top-cvpr-2024-papers
top-cvpr-2024-papers 是一个精心整理的计算机视觉领域顶级会议论文资源库。作为全球最具影响力的计算机视觉与模式识别会议之一,CVPR 2024 收到了超过一万一千篇投稿,最终录用两千多篇。面对如此庞大的信息量,普通研究者很难快速锁定最有价值的成果。
top-cvpr-2024-papers 旨在解决“选论文难”的问题,专门收录了当年最受瞩目和具有影响力的论文。它不仅提供论文原文链接,还整合了对应的开源代码和演示视频,让技术复现变得更加便捷。从三维重建到文本生成图像,涵盖了 SpatialTracker、ViewDiff 等多个热门方向。
无论是从事深度学习的研究人员、希望跟进前沿技术的开发者,还是对计算机视觉感兴趣的学生,都能在这里高效获取高质量的学习资料。列表由社区贡献并自动生成更新,确保了内容的时效性和多样性。通过 top-cvpr-2024-papers,你可以轻松跳过海量筛选过程,直接聚焦于真正推动行业发展的核心创新。
使用场景
某互联网公司的视觉算法工程师小张,负责开发新一代增强现实应用,急需了解 CVPR 2024 中关于多视图几何与 3D 生成的最新进展。
没有 top-cvpr-2024-papers 时
- 面对超过一万一千篇投稿,人工筛选高影响力论文如同大海捞针,耗费大量时间。
- 即使找到目标论文,也常面临代码缺失或环境配置困难,导致复现尝试屡屡失败。
- 难以快速区分理论创新与实际落地价值,容易陷入对低质量工作的无效阅读。
- 缺乏直观的 Demo 视频参考,仅凭文字描述难以评估模型在真实场景中的表现。
使用 top-cvpr-2024-papers 后
- 直接获取精心挑选的精华论文列表,跳过海量无关信息,调研效率提升数倍。
- 每个条目均提供 Paper、Code 及 Demo 的直接链接,确保资源可用且易于上手。
- 按 3D 重建等主题清晰分类,能快速定位 SpatialTracker 等关键技术的实现细节。
- 通过 Highlight 标记优先关注社区认可的核心成果,避免被边缘研究分散精力。
top-cvpr-2024-papers 将碎片化的学术资源整合成高效的知识地图,让研究人员能迅速站在巨人的肩膀上开始创新。
运行环境要求
- 未说明
未说明
未说明

快速开始


👋 你好
计算机视觉与模式识别(Computer Vision and Pattern Recognition,简称 CVPR)是一个大型会议。仅在 2024 年, 就有 11,532 篇论文提交,其中 2,719 篇被录用。我创建了这个仓库 来帮助你搜索 CVPR 出版物中的精华。如果你正在寻找的论文不在我的精选列表中,请查看完整的 已录用论文列表。
🗞️ 论文与海报
🔥 - 重点推荐论文
多视图与传感器三维重建
 🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
[论文] [代码]
主题: 多视图与传感器三维重建
场次: 周五 6 月 21 日 下午 1:30 EDT — 下午 3:00 EDT #84
 ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Lukas Höllein, Aljaž Božič, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, Matthias Nießner
[论文] [代码] [视频]
主题: 多视图与传感器三维重建
