TabPFN
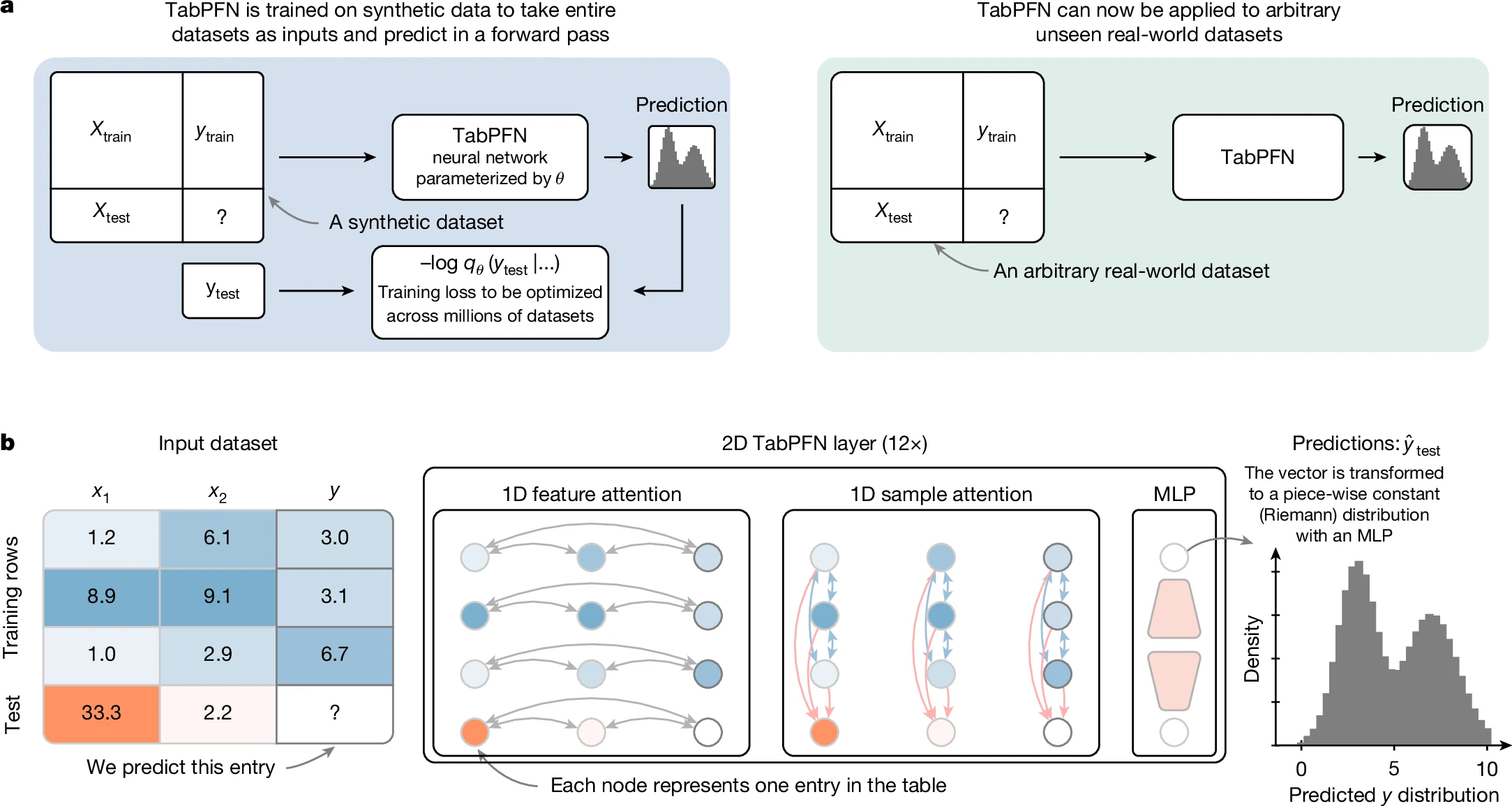
TabPFN 是一款专为表格数据设计的“基础模型”,旨在让机器学习变得像调用普通函数一样简单。它主要解决了传统表格建模中繁琐的特征工程、模型选择及超参数调优难题,用户无需进行数据缩放或独热编码等预处理,只需几行代码即可直接完成分类或回归任务。
这款工具特别适合希望快速验证想法的数据科学家、机器学习开发者以及研究人员。对于不熟悉深度学习细节但需要高性能预测结果的用户,TabPFN 也提供了极低的入门门槛。其核心技术亮点在于完全在合成数据上训练,能够理解表格数据的内在结构,从而在中小规模数据集(样本少于 10 万、特征少于 2000)上展现出媲美甚至超越传统集成方法的精度。
使用 TabPFN 时,建议搭配 GPU 以获得最佳体验,尤其是在处理较大批量预测时效率显著。虽然它在 CPU 上也能运行小样本任务,但官方推荐通过 GPU 加速来释放其全部潜力。无论是二分类、多分类还是数值预测,TabPFN 都能以统一的接口轻松应对,是将前沿 Transformer 架构应用于表格数据的创新实践。
使用场景
某金融风控团队需要在极短时间内,基于包含用户行为、设备指纹等混合特征的表格数据,构建高精度的欺诈交易识别模型。
没有 TabPFN 时
- 调参耗时漫长:数据科学家需花费数天时间手动调整 XGBoost 或 LightGBM 的超参数,反复试错以寻找最优配置。
- 预处理繁琐易错:必须严格执行特征缩放、缺失值填充和独热编码,任何一步处理不当都会导致模型性能大幅下降。
- 小样本表现不佳:面对新出现的欺诈模式,由于标注样本稀缺(仅几百条),传统深度学习模型难以收敛,泛化能力极弱。
- 部署门槛高:将复杂的预处理管道与模型串联部署到生产环境,代码维护成本高且容易出错。
使用 TabPFN 后
- 零调参即时可用:TabPFN 作为基础模型,无需任何超参数搜索,加载后直接
fit即可达到甚至超越调优后的传统模型效果。 - 原生支持原始数据:完全省去了数据缩放和编码步骤,直接将原始表格数据输入模型,大幅简化了数据流水线。
- 小样本精准预测:凭借在合成数据上的预训练优势,TabPFN 在仅有少量样本的情况下仍能捕捉复杂非线性关系,准确识别新型欺诈。
- 代码极简易部署:仅需几行代码即可完成从训练到预测的全流程,显著降低了工程落地难度和维护成本。
TabPFN 将表格数据建模从“手工匠人式”的调参预处理,转变为“开箱即用”的高效智能决策,极大释放了数据科学家的生产力。
运行环境要求
- 未说明
- 非必需但强烈推荐(CPU 仅适用于≲1000 样本的小数据集)
- 推荐 NVIDIA GPU,显存约 8GB+(部分大数据集需 16GB)
未说明

快速开始
TabPFN
![]()


![]()
快速入门
交互式笔记本教程
[!提示]
立即通过我们的交互式Colab笔记本开始体验吧!这是最直观的方式,带您一步步完成安装、分类和回归示例,亲身体验TabPFN的强大功能。
⚡ 推荐使用GPU: 为获得最佳性能,请使用GPU(即使是配备约8GB显存的旧款GPU也能很好地工作;对于某些大型数据集则需要16GB显存)。而在CPU上,仅能处理较小的数据集(≤1000个样本)。如果没有GPU?可以使用我们提供的免费托管推理服务——TabPFN Client。
