Text2Video-Zero
Text2Video-Zero 是一款创新的开源 AI 工具,能够直接将文本描述转化为连贯的视频内容,甚至支持根据指令编辑现有视频。它的核心突破在于“零样本”(Zero-Shot)能力:无需针对视频数据进行额外的昂贵训练,即可直接利用现有的文本生成图像模型(如 Stable Diffusion)来生成视频。这有效解决了传统视频生成模型依赖大量特定数据集训练、成本高且灵活性差的痛点,同时确保了生成画面在时间维度上的流畅与一致。
除了基础的文生视频,Text2Video-Zero 还展现了强大的可控性。用户不仅可以输入文字,还能结合姿态、边缘轮廓或深度信息来精准引导视频动作与结构,实现了类似“视频版 Instruct-Pix2Pix"的指令式编辑功能。技术层面,它集成了令牌合并(Token Merging)等优化手段,显著降低了显存需求,使更多设备能够运行。
这款工具非常适合 AI 研究人员探索多模态生成机制,也适合开发者快速构建视频应用原型。对于设计师和内容创作者而言,它提供了一个低门槛、高自由度的创意实验平台,让将脑海中的动态场景瞬间可视化成为可能。随着其被集成到主流 Diffusers 库中,Text2Video-Zero 正成为连接静态图像生成与动态视频创作的重要桥梁。
使用场景
某独立游戏开发者需要为一款复古像素风格的游戏快速生成一段“角色在雨中奔跑”的过场动画,以测试剧情节奏。
没有 Text2Video-Zero 时
- 高昂的训练成本:若要生成特定风格的视频,通常需收集大量该风格的视频数据并重新训练模型,耗时数天且需要多张高端显卡。
- 画面闪烁严重:直接使用传统的逐帧图像生成工具,会导致每一帧之间缺乏关联,角色动作和背景出现严重的抖动与不连贯。
- 编辑灵活性差:若想调整角色的奔跑姿势或雨势大小,往往需要重新生成整个序列,无法基于现有画面进行局部指令修改。
- 显存门槛极高:现有的视频生成方案对显存要求苛刻,普通开发者的单卡工作站(如 12GB 以下)难以运行,限制了创意验证的速度。
使用 Text2Video-Zero 后
- 零样本即时生成:直接利用已有的文本到图像扩散模型,无需任何额外训练或视频数据集,输入提示词即可生成符合像素风格的连贯视频。
- 时序高度一致:通过其特有的运动引导机制,生成的视频中角色奔跑动作流畅自然,背景雨滴下落稳定,彻底消除了画面闪烁问题。
- 指令化精准编辑:利用 Video Instruct-Pix2Pix 功能,只需输入“让雨下得更大”或“改变奔跑方向”等指令,即可在保留原视频结构的基础上完成编辑。
- 低显存友好部署:结合 Token Merging 技术,即使在显存小于 7GB 的消费级显卡上也能流畅运行,让独立开发者能在本地轻松迭代创意。
Text2Video-Zero 将视频生成的门槛从“专业实验室”拉低至“个人工作台”,让创作者能以最少的资源实现从零到一的动态视觉构思。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 最低显存需求:标准模式需 12GB
- 启用 Token Merging (merging_ratio) 且 chunk_size=2 时可降至 7GB 以下
- CUDA 版本需 >= 11.6
未说明

快速开始
Text2Video-Zero
本仓库是 Text2Video-Zero 的官方实现。
Text2Video-Zero:文本到图像扩散模型即为零样本视频生成器 Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, Humphrey Shi

我们的方法 Text2Video-Zero 能够实现零样本视频生成,支持 (i) 文本提示(见第1、2行),(ii) 结合姿态或边缘引导的提示(见右下角),以及 (iii) Video Instruct-Pix2Pix,即指令引导的视频编辑(见左下角)。生成结果在时间上保持一致,并紧密遵循引导和文本提示。
最新消息
- [2023年3月23日] 论文 Text2Video-Zero 发布!
