MoE-LLaVA
MoE-LLaVA 是一款面向大型视觉 - 语言模型的创新开源项目,旨在通过“混合专家”(Mixture-of-Experts, MoE)架构提升模型处理复杂多模态任务的能力。传统视觉 - 语言模型在参数量增大时往往面临计算成本高昂、推理速度慢的瓶颈,而 MoE-LLaVA 巧妙地将模型划分为多个专用“专家”子网络,仅在处理特定任务时动态激活相关部分。这种设计不仅显著降低了计算资源消耗,还大幅提升了模型在图像理解、视频分析及跨模态推理等场景下的效率与准确性。
该项目特别适合研究人员和开发者使用,尤其是那些希望在有限算力条件下探索大规模多模态模型潜力的团队。对于需要快速原型验证或部署高效 AI 应用的企业技术部门,MoE-LLaVA 也提供了灵活的接口和丰富的预训练模型支持。其核心技术亮点在于动态路由机制,能够智能分配输入数据到最合适的专家模块,从而实现性能与资源的最优平衡。此外,项目社区活跃,配套提供了 Hugging Face 空间演示、Colab 笔记本及详细文档,方便用户快速上手。无论是学术研究还是工业落地,MoE-LLaVA 都为多模态人工智能的发展提供了强有力的工具支持。
使用场景
某电商平台的智能客服团队正试图升级系统,使其能直接理解用户上传的商品实拍图并回答复杂的细节咨询。
没有 MoE-LLaVA 时
- 响应延迟高:传统大视觉语言模型参数量巨大,每次处理图片都需要激活全部计算资源,导致用户提问后需等待数秒才能收到回复,严重影响购物体验。
- 硬件成本昂贵:为了维持高并发下的流畅度,公司不得不部署大量高性能 GPU 服务器,运维预算居高不下。
- 细节识别模糊:面对用户询问“这件衣服领口的刺绣图案是什么”等细粒度问题时,模型往往只能给出泛泛的描述,无法精准定位图像局部特征。
- 场景适应性差:模型难以在“通用闲聊”与“专业商品分析”之间灵活切换,要么过于啰嗦,要么缺乏专业深度。
使用 MoE-LLaVA 后
- 推理速度显著提升:借助混合专家(MoE)架构,MoE-LLaVA 仅激活部分专家网络处理特定任务,将单次响应时间从秒级降低至毫秒级,实现近乎实时的交互。
- 算力资源大幅节约:在保持同等甚至更高智能水平的前提下,显著减少了活跃参数量,使原有硬件集群能支撑更高的并发流量,降低了部署门槛。
- 细粒度理解更精准:针对商品细节的提问,MoE-LLaVA 能调动专门的视觉专家模块,准确识别并描述领口刺绣、材质纹理等微小特征,回答专业度大幅提升。
- 动态任务适配:模型能根据用户问题类型自动路由到最合适的“专家”子网络,无论是轻松闲聊还是严谨的参数对比,都能给出恰到好处的回复。
MoE-LLaVA 通过“按需调用”专家网络的机制,完美解决了大型视觉语言模型在落地应用中成本高、速度慢与精度难以兼得的核心矛盾。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 训练需求:8x A100 GPU
- 推理需求:未明确具体显存大小,但模型参数量在 2.0B-3.6B (稀疏激活) 之间,建议使用支持 CUDA 的中高端显卡
未说明

快速开始

MoE-LLaVA:面向大型视觉-语言模型的专家混合模型
如果您喜欢我们的项目,请在 GitHub 上为我们点亮星标 ⭐,以获取最新更新。
![]()

![]() 

![]()


💡 我还有其他可能让您感兴趣的视觉-语言项目 ✨。
Open-Sora 计划:开源大型视频生成模型
林斌、葛云阳、程新华、李宗健、朱彬、王绍东、何先义、叶洋、袁圣海、陈刘汉、贾唐辉、张俊武、唐振宇、庞雅婷、佘彬、严岑、胡志恒、董晓艺、陈林、潘章、周兴、董绍玲、田永宏、袁力