安装
官方安装(通过pip)
pip install tabpfn
或者从源码安装
pip install "tabpfn @ git+https://github.com/PriorLabs/TabPFN.git"
又或者本地开发环境安装:首先安装uv(建议使用0.10.0及以上版本),这是我们用于开发的工具,然后执行以下命令:
git clone https://github.com/PriorLabs/TabPFN.git --depth 1
cd TabPFN
uv sync
基本用法
要使用我们默认的TabPFN-2.6模型,该模型完全基于合成数据训练:
from tabpfn import TabPFNClassifier, TabPFNRegressor
clf = TabPFNClassifier()
clf.fit(X_train, y_train) # 第一次使用时会自动下载检查点
predictions = clf.predict(X_test)
reg = TabPFNRegressor()
reg.fit(X_train, y_train) # 第一次使用时会自动下载检查点
predictions = reg.predict(X_test)
若需使用其他版本的模型(如TabPFN-2.5):
from tabpfn import TabPFNClassifier, TabPFNRegressor
from tabpfn.constants import ModelVersion
classifier = TabPFNClassifier.create_default_for_version(ModelVersion.V2_5)
regressor = TabPFNRegressor.create_default_for_version(ModelVersion.V2_5)
完整的示例请参阅以下文件:tabpfn_for_binary_classification.py、tabpfn_for_multiclass_classification.py以及tabpfn_for_regression.py。
使用技巧
- 使用批量预测模式:每次调用
predict方法都会重新计算训练集。如果分别对100个样本调用predict, 效率将比一次性处理100个样本低近100倍,并且成本更高。如果测试集非常大,可将其分成每批1000个样本的小块进行处理。 - 避免数据预处理:不要在输入模型之前对数据进行归一化或独热编码等操作。
- 使用GPU:TabPFN在CPU上的运行速度较慢。为了获得更好的性能,请确保使用GPU。
- 注意数据规模:TabPFN最适合处理少于10万条样本、不超过2000个特征的数据集。对于更大的数据集,建议参考大型数据集指南。
TabPFN生态系统
根据您的需求选择合适的TabPFN实现方式:
TabPFN Client 一个简单的API客户端,可通过云端推理来使用TabPFN。
TabPFN Extensions 一个功能强大的配套仓库,包含丰富的高级工具、集成和特性——非常适合贡献代码:
interpretability: 通过基于SHAP的解释、特征重要性分析及选择工具获取洞察。unsupervised: 用于异常检测和合成表格数据生成的工具。embeddings: 提取并利用TabPFN内部学习到的嵌入表示,以支持下游任务或分析。many_class: 处理超出TabPFN内置类别限制的多分类问题。rf_pfn: 将TabPFN与传统模型如随机森林结合,形成混合方法。hpo: 针对TabPFN的自动化超参数优化。post_hoc_ensembles: 在训练后集成多个TabPFN模型以提升性能。
安装方法如下:
git clone https://github.com/priorlabs/tabpfn-extensions.git
pip install -e tabpfn-extensions
TabPFN(本仓库) 核心实现,支持PyTorch和CUDA,适用于快速本地推理。
TabPFN UX 无代码图形界面,帮助探索TabPFN的功能——非常适合业务用户和原型设计。
TabPFN工作流程概览
按照此决策树构建您的模型,并从我们的生态系统中选择合适的扩展组件。它将引导您思考关于数据、硬件和性能需求的关键问题,从而找到最适合您特定应用场景的解决方案。
---
config:
theme: 'default'
themeVariables:
edgeLabelBackground: 'white'
---
graph LR
%% 1. 定义颜色方案和样式
classDef default fill:#fff,stroke:#333,stroke-width:2px,color:#333;
classDef start_node fill:#e8f5e9,stroke:#43a047,stroke-width:2px,color:#333;
classDef process_node fill:#e0f2f1,stroke:#00796b,stroke-width:2px,color:#333;
classDef decision_node fill:#fff8e1,stroke:#ffa000,stroke-width:2px,color:#333;
style Infrastructure fill:#fff,stroke:#ccc,stroke-width:5px;
style Unsupervised fill:#fff,stroke:#ccc,stroke-width:5px;
style Data fill:#fff,stroke:#ccc,stroke-width:5px;
style Performance fill:#fff,stroke:#ccc,stroke-width:5px;
style Interpretability fill:#fff,stroke:#ccc,stroke-width:5px;
%% 2. 定义图结构
subgraph Infrastructure
start((开始)) --> gpu_check["是否有GPU?"];
gpu_check -- 是 --> local_version["使用TabPFN<br/>(本地PyTorch)"];
gpu_check -- 否 --> api_client["使用TabPFN-Client<br/>(云API)"];
task_type["您的任务是什么?"]
