audio-flamingo
Audio Flamingo 是由英伟达推出的一系列先进音频理解语言模型,旨在让 AI 像人类一样“听懂”声音。它不仅能够识别环境音和语音,更在音乐理解领域取得了突破性进展,特别是其最新分支 Music Flamingo,能深入分析歌曲的和声、结构、音色乃至文化背景。
传统模型往往难以处理长段音频或缺乏深层推理能力,而 Audio Flamingo 有效解决了这一痛点。它具备强大的长音频理解能力,支持对整首歌曲进行多步骤的逻辑推理,并能通过少样本学习快速适应新任务。无论是复杂的乐器独奏还是跨文化的长篇音乐作品,它都能生成富含理论知识的描述并回答专业问题。
这套工具非常适合人工智能研究人员、音频算法开发者以及音乐科技领域的创新者使用。研究人员可利用其开源架构探索多模态学习的新边界;开发者能基于预训练模型构建智能音乐助手或自动标注系统;音乐教育工作者也可借助其专业的分析能力辅助教学。
技术亮点方面,Audio Flamingo 采用了独特的“思维链”训练策略,结合强化学习与自定义奖励机制,显著提升了模型的推理精度。作为完全开源的项目,它提供了从模型权重到专用数据集的全套资源,推动了音频智能技术的开放与普及。
使用场景
某数字音乐平台的内容运营团队需要每天处理数千首新上传的独立音乐人作品,以便自动生成包含风格、乐器构成及文化背景的元数据标签,从而优化推荐算法。
没有 audio-flamingo 时
- 人工标注成本极高:依赖音乐编辑逐首试听并手动填写标签,面对海量曲库时效率低下,导致新歌上架延迟严重。
- 深层乐理信息缺失:传统音频分类模型仅能识别“流行”或“摇滚”等宽泛流派,无法解析和弦走向、调式结构或具体音色细节。
- 长音频理解能力弱:现有工具难以处理完整歌曲长度的上下文,往往只分析前 30 秒片段,导致对歌曲后半段变奏或复杂编曲结构的描述错误。
