Awesome-Knowledge-Distillation-of-LLMs
Awesome-Knowledge-Distillation-of-LLMs 是一个专注于大语言模型(LLM)知识蒸馏技术的开源论文合集。它旨在解决如何将 GPT-4 等闭源强大模型的能力高效迁移至 LLaMA、Mistral 等开源小模型,以及如何利用开源模型自我压缩与提升的难题。通过系统梳理“知识提取”与“蒸馏算法”,该资源帮助开发者在降低计算成本的同时,让小型模型获得接近大型模型的语境理解、伦理对齐及深度语义洞察能力。
该项目特别适合 AI 研究人员、算法工程师及大模型开发者使用。无论是希望训练轻量级垂直领域模型,还是探索数据增强与知识蒸馏结合的前沿学者,都能从中获益。其核心亮点在于构建了清晰的三维分类体系:从底层算法机制、特定技能迁移到垂直行业应用,全方位覆盖了当前最新的研究成果。此外,项目团队每周持续更新论文列表,并配套发布了详细的综述文章,为社区提供了极具价值的技术导航。如果你正致力于优化模型效率或挖掘大模型潜力,这份动态更新的知识库将是不可或缺的参考指南。
使用场景
某医疗科技初创团队试图将 GPT-4 级别的临床问诊能力迁移到本地部署的轻量级模型中,以满足数据隐私合规要求并降低推理成本。
没有 Awesome-Knowledge-Distillation-of-LLMs 时
- 技术路线迷茫:团队在海量论文中难以筛选出适合“垂直领域(医疗)”的知识蒸馏算法,缺乏系统性的分类指引,导致试错成本极高。
- 能力迁移低效:仅简单模仿输出结果,忽略了“技能蒸馏”机制,使得小模型虽能对话但缺乏深层医学逻辑推理能力,误诊风险高。
- 数据增强缺失:不懂得利用大模型生成高质量的合成数据来扩充稀缺的医疗语料,导致小模型训练数据不足,泛化能力差。
- 法律合规隐患:对使用 proprietary 模型(如 GPT-4)输出进行训练的版权和条款限制认识模糊,面临潜在的法律纠纷风险。
使用 Awesome-Knowledge-Distillation-of-LLMs 后
- 精准定位方案:依托其清晰的“算法 - 技能 - 垂直化”三维分类体系,团队迅速锁定了针对医疗垂直领域的最新蒸馏论文,研发周期缩短 50%。
- 深度技能复刻:参考“技能蒸馏”板块,成功将大模型的诊断思维链(Chain-of-Thought)迁移至小模型,显著提升了复杂病例的分析准确率。
- 数据质量飞跃:利用收录的数据增强(DA)结合 KD 的前沿范式,生成了大量上下文丰富且符合医学伦理的训练数据,解决了数据饥渴问题。
- 规避法律风险:通过仓库中的法律声明提示,团队严格遵循了源模型的使用条款,确保了商业化落地的合规性与安全性。
Awesome-Knowledge-Distillation-of-LLMs 不仅是一张论文清单,更是连接顶尖大模型能力与低成本落地应用的关键桥梁,让中小企业也能安全、高效地拥有专属的行业大模型。
运行环境要求
未说明
未说明
快速开始
LLM 论文中的知识蒸馏精选
![]()
大型语言模型的知识蒸馏综述
夏浩然1 李明2 陶重阳3 沈涛4 雷诺德·程1 李金阳1 徐灿5 陶大成6 周天一2
1 香港大学 2 马里兰大学 3 微软 4 悉尼科技大学 5 北京大学 6 悉尼大学
这是一份与大型语言模型(LLM)知识蒸馏相关的论文合集。如果您希望利用 LLM 来提升小型模型的训练效果,或者通过自生成的知识实现自我改进,不妨看看这份合集。
我们将每周更新此合集。欢迎给本仓库标星 ⭐️,以便及时了解最新动态。
❗️法律注意事项:需要注意的是,使用 LLM 的输出结果可能存在法律风险,例如 ChatGPT 的使用限制(限制条款)、Llama 的许可协议(许可协议)等。我们强烈建议用户遵守模型提供商规定的使用条款,比如不得开发竞争性产品等。
💡 最新消息
2024年2月20日:📄 我们发布了一篇综述论文“大型语言模型知识蒸馏综述”(链接)。欢迎大家阅读并引用。我们也非常期待您的反馈和建议。
更新记录
- 2024年3月19日:新增14篇论文。
如何参与本合集的贡献
如果您发现有任何遗漏的分类或论文,请随时提交 issue 或 PR,或发送邮件至 shawnxxh@gmail.com、minglii@umd.edu、hishentao@gmail.com 和 chongyangtao@gmail.com。我们将持续更新本合集及综述内容。
📝 引言
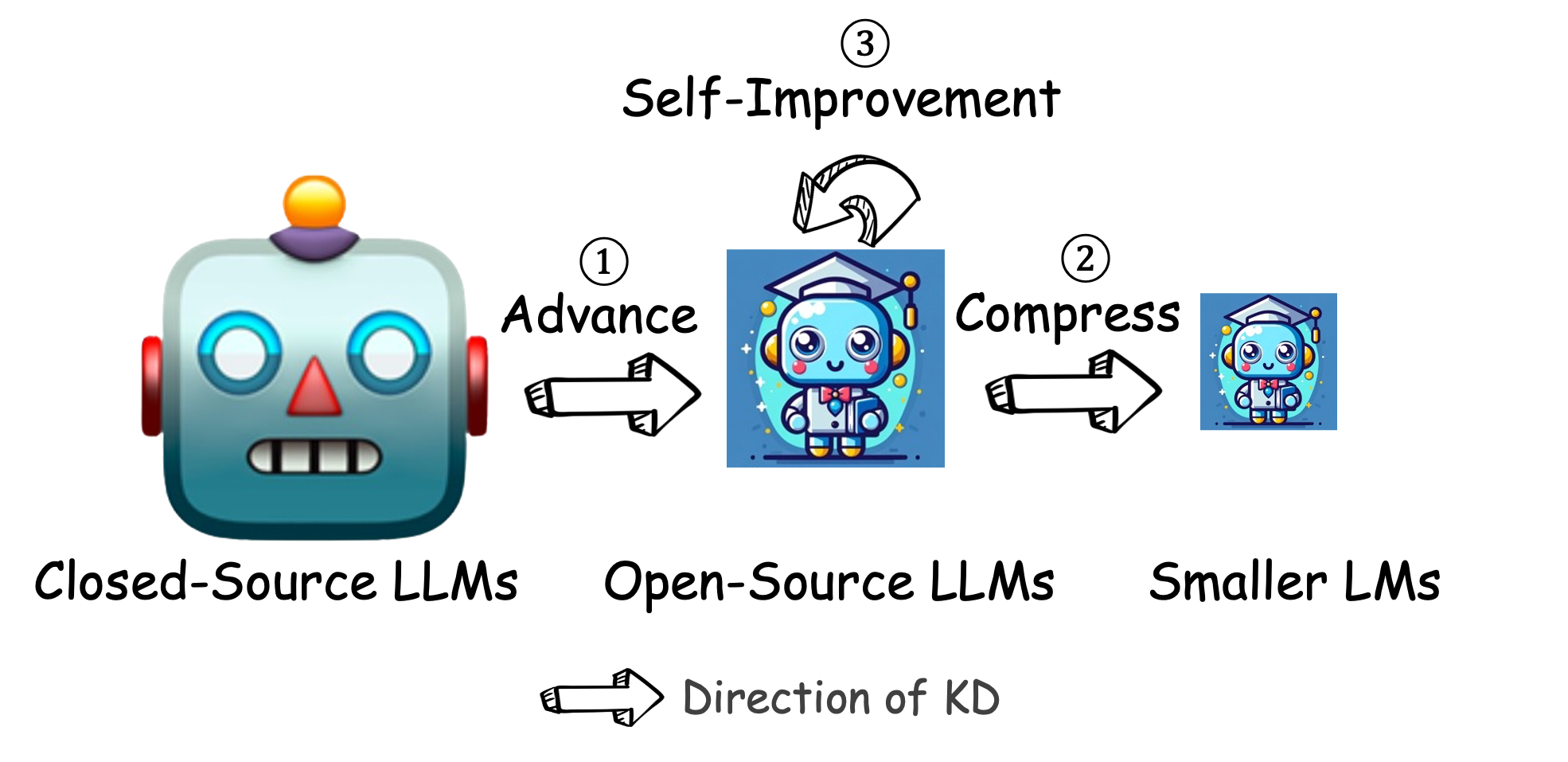
LLM 的知识蒸馏:本综述深入探讨了大型语言模型(LLM)中的知识蒸馏(KD)技术,重点阐述了 KD 在将 GPT-4 等专有 LLM 的先进能力迁移到 LLaMA、Mistral 等开源模型中所起到的关键作用。同时,我们也研究了如何通过以开源 LLM 为教师模型,实现其自身的压缩与自我提升。
KD 与数据增强:尤为重要的是,本综述剖析了数据增强(DA)与 KD 之间的复杂关系,指出 DA 已经成为 KD 框架下一种强大的范式,能够显著提升 LLM 的性能。通过利用 DA 生成富含上下文信息、针对特定技能的训练数据,KD 能够突破传统框架的限制,使开源模型在上下文理解能力、伦理对齐以及深层语义洞察力等方面逼近其专有对手的水平。
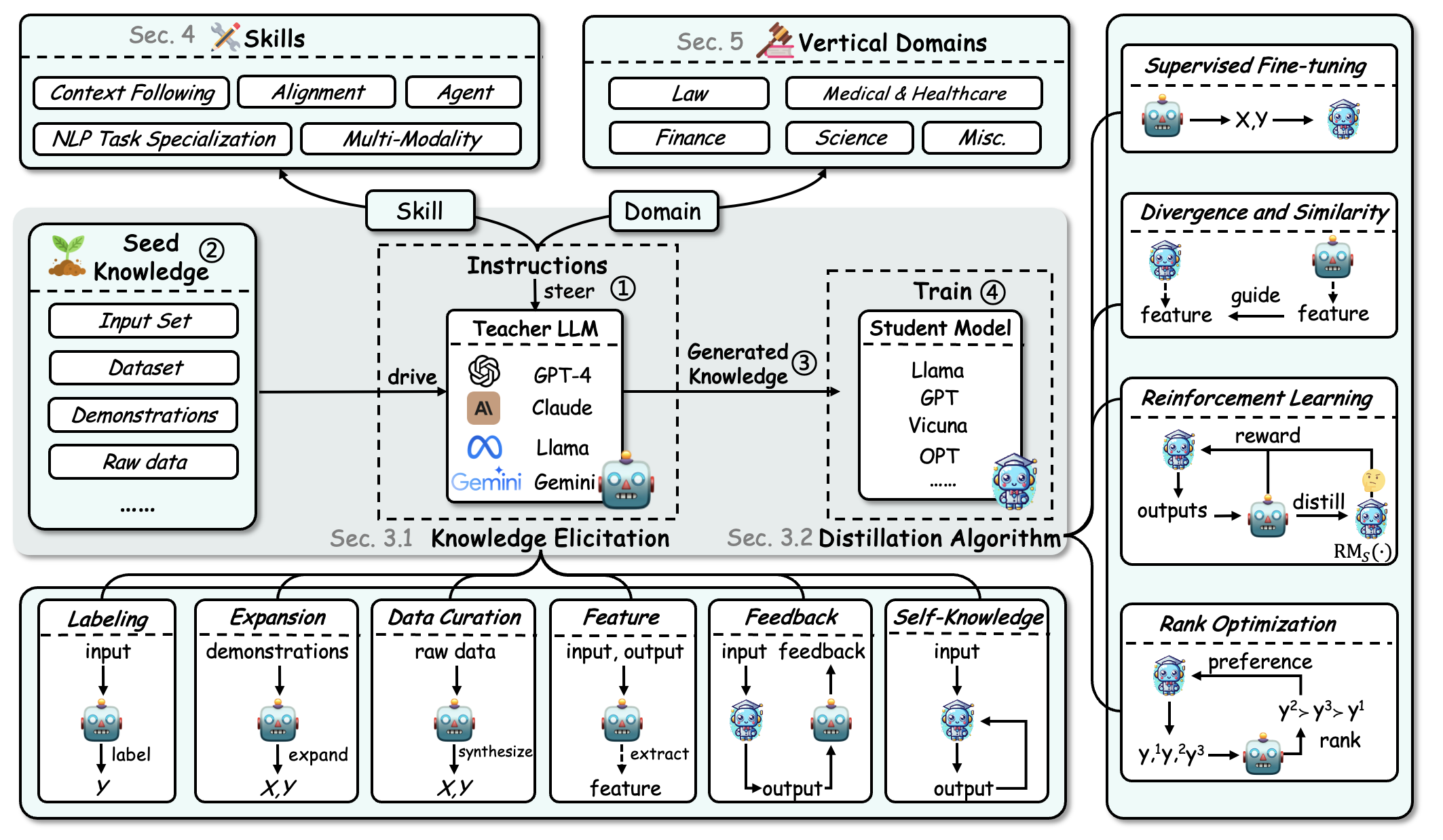
分类体系:我们的分析围绕三大基础支柱展开:算法、技能蒸馏 和 垂直化蒸馏——全面审视 KD 的机制、特定认知能力的提升及其在不同领域的实际应用。
KD 算法:对于 KD 算法,我们将其分为两个主要步骤:“知识提取”,专注于从教师 LLM 中提取知识;以及“蒸馏算法”,核心在于将这些知识注入学生模型中。
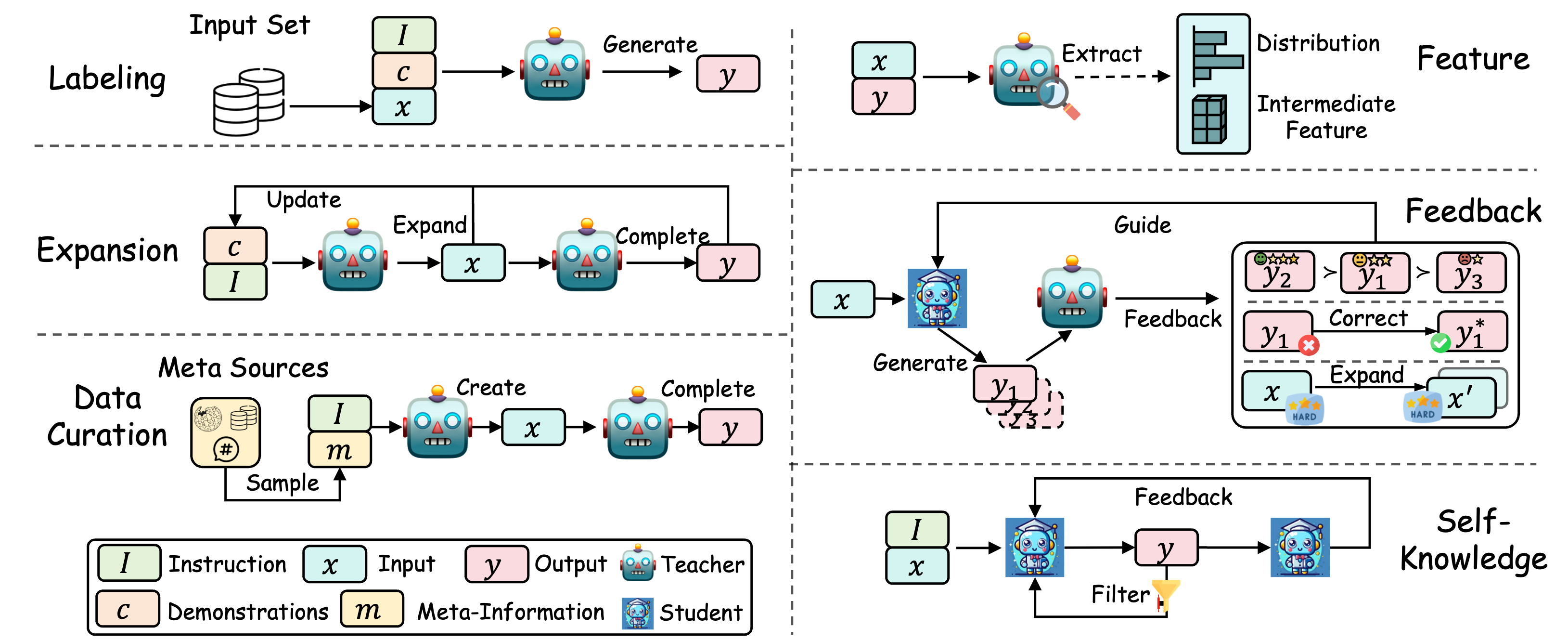
图示:来自教师 LLM 的不同知识提取方法。
技能蒸馏:我们深入探讨了特定认知能力的提升,如上下文理解、对齐性、代理能力、NLP 任务专业化以及多模态处理等。
垂直化蒸馏:我们探索了 KD 在法律、医疗健康、金融、科学及其他领域中的实际应用意义。
需要注意的是,无论是 技能蒸馏 还是 垂直化蒸馏,都依赖于 KD 算法 中的知识提取和蒸馏算法来实现其目标。因此,两者之间存在一定的交叉。不过,这也为相关论文提供了不同的视角。
为什么需要 LLM 的知识蒸馏?
在 LLM 时代,LLM 的知识蒸馏具有以下关键作用:
| 作用 | 描述 | 趋势 |
|---|---|---|
| ① 推动小型模型发展 | 将专有 LLM 的先进能力迁移到小型模型中,例如开源 LLM 或其他小型模型。 | 最常见 |
| ② 模型压缩 | 压缩 LLM,使其更加高效实用。 | 随着开源 LLM 的兴起而愈发流行 |
| ③ 自我改进 | 利用开源 LLM 自身的知识进行优化,即所谓的“自我蒸馏”。 | 是当前使开源 LLM 更具竞争力的新趋势 |
