picolm
picolm 是一款专为极低配置硬件设计的本地大语言模型推理引擎。它的核心能力在于让一个 10 亿参数的模型在仅 256MB 内存、售价约 10 美元的微型开发板上流畅运行。
许多用户受困于云端 API 的费用、隐私风险以及对网络的依赖,而本地部署又往往需要昂贵的显卡。picolm 完美解决了这些问题,实现了真正的离线 AI 体验。无需互联网连接,没有月度账单,所有数据都保留在设备本地。
技术上,picolm 采用纯 C 语言编写,没有任何外部依赖,生成的二进制文件仅有 80KB 左右,运行时内存占用低至 45MB。它支持标准输入输出,能轻松集成到各种脚本或应用中,比如与 PicoClaw 配合构建全功能的离线智能体。
嵌入式系统开发者、物联网爱好者,以及那些对数据隐私有严格要求的研究人员都能从中受益。如果你想在树莓派或更廉价的芯片上体验大模型的魅力,picolm 是绝佳的选择。
使用场景
一位物联网工程师在信号覆盖极差的矿区部署智能监测终端,需要设备能独立处理异常报警数据而不依赖外部网络。
没有 picolm 时
- 必须依赖云端 API 接口,一旦断网整个系统就瘫痪失效,无法响应现场指令。
- 长期运行需持续支付 Token 费用,运维成本随数据量线性增长,预算难以控制。
- 原始传感器数据需上传至第三方服务器,存在隐私泄露隐患,不符合合规要求。
- 传统大模型需要高性能 GPU 支持,普通嵌入式板卡无法承载,导致硬件选型受限。
使用 picolm 后
- 直接编译为单一二进制文件,在 $10 开发板上即可离线运行,彻底摆脱网络依赖。
- 硬件一次性投入,后续推理零成本,彻底消除月度账单,大幅降低总拥有成本。
- 所有数据处理均在本地完成,确保敏感信息绝不流出设备,满足严格的数据安全标准。
- 仅需 45MB 内存占用,完美适配 256MB RAM 的资源受限环境,让低端硬件也能跑大模型。
picolm 通过极致轻量化架构,让低成本硬件也能拥有安全可靠的本地智能决策能力。
运行环境要求
- Linux
- Windows
- macOS
无需 GPU (仅 CPU)
运行时约 45MB,建议硬件至少 256MB

快速开始
PicoLM
在拥有 256MB RAM 的 10 美元开发板上运行 10 亿参数的大语言模型 (LLM)。
纯 C 语言。零依赖。单个二进制文件。无需 Python。无需云端。
echo "Explain gravity" | ./picolm model.gguf -n 100 -j 4
完美搭档:PicoLM + PicoClaw

PicoLM 是 PicoClaw 的本地大脑——一个运行在 10 美元硬件上的超轻量级 Go 语言 AI 助手。两者结合形成一个完全离线的 AI 智能体——无需云端,无需 API 密钥,无需互联网,无需月费。
其他所有 LLM 提供商都需要互联网。PicoLM 不需要。
| 硬件 | 架构 |
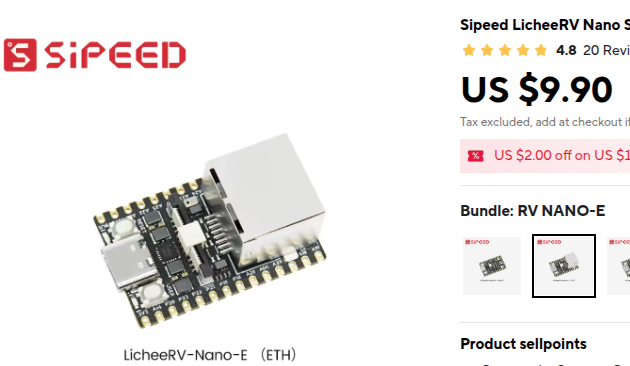 |
 |
| 9.90 美元——这就是整个服务器 | PicoLM 为 PicoClaw 智能体循环中的 LLM 模块提供动力 |
为什么它们是完美契合
| 云提供商 (OpenAI 等) | PicoLM (本地) | |
|---|---|---|
| 成本 | 按令牌付费,永久付费 | 永久免费 |
| 隐私 | 数据发送至服务器 | 所有数据保留在设备端 |
| 互联网 | 每次请求都需要 | 完全不需要 |
| 延迟 | 网络往返 + 推理 | 仅推理 |
| 硬件 | 需要价值 599 美元的 Mac Mini | 运行在 10 美元的开发板上 |
| 二进制文件 | N/A | ~80KB 单文件 |
| 内存 | N/A | 总计 45 MB |
工作原理
