GibsonEnv
GibsonEnv 是一个专为具身智能体(Embodied Agents)设计的虚拟环境模拟器,核心目标是为 AI 提供贴近真实世界的感知学习体验。它通过将真实空间数字化,让 AI 在虚拟环境中获得与物理世界高度相似的视觉和交互体验,从而解决传统仿真环境与现实差距过大、难以迁移的问题。
这个工具主要面向机器人学和人工智能领域的研究人员与开发者。如果你正在研究视觉导航、主动感知或强化学习,需要让 AI 在复杂三维空间中自主移动并理解环境,GibsonEnv 会是一个实用的选择。它也适合那些希望先在仿真环境中训练机器人策略、再部署到真实硬件的团队。
GibsonEnv 有几个值得关注的技术特点:首先,它的场景数据来自真实世界扫描,包含 572 个真实空间的 1440 层楼层,语义复杂度远高于人工设计的游戏场景;其次,内置的"Goggles"机制专门优化了从仿真到现实的迁移问题;最后,它集成了 Bullet 物理引擎,智能体的移动会受到真实物理约束,而非简单的碰撞检测。环境命名致敬了生态知觉理论家 James J. Gibson,体现了"感知与运动相互依存"的设计理念。
项目由斯坦福大学开发,2018 年入选 CVPR Spotlight Oral,支持 Docker 快速部署和 ROS 集成,降低了上手门槛。
使用场景
一家机器人初创公司正在开发一款家用服务机器人,需要训练其在真实家庭环境中完成导航和物品识别任务。
没有 GibsonEnv 时
- 开发团队只能依赖真实场景测试,需要搭建多个模拟房间,成本高昂且调整困难
- 真实环境中的测试速度受限,每次运行都需要人工干预,效率极低
- 由于机器人硬件脆弱,频繁的碰撞测试导致设备损坏率居高不下
- 缺乏对复杂语义信息(如家具类型、空间功能)的快速验证手段,算法迭代缓慢
- 难以保证训练环境的一致性,不同房间的光照、布局差异影响实验结果
使用 GibsonEnv 后
- 团队通过虚拟化的真实家庭场景进行训练,无需搭建实体环境,大幅降低开发成本
- 在仿真环境中可以全天候运行测试,无需人工干预,显著提升研发效率
- 借助内置物理引擎,机器人可以在虚拟环境中安全试错,避免硬件损耗
- 提供丰富的语义信息支持,开发者能快速验证感知算法的效果并优化模型
- 场景数据统一且可控,确保实验结果的可重复性和可靠性
GibsonEnv 让开发者在高度仿真的环境中高效训练机器人,真正实现了从虚拟到现实的无缝衔接。
运行环境要求
- Linux
需要 NVIDIA GPU,显存 >6GB,CUDA >=9.0(Docker 安装)或 CUDA >=8.0(源码安装)
未说明

快速开始
GIBSON 环境:用于真实感知的具身主动智能体
你不应该整天玩游戏,你的 AI 也不应该!我们构建了一个虚拟环境模拟器 Gibson,它通过真实世界的体验来学习感知。

概述:感知与主动性(即拥有一定程度的运动自由)密切相关。在物理世界中学习主动感知和传感器运动控制非常麻烦,因为现有算法太慢,无法高效地实时学习,而且机器人既脆弱又昂贵。这促使了在模拟环境中学习的兴起,但也引发了如何迁移到现实世界的问题。我们开发了 Gibson 环境,具有以下主要特点:
I. 源自真实世界,并通过虚拟化真实空间反映其语义复杂性,
II. 内置迁移到现实世界的机制(Goggles 功能),以及
III. 智能体的具身化,并通过集成物理引擎(Bulletphysics)使其受空间和物理约束。
命名:Gibson 环境以《视觉感知的生态学方法》(1979 年)的作者 James J. Gibson 命名。“我们必须感知才能行动,但我们也必须行动才能感知”——JJ Gibson
更多技术细节请参见 网站 (http://gibsonenv.stanford.edu/)。本仓库旨在分发环境并提供安装/运行说明。
论文
"Gibson Env: Real-World Perception for Embodied Agents",发表于 CVPR 2018 [Spotlight Oral]。

发布版本
这是 0.3.1 版本。欢迎并感谢提交错误报告、改进建议以及社区开发贡献。 更新日志文件。
数据库
完整数据库包含 572 个空间和 1440 个楼层,可从 这里 下载。Gibson 中所有空间的多样化可视化效果可在此处查看 here。为了减轻用户核心资产下载包的负担,我们仅包含了一小部分(39 个)空间。用户可以下载其余空间并将它们添加到资产文件夹中。我们还集成了 Stanford 2D3DS 和 Matterport 3D 作为单独的数据集,如果希望使用这些数据集与 Gibson 的模拟器(访问 此处)。
目录
安装
安装方法