end
local_version --> task_type
api_client --> task_type
end_node((工作流<br/>完成));
子图 无监督
unsupervised_type["选择<br/>无监督任务"];
unsupervised_type --> imputation["插补"];
unsupervised_type --> data_gen["数据<br/>生成"];
unsupervised_type --> tabebm["数据<br/>增强"];
unsupervised_type --> density["异常值<br/>检测"];
unsupervised_type --> embedding["获取<br/>嵌入"];
结束
子图 数据
data_check["数据检查"];
model_choice["样本数 > 5万 或<br/>类别数 > 10 吗?"];
data_check -- "表格中包含文本数据吗?" --> api_backend_note["注:API 客户端具有<br/>原生文本支持"];
api_backend_note --> model_choice;
data_check -- "时间序列数据吗?" --> ts_features["使用时间序列<br/>特征"];
ts_features --> model_choice;
data_check -- "纯表格数据" --> model_choice;
model_choice -- "否" --> finetune_check;
model_choice -- "是,5-10万样本" --> ignore_limits["设置<br/>ignore_pretraining_limits=True"];
model_choice -- "是,>10万样本" --> subsample["大型数据集指南<br/>(英文)"];
model_choice -- "是,>10个类别" --> many_class["多分类<br/>方法"];
结束
子图 性能
finetune_check["需要<br/>微调吗?"];
performance_check["需要更优的性能吗?"];
speed_check["需要在预测时更快地推理吗?"];
kv_cache["启用 KV 缓存<br/>(fit_mode='fit_with_cache')<br/><small>更快的预测;+内存 ~O(N×F)</small>"];
tuning_complete["微调完成"];
finetune_check -- 是 --> finetuning["微调"];
finetune_check -- 否 --> performance_check;
finetuning --> performance_check;
performance_check -- 否 --> tuning_complete;
performance_check -- 是 --> hpo["超参数优化"];
performance_check -- 是 --> post_hoc["事后<br/>集成"];
performance_check -- 是 --> more_estimators["更多<br/>估计器"];
performance_check -- 是 --> speed_check;
speed_check -- 是 --> kv_cache;
speed_check -- 否 --> tuning_complete;
hpo --> tuning_complete;
post_hoc --> tuning_complete;
more_estimators --> tuning_complete;
kv_cache --> tuning_complete;
结束
子图 可解释性
tuning_complete --> interpretability_check;
interpretability_check["需要<br/>可解释性吗?"];
interpretability_check --> feature_selection["特征选择"];
interpretability_check --> partial_dependence["部分依赖图"];
interpretability_check --> shapley["用<br/>SHAP 解释"];
interpretability_check --> shap_iq["用<br/>SHAP IQ 解释"];
interpretability_check -- 否 --> end_node;
feature_selection --> end_node;
partial_dependence --> end_node;
shapley --> end_node;
shap_iq --> end_node;
结束
%% 3. 连接子图和路径
task_type -- "分类或回归" --> data_check;
task_type -- "无监督" --> unsupervised_type;
subsample --> finetune_check;
ignore_limits --> finetune_check;
many_class --> finetune_check;
%% 4. 应用样式
类 start,end_node start_node;
类 local_version,api_client,imputation,data_gen,tabebm,density,embedding,api_backend_note,ts_features,subsample,ignore_limits,many_class,finetuning,feature_selection,partial_dependence,shapley,shap_iq,hpo,post_hoc,more_estimators,kv_cache process_node;
