robustbench
RobustBench 是一个专注于对抗鲁棒性评估的标准化基准平台。面对海量宣称能抵御攻击的论文,其中不少存在鲁棒性被高估的问题,RobustBench 旨在通过统一标准追踪真实的性能进步。
它支持对 Linf、L2 范数扰动及常见图像损坏(Corruptions)进行评测。为确保结果可信,RobustBench 对入选防御方法设定了严格门槛:必须具有非零梯度、前向传播完全确定且不包含优化循环,以此剔除那些仅增加攻击成本却无实质提升的“伪防御”。同时,平台整合了 AutoAttack 并欢迎外部自适应攻击评估,防止模型针对特定攻击过拟合。
除了在线排行榜,RobustBench 还提供精选的高质量模型库(Model Zoo)。这非常适合从事机器学习安全研究的科研人员以及需要部署高鲁棒性模型的开发者。无论是验证新算法的有效性,还是寻找可靠的预训练权重,RobustBench 都能提供权威的参考依据。
使用场景
某金融科技公司的安全研发团队正在构建人脸识别支付系统,急需在上线前验证模型对对抗样本的防御能力。
没有 robustbench 时
- 学术界论文泛滥,难以辨别哪些防御方法真实有效,容易陷入虚假鲁棒的陷阱。
- 缺乏统一评估标准,不同团队报告的鲁棒率无法横向对比,选型决策困难。
- 手动复现攻击测试极其耗时,且旧版攻击器容易漏测,导致高估模型安全性。
- 模型资源分散,找不到经过社区验证的高质量预训练权重。
使用 robustbench 后
- 直接查阅官方 Leaderboard,快速获取经过严格去伪存真验证的顶尖鲁棒模型。
- 基于标准化的 Linf 和 L2 指标体系,清晰量化各方案的真实抗攻击水平。
- 利用内置 AutoAttack 及自适应攻击检测,杜绝过拟合问题,确保评估结果可信。
- 通过 Model Zoo 一键下载预训练权重,省去从零训练和清洗数据的漫长周期。
robustbench 通过标准化基准消除了评估噪音,帮助团队高效锁定真正安全的模型方案。
运行环境要求
- 未说明
支持 CUDA 加速,具体型号/显存/CUDA 版本未说明
未说明

快速开始
RobustBench:一个标准化的对抗鲁棒性基准
Francesco Croce (蒂宾根大学), Maksym Andriushchenko (洛桑联邦理工学院 EPFL), Vikash Sehwag* (普林斯顿大学), Edoardo Debenedetti* (洛桑联邦理工学院 EPFL), Nicolas Flammarion (洛桑联邦理工学院 EPFL), Mung Chiang (普渡大学), Prateek Mittal (普林斯顿大学), Matthias Hein (蒂宾根大学)**
排行榜: https://robustbench.github.io/
论文: https://arxiv.org/abs/2010.09670
❗注意❗:如果您在从 Google Drive 自动下载模型时遇到问题,请通过 pip install git+https://github.com/RobustBench/robustbench.git 安装最新版本的 RobustBench。
新闻
2022 年 5 月:我们已在 ImageNet 上扩展了常见损坏排行榜,新增了 3D Common Corruptions(ImageNet-3DCC)。ImageNet-3DCC 评估之所以有趣,是因为 (1) 它包含更真实的损坏类型,(2) 它可以用于评估现有模型的泛化能力,这些模型可能已经针对 ImageNet-C 过拟合。如需快速开始,请点击 这里。请注意,排行榜中的条目仍根据 ImageNet-C 的性能进行排序。
2022 年 5 月:我们修复了 ImageNet 损坏评估的预处理问题:此前我们使用调整为 256x256 并中心裁剪至 224x224,但这并非必要,因为 ImageNet-C 图像已经是 224x224(参见 此问题)。请注意,这改变了前 1 名和前 2 名条目之间的排名。
主要理念
RobustBench 的目标是系统地跟踪对抗鲁棒性 (adversarial robustness) 的真实进展。
目前已有 超过 3000 篇论文
涉及此主题,但仍经常不清楚哪些方法真正有效,而哪些仅导致 高估的鲁棒性。
我们从对 Linf、L2 和常见损坏 (common corruption) 鲁棒性的基准测试开始,因为这些是文献中最受研究的设置。
评估对 Lp 扰动的鲁棒性通常并不直接,需要自适应攻击 (adaptive attacks)(Tramer et al., (2020))。 因此,为了建立一个可靠的标准化基准,我们需要对我们考虑的防御措施施加一些限制。 特别是,我们只接受满足以下条件的防御措施:(1) 通常相对于输入具有非零梯度,(2) 具有完全确定的前向传播(即无随机性),且 (3) 不包含优化循环。 通常,违反这三项原则的防御措施仅使基于梯度的攻击 (gradient-based attacks) 变得更难,但并未实质性提高鲁棒性(Carlini et al., (2019)),除非那些能提供具体可证明保证的方法(例如 Cohen et al., (2019))。
为了防止新防御措施对 AutoAttack 产生潜在的过度适应,我们也欢迎基于自适应攻击 (adaptive attacks) 的外部评估,特别是在 AutoAttack 标记 鲁棒性可能被高估的情况下。对于每个模型,我们关注的是已知的最佳鲁棒准确率,并将 AutoAttack 和自适应攻击视为相互补充。
RobustBench 由两部分组成:
- 一个网站 https://robustbench.github.io/,其中包含基于许多近期论文的排行榜(下图 👇)
- 一组最鲁棒的模型集合,即 模型库 (Model Zoo),易于用于任何下游应用(见 FAQ 后的教程 👇)
常见问题
问: RobustBench 排行榜与 AutoAttack 排行榜 有何不同?🤔
答: AutoAttack 排行榜 是 RobustBench 的起点。现在只有 RobustBench 排行榜 处于活跃维护状态。
问: RobustBench 排行榜与 robust-ml.org 有何不同?🤔
答: robust-ml.org 专注于自适应评估,但我们提供的是标准化基准。自适应评估非常有用(例如,参见 Tramer 等人,2020),但它们也非常耗时,且从定义上讲并不标准化。相反,我们认为可以在很大程度上无需自适应攻击的情况下准确估计鲁棒性,但这需要对所考虑的模型引入一些限制。不过,我们欢迎自适应评估,并且始终有兴趣展示已知的最佳鲁棒准确率。
问: 它与 foolbox / cleverhans / advertorch 等库有什么关系?🤔
答: 这些库提供了不同攻击方法的实现。除了标准化基准外,RobustBench 还提供了一个最鲁棒模型的仓库。因此,你可以用一行代码开始使用这些鲁棒模型(见下方教程 👇)。
问: 为什么 Lp-鲁棒性仍然值得关注?🤔
答: Lp-鲁棒性有许多有趣的应用,涵盖迁移学习 (Salman 等人 (2020), Utrera 等人 (2020))、可解释性 (Tsipras 等人 (2018), Kaur 等人 (2019), Engstrom 等人 (2019))、安全性 (Tramèr 等人 (2018), Saadatpanah 等人 (2019))、泛化能力 (Xie 等人 (2019), Zhu 等人 (2019), Bochkovskiy 等人 (2020))、对未见扰动的鲁棒性 (Xie 等人 (2019), Kang 等人 (2019))、以及生成对抗网络 (GAN) 训练的稳定化 (Zhong 等人 (2020))。
问: 关于验证过的对抗鲁棒性呢?🤔
答: 鉴于尚不清楚哪些方法真正提高了鲁棒性,而哪些只是让某些特定攻击失效,我们主要关注提高经验鲁棒性的防御措施。然而,我们并不限制提交可验证鲁棒的模型(例如,我们的 CIFAR-10 Linf 排行榜中就有 Zhang 等人 (2019))。针对旨在实现验证鲁棒性的方法,我们鼓励读者查看 Salman 等人 (2019) 和 Li 等人 (2020)。
问: 如果我有一个比本基准使用的更好的攻击方法怎么办?🤔
答: 我们将很乐意添加更好的攻击方法或任何能补充我们默认标准化攻击的自适应评估。
模型库:快速浏览
我们的 模型库 的目标是尽可能简化鲁棒模型的使用。请查看我们的 Colab 笔记本 👉 RobustBench: 快速入门 以获取快速介绍。下面也进行了总结 👇。
首先,安装 RobustBench 的最新版本(推荐):
pip install git+https://github.com/RobustBench/robustbench.git
或者安装 RobustBench 的最新稳定版本(自动下载模型可能无法工作):
pip install git+https://github.com/RobustBench/robustbench.git@v1.0
现在让我们尝试加载 CIFAR-10 数据集以及来自 Carmon2019Unlabeled 的一些相当鲁棒的 CIFAR-10 模型,该模型在 eps=8/255 下使用 AutoAttack (AA) 评估达到了 59.53% 的鲁棒准确率:
from robustbench.data import load_cifar10
x_test, y_test = load_cifar10(n_examples=50)
from robustbench.utils import load_model
model = load_model(model_name='Carmon2019Unlabeled', dataset='cifar10', threat_model='Linf')
让我们尝试评估此模型的鲁棒性。我们可以使用任何喜欢的库来完成此操作。例如,FoolBox 实现了许多不同的攻击方法。我们可以从一个简单的 PGD 攻击开始:
!pip install -q foolbox
import foolbox as fb
fmodel = fb.PyTorchModel(model, bounds=(0, 1))
_, advs, success = fb.attacks.LinfPGD()(fmodel, x_test.to('cuda:0'), y_test.to('cuda:0'), epsilons=[8/255])
print('Robust accuracy: {:.1%}'.format(1 - success.float().mean()))
>>> Robust accuracy: 58.0%
太棒了!如果我们使用更准确的攻击方法,能否做得更好?