有两种方式安装 Gibson:A. 使用我们的 Docker 镜像(推荐)和 B. 从源码构建。
系统要求
最低系统要求如下:
对于 Docker 安装(A):
- Ubuntu 16.04
- Nvidia GPU,显存 > 6.0GB
- Nvidia 驱动 >= 384
- CUDA >= 9.0,CuDNN >= v7
对于从源码构建(B):
- Ubuntu >= 14.04
- Nvidia GPU,显存 > 6.0GB
- Nvidia 驱动 >= 375
- CUDA >= 8.0,CuDNN >= v5
下载数据
首先,我们的环境核心资产数据可从 这里 获取。您可以按照以下安装指南下载并正确设置它们。gibson/assets 文件夹存储运行 Gibson 环境所需的必要数据(智能体模型、环境等)。用户可以将更多环境文件添加到 gibson/assets/dataset 中,以便在更多环境中运行 Gibson。访问 数据库 readme 下载更多空间。在使用 Gibson 数据库之前,请签署 许可协议。
A. 快速安装(docker)
我们使用 Docker 分发软件,您需要先安装 docker 和 nvidia-docker2.0。
运行 docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi 验证您的安装。
您可以选择 1. 从我们的 Docker 镜像拉取(推荐)或 2. 构建自己的 Docker 镜像。
- 从我们的 Docker 镜像拉取(推荐)
# 从 https://storage.googleapis.com/gibson_scenes/dataset.tar.gz 下载数据集
docker pull xf1280/gibson:0.3.1
xhost +local:root
docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <主机路径到数据集文件夹>:/root/mount/gibson/gibson/assets/dataset xf1280/gibson:0.3.1
- 构建自己的 Docker 镜像
git clone https://github.com/StanfordVL/GibsonEnv.git
cd GibsonEnv
./download.sh # 此脚本下载资产数据文件并解压缩到 gibson/assets 文件夹
docker build . -t gibson ### 在 Docker 内完成构建,默认情况下,数据集不会包含在 Docker 镜像中
xhost +local:root ## 启用 Docker 显示
如果安装成功,您应该能够运行 docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <主机路径到数据集文件夹>:/root/mount/gibson/gibson/assets/dataset gibson 创建一个容器。请注意,我们未将数据集文件包含在 Docker 镜像中以保持镜像轻量化,因此在启动容器时需要将其挂载到容器中。
关于无头服务器部署的注意事项
Gibson Env 支持在无头服务器上部署并通过 x11vnc 进行远程访问。
您可以使用上述 Dockerfile 构建自己的 Docker 镜像。
在无头服务器上运行 Gibson 的说明(需要 X 服务器运行):
- 按照入门指南安装
nvidia-docker2依赖项。使用sudo apt-get install x11vnc安装x11vnc。 - 在主机上运行 X server,并在 DISPLAY :0 上运行
x11vnc。 - 运行以下命令启动 Docker 容器:
docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix/X0:/tmp/.X11-unix/X0 -v <主机数据集文件夹路径>:/root/mount/gibson/gibson/assets/dataset <gibson 镜像名称> - 在 Docker 内通过
python <gibson 示例或训练脚本>运行 Gibson。 - 访问
主机:5900,你应该能够看到图形用户界面(GUI)。
如果你没有运行 X server,仍然可以运行 Gibson,请参阅此指南了解更多信息。
B. 从源码构建
如果你不想使用我们的 Docker 镜像,也可以在本地安装 Gibson。这需要安装一些依赖项。
首先,确保你已安装 Nvidia 驱动程序和 CUDA。如果从源码安装,CUDA 9 并不是必需的,因为这是为 nvidia-docker 2.0 准备的。然后,让我们安装一些依赖项:
