Multi-Modality-Arena
Multi-Modality-Arena 是一个专为大型多模态模型打造的评估平台,被誉为多模态领域的“竞技场”。它借鉴了著名的 Chatbot Arena 模式,让用户能够上传图像并提出问题,在盲测环境下并排对比两个匿名视觉语言模型的回答质量,从而直观地判断哪个模型表现更优。
这一工具主要解决了当前多模态模型缺乏统一、公平且贴近真实场景的评测标准的痛点。传统的基准测试往往依赖静态数据集,而 Multi-Modality-Arena 通过引入人类偏好投票机制,提供了更动态、更全面的性能反馈。平台不仅支持 MiniGPT-4、LLaVA、BLIP-2 等主流开源模型,还涵盖了医疗垂直领域的 OmniMedVQA 评测以及包含 Google Bard 在内的 Tiny LVLM-eHub 基准测试,能够从视觉感知、推理、常识等多个维度系统性地衡量模型能力。
Multi-Modality-Arena 非常适合 AI 研究人员、算法开发者以及对多模态技术感兴趣的技术爱好者使用。研究人员可利用其丰富的数据集和排行榜追踪最新技术进展;开发者能借此验证自己模型的实战表现;普通用户也能轻松参与评测,体验不同模型的理解能力。其独特的亮点在于构建了开放的在线对战平台和详尽的领导力榜单(Leaderboard),让模型评估从单纯的分数比拼进化为基于真实交互的综合较量,极大地推动了多模态社区的透明化发展。
使用场景
某医疗 AI 研发团队正在为远程诊断系统筛选最精准的视觉语言模型,需要处理包含 X 光、CT 及病理切片等多模态医学影像的复杂问答任务。
没有 Multi-Modality-Arena 时
- 评估维度单一:团队只能依赖纯文本指标或简单的图像分类准确率,无法全面衡量模型在“视觉推理”和“医学常识”等深层能力上的表现。
- 对比效率低下:若要测试 MiniGPT-4、LLaVA 和 BLIP-2 等多个候选模型,需分别搭建独立环境并手动编写脚本,耗时数天且难以保证输入条件完全一致。
- 缺乏真实场景验证:离线测试集往往过于理想化,无法模拟医生在实际诊疗中提出的模糊或非标准化问题,导致模型上线后出现“幻觉”或误诊。
- 决策依据不足:面对不同模型在特定解剖区域(如肺部结节 vs. 骨骼骨折)的表现差异,缺乏统一的排行榜数据支持选型决策。
使用 Multi-Modality-Arena 后
- 全景能力画像:利用内置的 OmniMedVQA 基准,团队一键获得了模型在 12 种影像模态和 20+ 人体区域的细粒度评分,清晰识别出各模型的强项与短板。
- 并排竞技评测:通过匿名侧边栏对比功能,研究人员在同一界面同时输入相同的病理图片和问题,直观观察 InternVL 与 Bard 等模型的回答差异,将评估周期从数天缩短至几小时。