让我们尝试使用来自 ICML 2020 的廉价版 AutoAttack 来评估其鲁棒性,包含 2/4 种攻击(仅 APGD-CE 和 APGD-DLR):
# autoattack 是 robustbench 的依赖项,因此无需单独安装
from autoattack import AutoAttack
adversary = AutoAttack(model, norm='Linf', eps=8/255, version='custom', attacks_to_run=['apgd-ce', 'apgd-dlr'])
adversary.apgd.n_restarts = 1
x_adv = adversary.run_standard_evaluation(x_test, y_test)
>>> initial accuracy: 92.00%
>>> apgd-ce - 1/1 - 19 out of 46 successfully perturbed
>>> robust accuracy after APGD-CE: 54.00% (total time 10.3 s)
>>> apgd-dlr - 1/1 - 1 out of 27 successfully perturbed
>>> robust accuracy after APGD-DLR: 52.00% (total time 17.0 s)
>>> max Linf perturbation: 0.03137, nan in tensor: 0, max: 1.00000, min: 0.00000
>>> robust accuracy: 52.00%
请注意,对于我们的 Linf (L∞范数) 鲁棒性标准化评估,我们使用 AutoAttack (自动攻击) 的完整版本,它速度较慢但更准确(只需使用 adversary = AutoAttack(model, norm='Linf', eps=8/255) 即可)。
那其他类型的扰动呢?Lp 鲁棒性在那里有用吗?我们可以在更一般的扰动上评估可用模型。 例如,让我们选取来自 CIFAR-10-C 且受雾扰动影响、严重程度最高(5)的图像。 不同的 Linf 鲁棒模型在这些数据上表现会更好吗?
from robustbench.data import load_cifar10c
from robustbench.utils import clean_accuracy
corruptions = ['fog']
x_test, y_test = load_cifar10c(n_examples=1000, corruptions=corruptions, severity=5)
for model_name in ['Standard', 'Engstrom2019Robustness', 'Rice2020Overfitting',
'Carmon2019Unlabeled']:
model = load_model(model_name, dataset='cifar10', threat_model='Linf')
acc = clean_accuracy(model, x_test, y_test)
print(f'Model: {model_name}, CIFAR-10-C accuracy: {acc:.1%}')
>>> Model: Standard, CIFAR-10-C accuracy: 74.4%
>>> Model: Engstrom2019Robustness, CIFAR-10-C accuracy: 38.8%
>>> Model: Rice2020Overfitting, CIFAR-10-C accuracy: 22.0%
>>> Model: Carmon2019Unlabeled, CIFAR-10-C accuracy: 31.1%
正如我们所见,所有这些 Linf 鲁棒模型在此类扰动上的表现都明显差于标准模型。 这一奇怪的现象最早在 Adversarial Examples Are a Natural Consequence of Test Error in Noise 中被注意到,并在 A Fourier Perspective on Model Robustness in Computer Vision 中从频域角度得到了解释。
然而,平均而言,对抗训练确实有助于 CIFAR-10-C。可以通过 load_cifar10c(n_examples=1000, severity=5) 加载所有类型的扰动,并重复评估来轻松验证这一点。
*新*: 评估 ImageNet 模型针对 3D 常见扰动 (ImageNet-3DCC) 的鲁棒性
3D 常见扰动 (3DCC) 是 Kar 等人 (CVPR 2022) 最近提出的基准测试,利用场景几何生成逼真的扰动。您可以按照以下步骤评估标准 ResNet-50 针对 ImageNet-3DCC 的鲁棒性:
使用提供的工具从 此处 下载数据。数据将保存到名为
ImageNet-3DCC的文件夹中。运行示例评估脚本以获得准确率并将它们保存为 pickle 文件:
import torch
from robustbench.data import load_imagenet3dcc
from robustbench.utils import clean_accuracy, load_model
corruptions_3dcc = ['near_focus', 'far_focus', 'bit_error', 'color_quant',
'flash', 'fog_3d', 'h265_abr', 'h265_crf',
'iso_noise', 'low_light', 'xy_motion_blur', 'z_motion_blur'] # 12 corruptions in ImageNet-3DCC
device = torch.device("cuda:0")
model = load_model('Standard_R50', dataset='imagenet', threat_model='corruptions').to(device)
for corruption in corruptions_3dcc:
for s in [1, 2, 3, 4, 5]: # 5 severity levels
x_test, y_test = load_imagenet3dcc(n_examples=5000, corruptions=[corruption], severity=s, data_dir=$PATH_IMAGENET_3DCC)
acc = clean_accuracy(model, x_test.to(device), y_test.to(device), device=device)
print(f'Model: {model_name}, ImageNet-3DCC corruption: {corruption} severity: {s} accuracy: {acc:.1%}')
模型库 (Model Zoo)
为了使用一个模型,你只需要知道它的 ID,例如 Carmon2019Unlabeled,然后运行:
from robustbench import load_model
model = load_model(model_name='Carmon2019Unlabeled', dataset='cifar10', threat_model='Linf')
这将自动下载模型(所有模型均在 model_zoo/models.py 中定义)。
复现模型库中模型的评估可以直接从命令行完成。以下是使用 AutoAttack 在 ImageNet 上对 Salman2020Do_R18 模型进行评估的示例,eps=4/255=0.0156862745:
python -m robustbench.eval --n_ex=5000 --dataset=imagenet --threat_model=Linf --model_name=Salman2020Do_R18 --data_dir=/tmldata1/andriush/imagenet --batch_size=128 --eps=0.0156862745
CIFAR-10、CIFAR-10-C、CIFAR-100 和 CIFAR-100-C 数据集会自动下载。然而,由于许可原因,ImageNet 数据集应手动下载:
- ImageNet:从 此处 获取下载链接
(仅需使用学术邮箱注册,那里的审批系统是自动的且即时生效),然后遵循
此处 的说明,将验证集提取为 PyTorch 兼容格式并存入文件夹
val。 - ImageNet-C:请访问 此处 查看说明。
- ImageNet-3DCC:使用提供的工具从 此处 下载数据。数据将保存到名为
ImageNet-3DCC的文件夹中。
为了使用模型库中的模型,您可以在下面的表格中找到所有可用的模型 ID。请注意,完整的 排行榜 包含稍多一点的模型,这些模型我们要么尚未添加到模型库中,要么其作者不希望它们出现在模型库中。
CIFAR-10
Linf, eps=8/255
| # | 模型 ID | 论文 | 清洁准确率 | 鲁棒准确率 | 架构 | 发表场合 |
|---|---|---|---|---|---|---|
| 1 | Bartoldson2024Adversarial_WRN-94-16 | Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies | 93.68% | 73.71% | WideResNet-94-16 | ICML 2024 |
| 2 | Amini2024MeanSparse_S-WRN-94-16 | MeanSparse: Post-Training Robustness Enhancement Through Mean-Centered Feature Sparsification | 93.60% | 73.10% | MeanSparse WideResNet-94-16 | arXiv, Jun 2024 |
| 3 | Bartoldson2024Adversarial_WRN-82-8 | Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies | 93.11% | 71.59% | WideResNet-82-8 | ICML 2024 |
| 4 | Peng2023Robust | Robust Principles: Architectural Design Principles for Adversarially Robust CNNs | 93.27% | 71.07% | RaWideResNet-70-16 | BMVC 2023 |
| 5 | Wang2023Better_WRN-70-16 | Better Diffusion Models Further Improve Adversarial Training | 93.25% | 70.69% | WideResNet-70-16 | ICML 2023 |