apt-get update
apt-get install libglew-dev libglm-dev libassimp-dev xorg-dev libglu1-mesa-dev libboost-dev \
mesa-common-dev freeglut3-dev libopenmpi-dev cmake golang libjpeg-turbo8-dev wmctrl \
xdotool libzmq3-dev zlib1g-dev
```
安装所需的深度学习库:推荐使用 Python 3.5。你可以先创建一个 Python 3.5 环境。
```bash
conda create -n py35 python=3.5 anaconda
source activate py35 # 后续步骤需要在 conda 环境中执行
conda install -c conda-forge opencv
pip install http://download.pytorch.org/whl/cu90/torch-0.3.1-cp35-cp35m-linux_x86_64.whl
pip install torchvision==0.2.0
pip install tensorflow==1.3
克隆代码仓库,下载数据并构建:
git clone https://github.com/StanfordVL/GibsonEnv.git
cd GibsonEnv
./download.sh # 此脚本下载资产数据文件并解压到 gibson/assets 文件夹
./build.sh build_local ### 构建 C++ 和 CUDA 文件
pip install -e . ### 安装 Python 库
如果需要运行训练示例,请安装 OpenAI baselines。
git clone https://github.com/fxia22/baselines.git
pip install -e baselines
卸载
卸载 Gibson 很简单。如果你是通过 Docker 安装的,只需运行以下命令清理镜像:
docker images -a | grep "gibson" | awk '{print $3}' | xargs docker rmi
如果你是从源码安装的,则通过 pip uninstall gibson 卸载。
快速开始
首先在主机上运行 xhost +local:root 以启用显示。你可能需要先运行 export DISPLAY=:0。通过以下命令进入 Docker 容器:
docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v <主机数据集文件夹路径>:/root/mount/gibson/gibson/assets/dataset gibson
进入后,你会获得一个交互式 shell。现在可以运行一些示例。
如果你是从源码安装的,可以直接运行以下命令而无需使用 Docker。
python examples/demo/play_husky_nonviz.py ### 使用键盘上的 ASWD 键控制一辆车在 Gates 建筑周围导航

在此示例中,你可以使用键盘上的 ASWD 键控制一辆车在 Gates 建筑周围导航。此示例不会显示相机输出。
python examples/demo/play_husky_camera.py ### 使用键盘上的 ASWD 键控制一辆车在 Gates 建筑周围导航,同时显示 RGB 和深度相机输出

你可以使用键盘上的 ASWD 键控制一辆车在 Gates 建筑周围导航。你还可以看到 RGB 和深度相机的输出。
python examples/train/train_husky_navigate_ppo2.py ### 使用 PPO2 训练一辆车通过 Gates 建筑的走廊,使用相机的视觉输入
 运行此命令后,你将开始训练一个 Husky 机器人在 Gates 建筑中导航并通过走廊,使用 RGBD 输入。每轮结束后,你将在终端中看到一些强化学习相关的统计数据。
运行此命令后,你将开始训练一个 Husky 机器人在 Gates 建筑中导航并通过走廊,使用 RGBD 输入。每轮结束后,你将在终端中看到一些强化学习相关的统计数据。
python examples/train/train_ant_navigate_ppo1.py ### 使用 PPO1 训练一只蚂蚁通过 Gates 建筑的走廊,使用相机的视觉输入
 运行此命令后,你将开始训练一只蚂蚁在 Gates 建筑中导航并通过走廊,使用 RGBD 输入。每轮结束后,你将在终端中看到一些强化学习相关的统计数据。
