年10月17日
- 任务:端到端
- 数据集:nuScenes
- 摘要:
- VDRive是一种新颖的端到端自动驾驶流程,通过建模状态-动作映射实现可解释且鲁棒的决策。
- 结合了用于上下文状态理解的视觉语言动作模型(VLA)和基于生成式扩散策略的动作头,用于几何动作的生成。
- 采用带有演员-评论家框架的强化学习微调流程,在Bench2Drive和nuScenes基准测试中达到了最先进水平。
DriveCritic:借助视觉-语言模型实现面向情境、符合人类偏好的自动驾驶评估
- 宋京宇、李振鑫、兰世怡、孙兴隆、张娜迪恩、沈玛英、陈约书亚、斯金纳·凯瑟琳、阿尔瓦雷斯·何塞
- 发表日期:2025年10月15日
- 任务:规划
- 摘要:
- 介绍了DriveCritic,一种用于情境感知、符合人类偏好的自动驾驶规划评估的新框架,包含标注了人类偏好意见的挑战性场景精选数据集,以及基于视觉-语言模型(VLM)的评估器。
- DriveCritic模型采用两阶段监督与强化学习相结合的微调流程,通过整合视觉与符号上下文来评判轨迹对之间的优劣,其在匹配人类偏好方面的表现显著优于现有指标。
DriveVLA-W0:世界模型放大自动驾驶中的数据规模效应
- 李英燕、尚书瑶、刘伟松、战兵、王浩辰、王雨琪、陈云涛、王小满、安亚松、唐楚峰、侯陆、范卢、张兆祥
- 发表日期:2025年10月14日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出了DriveVLA-W0,一种利用世界建模预测未来图像的训练范式,通过密集的自监督信号来学习驾驶环境的动力学特性。
- 引入了一个基于世界建模学习表示构建的轻量级动作专家,用于实时推理。
- 实验证明,该方法相比基线有显著性能提升,并显示出随着训练数据集规模的扩大,数据规模效应会进一步增强。
-
- 谭天毅、郑一楠、梁瑞明、王泽旭、郑可欣、郑金良、李建雄、詹宪元、刘静静
- 发表日期:2025年10月13日
- 代码:Flow-Planner
- 任务:规划
- 数据集:nuPlan、interPlan
- 摘要:
- 提出了Flow Planner,这是一个用于自动驾驶规划的框架,通过数据建模、架构设计和学习方式的创新来解决交互行为的建模问题。
- 引入了细粒度的轨迹标记化技术,以及专门用于高效时空融合的架构,以更好地捕捉交互行为。
- 结合无分类器指导的流匹配技术进行多模态行为生成,动态调整智能体间的交互权重,从而形成连贯的响应策略。
-
- 胡东、胡芬青、杨立东、黄超
- 发表日期:2025年10月13日
- 代码:GTR2L
- 任务:规划
- 摘要:
- 提出了一种用于安全自动驾驶的新型游戏论风险塑造强化学习(GTR2L)框架,该框架结合了多层级游戏论世界模型,以预测交互行为和风险。
- 具有基于预测不确定性的自适应展开 horizon,以及一种考虑不确定性的屏障机制,用于灵活调节安全边界。
- 在安全关键场景中表现出色,其成功率、碰撞减少率和效率均优于当前最先进的基线方法及人类驾驶员。
-
- 卡尼什卡·贾桑卡尔、苏尼迪·坦德尔
- 发表日期:2025年10月12日
- 任务:规划
- 数据集:nuPlan
- 摘要:
- Align2Act 是一个运动规划框架,它通过基于人类推理和交通规则的结构化驾驶指令,将指令微调的大语言模型转化为与人类行为一致的可解释规划器。
- Align2ActChain 模块引导逐步推理,生成可解释的理由说明和安全轨迹,并在 LLaMA-2-7B 上使用 LoRA 技术,基于 nuPlan 数据集进行微调。
- 在真实的 nuPlan 封闭环基准测试中,该框架展示了更好的规划质量和更接近人类的行为表现,其结构化的推理显著提升了性能,优于基线大语言模型规划器。
LinguaSim:基于大语言模型的自然语言指令驱动的多车辆交互测试场景生成
- 石庆远、孟庆文、程浩、徐庆、王建强
- 发表日期:2025年10月9日
- 任务:生成
- 摘要:
- LinguaSim 是一个基于大语言模型的框架,能够将自然语言转换为逼真的、可交互的 3D 场景,用于自动驾驶车辆的测试和训练,同时确保动态的车辆交互以及输入描述与生成场景之间的高度一致性。
- 反馈校准模块可以提升生成精度,更好地符合用户意图,并减少过度激进的行为(碰撞率从 46.9% 降至 6.3%)。
- 该框架弥合了自然语言与封闭式交互仿真之间的鸿沟,通过场景描述和自动驾驶模型双重约束来控制对抗性车辆行为。
GTR-Bench:评估视觉-语言模型中的地理-时间推理能力
- 谢庆洪兵、夏兆源、朱峰、龚利军、李子悦、赵睿、曾龙
- 发表日期:2025年10月9日
- 代码:GTR-Bench
- 任务:评估
- 摘要:
- 介绍了 GTR-Bench,这是一个用于评估大规模摄像头网络中移动目标地理-时间推理能力的新基准,要求在地图和视频之间切换视角,并在不重叠的视频视图之间进行联合推理。
- 评估结果显示,当前最先进的视觉-语言模型与人类在地理-时间推理方面的表现存在显著差距,揭示了这些模型在上下文利用、时间预测以及地图与视频对齐等方面的关键不足。
- 该基准为自动驾驶和具身智能等应用提供了关于时空智能的洞见,相关代码和基准将公开发布。
CVD-STORM:用于自动驾驶的跨视角视频扩散与时空重建模型
- 张天瑞、刘一辰、郭子林、郭宇欣、倪靖成、丁晨静、徐丹、陆雷威、吴泽寰
- 出版方:商汤科技
- 发表日期:2025年10月9日
- 项目页面:CVD-STORM
- 任务:生成
- 摘要:
- CVD-STORM 是一种跨视角视频扩散模型,配备时空重建变分自编码器,可在各种控制输入下生成具有 4D 重建效果的长期多视角视频。
- 该方法通过辅助的 4D 重建任务对变分自编码器进行微调,以增强 3D 结构和时间编码能力,随后将其整合到视频扩散过程中,从而提升生成质量。
- 该模型在 FID 和 FVD 指标上均有提升,其联合训练的高斯泼溅解码器能够重建动态场景,用于获取几何信息和场景理解。
-
- 王嘉豪、杨振沛、白怡静、李英伟、邹玉良、孙博、阿比吉特·昆杜、何塞·莱萨马、黄露娜、朱泽昊、黄继京、德拉戈米尔·安格洛夫、谭明兴、蒋驰宇
- 出版方:谷歌研究院、Waymo
- 发表日期:2025年10月7日
- 任务:生成
- 摘要:
- 提出了 Drive&Gen 方法,将驾驶模型与生成式世界模型相结合,利用新颖的统计指标评估视频的真实感,从而用于端到端规划器的评估。
- 利用视频生成的可控性,研究影响端到端规划器性能的分布差异和偏差。
- 结果表明,视频生成模型所生成的合成数据是替代真实数据的一种经济高效的方式,能够提升端到端模型在现有运行设计域之外的泛化能力。
-
- 廖义凡、孙震、邱晓云、赵子霄、唐文兵、何新磊、郑新虎、张天伟、黄心怡、韩星硕
- 发表日期:2025年10月3日
- 任务:规划
- 数据集:ROADWork
- 摘要:
- 首次系统性地研究了视觉-语言模型(VLM)在施工区域中的轨迹规划能力,发现主流 VLM 的失败率高达 68.0%,并识别出 8 种常见的失败模式。
- 提出了 REACT-Drive,这是一种将 VLM 与检索增强生成(RAG)技术相结合的轨迹规划框架,能够将以往的失败案例转化为约束规则,并检索相似模式以提供指导。
- 实验表明,REACT-Drive 效果显著,与 VLM 基线相比,平均位移误差降低了约 3 倍,并且在 ROADWork 数据集及 15 个真实施工区域场景的实验中,实现了最低的推理时间(0.58 秒)。
视觉语言模型的战略融合:基于Shapley赋权的上下文感知Dawid-Skene算法在自动驾驶多标签任务中的应用
- 冯宇翔、张可扬、哈桑·乌丘伊德、阿什维尔·卡尼亚姆帕姆比尔、伊万尼斯·索夫拉斯、帕纳约蒂斯·安格鲁迪斯
- 出版单位:帝国理工学院
- 发表日期:2025年10月1日
- 任务:感知、推理
- 数据集:HDD
- 摘要:
- 提出了一种基于博弈论的融合方法——具有共识机制的Shapley赋权上下文感知Dawid-Skene算法,用于对行车记录仪视频进行多标签理解,以解决自动驾驶系统中视觉语言模型产生的幻觉问题。
- 利用自动化的流水线,融合了HDD真实标注、车辆运动学和目标跟踪信息,构建了一个包含1000段真实行车记录仪片段的专用数据集,并进行了结构化标注。
- 该方法相比单一模型取得了显著提升,包括汉明距离降低23%,F1分数提高超过47%,为决策支持提供了校准且稳健的组件。
-
- 高源、马蒂亚·皮奇尼尼、罗伯托·布鲁斯尼基、张宇辰、约翰内斯·贝茨
- 出版单位:慕尼黑工业大学
- 发表日期:2025年9月30日
- 任务:VQA
- 数据集:nuScenes、Waymo、CommonRoad
- 摘要:
- 提出了NuRisk,一个用于自动驾驶中主体级风险评估的综合性视觉问答(VQA)数据集。该数据集基于nuScenes和Waymo的真实世界数据,并补充了来自CommonRoad仿真器的安全关键场景。
- 数据集提供基于鸟瞰视角(BEV)的序列图像,附带定量的主体级风险标注,旨在支持并基准测试时空推理能力。
- 基准测试表明,标准视觉语言模型在此任务上难以进行明确的时空推理;而经过微调的7B参数量视觉语言模型则提高了准确性和降低了延迟,使NuRisk成为推动自动驾驶推理能力发展的重要基准。
FuncPoison:用于劫持多智能体自动驾驶系统的中毒函数库攻击
- 龙宇振、李松泽
- 出版单位:加州大学洛杉矶分校
- 发表日期:2025年9月29日
- 任务:规划
- 摘要:
- 介绍了一种新型的基于中毒的攻击方法——FuncPoison,该方法针对由大语言模型驱动的多智能体自动驾驶系统中的共享函数库,通过注入恶意工具来操纵智能体行为,从而引发级联错误,导致系统轨迹精度下降。
- 攻击利用了基于文本的工具选择机制及标准化命令格式中的漏洞,成功演示了其规避防御的能力,并强调函数库是系统可靠性方面一个关键但尚未充分探索的攻击面。
-
- 杨盛、詹彤、陈冠成、陆延峰、王健
- 发表日期:2025年9月29日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 介绍了一种名为Max-V1的新颖单阶段端到端自动驾驶框架,该框架将驾驶重新概念化为一种广义的语言,并将轨迹规划表述为下一航点预测。
- 提出了一种单次生成范式,利用视觉语言模型(VLM)直接从前视摄像头输入预测轨迹,并由基于统计建模的原则性策略进行监督。
- 在nuScenes数据集上实现了最先进的性能,提升了30%以上,同时通过大规模专家示范的模仿学习,展现了强大的泛化能力和跨车型的鲁棒性。
学习采样:强化学习引导的采样方法在自动驾驶车辆运动规划中的应用
- 科尔比尼安·莫勒、罗兰·斯特鲁普、马蒂亚·皮奇尼尼、亚历山大·朗曼、约翰内斯·贝茨
- 出版单位:慕尼黑工业大学(TUM)
- 发表日期:2025年9月29日
- 代码:Learning-to-Sample
- 任务:规划
- 数据集:CommonRoad
- 摘要:
- 提出了一种混合式的基于采样的运动规划框架,利用强化学习智能体引导采样向行动空间中有希望的区域集中,同时保持轨迹生成和评估过程的分析性和可验证性。
- 将强化学习采样器与基于可解码深度集合编码器的世界模型相结合,以处理不同数量的交通参与者,并重建潜在表示。
- 在CommonRoad上的评估显示,所需样本数量减少了高达99%,运行时间缩短了84%,同时保持了规划的成功率和无碰撞率。
-
- 弗朗切斯科·马尔基奥里、罗汉·辛哈、克里斯托弗·阿吉亚、亚历山大·罗比、乔治·J·帕帕斯、毛罗·孔蒂、马尔科·帕沃内
- 出版单位:帕多瓦大学、斯坦福大学、宾夕法尼亚大学
- 发表日期:2025年9月27日
- 项目页面:J-DAPT
- 任务:规划
- 数据集:Waymo开放数据集、nuScenes
- 摘要:
- 介绍了一种轻量级的多模态越狱检测框架——J-DAPT,它利用基于注意力的融合技术和域适应技术,在机器人环境中实现越狱行为的检测。
- 通过整合文本和视觉嵌入,捕捉语义意图和环境背景,将通用越狱数据与领域特定参考对齐。
- 在自动驾驶、海洋机器人和四足机器人导航等场景下的评估表明,J-DAPT能够在极低开销下将检测准确率提升至接近100%。
-
- 陈冠成、杨盛、詹通、王健
- 发表日期:2025年9月27日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 介绍BEV-VLM框架,该框架利用视觉-语言模型,并以鸟瞰图特征图为视觉输入,用于轨迹规划。
- 使用融合多模态传感器数据得到的统一BEV-HD地图格式,实现几何一致的场景描述。
- 在nuScenes数据集中,规划精度提升44.8%,并完全避免了碰撞。
MTRDrive:面向边缘场景的鲁棒自动驾驶的记忆—工具协同推理
- 罗子昂、钱康安、王嘉华、罗悦辰、苗金宇、傅正、王云龙、蒋思聪、黄子林、胡一飞、杨宇浩、叶浩、杨梦梦、董晓健、姜坤、杨典歌
- 发表日期:2025年9月25日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- 提出MTRDrive框架,将程序化驾驶经验与动态工具箱相结合,以增强端到端自动驾驶的泛化能力和主动决策能力。
- 设计了一个闭环系统,将基于记忆的经验检索机制与动态工具箱结合,从而提升推理与决策能力。
- 在NAVSIM基准测试中达到最先进水平,并在新的Roadwork-VLM基准测试中展现出强大的零样本泛化能力。
-
- 孔德宏、于思凡、梁思远、梁家伟、甘建厚、刘爱珊、任文琪
- 发表日期:2025年9月24日
- 任务:端到端
- 摘要:
- 首次提出适用于自动驾驶视觉-语言模型的通用伪装攻击(UCA)框架,生成可在物理世界中实现且对不同指令和模型架构具有泛化性的伪装纹理。
- 引入针对编码器和投影层漏洞的特征发散损失(FDL),并采用多尺度学习策略,以提高在真实场景中对视角和尺度变化的鲁棒性。
- 攻击效果显著,在多种VLM-AD模型上均能诱导错误的驾驶指令,性能大幅超越现有方法,且在多样化的动态条件下仍保持高度稳健。
-
- 李鹏翔、郑义楠、王岳、王慧敏、赵航、刘静静、战宪元、战坤、郎贤鹏
- 发表日期:2025年9月24日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- 介绍ReflectDrive框架,该框架基于学习方法,通过离散扩散集成反射机制来生成安全轨迹,以解决视觉-语言-动作模型中模仿学习的局限性。
- 提出一种安全感知的反射机制,无需梯度计算即可进行迭代自我修正,利用局部搜索识别不安全标记,并通过修复填充技术生成安全锚点。
- 在NAVSIM基准测试中评估,结果表明其在自动驾驶系统的安全关键轨迹生成方面具有显著优势。
编排、生成、反思:基于VLM的多智能体协作框架用于自动驾驶策略学习
- 彭增奇、谢宇森、王宇斌、杨锐、陈启峰、马军
- 发表日期:2025年9月21日
- 任务:规划
- 数据集:CARLA
- 摘要:
- 提出OGR框架,这是一种新颖的自动驾驶策略学习框架,利用基于视觉-语言模型的多智能体协作系统自动设计奖励函数和训练课程。
- 引入一个包含编排、生成和反思模块的分层智能体系统,并辅以记忆模块和人机协作的并行生成方案,以促进策略的稳健演化。
- 实验表明,该框架在CARLA的城市场景中表现出色,具有广泛的适用性和与多种强化学习算法的兼容性,实际道路试验也验证了其可行性。
-
- 陈欣、何佳、李茂政、徐东亮、王天宇、陈一骁、林志新、姚悦
- 发表日期:2025年9月20日
- 任务:VQA
- 摘要:
- 系统性评估视觉-语言模型(VLM)在道路拓扑理解方面的能力,这是安全自动驾驶的关键要求。
- 基于鸟瞰图车道表示,提出了四个诊断性VQA任务,以捕捉空间拓扑推理的核心要素。
- 研究发现,空间推理仍然是当前VLM的基本瓶颈,其性能与模型规模、推理标记长度以及提供的示例数量密切相关。
