ChineseBert
ChineseBERT 是一款专为中文自然语言处理设计的预训练模型,旨在通过融合汉字的字形与拼音信息,显著提升模型对中文语义的理解能力。传统模型往往仅依赖字符编码,难以有效区分多音字或捕捉汉字表面的视觉特征,而 ChineseBERT 创新性地为每个汉字构建了三种嵌入表示:标准的字符嵌入、基于多种字体提取的字形嵌入,以及反映发音特征的拼音嵌入。这三者经过融合后输入 BERT 架构,使模型既能“看”懂字形结构,又能“听”懂读音线索,从而更精准地消歧多音字并捕捉深层上下文语义。
该工具特别适合从事中文 NLP 研究的科研人员、需要高性能中文基座模型的开发者,以及希望探索多模态字符表示的技术团队。ChineseBERT 提供了 Base 和 Large 两种规格,兼容 Hugging Face 生态,支持快速加载与微调,已在多个中文基准测试中验证了其优越性能。无论是进行文本分类、命名实体识别,还是掩码语言建模任务,ChineseBERT 都能凭借独特的字形 - 拼音增强机制,为用户提供更鲁棒、更细腻的中文语言理解能力。
使用场景
某电商平台的智能客服团队正在优化自动回复系统,旨在提升对用户评论中多音字、生僻字及形近错别字的理解准确率。
没有 ChineseBert 时
- 多音字歧义严重:面对“行长(háng/zhǎng)”或“重(chóng/zhòng)量”等词汇,传统模型仅靠上下文猜测,常因语境模糊导致意图识别错误。
- 形近错别字鲁棒性差:用户输入将“退款”误写为“退宽”,或把“登录”写成“登灵”时,模型无法捕捉字形相似性,直接判定为无关词汇。
- 生僻字处理失效:遇到品牌名或地名中的生僻字(如"𠮷野家”),由于缺乏字形特征输入,模型往往将其标记为未知 token,导致整句语义断裂。
- 冷启动数据依赖高:在新品类上线初期,缺乏足够标注数据训练特定词汇,模型难以快速适应新出现的专有名词。
使用 ChineseBert 后
- 拼音信息消除歧义:ChineseBert 引入拼音嵌入,能直接区分“银行行长”与“道路行走”,大幅降低多音字导致的分类错误率。
- 字形特征纠正错别字:通过融合 Glyph 嵌入,模型能识别“退宽”与“退款”在视觉结构上的高度相似,自动修正用户拼写错误并准确响应。
- 生僻字语义完整保留:即使面对未登录的生僻字,ChineseBert 也能通过笔画和字体结构提取有效特征,确保包含生僻字的句子语义不被截断。
- 小样本场景泛化强:凭借对汉字本身音形信息的深度预训练,在新品类冷启动阶段,无需大量标注数据即可精准理解新出现的商品名称。
ChineseBert 通过深度融合汉字的音、形、义三维信息,从根本上解决了中文 NLP 任务中因字符表面形式复杂而导致的语义理解瓶颈。
运行环境要求
- 未说明
实验复现建议使用 NVIDIA GPU,需安装 CUDA 10.1 (cu101)
未说明

快速开始
ChineseBERT:融合字形与拼音信息的中文预训练模型
本仓库包含 ACL2021 上发表的 ChineseBERT 的代码、模型及数据集。
ChineseBERT:融合字形与拼音信息的中文预训练模型
孙子俊、李晓娅、孙晓飞、孟宇贤、敖翔、何青、吴飞、李继伟
使用指南
| 章节 | 说明 |
|---|---|
| 简介 | ChineseBERT 简介 |
| 下载 | ChineseBERT 模型下载链接 |
| 快速入门 | 快速加载模型的方法 |
| 实验 | 在不同中文 NLP 数据集上的实验结果 |
| 引用 | 引用方式 |
| 联系我们 | 如何联系我们 |
简介
我们提出了 ChineseBERT,该模型在语言模型预训练过程中同时融入了汉字的字形和拼音信息。
首先,对于每一个汉字,我们生成三种类型的嵌入:
- 字符嵌入:与原始 BERT 的词元嵌入相同。
- 字形嵌入:基于不同字体的汉字视觉特征提取。
- 拼音嵌入:从汉字的拼音序列中捕捉语音特征。
随后,将字符嵌入、字形嵌入和拼音嵌入拼接在一起,并通过一个全连接层映射到 D 维空间,形成融合嵌入。
最后,将融合嵌入与位置嵌入相加,作为 BERT 模型的输入。
下图展示了 ChineseBERT 模型的整体架构。
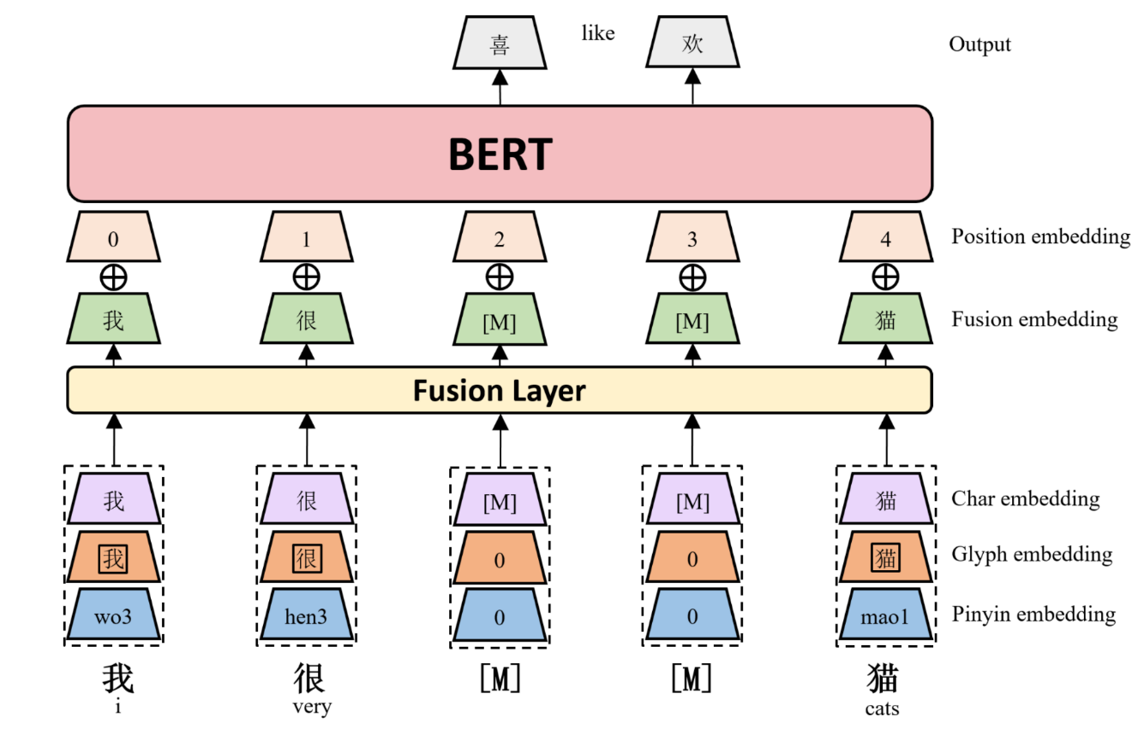