Video-LLaVA:通过对齐后再投影学习统一的视觉表征
林斌、叶洋、朱彬、崔家熙、宁慕楠、金鹏、袁力


LanguageBind:通过基于语言的语义对齐将视频-语言预训练扩展至 N 模态
朱彬、林斌、宁慕楠、杨燕、崔家熙、王洪法、庞雅婷、蒋文浩、张俊武、李宗伟、张万才、李志峰、刘伟、袁力


📣 新闻
- [2025.07.15] 🔥🔥🔥 我们的 MoE-LLaVA 已被 IEEE 多媒体汇刊(TMM)接收!
- [2024.03.16] 🎉 我们发布了所有 stage2 模型,请查看我们的 模型库。
- [2024.02.03] 🎉 我们发布了一个更强大的 MoE-LLaVA-StableLM。该模型仅使用 2.0B 的稀疏激活参数,平均性能就接近 LLaVA-1.5-7B,请查看我们的 模型库。
- [2024.02.02] 🤝 您可以体验 和
 ,这些内容由 @camenduru 制作,他慷慨地支持我们的研究!
,这些内容由 @camenduru 制作,他慷慨地支持我们的研究! - [2024.02.01] 🔥 对于无法访问 Hugging Face 的用户,现在可以通过
 ModelScope 下载模型,请查看我们的 模型库。
ModelScope 下载模型,请查看我们的 模型库。 - [2024.01.30] 🔥 我们发布了一个更强大的 MoE-LLaVA-Phi2。该模型仅使用 3.6B 的稀疏激活参数,平均性能就 超越了 LLaVA-1.5-7B,请查看我们的 模型库。
- [2024.01.27] 🤗 Hugging Face 演示以及 所有代码和数据集 现已可用!欢迎 关注 👀 此仓库,以获取最新动态。
😮 亮点
MoE-LLaVA 在多模态学习方面表现出色。
🔥 高性能,但参数量更少