📒 目录
KD算法
知识提炼
标注
扩展
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 指令融合:通过杂交推进提示进化 | arXiv | 2023-12 | ||
| 中文大型语言模型指令微调的实证研究 | EMNLP | 2023-10 | Github | 数据 |
| PromptMix:用于大型语言模型蒸馏的类别边界增强方法 | EMNLP | 2023-10 | Github | |
| Wizardmath:通过强化版Evol-Instruct赋能大型语言模型的数学推理能力 | arXiv | 2023-08 | Github | |
| Code Llama:面向代码的开源基础模型 | arXiv | 2023-08 | Github | |
| WizardCoder:用Evol-Instruct赋能代码大型语言模型 | ICLR | 2023-06 | Github | |
| 从零开始、在极少人工监督下进行原则驱动的语言模型自对齐 | NeurIPS | 2023-05 | Github | 数据 |
| 目标数据生成:发现并修复模型弱点 | ACL | 2023-05 | Github | |
| Wizardlm:赋能大型语言模型遵循复杂指令 | ICLR | 2023-04 | Github | 数据 数据 |
| LaMini-LM:由大规模指令蒸馏而来的多样化模型群 | arXiv | 2023-04 | Github | 数据 |
| Alpaca:使语言模型与人类偏好对齐 | - | 2023-03 | Github | 数据 |
| Code Alpaca:用于代码生成的指令遵循LLaMA模型 | - | 2023-03 | Github | 数据 |
| 探索指令数据规模对大型语言模型的影响:基于真实世界用例的实证研究 | arXiv | 2023-03 | Github | 数据 |
| AugGPT:利用ChatGPT进行文本数据增强 | arXiv | 2023-02 | Github | |
| Self-instruct:用自我生成的指令使语言模型对齐 | ACL | 2022-12 | Github | 数据 |
| 符号知识蒸馏:从通用语言模型到常识模型 | NAACL | 2021-10 | Github | 数据 |
精选
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 几乎从零开始的合成数据:面向语言模型的广义指令微调 | arXiv | 2024-02 | ||
| Phi-2:小型语言模型的惊人力量 | - | 2023-12 | ||
| WaveCoder:广泛而多功能的增强型指令微调,结合精细化数据生成 | arXiv | 2023-12 | ||
| Magicoder:源代码就是你所需要的全部 | arXiv | 2023-12 | Github | 数据 数据 |
| MFTCoder:通过多任务微调提升代码LLM | arXiv | 2023-11 | Github | 数据 数据 |
| 教科书就是你所需要的全部II:Phi-1.5技术报告 | arXiv | 2023-09 | ||
| 利用ChatGPT进行神经机器翻译数据生成和增强 | arXiv | 2023-07 | ||
| 教科书就是你所需要的全部:面向语言模型的大规模指令文本数据集 | arXiv | 2023-06 | ||
| 通过扩展高质量指令对话来增强聊天语言模型 | arXiv | 2023-05 | Github | 数据 |
| AugTriever:通过可扩展的数据增强实现无监督密集检索 | arXiv | 2022-12 | Github | |
| SunGen:用于高效零样本学习的自引导无噪声数据生成 | ICLR | 2022-05 | Github | |
| ZeroGen:通过数据集生成实现高效的零样本学习 | EMNLP | 2022-02 | Github | |
| InPars:利用大型语言模型进行信息检索的数据增强 | arXiv | 2022-02 | Github | 数据 |
| 迈向零标签语言学习 | arXiv | 2021-09 |
特色
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| PromptKD:通过提示微调为生成式语言模型提炼学生友好的知识 | EMNLP Findings | 2024-02 | Github | 数据 |
| 重新思考大型语言模型知识蒸馏中的KL散度 | arXiv | 2024-04 | ||
| 用于推测解码的草稿模型与聊天微调LLM的直接对齐 | arXiv | 2024-03 | ||
| DB-LLM:高效LLM的精确双二值化 | arXiv | 2024-02 | ||
| BitDistiller:通过自蒸馏释放低于4比特LLM的潜力 | arXiv | 2024-02 | Github | |
| DISTILLM:迈向大型语言模型的简化蒸馏 | arXiv | 2024-02 | Github | |
| 迈向跨分词器的知识蒸馏:LLM的通用logit蒸馏损失 | arXiv | 2024-02 | Github | 数据 |
| 重访自回归语言模型的知识蒸馏 | arXiv | 2024-02 | ||
| 大型语言模型的知识融合 | ICLR | 2024-01 | Github | |
| 通过双向对齐提升上下文学习能力 | arXiv | 2023-12 | ||
| 关于有限域上知识迁移的基本极限 | NeurIPS | 2023-10 | ||
| Baby Llama:在小型数据集上训练的教师集成进行知识蒸馏,且无性能损失 | CoNLL | 2023-08 | Github | 数据 |
| 序列级知识蒸馏中的f散度最小化 | ACL | 2023-07 | Github | 数据 |
| MiniLLM:大型语言模型的知识蒸馏 | ICLR | 2023-06 | Github | 数据 |
| 语言模型的策略内蒸馏:从自我生成的错误中学习 | ICLR | 2023-06 | ||
| LLM-QAT:大型语言模型的无数据量化感知训练 | arXiv | 2023-05 | Github | 数据 |
| 少即是多:面向任务的逐层蒸馏用于语言模型压缩 | PMLR | 2022-10 | Github |
反馈