ChineseBERT 利用汉字的字形和拼音信息,增强了模型从字符表面形式中捕捉上下文语义的能力,并有效消除了中文中的多音字歧义。
下载
我们提供了 PyTorch 版本的预训练 ChineseBERT 模型,遵循 Hugging Face 的模型格式。
ChineseBERT-base:12 层,768 隐层,12 头注意力机制,参数量为 1.47 亿ChineseBERT-large:24 层,1024 隐层,16 头注意力机制,参数量为 3.74 亿
您可在此处下载我们的模型:
| 模型 | Model Hub | Google Drive |
|---|---|---|
ChineseBERT-base |
564M | 560M |
ChineseBERT-large |
1.4G | 1.4G |
注:Model Hub 包含模型文件、字体文件以及拼音配置文件。
快速入门
我们使用 Hugging Face 框架训练模型,因此可以轻松加载。
请下载 ChineseBERT 模型并保存至 [CHINESEBERT_PATH]。
以下是一个快速加载模型的示例:
>>> from models.modeling_glycebert import GlyceBertForMaskedLM
>>> chinese_bert = GlyceBertForMaskedLM.from_pretrained([CHINESEBERT_PATH])
>>> print(chinese_bert)
完整的示例请参阅:
使用 ChineseBERT 进行掩码词预测
另一个获取句子表示的示例:
>>> from datasets.bert_dataset import BertDataset
>>> from models.modeling_glycebert import GlyceBertModel
>>> tokenizer = BertDataset([CHINESEBERT_PATH])
>>> chinese_bert = GlyceBertModel.from_pretrained([CHINESEBERT_PATH])
>>> 句子 = '我喜欢猫'
>>> input_ids, pinyin_ids = tokenizer.tokenize_sentence(sentence)
>>> length = input_ids.shape[0]
>>> input_ids = input_ids.view(1, length)
>>> pinyin_ids = pinyin_ids.view(1, length, 8)
>>> output_hidden = chinese_bert.forward(input_ids, pinyin_ids)[0]
>>> print(output_hidden)
tensor([[[ 0.0287, -0.0126, 0.0389, ..., 0.0228, -0.0677, -0.1519],
[ 0.0144, -0.2494, -0.1853, ..., 0.0673, 0.0424, -0.1074],
[ 0.0839, -0.2989, -0.2421, ..., 0.0454, -0.1474, -0.1736],
[-0.0499, -0.2983, -0.1604, ..., -0.0550, -0.1863, 0.0226],
[ 0.1428, -0.0682, -0.1310, ..., -0.1126, 0.0440, -0.1782],
[ 0.0287, -0.0126, 0.0389, ..., 0.0228, -0.0677, -0.1519]]],
grad_fn=<NativeLayerNormBackward>)
完整代码请参见 此处
实验结果
ChnSetiCorp
ChnSetiCorp 是一个情感分析数据集。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 95.4 | 95.5 |
| BERT | 95.1 | 95.4 |
| BERT-wwm | 95.4 | 95.3 |