- 缺乏推理与解释:系统无法回答“为什么这首歌具有爵士风味”这类需要逻辑推理的问题,只能输出冰冷的分类代码,不利于用户交互。
使用 audio-flamingo 后
- 自动化高效处理:audio-flamingo 能够批量自动聆听全曲,瞬间生成包含乐器、风格及情感色彩的详细自然语言描述,将上架周期从数天缩短至分钟级。
- 专业乐理深度解析:凭借 Music Flamingo 的专业训练,它能精准识别复杂的和声进行、节奏形态及文化背景,输出媲美专家的理论分析文案。
- 全曲上下文掌控:依托其长音频理解能力,audio-flamingo 能通盘分析整首歌曲的结构变化,准确捕捉桥段、尾奏等长程依赖关系,不再遗漏关键细节。
- 具备链式推理能力:面对复杂查询,audio-flamingo 能通过思维链(Chain-of-Thought)逐步推导,不仅给出结论,还能像音乐评论家一样解释判断依据,极大丰富了互动体验。
audio-flamingo 通过将深奥的音频信号转化为可推理的自然语言,彻底解决了音乐内容规模化深度理解的难题,让机器真正“听懂”了音乐。
运行环境要求
- 未说明
需要 NVIDIA GPU(基于 LLaVA 架构及 Whisper 编码器),具体显存需求未说明(参考 7B/3B 模型通常需 16GB-24GB+),CUDA 版本未说明
未说明

快速开始

Audio Flamingo:一系列先进的音频理解语言模型
概述
在这个仓库中,我们推出了Audio Flamingo系列先进的音频理解语言模型:
- Audio Flamingo:一种具有少样本学习和对话能力的新型音频语言模型(ICML 2024)
- Audio Flamingo 2:一种具备长音频理解和专家推理能力的音频-语言模型(ICML 2025)