- 贴近实战的反馈:平台提供的“视觉幻觉”检测和人机对齐评估机制,帮助团队提前发现模型在描述病灶时的虚构问题,显著提升了系统的临床可靠性。
- 数据驱动选型:参考 LVLM Leaderboard 中针对医疗场景的权威排名,团队迅速锁定了在医学专用任务上得分最高的 InternVL 作为核心基座,降低了试错成本。
Multi-Modality-Arena 通过标准化的多模态竞技场机制,将原本碎片化、高成本的模型筛选过程转化为高效、可视化的数据决策流程,确保了医疗 AI 系统在复杂视觉任务中的卓越表现。
运行环境要求
- 未说明
必需 (根据 model_worker.py 的 --device 参数及多模态大模型特性推断,通常需 NVIDIA GPU),具体型号和显存大小未说明
未说明
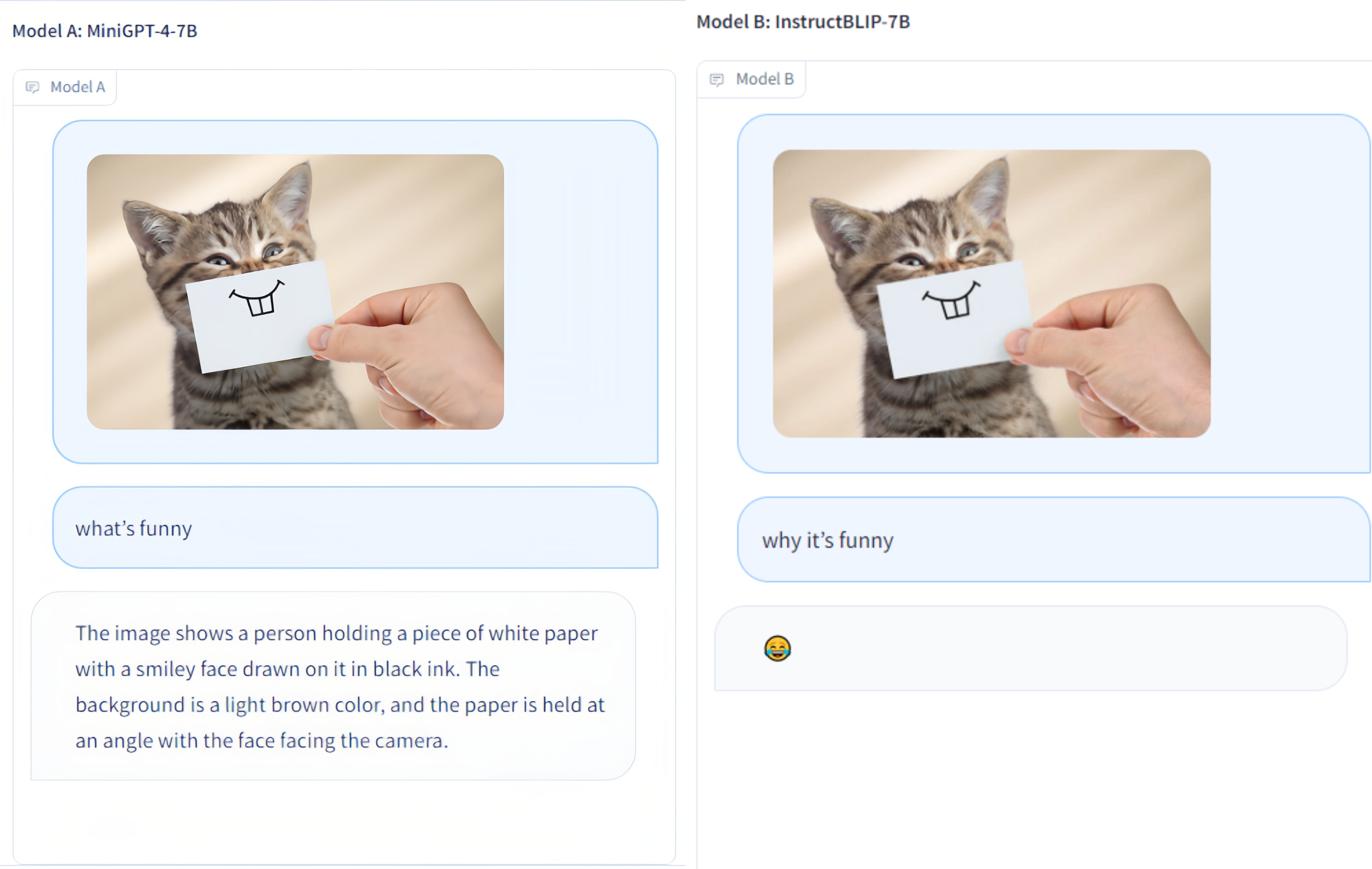
快速开始
多模态竞技场 🚀
![]()
多模态竞技场 是一个用于评估大型多模态模型的平台。仿照 Fastchat 的模式,两个匿名模型在视觉问答任务上进行并排比较。我们发布了 演示,并欢迎所有人参与这一评估活动。
![]()
![]()
![]()
 🔥🔥🔥
🔥🔥🔥
大型多模态模型的全面评估
OmniMedVQA:面向医学领域的全新大规模综合性评估基准
- OmniMedVQA 数据集:包含 118,010 张图像和 127,995 个问答对,涵盖 12 种不同的模态,并涉及超过 20 个人体解剖部位。该数据集可从 这里 下载。
- 12 模型:8 个通用领域的大规模视觉语言模型和 4 个医学专用的大规模视觉语言模型。
Tiny LVLM-eHub:与 Bard 的早期多模态实验
- 小规模数据集:每个数据集仅随机选取 50 个样本,即 42 个与文本相关的视觉基准测试,总计 2,100 个样本,便于使用。
- 更多模型:新增 4 个模型,共计 12 个模型,其中包括 Google Bard。
- ChatGPT 集成评估:相比之前的基于词语匹配的方法,与人工评估的一致性有所提高。
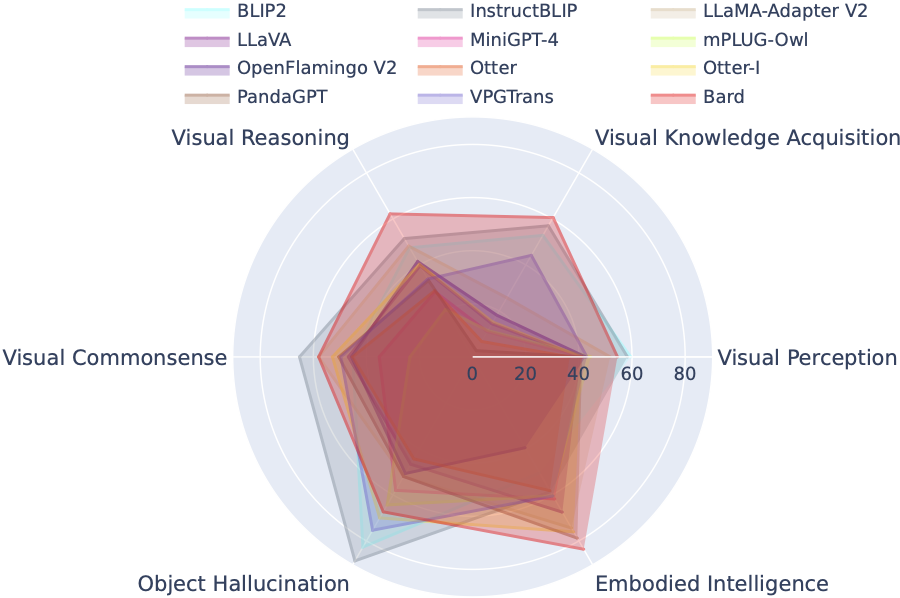
LVLM-eHub:大型视觉语言模型的评估基准 🚀
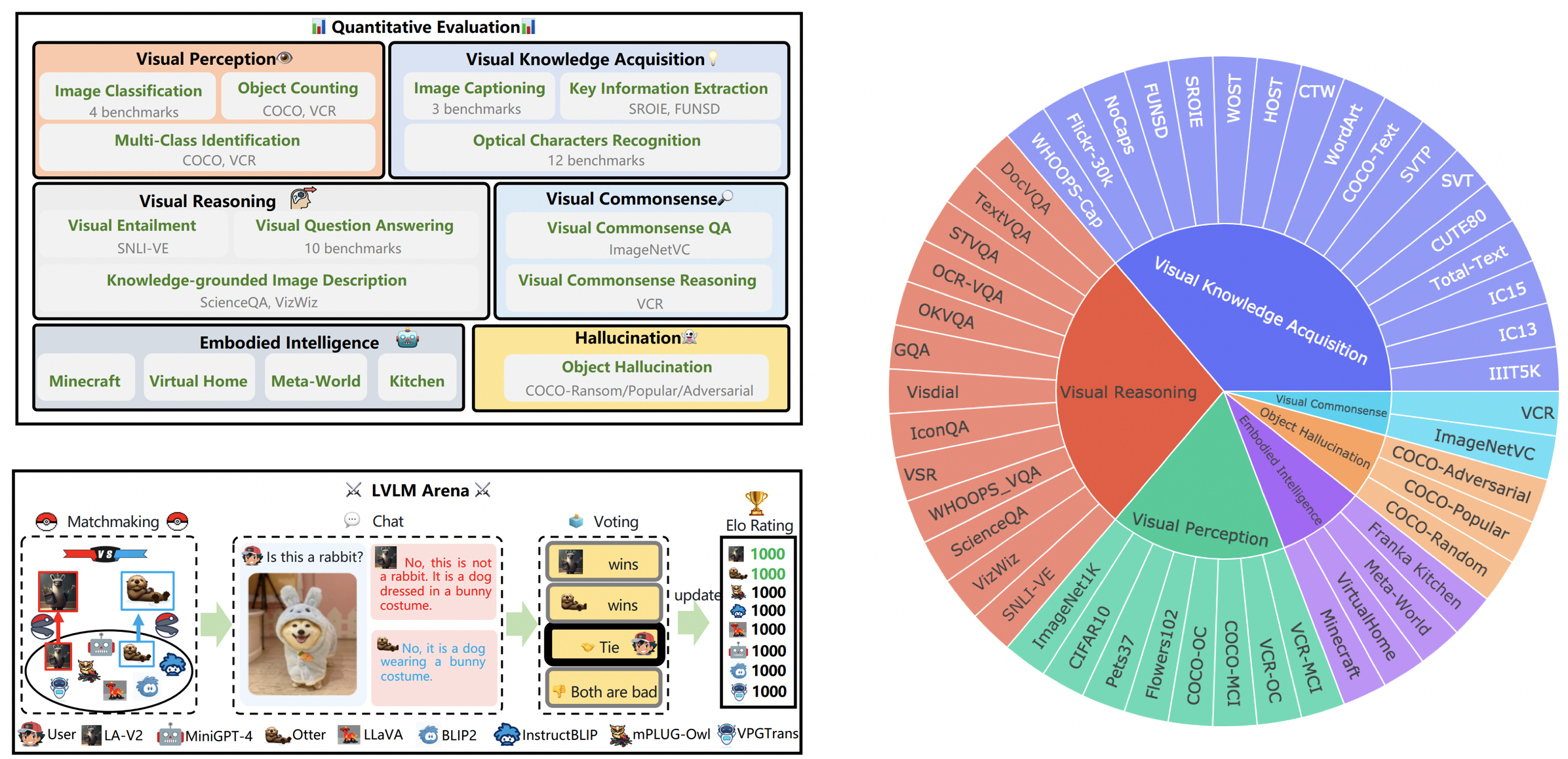
LVLM-eHub 是一个针对公开可用的大型多模态模型(LVLM)的综合性评估基准。它通过 47 个数据集和 1 个在线竞技场平台,从 6 个多模态能力类别对 $8$ 个 LVLM 进行了全面评估。
LVLM 排行榜