- [2023年3月25日] 我们的 Hugging Face 演示 第一个版本(包含
零样本文本到视频生成和Video Instruct Pix2Pix)发布! - [2023年3月27日] 我们的 Hugging Face 演示 完整版本 发布!现在还新增了:
文本与姿态条件下的视频生成、文本与边缘条件下的视频生成,以及文本、边缘和 DreamBooth 条件下的视频生成。 - [2023年3月28日] 我们所有生成方法的代码均已发布!我们新增了一种低显存配置。目前所需的最低 GPU 显存为 12 GB。未来版本将进一步降低这一要求。
- [2023年3月29日] 优化后的 Hugging Face 演示 上线!(i) 对于文本到视频生成,现在可以加载 Hugging Face 上托管的 任意 Stable Diffusion 基础模型 和 任意 DreamBooth 模型!(ii) 我们提升了 Video Instruct-Pix2Pix 的质量。(iii) 我们新增了两个更长的 Video Instruct-Pix2Pix 示例。
- [2023年3月30日] 新版代码发布!包含了我们最新 Hugging Face 版本的所有改进。详情请参阅 3月29日的更新内容。此外,生成的文本到视频还可以具有 任意长度。
- [2023年4月6日] 我们将 Token Merging 集成到了代码中。当使用最高压缩率并将 chunk size 设置为
2时,我们的代码可以在 低于 7 GB 显存 的情况下运行。 - [2023年4月11日] 新版代码和 Hugging Face 演示发布!我们集成了基于 MiDaS 的 深度控制。
- [2023年4月13日] 我们的算法已被集成到 🧨 Diffusers 中!
贡献
我们致力于推动 AI 民主化,激发每个人的创造力,而我们认为 Text2Video-Zero 是一个极具潜力的研究方向,能够释放优秀文本到图像模型在零样本视频生成和编辑方面的巨大潜能!
为了实现这一目标,我们欢迎所有贡献。请查看这些 Text2Video-Zero 的外部实现和扩展。感谢各位作者的努力与贡献:
- https://github.com/JiauZhang/Text2Video-Zero
- https://github.com/camenduru/text2video-zero-colab
- https://github.com/SHI-Labs/Text2Video-Zero-sd-webui
环境搭建
- 克隆本仓库并进入:
git clone https://github.com/Picsart-AI-Research/Text2Video-Zero.git
cd Text2Video-Zero/
- 使用 Python 3.9 和 CUDA >= 11.6 安装依赖项
virtualenv --system-site-packages -p python3.9 venv
source venv/bin/activate
pip install -r requirements.txt
推理 API
要进行推理,需创建 Model 类的实例
import torch
from model import Model
model = Model(device = "cuda", dtype = torch.float16)
文本到视频
要直接调用我们的文本到视频生成器,运行以下 Python 命令,结果将保存至 tmp/text2video/A_horse_galloping_on_a_street.mp4:
prompt = "A horse galloping on a street"
params = {"t0": 44, "t1": 47 , "motion_field_strength_x" : 12, "motion_field_strength_y" : 12, "video_length": 8}
out_path, fps = f"./text2video_{prompt.replace(' ','_')}.mp4", 4
model.process_text2video(prompt, fps = fps, path = out_path, **params)
若要使用不同的 Stable Diffusion 基础模型,运行以下 Python 命令:
from hf_utils import get_model_list
model_list = get_model_list()
for idx, name in enumerate(model_list):
print(idx, name)
idx = int(input("Select the model by the listed number: ")) # 选择您心仪的模型
model.process_text2video(prompt, model_name = model_list[idx], fps = fps, path = out_path, **params)
可选超参数
您可以定义以下超参数:
- 运动场强度:
motion_field_strength_x= $\delta_x$ 和motion_field_strength_y= $\delta_y$ (详见我们的论文第 3.3.1 节)。默认值为:motion_field_strength_x=motion_field_strength_y= 12。 - $T$ 和 $T'$(详见我们的论文第 3.3.1 节)。可设置
t0和t1的值,范围为{0,...,50}。默认值为:t0=44,t1=47(DDIM 步骤)。分别对应于时间步881和941。 - 视频长度:定义要生成的帧数
video_length。默认值为:video_length=8。
带姿态控制的文本到视频
要直接调用我们的带姿态控制的文本到视频生成器,运行以下 Python 命令:
prompt = 'an astronaut dancing in outer space'
motion_path = '__assets__/poses_skeleton_gifs/dance1_corr.mp4'
out_path = f"./text2video_pose_guidance_{prompt.replace(' ','_')}.gif"
model.process_controlnet_pose(motion_path, prompt=prompt, save_path=out_path)
带边缘控制的文本转视频
要直接调用我们的带边缘控制的文本转视频生成器,请运行以下 Python 命令:
prompt = '一幅鹿的油画,高质量、细节丰富且专业的照片'
video_path = '__assets__/canny_videos_mp4/deer.mp4'
out_path = f'./text2video_edge_guidance_{prompt}.mp4'