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| PromptKD:通过提示微调为生成式语言模型提炼学生友好的知识 | EMNLP Findings | 2024-02 | Github | 数据 |
| 面向知识增强型零样本问答的证据聚焦事实摘要 | arXiv | 2024-03 | ||
| 利用大型语言模型和主动学习演进知识蒸馏 | arXiv | 2024-03 | ||
| 基于在线AI反馈的直接语言模型对齐 | arXiv | 2024-02 | ||
| DISTILLM:迈向大型语言模型的流线型知识蒸馏 | arXiv | 2024-02 | Github | |
| 通过带有最小编辑约束的细粒度强化学习改进大型语言模型 | arXiv | 2024-01 | Github | |
| 超越模仿:利用细粒度质量信号进行对齐 | arXiv | 2023-11 | ||
| 语言模型能教导较弱的智能体吗?教师解释通过个性化提升学生表现 | ICLR | 2023-10 | Github | |
| Motif:来自人工智能反馈的内在动机 | ICLR | 2023-10 | Github | |
| Ultrafeedback:用高质量反馈提升语言模型性能 | arXiv | 2023-10 | Github | 数据 |
| 个性化知识蒸馏:以自适应学习赋能开源LLM进行代码生成 | EMNLP | 2023-10 | Github | |
| CycleAlign:从黑盒LLM到白盒模型的迭代知识蒸馏,以实现更好的人类对齐 | arXiv | 2023-10 | ||
| Rlaif:结合AI反馈扩展基于人类反馈的强化学习 | arXiv | 2023-09 | ||
| Wizardmath:通过强化版evol-instruct赋能大型语言模型的数学推理能力 | arXiv | 2023-08 | Github | |
| 语言模型的策略内知识蒸馏:从自我生成的错误中学习 | ICLR | 2023-06 | ||
| MiniLLM:大型语言模型的知识蒸馏 | ICLR | 2023-06 | Github | 数据 |
| 用于机器人技能合成的语言到奖励机制 | arXiv | 2023-06 | Github | |
| Lion:闭源大型语言模型的对抗性知识蒸馏 | EMNLP | 2023-05 | Github | |
| SelFee:由自我反馈生成驱动的迭代自我修正LLM | arXiv | 2023-05 | ||
| LaMini-LM:基于大规模指令蒸馏出的多样化模型群 | arXiv | 2023-04 | Github | 数据 |
| 使用语言模型进行奖励设计 | ICLR | 2023-03 | Github | |
| 宪章式AI:从AI反馈中确保无害性 | arXiv | 2022-12 |
自我认知
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| V-STaR:为自学习推理者训练验证器 | arXiv | 2024-02 | ||
| 自我奖励语言模型 | arXiv | 2024-01 | Github | |
| 自对弈微调将弱语言模型转化为强语言模型 | arXiv | 2024-01 | Github | 数据 |
| Kun:基于指令反向翻译的中文自我对齐答案润色 | arXiv | 2024-01 | Github | 数据 |
| APT:用于高效训练和推理的预训练语言模型自适应剪枝与调优 | arXiv | 2024-01 | ||
| GRATH:面向大型语言模型的渐进式自我校正 | arXiv | 2024-01 | ||
| 超越人类数据:扩展语言模型解决问题的自训练规模 | arXiv | 2023-12 | ||
| 自我认知引导的检索增强技术应用于大型语言模型 | EMNLP Findings | 2023-10 | Github | |
| RAIN:您的语言模型无需微调即可实现自我对齐 | arXiv | 2023-09 | Github | |
| 用于语言建模的强化自我训练(ReST) | arXiv | 2023-08 | ||
| Humback:基于指令反向翻译的自我对齐 | ICLR | 2023-08 | Github | |
| 通过对比蒸馏的强化学习实现大型语言模型的自我对齐 | ICLR | 2023-07 | Github | |
| 通过人类反馈的强化学习提升大型语言模型性能 | EMNLP | 2023-06 | ||
| 从零开始、以原则为导向,在极少人工监督下实现语言模型自我对齐 | NeurIPS | 2023-05 | Github | 数据 |
| 不可能蒸馏:从低质量模型到高质量摘要与改写数据集及模型 | arXiv | 2023-05 | Github | |
| 通过强化学习反思实现语言模型自我改进 | arXiv | 2023-05 | ||
| Baize:基于自我对话数据进行参数高效调优的开源聊天模型 | EMNLP | 2023-04 | Github | 数据 |
| Self-instruct:利用自动生成的指令对齐语言模型 | ACL | 2022-12 | Github | 数据 |
| 大型语言模型可以自我改进 | EMNLP | 2022-10 | ||
| STaR:用推理来启动推理能力 | NeurIPS | 2022-03 | Github |
蒸馏算法
监督微调
由于应用监督微调的研究成果众多,此处仅列出最具代表性的几项。
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 面向知识增强零样本问答的证据导向事实摘要 | arXiv | 2024-03 | ||
| 通过思维链推理对齐大小语言模型 | EACL | 2024-03 | Github | |
| 分而治之?你的大语言模型应该蒸馏哪一部分? | arXiv | 2024-02 | ||
| 从零开始(几乎)生成合成数据:面向语言模型的通用指令微调 | arXiv | 2024-02 | ||
| Orca 2:教小型语言模型如何进行推理 | arXiv | 2023-11 | ||
| TinyLLM:从多个大型语言模型中学习一个小型学生模型 | arXiv | 2024-02 | ||
| Wizardmath:通过强化进化指令微调赋能大型语言模型的数学推理能力 | arXiv | 2023-08 | Github | |
| Orca:基于GPT-4复杂解释轨迹的渐进式学习 | arXiv | 2023-06 | ||
| LaMini-LM:由大规模指令蒸馏得到的多样化模型集合 | arXiv | 2023-04 | Github | 数据 |