CoReVLA:基于收集与精炼的双阶段端到端自动驾驶框架,用于长尾场景
- 方世宇、崔一鸣、梁浩洋、吕晨、韩鹏、孙健
- 发表日期:2025年9月19日
- 代码:CoReVLA
- 任务:端到端
- 数据集:Bench2Drive
- 摘要:
- CoReVLA是一个持续学习的端到端自动驾驶框架,通过数据收集和行为精炼的双阶段流程,提升在长尾、安全关键场景中的表现。
- 该框架首先在驾驶问答数据上进行微调,随后在CAVE仿真环境中收集驾驶员接管数据,并通过直接偏好优化(DPO)进一步精炼,以学习人类偏好并避免奖励欺骗。
- 在Bench2Drive基准测试中,CoReVLA获得了72.18分的驾驶评分和50%的成功率,优于现有的长尾场景解决方案。
AdaThinkDrive:基于强化学习的自适应思维用于自动驾驶
- 罗悦晨、李芳、徐绍青、赖志毅、杨磊、陈启茂、罗子昂、谢子轩、蒋圣寅、刘佳鑫、陈龙、王兵、杨志新
- 发表日期:2025年9月17日
- 任务:端到端
- 数据集:NAVSIM
- 摘要:
- AdaThinkDrive是一种新颖的视觉-语言-动作(VLA)框架,具备双模推理机制(快速回答与慢速思考),用于自动驾驶中的自适应推理。
- 引入了自适应思考奖励策略,并结合分组相对策略优化(GRPO),以奖励模型有选择地应用思维链(CoT)推理。
- 在Navsim基准测试中取得了最先进的性能(PDMS为90.3),同时相比始终进行推理的基线模型,推理时间减少了14%。
-
- 戴伟、吴生根、吴伟、王振浩、吕思硕、廖海成、于利民、丁卫平、关润威、岳宇涛
- 发表日期:2025年9月11日
- 任务:预测
- 摘要:
- 对大型基础模型(LFMs),包括大语言模型(LLM)和多模态大语言模型(MLLM),在自动驾驶轨迹预测中的系统性综述,强调其在实现可解释上下文推理方面的作用。
- 涵盖了核心方法学,如轨迹-语言映射、多模态融合和基于约束的推理,以及相关任务、指标、数据集和关键挑战。
- 讨论了未来的研究方向,如低延迟推理、因果感知建模和运动基础模型。
DepthVision:基于GAN的LiDAR转RGB合成技术赋能鲁棒视觉-语言模型,用于自动驾驶
- 斯文·基希纳、尼尔斯·普尔施克、罗斯·格里尔、阿洛伊斯·C·克诺尔
- 出版单位:慕尼黑工业大学
- 发表日期:2025年9月9日
- 任务:感知
- 摘要:
- DepthVision是一个多模态框架,无需架构改动或重新训练,即可通过将稀疏的LiDAR点云合成出密集的类似RGB的图像,使视觉-语言模型(VLM)能够利用LiDAR数据。
- 引入了亮度感知模态适配(LAMA)模块,该模块根据环境光照动态加权融合合成图像和真实相机图像,以补偿黑暗或运动模糊等退化情况。
- 该设计使LiDAR在RGB不可靠时成为即插即用的视觉替代品,扩展了现有VLM的运行范围。评估表明,在低光照场景理解方面,相比仅使用RGB的基线模型有显著提升。
-
- 刘瑞勋、孔凌宇、李德润、赵航
- 发表日期:2025年9月6日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- 提出OccVLA框架,将3D占用表示整合到自动驾驶的多模态推理中,既作为预测输出,也作为监督信号。
- 无需显式3D输入或额外的推理开销,即可从2D视觉输入中学习精细的空间结构,因为占用预测可以被跳过。
- 在nuScenes上实现了轨迹规划的最先进结果,并在3D视觉问答任务中表现出色。
LatticeWorld:由多模态大语言模型驱动的交互式复杂世界生成框架
- 段英林、邹正霞、顾通伟、贾伟、赵展、许路易、刘新竹、林业楠、江浩、陈康、邱爽
- 发表日期:2025年9月5日
- 项目页面:演示视频
- 任务:生成
- 摘要:
- LatticeWorld是一个3D世界生成框架,利用轻量级大语言模型(LLaMA-2-7B)和虚幻引擎5,根据多模态文本和视觉指令创建大规模交互式世界。
- 该框架简化了工业级3D环境制作流程,效率提升了90倍以上,同时保持了与传统手动方式相当的高质量创意产出。
-
- 曹卓、史云霄、徐敏
- 发表日期:2025年9月3日
- 任务:预测
- 摘要:
- 介绍SAM-LLM混合架构,将大语言模型(LLM)的上下文推理能力与运动学正弦加速度模型(SAM)的物理精确性相结合,用于自动驾驶轨迹预测。
- 针对变道场景,模型输出可解释的物理参数(如横向位移、持续时间),而非原始坐标,从而生成连续且合理的轨迹,输出规模比基于坐标的方案减少了80%。
- 实现了98.73%的意图预测准确率,达到最先进的水平,与传统LLM预测器相当,同时提供了更优的可解释性和计算效率。
-
- 王宇金、王天一、刘泉峰、范文贤、焦俊峰、克里斯蒂安·克劳德尔、严云兵、高炳照、王建强、陈宏
- 发表日期:2025年9月3日
- 任务:预测
- 数据集:nuScenes
- 摘要:
- KEPT是一个知识增强型VLM框架,可直接从连续的前视驾驶帧中预测本车轨迹。
- 集成了时序频率-空间融合视频编码器与k-means及HNSW检索增强生成流水线,利用检索到的知识在思维链提示中结合规划约束。
- 采用三阶段微调范式对VLM骨干网络进行对齐,在nuScenes上实现了最先进的开环性能。
-
- 王明义、王景科、叶腾驹、陈俊博、俞凯成
- 发表日期:2025年9月2日
- 任务:预测
- 数据集:Waymo Sim Agents
- 摘要:
- 对五种关键的大语言模型模块在自动驾驶运动规划中的迁移能力进行了全面评估,包括分词器设计、位置嵌入、预训练范式、后训练策略以及推理时的计算方法。
- 结果表明,经过适当调整的大语言模型模块能够显著提升在Waymo Sim Agents基准上的性能,达到具有竞争力的水平。
- 研究还识别出哪些技术可以有效迁移,分析了失败的原因,并讨论了针对自动驾驶领域所需的必要调整。
CVPR2024端到端挑战赛亚军方案:基于视觉语言模型的端到端自动驾驶
- 郭子龙、罗毅、沙龙、王东旭、王攀渠、徐晨阳、杨毅
- 发表日期:2025年9月2日
- 任务:端到端
- 摘要:
- 提出了一种仅使用摄像头的端到端自动驾驶解决方案,将架构设计与视觉语言模型(VLM)相结合,在CVPR2024端到端挑战赛中获得第二名。
- 实验证明,将具备丰富知识的视觉语言模型融入端到端框架能够带来出色的性能,凸显了基于视觉的方法在驾驶任务中的潜力。
OmniReason:面向自动驾驶的时序引导型视觉-语言-行动框架
- 刘沛、宁青天、陆欣妍、刘海鹏、马伟良、佘丹根、贾鹏、郎贤鹏、马军
- 发表日期:2025年8月31日
- 任务:推理
- 摘要:
- OmniReason是面向自动驾驶的时序引导型视觉-语言-行动(VLA)框架,通过联合建模动态3D环境与决策过程,实现强大的时空推理能力。
- 提出了OmniReason-Data大规模VLA数据集,该数据集采用抗幻觉自动标注流水线生成密集的时空标注,确保物理合理性和时间一致性。
- 开发了OmniReason-Agent架构,配备稀疏时序记忆模块和解释生成器,利用时空知识蒸馏捕捉因果推理模式,从而实现可解释且具备时间感知的驾驶行为。
DrivingGaussian++:迈向周围动态驾驶场景的真实重建与可编辑仿真
- 熊亚娇、周晓宇、万永涛、孙德清、杨明轩
- 发表日期:2025年8月28日
- 项目页面:DrivingGaussian++
- 任务:生成
- 摘要:
- DrivingGaussian++是一个高效的框架,用于对周围动态自动驾驶场景进行真实重建和可控编辑。它采用增量式3D高斯分布表示静态背景,并用复合动态高斯图结构处理移动物体。
- 集成了激光雷达先验信息,以实现细节丰富且一致的场景重建;同时,借助多视角图像、深度先验以及大语言模型(LLM)生成的运动轨迹,支持无需训练即可进行纹理、天气和物体操作等可控编辑。
-
- 丁帆、罗雪文、许慧慧、鲁图拉吉·雷迪、王锡坤、卢俊勇
- 发表日期:2025年8月23日
- 任务:规划
- 数据集:nuPlan
- 摘要:
- 提出了一种基于扩散的多头轨迹规划器(M-diffusion planner),并结合群体相对策略优化(GRPO)对其进行微调,以学习多样化的特定于不同策略的驾驶行为。
- 推理阶段引入大语言模型(LLM),用于指导策略选择,实现动态且指令感知的规划,而无需切换模型。
- 在nuPlan基准上达到了最先进的性能,生成的轨迹展现出明显的多样性,能够满足多模式驾驶需求。
Prune2Drive:用于加速自动驾驶中视觉-语言模型的即插即用框架
- 雄明浩、文子辰、顾壮成、刘旭阳、张睿、康恒瑞、杨嘉兵、张俊远、李伟佳、何聪辉、王亚飞、张林峰
- 发表日期:2025年8月18日
- 任务:端到端
- 数据集:DriveLM、DriveLMM-o1
- 摘要:
- Prune2Drive 是一种用于自动驾驶多视角 VLM 的即插即用视觉令牌剪枝框架,旨在解决高分辨率多视角图像带来的计算开销问题。
- 提出了一种受最远点采样启发的多样性感知令牌选择机制,以及视图自适应剪枝控制器,以学习每路摄像头的最佳剪枝比例。
- 在保持 DriveLM 和 DriveLMM-o1 基准上任务性能的同时,实现了显著的速度提升和内存节省(例如,速度提升 6.40 倍,仅保留 10% 的令牌即可降至原 FLOPs 的 13.4%)。
-
- 崔灿、周宇鹏、彭俊通、朴成妍、杨子冲、普拉桑特·桑卡拉纳拉扬、张嘉如、张汝琪、王子然
- 发表日期:2025年8月18日
- 任务:端到端
- 数据集:nuScenes
- 摘要:
- 提出了 ViLaD,一种新颖的大型视觉语言扩散(LVLD)框架,用于端到端自动驾驶。该框架采用掩码扩散模型并行生成驾驶决策,从而降低延迟。
- 该框架支持双向推理和渐进式的“先易后难”生成策略,在 nuScenes 数据集上,其规划准确性和速度均优于自回归 VLM 基线。
- 通过在一辆自动驾驶汽车上进行交互式泊车任务的实际部署,证明了其可行性,并实现了接近零的失败率。
-
- 宋楠、张博洲、朱夏天、邓建康、张莉
- 发表日期:2025年8月17日
- 任务:端到端
- 数据集:DriveLM、nuScenes-QA
- 摘要:
- 提出了 LMAD,一种新型的自动驾驶视觉-语言框架,它模仿现代端到端范式,具备全面的场景理解能力和任务专用的 VLM 结构。
- 在驾驶任务结构中引入了初步的场景交互模块和专门的专家适配器,以更好地使 VLM 与自动驾驶场景相契合。
- 该方法设计为完全兼容现有 VLM,并能无缝集成到以规划为导向的驾驶系统中,为可解释性自动驾驶设定了新标准。
VISTA:模拟情境思维与注意力的视觉-语言模型,实现动态环境中类人驾驶员的专注力
- 凯撒·哈米德、坎达卡尔·阿什拉菲·阿克巴尔、梁娜德
- 发表日期:2025年8月7日
- 任务:感知
- 数据集:BDD-A
- 摘要:
- 这是一个视觉-语言框架,通过自然语言建模驾驶员的视线转移行为,利用单张 RGB 图像进行少样本和零样本学习。
- 在精选的 BDD-A 字幕数据上微调 LLaVA,使视觉感知与以注意力为中心的场景理解对齐,整合低层次线索和自上而下的上下文信息。
- 以自然语言形式生成驾驶员视觉注意力分配及转移的预测结果,为自动驾驶中的可解释人工智能提供了新的方向。
-
- 蒋安庆、高宇、王怡茹、孙志刚、王硕、衡雨文、孙浩、唐世臣、朱丽娟、柴金浩、王继军、顾子冲、江浩、孙莉
- 发表日期:2025年8月7日
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- IRL-VLA 是一种新颖的闭环强化学习框架,用于自动驾驶,采用逆向强化学习奖励世界模型结合视觉-语言-行动(VLA)策略。
- 该框架采用三阶段范式:首先通过模仿学习预训练 VLA 架构,然后利用 IRL 构建轻量级奖励世界模型,最后通过专门的 PPO 强化学习进一步优化规划。
- 在 NAVSIM v2 端到端驾驶基准测试中取得了最先进的性能,并在 CVPR2025 自动驾驶大挑战中获得亚军。
LiDARCrafter:从 LiDAR 序列中动态构建 4D 世界模型
- 梁傲、刘友泉、杨宇、陆东岳、李林峰、孔令东、赵怀慈、黄伟昌
- 发表日期:2025年8月5日
- 任务:生成
- 数据集:nuScenes
- 摘要:
- LiDARCrafter 是一个统一的框架,能够根据自由格式的自然语言指令生成和编辑 4D LiDAR 数据,将指令解析为以自我为中心的场景图,并以此作为条件输入到三分支扩散网络中。
- 该框架包含一个自回归模块,用于生成时间上连贯的 4D LiDAR 序列,并建立了涵盖场景、物体和序列层面指标的综合基准,用于标准化评估。
用于细粒度交通标志的Mapillary Vistas验证集:揭示视觉-语言模型局限性的基准测试
- 斯帕什·加格、阿比谢克·艾奇
- 出版商:美国NEC实验室
- 发表日期:2025年8月4日
- 代码:relabeling
- 任务:感知
- 数据集:Mapillary Vistas
- 摘要:
- 提出一个新的细粒度交通标志验证集——Mapillary Vistas交通标志验证集(MVV),该数据集包含像素级实例掩码和专家标注。
- 将视觉-语言模型与DINOv2进行对比基准测试,结果显示DINOv2在细粒度识别以及车辆、人类等其他类别上的表现更优。
- 揭示了当前视觉-语言模型在细粒度视觉理解方面的显著局限性,并将DINOv2确立为自动驾驶感知任务中的强大基线。
Bench2ADVLM:面向自动驾驶的视觉-语言模型闭环基准测试
- 张天元、金婷、王璐、刘江帆、梁思远、张明川、刘爱珊、刘向龙
- 发表日期:2025年8月4日
- 任务:评估
- 摘要:
- Bench2ADVLM是一个统一的分层闭环评估框架,用于在仿真和物理平台中对自动驾驶领域的视觉-语言模型进行实时、交互式评估。
- 引入了针对仿真的双系统适配架构和物理控制抽象层,以弥合仿真与现实之间的差距,从而实现在真实车辆上的闭环测试。
- 具备自我反思的场景生成模块,可自动探索模型行为并发现潜在故障模式,以生成安全关键场景。
-
- 亨特·斯科菲尔德、穆罕默德·埃尔马胡吉比、卡斯拉·雷扎伊、山金俊
- 出版商:约克大学
- 发表日期:2025年8月3日
- 任务:评估
- 数据集:Waymo开放数据集
- 摘要:
- 提出了新的指标来评估世界模型作为交通仿真器的鲁本性,特别是其作为策略训练的伪环境的能力。
- 将Waymo开放模拟智能体挑战赛(WOSAC)的评估范围扩展至包括与自车存在因果关系的智能体,揭示了顶级模型在轨迹回放条件下失效的场景。
- 基于这些新指标分析了最先进的世界模型,以评估其对不可控对象的敏感性及是否适合用于策略训练。
基于边缘的多模态传感器数据融合与视觉-语言模型(VLMs)结合,用于自动驾驶车辆的实时避撞
- 杨峰泽、于博、周洋、罗学文、涂正中、刘晨曦
- 发表日期:2025年8月1日
- 任务:规划
- 数据集:DeepAccident
- 摘要:
- 提出REACT,一个基于微调轻量级视觉-语言模型(VLM)的实时V2X集成轨迹优化框架,用于自动驾驶。
- 将基础设施危险预警与车载传感器数据相结合,利用视觉嵌入和上下文推理生成安全导向的轨迹。
- 采用残差轨迹融合(RTF)和边缘适应策略实现高效部署,在DeepAccident基准测试中达到最先进的性能。
-
- 张毅、埃里克·利奥·哈斯、曹国义、内纳德·彼得罗维奇、宋英雷、吴成东、阿洛伊斯·克诺尔
- 出版商:慕尼黑工业大学
- 发表日期:2025年7月31日
- 任务:规划
- 摘要:
- 提出了一个统一的感知-语言-行动(PLA)框架,将多传感器融合与LLM增强的视觉-语言-行动架构相结合,用于自动驾驶。
- 该框架配备GPT-4.1驱动的推理核心,将感知与自然语言理解相结合,实现情境感知、可解释且安全约束下的决策。
