HunyuanImage-2.1
HunyuanImage-2.1 是腾讯开源的一款高效扩散模型,专为生成高分辨率(2K)文本图像而设计。它主要解决了传统 AI 绘图在超高清画质下细节模糊、文字渲染不准以及多语言理解能力不足的痛点,能够轻松产出具有电影级构图和清晰细节的图像。
这款工具非常适合设计师、内容创作者、AI 研究人员及开发者使用。无论是需要高质量素材的专业人士,还是希望探索前沿技术的开发者,都能从中受益。普通用户也可通过官方网页或 ComfyUI 工作流直接体验其强大的生成能力。
技术亮点方面,HunyuanImage-2.1 采用独特的两阶段架构:第一阶段结合多模态大语言模型与多语言字符感知编码器,显著提升了图文对齐精度及中英文提示词的理解能力;第二阶段引入精炼模型,进一步优化画质并减少伪影。此外,它支持多种画幅比例,并凭借先进的 VAE 压缩技术和 FP8 量化方案,实现了在 24GB 显存下即可生成 2K 图像的高效推理。目前,该模型已在开源文生图榜单中名列前茅,是追求极致画质与多语言支持用户的理想选择。
使用场景
某电商设计团队需要在短时间内为“中秋国潮”营销活动生成一系列高分辨率、包含精准中文书法字体的宣传海报。
没有 HunyuanImage-2.1 时
- 分辨率受限严重:生成的图片通常仅为 1024×1024,放大后细节模糊,无法满足线下大屏或高清印刷的 2K 需求,后期需耗费大量时间进行超分修复。
- 中文文字渲染失败:主流模型对汉字理解能力弱,海报中的“月圆人团圆”等标语常出现笔画缺失、乱码或完全无法生成的情况。
- 多物体控制力差:当提示词包含“玉兔、月饼、灯笼”等多个特定元素时,画面容易出现物体融合、数量错误或位置混乱。
- 跨语言理解偏差:设计师使用中文描述复杂的国潮风格时,模型往往误解语义,导致生成的画面风格与预期大相径庭。
使用 HunyuanImage-2.1 后
- 原生 2K 高清直出:直接生成 2048×2048 分辨率图像,画面纹理清晰、构图电影级精致,无需后期超分即可投入印刷和使用。
- 精准汉字呈现:依托 ByT5 字符感知编码器和 MLLM 架构,海报中的中文书法字体笔画准确、风格统一,完美还原设计意图。
- 复杂场景精准掌控:能够准确区分并布局多个独立物体,玉兔的姿态、月饼的纹样及灯笼的光影均能按提示词精确呈现,无奇怪伪影。
- 原生中文语义对齐:直接使用中文提示词即可精准捕捉“国潮”、“水墨”等风格特征,大幅降低了编写和翻译提示词的沟通成本。
HunyuanImage-2.1 通过原生支持 2K 分辨率与高精度中文渲染,将电商海报的创作周期从“天”级缩短至“分钟”级,真正实现了创意到成品的无缝落地。
运行环境要求
- Linux
- 必需 NVIDIA GPU (支持 CUDA)
- 生成 2K (2048x2048) 图像最低需 24GB 显存(需开启模型 CPU 卸载和 FP8 量化)
- 若显存充足可关闭卸载以提升速度
未说明

快速开始

HunyuanImage-2.1:用于高分辨率(2K)文生图的高效扩散模型
🤗 HuggingFace | 💻 官方网站(官网)试用我们的模型!
本仓库包含我们HunyuanImage-2.1的PyTorch模型定义、预训练权重以及推理/采样代码。您可以在官方网站(官网)上直接试用我们的模型,并在我们的项目页面上找到更多可视化效果。
🔥🔥🔥 最新动态
- 2025年9月18日:✨ 试用PromptEnhancer-32B模型,获得更高质量的提示词增强!。
- 2025年9月18日:✨ HunyuanImage-2.1的ComfyUI工作流现已可用!
- 2025年9月16日:👑 我们在Arena的文生图开源模型排行榜上夺得第一名。排行榜
- 2025年9月12日:🚀 发布了FP8量化模型!现在仅需24GB显存即可生成2K图像!