| RoBERTa | 95.0 | 95.6 |
| MacBERT | 95.2 | 95.6 |
| ChineseBERT | 95.6 | 95.7 |
| ---- | ---- | |
| RoBERTa-large | 95.8 | 95.8 |
| MacBERT-large | 95.7 | 95.9 |
| ChineseBERT-large | 95.8 | 95.9 |
训练细节及代码请参见 此处
THUCNews
THUCNews 包含 10 类新闻。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 95.4 | 95.5 |
| BERT | 95.1 | 95.4 |
| BERT-wwm | 95.4 | 95.3 |
| RoBERTa | 95.0 | 95.6 |
| MacBERT | 95.2 | 95.6 |
| ChineseBERT | 95.6 | 95.7 |
| ---- | ---- | |
| RoBERTa-large | 95.8 | 95.8 |
| MacBERT-large | 95.7 | 95.9 |
| ChineseBERT-large | 95.8 | 95.9 |
训练细节及代码请参见 此处
XNLI
XNLI 是一个自然语言推理数据集。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 79.7 | 78.6 |
| BERT | 79.0 | 78.2 |
| BERT-wwm | 79.4 | 78.7 |
| RoBERTa | 80.0 | 78.8 |
| MacBERT | 80.3 | 79.3 |
| ChineseBERT | 80.5 | 79.6 |
| ---- | ---- | |
| RoBERTa-large | 82.1 | 81.2 |
| MacBERT-large | 82.4 | 81.3 |
| ChineseBERT-large | 82.7 | 81.6 |
训练细节及代码请参见 此处
BQ
BQ 语料库是一个句子对匹配数据集。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 86.3 | 85.0 |
| BERT | 86.1 | 85.2 |
| BERT-wwm | 86.4 | 85.3 |
| RoBERTa | 86.0 | 85.0 |
| MacBERT | 86.0 | 85.2 |
| ChineseBERT | 86.4 | 85.2 |
| ---- | ---- | |
| RoBERTa-large | 86.3 | 85.8 |
| MacBERT-large | 86.2 | 85.6 |
| ChineseBERT-large | 86.5 | 86.0 |
训练细节及代码请参见 此处
LCQMC
LCQMC语料库是一个句子对匹配数据集。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 89.8 | 87.2 |
| BERT | 89.4 | 87.0 |
| BERT-wwm | 89.6 | 87.1 |
| RoBERTa | 89.0 | 86.4 |
| MacBERT | 89.5 | 87.0 |
| ChineseBERT | 89.8 | 87.4 |
| ---- | ---- | |
| RoBERTa-large | 90.4 | 87.0 |
| MacBERT-large | 90.6 | 87.6 |
| ChineseBERT-large | 90.5 | 87.8 |
训练细节和代码可在这里找到。
TNEWS
TNEWS是一个包含15个类别的短新闻文本分类数据集。
评估指标:准确率
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 58.24 | 58.33 |
| BERT | 56.09 | 56.58 |
| BERT-wwm | 56.77 | 56.86 |
