alibi
Alibi 是一款专为机器学习模型设计的开源 Python 库,致力于实现模型的检查与解释。在实际应用中,许多复杂的算法如同“黑盒”,让人难以理解其决策逻辑。Alibi 正是为了解决这一透明度问题而生,它提供了一套高质量的方法,帮助用户深入洞察分类和回归模型的工作原理。
无论是针对黑盒还是白盒模型,Alibi 都支持局部和全局的解释策略。其技术亮点丰富,涵盖了图像领域的锚点解释、文本分析的集成梯度、反事实示例生成以及累积局部效应分析等先进算法。这些功能让模型的可信度评估变得更加直观。
Alibi 非常适合机器学习开发者、数据科学家及研究人员使用。通过 Alibi,团队可以更自信地部署模型,排查潜在偏差。此外,若需进行异常检测或对抗实例识别,还可结合其姊妹项目 alibi-detect 一同使用。完善的文档和社区支持也让上手过程更加顺畅。
使用场景
某金融科技公司的数据科学团队正在部署一款高风险信贷审批模型,业务方对部分优质客户的自动拒贷决定提出强烈质疑,急需透明化解释。
没有 alibi 时
- 模型决策如同黑盒,无法直观量化各特征对最终结果的贡献权重
- 排查特定样本的错误预测需手动编写脚本分析,排查效率极其低下
- 面对金融监管审查,难以提供具体、可解释的拒贷依据与证据
- 模型上线后若出现性能波动,无法快速定位是数据分布漂移还是算法问题
使用 alibi 后
- 利用内置的 SHAP 和 LIME 算法,一键生成可视化的特征归因报告
- 通过反事实示例功能,模拟调整关键指标(如收入)后的预测变化路径
- 自动生成符合合规要求的解释文档,大幅降低与法务及监管部门的沟通成本
- 结合全局累积效应分析,精准识别模型在不同客群中的潜在偏差与公平性问题
alibi 将复杂的深度学习决策转化为可理解的业务逻辑,显著提升了模型的可信度与落地效率。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始

![]()

![]()




![]()
Alibi 是一个源代码可用的 Python 库,旨在用于机器学习模型检查和解释。 该库的重点是为分类和回归模型提供高质量的黑盒、白盒、局部和全局解释方法的实现。
如果您对外部检测、概念漂移或对抗实例检测感兴趣,请查看我们的姊妹项目 alibi-detect。
|
图像的 Anchor 解释 
|
文本的集成梯度 
|
|
反事实示例 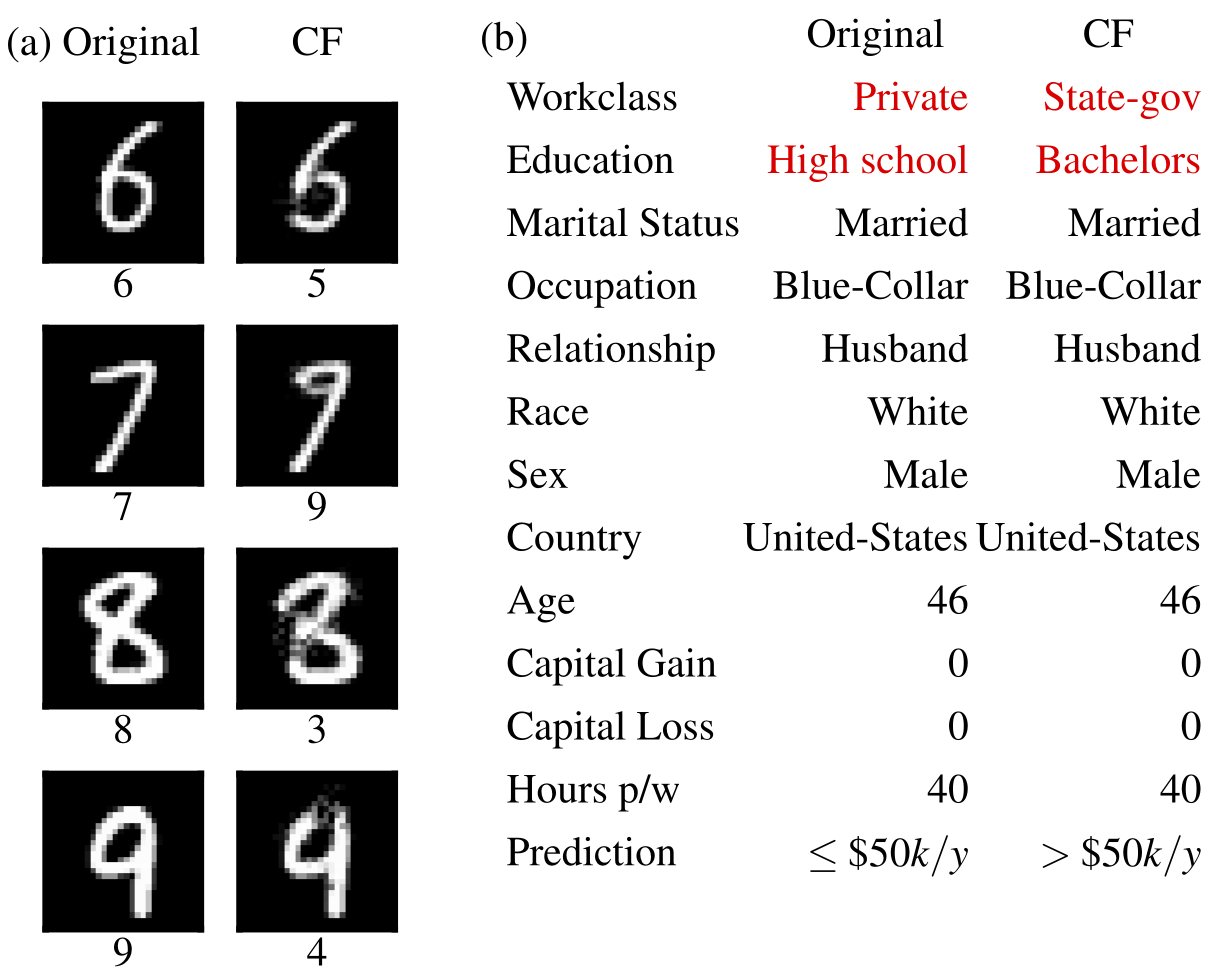
|
累积局部效应 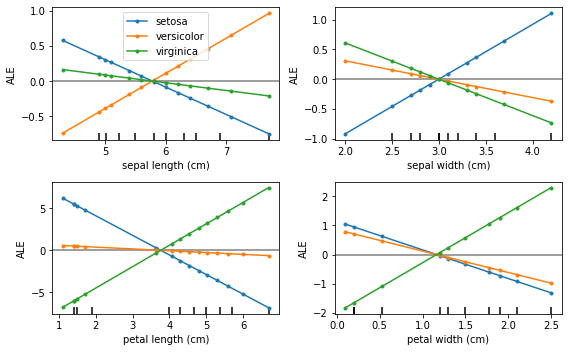
|
目录
安装与使用
Alibi 可以从以下位置安装:
- PyPI 或 GitHub 源码(使用
pip) - Anaconda(使用
conda/mamba)
使用 pip
Alibi 可以从 PyPI 安装:
pip install alibi或者,可以安装开发版本:
pip install git+https://github.com/SeldonIO/alibi.git为了利用解释的分布式计算,请使用
ray安装alibi:pip install alibi[ray]如需支持 SHAP,请按如下方式安装
alibi:pip install alibi[shap]
使用 conda
要从 conda-forge 安装,建议使用 mamba, 它可以安装在 base conda 环境中,命令如下:
conda install mamba -n base -c conda-forge
对于标准 Alibi 安装:
mamba install -c conda-forge alibi对于分布式计算支持:
mamba install -c conda-forge alibi ray对于 SHAP 支持:
mamba install -c conda-forge alibi shap
使用方式
Alibi 解释 API 借鉴了 scikit-learn(一个流行的机器学习库),包含独立的初始化、
拟合和解释步骤。我们将使用 AnchorTabular
解释器来说明该 API:
from alibi.explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular(predict_fn, feature_names=feature_names, category_map=category_map)