- 在复杂城市场景中,如施工区域的交叉路口,表现出优越的轨迹跟踪、速度预测和自适应规划性能。
FastDriveVLA:通过即插即用的重建式标记剪枝实现高效的端到端驾驶
- 曹佳俊、张启哲、贾培东、赵旭辉、兰波、张晓安、李卓、魏小宝、陈思翔、李云燕、刘贤明、卢明、王阳、张尚航
- 发表日期:2025年7月31日
- 任务:端到端
- 数据集:nuScenes
- 摘要:
- FastDriveVLA是一个新颖的基于重建的视觉标记剪枝框架,专为自动驾驶设计。它包含一个名为ReconPruner的即插即用视觉标记剪枝器,该剪枝器通过MAE风格的像素重建优先处理前景信息。
- 引入了一种对抗性的前景-背景重建策略来训练ReconPruner,并创建了一个新的大规模数据集nuScenes-FG,其中包含24.1万张带有前景区域标注的图像-掩码对。
- 在nuScenes开环规划基准测试中,不同剪枝比例下均取得了最先进的结果,通过降低VLA模型中长视觉标记的计算成本,实现了高效的端到端驾驶。
-
- 杨一鸣、林洪斌、罗悦如、傅苏忠、郑超、闫欣睿、梅淑琪、唐坤、崔书光、李振
- 发表日期:2025年7月31日
- 任务:感知、推理
- 数据集:OpenLane-V2
- 摘要:
- FASTopoWM是一个新颖的快慢车道段拓扑推理框架,通过潜在世界模型增强,以实现全面的BEV道路场景理解。
- 该框架能够并行监督历史查询和新查询,以减少姿态估计失败的影响;同时引入潜在查询和BEV世界模型,以提升时间维度上的感知能力。
- 在OpenLane-V2基准测试中,该框架在车道段检测和中心线感知方面表现出最先进的性能。
-
- 桑托什·帕塔帕蒂、特里桑斯·斯里尼瓦桑、穆拉里·安巴蒂
- 发表日期:2025年7月30日
- 任务:端到端
- 数据集:MD-NEX户外驾驶
- 摘要:
- XYZ-Drive是一套用于自动驾驶的单模态视觉-语言模型,能够读取前视摄像头画面、俯视地图和目标点信息,输出转向和速度指令。
- 它采用轻量级的目标导向交叉注意力层,在使用微调后的LLaMA-3.2 11B模型进行处理之前,融合目标点、图像和地图特征。
- 该模型在MD-NEX基准测试中取得了95%的成功率,超越了现有方法;消融实验进一步证实了各模态及融合机制的重要性。
SafeDriveRAG:基于知识图谱检索增强生成的安全自动驾驶
- 叶浩、齐梦实、刘兆宏、刘亮、马华东
- 发表日期:2025年7月29日
- 代码:SafeDriveRAG
- 任务:VQA
- 数据集:SafeDrive228K
- 摘要:
- 提出了SafeDrive228K,这是一个大规模多模态VQA基准,包含228,000个示例,覆盖18个子任务,用于评估驾驶场景中的交通安全理解能力。
- 介绍了一种即插即用的多模态知识图谱检索增强生成(RAG)框架,并配备了多尺度子图检索算法。
- 实验证明,该RAG框架显著提升了五种主流VLM在安全关键任务上的性能。
DriveAgent-R1:通过主动感知与混合思维推进基于VLM的自动驾驶
- 郑伟成、毛晓飞、叶南飞、李鹏翔、詹坤、郎献鹏、赵航
- 发表日期:2025年7月28日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- DriveAgent-R1是首个具备主动感知功能的自动驾驶规划智能体,它会主动调用视觉推理工具,以视觉证据为基础做出决策。
- 引入了一种混合思维框架,可根据场景复杂度自适应地在纯文本推理和工具辅助的视觉推理之间切换。
- 采用三阶段渐进式训练策略,核心为级联强化学习阶段,在Drive-Internal和nuScenes数据集上以30亿参数实现了具有竞争力的性能。
VESPA:迈向无人(类人)监督的开放世界点云标注,用于自动驾驶
- 莱文特·滕普夫利、埃斯特班·里韦拉、马库斯·连坎普
- 出版单位:慕尼黑工业大学
- 发表日期:2025年7月27日
- 任务:感知
- 数据集:nuScenes
- 摘要:
- VESPA是一个多模态自动标注流水线,将LiDAR几何信息与相机语义信息融合,从而在无需真值或高精地图的情况下实现可扩展的3D伪标签生成。
- 利用视觉-语言模型(VLM)直接在点云域内进行开放词汇的物体标注与检测优化,支持新类别发现。
-
- 唐志鹏、张莎、邓家俊、王晨杰、游国梁、黄玉婷、林欣睿、张燕勇
- 发表日期:2025年7月27日
- 任务:规划
- 数据集:nuPlan
- 摘要:
- VLMPlanner是一个混合框架,将基于学习的实时规划器与视觉-语言模型(VLM)结合,后者通过对原始多视角图像进行推理来生成鲁棒的轨迹。
- 引入了上下文适应性推理门控(CAI-Gate),可根据场景复杂度动态调整VLM的推理频率,从而在性能与计算效率之间取得平衡。
- 在nuPlan基准上进行了评估,结果表明其在道路条件复杂且存在动态元素的场景中表现出更优的规划能力。
-
- 费利克斯·布兰德施泰特、埃里克·舒茨、卡塔琳娜·温特、法比安·弗洛尔
- 发表日期:2025年7月25日
- 任务:感知
- 数据集:nuCaption、nuView、GroundView
- 摘要:
- BEV-LLM是一种用于自动驾驶3D场景描述的轻量级模型,利用BEVFusion将LiDAR数据和多视角图像结合,并引入了一种新颖的绝对位置编码。
- 在nuCaption数据集上取得了具有竞争力的性能,BLEU分数相比最先进方法最高提升了5%,且仅使用了一个10亿参数的小型基础模型。
- 同时提出了并评测了两个新的数据集——nuView和GroundView,以更好地评估不同驾驶场景下的场景描述能力和目标定位精度。
BetterCheck:迈向保障汽车感知系统中VLMs的安全性
- 马尔沙·阿沙尼·马哈瓦塔·多纳、贝亚特丽斯·卡布雷罗-丹尼尔、于一楠、克里斯蒂安·贝格尔
- 出版单位:哥德堡大学
- 发表日期:2025年7月23日
- 任务:感知
- 数据集:Waymo开放数据集
- 摘要:
- 提出了BetterCheck方法,用于检测视觉-语言模型(VLM)中的幻觉现象,以保障其在汽车感知系统中的安全性。
- 系统性地评估了3种最先进的VLM在Waymo开放数据集中的多种交通场景下的表现,发现它们虽然具备较强的场景理解能力,但仍易产生幻觉。
VLM-UDMC:面向城市自动驾驶的VLM增强型统一决策与运动控制
- 刘海超、郭浩然、刘沛、马本善、张宇翔、马军、李同恒
- 发表日期:2025年7月21日
- 代码:VLM-UDMC
- 任务:规划
- 摘要:
- 提出了VLM-UDMC框架,这是一种基于视觉-语言模型的城市自动驾驶统一决策与运动控制方案,融入了场景推理和风险感知洞察。
- 该框架采用两步推理策略,在上层慢速系统中运用检索增强生成(RAG),根据实时环境变化动态调整运动规划。
- 使用轻量级多核分解LSTM对交通参与者进行实时轨迹预测,并通过仿真和实际道路试验验证了该框架的有效性。
AGENTS-LLM:基于智能体LLM框架的挑战性交通场景增强生成
- 作者:Yao Yu、Salil Bhatnagar、Markus Mazzola、Vasileios Belagiannis、Igor Gilitschenski、Luigi Palmieri、Simon Razniewski、Marcel Hallgarten
- 发表日期:2025年7月18日
- 任务:规划
- 摘要:
- 提出了一种新颖的基于LLM智能体的框架,利用自然语言描述来增强现实世界中的交通场景,从而为自动驾驶规划器生成具有挑战性的测试用例。
- 采用智能体设计,实现对场景生成的精细控制,并能够在较小且经济高效的LLM上保持高性能,避免了对海量数据集或人工专家标注的依赖。
-
- 作者:Guan Yanchen、Liao Haicheng、Wang Chengyue、Liu Xingcheng、Zhang Jiaxun、Li Zhenning
- 发表日期:2025年7月17日
- 任务:生成
- 数据集:新基准数据集
- 摘要:
- 提出了一种将场景生成增强与自适应时间推理相结合的框架,以可靠地预测事故,解决数据稀缺和缺失物体级线索的问题。
- 开发了一个由领域知识驱动的提示引导的世界模型视频生成流水线,用于创建高分辨率且统计一致的驾驶场景,从而丰富边缘案例。
- 构建了一个动态预测模型,结合强化的图卷积和扩张时间算子来处理数据不完整性和视觉噪声问题,并发布了一个新的基准数据集。
-
- 作者:Lu Yuhang、Tu Jiadong、Ma Yuexin、Zhu Xinge
- 出版单位:4DV实验室
- 发表日期:2025年7月16日
- 项目页面:ReAL-AD
- 任务:端到端
- 摘要:
- 提出了ReAL-AD框架,即一种基于人类认知三层模型——驾驶策略、驾驶决策和驾驶操作——构建的推理增强学习框架。
- 集成视觉-语言模型(VLM)以提升态势感知能力,并引入战略推理注入器、战术推理集成器以及层次化轨迹解码器,实现分层推理和轨迹执行。
- 大量评估表明,该框架可将规划准确性和安全性提高30%以上,使端到端自动驾驶更具可解释性,并更贴近人类的推理方式。
VisioPath:视觉-语言增强的模型预测控制用于混合交通中的安全自主导航
- 作者:Wang Shanting、Typaldos Panagiotis、Li Chenjun、Malikopoulos Andreas A.
- 发表日期:2025年7月8日
- 任务:规划
- 数据集:SUMO
- 摘要:
- 提出了一种将视觉-语言模型(VLM)与模型预测控制(MPC)相结合的新框架,用于在动态交通环境中实现安全的自动驾驶。
- 利用鸟瞰视角管道和零样本VLM提取结构化的车辆信息,构建椭圆形避撞势场进行轨迹规划。
- 实现了一个通过微分动态规划求解的有限时域最优控制问题,并采用自适应正则化和事件触发的MPC循环,同时包含安全验证层。
-
- 作者:Zhang Yuhang、Liu Jiaqi、Xu Chengkai、Hang Peng、Sun Jian
- 发表日期:2025年7月8日
- 任务:规划
- 数据集:CARLA
- 摘要:
- LeAD是一种双速率自动驾驶架构,将基于模仿学习的端到端框架与大型语言模型(LLM)增强相结合,以提升场景理解和决策能力。
- 系统采用高频E2E子系统进行实时循环,而低频LLM模块则利用多模态感知融合和思维链推理来处理复杂场景和边缘情况。
-
- 作者:Li Siyu、Teng Fei、Cao Yihong、Yang Kailun、Li Zhiyong、Wang Yaonan
- 发表日期:2025年7月5日
- 代码:NRSeg
- 任务:感知
- 摘要:
- 提出了NRSeg框架,这是一种基于驾驶世界模型生成的合成数据,用于BEV语义分割的抗噪学习。
- 引入了透视几何一致性度量(PGCM)来评估生成数据的指导能力,并设计了一个双分布并行预测模块(BiDPP)以增强模型的鲁棒性。
- 在无监督和半监督的BEV语义分割任务中,mIoU分别提升了13.8%和11.4%,达到了当前最先进的水平。
FMOcc:基于TPV驱动流匹配的三维占用预测,采用选择性状态空间模型
- 陈江霞、黄通远、宋科
- 发表日期:2025年7月3日
- 任务:预测
- 数据集:Occ3D-nuScenes、OpenOcc
- 摘要:
- 提出FMOcc,一种结合流匹配选择性状态空间模型的三视角(TPV)精炼占用网络,用于少帧数的3D占用预测。
- 引入流匹配SSM模块(FMSSM)以生成缺失特征,并设计带有平面选择性SSM(PS3M)的TPV SSM层,对TPV特征进行选择性过滤,从而提升效率并改善远距离场景的预测效果。
- 设计掩码训练(MT)方法,增强对传感器数据丢失的鲁棒性,在Occ3D-nuScenes和OpenOcc数据集上取得当前最优结果。
VLAD:基于VLM增强的分层规划与可解释决策过程的自动驾驶框架
- 克里斯蒂安·加里博尔迪、时田隼人、金城健、浅田优希、亚历山大·卡巴略
- 发表日期:2025年7月2日
- 任务:端到端
- 数据集:nuScenes
- 摘要:
- VLAD是一种视觉-语言自动驾驶模型,将微调后的VLM与VAD端到端系统集成,利用自定义问答数据集增强空间推理能力。
- 该系统能够生成高层导航指令,并为驾驶决策提供可解释的自然语言说明,从而提高透明度。
- 在nuScenes上的评估显示,相比基线方法,平均碰撞率降低了31.82%。
-
- 傅永杰、查瑞建、田培、狄轩
- 发表日期:2025年7月2日
- 任务:生成
- 数据集:CARLA
- 摘要:
- 提出一种新颖的框架,利用大型语言模型(LLM)进行少样本代码生成,自动在CARLA模拟器中合成多样且具有安全关键性的驾驶场景。
- 集成Cosmos-Transfer1与ControlNet的视频生成流水线,将渲染的仿真场景转换为逼真的驾驶视频,弥合了仿真与真实之间的外观差距。
- 能够可控地生成罕见的边缘场景,如被遮挡的行人横道或突然的车辆切入,用于自动驾驶车辆的仿真测试。
World4Drive:基于意图感知物理潜在世界模型的端到端自动驾驶
- 郑宇鹏、杨鹏轩、邢泽彬、张启超、郑宇航、高银峰、李鹏飞、张腾、夏仲璞、贾鹏、赵东斌
- 出版单位:中国科学院大学
- 发表日期:2025年7月1日
- 代码:World4Drive
- 任务:端到端
- 数据集:nuScenes、NAVSIM
- 摘要:
- World4Drive是一个端到端自动驾驶框架,利用视觉基础模型构建潜在世界模型,无需感知标注即可生成和评估多模态规划轨迹。
- 该框架提取场景特征和意图,生成轨迹,预测潜在空间中的未来状态,并通过自监督对齐的筛选模块选择最佳轨迹。
- 在nuScenes和NavSim基准测试中表现出色,L2误差和碰撞率显著降低,同时训练收敛速度更快。
当数字孪生遇见大型语言模型:面向自动驾驶的真实、交互式可编辑仿真
- 坦迈·维拉斯·萨马克、钦迈·维拉斯·萨马克、李冰、文卡特·克罗维
- 发表日期:2025年6月30日
- 任务:生成
- 摘要:
- 提出一个统一框架,用于创建高保真数字孪生,以加速自动驾驶研究,兼顾动力学保真度、照片级渲染、情境相关的场景编排以及实时性能。
- 利用基于物理和数据驱动的技术实现从现实到仿真重建,达到几何和照片级的精度,并为资产注入物理属性以支持实时动力学仿真。
- 集成大型语言模型(LLM)接口,可通过自然语言提示在线灵活编辑驾驶场景,展现出高度的结构相似性、帧率和提示处理能力。
StyleDrive:迈向驾驶风格感知的端到端自动驾驶基准测试
- 郝睿阳、景博文、于海宝、聂再青
- 发表日期:2025年6月30日
- 项目页面:StyleDrive
- 任务:评估
- 数据集:StyleDrive
- 摘要:
- 介绍首个大规模真实世界数据集,专为个性化端到端自动驾驶(E2EAD)而精心策划,通过微调的视觉-语言模型将场景拓扑与动态上下文及语义相结合。
- 提出混合标注流程,结合行为分析、启发式方法和VLM推理,并通过人机协作验证进行优化。
- 建立首个标准化基准,用于评估个性化E2EAD模型,表明融入驾驶偏好有助于提升行为与人类示范的一致性。
DriveMRP:利用合成运动数据增强视觉-语言模型以进行运动风险预测
- 侯志毅、马恩辉、李芳、赖志毅、何嘉乐、吴展谦、周立军、陈龙、孙驰天、孙海洋、王兵、陈光、叶航俊、俞凯成
- 发表日期:2025年6月28日
- 代码:DriveMRP
- 任务:预测
- 摘要:
- 提出DriveMRP方法,通过基于鸟瞰视角(BEV)的仿真技术合成高风险运动数据,从而增强视觉-语言模型(VLM)的运动风险预测能力。
- 提出了DriveMRP-Agent框架,采用一种新颖的信息注入策略,用于全局上下文、自我视角和轨迹投影,以提升空间推理能力。
- 实验表明,该方法在合成数据上的事故识别准确率从27.13%提升至88.03%,在零样本真实场景评估中则从29.42%提升至68.50%,性能显著提升。