运行此命令后,你将开始训练一只蚂蚁在 Gates 建筑中导航并通过走廊,使用 RGBD 输入。每轮结束后,你将在终端中看到一些强化学习相关的统计数据。
Gibson 帧率
以下是 Gibson 环境在不同平台上的帧率基准测试结果。请参考 fps 分支 获取重现结果的代码。
| 平台 | 测试环境:Intel E5-2697 v4 + NVIDIA Tesla V100 | ||
|---|---|---|---|
| 分辨率 [nxn] | 128 | 256 | 512 |
RGBD,网络前f |
109.1 | 58.5 | 26.5 |
RGBD,网络后f |
77.7 | 30.6 | 14.5 |
RGBD,小型网络后f |
87.4 | 40.5 | 21.2 |
| 仅深度 | 253.0 | 197.9 | 124.7 |
| 仅表面法线 | 207.7 | 129.7 | 57.2 |
| 仅语义 | 190.0 | 144.2 | 55.6 |
| 非视觉感官 | 396.1 | 396.1 | 396.1 |
我们还在 Intel I7 7700 + NVIDIA GeForce GTX 1070Ti 和 Intel I7 6580k + NVIDIA GTX 1080Ti 平台上进行了测试。每个任务的帧率差异在 10% 以内。
| 平台 (Platform) | 在 Intel E5-2697 v4 + NVIDIA Tesla V100 上测试的多进程 FPS | |||||
|---|---|---|---|---|---|---|
| 配置 (Configuration) | 512x512 episode 同步 | 512x512 frame 同步 | 256x256 episode 同步 | 256x256 frame 同步 | 128x128 episode 同步 | 128x128 frame 同步 |
| 1 进程 | 12.8 | 12.02 | 32.98 | 32.98 | 52 | 52 |
| 2 进程 | 23.4 | 20.9 | 60.89 | 53.63 | 86.1 | 101.8 |
| 4 进程 | 42.4 | 31.97 | 105.26 | 76.23 | 97.6 | 145.9 |
| 8 进程 | 72.5 | 48.1 | 138.5 | 97.72 | 113 | 151 |

Web 用户界面
运行 Gibson 时,可以通过 python gibson/utils/web_ui.py python gibson/utils/web_ui.py 5552 启动一个 Web 用户界面。这在您无法物理访问运行 Gibson 的机器或在无头云环境中运行时非常有用。您需要将配置文件中的 mode 更改为 web_ui 才能使用 Web 用户界面。

渲染语义 (Rendering Semantics)

当模型经过语义标注后,Gibson 可以提供逐像素、逐帧的语义掩码。目前我们已经整合了来自 Stanford 2D-3D-Semantics 数据集 和 Matterport 3D 的模型用于此目的。您可以在 Gibson 中通过 这里 访问它们。有关其语义类别和标注的列表,请参考原始数据集的文档。
有关在 Gibson 中渲染语义的详细说明,请参阅 语义说明。例如,在安装时附带的入门数据集中,space7 包含 Stanford 2D-3D-Semantics 风格的标注。
机器人代理 (Robotic Agents)
Gibson 提供了一组基础的代理。这些代理及其对应的感知观察视频可以在此处查看 here。

为了(可选地)抽象化低级控制和机器人动力学以便于高级任务,我们还为每个代理提供了一组实用和理想的控制器。
| 代理名称 (Agent Name) | 自由度 (DOF) | 信息 (Information) | 控制器 (Controller) |
|---|---|---|---|
| Mujoco Ant | 8 | OpenAI 链接 | 力矩 (Torque) |
| Mujoco Humanoid | 17 | OpenAI 链接 | 力矩 (Torque) |
| Husky 机器人 | 4 | ROS, 制造商 | 力矩、速度、位置 (Torque, Velocity, Position) |
| Minitaur 机器人 | 8 | 机器人页面, 制造商 | 正弦控制器 (Sine Controller) |
| JackRabbot | 2 | 斯坦福项目链接 | 力矩、速度、位置 (Torque, Velocity, Position) |