- Audio Flamingo 3:通过完全开放的大规模音频语言模型推进音频智能(NeurIPS 2025,亮点论文)
- Music Flamingo:在音频语言模型中扩展音乐理解能力(arXiv)
Music Flamingo(arXiv)

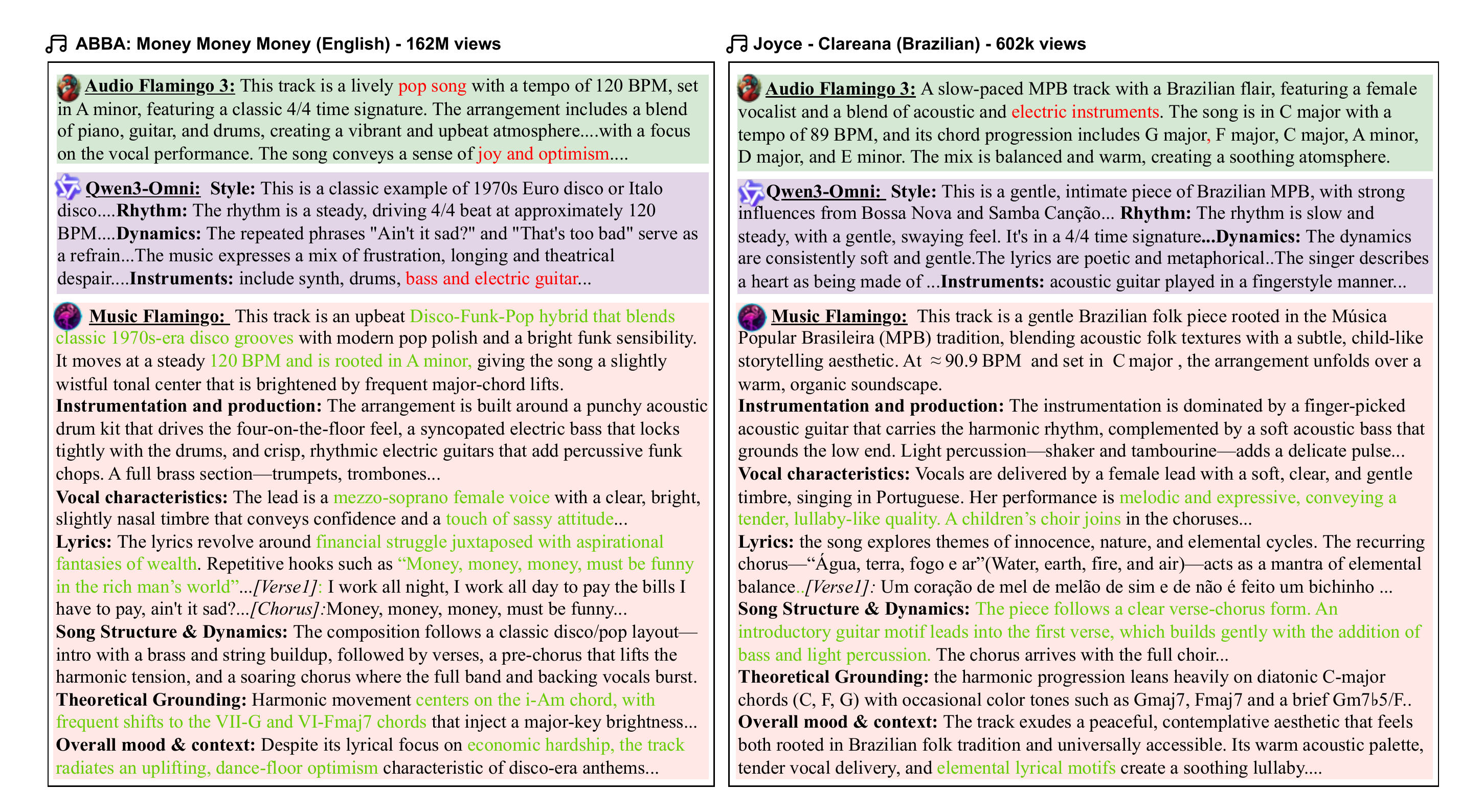
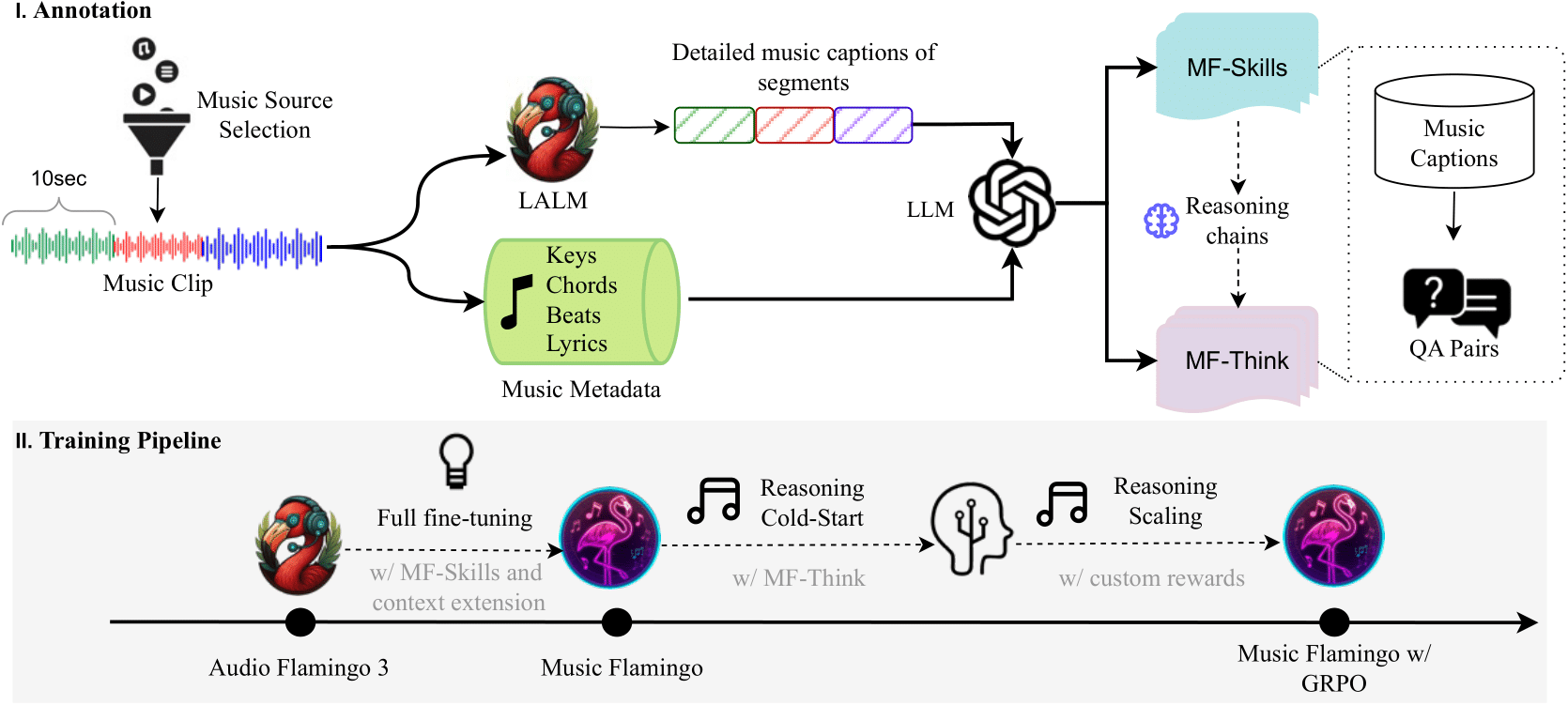
Music Flamingo(MF)是一款完全开放、最先进的大型音频-语言模型(LALM),基于Audio Flamingo 3的核心架构,旨在推动基础音频模型中的音乐(包括歌曲)理解能力。MF汇集了以下创新:
- 对歌曲和纯音乐的深度理解。
- 丰富且具备乐理知识的字幕与问答功能(和声、结构、音色、歌词、文化背景等)。