explainer.fit(X_train)
# explain an instance
explanation = explainer.explain(x)
返回的解释是一个 Explanation(解释对象),具有 meta 和 data 属性。meta 是一个包含解释器元数据和任何超参数的字典,data 是一个包含所有与计算出的解释相关内容的字典。例如,对于 Anchor 算法,可以通过 explanation.data['anchor'](或 explanation.anchor)访问解释。可用字段的详细信息因方法而异,因此我们鼓励读者熟悉
支持的方法类型。
支持的方法
下表总结了每种方法的潜在用例。
模型解释
| 方法 | 模型类型 | 解释类型 | 分类 | 回归 | 表格数据 | 文本 | 图像 | 类别特征 | 是否需要训练集 | 分布式 |
|---|---|---|---|---|---|---|---|---|---|---|
| ALE | BB | 全局 | ✔ | ✔ | ✔ | |||||
| 部分依赖 | BB WB | 全局 | ✔ | ✔ | ✔ | ✔ | ||||
| 部分依赖方差 | BB WB | 全局 | ✔ | ✔ | ✔ | ✔ | ||||
| 排列重要性 | BB | 全局 | ✔ | ✔ | ✔ | ✔ | ||||
| 锚点 | BB | 局部 | ✔ | ✔ | ✔ | ✔ | ✔ | 针对表格数据 | ||
| CEM | BB* TF/Keras | 局部 | ✔ | ✔ | ✔ | 可选 | ||||
| 反事实 | BB* TF/Keras | 局部 | ✔ | ✔ | ✔ | 否 | ||||
| 原型反事实 | BB* TF/Keras | 局部 | ✔ | ✔ | ✔ | ✔ | 可选 | |||
| 基于强化学习的反事实 | BB | 局部 | ✔ | ✔ | ✔ | ✔ | ✔ | |||
| 集成梯度 | TF/Keras | 局部 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 可选 | |
| Kernel SHAP | BB | 局部 全局 |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| Tree SHAP | WB | 局部 全局 |
✔ | ✔ | ✔ | ✔ | 可选 | |||
| 相似性解释 | WB | 局部 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
模型置信度
这些算法提供实例特定 (instance-specific) 的评分,用于衡量模型进行特定预测时的置信度。
| 方法 | 模型类型 | 分类 | 回归 | 表格数据 | 文本 | 图像 | 类别特征 | 是否需要训练集 |
|---|---|---|---|---|---|---|---|---|
| 信任分数 | BB | ✔ | ✔ | ✔(1) | ✔(2) | 是 | ||
| 线性度量 | BB | ✔ | ✔ | ✔ | ✔ | 可选 |
关键术语:
- BB - 黑盒 (Black-box)(仅需预测函数)
- BB* - 黑盒但假设模型是可微分的 (differentiable)
- WB - 需要白盒 (White-box) 模型访问权限。支持的模型可能存在限制
- TF/Keras - 通过 Keras API 的 TensorFlow 模型
- 局部 (Local) - 实例特定的解释,为何做出此预测?
- 全局 (Global) - 相对于一组实例解释模型
- (1) - 取决于模型
- (2) - 可能需要降维 (dimensionality reduction)
原型
这些算法提供数据集的提炼 (distilled) 视图,并帮助构建一个 1-KNN 可解释 (interpretable) 分类器。
| 方法 | 分类 | 回归 | 表格数据 | 文本 | 图像 | 类别特征 | 训练集标签 |
|---|---|---|---|---|---|---|---|