| TurtleBot | 2 | ROS, 制造商 | 力矩、速度、位置 (Torque, Velocity, Position) |
| 四轴飞行器 (Quadrotor) | 6 | 论文 | 位置 (Position) |
入门代码 (Starter Code)
更多演示示例可以在 examples/demo 文件夹中找到。
| 示例 (Example) | 说明 (Explanation) |
|---|---|
play_ant_camera.py |
使用键盘上的 1234567890qwerty 键控制蚂蚁在 Gates 大楼周围导航,同时显示 RGB 和深度相机输出。 |
play_ant_nonviz.py |
使用键盘上的 1234567890qwerty 键控制蚂蚁在 Gates 大楼周围导航。 |
play_drone_camera.py |
使用键盘上的 ASWDZX 键控制无人机在 Gates 大楼周围导航,同时显示 RGB 和深度相机输出。 |
play_drone_nonviz.py |
使用键盘上的 ASWDZX 键控制无人机在 Gates 大楼周围导航。 |
play_humanoid_camera.py |
使用键盘上的 1234567890qwertyui 键控制人形机器人在 Gates 大楼周围导航。开个玩笑,用键盘控制人形机器人太难了,你只能看着它摔倒。按 R 重置。RGB 和深度相机输出也会显示。 |
play_humanoid_nonviz.py |
看着人形机器人摔倒。按 R 重置。 |
play_husky_camera.py |
使用键盘上的 ASWD 键控制一辆车在 Gates 大楼周围导航,同时显示 RGB 和深度相机输出。 |
play_husky_nonviz.py |
使用键盘上的 ASWD 键控制一辆车在 Gates 大楼周围导航。 |
更多训练代码可以在 examples/train 文件夹中找到。
| 示例 (Example) | 说明 (Explanation) |
|---|---|
train_husky_navigate_ppo2.py |
使用 PPO2 训练一辆车沿着 Gates 大楼的走廊导航,使用相机的 RGBD 输入。 |
train_husky_navigate_ppo1.py |
使用 PPO1 训练一辆车沿着 Gates 大楼的走廊导航,使用相机的 RGBD 输入。 |
train_ant_navigate_ppo1.py |
使用 PPO1 训练一只蚂蚁沿着 Gates 大楼的走廊导航,使用相机的视觉输入。 |
train_ant_climb_ppo1.py |
使用 PPO1 训练一只蚂蚁沿着 Gates 大楼的楼梯下楼,使用相机的视觉输入。 |
train_ant_gibson_flagrun_ppo1.py |
使用 PPO1 训练一只蚂蚁在 Gates 大楼内追逐目标(一个红色立方体)。每次蚂蚁到达目标(或超时),目标会改变位置。 |
train_husky_gibson_flagrun_ppo1.py |
使用 PPO1 训练一辆车在 Gates 大楼内追逐目标(一个红色立方体)。每次车到达目标(或超时),目标会改变位置。 |
ROS 配置
我们在此处提供了使用 ROS 配置 Gibson 的示例。我们以 turtlebot 为例,在 Gibson 中训练策略后,只需进行极少的修改即可将其部署到 turtlebot 上。更多详细信息,请参阅 README。
编码你的强化学习(RL)智能体
你可以按照我们的约定来编写你的 RL 智能体。与我们的环境交互的接口非常简单(请参见本节末尾的一些示例)。
首先,可以通过创建 gibson/core/envs 文件夹中的类实例来创建一个环境。
env = AntNavigateEnv(is_discrete=False, config = config_file)
然后通过 env.step 执行一步模拟,并通过 env.reset() 重置环境。
obs, rew, env_done, info = env.step(action)
obs 提供了机器人的观测值。它是一个字典,每个组件作为键值对存在。其键由用户在配置文件中指定。例如,obs['nonviz_sensor'] 是本体感受传感器数据,obs['rgb_filled'] 是 RGB 相机数据。
rew 是定义的奖励。env_done 标志着一个回合的结束,例如当机器人“死亡”时。info 提供了此步骤的一些附加信息;有时我们用它传递额外的非视觉传感器值。