model.process_controlnet_canny(video_path, prompt=prompt, save_path=out_path)
超参数
您可以为 Canny 边缘检测定义以下超参数:
- 低阈值。定义
low_threshold的值,范围为 $(0, 255)$。默认值:low_threshold=100。 - 高阈值。定义
high_threshold的值,范围为 $(0, 255)$。默认值:high_threshold=200。请确保high_threshold>low_threshold。
您可以将超参数作为参数传递给 model.process_controlnet_canny
带边缘引导和 Dreambooth 专精的文本转视频
加载一个 Dreambooth 模型,然后按照“带边缘引导的文本转视频”中的说明进行操作。
prompt = '您的提示词'
video_path = '您视频的路径'
dreambooth_model_path = '您 Dreambooth 模型的路径'
out_path = f'./text2video_edge_db_{prompt}.gif'
model.process_controlnet_canny_db(dreambooth_model_path, video_path, prompt=prompt, save_path=out_path)
video_path 的值可以是 mp4 文件的路径。如果要使用提供的示例视频之一,可设置为 video_path="woman1"、video_path="woman2"、video_path="woman3" 或 video_path="man1"。
dreambooth_model_path 的值可以是扩散模型文件的链接,也可以是提供的 Dreambooth 模型之一的名称。为此,可设置为 dreambooth_model_path = "Anime DB"、dreambooth_model_path = "Avatar DB"、dreambooth_model_path = "GTA-5 DB" 或 dreambooth_model_path = "Arcane DB"。对应的关键词分别为:1girl(用于 Anime DB)、arcane style(用于 Arcane DB)、avatar style(用于 Avatar DB)以及 gtav style(用于 GTA-5 DB)。
自定义 Dreambooth 模型
要加载自定义 Dreambooth 模型,需将控制权转移到自定义模型,并将其转换为扩散格式。随后,dreambooth_model_path 的值必须指向包含扩散文件的文件夹。Dreambooth 模型可以从例如 CIVITAI 获取。
视频指令-Pix2Pix
要进行 Pix2Pix 视频编辑,请运行以下 Python 命令:
prompt = '让它变成梵高的《星夜》'
video_path = '__assets__/pix2pix video/camel.mp4'
out_path = f'./video_instruct_pix2pix_{prompt}.mp4'
model.process_pix2pix(video_path, prompt=prompt, save_path=out_path)
带深度控制的文本转视频
要直接调用我们的带深度控制的文本转视频生成器,请运行以下 Python 命令:
prompt = '一幅鹿的油画,高质量、细节丰富且专业的照片'
video_path = '__assets__/depth_videos/deer.mp4'
out_path = f'./text2video_depth_control_{prompt}.mp4'
model.process_controlnet_depth(video_path, prompt=prompt, save_path=out_path)
低内存推理
上述每种接口都可以在低内存环境下运行。在最低配置下,只需一块拥有 12 GB VRAM 的 GPU 即可。
为了减少内存使用量,在调用上述推理 API 时,可添加 chunk_size=k 作为额外参数。整数 k 的取值范围为 {2,...,video_length}。它定义了每次处理的帧数(不会影响画质)。数值越小,所需的内存就越少。
当使用 Gradio 应用程序时,可在“高级选项”中设置 chunk_size。
得益于 Token Merging 的出色工作,内存使用量还可以进一步降低。可以通过 merging_ratio 参数进行配置,其取值范围为 [0,1]。数值越高,压缩程度越大(从而加快推理速度并减少内存需求)。请注意,过高的数值会降低图像质量。
我们计划继续优化代码,以实现更低的内存消耗。
消融研究
要复现消融研究,在调用上述推理 API 时,需添加额外的参数。
- 若要禁用“跨帧注意力”:在参数列表中添加
use_cf_attn=False。 - 若要禁用用“运动动态”丰富潜在编码:在参数列表中添加
use_motion_field=False。
注意:添加 smooth_bg=True 可激活背景平滑功能。然而,我们的代码并不包含运行该功能所必需的显著物体检测器。
使用 Gradio 进行推理
点击查看详细信息。
从项目根目录运行以下 Shell 命令:
python app.py
然后使用浏览器在本地访问应用 http://127.0.0.1:7860。
若要远程访问应用,运行以下 Shell 命令:
python app.py --public_access
有关公共访问的安全信息,请参阅 Gradio 的文档。
结果
文本转视频
 |
 |
 |
 |
| “一只猫正在草地上奔跑” | “一只熊猫在时代广场弹吉他” | “一名男子正在雪地里跑步” | “一名宇航员正滑雪下山” |
 |
 |
 |
 |
| “一只熊猫正在玩醒板冲浪” | “一只熊在时代广场跳舞” | “一名男子在阳光下骑自行车” | “一匹马正在街道上飞奔” |
 |
 |
 |
 |
| “一只老虎独自走在街道上” | “一只熊猫正在玩醒板冲浪” | “一匹马正在街道上飞奔” | “一只可爱的小猫在美丽的草地上奔跑” |
 |
 |
 |
 |
| “一匹马正在街道上飞奔” | “一只熊猫独自走在街道上” | “一只狗正在街上散步” | “一名宇航员正在月球上挥手” |
带姿态引导的文本转视频
 |
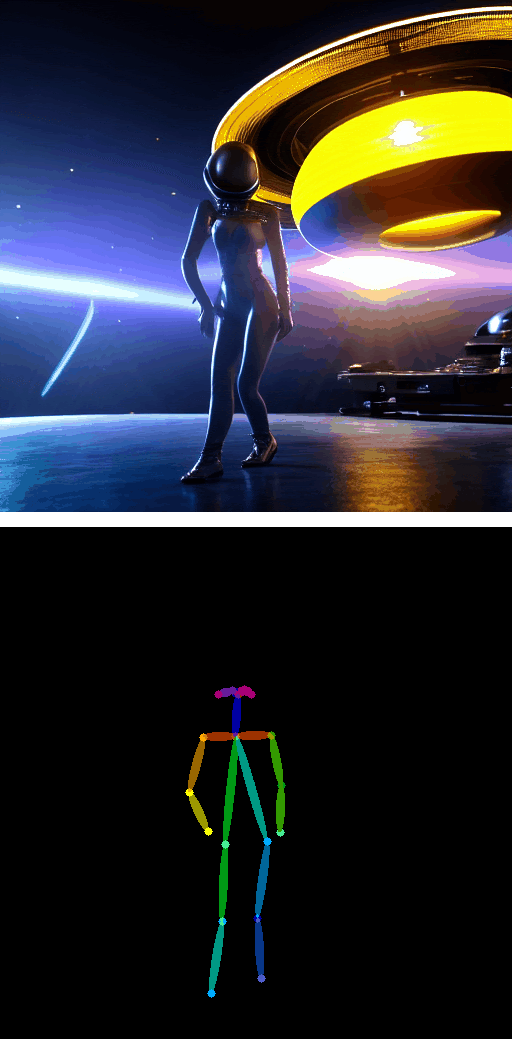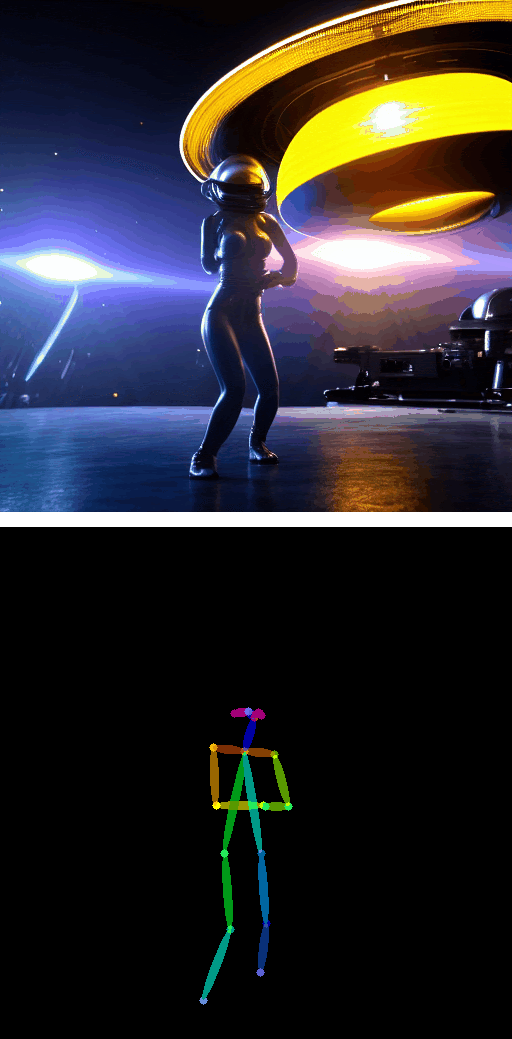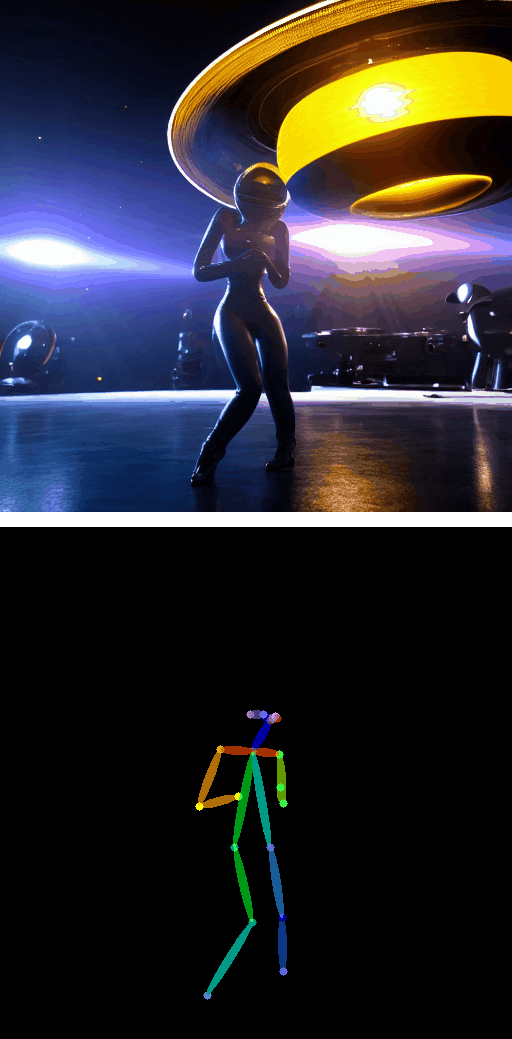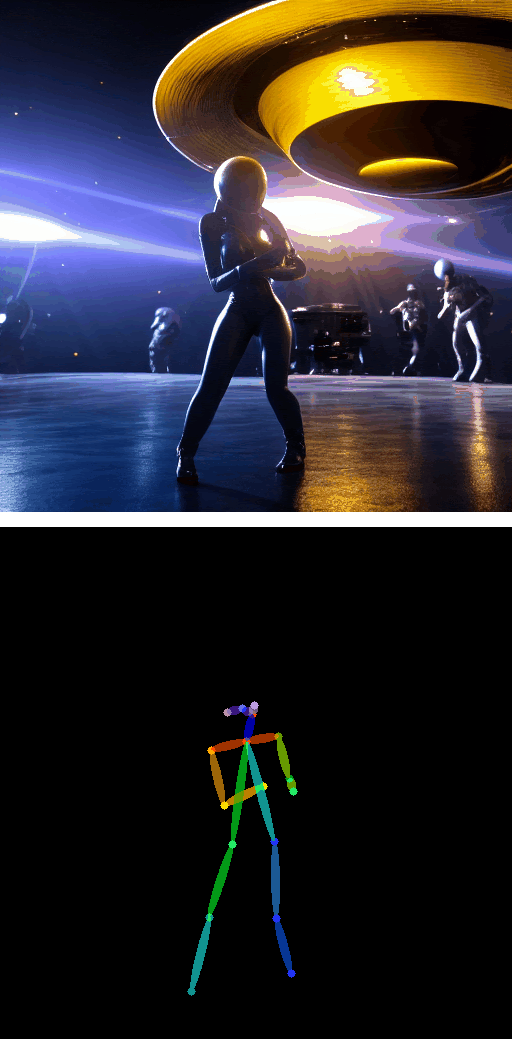 |
 |
 |
| “一只熊在水泥地上跳舞” | “一个外星人在飞碟下跳舞” | “一只熊猫在南极洲跳舞” | “一名宇航员在太空中跳舞” |