- 以推理为核心的训练方式,结合思维链与自定义奖励机制的强化学习,实现逐步推理。
- 针对全长、多文化背景的音频进行长篇幅歌曲推理(扩展上下文)。
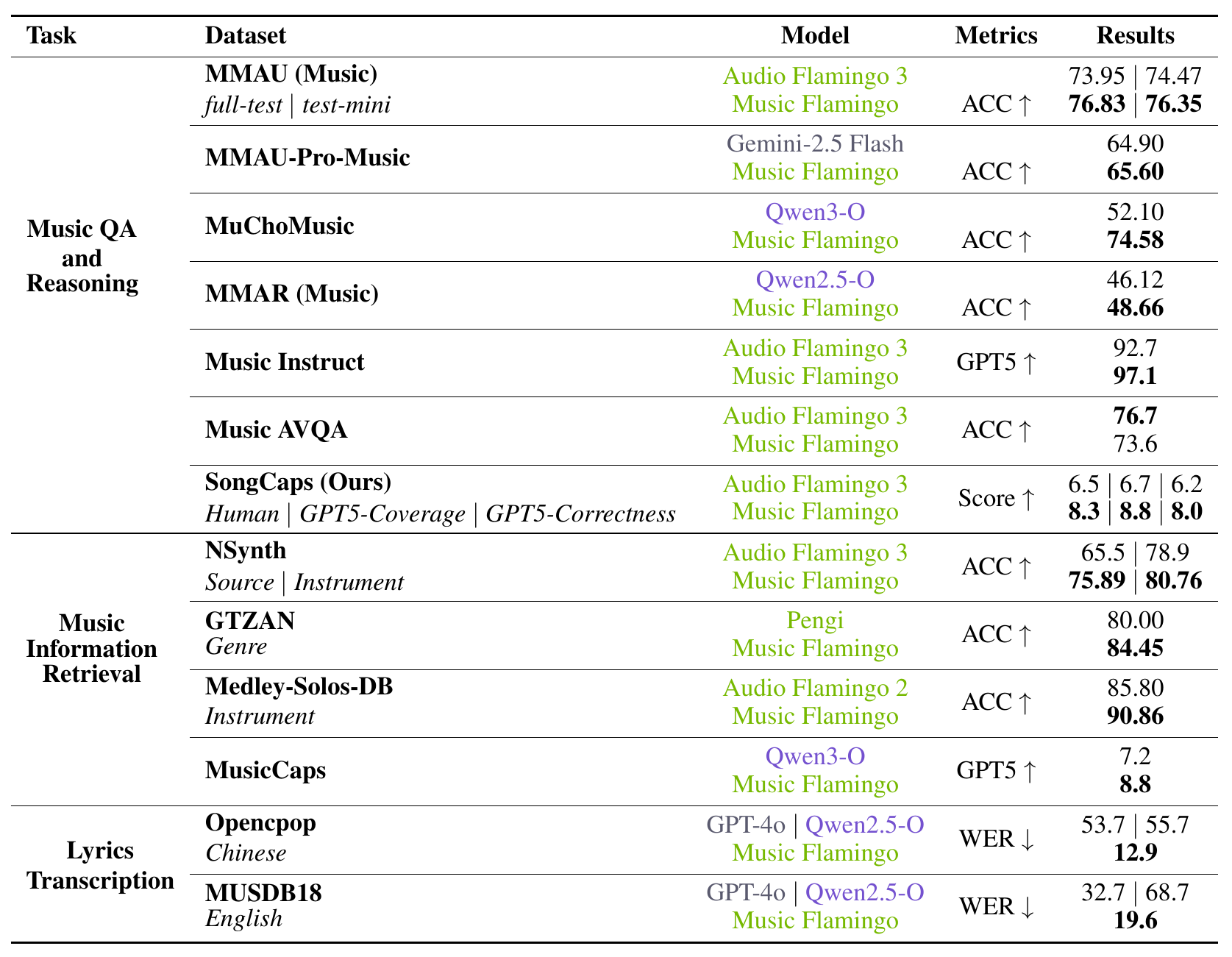
大量评估证实了Music Flamingo的有效性,在超过10项公开的音乐理解和推理任务上树立了新的基准。
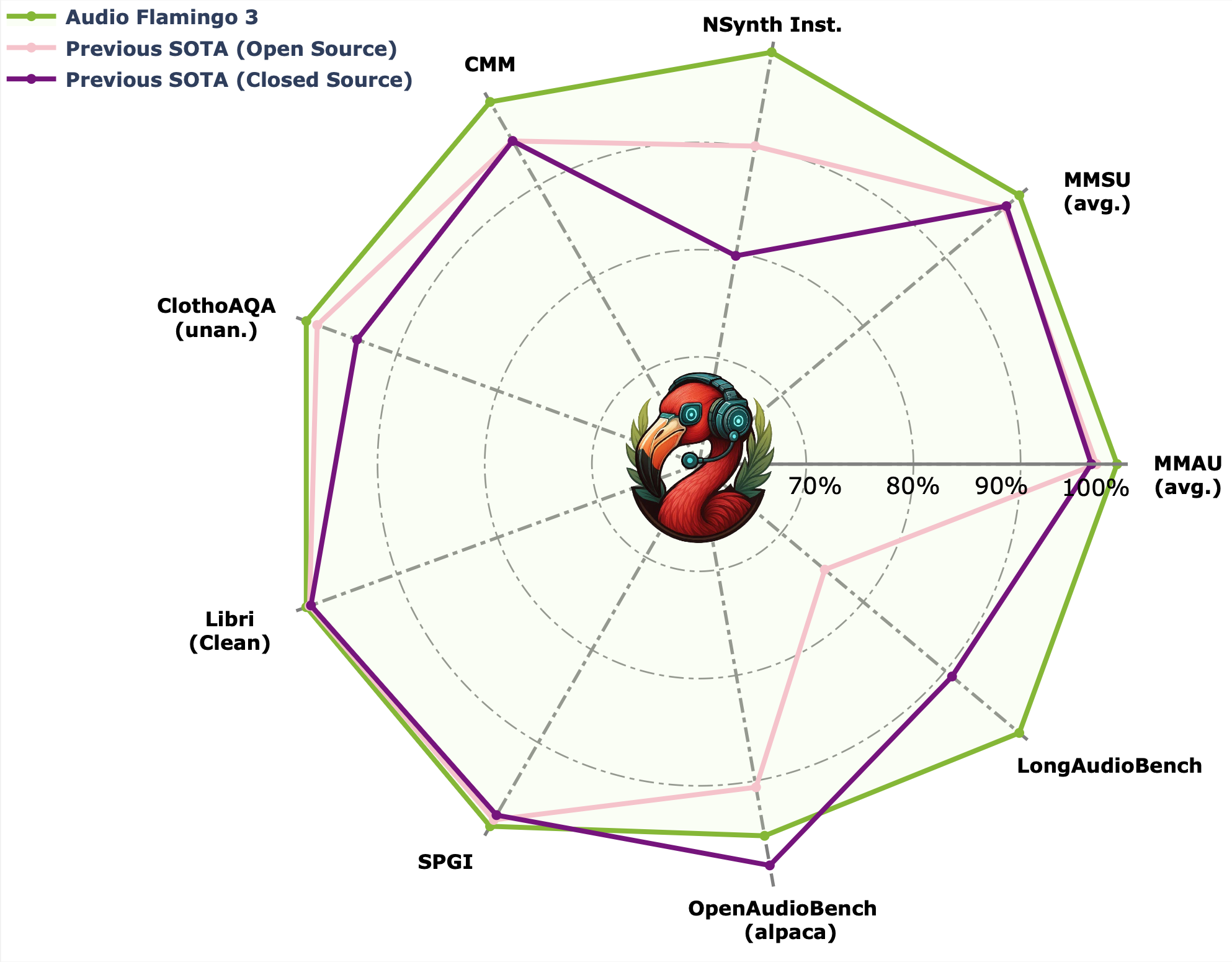
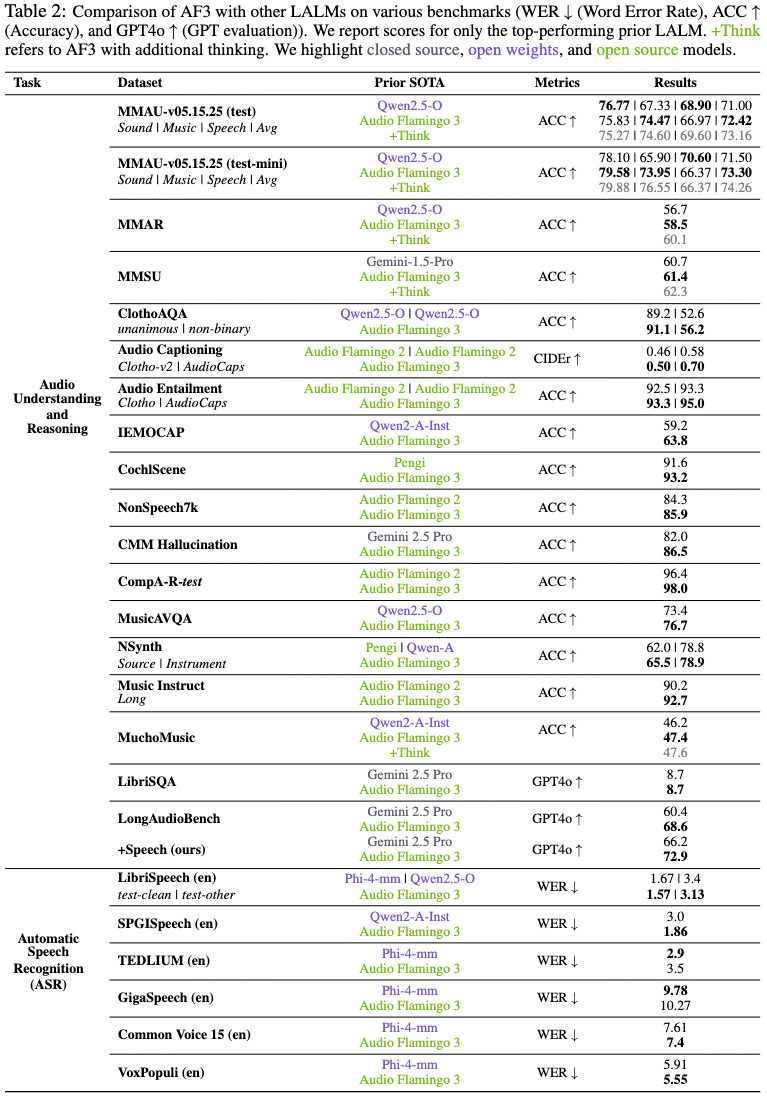
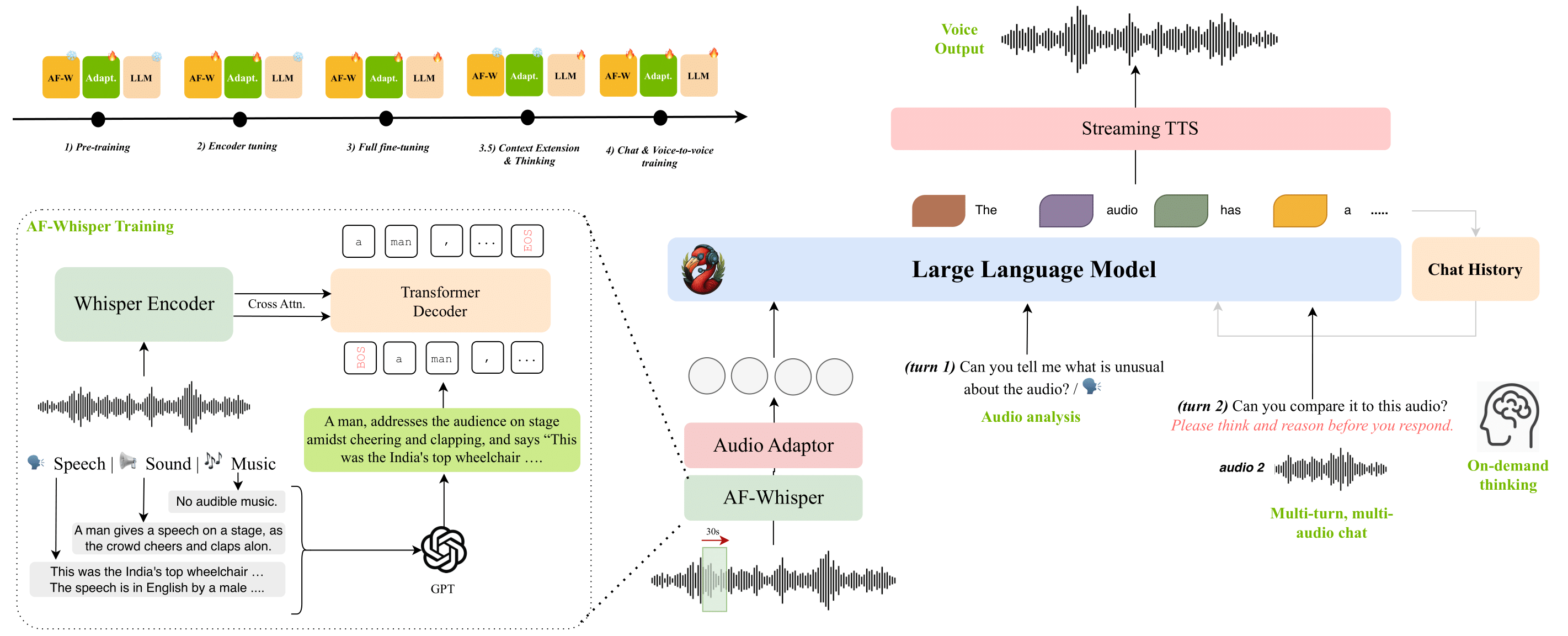
Audio Flamingo 3(NeurIPS 2025 Spotlight)
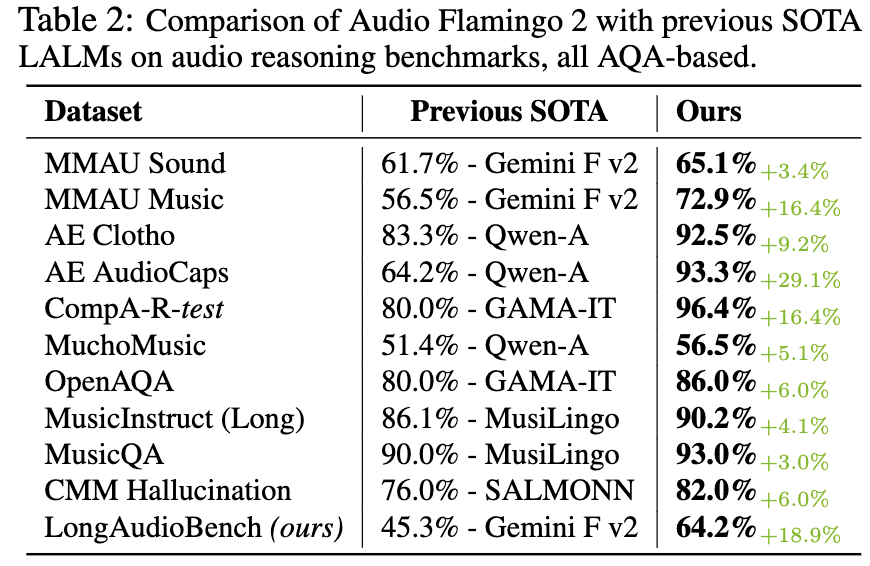
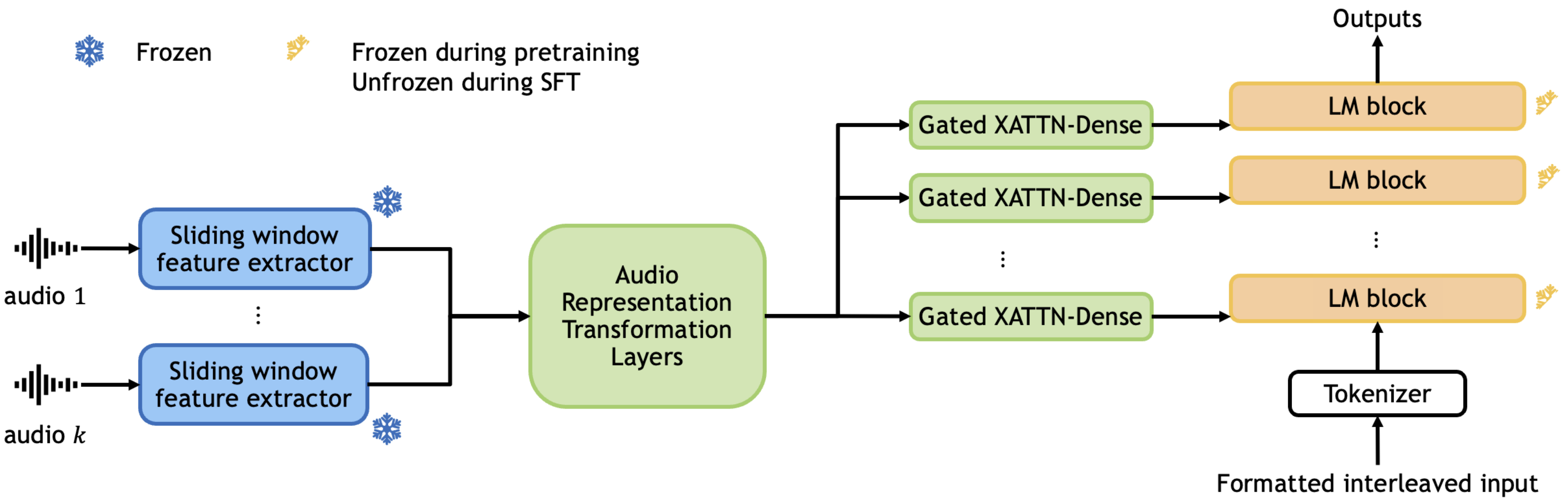