| 6 | Bai2024MixedNUTS | MixedNUTS: Training-Free Accuracy-Robustness Balance via Nonlinearly Mixed Classifiers | 95.19% | 69.71% | ResNet-152 + WideResNet-70-16 | TMLR, Aug 2024 |
| 7 | Amini2024MeanSparse_Ra_WRN_70_16 | MeanSparse: Post-Training Robustness Enhancement Through Mean-Centered Feature Sparsification | 93.24% | 68.94% | MeanSparse RaWideResNet-70-16 | arXiv, Jun 2024 |
| 8 | Bai2023Improving_edm | Improving the Accuracy-Robustness Trade-off of Classifiers via Adaptive Smoothing | 95.23% | 68.06% | ResNet-152 + WideResNet-70-16 + mixing network | SIMODS 2024 |
| 9 | Cui2023Decoupled_WRN-28-10 | Decoupled Kullback-Leibler Divergence Loss | 92.16% | 67.73% | WideResNet-28-10 | NeurIPS 2024 |
| 10 | Wang2023Better_WRN-28-10 | Better Diffusion Models Further Improve Adversarial Training | 92.44% | 67.31% | WideResNet-28-10 | ICML 2023 |
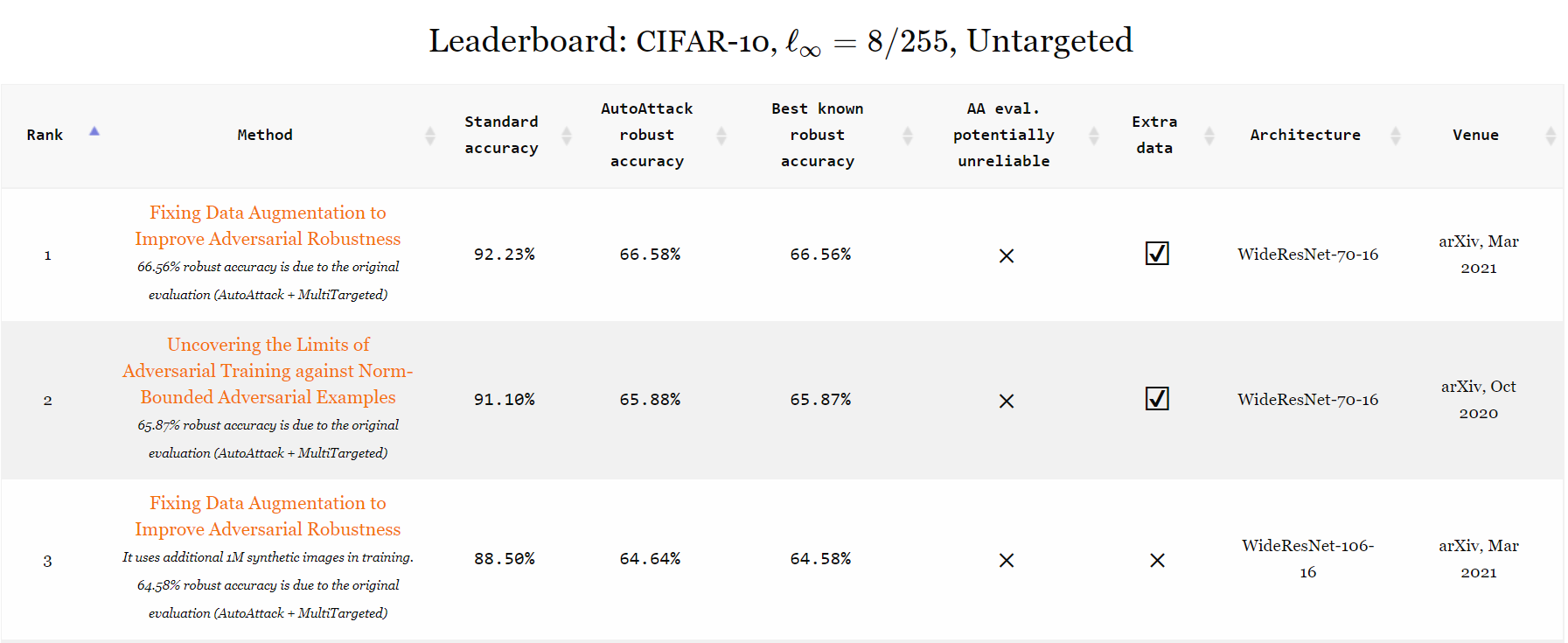
| 11 | Rebuffi2021Fixing_70_16_cutmix_extra | Fixing Data Augmentation to Improve Adversarial Robustness | 92.23% | 66.56% | WideResNet-70-16 | arXiv, Mar 2021 |
| 12 | Gowal2021Improving_70_16_ddpm_100m | Improving Robustness using Generated Data | 88.74% | 66.10% | WideResNet-70-16 | NeurIPS 2021 |
| 13 | Gowal2020Uncovering_70_16_extra | Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples | 91.10% | 65.87% | WideResNet-70-16 | arXiv, Oct 2020 |
| 14 | Huang2022Revisiting_WRN-A4 | Revisiting Residual Networks for Adversarial Robustness: An Architectural Perspective | 91.58% | 65.79% | WideResNet-A4 | arXiv, Dec. 2022 |
| 15 | Rebuffi2021Fixing_106_16_cutmix_ddpm | Fixing Data Augmentation to Improve Adversarial Robustness | 88.50% | 64.58% | WideResNet-106-16 | arXiv, Mar 2021 |
| 16 | Rebuffi2021Fixing_70_16_cutmix_ddpm | Fixing Data Augmentation to Improve Adversarial Robustness | 88.54% | 64.20% | WideResNet-70-16 | arXiv, Mar 2021 |
| 17 | Kang2021Stable | Stable Neural ODE with Lyapunov-Stable Equilibrium Points for Defending Against Adversarial Attacks | 93.73% | 64.20% | WideResNet-70-16, Neural ODE block | NeurIPS 2021 |
| 18 | Xu2023Exploring_WRN-28-10 | Exploring and Exploiting Decision Boundary Dynamics for Adversarial Robustness | 93.69% | 63.89% | WideResNet-28-10 | ICLR 2023 |
| 19 | Gowal2021Improving_28_10_ddpm_100m | Improving Robustness using Generated Data | 87.50% | 63.38% | WideResNet-28-10 | NeurIPS 2021 |
| 20 | Pang2022Robustness_WRN70_16 | Robustness and Accuracy Could Be Reconcilable by (Proper) Definition | 89.01% | 63.35% | WideResNet-70-16 | ICML 2022 |
| 21 | Rade2021Helper_extra | Helper-based Adversarial Training: Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off | 91.47% | 62.83% | WideResNet-34-10 | OpenReview, Jun 2021 |
| 22 | Sehwag2021Proxy_ResNest152 | Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness? | 87.30% | 62.79% | ResNest152 | ICLR 2022 |
| 23 | Gowal2020Uncovering_28_10_extra | Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples | 89.48% | 62.76% | WideResNet-28-10 | arXiv, Oct 2020 |
| 24 | Huang2021Exploring_ema | Exploring Architectural Ingredients of Adversarially Robust Deep Neural Networks | 91.23% | 62.54% | WideResNet-34-R | NeurIPS 2021 |
| 25 | Huang2021Exploring | Exploring Architectural Ingredients of Adversarially Robust Deep Neural Networks | 90.56% | 61.56% | WideResNet-34-R | NeurIPS 2021 |
| 26 | Dai2021Parameterizing | Parameterizing Activation Functions for Adversarial Robustness | 87.02% | 61.55% | WideResNet-28-10-PSSiLU | arXiv, Oct 2021 |
| 27 | Pang2022Robustness_WRN28_10 | Robustness and Accuracy Could Be Reconcilable by (Proper) Definition | 88.61% | 61.04% | WideResNet-28-10 | ICML 2022 |
| 28 | Rade2021Helper_ddpm | Helper-based Adversarial Training: Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off | 88.16% | 60.97% | WideResNet-28-10 | OpenReview, Jun 2021 |
| 29 | Rebuffi2021Fixing_28_10_cutmix_ddpm | Fixing Data Augmentation to Improve Adversarial Robustness | 87.33% | 60.73% | WideResNet-28-10 | arXiv, Mar 2021 |
| 30 | Sridhar2021Robust_34_15 | Improving Neural Network Robustness via Persistency of Excitation | 86.53% | 60.41% | WideResNet-34-15 | ACC 2022 |
| 31 | Sehwag2021Proxy | Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness? | 86.68% | 60.27% | WideResNet-34-10 | ICLR 2022 |
| 32 | Wu2020Adversarial_extra | Adversarial Weight Perturbation Helps Robust Generalization | 88.25% | 60.04% | WideResNet-28-10 | NeurIPS 2020 |
| 33 | Sridhar2021Robust | Improving Neural Network Robustness via Persistency of Excitation | 89.46% | 59.66% | WideResNet-28-10 | ACC 2022 |
| 34 | Zhang2020Geometry | Geometry-aware Instance-reweighted Adversarial Training | 89.36% | 59.64% | WideResNet-28-10 | ICLR 2021 |
| 35 | Carmon2019Unlabeled | Unlabeled Data Improves Adversarial Robustness | 89.69% | 59.53% | WideResNet-28-10 | NeurIPS 2019 |