- 仅需 3B 的稀疏激活参数,MoE-LLaVA 就能在多种视觉理解数据集上达到与 LLaVA-1.5-7B 相当的性能,甚至在物体幻觉基准测试中超越了 LLaVA-1.5-13B。
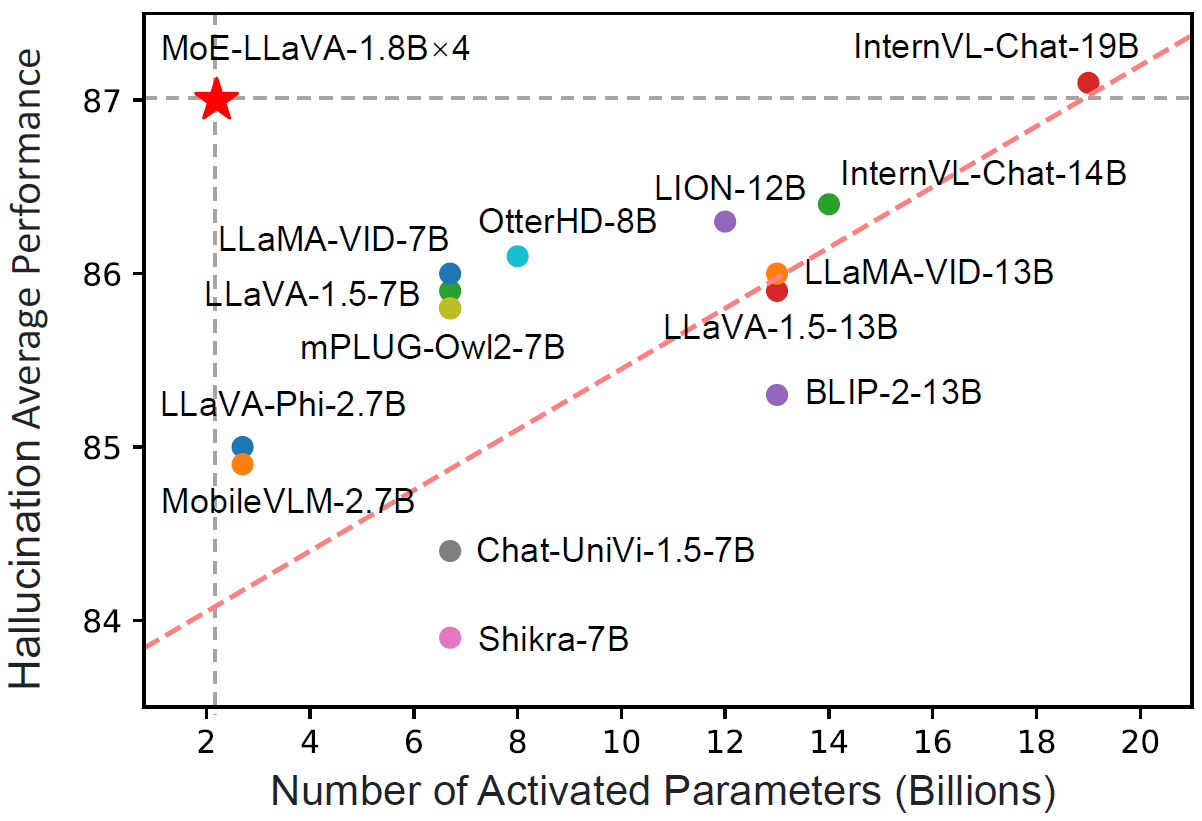
🚀 简单的基线,通过稀疏路径学习多模态交互。
- 通过增加 一个简单的 MoE 调优阶段,我们可以在 8 张 A100 GPU 上用不到 1 天的时间完成 MoE-LLaVA 的训练。
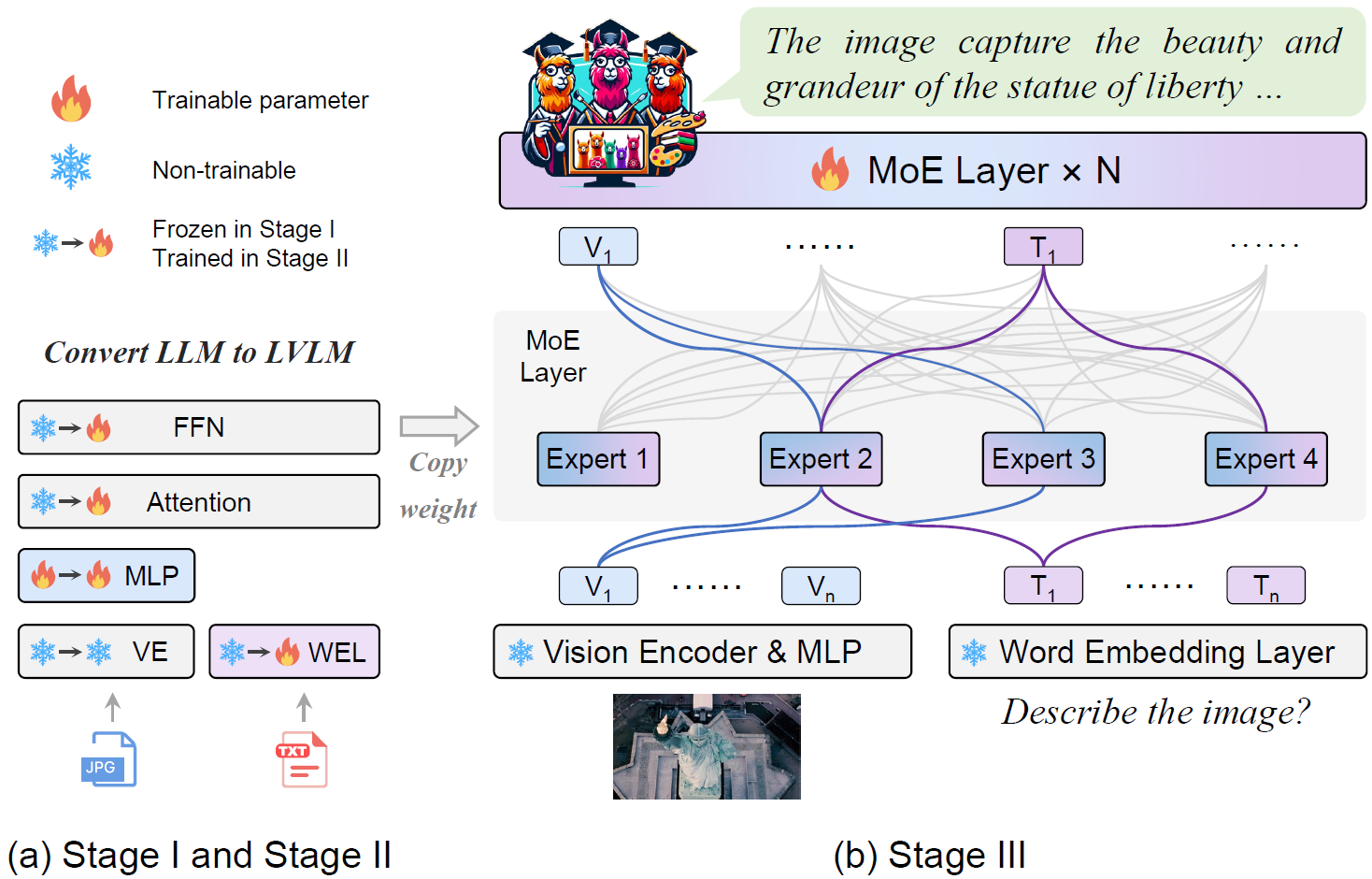
🤗 演示
Gradio Web UI 
强烈推荐您通过以下命令试用我们的网页演示,它包含了 MoE-LLaVA 目前支持的所有功能。我们还在 Huggingface Spaces 中提供了 在线演示。
# 使用 phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# 使用Qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# 使用StableLM
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
https://github.com/PKU-YuanGroup/MoE-LLaVA/assets/62638829/8541aac6-9ef6-4fde-aa94-80d0375b9bdb
命令行推理
# 使用Phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# 使用Qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# 使用StableLM
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"