PicoClaw 的智能体循环将 PicoLM 作为子进程启动。消息来自 Telegram、Discord 或命令行界面(CLI)——PicoClaw 将其格式化为聊天模板,通过标准输入(stdin)将提示词管道传输给 picolm,并从标准输出(stdout)读取响应。当需要工具时,--json 语法模式可确保即使是从 1B 模型也能生成有效的 JSON。
Telegram / Discord / CLI
│
▼
┌──────────┐ stdin: prompt ┌───────────┐
│ PicoClaw │ ──────────────────► │ picolm │
│ (Go) │ ◄────────────────── │ (C) │
└──────────┘ stdout: response │ + model │
│ └───────────┘
▼ 45 MB RAM
User gets reply No internet
快速设置
# 1. Build PicoLM
cd picolm && make native # or: make pi (Raspberry Pi)
# 2. Download model (one-time, 638 MB)
make model
# 3. Build PicoClaw
cd ../picoclaw && make deps && make build
# 4. Configure (~/.picoclaw/config.json)
{
"agents": {
"defaults": {
"provider": "picolm",
"model": "picolm-local"
}
},
"providers": {
"picolm": {
"binary": "~/.picolm/bin/picolm",
"model": "~/.picolm/models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf",
"max_tokens": 256,
"threads": 4,
"template": "chatml"
}
}
}
# 5. Chat — fully offline!
picoclaw agent -m "What is photosynthesis?"
或者一键安装所有内容
curl -sSL https://raw.githubusercontent.com/RightNow-AI/picolm/main/install.sh | bash
真实硬件性能表现
| 设备 | 价格 | 生成速度 | 占用内存 |
|---|---|---|---|
| Pi 5 (4 核) | 60 美元 | ~10 词元/秒 | 45 MB |
| Pi 4 (4 核) | 35 美元 | ~8 词元/秒 | 45 MB |
| Pi 3B+ | 25 美元 | ~4 词元/秒 | 45 MB |
| Pi Zero 2W | 15 美元 | ~2 词元/秒 | 45 MB |
| LicheeRV Nano | 10 美元 | ~1 词元/秒 | 45 MB |
JSON 工具调用
当需要结构化输出时,PicoClaw 会自动激活 --json 语法模式。这保证了即使是从 10 亿参数模型生成的 JSON 也是语法有效的——对于在微型硬件上可靠地进行工具调用至关重要:
picoclaw agent -m "Search for weather in Tokyo"
# → PicoLM generates: {"tool_calls": [{"function": {"name": "web_search", "arguments": "{\"query\": \"weather Tokyo\"}"}}]}
如需完整的 PicoClaw 文档,请参阅 PicoClaw README。
PicoLM 是什么?