- 2025年9月8日:🚀 发布了HunyuanImage-2.1的推理代码和模型权重。
简介
我们非常高兴地推出HunyuanImage-2.1,这是一款170亿参数的文生图模型,能够生成2K(2048 × 2048)分辨率的图像。
我们的架构分为两个阶段:
- 基础文生图模型:第一阶段是一个文生图模型,使用了两个文本编码器:一个多模态大语言模型(MLLM),用于提升图像与文本的对齐效果;另一个是多语言、字符感知编码器,用于增强多种语言下的文本渲染能力。
- 精修模型:第二阶段引入了一个精修模型,进一步提升图像质量和清晰度,同时减少伪影。
👑 我们在Arena的文生图开源模型排行榜上获得了第一名。

🎉 HunyuanImage-2.1 主要特性
- 高质量生成:高效生成超高清(2K)图像,构图极具电影感。
- 多语言支持:原生支持中文和英文提示词。
- 先进架构:基于多模态、单流与双流结合的DiT(扩散Transformer)骨干网络。
- 字形感知处理:利用ByT5的文本渲染能力,提升文本生成的准确性。
- 灵活的宽高比:支持多种图像宽高比(1:1、16:9、9:16、4:3、3:4、3:2、2:3)。
- 提示词增强:自动改写提示词,以提高描述准确性和视觉质量。
📜 系统要求
硬件和操作系统要求:
支持CUDA的NVIDIA GPU。
目前最低要求: 生成2048×2048图像需24GB显存。
注意: 上述显存要求是在启用模型CPU卸载和FP8量化的情况下测得的。如果您的显存充足,可以关闭卸载以提升推理速度。
支持的操作系统:Linux。
🛠️ 依赖与安装
- 克隆仓库:
git clone https://github.com/Tencent-Hunyuan/HunyuanImage-2.1.git
cd HunyuanImage-2.1
- 安装依赖:
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
🧱 下载预训练模型
预训练模型的下载详情请见此处。
🔑 使用方法
提示词增强
提示词增强在使我们的模型生成高质量图像方面起着关键作用。通过撰写更长、更详细的提示词,生成的图像将得到显著提升。我们鼓励您编写全面且富有描述性的提示词,以获得最佳的图像质量。
我们强烈推荐您试用PromptEnhancer-32B模型,以获得更高质量的提示词增强效果。
文生图
HunyuanImage-2.1仅支持2K图像生成(例如,1:1图像为2048×2048,16:9图像为2560×1536等)。生成1K分辨率的图像会导致伪影。
此外,我们强烈建议使用完整的生成流程以获得更好的质量(即启用提示词增强和精修)。
| 模型类型 | 模型名称 | 描述 | num_inference_steps | guidance_scale | shift |
|---|---|---|---|---|---|
| 基础文生图模型 | hunyuanimage2.1 | 未蒸馏模型,用于获得最佳质量。 | 50 | 3.5 | 5 |
| 蒸馏文生图模型 | hunyuanimage2.1-distilled | 蒸馏模型,用于更快的推理 | 8 | 3.25 | 4 |
| 精修模型 | hunyuanimage-refiner | 精修模型 | N/A | N/A | N/A |