| Wizardlm:赋能大型语言模型遵循复杂指令 | ICLR | 2023-04 | Github | 数据 数据 |
| Baize:基于自对话数据进行参数高效微调的开源聊天模型 | EMNLP | 2023-04 | Github | 数据 |
| Alpaca:使语言模型与人类偏好对齐 | - | 2023-03 | Github | 数据 |
| Vicuna:一款以90% ChatGPT质量惊艳GPT-4的开源聊天机器人* | - | 2023-03 | Github | 数据 |
| Self-instruct:利用自我生成的指令对齐语言模型 | ACL | 2022-12 | Github | 数据 |
| 大型语言模型可以自我改进 | EMNLP | 2022-10 | ||
| STaR:用推理来启动推理 | NeurIPS | 2022-03 | Github |
差异与相似性
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| PromptKD:通过提示微调为生成式语言模型提炼学生友好的知识 | EMNLP Findings | 2024-02 | Github | 数据 |
| 重新思考大型语言模型知识蒸馏中的KL散度 | arXiv | 2024-04 | ||
| 面向任务无关的BERT压缩的权重继承型蒸馏 | NAACL | 2024-03 | Github | |
| BitDistiller:通过自蒸馏释放低于4比特LLM的潜力 | arXiv | 2024-02 | Github | |
| DISTILLM:迈向大型语言模型的简化蒸馏 | arXiv | 2024-02 | Github | |
| 迈向跨分词器蒸馏:LLM的通用logit蒸馏损失 | arXiv | 2024-02 | Github | 数据 |
| 重访自回归语言模型的知识蒸馏 | arXiv | 2024-02 | ||
| 闭源语言模型的知识蒸馏 | arXiv | 2024-01 | ||
| 大型语言模型的知识融合 | ICLR | 2024-01 | Github | |
| 通过双向对齐改进上下文学习 | arXiv | 2023-12 | ||
| 关于有限域上知识迁移的基本极限 | NeurIPS | 2023-10 | ||
| Baby Llama:在小型数据集上训练的教师集成进行知识蒸馏,且无性能损失 | CoNLL | 2023-08 | Github | 数据 |
| 序列级知识蒸馏中的f散度最小化 | ACL | 2023-07 | Github | 数据 |
| 序列级知识蒸馏中的f散度最小化 | ACL | 2023-07 | Github | 数据 |
| MiniLLM:大型语言模型的知识蒸馏 | ICLR | 2023-06 | Github | 数据 |
| 语言模型的策略内蒸馏:从自我生成的错误中学习 | ICLR | 2023-06 | ||
| LLM-QAT:大型语言模型的无数据量化感知训练 | arXiv | 2023-05 | Github | 数据 |
| 少即是多:面向任务的语言模型压缩分层蒸馏 | PMLR | 2022-10 | Github | |
| DistilBERT,一个蒸馏版的BERT:更小、更快、更便宜、更轻 | NeurIPS | 2019-10 |
强化学习
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 基于在线AI反馈的直接语言模型对齐 | arXiv | 2024-02 | ||
| 通过带有最小编辑约束的细粒度强化学习改进大型语言模型 | arXiv | 2024-01 | Github | |
| 利用大型语言模型反馈加速机器人操作的强化学习 | CoRL | 2023-11 | ||
| Motif:来自人工智能反馈的内在动机 | ICLR | 2023-10 | Github | |
| Ultrafeedback:用高质量反馈提升语言模型 | arXiv | 2023-10 | Github | 数据 |
| Eureka:通过编码大型语言模型实现人类水平的奖励设计 | arXiv | 2023-10 | Github | |
| Rlaif:利用AI反馈扩展人类反馈的强化学习 | arXiv | 2023-09 | ||
| Wizardmath:通过强化evol-instruct赋能大型语言模型的数学推理能力 | arXiv | 2023-08 | Github | |
| 语言模型的策略内蒸馏:从自我生成的错误中学习 | ICLR | 2023-06 | ||
| 通过合成反馈对齐大型语言模型 | EMNLP | 2023-05 | Github | 数据 |
| 语言模型通过强化学习反思实现自我改进 | arXiv | 2023-05 | ||
| 宪法式AI:来自AI反馈的无害性 | arXiv | 2022-12 |
排序优化
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 面向知识增强的零样本问答的证据聚焦事实摘要 | arXiv | 2024-03 | ||
| KnowTuning:面向大型语言模型的知识感知微调 | arXiv | 2024-02 | Github | |
| 自我奖励的语言模型 | arXiv | 2024-01 | Github | |
| 自对弈微调将弱语言模型转化为强语言模型 | arXiv | 2024-01 | Github | 数据 |
| Zephyr:语言模型对齐的直接蒸馏 | arXiv | 2023-10 | Github | 数据 |
| CycleAlign:从黑盒LLM到白盒模型的迭代蒸馏,以实现更好的人类对齐 | arXiv | 2023-10 |
技能蒸馏
上下文跟随
指令跟随
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 从零开始(几乎)生成合成数据:面向语言模型的广义指令微调 | arXiv | 2024-02 | ||
| 重新审视自回归语言模型的知识蒸馏 | arXiv | 2024-02 | ||
| 选择性反思-微调:用于LLM指令微调的学生选择型数据循环利用 | arXiv | 2024-02 | Github | 数据 |
| Phi-2:小型语言模型的惊人能力 | - | 2023-12 | ||
| 什么才是对齐任务中的优质数据?指令微调中自动数据选择的全面研究 | ICLR | 2023-12 | Github | 数据 |