基于案例推理增强大型语言模型的框架:用于现实安全关键驾驶场景下的决策
- 甘文斌、道明山、泽津浩二
- 出版单位:NICT、兵库大学
- 发表日期:2025年6月25日
- 任务:规划
- 摘要:
- 提出了一种基于案例推理增强大型语言模型(CBR-LLM)的框架,用于复杂且安全关键的驾驶场景中的规避动作决策。
- 将行车记录仪视频中的语义场景理解与相关过往驾驶案例的检索相结合,生成情境敏感且符合人类行为规范的动作建议。
- 在多个大型语言模型上均表现出更高的决策准确性、更优质的理由说明以及与人类专家的一致性;通过风险感知提示和基于相似性的案例检索进一步提升了性能。
-
- 王宇奇、李兴航、王文轩、张俊博、李英燕、陈云涛、王新龙、张兆祥
- 发表日期:2025年6月24日
- 任务:规划
- 数据集:CALVIN、LIBERO、Simplenv-Bridge、ALOHA
- 摘要:
- UniVLA是一种统一且原生的多模态VLA模型,能够自回归地将视觉、语言和动作信号建模为离散的标记序列,从而实现灵活的多模态任务学习。
- 在后训练阶段引入世界建模,以捕捉视频中的因果动态,促进向下游策略学习的有效迁移,尤其适用于长时程任务。
- 在仿真基准测试中取得了新的最先进成果(例如在LIBERO上达到95.5%的准确率),并在真实的ALOHA操作和自动驾驶任务中展现出广泛的适用性。
Drive-R1:利用强化学习在视觉-语言模型中弥合自动驾驶中的推理与规划
- 李悦、田萌、朱德昌、朱江通、林振宇、熊志伟、赵新海
- 发表日期:2025年6月23日
- 任务:规划
- 数据集:nuScenes、DriveLM-nuScenes
- 摘要:
- 提出Drive-R1,这是一种针对自动驾驶场景设计的领域特定视觉-语言模型,旨在连接场景推理与运动规划。
- 采用两阶段训练方法:首先在包含思维链推理的数据集上进行监督微调,随后通过强化学习使推理路径与规划结果相一致。
-
- 米希尔·戈博勒、高翔波、涂正中
- 出版单位:加州大学伯克利分校、密歇根大学
- 发表日期:2025年6月21日
- 任务:评估
- 数据集:DRAMA
- 摘要:
- 引入DRAMA-X,这是一个基于自动化标注流水线构建的细粒度基准测试,用于评估安全关键驾驶场景中的多类别意图预测和风险推理。
- 提出SGG-Intent轻量级无训练推理框架,该框架利用视觉-语言模型支持的场景图生成器和大型语言模型进行组合式推理,以完成目标检测、意图预测、风险评估及行动建议。
- 提供了对四个相互关联的自动驾驶任务的结构化评估,并证明基于场景图的推理能够提升意图和风险预测的准确性,尤其是在明确上下文建模的情况下。
-
- 曾凡志、王思琪、朱楚昭、李莉
- 发表日期:2025年6月17日
- 任务:规划
- 摘要:
- ADRD是一种新型框架,利用大型语言模型生成可执行的规则驱动决策系统,以实现可解释的自动驾驶。
- 该框架集成了三个核心模块:信息模块、代理模块和测试模块,用于迭代生成和优化驾驶策略。
- 相比传统的强化学习和先进的大型语言模型方法,ADRD在可解释性、响应速度和驾驶性能方面表现出色。
-
- 周宇鹏、崔灿、彭俊桐、杨子冲、陆俊武、潘查尔·吉特什、姚彬、王子然
- 出版单位:普渡大学
- 发表日期:2025年6月17日
- 任务:评估
- 摘要:
- 本文介绍了一种轻量级、结构化且低延迟的车载中间件流水线,并在封闭测试赛道上开发了一种可定制的真实世界交通场景形式。
AutoVLA:一种用于端到端自动驾驶的视觉-语言-动作模型,具备自适应推理与强化微调功能
- 周泽伟、蔡天辉、赵塞斯·Z、张云、黄志宇、周博磊、马佳琪
- 出版单位:加州大学洛杉矶分校
- 发表日期:2025年6月16日
- 项目页面:AutoVLA
- 代码:AutoVLA
- 任务:规划
- 数据集:nuPlan、nuScenes、Waymo、Bench2Drive(使用CARLA-Garage数据集进行训练)
- 摘要:
- AutoVLA是一个端到端自动驾驶框架,利用预训练的VLM骨干网络,并结合物理离散动作标记。
- 采用GRPO方法实现自适应推理,进一步提升模型在端到端驾驶任务中的性能。
-
- 佩德拉姆·莫哈杰尔安萨里、阿米尔·萨拉普尔、迈克尔·库尔、黄思宇、穆罕默德·哈马德、塞巴斯蒂安·施泰因霍斯特、哈比卜·奥卢福沃比、梅特·D·佩塞
- 出版单位:克莱姆森大学、慕尼黑工业大学、德克萨斯大学阿灵顿分校
- 发表日期:2025年6月13日
- 任务:感知
- 代码:V2LM
- 摘要:
- 本文介绍了车辆视觉语言模型(V2LMs),即专为自动驾驶感知任务微调过的VLM。
-
- 李永康、熊凯欣、郭向宇、李芳、闫思旭、徐刚伟、周利军、陈龙、孙海阳、王兵、陈光、叶航俊、刘文宇、王兴刚
- 出版单位:华中科技大学、小米电动车
- 发表日期:2025年6月9日
- 项目页面:ReCogDrive
- 代码:ReCogDrive
- 任务:规划
- 数据集:NAVSIM
- 摘要:
- ReCogDrive是一种新颖的强化认知框架,适用于端到端自动驾驶,包含一个视觉-语言模型(VLM)以及基于扩散的规划器,并通过强化学习进一步优化。
- ReCogDrive采用三阶段训练范式,首先进行驾驶预训练,随后进行模仿学习和GRPO强化学习,以提升视觉-语言-动作(VLA)系统的规划能力。
-
- 蒋浩、胡川、石宇康、何源、王科、张曦、张志鹏
- 出版单位:上海交通大学、KargoBot
- 发表日期:2025年6月5日
- 任务:视觉问答
- 数据集:nuScenes
- 摘要:
- 本文介绍了一个结构化且简洁的基准数据集NuScenes-S,它源自NuScenes数据集,包含机器友好的结构化表示。
-
- 调牧溪、杨乐乐、尹洪波、王哲旭、王业杰、田大鑫、梁孔明、马展宇
- 出版单位:北京邮电大学、中关村研究院、北京航空航天大学
- 发表日期:2025年5月27日
- 项目页面:DriveRX
- 任务:视觉问答
- 摘要:
- AutoDriveRL是一个统一的训练框架,将自动驾驶建模为一个涉及四个核心任务的结构化推理过程。每个任务都被独立地建模为视觉-语言问答问题,并使用特定于任务的奖励模型进行优化,从而在不同的推理阶段提供细粒度的强化信号。
- 在此框架下,训练出了DriveRX,这是一种专为实时决策设计的跨任务推理VLM。
WOMD-Reasoning:用于驾驶中交互推理的大规模数据集
- 李一恒、范存信、葛崇健、赵志豪、李晨然、许晨峰、姚华秀、富冢正义、周博磊、唐晨、丁明宇、詹伟 ICML 2025
- 出版单位:加州大学伯克利分校、加州大学洛杉矶分校、北卡罗来纳大学教堂山分校、德克萨斯大学奥斯汀分校
- 发表日期:2025年5月25日
- 代码:WOMD-Reasoning
- 数据集:Waymo开放运动数据集
- 任务:视觉问答
- 摘要:
- WOMD-Reasoning是一个基于Waymo开放运动数据集(WOMD)构建的语言标注数据集,专注于描述和推理驾驶场景中的交互与意图。
-
- 作者:奥古斯托·路易斯·巴拉迪尼、米格尔·安赫尔·索特洛
- 出版单位:阿卡拉大学
- 发表日期:2025年5月22日
- 任务:问答
- 摘要:
- 探讨如何利用大语言模型,将非正式的导航指令转化为结构化的逻辑推理规则,从而生成答案集编程规则。
DriveMoE:端到端自动驾驶中基于视觉-语言-动作模型的专家混合架构
- 作者:杨振杰、柴怡琳、贾晓松、李启峰、邵宇倩、朱学凯、苏海生、严俊驰 CVPR 2026
- 出版单位:上海交通大学
- 发表日期:2025年5月22日
- 项目页面:DriveMoE
- 代码:DriveMoE
- 数据集:Bench2Drive
- 任务:规划
- 摘要:
- DriveMoE是一种新颖的基于专家混合的端到端自动驾驶框架,包含场景专用的视觉专家网络和技能专用的动作专家网络。
- DriveMoE建立在我们的视觉-语言-动作(VLA)基线之上,该基线最初源自具身智能领域,名为Drive-π0。
AgentThink:面向自动驾驶的视觉-语言模型工具增强型思维链统一框架
- 作者:钱侃干、蒋思聪、钟洋、罗子昂、黄子林、朱天泽、姜坤、杨梦梦、傅正、苗金宇、史依宁、林何哲、刘莉、周天宝、黄宇、胡一飞、李广、陈光、叶浩、孙立军、杨殿阁
- 出版单位:清华大学、麦吉尔大学、小米公司、威斯康星大学麦迪逊分校
- 发表日期:2025年6月12日
- 任务:视觉问答
- 摘要:
- AgentThink是首个将动态代理式工具调用融入视觉-语言推理以支持自动驾驶任务的框架。
- 采用两阶段训练流程,结合监督微调与GRPO算法。
-
- 作者:赵宗创、付浩宇、梁定康、周欣、张鼎元、谢宏伟、王兵、白翔
- 出版单位:华中科技大学、小米汽车
- 发表日期:2025年5月13日
- 任务:视觉问答
- 代码:DriveMonkey
- 摘要:
- NuInteract是一个大规模数据集,旨在推动大型视觉-语言模型在自动驾驶领域的应用。该数据集包含23.9万张图像、3.4万帧视频以及超过150万个跨850个场景的图像-语言对,提供详尽的环境描述性文本及2D/3D标注,支持2D/3D视觉定位等任务,从而实现全面的感知、预测和规划。
- DriveMonkey是一个灵活的框架,可通过用户提示支持多种交互任务。
迈向以人为中心的自动驾驶:融合大语言模型指导与强化学习的快慢架构
- 作者:许成凯、刘佳琪、郭一程、张宇航、彭航、孙健
- 出版单位:同济大学
- 发表日期:2025年5月11日
- 任务:规划
- 环境:Highway-Env
- 摘要:
- 提出一种“快慢”决策框架,将大语言模型用于高层次指令解析,同时结合强化学习智能体进行低层次实时决策。
-
- 作者:刘明、梁思远、考希克·豪拉德、王丽雯、陶大成、张文胜
- 出版单位:爱荷华州立大学、新加坡国立大学
- 发表日期:2025年5月9日
- 任务:视觉问答
- 数据集:DriveLM
- 摘要:
- 提出一种基于自然反射的后门攻击方法,专门针对自动驾驶场景下的视觉-语言模型系统,旨在当特定视觉触发条件出现时,诱导系统产生显著的响应延迟。
DSDrive:通过统一推理与规划,蒸馏大语言模型实现轻量级端到端自动驾驶
- 作者:刘文儒、刘沛、马俊
- 出版单位:香港科技大学
- 发表日期:2025年5月8日
- 任务:规划
- 视频:DSDrive
- 摘要:
- DSDrive是一个轻量级的端到端自动驾驶框架,采用小型大语言模型处理多模态输入,实现明确的推理与闭环规划。具体而言,我们利用知识蒸馏技术,使小型大语言模型能够承担推理和规划任务,从而提升其整体性能。
- 引入了一种新颖的基于航点的双头协同模块,用于连接高层推理与底层轨迹规划。
-
- 作者:刘伟、张继元、郑彬雄、胡宇峰、林英展、曾增峰
- 出版单位:哈尔滨工业大学、百度公司
- 发表日期:2025年5月8日
- 任务:视觉问答、规划
- 数据集:Bench2Drive
- 摘要:
- X-Driver是一个统一的多模态大语言模型框架,专为闭环自动驾驶设计,利用思维链和自回归建模来增强感知与决策能力。
寻求碰撞:基于检索增强型大语言模型的自动驾驶在线安全关键场景生成
- 梅月文、聂彤、孙健、田晔
- 出版单位:同济大学、香港理工大学
- 发表日期:2025年5月2日
- 任务:生成
- 数据集:Waymo
- 摘要:
- 提出了一种基于LLM的智能体框架,用于在线生成交互式且具有安全关键性的场景。
- 开发了一种记忆与检索机制,使LLM能够持续适应不断变化的场景。
-
- 扬尼克·吕伯施泰特、埃斯特班·里韦拉、尼科·乌勒曼、马库斯·利恩坎普
- 出版单位:慕尼黑工业大学、慕尼黑机器人与机器智能研究所
- 发表日期:2025年4月30日
- 任务:VQA
- 数据集:LingoQA
- 摘要:
- 提出并评估了V3LMA,这是一种新颖的方法,结合了LLM和LVLM的优势,以增强交通场景中的3D场景理解能力——且无需进行模型训练或微调。
-
- 尼古拉斯·鲍曼、胡成、帕维特里伦·西瓦索蒂林加姆、秦浩通、谢磊、米凯莱·马尼奥、卢卡·贝尼尼 RSS 2025
- 出版单位:苏黎世联邦理工学院、浙江大学
- 发表日期:2025年4月15日
- 任务:规划
- 摘要:
- 提出了一种混合架构,将低层级的模型预测控制(MPC)与本地部署的大语言模型(LLM)相结合,以提升决策能力和人机交互(HMI)。
NuScenes-SpatialQA:自动驾驶中视觉-语言模型的空间理解与推理基准测试
- 天可欣、毛静睿、张云龙、蒋继万、周洋、涂正中
- 出版单位:德克萨斯农工大学、威斯康星大学麦迪逊分校
- 发表日期:2025年4月7日
- 项目页面:NuScenes-SpatialQA
- 任务:VQA
- 摘要:
- NuScenes-SpatialQA是首个大规模基于真实标注的问答(QA)基准测试,专门用于评估VLM在自动驾驶中的空间理解和推理能力。
OpenDriveVLA:迈向端到端自动驾驶的大规模视觉语言行动模型
- 周兴成、韩旭元、杨峰、马云普、阿洛伊斯·C·克诺尔
- 出版单位:慕尼黑工业大学、慕尼黑路德维希-马克西米利安大学
- 发表日期:2025年3月30日
- 项目页面:OpenDriveVLA
- 代码:OpenDriveVLA
- 任务:VQA、规划
- 摘要:
- OpenDriveVLA是一种专为端到端自动驾驶设计的视觉-语言行动(VLA)模型。
VLM-C4L:基于视觉-语言模型的自动驾驶持续核心数据学习与边缘场景优化
- 胡海波、左家诚、楼阳、崔宇飞、王建平、关楠、王进、李永辉、薛春杰 COLM 2025
- 出版单位:香港城市大学、苏州大学、麦吉尔大学、鸿海研究院、穆罕默德·本·扎耶德人工智能大学
- 发表日期:2025年3月29日
- 项目页面:VLM-C4L
- 任务:感知
- 摘要:
- VLM-C4L是一个持续学习框架,引入视觉-语言模型(VLM)来动态优化和增强边缘场景数据集。该框架将VLM引导的高质量数据提取与核心数据重放策略相结合,使模型能够在保留先前常规场景性能的同时,逐步从多样化的边缘场景中学习,从而确保其在实际自动驾驶中的长期稳定性和适应性。
-
- 李悦、田萌、林振宇、朱江桐、朱德昌、刘海强、王子宁、张悦怡、熊志伟、赵新海
- 出版单位:中国科学技术大学、华为诺亚方舟实验室、加州大学伯克利分校
- 发表日期:2025年3月27日
- 代码:VLADBench
- 任务:VQA
- 摘要:
- VLADBench专门用于严格评估VLM在自动驾驶中的能力。该基准测试采用分层结构,反映了可靠驾驶所需的复杂技能体系,从对基本场景和交通要素的理解,逐步过渡到高级推理和决策能力。
ORION:基于视觉-语言指令驱动行动生成的全栈端到端自动驾驶框架
- 傅浩宇、张典坤、赵宗创、崔建峰、梁定康、张冲、张鼎远、谢宏伟、王兵、白翔
- 出版单位:华中科技大学、小米电动汽车
- 发表日期:2025年3月25日
- 任务:规划
- 项目页面:ORION
- 代码:ORION
- 数据集:Bench2Drive
- 摘要:
- ORION是一个由视觉-语言指令驱动行动生成的全栈端到端自动驾驶框架。ORION独特地结合了QT-Former来聚合长期历史上下文、大语言模型(LLM)用于驾驶场景推理,以及生成式规划器来进行精确的轨迹预测。
AED:利用大语言模型自动发现自动驾驶策略中的有效且多样化漏洞
- 邱乐、徐泽来、谭齐鑫、唐文豪、于超、王宇
- 出版单位:清华大学、北京中关村研究院
- 发表日期:2025年3月24日
- 任务:规划
- 环境:Highway-Env
- 摘要:
- AED是一个利用大语言模型(LLM)自动发现自动驾驶策略中有效且多样化漏洞的框架。
- AED首先使用LLM自动设计强化学习训练的奖励函数。
AutoDrive-QA:利用大型视觉-语言模型自动生成自动驾驶数据集的选择题