类 gpu_check,task_type,unsupervised_type,data_check,model_choice,finetune_check,interpretability_check,performance_check,speed_check decision_node;
类 tuning_complete process_node;
%% 5. 添加可点击链接(包括 KV 缓存示例)
点击 local_version "https://github.com/PriorLabs/TabPFN" "TabPFN 后端选项"
点击 api_client "https://github.com/PriorLabs/tabpfn-client" "TabPFN API 客户端"
点击 api_backend_note "https://github.com/PriorLabs/tabpfn-client" "TabPFN API 后端"
点击 unsupervised_type "https://github.com/PriorLabs/tabpfn-extensions" "TabPFN 扩展"
点击 imputation "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/imputation.py" "TabPFN 插补示例"
点击 data_gen "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/generate_data.py" "TabPFN 数据生成示例"
点击 tabebm "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/tabebm/tabebm_augment_real_world_data.ipynb" "TabEBM 数据增强示例"
点击 density "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/unsupervised/density_estimation_outlier_detection.py" "TabPFN 密度估计/异常值检测示例"
点击 embedding "https://github.com/PriorLabs/tabpfn-extensions/tree/main/examples/embedding" "TabPFN 嵌入示例"
点击 ts_features "https://github.com/PriorLabs/tabpfn-time-series" "TabPFN 时间序列示例"
点击 many_class "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/many_class/many_class_classifier_example.py" "多分类示例"
点击 finetuning "https://github.com/PriorLabs/TabPFN/blob/main/examples/finetune_classifier.py" "微调示例"
点击 feature_selection "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/feature_selection.py" "特征选择示例"
点击 partial_dependence "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/pdp_example.py" "部分依赖图示例"
点击 shapley "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/shap_example.py" "Shapley 值示例"
点击 shap_iq "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/interpretability/shapiq_example.py" "SHAP IQ 示例"
点击 post_hoc "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/phe/phe_example.py" "事后集成示例"
点击 hpo "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/hpo/tuned_tabpfn.py" "超参数优化示例"
点击 subsample "https://github.com/PriorLabs/tabpfn-extensions/blob/main/examples/large_datasets/large_datasets_example.py" "大型数据集示例"
点击 kv_cache "https://github.com/PriorLabs/TabPFN/blob/main/examples/kv_cache_fast_prediction.py" "KV 缓存加速预测示例"
许可协议
TabPFN-2.5 和 TabPFN-2.6 模型权重采用非商业许可进行授权。这些是默认使用的版本。
代码和 TabPFN-2 模型权重则采用 Prior Labs 许可(Apache 2.0,并附加署名要求):此处。如需使用 v2 版本的模型权重,请按如下方式实例化您的模型:
from tabpfn.constants import ModelVersion
tabpfn_v2 = TabPFNRegressor.create_default_for_version(ModelVersion.V2)
企业级与生产环境
针对高吞吐量或大规模生产环境,我们提供具有以下功能的 企业版:
- 快速推理模式:一种专有的蒸馏引擎,可将 TabPFN-2.6 转换为紧凑的 MLP 或树集成模型,从而在实时应用中实现数量级级别的更低延迟。
- 大数据模式(扩展模式):一种高级运行模式,可解除行数限制,支持包含多达 1,000 万行 的数据集——这一容量比默认的 TabPFN-2.5 和 TabPFN-2.6 模型提升了 1,000 倍。
- 商业支持:包括用于生产场景的商业企业许可证、专属集成支持,以及对私有高速推理引擎的访问权限。