| MUFFIN:为提升指令遵循能力而策划的多维度指令集 | arXiv | 2023-12 | Github | 数据 |
| 指令融合:通过混合方法推进提示进化 | arXiv | 2023-12 | ||
| Orca 2:教导小型语言模型如何进行推理 | arXiv | 2023-11 | ||
| 反思-微调:数据循环利用提升LLM指令微调效果 | NIPS Workshop | 2023-10 | Github | 数据 |
| 教科书就够了II:Phi-1.5技术报告 | arXiv | 2023-09 | ||
| Orca:从GPT-4的复杂解释轨迹中逐步学习 | arXiv | 2023-06 | ||
| 教科书就够了:面向语言模型的大规模教学文本数据集 | arXiv | 2023-06 | ||
| SelFee:由自我反馈生成驱动的迭代式自我修正LLM | arXiv | 2023-05 | ||
| ExpertPrompting:指导大型语言模型成为杰出专家 | arXiv | 2023-05 | Github | 数据 |
| LaMini-LM:基于大规模指令蒸馏而成的多样化模型群 | arXiv | 2023-04 | Github | 数据 |
| Wizardlm:赋能大型语言模型以遵循复杂指令 | ICLR | 2023-04 | Github | 数据 数据 |
| Koala:一款用于学术研究的对话模型 | - | 2023-04 | Github | 数据 |
| Alpaca:使语言模型与人类偏好对齐 | - | 2023-03 | Github | 数据 |
| Vicuna:一款开源聊天机器人,其质量可媲美ChatGPT的90%*,并能打动GPT-4 | - | 2023-03 | Github | 数据 |
| Self-instruct:通过自动生成的指令使语言模型对齐 | ACL | 2022-12 | Github | 数据 |
多轮对话
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Zephyr:直接蒸馏实现LM对齐 | arXiv | 2023-10 | Github | 数据 |
| OPENCHAT:利用混合质量数据推进开源语言模型发展 | ICLR | 2023-09 | Github | 数据 |
| 通过扩展高质量指令型对话来增强聊天语言模型 | arXiv | 2023-05 | Github | 数据 |
| Baize:一款开源聊天模型,在自聊天数据上采用参数高效的微调 | EMNLP | 2023-04 | Github | 数据 |
| Vicuna:一款开源聊天机器人,其质量可媲美ChatGPT的90%*,并能打动GPT-4 | - | 2023-03 | Github | 数据 |
RAG能力
| 标题 | 场所 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Self-RAG:通过自我反思学习检索、生成和批判 | NIPS | 2023-10 | Github | 数据 |
| SAIL:搜索增强型指令学习 | arXiv | 2023-05 | Github | 数据 |
| 面向知识密集型任务的小型语言模型的知识增强型推理蒸馏 | NIPS | 2023-05 | Github | 数据 |
对齐
思维模式
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 通过思维链推理对齐大型和小型语言模型 | EACL | 2024-03 | Github | |
| 分而治之?你应该蒸馏你的LLM的哪一部分? | arXiv | 2024-02 | ||
| 选择性反思调优:用于LLM指令调优的学生自选数据循环利用 | arXiv | 2024-02 | Github | 数据 |
| LLM能为不同人群发声吗?通过辩论调优LLM以生成可控的争议性言论 | arXiv | 2024-02 | Github | 数据 |
| 面向领域特定问答的LLM知识型偏好对齐 | arXiv | 2023-11 | Github | |
| Orca 2:教小型语言模型如何进行推理 | arXiv | 2023-11 | ||
| 反思调优:数据循环利用提升LLM指令调优效果 | NIPS Workshop | 2023-10 | Github | 数据 |
| Orca:从GPT-4复杂解释轨迹中逐步学习 | arXiv | 2023-06 | ||
| SelFee:由自我反馈生成赋能的迭代式自我修正LLM | arXiv | 2023-05 |
偏好
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Ultrafeedback:用高质量反馈提升语言模型性能 | arXiv | 2023-10 | Github | 数据 |
| Zephyr:直接蒸馏实现LM对齐 | arXiv | 2023-10 | Github | 数据 |
| Rlaif:结合人类与AI反馈扩展强化学习 | arXiv | 2023-09 | ||
| OPENCHAT:利用混合质量数据推进开源语言模型发展 | ICLR | 2023-09 | Github | 数据 |
| RLCD:基于对比蒸馏的强化学习用于语言模型对齐 | arXiv | 2023-07 | Github | |
| 通过合成反馈对齐大型语言模型 | EMNLP | 2023-05 | Github | 数据 |
| 使用语言模型设计奖励函数 | ICLR | 2023-03 | Github | |
| 大规模语言反馈训练语言模型 | arXiv | 2023-03 | ||
| 宪法式AI:由AI反馈确保无害性 | arXiv | 2022-12 |
价值观
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Ultrafeedback:用高质量反馈提升语言模型性能 | arXiv | 2023-10 | Github | 数据 |
| RLCD:基于对比蒸馏的强化学习用于语言模型对齐 | arXiv | 2023-07 | Github | |
| 从零开始、在极少人工监督下实现原则驱动的语言模型自我对齐 | NeurIPS | 2023-05 | Github | 数据 |
| 在模拟社交互动上训练社会对齐的语言模型 | arXiv | 2023-05 | ||
| 宪法式AI:由AI反馈确保无害性 | arXiv | 2022-12 |
代理
工具使用