🐳 模型库
| 模型 | 激活参数 | Transformers(HF) | ModelScope(HF) | 平均 | VQAv2 | GQA | VizWiz | SQA-IMG | T-VQA | POPE | MME | MM-Bench | MM-Vet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 2.0B | 🤗LanguageBind/MoE-LLaVA-StableLM-1.6B-4e | PKU-YuanLab/MoE-LLaVA-StableLM-1.6B-4e |
57.3 | 76.7 | 60.3 | 36.2 | 62.6 | 50.1 | 85.7 | 1318.1 | 60.2 | 26.9 |
| MoE-LLaVA-1.8B×4-Top2 | 2.2B | 🤗LanguageBind/MoE-LLaVA-Qwen-1.8B-4e | PKU-YuanLab/MoE-LLaVA-Qwen-1.8B-4e |
56.7 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 1291.6 | 59.6 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 3.6B | 🤗LanguageBind/MoE-LLaVA-Phi2-2.7B-4e | PKU-YuanLab/MoE-LLaVA-Phi2-2.7B-4e |
61.1 | 77.6 | 61.4 | 43.9 | 68.5 | 51.4 | 86.3 | 1423.0 | 65.2 | 34.3 |
| MoE-LLaVA-1.6B×4-Top2-384 | 2.0B | 🤗LanguageBind/MoE-LLaVA-StableLM-1.6B-4e-384 | PKU-YuanLab/MoE-LLaVA-StableLM-1.6B-4e-384 |
60.0 | 78.6 | 61.5 | 40.5 | 63.9 | 54.3 | 85.9 | 1335.7 | 63.3 | 32.3 |
| MoE-LLaVA-2.7B×4-Top2-384 | 3.6B | 🤗LanguageBind/MoE-LLaVA-Phi2-2.7B-4e-384 | PKU-YuanLab/MoE-LLaVA-Phi2-2.7B-4e-384 |
62.9 | 79.9 | 62.6 | 43.7 | 70.3 | 57.0 | 85.7 | 1431.3 | 68.0 | 35.9 |
| LLaVA-1.5 | 7B | 🤗liuhaotian/llava-v1.5-7b | - | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 30.5 |
🚨 请注意 https://github.com/PKU-YuanGroup/MoE-LLaVA/issues/27。
Stage2模型
| 模型 | 检查点 |
|---|---|
| MoE-LLaVA-1.6B×4-Top2 | LanguageBind/MoE-LLaVA-StableLM-Stage2 |
| MoE-LLaVA-1.6B×4-Top2-384 | LanguageBind/MoE-LLaVA-StableLM-Stage2-384 |
| MoE-LLaVA-1.8B×4-Top2 | LanguageBind/MoE-LLaVA-Qwen-Stage2 |
| MoE-LLaVA-2.7B×4-Top2 | LanguageBind/MoE-LLaVA-Phi2-Stage2 |
| MoE-LLaVA-2.7B×4-Top2-384 | LanguageBind/MoE-LLaVA-Phi2-Stage2-384 |
预训练模型
| 模型 | 检查点 |
|---|---|
| MoE-LLaVA-1.6B×4-Top2 | LanguageBind/MoE-LLaVA-StableLM-Pretrain |
| MoE-LLaVA-1.6B×4-Top2-384 | LanguageBind/MoE-LLaVA-StableLM-384-Pretrain |
| MoE-LLaVA-1.8B×4-Top2 | LanguageBind/MoE-LLaVA-Qwen-Pretrain |