import os
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True'
import torch
from hyimage.diffusion.pipelines.hunyuanimage_pipeline import HunyuanImagePipeline
# 支持的模型名称:hunyuanimage-v2.1,hunyuanimage-v2.1-distilled
model_name = "hunyuanimage-v2.1"
pipe = HunyuanImagePipeline.from_pretrained(model_name=model_name,use_fp8=True)
pipe = pipe.to("cuda")
# 输入提示
prompt = "一只可爱、卡通风格的拟人企鹅毛绒玩具,有着蓬松柔软的毛发,正站在一间画室里,戴着一条红色针织围巾和一顶印有‘腾讯’二字的红色贝雷帽,神情专注地拿着画笔,正在绘制一幅蒙娜丽莎的油画,画面以写实的摄影风格呈现。"
# 使用不同宽高比生成图像
aspect_ratios = {
"16:9": (2560, 1536),
"4:3": (2304, 1792),
"1:1": (2048, 2048),
"3:4": (1792, 2304),
"9:16": (1536, 2560),
}
width, height = aspect_ratios["1:1"]
image = pipe(
prompt=prompt,
width=width,
height=height,
# 如果已经使用提示增强功能来优化提示,则禁用重新提示
use_reprompt=False, # 启用提示增强功能(可能会增加显存占用)
use_refiner=True, # 启用精修模型
# 对于蒸馏模型,使用8步以加快推理速度。
# 对于非蒸馏模型,使用50步以获得更好的质量。
num_inference_steps=8 if "distilled" in model_name else 50,
guidance_scale=3.25 if "distilled" in model_name else 3.5,
shift=4 if "distilled" in model_name else 5,
seed=649151,
)
image.save("generated_image.png")
更多案例
我们的模型能够遵循复杂的指令,生成高质量、富有创意的图像。

我们建议使用更长、更详细的提示词。您也可以尝试我们提供的提示词。
| 序号 | 用户提示 | 图像 |
|---|---|---|
| 1 | 一座宏伟教堂的内部,穹顶下方的中央矗立着一尊小巧的维纳斯雕像,微微侧对镜头。雕像没有双手,布满裂纹,表面若干古老的水泥片剥落,露出内部真人质感的牛奶肌肤。雕像穿着薄薄的白色婚纱,在雕像的身后,一只浮空水泥断手轻轻提起长长的婚纱拖尾;在雕像的头顶上方,另一只浮空水泥断手正为她戴上一个由白色花朵组成的花环,雕像本身是没有双手的。教堂穹顶上布满彩色玻璃窗,一束阳光从上往下照射到雕像上,形成丁达尔效应,光斑点点洒在雕像的脸庞和胸前。充满神性的光辉,背景微微虚化,物体的边缘模糊柔和。拉斐尔前派的梦幻朦胧美学风格。 |  |