| RoBERTa | 57.51 | 56.94 |
| ChineseBERT | 58.64 | 58.95 |
| ---- | ---- | |
| RoBERTa-large | 58.32 | 58.61 |
| ChineseBERT-large | 59.06 | 59.47 |
训练细节和代码可在这里找到。
CMRC
CMRC是一个机器阅读理解任务数据集。
评估指标:EM
| 模型 | 开发集 | 测试集 |
|---|---|---|
| ERNIE | 66.89 | 74.70 |
| BERT | 66.77 | 71.60 |
| BERT-wwm | 66.96 | 73.95 |
| RoBERTa | 67.89 | 75.20 |
| MacBERT | - | - |
| ChineseBERT | 67.95 | 95.7 |
| ---- | ---- | |
| RoBERTa-large | 70.59 | 77.95 |
| ChineseBERT-large | 70.70 | 78.05 |
训练细节和代码可在这里找到。
OntoNotes
OntoNotes 4.0是一个中文命名实体识别数据集,包含18种命名实体类型。
评估指标:跨度级别F1
| 模型 | 测试精确率 | 测试召回率 | 测试F1 |
|---|---|---|---|
| BERT | 79.69 | 82.09 | 80.87 |
| RoBERTa | 80.43 | 80.30 | 80.37 |
| ChineseBERT | 80.03 | 83.33 | 81.65 |
| ---- | ---- | ---- | |
| RoBERTa-large | 80.72 | 82.07 | 81.39 |
| ChineseBERT-large | 80.77 | 83.65 | 82.18 |
为复现实验结果,请通过pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html安装并使用torch1.7.1+cu101。
训练细节和代码可在这里找到。
Weibo是一个中文命名实体识别数据集,包含4种命名实体类型。
评估指标:跨度级别F1
| 模型 | 测试精确率 | 测试召回率 | 测试F1 |
|---|---|---|---|
| BERT | 67.12 | 66.88 | 67.33 |
| RoBERTa | 68.49 | 67.81 | 68.15 |
| ChineseBERT | 68.27 | 69.78 | 69.02 |
| ---- | ---- | ---- | |
| RoBERTa-large | 66.74 | 70.02 | 68.35 |
| ChineseBERT-large | 68.75 | 72.97 | 70.80 |
为复现实验结果,请通过pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html安装并使用torch1.7.1+cu101。
训练细节和代码可在这里找到。
引用
@article{sun2021chinesebert,
title={ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information},
author={Sun, Zijun and Li, Xiaoya and Sun, Xiaofei and Meng, Yuxian and Ao, Xiang and He, Qing and Wu, Fei and Li, Jiwei},
journal={arXiv preprint arXiv:2106.16038},
year={2021}
}
联系方式
如您对我们的论文/代码/模型/数据等有任何疑问,
欢迎通过GitHub Issues或电子邮件与我们交流。
您可以通过以下邮箱联系我们:zijun_sun@shannonai.com 或 xiaoya_li@shannonai.com。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。