如需了解更多信息或申请商业许可,请通过 sales@priorlabs.ai 联系我们。
加入我们的社区
我们正在构建表格型机器学习的未来,非常欢迎您的参与:
交流与学习:
- 加入我们的 Discord 社区
- 阅读我们的 文档
- 查看 GitHub 问题
贡献:
- 报告错误或请求新功能
- 提交拉取请求(请务必先打开一个讨论相关功能/错误的问题,如果尚不存在)
- 分享您的研究和使用案例
保持更新:为仓库加星并加入 Discord,以获取最新动态
引用
您可在此阅读解释 TabPFNv2 的论文 这里,以及关于 TabPFN-2.5 的模型报告 这里。
@misc{grinsztajn2025tabpfn,
title={TabPFN-2.5: 推进表格基础模型的最先进水平},
author={Léo Grinsztajn 和 Klemens Flöge 和 Oscar Key 和 Felix Birkel 和 Philipp Jund 和 Brendan Roof 和
Benjamin Jäger 和 Dominik Safaric 和 Simone Alessi 和 Adrian Hayler 和 Mihir Manium 和 Rosen Yu 和
Felix Jablonski 和 Shi Bin Hoo 和 Anurag Garg 和 Jake Robertson 和 Magnus Bühler 和 Vladyslav Moroshan 和
Lennart Purucker 和 Clara Cornu 和 Lilly Charlotte Wehrhahn 和 Alessandro Bonetto 和
Bernhard Schölkopf 和 Sauraj Gambhir 和 Noah Hollmann 和 Frank Hutter},
year={2025},
eprint={2511.08667},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2511.08667},
}
@article{hollmann2025tabpfn,
title={利用表格基础模型在小数据上实现精准预测},
author={Hollmann, Noah 和 M{\"u}ller, Samuel 和 Purucker, Lennart 和
Krishnakumar, Arjun 和 K{\"o}rfer, Max 和 Hoo, Shi Bin 和
Schirrmeister, Robin Tibor 和 Hutter, Frank},
journal={Nature},
year={2025},
month={01},
day={09},
doi={10.1038/s41586-024-08328-6},
publisher={Springer Nature},
url={https://www.nature.com/articles/s41586-024-08328-6},
}
@inproceedings{hollmann2023tabpfn,
title={TabPFN:一种能在一秒钟内解决小型表格分类问题的 Transformer 模型},
author={Hollmann, Noah 和 M{\"u}ller, Samuel 和 Eggensperger, Katharina 和 Hutter, Frank},
booktitle={2023 年国际学习表征会议},
year={2023}
}
❓ 常见问题解答
使用与兼容性
问:TabPFN 最适合处理多大规模的数据集? 答:TabPFN-2.5 专为 最多 5 万行 的数据集而优化。对于更大的数据集,建议使用 随机森林预处理 或其他扩展方法。有关策略,请参阅我们的 Colab 笔记本。
问:为什么我不能使用 Python 3.8 运行 TabPFN? 答:TabPFN 需要 Python 3.9 及以上版本,因为其依赖于较新的语言特性。兼容的版本包括:3.9、3.10、3.11、3.12、3.13。
安装与设置
问:如何获取 TabPFN-2.5 / TabPFN-2.6 的使用权限?
首次使用时,TabPFN 会自动打开一个浏览器窗口,您可以在其中通过 PriorLabs 登录并接受许可条款。您的认证令牌会被本地缓存,因此只需执行一次即可。
对于无界面 / CI 环境,即无法使用浏览器的环境,请访问 https://ux.priorlabs.ai,进入 许可 选项卡以接受许可协议,然后使用从您的账户获得的令牌设置 TABPFN_TOKEN 环境变量。
如果您无法通过基于浏览器的流程获取访问权限,请通过 sales@priorlabs.ai 联系我们。
问:如何在没有互联网连接的情况下使用 TabPFN?
TabPFN 在首次使用时会自动下载模型权重。若需离线使用:
使用提供的下载脚本
如果您拥有 TabPFN 仓库,可以使用其中包含的脚本下载所有模型(包括集成变体):
# 安装 TabPFN 后
python scripts/download_all_models.py
此脚本会将主分类器和回归器模型,以及所有集成变体模型下载到您系统的默认缓存目录。
手动下载
从 HuggingFace 手动下载模型文件:
- 分类器:tabpfn-v2.5-classifier-v2.5_default.ckpt(注意:分类器的默认版本使用在真实数据上微调的模型)。
- 回归器:tabpfn-v2.5-regressor-v2.5_default.ckpt
将文件放置在以下任一位置:
- 直接指定路径:
TabPFNClassifier(model_path="/path/to/model.ckpt") - 设置环境变量:
export TABPFN_MODEL_CACHE_DIR="/path/to/dir"(参见下方的环境变量常见问题) - 默认操作系统缓存目录:
- Windows:
%APPDATA%\tabpfn\ - macOS:
~/Library/Caches/tabpfn/ - Linux:
~/.cache/tabpfn/
- Windows:
- 直接指定路径:
问:加载模型时出现 pickle 错误,该怎么办?