| 2 | 一张超写实的照片,展示了一个水晶球立体模型,它坐落在柔软的森林苔藓之上,周围洒满了散射的阳光。模型内部精细地还原了一间腾讯会议室、一座会说话的聊天气泡雕塑,以及几只欢快的企鹅——其中一只戴着毕业帽,其余的则在踢足球并挥舞着小旗帜。水晶球的底座上用醒目的白色立体大字写着“腾讯”。背景柔和地虚化,充满焦外光斑效果,更加突出了球体中那些可爱而生动的细节。 |  |
| 3 | 一位年迈意大利男士的特写肖像,他皮肤深深褶皱,眼神深邃而富有表现力,留着修剪整齐的白色小胡子。他的橄榄色肤色透露出岁月与阳光的痕迹,头戴一顶微微歪向一侧的平顶帽。他嘴角微扬,流露出温暖与智慧,手中端着一小杯浓缩咖啡。背景是柔和虚化的质朴石墙,上面爬满了常春藤,整体以写实的摄影风格呈现。 |  |
| 4 | 一只打开的复古旅行箱,置于中性且光线柔和的背景之上。箱子由深棕色的旧皮革制成,表面可见明显的磨损和折痕,内衬则是深色的柔软织物。箱内精心打造了一幅中国微型景观,其中包括蜿蜒于模型山峦之间的长城、故宫的宝塔屋顶,以及兵马俑的缩影,这些元素与生机勃勃的绿色稻田交织在一起。箱子侧面还标注着“China”字样。整个场景沐浴在温暖而空灵的光线下,镜头晕影营造出梦幻般的氛围,亮点柔和而明亮。写实风格,纹理极其细腻,光影极具电影感。 |  |
为提升生成图像的质量和细节,我们使用了一个提示重写模型。该模型会自动增强用户提供的文本提示,添加详细且描述性的信息。
| 序号 | 用户提示 | 增强后的提示 | 图像 |
|---|---|---|---|
| 1 | 塞伦盖蒂平原的野生动物海报。大眼睛的Q版探险家骑着友好的小狮子。“塞伦盖蒂:冒险的咆哮”采用奇幻风格字体。“梦想在此肆意奔腾”标语。温暖的黄色和柔和的棕色。 | 这是一张以塞伦盖蒂平原为主题的野生动物海报设计,画面中央是一位骑在小狮子背上的Q版探险家,背景则是起伏的山丘。构图顶部用大号、充满趣味的装饰性卷曲字母写着标题“塞伦盖蒂:冒险的咆哮”。主体场景中,一位大头小身的Q版探险家戴着绿色的探险帽,背着背包,双手抓住小狮子的鬃毛,面带惊喜地向前望去。小狮子则有着浅棕色的鬃毛和微笑的表情,正迈步向前,身体以温暖的橙色为主色调。背景部分描绘了塞伦盖蒂平原的连绵丘陵与稀树草原,整体色调为温暖的黄色和柔和的棕色。主图下方用较小而优雅的字体写着标语“梦想在此肆意奔腾”。整幅作品呈现出一种将可爱Q版插画风格与俏皮奇幻字体相结合的海报设计感。 |  |
| 2 | 纽约市活力四射的海报。动漫风格的女商人正在路边招手拦出租车,周围是摩天大楼和时代广场的广告牌。“纽约:璀璨抱负”采用都市涂鸦字体。“成就每一个梦想”标语。饱和的黄色、红色和鲜明的蓝色。 | 这是一张充满活力的纽约市海报,画面中央是一位正在招手拦出租车的动漫风格女商人。她有着大而富有表现力的眼睛,一头黑色短发,身穿带有动感线条的职业蓝色西装套装,站在繁忙的街道上,双臂伸展呼唤一辆迎面驶来的经典黄色出租车。背景中,高耸入云的摩天大楼拥有流畅的动漫风格建筑造型,上面布满了时代广场标志性的鲜艳发光广告牌和霓虹灯招牌。海报顶部用大型、风格化的都市涂鸦字体写着“纽约:璀璨抱负”,边缘仿佛喷漆效果一般。在这句主标题下方,用较小而简洁的字体写着标语“成就每一个梦想”。整个画面运用了饱和度极高的色彩,以明亮的黄色、红色和锐利的蓝色为主调。整体呈现出动漫插画与平面设计相融合的效果。 |  |