| 标题 | 出处 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Toolformer:语言模型可以自我学习使用工具 | arXiv | 2023-02 | ||
| Graph-ToolFormer:通过ChatGPT增强的提示词赋予大语言模型图推理能力 | arXiv | 2023-04 | Github | 数据 |
| Gorilla:连接海量API的大语言模型 | arXiv | 2023-05 | Github | 数据 |
| GPT4Tools:通过自我指令教导大语言模型使用工具 | arXiv | 2023-05 | Github | 数据 |
| ToolAlpaca:基于3000个模拟案例的语言模型通用工具学习 | arXiv | 2023-06 | Github | 数据 |
| ToolLLM:助力大语言模型掌握16000+真实世界API | arXiv | 2023-07 | Github | 数据 |
| Confucius:从内省反馈中循序渐进地进行工具学习 | arXiv | 2023-08 | Github | |
| CRAFT:通过创建和检索专用工具集来定制大语言模型 | arXiv | 2023-09 | Github | |
| MLLM-Tool:用于工具代理学习的多模态大语言模型 | arXiv | 2024-01 | Github | 数据 |
| 小型语言模型是弱工具学习者:一个多语言模型代理 | arXiv | 2024-01 | Github | |
| EASYTOOL:用简洁的工具指令增强基于大语言模型的代理 | arXiv | 2024-01 | Github |
规划
| 标题 | 出处 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| AUTOACT:通过自我规划从零开始自动学习代理 | arXiv | 2024-01 | Github | |
| Lumos:使用统一数据、模块化设计和开源大语言模型学习代理 | arXiv | 2023-11 | Github | 数据 |
| TPTU-v2:提升大型语言模型代理在现实系统中的任务规划和工具使用能力 | arXiv | 2023-11 | ||
| 由大语言模型从平行TextWorld训练的具身多模态代理 | arXiv | 2023-11 | ||
| 通过大语言模型的反馈加速机器人操作的强化学习 | CoRL | 2023-11 | ||
| Motif:来自人工智能反馈的内在动机 | ICLR | 2023-10 | Github | |
| FireAct:迈向语言模型代理的微调 | arXiv | 2023-10 | Github | 数据 |
| AgentTuning:为大语言模型实现通用代理能力 | arXiv | 2023-10 | Github | |
| Eureka:通过大语言模型编码实现人类水平的奖励设计 | arXiv | 2023-10 | Github | |
| 面向人机协作的语言指导式强化学习 | PMLR | 2023-04 | ||
| 用大语言模型引导强化学习的预训练 | PMLR | 2023-02 | ||
| 将互联网规模的视觉-语言模型提炼为具身代理 | ICML | 2023-01 |
NLP任务专业化
NLU
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 大模型 vs 小模型?基于大语言模型的文本增强个性化检测模型 | arXiv | 2024-03 | ||
| 利用大语言模型与主动学习进化知识蒸馏 | arXiv | 2024-03 | ||
| 混合蒸馏助力小型语言模型提升推理能力 | arXiv | 2023-12 | ||
| PromptMix:一种用于大语言模型蒸馏的类别边界增强方法 | EMNLP | 2023-10 | Github | |
| TinyLLM:从多个大语言模型中学习小型学生模型 | arXiv | 2024-02 | ||
| 目标数据生成:发现并修复模型弱点 | ACL | 2023-05 | Github | |
| 为可解释的自动化学生答案评估蒸馏ChatGPT | arXiv | 2023-05 | Github | |
| ChatGPT在文本标注任务中优于众包工作者 | arXiv | 2023-03 | ||
| Annollm:让大语言模型成为更好的众包标注者 | arXiv | 2023-03 | ||
| AugGPT:利用ChatGPT进行文本数据增强 | arXiv | 2023-02 | Github | |
| GPT-3是优秀的数据标注者吗? | ACL | 2022-12 | Github | |
| SunGen:自引导无噪声数据生成,实现高效的零样本学习 | ICLR | 2022-05 | Github | |
| ZeroGen:通过数据集生成实现高效零样本学习 | EMNLP | 2022-02 | Github | |
| 利用语言模型生成训练数据:迈向零样本语言理解 | NeurIPS | 2022-02 | Github | |
| 迈向零标签语言学习 | arXiv | 2021-09 | ||
| 生成、标注与学习:使用合成文本进行NLP | TACL | 2021-06 |
NLG
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| 通过多奖励蒸馏定制自我解释器 | arXiv | 2023-11 | Github | 数据 |
| RECOMP:通过压缩和选择性增强改进检索增强型LMs | arXiv | 2023-10 | Github | |
| 利用ChatGPT进行神经机器翻译数据生成与增强 | arXiv | 2023-07 | ||
| 语言模型的在线蒸馏:从自我生成的错误中学习 | ICLR | 2023-06 | ||
| LLMs能否生成高质量的以笔记为导向的医患对话? | arXiv | 2023-06 | Github | 数据 |
| InheritSumm:通过从GPT蒸馏得到的通用、多功能且紧凑的摘要器 | EMNLP | 2023-05 | ||
| 不可能的蒸馏:从低质量模型到高质量的摘要和改写数据集及模型 | arXiv | 2023-05 | Github | |
| 放射科报告简化中的数据增强 | EACL成果 | 2023-04 | Github | |
| 想降低标注成本吗?GPT-3可以帮忙 | EMNLP成果 | 2021-08 |
信息检索
| 标题 | 会议/平台 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| InstructDistill:指令蒸馏使大语言模型成为高效的零样本排序器 | arXiv | 2023-11 | Github | 数据 |