| 36 | Gowal2021Improving_R18_ddpm_100m | Improving Robustness using Generated Data | 87.35% | 58.50% | PreActResNet-18 | NeurIPS 2021 |
| 37 | Chen2024Data_WRN_34_20 | Data filtering for efficient adversarial training | 86.10% | 58.09% | WideResNet-34-20 | Pattern Recognition 2024 |
| 38 | Addepalli2021Towards_WRN34 | Scaling Adversarial Training to Large Perturbation Bounds | 85.32% | 58.04% | WideResNet-34-10 | ECCV 2022 |
| 39 | Addepalli2022Efficient_WRN_34_10 | Efficient and Effective Augmentation Strategy for Adversarial Training | 88.71% | 57.81% | WideResNet-34-10 | NeurIPS 2022 |
| 40 | Chen2021LTD_WRN34_20 | LTD: Low Temperature Distillation for Robust Adversarial Training | 86.03% | 57.71% | WideResNet-34-20 | arXiv, Nov 2021 |
| 41 | Rade2021Helper_R18_extra | Helper-based Adversarial Training: Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off | 89.02% | 57.67% | PreActResNet-18 | OpenReview, Jun 2021 |
| 42 | Jia2022LAS-AT_70_16 | LAS-AT: Adversarial Training with Learnable Attack Strategy | 85.66% | 57.61% | WideResNet-70-16 | arXiv, Mar 2022 |
| 43 | Debenedetti2022Light_XCiT-L12 | A Light Recipe to Train Robust Vision Transformers | 91.73% | 57.58% | XCiT-L12 | arXiv, Sep 2022 |
| 44 | Chen2024Data_WRN_34_10 | Data filtering for efficient adversarial training | 86.54% | 57.30% | WideResNet-34-10 | Pattern Recognition 2024 |
| 45 | Debenedetti2022Light_XCiT-M12 | A Light Recipe to Train Robust Vision Transformers | 91.30% | 57.27% | XCiT-M12 | arXiv, Sep 2022 |
| 46 | Sehwag2020Hydra | HYDRA: Pruning Adversarially Robust Neural Networks | 88.98% | 57.14% | WideResNet-28-10 | NeurIPS 2020 |
| 47 | Gowal2020Uncovering_70_16 | Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples | 85.29% | 57.14% | WideResNet-70-16 | arXiv, Oct 2020 |
| 48 | Rade2021Helper_R18_ddpm | Helper-based Adversarial Training: Reducing Excessive Margin to Achieve a Better Accuracy vs. Robustness Trade-off | 86.86% | 57.09% | PreActResNet-18 | OpenReview, Jun 2021 |
| 49 | Cui2023Decoupled_WRN-34-10 | Decoupled Kullback-Leibler Divergence Loss | 85.31% | 57.09% | WideResNet-34-10 | NeurIPS 2024 |
| 50 | Chen2021LTD_WRN34_10 | LTD: Low Temperature Distillation for Robust Adversarial Training | 85.21% | 56.94% | WideResNet-34-10 | arXiv, Nov 2021 |
| 51 | Gowal2020Uncovering_34_20 | Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples | 85.64% | 56.82% | WideResNet-34-20 | arXiv, Oct 2020 |
| 52 | Rebuffi2021Fixing_R18_ddpm | Fixing Data Augmentation to Improve Adversarial Robustness | 83.53% | 56.66% | PreActResNet-18 | arXiv, Mar 2021 |
| 53 | Wang2020Improving | Improving Adversarial Robustness Requires Revisiting Misclassified Examples | 87.50% | 56.29% | WideResNet-28-10 | ICLR 2020 |
| 54 | Jia2022LAS-AT_34_10 | LAS-AT: Adversarial Training with Learnable Attack Strategy | 84.98% | 56.26% | WideResNet-34-10 | arXiv, Mar 2022 |
| 55 | Wu2020Adversarial | Adversarial Weight Perturbation Helps Robust Generalization | 85.36% | 56.17% | WideResNet-34-10 | NeurIPS 2020 |
| 56 | Debenedetti2022Light_XCiT-S12 | A Light Recipe to Train Robust Vision Transformers | 90.06% | 56.14% | XCiT-S12 | arXiv, Sep 2022 |
| 57 | Sehwag2021Proxy_R18 | Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness? | 84.59% | 55.54% | ResNet-18 | ICLR 2022 |
| 58 | Hendrycks2019Using | Using Pre-Training Can Improve Model Robustness and Uncertainty | 87.11% | 54.92% | WideResNet-28-10 | ICML 2019 |
| 59 | Pang2020Boosting | Boosting Adversarial Training with Hypersphere Embedding | 85.14% | 53.74% | WideResNet-34-20 | NeurIPS 2020 |
| 60 | Cui2020Learnable_34_20 | Learnable Boundary Guided Adversarial Training | 88.70% | 53.57% | < |
L2 范数,eps=0.5
| # | 模型 ID | 论文 | 干净准确率 | 鲁棒准确率 | 网络架构 | 发表场合 |
|---|---|---|---|---|---|---|
| 1 | Wang2023Better_WRN-70-16 | 更优的扩散模型进一步提升对抗训练效果 | 95.54% | 84.97% | WideResNet-70-16 | arXiv, 2023 年 2 月 |
| 2 | Amini2024MeanSparse_S-WRN-70-16 | MeanSparse:通过均值中心化特征稀疏化进行后训练鲁棒性增强 | 95.51% | 84.33% | MeanSparse WideResNet-70-16 | arXiv, 2024 年 6 月 |
| 3 | Wang2023Better_WRN-28-10 | 更优的扩散模型进一步提升对抗训练效果 | 95.16% | 83.68% | WideResNet-28-10 | ICML 2023 |
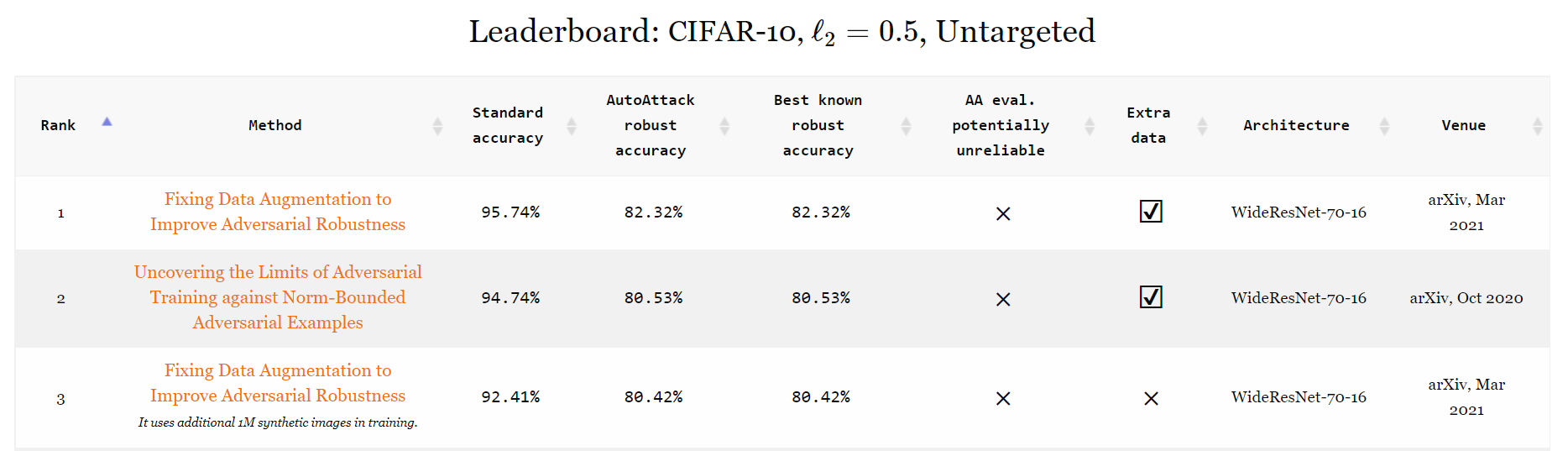
| 4 | Rebuffi2021Fixing_70_16_cutmix_extra | 修复数据增强以提升对抗鲁棒性 | 95.74% | 82.32% | WideResNet-70-16 | arXiv, 2021 年 3 月 |
| 5 | Gowal2020Uncovering_extra | 揭示针对范数有界对抗样本的对抗训练的极限 | 94.74% | 80.53% | WideResNet-70-16 | arXiv, 2020 年 10 月 |
| 6 | Rebuffi2021Fixing_70_16_cutmix_ddpm | 修复数据增强以提升对抗鲁棒性 | 92.41% | 80.42% | WideResNet-70-16 | arXiv, 2021 年 3 月 |
| 7 | Rebuffi2021Fixing_28_10_cutmix_ddpm | 修复数据增强以提升对抗鲁棒性 | 91.79% | 78.80% | WideResNet-28-10 | arXiv, 2021 年 3 月 |
| 8 | Augustin2020Adversarial_34_10_extra | 分布内和分布外的对抗鲁棒性提升可解释性 | 93.96% | 78.79% | WideResNet-34-10 | ECCV 2020 |
| 9 | Sehwag2021Proxy | 鲁棒学习遇见生成模型:代理分布能否提升对抗鲁棒性? | 90.93% | 77.24% | WideResNet-34-10 | ICLR 2022 |