PicoLM 是一个用约 2,500 行 C11 代码编写的极简从头构建的 LLM 推理引擎。它能在大多数推理框架甚至不会考虑运行的硬件上运行 TinyLlama 1.1B(以及以 GGUF 格式的其他 LLaMA 架构模型):
- Raspberry Pi Zero 2W(15 美元,512MB RAM,ARM Cortex-A53)
- Sipeed LicheeRV(12 美元,512MB RAM,RISC-V)
- Raspberry Pi 3/4/5(1-8GB RAM,ARM NEON SIMD)
- 任何 Linux/Windows/macOS x86-64 机器
模型文件(638MB)保留在磁盘上。PicoLM 对其使用内存映射(memory-mapping),并通过 RAM 逐层流式传输。总运行时内存:约 45MB,包括 FP16 KV 缓存。
┌──────────────────────────────────────────┐
What goes │ 45 MB Runtime RAM │
in RAM │ ┌─────────┐ ┌──────────┐ ┌───────────┐ │
│ │ Buffers │ │ FP16 KV │ │ Tokenizer │ │
│ │ 1.2 MB │ │ Cache │ │ 4.5 MB │ │
│ │ │ │ ~40 MB │ │ │ │
│ └─────────┘ └──────────┘ └───────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
What stays │ 638 MB Model on Disk │
on disk │ (mmap — OS pages in layers │
(via mmap) │ as needed, ~1 at a time) │
└──────────────────────────────────────────┘
功能特性
| 功能 | 描述 |
|---|---|
| GGUF Native | 直接读取 GGUF v2/v3 文件 — 无需转换 |
| K-Quant 支持 | Q2_K, Q3_K, Q4_K, Q5_K, Q6_K, Q8_0, Q4_0, F16, F32 |
| mmap 层流式加载 | 模型权重保留在磁盘上;OS 逐页加载一层 (mmap 内存映射) |
| FP16 KV 缓存 | 减少一半 KV 缓存 (Key-Value Cache) 内存 (2048 上下文下 44MB vs 88MB) |
| Flash Attention | 在线 Softmax — 无需 O(seq_len) Attention (注意力机制) 缓冲区 |
| 预计算 RoPE | cos/sin 查找表消除热点循环中的超越函数 (RoPE 旋转位置编码) |
| SIMD 加速 | ARM NEON (Pi 3/4/5) 和 x86 SSE2 (Intel/AMD) 自动检测 (SIMD 单指令多数据流) |
| 融合点积 | 反量化 + 点积一次完成 — 无中间缓冲区 |
| 多线程矩阵乘法 | 跨 CPU 核心并行矩阵向量乘法 |
| 语法约束 JSON | --json 标志强制输出有效 JSON(用于工具调用) |
| KV 缓存持久化 | --cache 保存/加载提示状态 — 重新运行时跳过预填充 (Prefill) |
| BPE 分词器 | 基于分数的字节对编码 (BPE),从 GGUF 元数据加载 |
| Top-p 采样 | 温度 + 核采样,可配置种子 |
| 管道友好 | 从 stdin 读取提示:echo "Hello" | ./picolm model.gguf |
| 零依赖 | 仅 libc, libm, libpthread。无外部库。 |
| 跨平台 | Linux, Windows (MSVC), macOS。ARM, x86-64, RISC-V。 |
快速开始
一键安装 (树莓派 / Linux)
curl -sSL https://raw.githubusercontent.com/RightNow-AI/picolm/main/install.sh | bash
这将执行以下操作:
- 检测你的平台 (ARM64, ARMv7, x86-64)
- 安装构建依赖项 (
gcc,make,curl) - 使用针对你 CPU 优化的 SIMD 标志构建 PicoLM
- 下载 TinyLlama 1.1B Q4_K_M (638 MB)
- 运行快速测试
- 生成 PicoClaw 配置
- 将
picolm添加到你的 PATH
从源码构建
git clone https://github.com/rightnow-ai/picolm.git
cd picolm/picolm
# 自动检测 CPU (在 x86 上启用 SSE2/AVX,在 ARM 上启用 NEON)
make native
# 下载模型
make model
# 运行它
./picolm /opt/picolm/models/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf \
-p "The meaning of life is" -n 100
Windows 构建 (MSVC)
cd picolm
build.bat
picolm.exe model.gguf -p "Hello world" -n 50
特定平台构建
make native # x86/ARM 自动检测 (推荐用于本地机器)
make pi # Raspberry Pi 3/4/5 (64 位 ARM + NEON SIMD)
make pi-arm32 # Pi Zero / Pi 1 (32 位 ARM)
make cross-pi # 从 x86 交叉编译给 Pi (静态二进制)
make riscv # RISC-V (Sipeed LicheeRV 等)
make static # 用于单文件部署的静态二进制
make debug # 带符号、无优化的调试构建
使用方法
PicoLM — 超轻量级大语言模型推理引擎
用法:picolm <model.gguf> [选项]
生成选项:
-p <prompt> 输入提示 (或通过 stdin 管道输入)
-n <int> 最大生成词元数 (默认:256)
-t <float> 温度 (默认:0.8, 0=贪婪)
-k <float> Top-p / 核采样 (默认:0.9)
-s <int> RNG 种子 (默认:42)
-c <int> 上下文长度覆盖
-j <int> 线程数 (默认:4)
高级选项:
--json 语法约束 JSON 输出模式
--cache <file> KV 缓存文件 (保存/加载提示状态)
示例
基本生成:
./picolm model.gguf -p "Once upon a time" -n 200
贪婪解码(确定性,temperature=0):