- 博什拉·哈利利、安德鲁·W·史密斯
- 出版单位:哥伦比亚大学
- 发表日期:2025年3月20日
- 任务:VQA
- 摘要:
- AutoDrive-QA是一个自动化流程,可以将现有的驾驶问答数据集(包括DriveLM、NuScenes-QA和LingoQA)转换为结构化的多项选择题(MCQ)格式。
RAD:基于视觉-语言模型的元动作检索增强决策在自动驾驶中的应用
- 王宇晋、刘泉峰、蒋正欣、王天一、焦俊峰、褚洪庆、高炳昭、陈宏
- 出版单位:同济大学、耶鲁大学、德克萨斯大学奥斯汀分校
- 发表日期:2025年3月18日
- 任务:VQA
- 摘要:
- 提出一种检索增强决策(RAD)框架,这是一种新颖的架构,旨在提升视觉-语言模型在自动驾驶场景中可靠生成元动作的能力。
-
- Tin Stribor Sohn、Philipp Reis、Maximilian Dillitzer、Johannes Bach、Jason J. Corso、Eric Sax
- 出版单位:保时捷股份公司、信息学研究中心、埃斯林根应用科学大学、密歇根大学、卡尔斯鲁厄理工学院
- 发表日期:2025年3月14日
- 任务:评估
- 摘要:
- 本文提出了一种针对自动驾驶领域多模态大语言模型的能力驱动评估的综合框架。该框架从语义、空间、时间及物理四个核心能力维度对场景理解进行结构化分析。
DynRsl-VLM:利用动态分辨率视觉-语言模型提升自动驾驶感知能力
- 周希睿、单连磊、桂晓林
- 出版单位:西安交通大学、中国科学院大学
- 发表日期:2025年3月14日
- 任务:VQA
- 摘要:
- DynRsl-VLM引入了一种动态分辨率图像输入处理方法,能够在捕捉图像中所有实体特征信息的同时,确保图像输入对于视觉Transformer(ViT)而言仍具有计算上的可处理性。
-
- 卡特琳·伦茨、陈龙、Elahe Arani、奥列格·西纳夫斯基 CVPR 2025
- 出版单位:Wayve、图宾根大学、图宾根人工智能中心
- 发表日期:2025年3月12日
- 任务:规划
- 数据集:Carla Leaderboard V2、Bench2Drive
- 摘要:
- 一种基于视觉-语言模型的驾驶模型,在CARLA模拟器的官方CARLA Leaderboard 2.0和本地基准Bench2Drive上均取得了最先进的驾驶性能。 (2) 引入一项新任务“动作梦境”,并配套提出了收集指令-动作对的方法以及一个无需执行危险动作即可评估语言与动作理解关联性的基准。 (3) 该模型不仅具备优秀的驾驶性能,还整合了多项与语言相关的任务。
CoT-Drive:利用大语言模型与思维链提示实现自动驾驶高效运动预测
- 廖海成、孔翰林、王博楠、王承悦、叶旺、何正兵、徐成忠、李振宁 IEEE TAI 2025
- 出版单位:澳门大学、麻省理工学院
- 发表日期:2025年3月10日
- 任务:VQA
- 摘要:
- 提出一种师生知识蒸馏策略,将大语言模型先进的场景理解能力有效迁移到轻量级语言模型(LM)中,从而确保CoT-Drive能够在边缘设备上实现实时运行,同时保持全面的场景理解和泛化能力。
-
- 张恩明、龚培哲、戴兴源、吕一升、苗青海
- 出版单位:中国科学院大学
- 发表日期:2025年3月9日
- 代码:SCD-Bench
- 任务:评估
- 摘要:
- 提出一种新的评估方法——安全认知驾驶基准测试(SCD-Bench),并开发了自动驾驶图文标注系统(ADA)。
VLM-E2E:通过多模态驾驶员注意力融合提升端到端自动驾驶性能
- 刘沛、刘海鹏、刘海超、刘鑫、倪金鑫、马军
- 出版单位:香港科技大学(广州)、理想汽车、厦门大学、香港科技大学
- 发表日期:2025年2月25日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- VLME2E是一种新颖的框架,利用视觉-语言模型提供注意力线索以增强训练效果。
- 将文本表示融入鸟瞰视角(BEV)特征中进行语义监督,从而使模型能够学习到更丰富的特征表示,明确捕捉驾驶员的注意力语义。
CurricuVLM:通过视觉-语言模型实现个性化安全关键课程学习,迈向安全自动驾驶
- 盛子豪、黄子林、曲延松、冷岳、Sruthi Bhavanam、陈思凯
- 出版单位:威斯康星大学麦迪逊分校、普渡大学
- 发表日期:2025年2月21日
- 任务:规划
- 项目页面:CurricuVLM
- 数据集:MetaDrive、Waymo
- 摘要:
- CurricuVLM是一个新颖的框架,利用视觉-语言模型为自动驾驶智能体实现个性化课程学习。
- CurricuVLM是首个将视觉-语言模型用于闭环自动驾驶训练中动态课程生成的工作。
-
- 邱旭光、八百原亮、王建义、Stephen F. Smith、Frank Wang、陈敏弘
- 出版单位:英伟达、卡内基梅隆大学
- 发表日期:2025年2月14日
- 任务:VQA
- 摘要:
- 创建并发布V2V-QA数据集,以支持基于大语言模型的端到端协同自动驾驶方法的开发与评估。
- 提出一种用于协同自动驾驶的基线方法V2V-LLM,为V2V-QA提供初始基准。
-
- 许天硕、陆浩、闫旭、蔡英杰、刘冰冰、陈颖聪 ICRA 2025
- 出版单位:香港科技大学(广州)、华为诺亚方舟实验室
- 发表日期:2025年2月10日
- 任务:感知、规划
- 数据集:nuScenes
- 摘要:
- 提出一种用于自动驾驶的基于占用网格的大语言模型(Occ-LLM),展示了其在场景理解方面的优越性能。
INSIGHT:通过视觉—语言模型实现情境感知的危险检测与边缘场景评估,提升自动驾驶安全性
- 陈典伟、张子凡、刘宇辰、杨显峰特里
- 出版单位:马里兰大学、北卡罗来纳州立大学
- 发表日期:2025年2月1日
- 任务:VQA
- 摘要:
- INSIGHT(语义与视觉输入融合的通用危险追踪系统)是一个分层的视觉—语言模型框架,旨在增强危险检测和边缘场景评估能力。
LLM-attacker:利用大语言模型增强自动驾驶闭环对抗场景生成
- 梅岳文、聂彤、孙健、田烨 IEEE TITS 2025
- 出版单位:同济大学、香港理工大学
- 发表日期:2025年1月27日
- 视频:LLM-attacker
- 任务:生成
- 数据集:MetaDrive、Waymo
- 摘要:
- LLM-attacker:一个基于大语言模型(LLMs)的闭环对抗场景生成框架。
-
- 王璐、张天元、曲阳、梁思远、陈宇威、刘爱珊、刘向龙、陶大成
- 出版单位:北京航空航天大学、新加坡国立大学、中国航空工业发展研究中心、南洋理工大学
- 发表日期:2025年1月23日
- 任务:VQA
- 摘要:
- 级联对抗干扰(CAD)首次引入决策链破坏机制,通过生成并注入欺骗性语义,导致低层次推理失效,从而确保扰动在整个决策链条中持续有效。
-
- 迪普蒂·赫格德、拉吉夫·亚萨尔拉、蔡宏、韩世忠、阿普拉蒂姆·巴塔查里亚、什韦塔·马哈詹、刘丽婷、里希克·加雷帕利、维沙尔·M·帕特尔、法提赫·波里克利
- 出版单位:约翰斯·霍普金斯大学、高通AI研究
- 发表日期:2025年1月16日
- 任务:规划
- 摘要:
- DiMA是一个端到端的自动驾驶框架,通过将多模态大语言模型的知识蒸馏到基于视觉的规划器中,以确保对长尾事件的鲁棒性,同时保持高效。
- 提出了蒸馏任务以及以下代理任务,以对齐视觉规划器和多模态大语言模型的目标:(i) 掩码标记重建 (ii) 未来标记预测 (iii) 场景编辑。
-
- 青木俊明、富田隆史、河合达治、川上大辅、千田信夫
- 出版单位:日本高等科学技术研究院、高知大学、三菱电机株式会社
- 发表日期:2025年1月16日
- 任务:开发
- 摘要:
- 本研究提出了一种称为“车辆位置图”(CPD)的表示方法。CPD能够简洁地表达大量场景,尤其适用于场景分析和设计。
-
- 高浩翔、赵宇
- 出版单位:Motional AD LLC、多伦多大学
- 发表日期:2025年1月12日
- 任务:VQA
- 摘要:
- 分析了将大语言模型的语义标签有效蒸馏到小型视觉网络中的方法,可用于复杂场景的语义表示,从而支持下游的规划与控制决策。
-
- 郑旭然、俞昌德
- 出版单位:韩国科学技术院
- 发表日期:2025年1月9日
- 任务:VQA
- 摘要:
- 探讨了小型多模态大语言模型及其应用在自动驾驶领域的效用。
-
- 穆罕默德·埃尔赫纳维、胡泰法·I·阿什卡尔、安德里·拉科托尼赖、塔夸·I·阿尔哈迪迪、艾哈迈德·贾伯、穆罕默德·阿布·塔米
- 出版单位:昆士兰科技大学、阿拉伯美国大学、哥伦比亚大学
- 发表日期:2025年1月9日
- 任务:场景理解
- 摘要:
- 本研究利用对比语言—图像预训练(CLIP)模型开发了一套动态场景检索系统,该系统可优化后实现实时部署于边缘设备。
视觉—语言模型已准备好用于自动驾驶吗?从可靠性、数据与指标角度的实证研究
- 谢绍远、孔令东、董宇豪、司马冲浩、张文伟、陈启 Alfred、刘子威、潘亮 ICCV 2025
- 项目页面:DriveBench
- 代码:DriveBench
- HuggingFace:DriveBench
- 发表日期:2025年1月7日
- 任务:基准测试
- 摘要:
- DriveBench是一个基准数据集,旨在评估视觉—语言模型在17种场景下的可靠性(包括干净、损坏及纯文本输入),涵盖19,200帧、20,498组问答对、三种问题类型、四项主流驾驶任务,以及共12种流行的视觉—语言模型。
-
- 艾孜尔江·艾尔西兰 AAAI 2025 口头报告
- 出版单位:澳门大学
- 发表日期:2024年12月24日
- 任务:生成
- 环境:CARLA
- 项目页面:AutoSceneGen
- 代码:AutoSceneGen
- 摘要:
- 提出了一种通用、灵活且经济高效的框架“AutoSceneGen”,可通过场景描述自动增强交通场景的多样性,从而加速仿真与测试过程。
-
- 邵鹏、王振坡、李国强
- 出版单位:北京理工大学
- 发表日期:2024年12月24日
- 任务:规划
- 代码:LGDRL
- 环境:HighwayEnv
- 摘要:
- 提出了一种新颖的大型语言模型(LLM)引导的深度强化学习(LGDRL)框架,用于解决自动驾驶车辆的决策问题。在此框架中,基于LLM的驾驶专家被整合到DRL中,为DRL的学习过程提供智能指导。
-
- Md Robiul Islam
- 出版单位:威廉与玛丽学院
- 发表日期:2025年12月21日
- 任务:VQA
- 摘要:
- 构建了一个虚拟问答(VQA)数据集来微调模型,以解决MLLM在自动驾驶任务中表现不佳的问题。
VLM-RL:一种统一的视觉语言模型与强化学习框架,用于安全自动驾驶
- 黄子林、盛子豪、曲彦松、游俊伟、陈思凯
- 出版单位:威斯康星大学麦迪逊分校、普渡大学
- 发表日期:2024年12月20日
- 任务:奖励设计
- 项目页面:VLM-RL
- 摘要:
- VLM-RL是一个统一的框架,将预训练的视觉语言模型(VLMs)与强化学习相结合,利用图像观测和自然语言目标生成奖励信号。
-
- 徐毅、胡宇鑫、张载伟、格雷戈里·P·迈耶、西瓦·卡尔蒂克·穆斯蒂科韦拉、西达尔塔·斯里尼瓦萨、埃里克·M·沃尔夫、黄欣
- 出版单位:Cruise LLC、东北大学
- 发表日期:2024年12月19日
- 任务:规划
- 数据集:nuScenes
- 摘要:
- VLM-AD是一种方法,利用视觉语言模型(VLMs)作为教师,通过提供包含非结构化推理信息和结构化动作标签的额外监督来增强训练效果。
RAC3:基于视觉语言模型的检索增强型边缘场景理解用于自动驾驶
- 王宇金、刘泉峰、范佳琪、洪锦龙、楚洪庆、田孟健、高炳兆、陈宏
- 出版单位:同济大学、深圳技术大学
- 发表日期:2024年12月15日
- 任务:VQA
- 数据集:CODA-LM
- 摘要:
- RAC3是一个新框架,旨在提升VLMs在边缘场景理解方面的性能。
- RAC3集成了频率空间融合(FSF)图像编码器、用于嵌入模型的跨模态对齐训练方法(结合硬负样本和半硬负样本挖掘),以及基于K-Means聚类和分层可导航小世界(HNSW)索引的快速查询与检索管道。
-
- 张松岩、黄文辉、高子慧、陈浩、吕晨
- 出版单位:南洋理工大学、浙江大学
- 发表日期:2024年12月13日
- 任务:规划
- 摘要:
- 研究了基础驾驶知识的深度和广度对闭环轨迹规划的影响,并提出了WiseAD,这是一种专为端到端自动驾驶设计的特殊VLM,能够在不同场景下进行驾驶推理、行动解释、目标识别、风险分析、驾驶建议和轨迹规划。
PKRD-CoT:自动驾驶中多模态大型语言模型的统一思维链提示
- 罗雪雯、丁凡、宋银生、张晓峰、卢俊勇 ICONIP 2024
- 出版单位:马来西亚莫纳什大学
- 任务:问答、提示工程
- 发表日期:2024年12月2日
- 摘要:
- PKRD-CoT基于自动驾驶的四项基本能力——感知、知识、推理和决策——构建而成。
-
- 张天元、王璐、张新伟、张一桐、贾博义、梁思源、胡圣山、傅强、刘爱珊、刘向龙
- 出版单位:北京航空航天大学、新加坡国立大学、华中科技大学
- 任务:VQA
- 发表日期:2024年11月27日
- 摘要:
- ADvLM是首个专为自动驾驶领域中的VLM设计的视觉对抗攻击框架。
- 在文本域采用语义不变诱导,在视觉域采用场景关联增强,以确保攻击在不同指令和连续视角下均具有效力。
-
- 山崎翔太、张晨宇、南里拓也、重兼明夫、王思源、西山丈、朱涛、横泽浩平 ECCV 2024 VCAD研讨会
- 出版单位:日产汽车公司
- 发表日期:2024年11月15日
- 任务:VQA
- 摘要:
- 提出了一种推理模型,以本车未来的规划轨迹为输入,生成推理文本。
-
- 林峰何、孙一鸣、吴思豪、刘家旭、黄晓伟 NeurIPS 2024 SafeGenAI Workshop
- 出版单位:利物浦大学、诺丁汉大学
- 发表日期:2024年11月8日
- 任务:感知
- 数据集:DriveLM
- 摘要:
- 通过在CLIP感知网络之外加入基于YOLOS的检测网络,扩展Llama-Adapter架构,以解决目标检测和定位方面的局限性。
-
- 柳灿辉、成贤基、李大奎、文成佑、闵成宰、沈贤哲
- 出版单位:KAIST、ETRI
- 发表日期:2024年10月14日
- 任务:VQA
- 摘要:
- 介绍了一种基础模型的创新应用,使配备RGB-D相机的无人地面车辆能够根据人类语言指令导航至指定目的地。
LeGEND:大型语言模型辅助的自动驾驶系统场景生成自顶向下方法
- 唐顺成、张振亚、周继祥、雷磊、周源、薛银星 ASE 2024
- 出版单位:中国科学技术大学、九州大学、浙江理工大学
- 任务:生成
- 发表日期:2024年9月16日
- 代码:LeGEND
- 摘要:
- LeGEND是一种自顶向下的场景生成方法,能够同时实现场景的严重性和多样性。
- 采用中间语言作为媒介,通过两阶段转换,将事故报告转化为逻辑场景;因此,LeGEND使用两个LLM,分别负责不同阶段。
- 实现并验证了LeGEND在Apollo平台上的有效性,发现了11种反映系统缺陷不同方面的关键具体场景。
MiniDrive:用于自动驾驶的多层级2D特征作为文本标记的更高效视觉语言模型
- 张恩明、戴兴元、吕义生、苗庆海
- 出版单位:中国科学院大学、中科院自动化所
- 任务:问答
- 发表日期:2024年9月14日
- 代码:MiniDrive
- 摘要:
- MiniDrive解决了自动驾驶系统中VLM高效部署和实时响应的挑战。它可以在配备24GB显存的RTX 4090 GPU上完成全量训练。
- 特征工程专家混合模型(FE-MoE)解决了如何将多视角的2D特征高效编码为文本标记嵌入的问题,有效减少了视觉特征标记的数量并最小化了特征冗余。