| 3 | 一幅艺术工作室人像,捕捉到一位高级时装模特极具冲击力的动态姿势。她的脸庞宛如一块前卫妆容的画布,以大胆的几何形状和原色点缀。她身着一件雕塑感十足的非常规服装,强调干净利落的线条与形态。现场由戏剧性的灯光照明,形成强烈的明暗对比,使她的面部特征在抽象模糊的彩色背景中格外突出。照片以写实风格呈现。 | 一幅艺术工作室人像,拍摄了一位高级时装模特极具冲击力的动态姿势,她身体扭转,一只手臂高高举起,展现出力量与动感。她的脸部成为前卫妆容的画布,以大胆的几何图形和原色进行创作:额头处绘有鲜艳的黄色三角形,眼窝周围则用电光蓝线条勾勒。她身着一件由硬挺哑光白色面料制成的雕塑感十足的非常规服装,不对称的衣片环绕躯干,凸显出干净利落的线条与形态。摄影师使用了戏剧性的灯光效果,侧方强光投下清晰的阴影,将她的面部轮廓与身体曲线从紫色和橙色交织的抽象模糊背景中凸显出来,营造出散景般的视觉效果。照片以写实风格呈现。 |  |
| 4 | 一位厨师的环境肖像,定格在他专注神情的繁忙厨房之中。他手中握着厨具,目光牢牢锁定在工作上,尽显热情与创造力。背景则是一片流动的模糊影像,不锈钢操作台等元素若隐若现,在温暖的环境光映衬下显得格外柔和。照片以写实风格呈现。 | 一张男性厨师在繁忙厨房中工作的环境肖像。作为画面主体,厨师自胸部以上被拍摄,他眉头紧锁,目光低垂,专注地看着手中的厨具。他身着白色厨师服和传统厨师帽,脸上和衣服上还沾着些许面粉。他的手中握着一把巨大的厨师刀和一把金属铲,似乎正准备在看不见的烹饪台上施展厨艺。背景则是一片动态模糊的影像,不锈钢操作台、锅具等厨房设备的轮廓若隐若现,暗示着这里一片忙碌的景象。头顶暖光灯散发出金色光芒,为厨师的制服和工具镀上一层光晕。照片采用写实风格,通过浅景深突出主体,同时传达出厨房内的活力与创意。 |  |
📈 对比
SSAE 评估
SSAE(结构化语义对齐评估)是一种基于先进多模态大语言模型(MLLM)的智能图像-文本对齐评估指标。我们提取了12个类别下的3500个关键点,然后利用多模态大语言模型,通过比较生成的图像与这些关键点,并根据图像的视觉内容进行自动评估和打分。平均图像准确率表示所有关键点上的逐张图像平均得分,而全局准确率则直接计算所有关键点的平均得分。
| 模型 | 开源 | 平均图像准确率 | 全局准确率 | 主要主体 | 次要主体 | 场景 | 其他 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 名词 | 关键属性 | 其他属性 | 动作 | 名词 | 属性 | 动作 | 名词 | 属性 | 镜头 | 风格 | 构图 | ||||
| FLUX-dev | ✅ | 0.7122 | 0.6995 | 0.7965 | 0.7824 | 0.5993 | 0.5777 | 0.7950 | 0.6826 | 0.6923 | 0.8453 | 0.8094 | 0.6452 | 0.7096 | 0.6190 |
| Seedream-3.0 | ❌ | 0.8827 | 0.8792 | 0.9490 | 0.9311 | 0.8242 | 0.8177 | 0.9747 | 0.9103 | 0.8400 | 0.9489 | 0.8848 | 0.7582 | 0.8726 | 0.7619 |