在设计 RL 算法和环境的接口时,我们主要遵循了 OpenAI gym 的约定。为了帮助用户更快上手环境,我们在 examples/train 提供了一些示例。我们使用的 RL 算法来自 openAI baselines,并经过一些调整以适配混合视觉和非视觉感官数据。 具体来说,我们使用了 PPO 和速度优化版本的 PPO。
环境配置
每个环境都通过一个 yaml 文件进行配置。yaml 文件的示例可以在 examples/configs 文件夹中找到。以下是对文件参数的解释。有关 Bullet 物理引擎的更多信息,请参阅文档 此处。
| 参数名称 | 示例值 | 解释 |
|---|---|---|
| envname | AntClimbEnv | 环境名称,确保它与环境的类名相同 |
| model_id | space1-space8 | 场景 ID,在测试版发布中,从 space1 到 space8 中选择 |
| target_orn | [0, 0, 3.14] | 导航的目标方向(欧拉角,单位为弧度),参考系为世界坐标系。对于非导航任务,此参数将被忽略。 |
| target_pos | [-7, 2.6, -1.5] | 导航的目标位置(单位为米),参考系为世界坐标系。对于非导航任务,此参数将被忽略。 |
| initial_orn | [0, 0, 3.14] | 导航的初始方向(单位为弧度),参考系为世界坐标系 |
| initial_pos | [-7, 2.6, 0.5] | 导航的初始位置(单位为米),参考系为世界坐标系 |
| fov | 1.57 | 相机的视场角(单位为弧度) |
| use_filler | true/false | 是否使用神经网络填充器。建议将此参数保持为 true。更多信息请参阅 Gibson 环境网站。 |
| display_ui | true/false | Gibson 有两种显示视觉输出的方式,要么在多个窗口中显示,要么将它们聚合到一个 pygame 窗口中。此参数决定是否显示 pygame UI,如果是在生产环境(训练)中,则需要将其关闭。 |
| show_diagnostics | true/false | 在 RGB 图像上叠加显示诊断信息(包括帧率、机器人位置和方向、累计奖励)。 |
| ui_num | 2 | 要显示的 UI 组件数量,这应该是 ui_components 的长度。 |
| ui_components | [RGB_FILLED, DEPTH] | UI 组件有哪些,可从 [RGB_FILLED, DEPTH, NORMAL, SEMANTICS, RGB_PREFILLED] 中选择。 |
| output | [nonviz_sensor, rgb_filled, depth] | 环境向机器人提供的输出,可从 [nonviz_sensor, rgb_filled, depth] 中选择。这些值独立于 ui_components,因为 ui_components 决定要显示的内容,而 output 决定机器人接收到的内容。 |
| resolution | 512 | 可从 [128, 256, 512] 中选择 RGB/深度图像的分辨率。 |
| initial_orn | [0, 0, 3.14] | 导航的初始方向(单位为弧度),参考系为世界坐标系。 |
| speed : timestep | 0.01 | 单个物理模拟步长的时间(以秒为单位,定义见 Bullet)。例如,如果 timestep=0.01 秒,frameskip=10,且环境以 100fps 运行,则模拟速度将是实时的 10 倍。注意:在当前版本的 Bullet 模拟器中,将 timestep 设置为高于 0.1 可能会导致不稳定,因为物体在一个时间步内不应移动超过其自身半径的距离。可以将 timestep 保持在较低值,但增加 frameskip 以实现更快的模拟速度。更多信息请参阅 Bullet 指南 中的“离散碰撞检测”。 |
| speed : frameskip | 10 | 渲染帧时跳过的时间步数。请参见上一行的示例。对于不需要高频控制的任务,可以将 frameskip 设置为更大的值以进一步加速。 |
| mode | gui/headless/web_ui | gui 或 headless,如果是在生产环境(训练)中,则需要将其设置为 headless。在 gui 模式下会有视觉输出;在 headless 模式下则没有视觉输出。此外,如果将模式设置为 web_ui,它的行为类似于 headless 模式,但视觉内容会渲染到 Web UI 服务器上。(更多信息) |
| verbose | true/false | 在终端中显示诊断信息 |