场次: 周三 6 月 19 日 晚上 8:00 EDT — 晚上 9:30 EDT #20
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, Andre Araujo
[论文] [代码] [演示]
主题: 多视图与传感器三维重建
场次: 周五 6 月 21 日 下午 1:30 EDT — 下午 3:00 EDT #32
深度学习架构与技术
 🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan
[论文] [视频] [演示] [colab]
主题: 深度学习架构与技术
场次: 周三 6 月 19 日 晚上 8:00 EDT — 晚上 9:30 EDT #102
文档分析与理解
DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
Jiaxin Zhang, Dezhi Peng, Chongyu Liu, Peirong Zhang, Lianwen Jin
[论文] [代码] [演示]
主题: 文档分析与理解
场次: 周四 6 月 20 日 晚上 8:00 EDT — 晚上 9:30 EDT #101
高效且可扩展的视觉
 🔥 EfficientSAM:利用掩码图像预训练(Masked Image Pretraining)实现高效的 Segment Anything(分割一切)
🔥 EfficientSAM:利用掩码图像预训练(Masked Image Pretraining)实现高效的 Segment Anything(分割一切)
Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra
[论文] [代码] [演示]
主题: 高效且可扩展的视觉
会议场次: 周四 6 月 20 日 晚上 8 点 EDT(东部夏令时)— 晚上 9:30 点 EDT #144
 MobileCLIP:通过多模态强化训练实现快速图文模型
MobileCLIP:通过多模态强化训练实现快速图文模型
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel
[论文] [代码] [演示]
主题: 高效且可扩展的视觉
会议场次: 周四 6 月 20 日 晚上 8 点 EDT — 晚上 9:30 点 EDT #130
可解释计算机视觉
 🔥 使用自然语言描述图像集之间的差异
🔥 使用自然语言描述图像集之间的差异
Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy
[论文] [代码]
主题: 可解释计算机视觉
会议场次: 周五 6 月 21 日 晚上 8 点 EDT — 晚上 9:30 点 EDT #115
图像和视频合成与生成
DemoFusion:零成本普及高分辨率图像生成
Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma
[论文] [代码] [演示] [Colab(Google Colaboratory)]
主题: 图像和视频合成与生成
会议场次: 周三 6 月 19 日 晚上 8 点 EDT — 晚上 9:30 点 EDT #132
 🔥 DragDiffusion:利用 Diffusion Models(扩散模型)进行交互式基于点的图像编辑
🔥 DragDiffusion:利用 Diffusion Models(扩散模型)进行交互式基于点的图像编辑