./picolm model.gguf -p "The capital of France is" -n 20 -t 0
# 输出:Paris. It is the largest city in France and...
与 TinyLlama 聊天 (ChatML 格式):
./picolm model.gguf -n 200 -t 0.7 -p "<|user|>
What is photosynthesis?</s>
<|assistant|>
"
强制 JSON 输出(用于工具调用/结构化数据):
./picolm model.gguf --json -t 0.3 -n 100 -p "<|user|>
Return the current time as JSON.</s>
<|assistant|>
"
# 输出:{"time": "12:00 PM"}
从 stdin 管道输入:
echo "Explain quantum computing in one sentence" | ./picolm model.gguf -n 50
KV 缓存 — 跳过重复预填充:
# 第一次运行:处理提示 + 保存缓存
./picolm model.gguf --cache prompt.kvc -p "Long system prompt here..." -n 50
# 第二次运行:加载缓存,跳过提示预填充 (快 74%)
./picolm model.gguf --cache prompt.kvc -p "Long system prompt here..." -n 50
# 输出:"Skipping 25 cached prompt tokens"
Pi 4 多线程(4 核):
./picolm model.gguf -p "Hello" -n 100 -j 4
性能
基于 TinyLlama 1.1B Q4_K_M(638 MB 模型)测量:
| 指标 | x86-64 (8 线程) | Pi 4 (4 核,NEON) | Pi Zero 2W |
|---|---|---|---|
| 预填充 | ~11 tok/s | ~6 tok/s | ~1.5 tok/s |
| 生成 | ~13 tok/s | ~8 tok/s* | ~2 tok/s* |
| 运行时内存 | 45 MB | 45 MB | 45 MB |
| 首词时间 | ~2.3s | ~4s | ~16s |
| 二进制大小 | ~80 KB | ~70 KB | ~65 KB |
*估计启用 NEON SIMD。实际数字取决于 SD 卡速度和热节流。
为何如此快速
原始 C 推理 ████████████░░░░░░░░ 13.5 tok/s (基准:1.6)
+ 融合点积 ████████████████░░░░ (消除反量化缓冲区)
+ 多线程矩阵乘法 █████████████████░░░ (4-8 核并行)
+ FP16 KV 缓存 █████████████████░░░ (减半内存带宽)
+ 预计算 RoPE ██████████████████░░ (热点循环中无 sin/cos)
+ Flash Attention ██████████████████░░ (无 O(n) 注意力分配)
+ NEON/SSE2 SIMD ███████████████████░ (4 宽向量运算)
+ KV 缓存持久化 ████████████████████ (完全跳过预填充)
架构
┌─────────────────────────────────┐
│ picolm.c │
│ CLI + Generation Loop │
└──────┬──────────────┬───────────┘
│ │
┌────────────┘ └────────────┐
│ │
┌────────┴────────┐ ┌──────────┴──────────┐
│ model.h/c │ │ sampler.h/c │
│ GGUF Parser │ │ Temperature + │
│ mmap Layer │ │ Top-p Sampling │
│ Streaming │ └──────────┬──────────┘
│ Forward Pass │ │
│ KV Cache I/O │ ┌──────────┴──────────┐
└───┬────────┬────┘ │ grammar.h/c │
│ │ │ JSON Constraint │
┌────────┘ └───────┐ │ Logit Masking │
│ │ └─────────────────────┘
┌─────┴──────┐ ┌───────┴────────┐
│ tensor.h/c │ │ tokenizer.h/c │
│ matmul │ │ BPE Encode │