| Qwen-Image | ✅ | 0.8854 | 0.8828 | 0.9502 | 0.9231 | 0.8351 | 0.8161 | 0.9938 | 0.9043 | 0.8846 | 0.9613 | 0.8978 | 0.7634 | 0.8548 | 0.8095 |
| GPT-Image | ❌ | 0.8952 | 0.8929 | 0.9448 | 0.9289 | 0.8655 | 0.8445 | 0.9494 | 0.9283 | 0.8800 | 0.9432 | 0.9017 | 0.7253 | 0.8582 | 0.7143 |
| HunyuanImage 2.1 | ✅ | 0.8888 | 0.8832 | 0.9339 | 0.9341 | 0.8363 | 0.8342 | 0.9627 | 0.8870 | 0.9615 | 0.9448 | 0.9254 | 0.7527 | 0.8689 | 0.7619 |
从SSAE评估结果来看,我们的模型目前在语义对齐方面已达到开源模型中的最优水平,且与闭源商用模型(GPT-Image)的表现非常接近。
GSB 评估
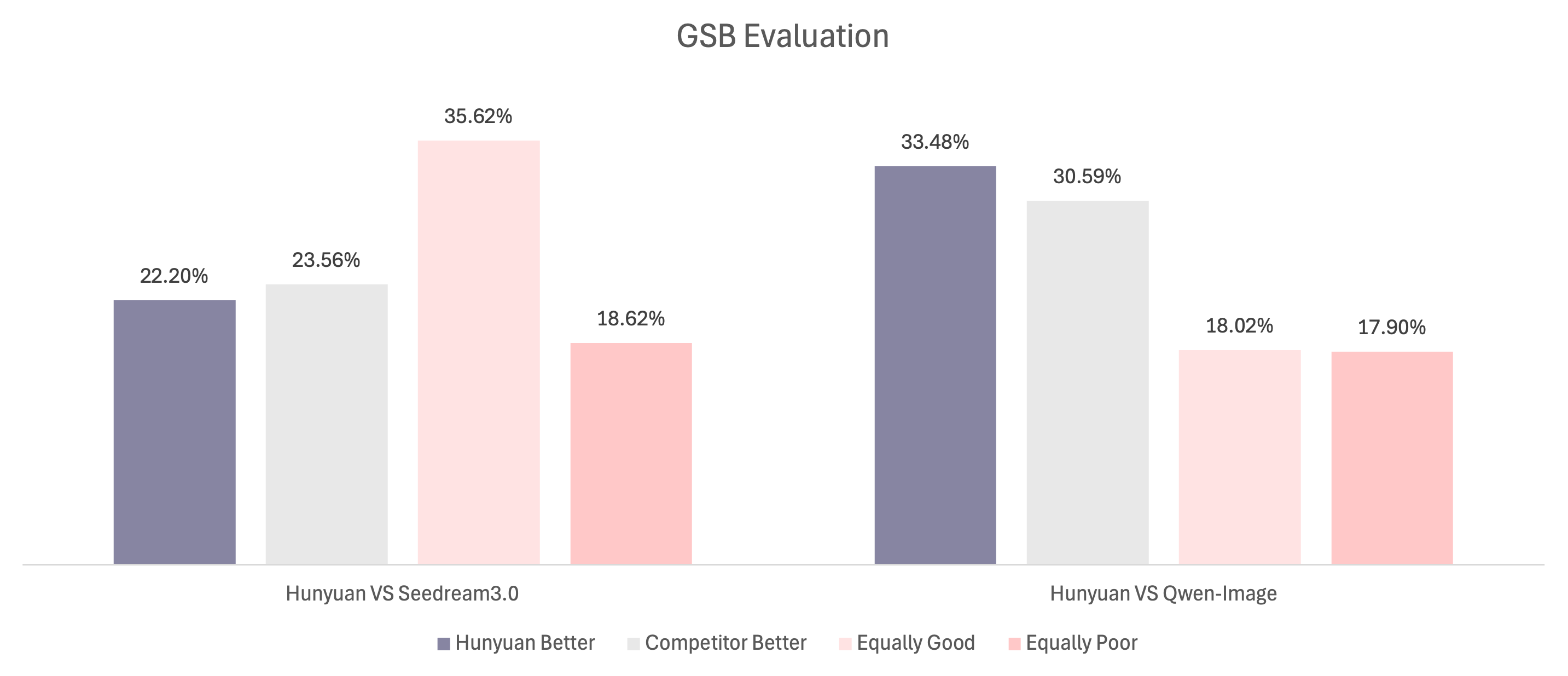
我们采用了GSB评估方法,该方法常用于从整体图像感知的角度评估两个模型之间的相对性能。总共使用了1000个文本提示,在一次运行中为所有对比模型生成了相同数量的图像样本。为了公平比较,我们对每个提示仅进行一次推理,避免挑选最佳结果。与基线方法比较时,我们保持所有选定模型的默认设置不变。评估由超过100名专业评估员完成。 结果显示,HunyuanImage 2.1相对于Seedream3.0(闭源)的相对胜率为-1.36%,而优于Qwen-Image(开源)2.89%。GSB评估结果表明,作为一款开源模型,HunyuanImage 2.1的图像生成质量已达到与闭源商用模型(Seedream3.0)相当的水平,同时在与同类开源模型(Qwen-Image)的比较中展现出一定优势。这充分验证了HunyuanImage 2.1在文生图任务中的技术先进性和实际价值。
联系方式
欢迎加入我们的Discord服务器或微信交流群——不仅可交流想法、探讨合作,还可提出任何疑问。您也可以在GitHub上提交问题或拉取请求。您的反馈对我们至关重要,将推动HunyuanImage不断向前发展。感谢您成为我们社区的一员!
🔗 BibTeX
如果您发现本项目对您的研究和应用有所帮助,请引用如下:
@misc{HunyuanImage-2.1,
title={HunyuanImage 2.1: 高分辨率(2K)文生图的高效扩散模型},
author={腾讯混元团队},
year={2025},
howpublished={\url{https://github.com/Tencent-Hunyuan/HunyuanImage-2.1}},
}
致谢
我们衷心感谢以下开源项目和社区为开放研究与探索所作出的贡献:Qwen、FLUX、diffusers以及HuggingFace。
GitHub 星标历史

常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。