| MoE-LLaVA-2.7B×4-Top2 | LanguageBind/MoE-LLaVA-Phi2-Pretrain |
| MoE-LLaVA-2.7B×4-Top2-384 | LanguageBind/MoE-LLaVA-Phi2-384-Pretrain |
⚙️ 要求与安装
我们推荐以下要求:
- Python == 3.10
- Pytorch == 2.0.1
- CUDA版本 >= 11.7
- Transformers == 4.37.0
- Tokenizers==0.15.1
- 安装所需包:
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # 启用PEP 660支持
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# 以下是可选的。对于Qwen模型。
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 以下是可选的。安装它们可能会比较慢。
# pip install csrc/layer_norm
# 如果flash-attn版本高于2.1.1,则不需要以下操作。
# pip install csrc/rotary
[!警告]
🚨 我们发现使用flash attention2会导致性能下降。
🗝️ 训练与验证
训练与验证说明请参阅 TRAIN.md 和 EVAL.md。
💡 自定义你的MoE-LLaVA
自定义说明请参阅 CUSTOM.md。
😍 可视化
可视化说明请参阅 VISUALIZATION.md。
🤖 API
我们已将所有代码开源。 如果您想在本地加载该模型(例如 LanguageBind/MoE-LLaVA-Phi2-2.7B-4e),可以使用以下代码片段。
使用以下命令运行代码。
deepspeed --include localhost:0 predict.py
import torch
from PIL import Image
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e 或 LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed 是否支持 4bit 或 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen 或 stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(Image.open(image).convert('RGB'), return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
🙌 相关项目
- Video-LLaVA 该框架使模型能够高效利用统一的视觉标记。
- LanguageBind 一个开源的五模态语言检索框架。
👍 致谢
- LLaVA 我们在此基础上构建了代码库,它是一个高效的大规模语言和视觉助手。
🔒 许可证
- 本项目的大部分内容根据 LICENSE 文件中的 Apache 2.0 许可证发布。
- 该服务为研究预览版,仅供非商业用途,受 LLaMA 模型的 许可证、由 OpenAI 生成的数据的 使用条款以及 ShareGPT 的 隐私政策约束。如发现任何潜在违规行为,请与我们联系。
✏️ 引用
如果您在研究中发现我们的论文和代码有用,请考虑给个赞 :star: 和引用 :pencil:。
@article{lin2024moe,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Lin, Bin and Tang, Zhenyu and Ye, Yang and Cui, Jiaxi and Zhu, Bin and Jin, Peng and Zhang, Junwu and Ning, Munan and Yuan, Li},
journal={arXiv preprint arXiv:2401.15947},
year={2024}
}
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
✨ 星标历史

🤝 贡献者

版本历史
v1.0.02024/02/04常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。