│ rmsnorm │ │ Decode │
│ softmax │ │ Vocab Lookup │
│ rope │ └────────────────┘
│ silu │
│ threading │
└─────┬──────┘
│
┌─────┴──────┐
│ quant.h/c │
│ Q4_K, Q6_K │
│ Q3_K, Q2_K │
│ FP16, F32 │
│ NEON + SSE │
│ Fused Dots │
└────────────┘
LLaMA 前向传播(每个 Token 发生了什么)
Input Token
│
▼
┌───────────────┐
│ Embedding │ Dequantize row from token_embd → x[2048]
│ Lookup │
└───────┬───────┘
│
▼
┌───────────────┐ ×22 layers
│ RMSNorm │─────────────────────────────────────────┐
│ │ │
│ Q = xb @ Wq │ Matrix-vector multiply (quantized) │
│ K = xb @ Wk │ Store K,V in FP16 KV cache │
│ V = xb @ Wv │ │
│ │ │
│ RoPE(Q, K) │ Rotary position encoding (table lookup)│
│ │ │
│ Attention │ Flash attention with online softmax │
│ (GQA 32→4) │ Grouped-query: 32 Q heads, 4 KV heads │
│ │ │
│ x += Out@Wo │ Output projection + residual │
│ │ │
│ RMSNorm │ │
│ │ │
│ SwiGLU FFN │ gate=SiLU(xb@Wg), up=xb@Wu │
│ │ x += (gate*up) @ Wd │
└───────┬───────┘─────────────────────────────────────────┘
│
▼
┌───────────────┐
│ Final RMSNorm │
│ x @ W_output │─→ logits[32000]
└───────┬───────┘
│
▼
┌───────────────┐
│ Grammar Mask │ (if --json: force valid JSON structure)
│ Sample Token │ temperature → softmax → top-p → pick
└───────────────┘
内存预算
对于上下文长度为 2048 的 TinyLlama 1.1B Q4_K_M:
| 组件 | 大小 | 备注 |
|---|---|---|
| FP16 KV Cache (键值缓存) | ~40 MB | 22 层 x 2 x 2048 x 256 x 2 字节 |
| 分词器 | ~4.5 MB | 32K 词表字符串 + 分数 + 排序索引 |
| 激活缓冲 | ~0.14 MB | x, xb, xb2, q, hb, hb2 |
| Logits 缓冲 | ~0.12 MB | 32000 x 4 字节 |
| 反量化临时区 | ~0.02 MB | Max(n_embd, n_ffn) 浮点数 |
| 归一化权重(反量化前) | ~0.35 MB | 45 个归一化向量 x 2048 x 4 字节 |
| RoPE 表 | ~0.03 MB | cos + sin x 2048 x 32 项 |
| 总运行时 | ~45 MB | |
| 模型文件(磁盘上) | 638 MB | 内存映射,每次约 1 层在 RAM 中 |
使用 512 上下文(针对受限设备):
| 组件 | 大小 |
|---|---|
| FP16 KV Cache (键值缓存) | ~10 MB |
| 其他所有内容 | ~5 MB |
| 总计 | ~15 MB |
优化深度解析
PicoLM 实现了 9 项优化,将 x86 上的生成速度从 1.6 tok/s 提升至 13.5 tok/s,预计基于 ARM 和 NEON 的增益更大:
1. ARM NEON SIMD (单指令多数据流)
所有热点路径均采用 4 宽浮点向量操作。示例:使用 vmovl_u8 → vmovl_u16 → vcvtq_f32_u32 对 Q4_K 半字节进行反量化,以及使用交错的 vld2q_f32 / vst2q_f32 处理 RoPE。
2. x86 SSE2 SIMD
在 Intel/AMD 上自动检测。用于点积、RMSNorm 和向量操作的 4 宽 __m128 操作。
3. FP16 KV Cache (键值缓存)