| 原型选择 | ✔ | ✔ | ✔ | ✔ | ✔ | 可选 |
引用与示例
累积局部效应 (ALE, Apley and Zhu, 2016)
部分依赖 (J.H. Friedman, 2001)
部分依赖方差 (Greenwell et al., 2018)
排列重要性 (Permutation Importance) (Breiman, 2001; Fisher et al., 2018)
锚点解释 (Anchor explanations) (Ribeiro et al., 2018)
对比解释方法 (CEM, Dhurandhar et al., 2018)
反事实解释 (Counterfactual Explanations) (扩展自 Wachter et al., 2017)
原型引导的反事实解释 (Counterfactual Explanations Guided by Prototypes) (Van Looveren and Klaise, 2019)
- 文档
- 示例: MNIST, 加州住房数据集, 成人收入 (one-hot), 成人收入 (ordinal)
基于强化学习 (RL) 的模型无关反事实解释 (Model-agnostic Counterfactual Explanations via RL) (Samoilescu et al., 2021)
集成梯度 (Integrated Gradients) (Sundararajan et al., 2017)
- 文档,
- 示例: MNIST 示例, Imagenet 示例, IMDB 示例.
核 SHAP 可加性解释 (Kernel Shapley Additive Explanations) (Lundberg et al., 2017)
- 文档
- 示例: 连续数据的 SVM, 连续数据的多项逻辑回归, 处理分类变量
树 SHAP 可加性解释 (Tree Shapley Additive Explanations) (Lundberg et al., 2020)
信任分数 (Trust Scores) (Jiang et al., 2018)
线性度量 (Linearity Measure)
- 文档
- 示例: Iris 数据集, Fashion MNIST
ProtoSelect
- 文档
- 示例: 成人人口普查 & CIFAR10
相似性解释 (Similarity explanations)
- 文档
- 示例: 20 个新闻组数据集, ImageNet 数据集, MNIST 数据集
引用
如果您在研究中使用 Alibi,请考虑引用它。
BibTeX 条目:
@article{JMLR:v22:21-0017,
author = {Janis Klaise and Arnaud Van Looveren and Giovanni Vacanti and Alexandru Coca},
title = {Alibi Explain: Algorithms for Explaining Machine Learning Models},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {181},
pages = {1-7},
url = {http://jmlr.org/papers/v22/21-0017.html}
}
版本历史
v0.9.32023/06/21v0.9.22023/04/28v0.9.12023/03/13v0.9.52024/01/22v0.9.42023/07/07v0.9.62024/04/18v0.9.02023/01/11v0.8.02022/09/26v0.7.02022/05/18v0.6.52022/03/18v0.6.42022/01/28v0.6.32022/01/18v0.6.22021/11/18v0.6.12021/09/02v0.6.02021/07/08v0.5.82021/04/29v0.5.72021/03/31v0.5.62021/02/18v0.5.52020/10/20v0.5.42020/09/03常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。