| 10 | Augustin2020Adversarial_34_10 | 分布内和分布外的对抗鲁棒性提升可解释性 | 92.23% | 76.25% | WideResNet-34-10 | ECCV 2020 |
| 11 | Rade2021Helper_R18_ddpm | 基于辅助器的对抗训练:减少过大边距以实现更好的准确率与鲁棒性权衡 | 90.57% | 76.15% | PreActResNet-18 | OpenReview, 2021 年 6 月 |
| 12 | Rebuffi2021Fixing_R18_cutmix_ddpm | 修复数据增强以提升对抗鲁棒性 | 90.33% | 75.86% | PreActResNet-18 | arXiv, 2021 年 3 月 |
| 13 | Gowal2020Uncovering | 揭示针对范数有界对抗样本的对抗训练的极限 | 90.90% | 74.50% | WideResNet-70-16 | arXiv, 2020 年 10 月 |
| 14 | Sehwag2021Proxy_R18 | 鲁棒学习遇见生成模型:代理分布能否提升对抗鲁棒性? | 89.76% | 74.41% | ResNet-18 | ICLR 2022 |
| 15 | Wu2020Adversarial | 对抗权重扰动有助于鲁棒泛化 | 88.51% | 73.66% | WideResNet-34-10 | NeurIPS 2020 |
| 16 | Augustin2020Adversarial | 分布内和分布外的对抗鲁棒性提升可解释性 | 91.08% | 72.91% | ResNet-50 | ECCV 2020 |
| 17 | Engstrom2019Robustness | 鲁棒性库 | 90.83% | 69.24% | ResNet-50 | GitHub, 2019 年 9 月 |
| 18 | Rice2020Overfitting | 对抗鲁棒深度学习中的过拟合 | 88.67% | 67.68% | PreActResNet-18 | ICML 2020 |
| 19 | Rony2019Decoupling | 解耦方向与范数以实现高效的基于梯度的 L2 对抗攻击与防御 | 89.05% | 66.44% | WideResNet-28-10 | CVPR 2019 |
| 20 | Ding2020MMA | MMA 训练:通过对抗训练直接最大化输入空间边距 | 88.02% | 66.09% | WideResNet-28-4 | ICLR 2020 |
| 21 | Standard | 标准训练模型 | 94.78% | 0.00% | WideResNet-28-10 | 不适用 |
常见损坏 (Common Corruptions)
| 序号 | 模型 ID | 论文 | 清洁准确率 | 鲁棒准确率 | 架构 | 发表场合 |
|---|---|---|---|---|---|---|
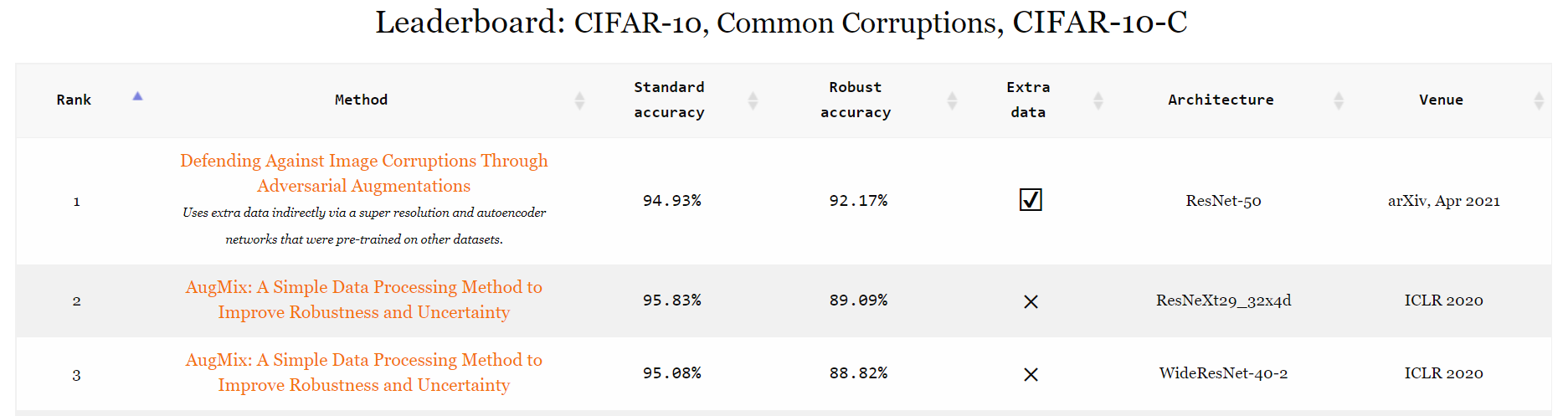
| 1 | Diffenderfer2021Winning_LRR_CARD_Deck | 一手好牌:压缩深度网络可提高分布外鲁棒性 | 96.56% | 92.78% | WideResNet-18-2 | NeurIPS 2021 |
| 2 | Diffenderfer2021Winning_LRR | 一手好牌:压缩深度网络可提高分布外鲁棒性 | 96.66% | 90.94% | WideResNet-18-2 | NeurIPS 2021 |
| 3 | Diffenderfer2021Winning_Binary_CARD_Deck | 一手好牌:压缩深度网络可提高分布外鲁棒性 | 95.09% | 90.15% | WideResNet-18-2 | NeurIPS 2021 |
| 4 | Kireev2021Effectiveness_RLATAugMix | 对抗训练对常见扰动的有效性研究 | 94.75% | 89.60% | ResNet-18 | arXiv, 2021 年 3 月 |
| 5 | Hendrycks2020AugMix_ResNeXt | AugMix:一种提高鲁棒性和不确定性的简单数据处理方法 | 95.83% | 89.09% | ResNeXt29_32x4d | ICLR 2020 |
| 6 | Modas2021PRIMEResNet18 | PRIME:少量原语即可提升对常见扰动的鲁棒性 | 93.06% | 89.05% | ResNet-18 | arXiv, 2021 年 12 月 |
| 7 | Hendrycks2020AugMix_WRN | AugMix:一种提高鲁棒性和不确定性的简单数据处理方法 | 95.08% | 88.82% | WideResNet-40-2 | ICLR 2020 |
| 8 | Kireev2021Effectiveness_RLATAugMixNoJSD | 对抗训练对常见扰动的有效性研究 | 94.77% | 88.53% | PreActResNet-18 | arXiv, 2021 年 3 月 |
| 9 | Diffenderfer2021Winning_Binary | 一手好牌:压缩深度网络可提高分布外鲁棒性 | 94.87% | 88.32% | WideResNet-18-2 | NeurIPS 2021 |
| 10 | Rebuffi2021Fixing_70_16_cutmix_extra_L2 | 修复数据增强以提升对抗鲁棒性 | 95.74% | 88.23% | WideResNet-70-16 | arXiv, 2021 年 3 月 |
| 11 | Kireev2021Effectiveness_AugMixNoJSD | 对抗训练对常见扰动的有效性研究 | 94.97% | 86.60% | PreActResNet-18 | arXiv, 2021 年 3 月 |
| 12 | Kireev2021Effectiveness_Gauss50percent | 对抗训练对常见扰动的有效性研究 | 93.24% | 85.04% | PreActResNet-18 | arXiv, 2021 年 3 月 |
| 13 | Kireev2021Effectiveness_RLAT | 对抗训练对常见扰动的有效性研究 | 93.10% | 84.10% | PreActResNet-18 | arXiv, 2021 年 3 月 |
| 14 | Rebuffi2021Fixing_70_16_cutmix_extra_Linf | 修复数据增强以提升对抗鲁棒性 | 92.23% | 82.82% | WideResNet-70-16 | arXiv, 2021 年 3 月 |
| 15 | Addepalli2022Efficient_WRN_34_10 | 用于对抗训练的高效且有效的增强策略 | 88.71% | 80.12% | WideResNet-34-10 | CVPRW 2022 |
| 16 | Addepalli2021Towards_WRN34 | 迈向超越感知极限的对抗鲁棒性 | 85.32% | 76.78% | WideResNet-34-10 | arXiv, 2021 年 4 月 |
| 17 | Standard | 标准训练模型 | 94.78% | 73.46% | WideResNet-28-10 | N/A |
CIFAR-100
Linf, eps=8/255
| # | 模型 ID | 论文 | 原始准确率 | 鲁棒准确率 | 架构 | 会议/期刊 |
|---|---|---|---|---|---|---|
| 1 | Wang2023Better_WRN-70-16 | 更好的扩散模型进一步提升对抗训练 | 75.22% | 42.66% | WideResNet-70-16 | ICML 2023 |
| 2 | Amini2024MeanSparse_S-WRN-70-16 | MeanSparse:通过均值中心化特征稀疏化实现后训练鲁棒性增强 | 75.13% | 42.25% | MeanSparse WideResNet-70-16 | arXiv, Jun 2024 |
| 3 | Bai2024MixedNUTS | MixedNUTS:通过非线性混合分类器实现无需训练的准确率 - 鲁棒性平衡 | 83.08% | 41.80% | ResNet-152 + WideResNet-70-16 | TMLR, Aug 2024 |
| 4 | Cui2023Decoupled_WRN-28-10 | 解耦的 KL 散度损失 | 73.85% | 39.18% | WideResNet-28-10 | NeurIPS 2024 |
| 5 | Wang2023Better_WRN-28-10 | 更好的扩散模型进一步提升对抗训练 | 72.58% | 38.77% | WideResNet-28-10 | ICML 2023 |
| 6 | Bai2023Improving_edm | 通过自适应平滑改进分类器的准确率 - 鲁棒性权衡 | 85.21% | 38.72% | ResNet-152 + WideResNet-70-16 + mixing network | SIMODS 2024 |
| 7 | Gowal2020Uncovering_extra | 揭示对抗训练在范数有界对抗样本上的极限 | 69.15% | 36.88% | WideResNet-70-16 | arXiv, Oct 2020 |
| 8 | Bai2023Improving_trades | 通过自适应平滑改进分类器的准确率 - 鲁棒性权衡 | 80.18% | 35.15% | ResNet-152 + WideResNet-70-16 + mixing network | SIMODS 2024 |
| 9 | Debenedetti2022Light_XCiT-L12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 70.76% | 35.08% | XCiT-L12 | arXiv, Sep 2022 |
| 10 | Rebuffi2021Fixing_70_16_cutmix_ddpm | 修正数据增强以提升对抗鲁棒性 | 63.56% | 34.64% | WideResNet-70-16 | arXiv, Mar 2021 |
| 11 | Debenedetti2022Light_XCiT-M12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 69.21% | 34.21% | XCiT-M12 | arXiv, Sep 2022 |
| 12 | Pang2022Robustness_WRN70_16 | 鲁棒性和准确率可以通过(适当)定义达成和解 | 65.56% | 33.05% | WideResNet-70-16 | ICML 2022 |