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
[论文] [代码] [视频]
主题: 图像和视频合成与生成
会议场次: 周三 6 月 19 日 晚上 8 点 EDT — 晚上 9:30 点 EDT #392
 🔥 视觉字谜:利用扩散模型生成多视角光学错觉
🔥 视觉字谜:利用扩散模型生成多视角光学错觉
Daniel Geng, Inbum Park, Andrew Owens
[论文] [代码] [Colab]
主题: 图像和视频合成与生成
会议场次: 周五 6 月 21 日 晚上 8 点 EDT — 晚上 9:30 点 EDT #118
低级视觉 (low-level vision)
 XFeat: Accelerated Features for Lightweight Image Matching
XFeat: Accelerated Features for Lightweight Image Matching
Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento
[论文] [代码] [视频] [演示] [Colab]
主题: 低级视觉
场次: 6 月 19 日周三 下午 1:30 EDT — 下午 3:00 EDT #245
 Robust Image Denoising through Adversarial Frequency Mixup
Robust Image Denoising through Adversarial Frequency Mixup
Donghun Ryou, Inju Ha, Hyewon Yoo, Dongwan Kim, Bohyung Han
[论文] [代码] [视频]
主题: 低级视觉
场次: 6 月 19 日周三 下午 1:30 EDT — 下午 3:00 EDT #250
多模态学习 (multi-modal learning)
🔥 Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
[论文] [代码]
主题: 多模态学习
场次: 6 月 21 日周五 晚上 8:00 EDT — 晚上 9:30 EDT #209
识别:分类、检测、检索 (recognition: categorization, detection, retrieval)
 DETRs Beat YOLOs on Real-time Object Detection
DETRs Beat YOLOs on Real-time Object Detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
[论文] [代码] [视频]
主题: 识别:分类、检测、检索
场次: 6 月 20 日周四 晚上 8:00 EDT — 晚上 9:30 EDT #229
 YOLO-World: Real-Time Open-Vocabulary Object Detection
YOLO-World: Real-Time Open-Vocabulary Object Detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
[论文] [代码] [视频] [演示] [Colab]
主题: 识别:分类、检测、检索
场次: 6 月 20 日周四 晚上 8:00 EDT — 晚上 9:30 EDT #223