| 软提示调优:用大语言模型增强密集检索 | arXiv | 2023-07 | Github | |
| 检索增强型大语言模型中的查询重写 | EMNLP | 2023-05 | ||
| ChatGPT擅长搜索吗?探究大语言模型作为重新排序代理 | EMNLP | 2023-04 | Github | 数据 |
| AugTriever:通过可扩展的数据增强实现无监督密集检索 | arXiv | 2022-12 | Github | |
| QUILL:利用检索增强和多阶段蒸馏,通过大语言模型理解查询意图 | EMNLP | 2022-10 | ||
| Promptagator:仅需8个示例即可实现少样本密集检索 | ICLR | 2022-09 | ||
| 只需问题就能训练密集段落检索 | TACL | 2022-06 | Github | |
| 通过零样本问题生成改进段落检索 | EMNLP | 2022-04 | Github | 数据 |
| InPars:利用大语言模型进行信息检索的数据增强 | arXiv | 2022-02 | Github | 数据 |
| 利用预训练语言模型生成数据集 | EMNLP | 2021-04 | Github |
推荐
| 标题 | 会议/期刊 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| 小型语言模型能否成为序列推荐的良好推理者? | arXiv | 2024-03 | ||
| 大型语言模型增强的叙事驱动推荐 | arXiv | 2023-06 | ||
| 作为指令遵循的推荐:一种由大型语言模型赋能的推荐方法 | arXiv | 2023-05 | ||
| ONCE:利用开源与闭源大型语言模型提升基于内容的推荐 | WSDM | 2023-05 | Github | 数据 |
文本生成评估
| 标题 | 会议/期刊 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| 普罗米修斯:在语言模型中诱导细粒度评估能力 | ICLR | 2023-10 | Github | 数据 |
| TIGERScore:迈向构建适用于所有文本生成任务的可解释性指标 | arXiv | 2023-10 | Github | 数据 |
| 用于评估对齐性的生成式评判器 | ICLR | 2023-10 | Github | 数据 |
| PandaLM:一个用于LLM指令微调优化的自动评估基准 | arXiv | 2023-06 | Github | 数据 |
| INSTRUCTSCORE:带有细粒度反馈的可解释性文本生成评估 | EMNLP | 2023-05 | Github | 数据 |
代码
| 标题 | 会议/期刊 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| Magicoder:源代码就是你需要的一切 | arXiv | 2023-12 | Github | 数据 数据 |
| WaveCoder:广泛而多功能的增强型指令微调,结合精细化数据生成 | arXiv | 2023-12 | ||
| 指令融合:通过混合化推进提示进化 | arXiv | 2023-12 | ||
| MFTCoder:通过多任务微调提升代码LLM性能 | arXiv | 2023-11 | Github | 数据 数据 |
| LLM辅助的代码清理:用于训练精准代码生成器 | arXiv | 2023-11 | ||
| 个性化蒸馏:以自适应学习赋能开源LLM进行代码生成 | EMNLP | 2023-10 | Github | |
| Code Llama:面向代码的开源基础模型 | arXiv | 2023-08 | Github | |
| 用于源代码摘要的蒸馏版GPT | arXiv | 2023-08 | Github | 数据 |
| 教科书就是你需要的一切:面向语言模型的大规模教学文本数据集 | arXiv | 2023-06 | ||
| Code Alpaca:一款用于代码生成的遵循指令的LLaMA模型 | - | 2023-03 | Github | 数据 |
多模态
| 标题 | 地点 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Miko:从大型语言模型中进行多模态意图知识蒸馏,用于社交媒体常识发现 | arXiv | 2024-02 | ||
| 在大型语言模型中定位视觉常识知识 | NeurIPS | 2023-12 | Github | 数据 |
| 眼见为实:通过提示优化GPT-4V以更好地进行视觉指令微调 | arXiv | 2023-11 | Github | 数据 |
| ILuvUI:基于机器对话的用户界面指令微调语言-视觉模型 | arXiv | 2023-10 | ||
| NExT-GPT:任意到任意的多模态大语言模型 | arXiv | 2023-09 | Github | 数据 |
| StableLLaVA:利用合成图像-对话数据增强视觉指令微调 | arXiv | 2023-08 | Github | 数据 |
| PointLLM:赋能大型语言模型理解点云数据 | arXiv | 2023-08 | Github | 数据 |
| SVIT:扩展视觉指令微调规模 | arXiv | 2023-07 | Github | 数据 |
| ChatSpot:通过精准指代指令微调来构建多模态大语言模型 | arXiv | 2023-07 | ||
| Shikra:释放多模态大语言模型的指代对话魔法 | arXiv | 2023-06 | Github | 数据 |
| 通过稳健的指令微调缓解大型多模态模型中的幻觉现象 | ICLR | 2023-06 | Github | 数据 |
| Valley:具有大型语言模型增强能力的视频助手 | arXiv | 2023-06 | Github | 数据 |
| DetGPT:通过推理检测你需要的内容 | EMNLP | 2023-05 | Github | |
| 视觉指令微调:关于大型语言模型视觉指令微调的全面研究 | NeurIPS | 2023-04 | Github | 数据 |
总结表
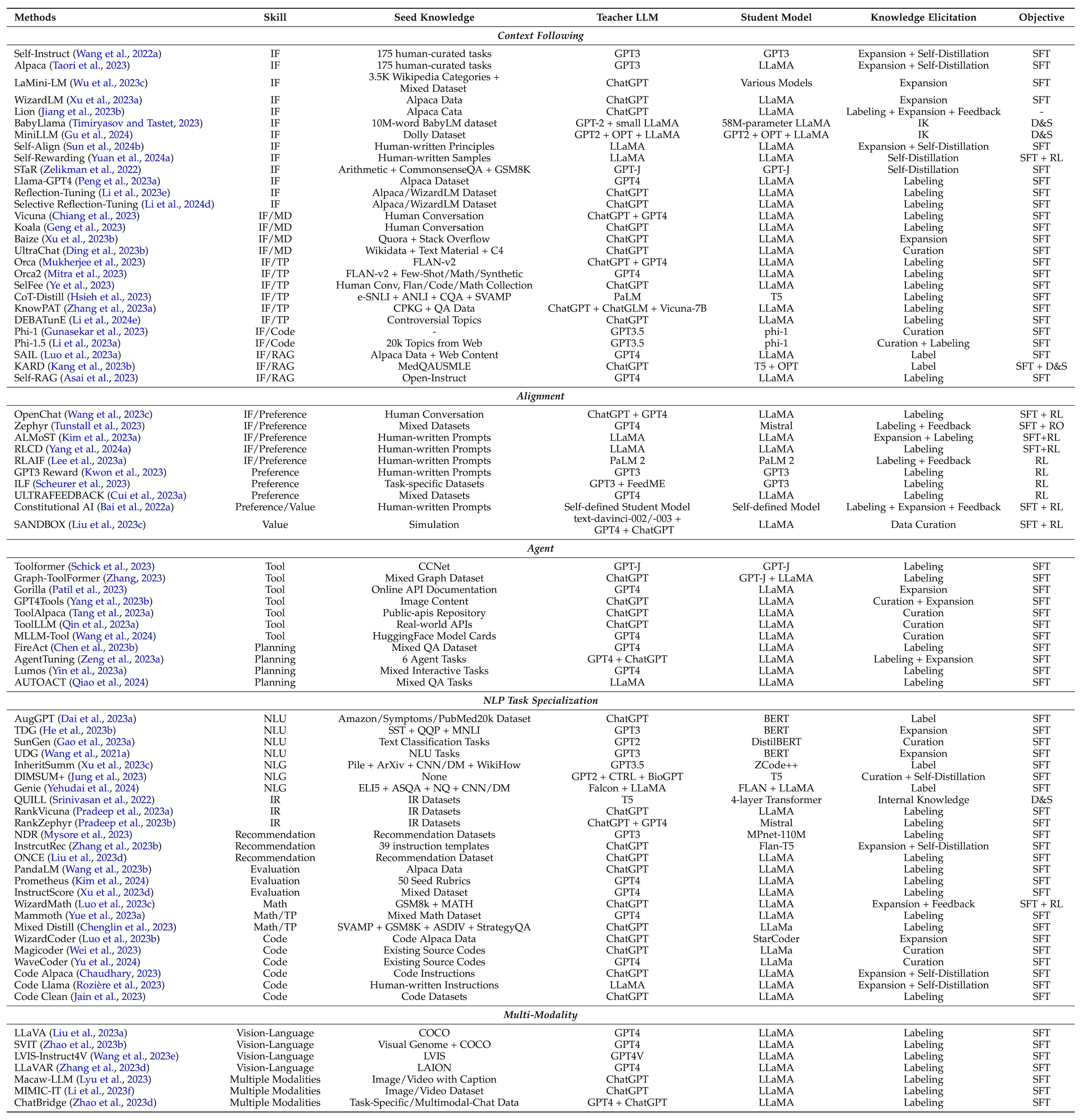
图:技能蒸馏代表性工作的总结。
垂直领域蒸馏
法律
| 标题 | 地点 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| Fuzi | - | 2023-08 | Github | |