| 13 | Cui2023Decoupled_WRN-34-10_autoaug | 解耦的 KL 散度损失 | 65.93% | 32.52% | WideResNet-34-10 | NeurIPS 2024 |
| 14 | Debenedetti2022Light_XCiT-S12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 67.34% | 32.19% | XCiT-S12 | arXiv, Sep 2022 |
| 15 | Rebuffi2021Fixing_28_10_cutmix_ddpm | 修正数据增强以提升对抗鲁棒性 | 62.41% | 32.06% | WideResNet-28-10 | arXiv, Mar 2021 |
| 16 | Jia2022LAS-AT_34_20 | LAS-AT:具有可学习攻击策略的对抗训练 | 67.31% | 31.91% | WideResNet-34-20 | arXiv, Mar 2022 |
| 17 | Cui2023Decoupled_WRN-34-10 | 解耦的 KL 散度损失 | 65.76% | 31.91% | WideResNet-34-10 | NeurIPS 2024 |
| 18 | Addepalli2022Efficient_WRN_34_10 | 用于对抗训练的高效有效增强策略 | 68.75% | 31.85% | WideResNet-34-10 | NeurIPS 2022 |
| 19 | Cui2020Learnable_34_10_LBGAT9_eps_8_255 | 可学习的边界引导对抗训练 | 62.99% | 31.20% | WideResNet-34-10 | ICCV 2021 |
| 20 | Sehwag2021Proxy | 鲁棒学习与生成模型相遇:代理分布能否提升对抗鲁棒性? | 65.93% | 31.15% | WideResNet-34-10 | ICLR 2022 |
| 21 | Chen2024Data_WRN_34_10 | 用于高效对抗训练的数据过滤 | 64.32% | 31.13% | WideResNet-34-10 | Pattern Recognition 2024 |
| 22 | Pang2022Robustness_WRN28_10 | 鲁棒性和准确率可以通过(适当)定义达成和解 | 63.66% | 31.08% | WideResNet-28-10 | ICML 2022 |
| 23 | Jia2022LAS-AT_34_10 | LAS-AT:具有可学习攻击策略的对抗训练 | 64.89% | 30.77% | WideResNet-34-10 | arXiv, Mar 2022 |
| 24 | Chen2021LTD_WRN34_10 | LTD:用于鲁棒对抗训练的低温度蒸馏 | 64.07% | 30.59% | WideResNet-34-10 | arXiv, Nov 2021 |
| 25 | Addepalli2021Towards_WRN34 | 将对抗训练扩展至大扰动边界 | 65.73% | 30.35% | WideResNet-34-10 | ECCV 2022 |
| 26 | Cui2020Learnable_34_20_LBGAT6 | 可学习的边界引导对抗训练 | 62.55% | 30.20% | WideResNet-34-20 | ICCV 2021 |
| 27 | Gowal2020Uncovering | 揭示对抗训练在范数有界对抗样本上的极限 | 60.86% | 30.03% | WideResNet-70-16 | arXiv, Oct 2020 |
| 28 | Cui2020Learnable_34_10_LBGAT6 | 可学习的边界引导对抗训练 | 60.64% | 29.33% | WideResNet-34-10 | ICCV 2021 |
| 29 | Rade2021Helper_R18_ddpm | 基于辅助模型的对抗训练:减少过大边距以实现更好的准确率与鲁棒性权衡 | 61.50% | 28.88% | PreActResNet-18 | OpenReview, Jun 2021 |
| 30 | Wu2020Adversarial | 对抗权重扰动有助于鲁棒泛化 | 60.38% | 28.86% | WideResNet-34-10 | NeurIPS 2020 |
| 31 | Rebuffi2021Fixing_R18_ddpm | 修正数据增强以提升对抗鲁棒性 | 56.87% | 28.50% | PreActResNet-18 | arXiv, Mar 2021 |
| 32 | Hendrycks2019Using | 使用预训练可以提升模型鲁棒性和不确定性 | 59.23% | 28.42% | WideResNet-28-10 | ICML 2019 |
| 33 | Addepalli2022Efficient_RN18 | 用于对抗训练的高效有效增强策略 | 65.45% | 27.67% | ResNet-18 | NeurIPS 2022 |
| 34 | Cui2020Learnable_34_10_LBGAT0 | 可学习的边界引导对抗训练 | 70.25% | 27.16% | WideResNet-34-10 | ICCV 2021 |
| 35 | Addepalli2021Towards_PARN18 | 将对抗训练扩展至大扰动边界 | 62.02% | 27.14% | PreActResNet-18 | ECCV 2022 |
| 36 | Chen2020Efficient | 通过反向平滑实现高效鲁棒训练 | 62.15% | 26.94% | WideResNet-34-10 | arXiv, Oct 2020 |
| 37 | Sitawarin2020Improving | 通过渐进式硬化提升对抗鲁棒性 | 62.82% | 24.57% | WideResNet-34-10 | arXiv, Mar 2020 |
| 38 | Rice2020Overfitting | 对抗鲁棒深度学习中过拟合现象 | 53.83% | 18.95% | PreActResNet-18 | ICML 2020 |
损坏
| # | 模型 ID | 论文 | 清洁准确率 | 鲁棒准确率 | 架构 | 会议/来源 |
|---|---|---|---|---|---|---|
| 1 | Diffenderfer2021Winning_LRR_CARD_Deck | 一手好牌:压缩深度网络可以提升分布外鲁棒性 | 79.93% | 71.08% | WideResNet-18-2 | NeurIPS 2021 |
| 2 | Diffenderfer2021Winning_Binary_CARD_Deck | 一手好牌:压缩深度网络可以提升分布外鲁棒性 | 78.50% | 69.09% | WideResNet-18-2 | NeurIPS 2021 |
| 3 | Modas2021PRIMEResNet18 | PRIME:少量原语可以提升对常见损坏的鲁棒性 | 77.60% | 68.28% | ResNet-18 | arXiv, Dec 2021 |
| 4 | Diffenderfer2021Winning_LRR | 一手好牌:压缩深度网络可以提升分布外鲁棒性 | 78.41% | 66.45% | WideResNet-18-2 | NeurIPS 2021 |
| 5 | Diffenderfer2021Winning_Binary | 一手好牌:压缩深度网络可以提升分布外鲁棒性 | 77.69% | 65.26% | WideResNet-18-2 | NeurIPS 2021 |
| 6 | Hendrycks2020AugMix_ResNeXt | AugMix:一种提升鲁棒性和不确定性的简单数据处理方法 | 78.90% | 65.14% | ResNeXt29_32x4d | ICLR 2020 |
| 7 | Hendrycks2020AugMix_WRN | AugMix:一种提升鲁棒性和不确定性的简单数据处理方法 | 76.28% | 64.11% | WideResNet-40-2 | ICLR 2020 |
| 8 | Addepalli2022Efficient_WRN_34_10 | 对抗训练的高效有效增强策略 | 68.75% | 56.95% | WideResNet-34-10 | CVPRW 2022 |
| 9 | Gowal2020Uncovering_extra_Linf | 揭示针对范数有界对抗样本的对抗训练的极限 | 69.15% | 56.00% | WideResNet-70-16 | arXiv, Oct 2020 |
| 10 | Addepalli2021Towards_WRN34 | 迈向超越感知限制的对抗鲁棒性 | 65.73% | 54.88% | WideResNet-34-10 | OpenReview, Jun 2021 |
| 11 | Addepalli2021Towards_PARN18 | 迈向超越感知限制的对抗鲁棒性 | 62.02% | 51.77% | PreActResNet-18 | OpenReview, Jun 2021 |
| 12 | Gowal2020Uncovering_Linf | 揭示针对范数有界对抗样本的对抗训练的极限 | 60.86% | 49.46% | WideResNet-70-16 | arXiv, Oct 2020 |
ImageNet
注意: 数值(即使是清洁准确率)可能会因包版本(例如 torchvision)的不同而有微小波动。
Linf, eps=4/255
| # | 模型 ID | 论文 | 清洁准确率 | 鲁棒准确率 | 架构 | 发表来源 |
|---|---|---|---|---|---|---|
| 1 | Xu2024MIMIR_Swin-L | MIMIR:基于互信息的对抗鲁棒性掩码图像建模 | 78.62% | 59.68% | Swin-L | arXiv, 2023 年 12 月 |
| 2 | Liu2023Comprehensive_Swin-L | 图像分类模型鲁棒性的全面研究:基准测试与再思考 | 78.92% | 59.56% | Swin-L | arXiv, 2023 年 2 月 |
| 3 | Amini2024MeanSparse_Swin-L | MeanSparse:通过均值中心化特征稀疏化进行后训练鲁棒性增强 | 78.80% | 58.92% | MeanSparse Swin-L | arXiv, 2024 年 6 月 |