答:请尝试以下操作:
- 使用
pip install tabpfn --upgrade下载最新版本的 TabPFN。 - 确保模型文件已正确下载(如有必要,请重新下载)。
问:我可以使用哪些环境变量来配置 TabPFN?
答:TabPFN 使用 Pydantic 设置进行配置,支持环境变量和 .env 文件:
身份验证:
TABPFN_TOKEN:直接提供 PriorLabs 身份验证令牌(适用于无界面或 CI 环境)。可从 https://ux.priorlabs.ai 获取。TABPFN_NO_BROWSER:设置为禁用自动浏览器登录(例如,在不希望打开浏览器的环境中)。
模型配置:
TABPFN_MODEL_CACHE_DIR:用于缓存下载的 TabPFN 模型的自定义目录(默认为平台特定的用户缓存目录)。TABPFN_ALLOW_CPU_LARGE_DATASET:允许在 CPU 上运行处理大型数据集(超过 1000 个样本)的 TabPFN。将其设置为true可以绕过 CPU 的限制。注意:这将非常缓慢!
PyTorch 设置:
PYTORCH_CUDA_ALLOC_CONF:PyTorch CUDA 内存分配配置,用于优化 GPU 内存使用(默认值为max_split_size_mb:512)。更多信息请参阅 PyTorch CUDA 文档。
示例:
export TABPFN_MODEL_CACHE_DIR="/path/to/models"
export TABPFN_ALLOW_CPU_LARGE_DATASET=true
export PYTORCH_CUDA_ALLOC_CONF="max_split_size_mb:512"
或者直接在 .env 文件中设置。
问:如何保存和加载训练好的 TabPFN 模型?
答:使用 save_fitted_tabpfn_model 来持久化已拟合的估计器,并稍后使用 load_fitted_tabpfn_model(或相应的 load_from_fit_state 类方法)重新加载。
from tabpfn import TabPFNRegressor
from tabpfn.model_loading import (
load_fitted_tabpfn_model,
save_fitted_tabpfn_model,
)
# 在 GPU 上训练回归器
reg = TabPFNRegressor(device="cuda")
reg.fit(X_train, y_train)
save_fitted_tabpfn_model(reg, "my_reg.tabpfn_fit")
# 稍后或在仅含 CPU 的机器上
reg_cpu = load_fitted_tabpfn_model("my_reg.tabpfn_fit", device="cpu")
如果只想存储基础模型权重(而不包含已拟合的估计器),可以使用 save_tabpfn_model(reg.model_, "my_tabpfn.ckpt")。这只会保存预训练权重的检查点,以便日后创建并拟合一个新的估计器。可以通过 load_model_criterion_config 重新加载该检查点。
性能与限制
问:TabPFN 能否处理缺失值? 答:能!
问:如何提高 TabPFN 的性能? 答:最佳实践:
- 使用 TabPFN Extensions 中的
AutoTabPFNClassifier进行事后集成。 - 特征工程:添加领域特定特征以提升模型性能。
无效的方法:
- 调整特征缩放。
- 将分类特征转换为数值类型(例如,独热编码)。
问:Hugging-Face 上有哪些不同的检查点?