- 通过残差结构实现动态指令适配器,解决了同一图像在输入语言模型之前视觉标记固定的问题。
-
- 丁凯瑞、陈博远、苏宇辰、高焕昂、金步、司马冲浩、张武强、李晓辉、保罗·巴尔施、李洪洋、赵浩 CoRL 2024
- 出版单位:人工智能产业研究院、梅赛德斯-奔驰集团中国有限公司、清华大学、上海人工智能实验室
- 发表日期:2024年9月10日
- 项目页面:Hint-AD
- 任务:VQA
- 摘要:
- Hint-AD是一个集成的AD-语言系统,能够生成与AD模型的整体感知-预测-规划输出相一致的语言。通过引入中间输出和一个用于有效特征适配的全局标记混合子网络,Hint-AD实现了理想的准确性,在包括驾驶解释、3D密集字幕和命令预测在内的驾驶语言任务中达到了最先进的水平。
- 贡献了一个人工标注的驾驶解释数据集Nu-X on nuScenes,以弥补这一广泛使用的AD数据集中缺乏驾驶解释数据的问题。
OccLLaMA:用于自动驾驶的占用-语言-动作生成式世界模型
- 魏聚龙、袁善帅、李鹏飞、胡庆达、甘仲学、丁文超
- 出版单位:复旦大学、清华大学
- 任务:感知(占用)+ 推理
- 发表日期:2024年9月5日
- 摘要:
- OccLLaMA是一个统一的3D占用-语言-动作生成式世界模型,整合了包括但不限于场景理解、规划和4D占用预测等VLA相关任务。
- 一种新型场景分词器(类似VQVAE的架构),能够高效地离散化和重建Occ场景,同时考虑稀疏性和类别不平衡问题。
ContextVLM:利用视觉语言模型进行零样本和少样本情境理解的自动驾驶
- 肖纳克·苏拉尔、纳伦、拉古纳坦·拉杰库马尔 ITSC 2024
- 出版单位:卡内基梅隆大学
- 任务:情境识别
- 代码:ContextVLM
- 发表日期:2024年8月30日
- 摘要:
- DrivingContexts是一个大型公开数据集,结合了人工标注和机器标注标签,旨在提升VLM的情境识别能力。
- ContextVLM利用视觉语言模型,通过零样本和少样本方法来检测情境。
DriveGenVLM:基于视觉语言模型的自动驾驶真实世界视频生成
- 傅勇杰、安莫尔·贾因、狄璇、陈旭、莫兆斌 IAVVC 2024
- 出版单位:哥伦比亚大学
- 任务:生成
- 数据集:Waymo开放数据集
- 发表日期:2024年8月29日
- 摘要:
- DriveGenVLM采用基于去噪扩散概率模型的视频生成框架,创建能够模拟真实世界动态的逼真视频序列。
- 生成的视频随后使用一个名为“基于第一人称视频的有效上下文学习”(EILEV)的预训练模型,评估其对视觉语言模型(VLM)的适用性。
-
- 陈娇、戴素燕、陈芳芳、吕作宏、唐建华
- 出版单位:华南理工大学、琶洲实验室
- 任务:规划 + QA
- 项目页面:EC-Drive
- 发表日期:2024年8月19日
- 摘要:
- EC-Drive是一种新颖的边缘—云端协同自动驾驶系统。
AgentsCoMerge:大语言模型赋能的匝道汇入协同决策
- 胡森康、方正儒、方子涵、邓怡琴、陈贤浩、方玉光、Sam Kwong IEEE TMC
- 出版单位:香港城市大学、香港大学、岭南大学
- 任务:多智能体规划
- 发表日期:2024年8月7日
- 摘要:
- AgentsCoMerge是一个由大语言模型赋能的匝道汇入协同决策系统,包含观测、规划、通信和强化训练模块。实验表明,该系统能够有效提升多智能体协作效率。
VLM-MPC:视觉语言基础模型(VLM)引导的自动驾驶模型预测控制器(MPC)
- 龙可可、史浩天、刘嘉熙、李晓鹏
- 出版单位:威斯康星大学麦迪逊分校
- 任务:规划
- 发表日期:2024年8月4日
- 摘要:
- 提出了一种闭环自动驾驶控制器,将VLM应用于车辆的高层控制。
- 上层VLM以车辆前视摄像头图像、文本场景描述以及经验记忆为输入,生成下层MPC所需的控制参数。
- 下层MPC则利用这些参数,结合考虑发动机延迟的车辆动力学特性,实现逼真的车辆行为,并将状态反馈回上层。
- 这种异步双层结构解决了当前VLM响应速度较慢的问题。
SimpleLLM4AD:用于自动驾驶的图式视觉问答端到端视觉语言模型
- 郑培汝、赵云、龚展、朱洪、吴绍华 IEIT Systems
- 出版单位:威斯康星大学麦迪逊分校
- 任务:QA
- 发表日期:2024年7月31日
- 摘要:
- SimpleLLM4AD重新构想了传统的自动驾驶流程,将其划分为感知、预测、规划和行为四个相互关联的阶段。
- 每个阶段都被表述为一系列视觉问答(VQA)对,这些问答对相互连接形成图式视觉问答(GVQA)。这种基于图的结构使系统能够系统地推理每个VQA对,从而确保从感知到行动的信息流和决策过程连贯一致。
-
- 唐左音、何建华、裴大帅、刘克中、高涛
- 出版单位:阿斯顿大学、埃塞克斯大学、武汉理工大学、长安大学
- 任务:评估
- 发表日期:2024年7月24日
- 数据:英国驾驶理论考试练习题及答案
- 摘要:
- 设计并运行了针对多个专有LLM模型(OpenAI GPT系列、百度文心一言和阿里通义千问)以及开源LLM模型(清华大学MiniCPM-2B和MiniCPM-Llama3-V2.5)的驾驶理论测试,共包含500余道选择题。
-
- 蒋科谋、蔡轩、崔志勇、李傲勇、任一龙、于海阳、杨浩、傅道成、温立成、蔡品隆
- 出版单位:北京航空航天大学、约翰霍普金斯大学、上海人工智能实验室
- 任务:多智能体规划
- 环境:HighwayEnv
- 项目页面:KoMA
- 发表日期:2024年7月19日
- 摘要:
- 介绍了一个基于知识驱动的自动驾驶框架KoMA,该框架整合了由大语言模型赋能的多智能体,包含五个核心模块:环境、多智能体交互、多步规划、共享内存和基于排名的反思。
WOMD-Reasoning:用于交互与驾驶意图推理的大规模语言数据集
- 李一恒、葛崇健、李晨然、徐晨峰、富冢正芳、唐晨、丁明宇、詹伟
- 出版单位:加州大学伯克利分校、德克萨斯大学奥斯汀分校
- 任务:数据集 + 推理
- 发表日期:2024年7月5日
- 数据集:WOMD-Reasoning
- 摘要:
- WOMD-Reasoning 是一个以交互描述和推理为核心的语言数据集。它深入探讨了由交通规则和人类意图引发的、此前被忽视的关键交互,提供了丰富的见解。
- 开发了一套自动语言标注流水线,利用基于规则的转换器将运动数据转化为语言描述,并结合一组人工提示引导 ChatGPT 生成问答对。
-
- 科拉瓦特·查伦皮塔克斯、阮文光、菅沼昌则、高桥雅弘、新原龙马、冈谷隆之 IEEE TIV 2024
- 出版单位:东北大学、RIKEN AIP 中心、电装公司
- 任务:预测
- 代码:DHPR
- 发表日期:2024年6月21日
- 摘要:
- DHPR(驾驶危险预测与推理)数据集包含 1.5 万张行车记录仪拍摄的街景图像,每张图像都关联着一个元组,其中包括车速、假设的危险描述以及场景中存在的视觉实体。
- 提出了几种基线方法并对其性能进行了评估。
-
- 陈源、丁子涵、王梓钦、王燕、张立军、刘思 ECCV 2024
- 出版单位:北京航空航天大学、清华大学
- 任务:规划
- 发表日期:2024年6月20日
- 代码:AsyncDriver
- 数据集:nuPlan 封闭环路反应式 Hard20
- 摘要:
- AsyncDriver 是一种新颖的异步 LLM 增强框架,其中 LLM 的推理频率可调,并可与实时规划器的频率解耦。
- 自适应注入模块具有模型无关性,能够轻松将场景相关的指令特征融入任何基于 Transformer 的实时规划器中,从而提升其理解和执行一系列语言驱动的导航指令的能力。
- 与现有方法相比,我们的方法在 nuPlan 的挑战性场景中表现出更优越的闭环评估性能。
-
- 孔祥瑞、托马斯·布劳恩尔、马尔科·法米、王悦
- 出版单位:西澳大利亚大学、昆士兰州政府、昆士兰科技大学
- 任务:问答
- 发表日期:2024年6月9日
- 摘要:
- 提出了一种安全的交互框架,用于有效审计与云端 LLM 交互的数据。
- 分析了 11 种基于大型语言模型的自动驾驶方法,包括驾驶安全性、token 使用情况、隐私保护以及与人类价值观的一致性。
- 在 nuScenesQA 数据集中评估了驾驶提示的有效性,并比较了 gpt-35-turbo 和 llama2-70b 这两种 LLM 后端的不同结果。
PlanAgent:用于闭环车辆运动规划的多模态大型语言代理
- 郑宇鹏、邢泽斌、张启超、金步、李鹏飞、郑宇航、夏仲璞、詹坤、郎献鹏、陈亚然、赵东彬
- 出版单位:中国科学院、北京邮电大学、北京航空航天大学、清华大学、理想汽车
- 任务:规划
- 发表日期:2024年6月4日
- 摘要:
- PlanAgent 是首个基于多模态大型语言模型的中—中级(使用 BEV,无需原始传感器)闭环自动驾驶规划代理系统。
- 提出了一个高效的环境转换模块,该模块通过车道图表示提取多模态信息输入。
- 设计了一个推理引擎模块,引入分层思维链(CoT)来指导 MLLM 生成规划代码,并设计了一个反思模块,结合仿真和评分机制筛选掉 MLLM 生成的不合理方案。
-
- 希瓦·斯里拉姆、王敦轩、阿拉·马卢夫、盖伊·罗斯曼、塞尔塔克·卡拉曼、丹妮拉·鲁斯
- 出版单位:MIT CSAIL、TRI、MIT LID
- 任务:基准测试与评估
- 代码:DriveSim
- 发表日期:2024年5月9日
- 摘要:
- 这是一项全面的实验研究,旨在评估不同 MLLM 在闭环驾驶场景中的推理和理解能力,以及其决策能力。
- DriveSim 是一款专门设计的模拟器,用于生成多样化的驾驶场景,从而为测试和评估 MLLM 从固定车载摄像头视角(即驾驶者视角)理解和推理真实世界驾驶场景的能力提供平台。
OmniDrive:用于自动驾驶的全栈式LLM-Agent框架,具备3D感知推理与规划能力
- 王世豪、于志鼎、蒋晓辉、兰士毅、施敏、Nadine Chang、Jan Kautz、李颖、Jose M. Alvarez
- 出版单位:北京理工大学、NVIDIA、华中科技大学
- 任务:基准测试与规划
- 发布日期:2024年5月2日
- 代码:OmniDrive
- 摘要:
- OmniDrive是一个旨在实现智能体模型与3D驾驶任务之间强对齐的全栈式框架。
- 提出了一套包含场景描述、交通规则、3D定位、反事实推理、决策与规划等全面视觉问答(VQA)任务的新基准。
Chat2Scenario:利用大型语言模型从数据集中提取驾驶场景
- 赵永奇、肖文博、Tomislav Mihalj、胡佳、Arno Eichberger IEEE IV 2024
- 出版单位:
- 发布日期:2024年4月26日
- 任务:生成
- 数据集:Chat2Scenario
- 摘要:
- Chat2Scenario是一款基于Web的工具,允许用户通过输入描述性功能场景文本,在数据集中搜索特定的驾驶场景。
-
- SungYeon Park、MinJae Lee、JiHyuk Kang、Hahyeon Choi、Yoonah Park、Juhwan Cho、Adam Lee、DongKyu Kim WACV 2024工作坊
- 出版单位:首尔国立大学、加州大学伯克利分校
- 发布日期:2024年4月16日
- 任务:VQA
- 代码:VLAAD
- 摘要:
- 介绍了一个多模态指令微调数据集,帮助语言模型在多样化的驾驶场景中学习视觉指令。
- 基于该数据集,提出了一款名为VLAAD的多模态LLM驾驶助手。
AGENTSCODRIVER:大型语言模型赋能的终身学习型协同驾驶
- 胡森康、方正儒、方子涵、陈献浩、方宇光
- 出版单位:香港城市大学、香港大学
- 任务:规划(多车协同)
- 发布日期:2024年4月9日
- 环境:HighwayEnv
- 摘要:
- AGENTSCODRIVER是一个由LLM驱动、具备终身学习能力的多车协同驾驶框架,允许多个驾驶智能体在复杂交通场景中相互通信并协同驾驶。
- 该框架包含推理引擎、认知记忆、强化学习反思机制和通信模块。
-
- 彭明星、郭旭森、陈贤达、朱美欣、陈科华、杨浩(Frank)、王学松、王银海
- 出版单位:香港科技大学、约翰斯·霍普金斯大学、同济大学、STAR实验室
- 任务:轨迹预测
- 发布日期:2024年3月27日
- 数据集:highD
- 摘要:
- LC-LLM是首个用于变道预测的大型语言模型。它充分利用LLM的强大能力来理解复杂的交互场景,从而提升变道预测性能。
- LC-LLM能够提供可解释的预测结果,不仅预测变道意图和轨迹,还能生成对预测结果的解释说明。
-
- Ali Nouri、Beatriz Cabrero-Daniel、Fredrik Törner、Hȧkan Sivencrona、Christian Berger
- 出版单位:查尔姆斯理工大学、哥德堡大学、沃尔沃汽车、Zenseact、哥德堡大学
- 任务:问答
- 发布日期:2024年3月24日
- 摘要:
- 提出了一种由提示词和LLM组成的原型流水线,该流水线接收物品定义并以安全要求的形式输出解决方案。
-
- 作者:Pranjal Paul、Anant Garg、Tushar Choudhary、Arun Kumar Singh、K. Madhava Krishna
- 出版单位:海得拉巴国际信息技术研究所、爱沙尼亚塔尔图大学
- 项目主页:LeGo-Drive
- 代码:LeGo-Drive
- 环境:Carla
- 任务:轨迹预测
- 发表日期:2024年3月20日
- 摘要:
- 提出了一种基于大型语言模型的新型规划引导式端到端目标点导航方案,通过与环境动态交互并生成无碰撞轨迹,从而预测和优化期望状态。
-
- 作者:Mehdi Azarafza、Mojtaba Nayyeri、Charles Steinmetz、Steffen Staab、Achim Rettberg
- 出版单位:哈姆-利普施塔特应用科学大学、斯图加特大学
- 发表日期:2024年3月18日
- 任务:推理
- 环境:Carla
- 摘要:
- 结合算术与常识性元素,利用YOLOv8检测到的物体信息。
- 将“物体位置”、“本车速度”、“与物体距离”以及“本车行驶方向”输入大型语言模型,在CARLA环境中进行数学计算。
- 综合考虑天气条件等因素后,生成精确的刹车与加速控制指令。
-
- 作者:Jiazhi Yang、Shenyuan Gao、Yihang Qiu、Li Chen、Tianyu Li、Bo Dai、Kashyap Chitta、Penghao Wu、Jia Zeng、Ping Luo、Jun Zhang、Andreas Geiger、Yu Qiao、Hongyang Li ECCV 2024
- 出版单位:OpenDriveLab与上海人工智能实验室、香港科技大学、香港大学、图宾根大学、图宾根人工智能中心
- 任务:数据集构建与生成
- 代码:DriveAGI
- 发表日期:2024年3月14日
- 摘要:
- 提出首个自动驾驶领域的大规模视频预测模型。
- 构建的数据集累计超过2000小时的驾驶视频,覆盖全球各地,包含多样化的天气条件和交通场景。
- GenAD继承了近期潜在扩散模型的优点,通过新颖的时间推理模块处理驾驶场景中的复杂动态。
LLM辅助交通信号灯:利用大型语言模型能力实现复杂城市环境下的拟人化交通信号控制
- 作者:Maonan Wang、Aoyu Pang、Yuheng Kan、Man-On Pun、Chung Shue Chen、Bo Huang
- 出版单位:香港中文大学、上海人工智能实验室、商汤科技有限公司、诺基亚贝尔实验室
- 发表日期:2024年3月13日
- 任务:生成
- 代码:LLM-Assisted-Light
- 摘要:
- LA-Light是一种混合型交通信号控制系统框架,融合了大型语言模型的拟人化推理能力,使信号控制算法能够以人类认知般的细腻判断来理解和响应复杂的交通场景。