LVLM 排行榜系统地将 Tiny LVLM 评估中的数据集按照其特定的目标能力进行分类,包括视觉感知、视觉推理、视觉常识、视觉知识获取以及对象幻觉等。该排行榜还包括近期发布的模型,以增强其全面性。
| 排名 | 模型 | 版本 | 分数 |
|---|---|---|---|
| 🏅️ | InternVL | InternVL-Chat | 327.61 |
| 🥈 | InternLM-XComposer-VL | InternLM-XComposer-VL-7B | 322.51 |
| 🥉 | Bard | Bard | 319.59 |
| 4 | Qwen-VL-Chat | Qwen-VL-Chat | 316.81 |
| 5 | LLaVA-1.5 | Vicuna-7B | 307.17 |
| 6 | InstructBLIP | Vicuna-7B | 300.64 |
| 7 | InternLM-XComposer | InternLM-XComposer-7B | 288.89 |
| 8 | BLIP2 | FlanT5xl | 284.72 |
| 9 | BLIVA | Vicuna-7B | 284.17 |
| 10 | Lynx | Vicuna-7B | 279.24 |
| 11 | Cheetah | Vicuna-7B | 258.91 |
| 12 | LLaMA-Adapter-v2 | LLaMA-7B | 229.16 |
| 13 | VPGTrans | Vicuna-7B | 218.91 |
| 14 | Otter-Image | Otter-9B-LA-InContext | 216.43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211.98 |
| 16 | mPLUG-Owl | LLaMA-7B | 209.40 |
| 17 | LLaVA | Vicuna-7B | 200.93 |
| 18 | MiniGPT-4 | Vicuna-7B | 192.62 |
| 19 | Otter | Otter-9B | 180.87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | PandaGPT | Vicuna-7B | 174.25 |
| 22 | LaVIN | LLaMA-7B | 97.51 |
| 23 | MIC | FlanT5xl | 94.09 |
更新
- 🔥 2024年3月31日。我们发布了 OmniMedVQA,这是一个面向医学领域 LVLM 的大规模综合性评估基准。同时,我们评估了 8 个通用领域的大规模视觉语言模型和 4 个医学专用的大规模视觉语言模型。更多详情请访问 MedicalEval。