答:除了默认检查点外,其他可用的检查点均为实验性,平均表现较差。我们建议始终从默认检查点开始。这些检查点可以用作集成或超参数优化系统的一部分(并在 AutoTabPFNClassifier 中自动使用),也可以手动尝试。它们的名称后缀表明了我们期望它们擅长的任务。
关于每个 TabPFN-2.5 检查点的详细信息
我们为在真实数据上微调的检查点添加了 🌍 图标。43 个数据集的列表请参阅 TabPFN-2.5 论文。
tabpfn-v2.5-classifier-v2.5_default.ckpt🌍:默认分类检查点,已在真实数据上微调。tabpfn-v2.5-classifier-v2.5_default-2.ckpt:最佳的合成数据分类检查点。使用此检查点可以获得未经过真实数据微调的默认 TabPFN-2.5 分类模型。tabpfn-v2.5-classifier-v2.5_large-features-L.ckpt:专为特征数量较多(最多 500 个)且样本量较小(少于 5000 个)的情况设计。tabpfn-v2.5-classifier-v2.5_large-features-XL.ckpt:专为特征数量更多(最多 1000 个,可能支持max_features_per_estimator=1000)的情况设计。tabpfn-v2.5-classifier-v2.5_large-samples.ckpt:专为样本量较大的情况(超过 3 万个)设计。tabpfn-v2.5-classifier-v2.5_real.ckpt🌍:另一个在真实数据上微调的分类检查点。整体表现不错,但在特征数量较多(超过 100-200 个)时表现较差。tabpfn-v2.5-classifier-v2.5_real-large-features.ckpt🌍:另一个在真实数据上微调的分类检查点,但在样本量较大(超过 1 万个)时表现不佳。tabpfn-v2.5-classifier-v2.5_real-large-samples-and-features.ckpt🌍:与tabpfn-v2.5-classifier-v2.5_default.ckpt完全相同。tabpfn-v2.5-classifier-v2.5_variant.ckpt:整体表现尚可,但在特征数量较多(超过 100-200 个)时表现较差。tabpfn-v2.5-regressor-v2.5_default.ckpt:默认回归检查点,仅在合成数据上训练。tabpfn-v2.5-regressor-v2.5_low-skew.ckpt:专为目标变量偏度较低的数据设计(但总体表现一般)。tabpfn-v2.5-regressor-v2.5_quantiles.ckpt:可用于分位数或分布估计的变体,不过仍应优先考虑默认检查点。tabpfn-v2.5-regressor-v2.5_real.ckpt🌍:在真实数据上微调的回归检查点。这是所有在真实数据上微调的检查点中表现最好的一个。对于回归任务,我们建议默认使用仅在合成数据上训练的检查点,但此检查点在某些数据集上确实表现更好。tabpfn-v2.5-regressor-v2.5_real-variant.ckpt🌍:另一个在真实数据上微调的回归变体。tabpfn-v2.5-regressor-v2.5_small-samples.ckpt:在小样本量(少于 3000 个)的情况下表现略好。tabpfn-v2.5-regressor-v2.5_variant.ckpt:另一种变体,没有明确的特长,但在少数数据集上可能表现更好。
开发
- 安装 uv
- 设置开发环境:
git clone https://github.com/PriorLabs/TabPFN.git
cd TabPFN
uv sync
source venv/bin/activate # 在 Windows 上:venv\Scripts\activate
pre-commit install
- 提交代码前:
pre-commit run --all-files
- 运行测试:
pytest tests/
匿名化遥测
本项目会收集完全匿名的使用情况遥测数据,并提供选择退出所有遥测或选择加入扩展遥测的功能。
这些数据仅用于帮助我们提升相关产品和计算环境的稳定性,并指导未来的改进方向。
- 不会收集任何个人数据
- 绝不会发送代码、模型输入或输出
- 数据严格匿名,无法与个人关联
如需选择退出遥测,请设置以下环境变量:
export TABPFN_DISABLE_TELEMETRY=1
由 Prior Labs 用心打造 - 版权所有 © 2025 Prior Labs GmbH
版本历史
v7.1.02026/04/02v7.0.12026/03/26v7.0.02026/03/24v6.4.12026/02/19v6.4.02026/02/19v6.3.22026/01/30v6.0.62025/12/01v6.0.02025/12/01v2.1.32025/08/22v2.1.12025/08/03v2.1.02025/07/28v2.0.9_2025/07/28常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。