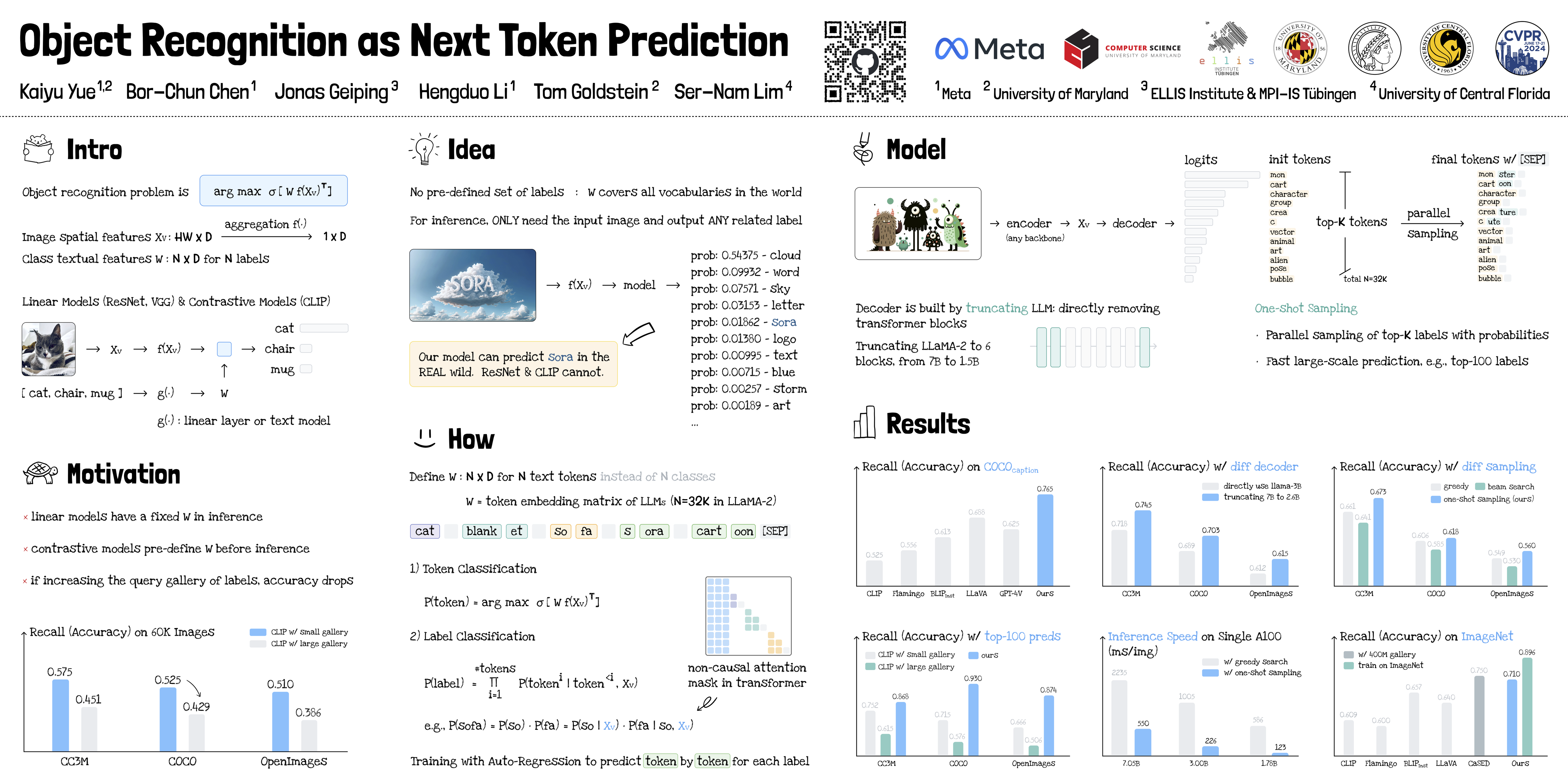 🔥 Object Recognition as Next Token Prediction
🔥 Object Recognition as Next Token Prediction
Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, Ser-Nam Lim
[论文] [代码] [视频] [Colab]
主题: 识别:分类、检测、检索
场次: 6 月 20 日周四 晚上 8:00 EDT — 晚上 9:30 EDT #199
分割、分组与形状分析
 🔥 RobustSAM:在退化图像上鲁棒地分割任意对象
🔥 RobustSAM:在退化图像上鲁棒地分割任意对象
Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhou Ma, Jian Wang
[论文] [视频]
主题: 分割、分组与形状分析
场次: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #378
 🔥 Frozen CLIP:用于弱监督语义分割的强大骨干网络
🔥 Frozen CLIP:用于弱监督语义分割的强大骨干网络
Bingfeng Zhang, Siyue Yu, Yunchao Wei, Yao Zhao, Jimin Xiao
[论文] [代码] [视频]
主题: 分割、分组与形状分析
场次: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #351
 🔥 面向点提示实例分割的语义感知 SAM
🔥 面向点提示实例分割的语义感知 SAM
Zhaoyang Wei, Pengfei Chen, Xuehui Yu, Guorong Li, Jianbin Jiao, Zhenjun Han
[论文] [代码] [视频]
主题: 分割、分组与形状分析
场次: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #331
🔥 上下文抠图
He Guo, Zixuan Ye, Zhiguo Cao, Hao Lu
[论文] [代码]
主题: 分割、分组与形状分析
场次: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #343
 🔥 大规模通用图像和视频对象基础模型
🔥 大规模通用图像和视频对象基础模型
Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, Song Bai
[论文] [代码] [视频]
主题: 分割、分组与形状分析
场次: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #350
自监督或无监督表示学习
 🔥 InternVL:扩展视觉基础模型并适配通用视觉 - 语言任务
🔥 InternVL:扩展视觉基础模型并适配通用视觉 - 语言任务
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai
[论文] [代码] [演示]
主题: 自监督或无监督表示学习
场次: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #412
视频:底层分析、运动与跟踪