键值向量以 16 位浮点数而非 32 位存储。KV 缓存内存减少一半,从 ~88MB 降至 ~44MB。转换使用软件 fp32_to_fp16() / fp16_to_fp32() —— 无需硬件 FP16 支持。
4. 预计算 RoPE 表
所有位置的正弦和余弦值在模型加载时计算一次。前向传播执行表查找,而不是每个 token 调用 64 次 sinf() / cosf() / powf()。
5. Flash Attention (在线 Softmax)
单次通过注意力机制,带有运行最大值重缩放。消除了 O(seq_len) 注意力分数缓冲区 —— 对于内存受限设备上的长上下文至关重要。
6. 融合反量化 + 点积
vec_dot_q4_K_f32() 在一个传递中完成反量化和累加。权重行没有中间浮点缓冲区。将矩阵乘法的内存流量减少约 50%。
7. 多线程矩阵乘法
matmul() 使用 pthreads 将输出行分发到各个线程。每个线程独立处理其块并使用融合点积。可扩展至约 8 个核心。
8. 语法约束 JSON
--json 模式在加载时预先分析词表中的每个 token(大括号差值、方括号差值、引号配对)。生成期间,它屏蔽 logits 以确保语法有效的 JSON —— 对于小模型的函数调用至关重要。
9. KV 缓存持久化
--cache file.kvc 在提示词处理后保存 FP16 KV 缓存状态。下次使用相同提示词运行时,它加载缓存并完全跳过预填充。重复系统提示可降低 74% 延迟。
支持的模型
PicoLM 支持任何 GGUF 格式的 LLaMA 架构模型:
| 模型 | 参数量 | GGUF 大小 (Q4_K_M) | 所需 RAM |
|---|---|---|---|
| TinyLlama 1.1B | 1.1B | 638 MB | ~45 MB |
| Llama 2 7B | 7B | 4.1 GB | ~200 MB |
| Phi-2 | 2.7B | 1.6 GB | ~90 MB |
嵌入式推荐: TinyLlama 1.1B Q4_K_M —— 可舒适地运行在 256MB+ RAM 的设备上。
支持的量化格式
Q2_K Q3_K Q4_K Q4_0 Q5_K Q6_K Q8_0 F16 F32
文件结构
PicoLM/
├── README.md ← you are here
├── BLOG.md ← technical deep-dive blog post
├── install.sh ← one-liner Pi installer
│
├── picolm/ ← the inference engine (pure C)
│ ├── picolm.c ← CLI entry point, generation loop (273 lines)
│ ├── model.h/c ← GGUF parser, mmap, forward pass (146 + 833 lines)
│ ├── tensor.h/c ← matmul, rmsnorm, softmax, rope (44 + 298 lines)
│ ├── quant.h/c ← dequantization, SIMD kernels (140 + 534 lines)
│ ├── tokenizer.h/c ← BPE tokenizer (32 + ~200 lines)
│ ├── sampler.h/c ← temperature + top-p sampling (19 + ~100 lines)
│ ├── grammar.h/c ← JSON grammar constraints (64 + 175 lines)
│ ├── Makefile ← build targets for all platforms
│ └── build.bat ← Windows MSVC build script
│
└── tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf ← model file (638 MB, not in git)
**总计 C 源代码:约 2,500 行。**这就是整个推理引擎——包括 GGUF 解析、内存映射(mmap)、反量化、矩阵运算、注意力机制、分词、采样和语法约束。
工作原理
mmap 技巧
传统的推理引擎将整个模型加载到 RAM(随机存取存储器)中。PicoLM 则不然。相反:
- 模型文件被内存映射(Linux/macOS 上使用
mmap,Windows 上使用MapViewOfFile) - 权重指针直接指向映射的文件——无需复制
- 在**前向传播(forward pass)**期间,每一层的权重按顺序访问
- 操作系统会自动将需要的权重调入页面并淘汰旧的
madvise(MADV_SEQUENTIAL)向内核提示访问模式