| fast_lq_render | true/false | 如果 yaml 文件中有 fast_lq_render,Gibson 将使用较小的填充网络,这将加快渲染速度,但生成的相机输出质量会略低。此选项对于快速训练 RL 智能体很有用。 |
创建自定义环境
Gibson 提供了一组方法供你定义自己的环境。你可以参考 gibson/core/envs 中现有的环境。
| 方法名称 | 用途 |
|---|---|
| robot.render_observation(pose) | 根据姿态 (pose) 渲染新的观测结果,返回一个字典。 |
| robot.get_observation() | 获取当前姿态下的观测结果。需要在调用 robot.render_observation(pose) 后使用。此操作不会引入额外的计算。 |
| robot.get_position() | 获取机器人当前位置。 |
| robot.get_orientation() | 获取机器人当前方向。 |
| robot.eyes.get_position() | 获取机器人感知相机的当前位置。 |
| robot.eyes.get_orientation() | 获取机器人感知相机的当前方向。 |
| robot.get_target_position() | 获取机器人目标位置。 |
| robot.apply_action(action) | 对机器人应用动作 (action)。 |
| robot.reset_new_pose(pos, orn) | 将机器人重置为任意姿态 (pose)。 |
| robot.dist_to_target() | 获取机器人到目标的当前距离。 |
Goggles:将智能体迁移到现实世界
Gibson 包含一种内置的域适应机制,名为 Goggles(护目镜),用于将在 Gibson 中训练的智能体部署到现实世界时(即基于车载摄像头传来的图像进行操作)。该机制本质上是一个学习到的逆函数,可以将来自真实摄像头的画面调整为看起来像是通过 Gibson 渲染的效果,从而消除域差异。
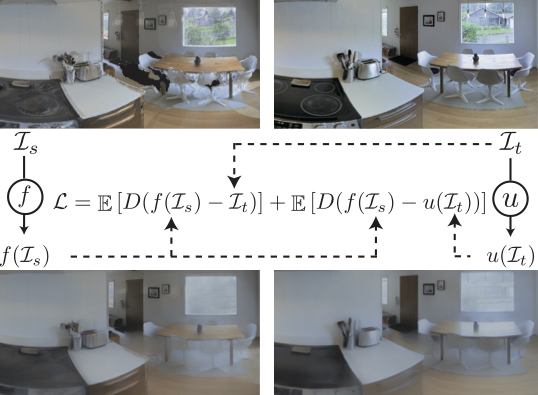
更多细节: 尽管点云渲染存在各种不完美之处,但事实证明,通过神经网络修复实现完全逼真的渲染非常困难。剩余的问题导致合成图像与真实图像之间存在域差异。因此,我们将渲染问题定义为构建一个联合空间,确保渲染图像与真实图像之间的对应关系,而不是试图(徒劳地)渲染出与真实图像完全相同的图像。这提供了一种确定性的跨域路径,从而消除了域差异。我们为目标图像 (I_t) 添加了另一个网络 "u",并定义了渲染损失以最小化 f(I_s) 和 u(I_t) 之间的距离,其中 "f" 和 "I_s" 分别表示填充神经网络和点云渲染输出(见上图中的损失公式)。我们对 f 和 u 使用了相同的网络结构。函数 u(I) 被训练用于调整现实世界中的观测值 I_t,使其看起来像对应的 I_s,从而消除域差异。我们将 u 网络命名为 Goggles(护目镜),因为它类似于智能体在现实世界中部署时的矫正镜片。该机制的详细公式和讨论请参阅论文。您可以下载函数 u 并在现实世界中部署训练好的智能体时应用它。
为了使用 Goggle,您最好配备一个带深度传感器的摄像头,我们在此提供了一个 Kinect 的示例 这里。训练好的 Goggle 函数存储在 assets/unfiller_{resolution}.pth 中,每个函数都与一个填充函数配对。您需要根据所使用的填充函数选择正确的 Goggle 函数。如果您没有带深度传感器的摄像头,我们也提供了一个仅支持 RGB 的示例 这里。
引用
如果您使用 Gibson 环境的软件或数据库,请引用:
@inproceedings{xiazamirhe2018gibsonenv,
title={Gibson {Env}: real-world perception for embodied agents},
author={Xia, Fei and R. Zamir, Amir and He, Zhi-Yang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio},
booktitle={Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on},
year={2018},
organization={IEEE}
}
版本历史
v0.3.12018/08/11v0.1.02018/02/26常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。