| 4 | Bai2024MixedNUTS | MixedNUTS:通过非线性混合分类器实现无需训练的准确率 - 鲁棒性平衡 | 81.48% | 58.50% | ConvNeXtV2-L + Swin-L | TMLR, 2024 年 8 月 |
| 5 | Liu2023Comprehensive_ConvNeXt-L | 图像分类模型鲁棒性的全面研究:基准测试与再思考 | 78.02% | 58.48% | ConvNeXt-L | arXiv, 2023 年 2 月 |
| 6 | Amini2024MeanSparse_ConvNeXt-L | MeanSparse:通过均值中心化特征稀疏化进行后训练鲁棒性增强 | 77.92% | 58.22% | MeanSparse ConvNeXt-L | arXiv, 2024 年 6 月 |
| 7 | Singh2023Revisiting_ConvNeXt-L-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 77.00% | 57.70% | ConvNeXt-L + ConvStem | NeurIPS 2023 |
| 8 | Liu2023Comprehensive_Swin-B | 图像分类模型鲁棒性的全面研究:基准测试与再思考 | 76.16% | 56.16% | Swin-B | arXiv, 2023 年 2 月 |
| 9 | Singh2023Revisiting_ConvNeXt-B-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 75.90% | 56.14% | ConvNeXt-B + ConvStem | NeurIPS 2023 |
| 10 | Xu2024MIMIR_Swin-B | MIMIR:基于互信息的对抗鲁棒性掩码图像建模 | 76.62% | 55.90% | Swin-B | arXiv, 2023 年 12 月 |
| 11 | Liu2023Comprehensive_ConvNeXt-B | 图像分类模型鲁棒性的全面研究:基准测试与再思考 | 76.02% | 55.82% | ConvNeXt-B | arXiv, 2023 年 2 月 |
| 12 | Singh2023Revisiting_ViT-B-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 76.30% | 54.66% | ViT-B + ConvStem | NeurIPS 2023 |
| 13 | RodriguezMunoz2024Characterizing_Swin-L | 通过自然输入梯度表征模型鲁棒性 | 79.36% | 53.82% | Swin-L | arXiv, 2024 年 9 月 |
| 14 | Singh2023Revisiting_ConvNeXt-S-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 74.10% | 52.42% | ConvNeXt-S + ConvStem | NeurIPS 2023 |
| 15 | RodriguezMunoz2024Characterizing_Swin-B | 通过自然输入梯度表征模型鲁棒性 | 77.76% | 51.56% | Swin-B | arXiv, 2024 年 9 月 |
| 16 | Singh2023Revisiting_ConvNeXt-T-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 72.72% | 49.46% | ConvNeXt-T + ConvStem | NeurIPS 2023 |
| 17 | Peng2023Robust | 鲁棒原则:面向对抗鲁棒 CNN 的架构设计原则 | 73.44% | 48.94% | RaWideResNet-101-2 | BMVC 2023 |
| 18 | Singh2023Revisiting_ViT-S-ConvStem | 重新审视 ImageNet 的对抗训练:跨威胁模型的架构、训练与泛化 | 72.56% | 48.08% | ViT-S + ConvStem | NeurIPS 2023 |
| 19 | Debenedetti2022Light_XCiT-L12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 73.76% | 47.60% | XCiT-L12 | arXiv, 2022 年 9 月 |
| 20 | Debenedetti2022Light_XCiT-M12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 74.04% | 45.24% | XCiT-M12 | arXiv, 2022 年 9 月 |
| 21 | Debenedetti2022Light_XCiT-S12 | 训练鲁棒视觉 Transformer 的轻量级配方 | 72.34% | 41.78% | XCiT-S12 | arXiv, 2022 年 9 月 |
| 22 | Chen2024Data_WRN_50_2 | 用于高效对抗训练的数据过滤 | 68.76% | 40.60% | WideResNet-50-2 | Pattern Recognition 2024 |
| 23 | Mo2022When_Swin-B | 当对抗训练遇见视觉 Transformer:从训练到架构的配方 | 74.66% | 38.30% | Swin-B | NeurIPS 2022 |
| 24 | Salman2020Do_50_2 | 对抗鲁棒的 ImageNet 模型迁移效果更好吗? | 68.46% | 38.14% | WideResNet-50-2 | NeurIPS 2020 |
| 25 | Salman2020Do_R50 | 对抗鲁棒的 ImageNet 模型迁移效果更好吗? | 64.02% | 34.96% | ResNet-50 | NeurIPS 2020 |
| 26 | Mo2022When_ViT-B | 当对抗训练遇见视觉 Transformer:从训练到架构的配方 | 68.38% | 34.40% | ViT-B | NeurIPS 2022 |
| 27 | Engstrom2019Robustness | 鲁棒性库 | 62.56% | 29.22% | ResNet-50 | GitHub, 2019 年 10 月 |
| 28 | Wong2020Fast | 快比免费好:重新审视对抗训练 | 55.62% | 26.24% | ResNet-50 | ICLR 2020 |
| 29 | Salman2020Do_R18 | 对抗鲁棒的 ImageNet 模型迁移效果更好吗? | 52.92% | 25.32% | ResNet-18 | NeurIPS 2020 |
| 30 | Standard_R50 | 标准训练模型 | 76.52% | 0.00% | ResNet-50 | 无 |
损坏(ImageNet-C & ImageNet-3DCC)
| # | 模型 ID | 论文 | 干净准确率 | 鲁棒准确率 | 架构 | 发表场合 |
|---|---|---|---|---|---|---|
| 1 | Tian2022Deeper_DeiT-B | 深入理解视觉 Transformer (ViTs) 对常见损坏的鲁棒性 | 81.38% | 67.55% | DeiT Base | arXiv, Apr 2022 |
| 2 | Tian2022Deeper_DeiT-S | 深入理解视觉 Transformer (ViTs) 对常见损坏的鲁棒性 | 79.76% | 62.91% | DeiT Small | arXiv, Apr 2022 |
| 3 | Erichson2022NoisyMix_new | NoisyMix:通过结合数据增强、稳定性训练和噪声注入来提升鲁棒性 | 76.90% | 53.28% | ResNet-50 | arXiv, Feb 2022 |
| 4 | Hendrycks2020Many | 鲁棒性的多面性:对分布外泛化的批判性分析 | 76.86% | 52.90% | ResNet-50 | ICCV 2021 |
| 5 | Erichson2022NoisyMix | NoisyMix:通过结合数据增强、稳定性训练和噪声注入来提升鲁棒性 | 76.98% | 52.47% | ResNet-50 | arXiv, Feb 2022 |
| 6 | Hendrycks2020AugMix | AugMix:一种提高鲁棒性和不确定性的简单数据处理方法 | 77.34% | 49.33% | ResNet-50 | ICLR 2020 |
| 7 | Geirhos2018_SIN_IN | 在 ImageNet 上训练的卷积神经网络 (CNNs) 倾向于纹理;增加形状偏差可提高准确性和鲁棒性 | 74.98% | 45.76% | ResNet-50 | ICLR 2019 |
| 8 | Geirhos2018_SIN_IN_IN | 在 ImageNet 上训练的卷积神经网络 (CNNs) 倾向于纹理;增加形状偏差可提高准确性和鲁棒性 | 77.56% | 42.00% | ResNet-50 | ICLR 2019 |
| 9 | Geirhos2018_SIN | 在 ImageNet 上训练的卷积神经网络 (CNNs) 倾向于纹理;增加形状偏差可提高准确性和鲁棒性 | 60.08% | 39.92% | ResNet-50 | ICLR 2019 |
| 10 | Standard_R50 | 标准训练的模型 | 76.72% | 39.48% | ResNet-50 | N/A |
| 11 | Salman2020Do_50_2_Linf | 对抗鲁棒的 ImageNet 模型是否迁移得更好? | 68.64% | 36.09% | WideResNet-50-2 | NeurIPS 2020 |
| 12 | AlexNet | 使用深度卷积神经网络 (CNNs) 进行 ImageNet 分类 | 56.24% | 21.12% | AlexNet | NeurIPS 2012 |
笔记本
我们在 Google Colab 上托管了所有笔记本:
- RobustBench: 快速开始:
一个快速入门教程,展示了
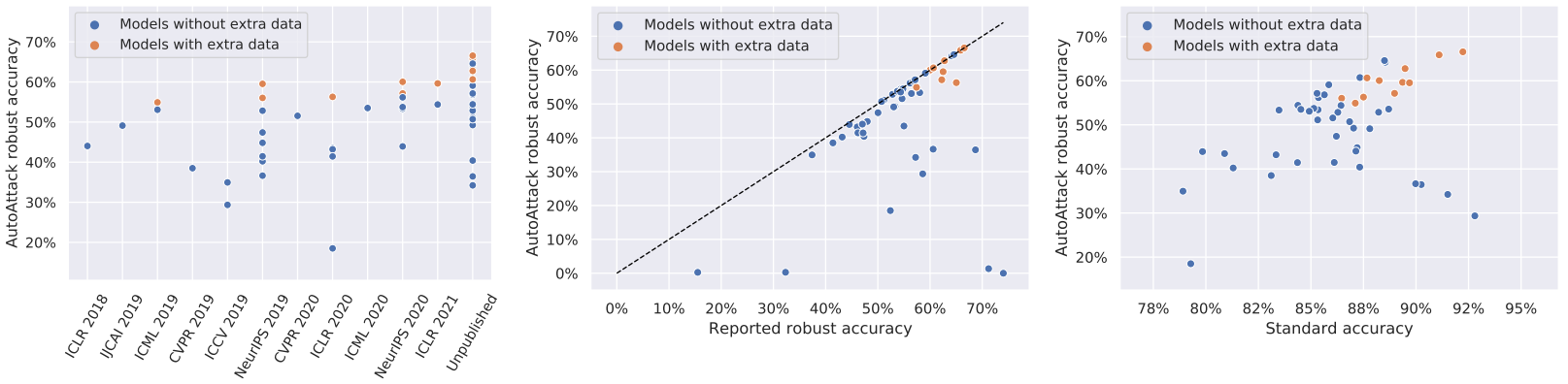
RobustBench的主要功能。 - RobustBench: JSON 统计信息:
基于
model_info中的 JSON 的各种图表(不同发表场合的鲁棒性、鲁棒性与准确率对比等)。
欢迎基于 模型库 或 model_info 中的 JSON 建议新的笔记本。我们非常感兴趣收集关于不同扰动类型之间的好处和权衡的新见解。
如何贡献
非常欢迎对 RobustBench 做出贡献!你可以帮助改进 RobustBench:
- 你是最近一篇关注提高对抗鲁棒性的论文的作者吗?考虑添加新模型(见下方说明 👇)。
- 你是否想到了一些更好的标准化攻击?你想将
RobustBench扩展到其他威胁模型吗?我们将很乐意讨论这一点! - 你有想法如何让现有的代码库更好吗?只需打开一个拉取请求 (pull request) 或创建一个问题 (issue),我们将很乐意讨论潜在的更改。
添加新评估
如果您有一些新的(可能是自适应的)评估方法,其导致的鲁棒准确率低于 AutoAttack,我们将很乐意将其添加到排行榜中。 最简单的方法是使用“新外部评估”模板打开一个问题并填写所有字段。
添加新模型
公开模型提交(排行榜 + 模型库)
向排行榜和/或模型库添加新模型最简单的方法是使用“新模型”模板打开一个 issue并填写所有字段。
在以下部分中,有一些关于如何准备性能声明的建议。
性能声明
性能声明可以通过以下方式计算(以 cifar10 和 Linf 威胁模型为例):
import torch
from robustbench import benchmark
from myrobust model import MyRobustModel
threat_model = "Linf" # one of {"Linf", "L2", "corruptions"}
dataset = "cifar10" # one of {"cifar10", "cifar100", "imagenet"}
model = MyRobustModel()
model_name = "<Name><Year><FirstWordOfTheTitle>"
device = torch.device("cuda:0")
clean_acc, robust_acc = benchmark(model, model_name=model_name, n_examples=10000, dataset=dataset,
threat_model=threat_model, eps=8/255, device=device,
to_disk=True)
特别是,如果 to_disk 参数为 True,则会在路径 model_info/<dataset>/<threat_model>/<Name><Year><FirstWordOfTheTitle>.json 生成一个 json 文件,其结构如下(示例来自 model_info/cifar10/Linf/Rice2020Overfitting.json):
{
"link": "https://arxiv.org/abs/2002.11569",
"name": "Overfitting in adversarially robust deep learning",
"authors": "Leslie Rice, Eric Wong, J. Zico Kolter",
"additional_data": false,
"number_forward_passes": 1,
"dataset": "cifar10",
"venue": "ICML 2020",
"architecture": "WideResNet-34-20",
"eps": "8/255",
"clean_acc": "85.34",
"reported": "58",
"autoattack_acc": "53.42"
}
唯一的区别是生成的 json 将仅包含已指定的字段 "clean_acc" 和 "autoattack_acc"(针对 "Linf" 和 "L2" 威胁模型)或 "corruptions_acc"(针对 "corruptions" 威胁模型)。其他字段需要手动填写。
如果给定的 threat_model 是 corruptions,我们还会将不同类型和严重程度的组合的非聚合结果保存在 此 csv 文件 中(适用于 CIFAR-10)。
对于 ImageNet 基准测试,用户应指定使用的预处理方法(例如调整大小并裁剪到所需分辨率)。robustbench.data.PREPROCESSINGS 中已经定义了一些预处理方法,可以通过将键指定为 benchmark 的 preprocessing 参数来使用。否则,可以传递任意的 torchvision transform(或兼容 torchvision 的 transform),例如:
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
clean_acc, robust_acc = benchmark(model, model_name=model_name, n_examples=10000, dataset=dataset,
threat_model=threat_model, eps=8/255, device=device,
to_disk=True, preprocessing=transform)
模型定义
如果您想自行向模型库添加模型,您还应该为您想要添加的新模型打开一个 PR(拉取请求)。每个 <dataset> 的所有模型都保存在 robustbench/model_zoo/<dataset>.py 中。每个文件包含每个威胁模型的字典,其中键是每个模型的标识符,值要么是类构造函数(用于需要更改标准架构的模型),要么是返回构造模型的 lambda 函数。
如果您的模型是标准架构(例如 WideResNet),不对输入应用任何归一化,也不需要与标准架构有所不同,请考虑将您的模型作为 lambda 函数添加,例如:
('Cui2020Learnable_34_10', {
'model': lambda: WideResNet(depth=34, widen_factor=10, sub_block1=True),
'gdrive_id': '16s9pi_1QgMbFLISVvaVUiNfCzah6g2YV'
})
如果您的模型是标准架构,但您需要做一些不同的事情(例如应用归一化),请考虑继承 wide_resnet.py 或 resnet.py 中定义的类。例如:
class Rice2020OverfittingNet(WideResNet):
def __init__(self, depth, widen_factor):
super(Rice2020OverfittingNet, self).__init__(depth=depth, widen_factor=widen_factor,
sub_block1=False)
self.mu = torch.Tensor([0.4914, 0.4822, 0.4465]).float().view(3, 1, 1).cuda()
self.sigma = torch.Tensor([0.2471, 0.2435, 0.2616]).float().view(3, 1, 1).cuda()
def forward(self, x):
x = (x - self.mu) / self.sigma
return super(Rice2020OverfittingNet, self).forward(x)
相反,如果您需要创建一个新的架构,请将其放在 robustbench/model_zoo/archietectures/<my_architecture>.py 中。
模型检查点
您还应该在文件 robustbench/model_zoo/<dataset>.py 中的相应 <threat_model> 字典中添加您的模型条目。例如,假设您的模型对 CIFAR-10 中的常见损坏具有鲁棒性(即 CIFAR-10-C),那么您应该将您的模型添加到 robustbench/model_zoo/cifar10.py 中的 common_corruptions 字典中。
模型还应包含带有您的 PyTorch 模型的 Google Drive ID,以便可以从 Google Drive 自动下载:
('Rice2020Overfitting', {
'model': Rice2020OverfittingNet(34, 20),
'gdrive_id': '1vC_Twazji7lBjeMQvAD9uEQxi9Nx2oG-',
})
私有模型提交(仅限排行榜)
如果您出于某些原因希望保持检查点私有,您也可以通过使用相同的“新模型”模板打开一个 issue 来提交您的声明,指定提交是私有的,并通过电子邮件地址 adversarial.benchmark@gmail.com 共享检查点。在这种情况下,我们将把您的模型添加到排行榜中,但不添加到模型库中,并且不会公开共享您的检查点。
模型许可证
默认情况下,模型是根据 MIT 许可证发布的,但如果您希望根据自定义许可证发布模型,也可以告诉我们。
自动测试
为了运行测试,请运行:
python -m unittest discover tests -t . -v用于快速测试RUN_SLOW=true python -m unittest discover tests -t . -v用于较慢的测试
例如,可以测试 200 个样本上的干净准确率是否超过某个阈值(70%),或者每个模型在 10'000 个样本上的干净准确率是否与位于 robustbench/model_info 的 json 文件中的匹配。
请注意,可以在 tests/config.py 中指定一些配置,如 batch_size、data_dir、model_dir,以运行测试。
引用
如果您希望引用 RobustBench 排行榜,或者正在使用来自 模型库 (Model Zoo) 的模型?
那么请考虑引用我们的 白皮书:
@inproceedings{croce2021robustbench,
title = {RobustBench: a standardized adversarial robustness benchmark},
author = {Croce, Francesco and Andriushchenko, Maksym and Sehwag, Vikash and Debenedetti, Edoardo and Flammarion, Nicolas and Chiang, Mung and Mittal, Prateek and Matthias Hein},
booktitle = {Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year = {2021},
url = {https://openreview.net/forum?id=SSKZPJCt7B}
}
联系方式
如有任何关于 RobustBench 的问题,欢迎通过创建 issue (问题)、pull request (拉取请求) 或发送邮件至 adversarial.benchmark@gmail.com 与我们联系。
版本历史
v1.1.1-test2023/04/09v1.12022/09/28v1.02021/11/29v0.2.12021/05/07v0.22021/05/05v0.12021/03/11常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。