结果: 638MB 的模型可以在拥有 256MB RAM 的设备上运行。任何时刻只有约 30MB 的模型数据在物理内存中。
量化
权重以 4 位量化格式存储(Q4_K_M)。对于 TinyLlama:
- 原始大小: 11 亿参数 x 4 字节 = 4.4 GB
- Q4_K: 11 亿参数 x ~0.56 字节 = 638 MB
- 质量损失: 极小——Q4_K 每 32 个权重的子块保留 6 位缩放比例
分组查询注意力 (GQA)
TinyLlama 使用 32 个查询头,但只有 4 个键/值头。每个 KV 头由 8 个查询头共享。与完整的**多头注意力(multi-head attention)机制相比,这使KV 缓存(KV cache)**大小减少了 8 倍。
构建与测试
前置条件
| 平台 | 要求 |
|---|---|
| Linux/Pi | gcc, make(通过 apt install build-essential 安装) |
| macOS | Xcode 命令行工具(xcode-select --install) |
| Windows | Visual Studio 构建工具(cl.exe) |
验证构建
# Build
make native
# Test with greedy decoding (deterministic output)
./picolm model.gguf -p "The capital of France is" -n 20 -t 0
# Expected: "Paris. It is the largest city in France..."
# Test JSON mode
./picolm model.gguf --json -p "Return JSON with name and age" -n 50 -t 0.3
# Expected: valid JSON like {"name": "...", "age": ...}
# Test KV cache
./picolm model.gguf --cache test.kvc -p "Hello" -n 10 -t 0
./picolm model.gguf --cache test.kvc -p "Hello" -n 10 -t 0
# Second run should say "Skipping N cached prompt tokens"
内存验证
PicoLM 将内存统计信息打印到标准错误输出(stderr):
Memory: 1.17 MB runtime state (FP16 KV cache separate)
总计 = 运行时状态 + FP16 KV 缓存。对于上下文长度为 2048 的 TinyLlama:约 45 MB。
常见问题
问:能运行 Llama 2 7B 吗? 答:可以,前提是你有足够的 RAM 用于 KV 缓存(4096 上下文下 7B 模型约需 1.4 GB)。模型文件通过 mmap 保留在磁盘上。在配备 4GB RAM 的 Pi 4 上可以运行,但速度较慢(约 1-2 tok/s)。
问:为什么不使用 llama.cpp? 答:llama.cpp 很优秀,但在小模型上运行时仍需约 200MB+ 内存,构建依赖复杂,且主要针对桌面/服务器用例。PicoLM 专为嵌入式设计:仅需 45MB RAM,80KB 二进制文件,零依赖。
问:输出质量好吗?
答:TinyLlama 1.1B 是一个小模型——它能很好地处理简单任务(问答、摘要、基本推理、JSON 生成)。它无法与 GPT-4 相媲美,但能在没有网络的 10 美元开发板上运行。对于结构化输出,--json 语法模式可确保生成有效的 JSON,无论模型质量如何。
问:关于 GPU 加速呢? 答:PicoLM 设计上仅支持 CPU。目标硬件(10-15 美元的开发板)没有 GPU。在 x86/ARM CPU 上,SIMD(单指令多数据流)(NEON/SSE2)可提供显著的速度提升。
问:我可以使用不同的模型吗? 答:任何 LLaMA 架构的 GGUF 模型均可。从 HuggingFace 下载并将 PicoLM 指向该模型。推荐的量化方式:Q4_K_M(最佳质量/大小平衡)或 Q2_K(最小,质量较低)。
路线图
- AVX2/AVX-512 内核(现代 CPU 上生成速度提升 2-4 倍)
- 使用草稿模型的投机解码
- 上下文滑动窗口(超出 max_seq_len 的无限生成)
- 权重剪枝以进一步减少内存
- 服务器模式的连续批处理
- 支持 Mistral / Phi 架构
技术博客
有关优化历程的详细文章(包含代码片段和实战经验),请查看 BLOG.md。
许可证
MIT 许可证。详情见 LICENSE。
PicoLM —— 因为智能不应需要数据中心。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。