- 🔥 2023年10月16日。我们提出了基于 LVLM-eHub 的能力级别数据集划分,并补充纳入了八款近期发布的新模型。如需访问数据集划分、评估代码、模型推理结果及综合性能表格,请前往 tiny_lvlm_evaluation ✅。
- 2023年8月8日。我们发布了 [Tiny LVLM-eHub]。评估源代码和模型推理结果已在 tiny_lvlm_evaluation 中开源。
- 2023年6月15日。我们发布了 [LVLM-eHub],这是一个用于评估大型视觉语言模型的基准。相关代码即将发布。
- 2023年6月8日。感谢 VPGTrans 的作者张博士提出的修正意见。VPGTrans 的主要作者来自新加坡国立大学和清华大学。我们在重新实现 VPGTrans 时曾遇到一些小问题,但后来发现其实际性能更好。如需了解更多关于其他模型作者的信息,请通过 邮箱 与我联系讨论。同时,请关注我们的模型排名列表,那里将提供更准确的结果。
- 2023年5月22日。感谢 mPLUG-Owl 的作者叶博士提出的修正意见。我们已修复了在实现 mPLIG-Owl 时的一些小问题。
支持的多模态模型
目前参与随机对抗赛的模型如下:
- KAUST/MiniGPT-4
- Salesforce/BLIP2
- Salesforce/InstructBLIP
- DAMO Academy/mPLUG-Owl
- NTU/Otter
- 威斯康星大学麦迪逊分校/LLaVA
- 上海人工智能实验室/llama_adapter_v2
- 新加坡国立大学/VPGTrans
关于这些模型的更多详细信息,请参阅 ./model_detail/.model.jpg。我们将会尽力安排计算资源,以在竞技场中支持更多多模态模型。
微信联系我们
如果您对我们的VLarena平台有任何兴趣,欢迎加入我们的微信群。

安装说明
- 创建Conda环境
conda create -n arena python=3.10
conda activate arena
- 安装运行控制器和服务器所需的包
pip install numpy gradio uvicorn fastapi
- 由于每个模型可能需要不同版本的Python包,我们建议根据各自的GitHub仓库为每个模型创建专用的环境。
启动演示
要通过Web界面提供服务,您需要三个主要组件:与用户交互的Web服务器、承载两个或多个模型的模型工作节点,以及用于协调Web服务器和模型工作节点的控制器。
请在终端中按照以下步骤操作:
启动控制器