- 开发了一个闭环交通信号控制系统,将大型语言模型与一系列可互操作的工具集成在一起。
DriveDreamer-2:LLM增强的世界模型用于多样化驾驶视频生成
- 作者:Guosheng Zhao、Xiaofeng Wang、Zheng Zhu、Xinze Chen、Guan Huang、Xiaoyi Bao、Xingang Wang
- 出版单位:中国科学院自动化研究所、GigaAI
- 发表日期:2024年3月11日
- 任务:生成
- 项目:DriveDreamer-2
- 数据集:nuScenes
- 摘要:
- DriveDreamer-2基于DriveDreamer框架,并引入大型语言模型(LLM)以生成用户自定义的驾驶视频。
- UniMVM(统一多视角模型)增强了生成驾驶视频的时间与空间连贯性。
- HDMap生成器确保背景元素不会与前景轨迹发生冲突。
- 利用构建的文本到脚本数据集,对GPT-3.5进行微调,使其具备专门的轨迹生成知识。
-
- 作者:Yuxi Wei、Zi Wang、Yifan Lu、Chenxin Xu、Changxing Liu、Hao Zhao、Siheng Chen、Yanfeng Wang
- 出版单位:上海交通大学、上海人工智能实验室、卡内基梅隆大学、清华大学
- 发表日期:2024年3月11日
- 任务:生成
- 代码:ChatSim
- 数据集:Waymo
- 摘要:
- ChatSim是首个可通过自然语言指令结合外部数字资产实现可编辑的逼真3D驾驶场景仿真的系统。
- McNeRF是一种新颖的神经辐射场方法,整合多摄像头输入,提供更广阔的场景渲染能力,有助于生成逼真的效果。
- McLight是一种新的多摄像头光照估计技术,融合天穹光与周围环境光,使外部数字资产呈现出真实的纹理和材质。
-
- 作者:Yunsong Zhou、Linyan Huang、Qingwen Bu、Jia Zeng、Tianyu Li、Hang Qiu、Hongzi Zhu、Minyi Guo、Yu Qiao、Hongyang Li ECCV 2024
- 上海人工智能实验室、上海交通大学、加州大学河滨分校
- 发表日期:2024年3月7日
- 任务:基准测试与场景理解
- 代码:ELM
- 摘要:
- ELM是一种具身化语言模型,用于理解时空维度上的长期驾驶场景。
RAG-Driver:基于检索增强上下文学习的多模态大语言模型驱动的可泛化驾驶解释
- 袁建豪、孙书阳、丹尼尔·奥梅扎、赵博、保罗·纽曼、拉尔斯·昆策、马修·加德
- 出版方:牛津大学、北京智源人工智能研究院
- 发表日期:2024年2月16日
- 任务:可解释性驾驶
- 项目:RAG-Driver
- 摘要:
- RAG-Driver是一种具备检索增强上下文学习能力的多模态大语言模型,专为具有强大零样本泛化能力的可泛化、可解释的端到端驾驶设计。
- 在BDD-X(分布内)和SAX(分布外)基准测试中均达到最先进的动作解释与论证性能。
-
- 傅道成、雷文杰、温立成、蔡品隆、毛松、窦敏、史博天、乔宇
- 出版方:上海人工智能实验室、浙江大学
- 发表日期:2024年2月2日
- 项目:LimSim++
- 摘要:
- LimSim++是LimSim的扩展版本,专为在自动驾驶中应用(M)LLM而设计。
- 引入了一个基于(M)LLM的基础框架,并通过跨多种场景的定量实验进行了系统验证。
-
- 潘晨斌、布尔哈内丁·亚曼、托马索·内斯蒂、阿比鲁普·马利克、亚历山德罗·G·阿列维、塞内姆·韦利帕萨拉尔、任刘 CVPR 2024
- 出版方:雪城大学、博世北美研究院及博世人工智能中心(BCAI)
- 发表日期:2024年1月14日
- 数据集:nuScenes
- 摘要:
- 提出VLP视觉语言规划模型,由ALP和SLP两个创新组件构成,分别从自动驾驶的BEV推理和决策方面提升ADS性能。
- ALP(主体导向的学习范式)将生成的BEV与真实的鸟瞰图地图对齐。
- SLP(以自动驾驶车辆为中心的学习范式)将本车查询特征与本车文本规划特征对齐。
DME-Driver:在自动驾驶中整合人类决策逻辑与3D场景感知
- 韩文成、郭东倩、徐承中、沈健兵
- 出版方:澳门大学CIS、SKL-IOTSC
- 发表日期:2024年1月8日
- 摘要:
- DME-Driver = 决策者 + 执行者 + CL
- 基于UniAD的执行者网络引入OccFormer和规划模块中的文本信息。
- 基于LLaVA的决策者处理来自三种不同模态的输入:当前及先前场景的视觉输入、提示形式的文本输入,以及描述车辆运行状态的当前状态信息。
- CL是一种一致性损失机制,虽略微降低性能指标,但显著增强了执行者与决策者之间的决策一致性。
AccidentGPT:基于多模态大模型的V2X环境感知事故分析与预防
- 王乐宁、任一龙、江涵、蔡品隆、傅道成、王天奇、崔志勇、于海洋、王雪松、周汉初、黄和来、王银海
- 出版单位:北京航空航天大学、上海人工智能实验室、香港大学、中关村实验室、同济大学、中南大学、华盛顿大学西雅图分校
- 发表日期:2023年12月29日
- 项目页面:AccidentGPT
- 摘要:
- AccidentGPT是一款全面的事故分析与预防多模态大模型。
- 集成了多车协同感知,以增强对环境的理解和碰撞规避能力。
- 提供主动远程安全预警和盲区提醒等高级安全功能。
- 为交通警察和管理部门提供实时的交通安全因素智能分析服务。
-
- S P Sharan、Francesco Pittaluga、Vijay Kumar B G、Manmohan Chandraker
- 出版单位:德克萨斯大学奥斯汀分校、NEC美国实验室、加州大学圣地亚哥分校
- 发表日期:2023年12月30日
- 任务:规划
- 环境/数据集:nuPlan闭环非反应式挑战赛
- 项目:LLM-ASSIST
- 摘要:
- LLM-Planner接管PDM-Closed无法处理的场景。
- 提出两种基于LLM的规划器。
- LLM-ASSIST(unc)考虑最无约束的规划问题版本,在该版本中LLM必须直接返回一辆自车的安全未来轨迹。
- LLM-ASSIST(par)则考虑参数化的规划问题版本,在该版本中LLM只需为基于规则的规划器PDM-Closed返回一组参数。
-
- 司马冲浩、卡特琳·伦茨、卡希亚普·奇塔、陈莉、张瀚雪、谢成恩、罗平、安德烈亚斯·盖格、李洪洋 ECCV 2024
- 出版单位:OpenDriveLab、蒂宾根大学、蒂宾根AI中心、香港大学
- 代码:官方
- 发表日期:2023年12月21日
- 摘要:
- DriveLM任务
- 图形VQA将P1-3(感知、预测、规划)推理转化为有向图中的系列问答对(QAs)。
- DriveLM数据
- DriveLM-Carla
- 使用CARLA 0.9.14在Leaderboard 2.0框架下[17]收集数据,并由特权规则型专家进行操作。
- Drive-nuScenes
- 从视频片段中选取关键帧,挑选这些关键帧中的关键对象,随后为这些关键对象标注帧级别的P1−3 QA。部分感知QA来自nuScenes和OpenLane-V2的真值,其余QA则由人工标注。
- DriveLM-Carla
- DriveLM智能体
- DriveLMAgent基于通用视觉-语言模型构建,因此能够利用预训练过程中获得的基础知识。
- DriveLM任务
-
- 安娜-玛丽亚·马库、陈龙、扬·许内尔曼、爱丽丝·卡尔松、贝努瓦·哈诺特、普拉贾瓦尔·奇达南达、索拉布·奈尔、维杰·巴德里纳拉扬、亚历克斯·肯德尔、杰米·肖顿、奥列格·西纳夫斯基
- 出版单位:Wayve
- 任务:VQA + 评估/数据集
- 代码:官方
- 发表日期:2023年12月21日
- 摘要:
- 引入一种用于自动驾驶视频QA的新基准测试,采用学习型文本分类器进行评估。
- 构建伦敦市中心的视频QA数据集,包含419,000个样本及其自由形式的问题和答案。
- 基于Vicuna-1.5-7B模型组合,为该领域确立新的基准。
DriveMLM:将多模态大语言模型与自动驾驶行为规划状态对齐
- 王文海、谢江伟、胡传阳、邹浩明、范佳楠、童文文、温杨、吴思磊、邓汉明、李志琪、田浩、陆雷威、朱锡洲、王小刚、乔宇、戴继峰
- 出版单位:OpenGVLab、上海人工智能实验室、香港中文大学、商汤科技研究院、斯坦福大学、南京大学、清华大学
- 任务:规划 + 解释
- 代码:官方
- 环境:Carla
- 发表日期:2023年12月14日
- 摘要:
- DriveMLM是首个能够在真实模拟器中执行闭环自动驾驶的基于LLM的AD框架。
- 设计了一种用于决策预测的MLLM规划器,并开发了一个数据引擎,可有效生成决策状态及相应的解释性标注,用于模型训练和评估。
- 在CARLA Town05 Long上取得了76.1 DS、0.955 MPI的成绩。
-
- 崔灿、马云生、曹旭、叶文倩、周阳、梁凯钊、陈锦泰、卢俊武、杨子冲、廖贵达、高天仁、李尔龙、唐坤、曹志鹏、周彤、刘傲、闫欣睿、梅淑琪、曹建国、王子然、郑超
- 出版单位:普渡大学
- 发表日期:2023年12月14日
- 项目:官方
- 摘要:
- 介绍基于大语言模型(LLM)的Talk-to-Drive(Talk2Drive)框架,用于处理人类口头命令并结合上下文信息做出自动驾驶决策,以满足用户在安全性、效率和舒适性方面的个性化偏好。
-
- 小田桥孝太郎、井上裕一、山口优、八木沼秀达、塩塚大辉、岛谷博之、岩政浩平、井上义明、山口隆文、五十里幸希、堀内司、徳弘健人、十口雄吾、青木俊介
- 出版单位:日本图灵公司
- 任务:评估
- 发表日期:2023年12月11日
- 摘要:
- 评估两大核心能力:
- 空间感知决策能力,即LLM能够根据坐标信息准确识别空间布局;
- 遵守交通规则的能力,确保LLM在驾驶过程中严格遵守交通法规。
- 评估两大核心能力:
-
- 马云生、崔灿、曹旭、叶文谦、刘培然、陆俊武、阿姆尔·阿卜杜勒拉乌夫、罗希特·古普塔、韩京泰、阿尼凯特·贝拉、詹姆斯·M·雷格、王子然
- 出版单位:普渡大学、伊利诺伊大学厄巴纳-香槟分校、弗吉尼亚大学、InfoTech实验室、丰田汽车北美公司
- 任务:基准测试
- 发表日期:2023年12月7日
- 摘要:
- LaMPilot是首个专为评估基于LLM的智能体在驾驶场景中表现而设计的交互式环境与数据集。
- 包含4,900个场景,专门用于评估自动驾驶中的指令跟踪任务。
驶向未来:基于世界模型的多视角视觉预测与规划在自动驾驶中的应用
- 王宇奇、何佳伟、范璐、李宏鑫、陈云涛、张兆祥
- 出版单位:中科院自动化所、CAIR、香港科学园研究所、中国科学院
- 任务:生成
- 项目:Drive-WM
- 代码:Drive-WM
- 数据集:nuScenes、Waymo开放数据集
- 发表日期:2023年11月29日
- 摘要:
- Drive-WM是一种多视角世界模型,能够在自动驾驶场景中生成高质量、可控且一致的多视角视频。
- 首次探索世界模型在自动驾驶端到端规划中的潜在应用。
-
- 王一轩、焦若晨、郎成田、辛农·西蒙·詹、黄超、王兆然、杨卓然、朱琪
- 出版单位:西北大学、利物浦大学、耶鲁大学
- 任务:规划
- 环境:HighwayEnv
- 代码:官方
- 发表日期:2023年11月28日
- 摘要:
- 将LLM部署为规划中的智能决策者,结合上下文安全学习的安全验证器,以提升整体自动驾驶性能和安全性。
-
- 贾凡、毛伟欣、刘英飞、赵宇成、温玉清、张驰、张翔宇、王天赐
- 出版单位:旷视科技、早稻田大学、中国科学技术大学、Mach Drive
- 任务:生成+规划
- 数据集:nuScenes、大规模私有数据集
- 发表日期:2023年11月22日
- 摘要:
- ADriver-I以视觉-动作对作为输入,自回归地预测当前帧的控制信号。生成的控制信号连同历史视觉-动作对进一步作为条件,用于预测未来帧。
- MLLM(多模态大语言模型)=LLaVA-7B-1.5,VDM(视频扩散模型)=latent-diffusion
- 评价指标:
- 当前帧的速度和转向角的L1误差。
- 生成质量:弗雷歇起始距离(FID)、弗雷歇视频距离(FVD)。
-
- 毛家庚、叶俊杰、钱宇曦、马可·帕沃内、王悦
- 南加州大学、斯坦福大学、NVIDIA
- 任务:生成+规划
- 项目:Agent-Driver
- 数据集:nuScenes
- 发表日期:2023年11月17日
- 摘要:
- Agent-Driver整合了用于动态感知与预测的工具库、存储人类知识的认知记忆,以及模拟人类决策过程的推理引擎。
- 在运动规划方面,沿用GPT-Driver(#GPT-Driver)的方法,使用nuScenes训练集中的真实驾驶轨迹对大语言模型进行一个epoch的微调。
- 神经模块则采用UniAD中的模块。
- 评价指标:
- L2误差(以米为单位)和碰撞率(以百分比计)。
与GPT-4V(ision)同行:视觉-语言模型在自动驾驶中的早期探索
- 文立成、杨雪萌、傅道成、王晓峰、蔡品龙、李鑫、马涛、李颖轩、徐林然、尚登科、朱正、孙绍燕、白业奇、蔡新宇、窦敏、胡双陆、史博天
- 出版单位:上海人工智能实验室、GigaAI、华东师范大学、香港中文大学、WeRide.ai
- 项目:官方
- 数据集:
- 发表日期:2023年11月9日
- 摘要:
- 对GPT-4V在各类自动驾驶场景中的表现进行了全面且多角度的评估。
- 测试了GPT-4V在场景理解、推理以及扮演驾驶员等方面的能力。
-
- 王世义、朱宇轩、李志恒、王宇彤、李莉、何正兵
- 出版单位:清华大学、中国科学院自动化研究所、麻省理工学院
- 任务:规划
- 发表日期:2023年10月17日
- 摘要:
- 设计了一个通用框架,将大语言模型嵌入为车辆的“副驾驶”,使其能够根据提供的信息,在满足人类意图的前提下完成特定的驾驶任务。
-
- 高瑞源、陈凯、谢恩泽、洪兰青、李振国、叶德彦、许强
- 出版单位:香港中文大学、香港科技大学、华为诺亚方舟实验室
- 任务:生成
- 项目:MagicDrive
- 代码:MagicDrive
- 数据集:nuScenes
- 发表日期:2023年10月13日
- 摘要:
- MagicDrive通过独立编码道路地图、物体边界框和相机参数,利用3D标注中的几何信息,实现精确的几何引导合成,从而生成高度逼真的图像。这种方法有效解决了多摄像头视角一致性的问题。
- 然而,在一些复杂场景中,例如夜间场景和未见过的天气条件下,仍然面临巨大挑战。
-
- 崔灿、马云生、曹旭、叶文谦、王子然
- 出版单位:普渡大学、伊利诺伊大学厄巴纳-香槟分校、弗吉尼亚大学、PediaMed.AI。
- 任务:规划
- 项目:视频
- 环境:HighwayEnv
- 发表日期:2023年10月12日
- 摘要:
- 利用专门工具发挥大型语言模型的语言和上下文理解能力,将LLM的语言与推理能力融入自动驾驶车辆。
-
- 沙浩、穆瑶、蒋宇轩、陈力、徐晨峰、罗平、李恩波、富冢正敏、詹伟、丁明宇
- 出版单位:清华大学、香港大学、加州大学伯克利分校
- 任务:规划/控制
- 代码:官方
- 环境:
- 发表日期:2023年10月4日
- 摘要:
- 利用大型语言模型通过思维链提供高层次决策。
- 将高层决策转化为数学表达式,以指导底层控制器(MPC)。
- 评价指标:失败/碰撞次数、效率、时间、惩罚分数。
-
- 陈龙、奥列格·西纳夫斯基、扬·许内尔曼、爱丽丝·卡恩松德、安德鲁·詹姆斯·威尔莫特、丹尼·伯奇、丹尼尔·芒德、杰米·肖顿
- 出版单位:Wayve公司
- 任务:规划+VQA
- 代码:官方
- 模拟器:定制开发的真实2D模拟器(该模拟器未开源)。
- 数据集:Driving QA,由RL专家在模拟器中收集的数据。