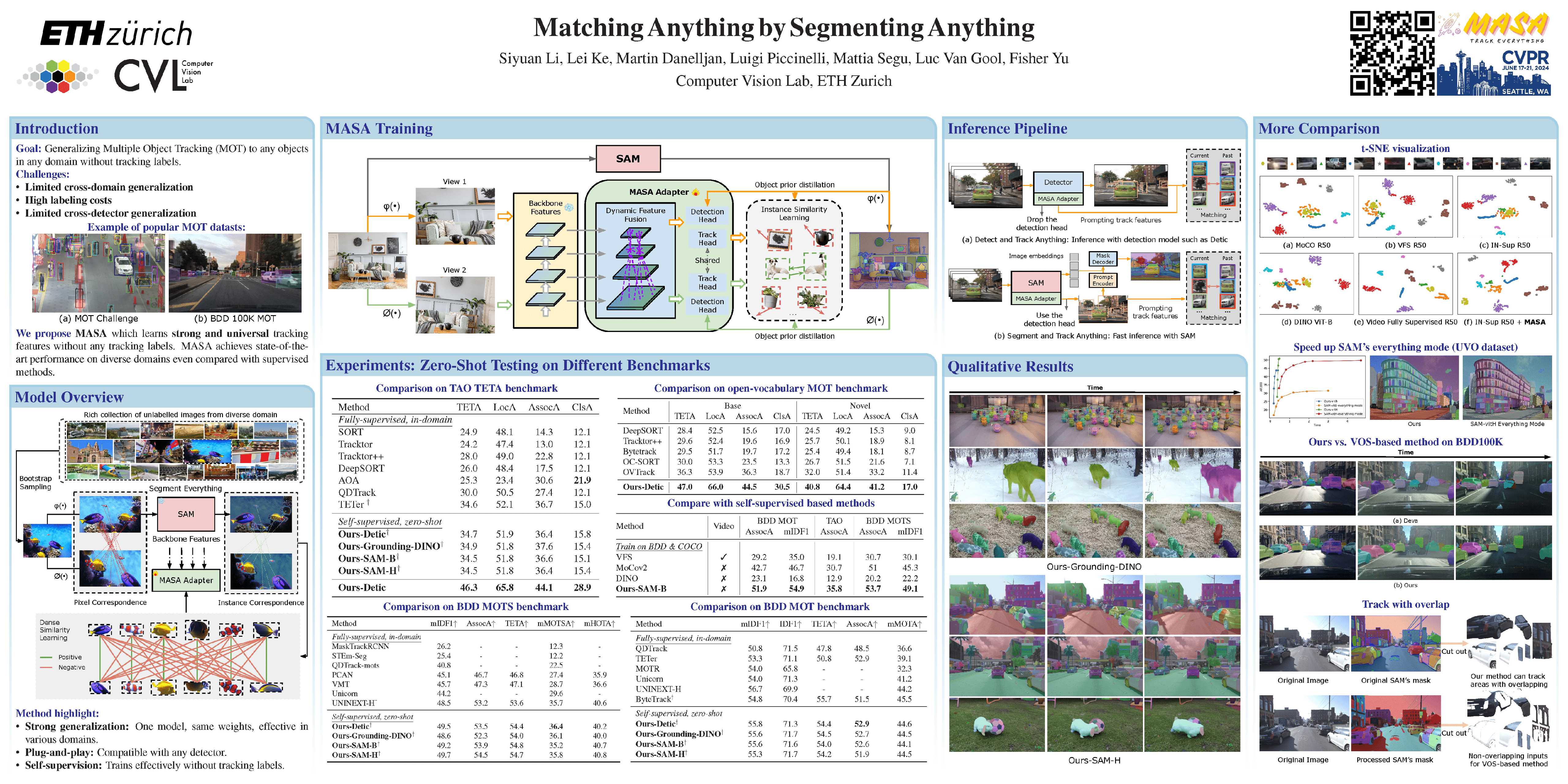 🔥 通过分割任意对象实现任意匹配
🔥 通过分割任意对象实现任意匹配
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
[论文] [代码] [视频]
主题: 视频:底层分析、运动与跟踪
会议场次: 6 月 20 日周四 晚上 8:00 EDT(东部夏令时)— 9:30 PM EDT #421
 DiffMOT:一种基于扩散模型的实时非线性预测多目标跟踪器
DiffMOT:一种基于扩散模型的实时非线性预测多目标跟踪器
Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, Dan Zeng
[论文] [代码]
主题: 视频:底层分析、运动与跟踪
会议场次: 6 月 20 日周四 晚上 8:00 EDT(东部夏令时)— 9:30 PM EDT #455
视觉、语言与推理
 Alpha-CLIP:一个关注任意位置的 CLIP 模型
Alpha-CLIP:一个关注任意位置的 CLIP 模型
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
[论文] [代码] [视频] [演示]
主题: 视觉、语言与推理
场次: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #327
🔥 睁眼瞎?探索多模态大语言模型的视觉短板
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
[论文] [代码]
主题: 视觉、语言与推理
场次: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #390
 🔥 LISA:通过大语言模型进行推理分割
🔥 LISA:通过大语言模型进行推理分割
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
[论文] [代码] [演示]
主题: 视觉、语言与推理
场次: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #413
 ViP-LLaVA:使大型多模态模型理解任意视觉提示
ViP-LLaVA:使大型多模态模型理解任意视觉提示
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
[论文] [代码] [视频] [演示]
主题: 视觉、语言与推理
场次: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #317
 🔥 MMMU:面向专家级 AGI(通用人工智能)的超大规模多学科多模态理解与推理基准
🔥 MMMU:面向专家级 AGI(通用人工智能)的超大规模多学科多模态理解与推理基准
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen
[论文]
主题: 视觉、语言与推理
场次: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #382
🦸 贡献
我们非常乐意得到您的帮助,以使本仓库变得更好!如果您知道这里有遗漏的精彩论文,或者有任何改进建议,请随时提交 问题 或提交 拉取请求。
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。