python controller.py
该控制器负责管理分布式的工作节点。
启动模型工作节点
python model_worker.py --model-name SELECTED_MODEL --device TARGET_DEVICE
等待进程完成模型加载,直到看到“Uvicorn running on ...”的提示。此时,模型工作节点将自动注册到控制器上。对于每个模型工作节点,您需要指定模型名称和目标设备。
启动Gradio Web服务器
python server_demo.py
这是用户与模型交互的界面。
按照上述步骤操作后,您就可以通过Web界面使用您的模型了。现在您可以打开浏览器,与模型进行对话。如果模型未显示出来,请尝试重启Gradio Web服务器。
贡献指南
我们非常重视所有旨在提升评估质量的贡献。本节分为两个部分:“LVLM评估贡献”和“LVLM竞技场贡献”。
参与LVLM评估
您可以在LVLM_evaluation文件夹中找到最新版本的评估代码。该目录包含完整的评估代码及所需的数据集。如果您希望参与评估工作,请随时通过电子邮件xupeng@pjlab.org.cn与我们分享您的评估结果或模型推理API。
参与LVLM竞技场
我们感谢您有意将自己的模型接入我们的LVLM竞技场!如需将您的模型整合进竞技场,请准备一个如下所示的模型测试器:
class ModelTester:
def __init__(self, device=None) -> None:
# TODO: 初始化模型及必要的预处理流程
def move_to_device(self, device) -> None:
# TODO: 此函数用于在CPU和GPU之间切换模型(可选)
def generate(self, image, question) -> str:
# TODO: 模型推理代码
此外,我们也接受在线模型推理链接,例如由Gradio等平台提供的链接。我们衷心感谢您的贡献。
致谢
我们衷心感谢ChatBot Arena团队及其论文《Judging LLM-as-a-judge》(arXiv:2306.05685),他们的工作对我们开展LVLM评估提供了重要启发。同时,我们也向LVLM的提供者们致以诚挚的谢意,正是他们的宝贵贡献推动了大型视觉语言模型的发展与进步。最后,感谢为我们LVLM-eHub所用数据集提供方的支持。
使用条款
本项目仅为非商业用途的实验性研究工具。其安全防护措施有限,可能会生成不当内容。严禁将其用于任何非法、有害、暴力、种族歧视或色情相关的行为。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。