- 发表日期:2023年10月3日
- 摘要:
- 提出一种独特的对象级多模态LLM架构(Llama2+Lora),仅使用向量化表示作为输入。
- 开发了一个包含16万个问答对的新数据集,源自1万个驾驶场景(控制指令由RL(PPO)收集,问答对由GPT-3.5生成)。
- 评价指标:
- 交通信号灯检测准确率
- 交通信号灯距离预测的MAE
- 加速度预测的MAE
- 制动压力预测的MAE
- 转向角度预测的MAE
-
- 维克兰特·德万甘、图沙尔·乔杜里、希瓦姆·钱多克、舒巴姆·普里亚达尔尚、阿努什卡·贾因、阿伦·K·辛格、西达尔特·斯里瓦斯塔瓦、克里希纳·穆尔蒂·贾塔瓦拉布拉胡拉、K·马达瓦·克里希纳
- 出版单位:海得拉巴国际信息技术学院、英属哥伦比亚大学、塔尔图大学、TensorTour公司、麻省理工学院
- 项目页面:官方
- 代码:Talk2BEV
- 发表日期:2023年10月3日
- 摘要:
- 介绍Talk2BEV,这是一种用于自动驾驶场景中鸟瞰图(BEV)地图的大规模视觉语言模型(LVLM)接口。
- 无需任何训练或微调,直接依赖预训练的图文模型。
- 开发并发布Talk2BEV-Bench基准测试,涵盖1000个由人工标注的BEV场景,包含来自NuScenes数据集的超过2万条问题及真实答案。
-
- 毛家庚、钱宇曦、赵航、王悦
- 出版单位:南加州大学、清华大学
- 任务:规划(微调预训练模型)
- 项目:官方
- 数据集:nuScenes
- 代码:GPT-Driver
- 发表日期:2023年10月2日
- 摘要:
- 将运动规划视为语言建模问题。
- 通过使用OpenAI微调API的策略,使LLM的输出与人类驾驶行为保持一致。
- 利用LLM生成驾驶轨迹。
- 评价指标:
- L2指标和碰撞率
-
- 作者:Anthony Hu、Lloyd Russell、Hudson Yeo、Zak Murez、George Fedoseev、Alex Kendall、Jamie Shotton、Gianluca Corrado
- 出版方:Wayve
- 任务:生成
- 数据集:
- 训练数据集包含4,700小时、25Hz帧率的专有驾驶数据,这些数据于2019年至2023年间在英国伦敦收集,共计约4.2亿张独特图像。
- 验证数据集包含400小时的驾驶数据,来自未纳入训练集的行驶记录。
- 文本数据来源于在线叙述或离线元数据源。
- 发表日期:2023年9月29日
- 摘要:
- 介绍GAIA-1,这是一种利用视频(预训练的DINO)、文本(T5-large)和动作输入来生成逼真驾驶场景的生成式世界模型。
- 它可作为有价值的神经网络模拟器,用于生成无限量的数据。
-
- 作者:Licheng Wen、Daocheng Fu、Xin Li、Xinyu Cai、Tao Ma、Pinlong Cai、Min Dou、Botian Shi、Liang He、Yu Qiao ICLR 2024
- 出版方:上海人工智能实验室、华东师范大学、香港中文大学
- 发表日期:2023年9月28日
- 任务:规划
- 环境:
- HighwayEnv
- CitySim,一个基于无人机的车辆轨迹数据集。
- 摘要:
- 提出DiLu框架,该框架结合了推理模块和反思模块,使系统能够基于常识知识进行决策,并不断进化。
SurrealDriver:基于大语言模型的城市环境生成式驾驶员代理仿真框架
- 作者:Ye Jin、Xiaoxi Shen、Huiling Peng、Xiaoan Liu、Jingli Qin、Jiayang Li、Jintao Xie、Peizhong Gao、Guyue Zhou、Jiangtao Gong
- 关键词:人机交互、驾驶员模型、代理、生成式AI、大语言模型、仿真框架
- 环境:CARLA
- 出版方:清华大学
- 摘要:提出一种基于大语言模型(LLMs)的生成式驾驶员代理仿真框架,能够感知复杂的交通场景并提供逼真的驾驶操作。
像说话一样驾驶:在自动驾驶车辆中实现与大语言模型的人类般交互
- 作者:Can Cui、Yunsheng Ma、Xu Cao、Wenqian Ye、Ziran Wang
- 出版方:普渡大学、PediaMed.AI实验室、弗吉尼亚大学
- 任务:规划
- 发表日期:2023年9月18日
- 摘要:
- 提供一个将大语言模型(LLMs)集成到AD中的综合框架。
你能描述一下正在发生的事情吗?将预训练的语言编码器集成到自动驾驶轨迹预测模型中
- 作者:Ali Keysan、Andreas Look、Eitan Kosman、Gonca Gürsun、Jörg Wagner、Yu Yao、Barbara Rakitsch
- 出版方:博世人工智能中心、图宾根大学
- 任务:预测
- 数据集:nuScenes
- 发表日期:2023年9月13日
- 摘要:
- 将预训练的语言模型作为基于文本的输入编码器集成到AD轨迹预测任务中。
- 评估指标:
- 最小平均位移误差(minADEk)
- 最终位移误差(minFDEk)
- 超过2米的漏检率
-
- 作者:Siyao Zhang、Daocheng Fu、Zhao Zhang、Bin Yu、Pinlong Cai
- 出版方:北京航空航天大学、智能交通技术与系统重点实验室、上海人工智能实验室
- 任务:规划
- 代码:官方
- 发表日期:2023年9月13日
- 摘要:
- 展示TrafficGPT——ChatGPT与交通基础模型的融合。
- 通过定义一系列提示,弥合了大语言模型与交通基础模型之间的关键鸿沟。
-
- 作者:Xinpeng Ding、Jianhua Han、Hang Xu、Wei Zhang、Xiaomeng Li
- 出版方:香港科技大学、华为诺亚方舟实验室
- 任务:检测+VQA
- 数据集:DRAMA
- 发表日期:2023年9月11日
- 摘要:
- 提出HiLM-D(迈向自动驾驶多模态大语言模型中的高分辨率理解),这是一种将HR信息高效融入MLLMs以完成ROLISP任务的方法。
- ROLISP旨在识别、解释并定位对自车构成风险的对象,同时预测其意图并给出建议。
- 评估指标:
- LLM指标:BLEU4、CIDEr、METEOR、SPICE。
- 检测指标:mIoU、IoUs等。
MTD-GPT:用于无信号交叉口自动驾驶的多任务决策GPT模型
- 刘家琪、彭航、肖琦、王建强、孙健。ITSC 2023
- 出版单位:同济大学、清华大学
- 任务:预测
- 环境:HighwayEnv
- 发表日期:2023年7月30日
- 摘要:
- 设计了一套利用强化学习算法训练单任务决策专家并使用专家数据的流程。
- 提出MTD-GPT模型,用于自动驾驶车辆在无信号交叉口的多任务(左转、直行、右转)决策。
-
- 唐云、安东尼奥·A·布鲁托·达科斯塔、张希哲、欧文·帕特里克、西达塔·卡斯特吉尔、保罗·詹宁斯。ITSC 2023
- 出版单位:华威大学
- 任务:问答
- 发表日期:2023年7月17日
- 摘要:
- 开发了一款基于Web的知识蒸馏助手,通过提示工程和LLM ChatGPT实现运行时的监督与灵活干预。
-
- 傅道成、李欣、温立成、窦敏、蔡品龙、史博天、乔宇
- 出版单位:上海人工智能实验室、华东师范大学
- 任务:规划
- 代码:官方
- 环境:HighwayEnv
- 发表日期:2023年7月14日
- 摘要:
- 识别出三种关键能力:推理、解释与记忆(积累经验与自我反思)。
- 将LLM应用于自动驾驶中的决策环节,以解决长尾场景问题并提升可解释性。
- 在闭环离线数据中验证了其可解释性。
-
- 钟子渊、戴维斯·伦佩、陈宇晓、鲍里斯·伊万诺维奇、曹宇龙、徐丹菲、马可·帕沃内、雷百石
- 出版单位:哥伦比亚大学、NVIDIA研究院、斯坦福大学、佐治亚理工学院
- 任务:扩散
- 发表日期:2023年7月10日
- 摘要:
- 提出CTG++,一种语言引导的场景级条件扩散模型,用于生成符合查询要求的逼真交通仿真。
- 利用LLM将用户查询转化为可微分的损失函数,并提出一种基于时空Transformer架构的场景级条件扩散模型,将该损失函数转换为逼真的、符合查询要求的轨迹。
工作坊
展开/收起
- 用于自动驾驶的大规模语言与视觉模型(LLVM-AD)研讨会 @ WACV 2024
- 出版单位:腾讯地图高清地图T.Lab、伊利诺伊大学厄巴纳-香槟分校、普渡大学、弗吉尼亚大学
- 挑战1:MAPLM:用于地图与交通场景理解的大规模视觉-语言数据集
- 数据集:下载
- 任务:问答
- 代码:https://github.com/LLVM-AD/MAPLM
- 描述:MAPLM结合点云鸟瞰图和全景图像,提供丰富的道路场景图像集合。它包含多层次的场景描述数据,有助于模型在复杂多样的交通环境中导航。
- 评价指标:
- 帧整体准确率(FRM):若关于某一帧的所有封闭式问题均回答正确,则该帧被视为正确。
- 问题整体准确率(QNS):若某一个问题的答案正确,则该问题被视为正确。
- LAN:当前道路上有多少条车道?
- INT:主干道上是否存在路口、交叉口或变道区域?
- QLT:该图像中当前路段的点云数据质量如何?
- SCN:图片中呈现的是哪种道路场景?(SCN)
- 挑战2:车内用户指令理解(UCU)
- 数据集:下载
- 任务:问答
- 代码:https://github.com/LLVM-AD/ucu-dataset
- 描述:
- 本数据集专注于理解自动驾驶汽车环境下的用户指令。它包含1,099条已标注的指令,每条指令都是用户向车辆发出的请求语句。
- 评价指标:
- 指令级别准确率:若八项答案全部正确,则该指令被视为被正确理解。
- 问题级别准确率:按单个问题进行评估。
数据集
展开/收起
格式:
- [标题](数据集链接) [链接]
- 作者1、作者2、作者3…
- 关键词
- 实验环境或任务
-
- 冯浩杰、张培志、田梦洁、张欣睿、李卓仁、黄俊鹏、王秀荣、朱俊凡、王建洲、尹东晓、熊璐
- 发表日期:2026年2月24日
- 任务:VQA
- 数据集:IEDD
- 摘要:
- 提出交互式增强驾驶数据集(IEDD),以解决自动驾驶中视觉-语言-行动(VLA)模型面临的交互场景稀疏及多模态对齐不足的问题。
- 开发了一套可扩展的流水线,从自然驾驶数据中挖掘百万级别的交互片段,并构建了IEDD-VQA数据集,其中合成的BEV视频将语义动作与结构化语言严格对齐。
- 提供基准结果,评估了十种主流视觉语言模型(VLMs),以展示该数据集在评估和微调自动驾驶模型推理能力方面的重用价值。
-
- 刘佳鑫、闫翔宇、彭亮、杨磊、张凌军、罗岳晨、陶跃明、谭宇轩、李牧、张雷、战子琪、郭赛、王宏、李俊
- 发表日期:2025年11月28日
- 任务:VQA
- 数据集:PotentialRiskQA
- 摘要:
- 引入PotentialRiskQA,这是一个全新的视觉-语言数据集,用于在潜在风险变得可见之前对其进行推理,包含场景描述、前兆及推断结果的结构化标注。
- 提出PR-Reasoner框架,该框架基于视觉语言模型,专为车载潜在风险推理设计,在使用新数据集进行微调后表现出显著的性能提升。
-
- 石原圭史、佐佐木健人、高桥翼、盐野大辉、山口优
- 发表日期:2025年8月14日
- 项目页面:STRIDE-QA
- 任务:VQA
- 数据集:STRIDE-QA
- 摘要:
- STRIDE-QA是一个大规模的视觉问答(VQA)数据集,旨在从自我中心视角进行物理基础的时空推理,数据来源于东京100小时的多传感器驾驶数据。
- 该数据集提供28.5万帧上的1600万个问答对,并配有密集的自动标注,支持以物体为中心和以自我为中心的推理,涵盖三种需要空间定位和时间预测的新颖问答任务。
- 基准测试表明,在STRIDE-QA上微调后的VLMs相比通用VLMs几乎为零的得分,其性能大幅提升(空间定位提升55%,预测一致性提升28%),为自动驾驶系统中可靠的VLMs奠定了基础。
-
- 新井英久、三轮圭太、佐佐木健人、山口优、渡边浩平、青木俊介、山本一成 WACV 2025 口头报告
- 出版单位:图灵公司
- 发表日期:2024年12月2日
- 代码:CoVLA
- 摘要:
- CoVLA(综合视觉-语言-行动)数据集是一个庞大的数据集,包含了超过80小时的真实驾驶视频。该数据集采用了一种新颖的可扩展方法,基于自动化数据处理和字幕生成流水线,生成准确的驾驶轨迹,并配以详细的自然语言描述,涵盖驾驶环境和操作动作。
Rank2Tell:用于联合重要性排序与推理的多模态驾驶数据集
- 恩娜·萨奇德瓦、纳库尔·阿加瓦尔、苏哈斯·春迪、肖恩·鲁洛夫斯、李嘉辰、贝赫扎德·达里乌什、崔智浩、迈克尔·科亨德费尔
- 出版单位:本田研究院、斯坦福大学
- 发表日期:2023年9月10日
- 摘要:
- 这是一个多模态的自我中心数据集,用于对重要性级别进行排序并说明其原因。
- 引入了一个联合模型,用于同时进行重要性级别排序和自然语言字幕生成,以对该数据集进行基准测试。
-
- 发表者:Sima, Chonghao;Renz, Katrin;Chitta, Kashyap;Chen, Li;Zhang, Hanxue;Xie, Chengen;Luo, Ping;Geiger, Andreas;Li, Hongyang ECCV 2024
- 数据集:DriveLM
- 发表日期:2023年8月
- 摘要:
- 基于nuScenes数据集构建数据集。
- 感知类问题要求模型识别场景中的物体。
- 预测类问题要求模型预测场景中重要物体的未来状态。
- 规划类问题则要求模型给出合理的规划动作,并避免危险行为。
WEDGE:基于生成式视觉-语言模型构建的多天气自动驾驶数据集
- Aboli Marathe、Deva Ramanan、Rahee Walambe、Ketan Kotecha。CVPR 2023
- 发表单位:卡内基梅隆大学、共生国际大学
- 数据集:WEDGE
- 发表日期:2023年5月12日
- 摘要:
- 基于生成式视觉-语言模型构建的多天气自动驾驶数据集。
NuScenes-QA:面向自动驾驶场景的多模态视觉问答基准
- Tianwen Qian、Jingjing Chen、Linhai Zhuo、Yang Jiao、Yu-Gang Jiang
- 发表单位:复旦大学
- 数据集:NuScenes-QA
- 摘要:
- NuScenes-QA基于34,149个视觉场景提供了459,941对问答,其中来自28,130个场景的376,604道题用于训练,而来自6,019个场景的83,337道题则用于测试。
- 多视角图像和点云首先通过特征提取主干网络处理,以获得BEV特征。
-
- Srikanth Malla、Chiho Choi、Isht Dwivedi、Joon Hee Choi、Jiachen Li
- 发表单位:
- 数据集:DRAMA
- 摘要:
- 介绍了一种新颖的数据集DRAMA,该数据集提供了与重要物体相关的驾驶风险的语言描述(重点在于原因),可用于评估驾驶场景中多种视觉描述能力。
-
- 数据集:Nuprompt(未公开)
- 先前摘要
-
- Jinkyu Kim、Anna Rohrbach、Trevor Darrell、John Canny、Zeynep Akata ECCV 2018。
- 发表单位:加州大学伯克利分校、萨尔兰信息学园区、阿姆斯特丹大学
- BDD-X数据集
-
- Jinkyu Kim、Teruhisa Misu、Yi-Ting Chen、Ashish Tawari、John Canny CVPR 2019
- 发表单位:加州大学伯克利分校、本田美国研究院
- HAD数据集
许可证
“自动驾驶领域优秀LLM资源”根据Apache 2.0许可证发布。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。