| ChatLaw:集成外部知识库的开源法律大语言模型 | arXiv | 2023-06 | Github | |
| Lawyer LLaMA技术报告 | arXiv | 2023-05 | Github | 数据 |
医疗与健康
| 标题 | 地点 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| HuatuoGPT-II:针对医疗场景的一站式大语言模型训练 | arXiv | 2023-11 | Github | 数据 |
| AlpaCare:面向医疗应用的指令微调大语言模型 | arXiv | 2023-10 | Github | 数据 |
| DISC-MedLLM:连接通用大语言模型与真实世界医疗咨询 | arXiv | 2023-08 | Github | 数据 |
| HuatuoGPT:驯服语言模型成为医生 | EMNLP | 2023-05 | Github | 数据 |
| DoctorGLM:微调你的中文医生并非难事 | arXiv | 2023-04 | Github | 数据 |
| Huatuo:用中医知识微调大语言模型 | arXiv | 2023-04 | Github | |
| MedAlpaca:一个开源的医疗对话AI模型及训练数据集合 | arXiv | 2023-04 | Github | 数据 |
| PMC-LLaMA:在医学论文上进一步微调LLaMA | arXiv | 2023-04 | Github | 数据 |
| ChatDoctor:基于大型语言模型Meta-AI(LLaMA)并结合医学领域知识进行微调的医疗聊天模型 | arXiv | 2023-03 | Github |
金融
| 标题 | 地点 | 日期 | 代码 | 数据 |
|---|---|---|---|---|
| XuanYuan 2.0:一款拥有数千亿参数的大型中文金融聊天模型 | CIKM | 2023-05 |
科学
| 标题 | 会议/平台 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| MuseGraph:面向图的大语言模型指令微调,用于通用图挖掘 | arXiv | 2024-03 | ||
| SciGLM:基于自我反思式指令标注与微调的科学语言模型训练 | arXiv | 2024-01 | Github | |
| AstroLLaMA-Chat:利用对话式和多样化数据集扩展 AstroLLaMA | arXiv | 2024-01 | ||
| GeoGalactica:地球科学领域的科学大语言模型 | arXiv | 2024-01 | Github | 数据 |
| InstructMol:多模态融合,构建药物发现中通用且可靠的分子助手 | arXiv | 2023-11 | Github | |
| LLM-Prop:从文本描述中预测晶体固体的物理和电子性质 | arXiv | 2023-10 | Github | |
| OceanGPT:面向海洋科学任务的大语言模型 | arXiv | 2023-10 | Github | 数据 |
| MarineGPT:向公众揭示海洋奥秘 | arXiv | 2023-10 | Github | |
| Mammoth:通过混合指令微调构建数学通才模型 | arXiv | 2023-09 | Github | 数据 |
| ToRA:用于数学问题解决的工具集成推理代理 | ICLR | 2023-09 | Github | |
| DARWIN系列:面向自然科学的领域专用大语言模型 | arXiv | 2023-08 | Github | |
| Wizardmath:通过强化进化指令微调增强大语言模型的数学推理能力 | arXiv | 2023-08 | Github | |
| Biomedgpt:面向生物医学的开源多模态生成式预训练Transformer | arXiv | 2023-08 | Github | 数据 |
| Prot2Text:结合GNN和Transformer的多模态蛋白质功能生成 | NeurIPS | 2023-07 | ||
| xTrimoPGLM:统一的1000亿参数级预训练Transformer,用于破译蛋白质的语言 | bioRxiv | 2023-07 | ||
| GIMLET:基于指令的分子零样本学习的统一图-文本模型 | NeurIPS | 2023-06 | Github | 数据 |
| K2:用于地球科学知识理解和利用的基础语言模型 | arXiv | 2023-06 | Github | |
| 视觉指令微调:大语言模型视觉指令微调的全面研究 | NeurIPS | 2023-04 | Github | 数据 |
杂项
| 标题 | 会议/平台 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| OWL:面向IT运维的大语言模型 | arXiv | 2023-09 | Github | 数据 |
| EduChat:基于大规模语言模型的智能教育聊天机器人系统 | arXiv | 2023-08 | Github | 数据 |
基于编码器的蒸馏
注:本综述主要关注生成式大语言模型,因此未包含基于编码器的蒸馏内容。然而,我们对此主题也十分感兴趣,并将持续更新该领域的最新研究成果。
| 标题 | 会议/平台 | 发表日期 | 代码 | 数据 |
|---|---|---|---|---|
| 掩码潜在语义建模:一种高效的掩码语言模型替代预训练方法 | ACL Findings | 2023-08 | ||
| 协同增效:联合使用掩码潜在语义建模和掩码语言模型进行高效样本预训练 | CoNLL | 2023-08 |
待办事项
- 添加关于O1类蒸馏的相关工作。敬请期待!
引用
如果您觉得本仓库有所帮助,请考虑引用以下论文:
@misc{xu2024survey,
title={大语言模型知识蒸馏综述},
author={Xiaohan Xu、Ming Li、Chongyang Tao、Tao Shen、Reynold Cheng、Jinyang Li、Can Xu、Dacheng Tao、Tianyi Zhou},
year={2024},
eprint={2402.13116},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
星标历史

相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。