Audio Flamingo 3是我们最新的模型,基于7B参数的语言模型和LLaVA架构。我们以Whisper为基础,训练了统一的AF-Whisper音频编码器,使其能够处理超越语音识别的理解任务。我们在Audio Flamingo 3中加入了与语音相关的任务,并将训练数据集扩大到约5000万对音频-文本数据。因此,Audio Flamingo 3能够同时处理音频中的三种模态:声音、音乐和语音。它在多项理解和推理基准测试中,均优于此前的SOTA模型,包括GAMA、Audio Flamingo、Audio Flamingo 2、Qwen-Audio、Qwen2-Audio、Qwen2.5-Omni、LTU、LTU-AS、SALMONN、AudioGPT、Gemini Flash v2以及Gemini Pro v1.5。
Audio Flamingo 3可以接受长达10分钟的音频输入,并配备流式TTS模块(AF3-Chat),用于输出语音。
音频火烈鸟 Sound-CoT(技术报告)
音频火烈鸟 Sound-CoT 在思维链(CoT)推理能力方面有了显著提升。我们基于音频火烈鸟 2 训练的 3B 参数微调模型,在推理基准测试中可与多个 7B 参数的推理基线相媲美。
我们推出了 AF-Reasoning-Eval,这是一个专注于常识推理以及在密切相关选项间进行区分能力的声音推理基准测试。此外,我们还发布了 AF-CoT-Train 数据集,其中包含约 100 万个 CoT 推理轨迹,旨在推动音频理解领域的进步。
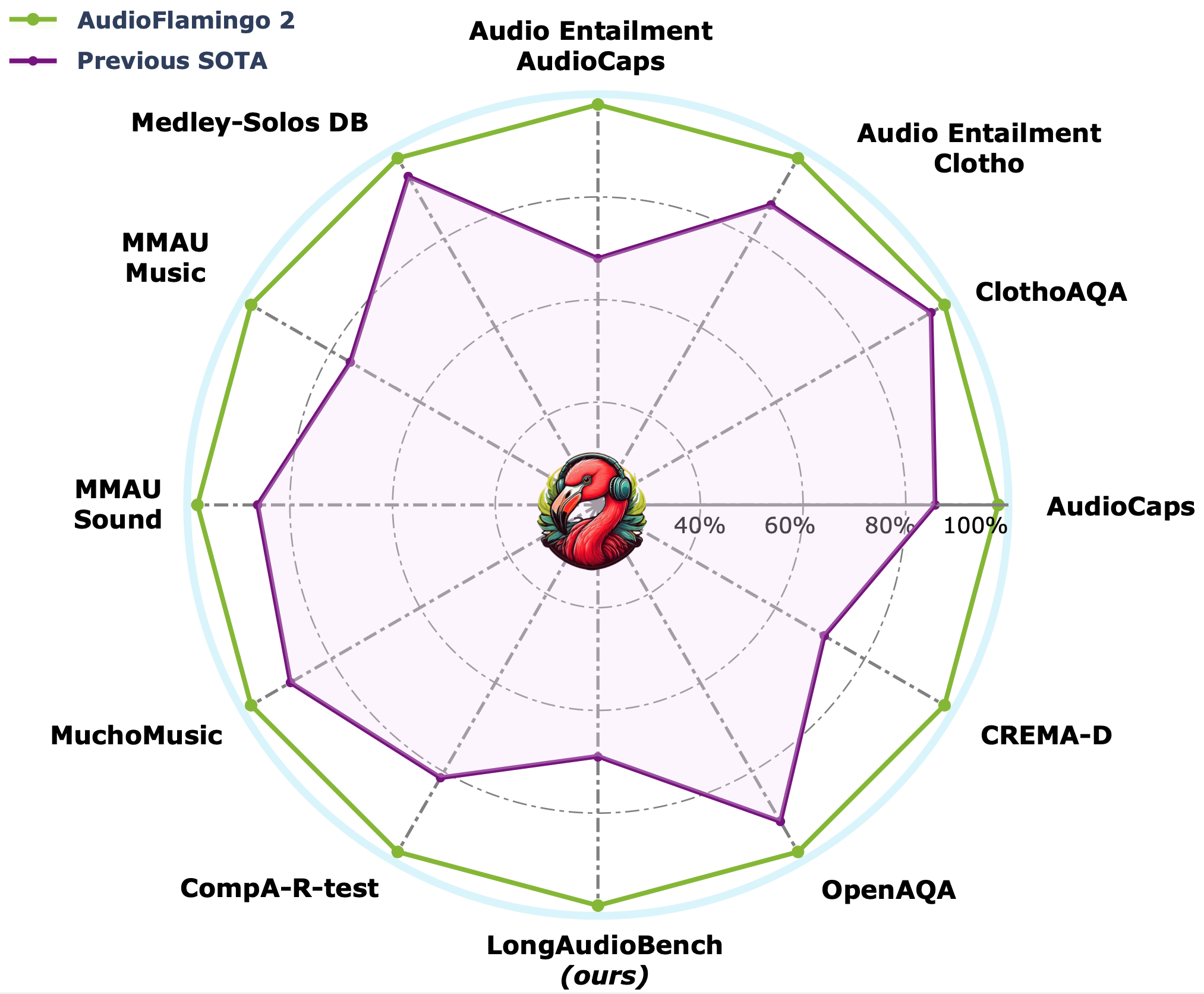
音频火烈鸟 2(ICML 2025)
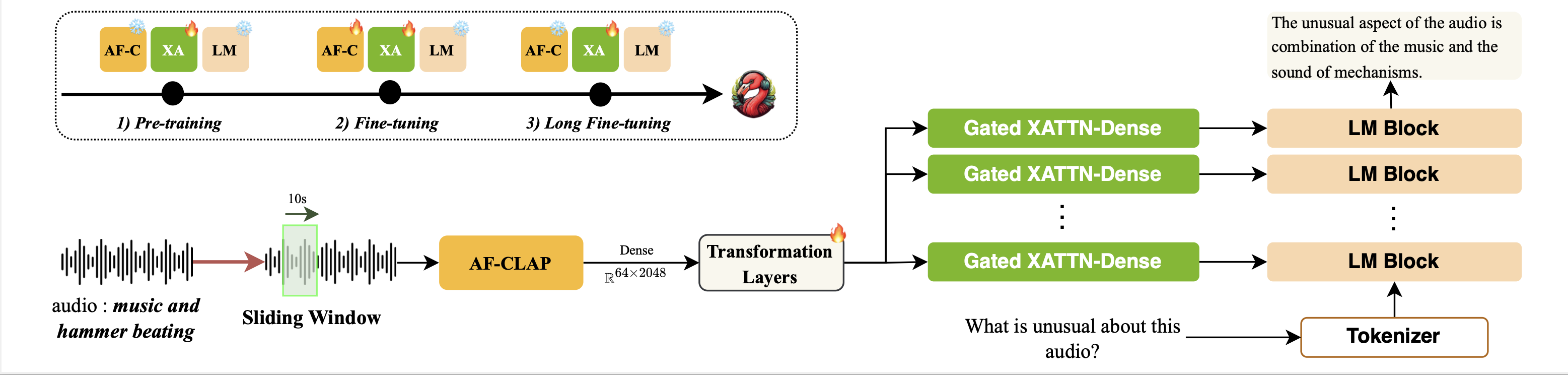
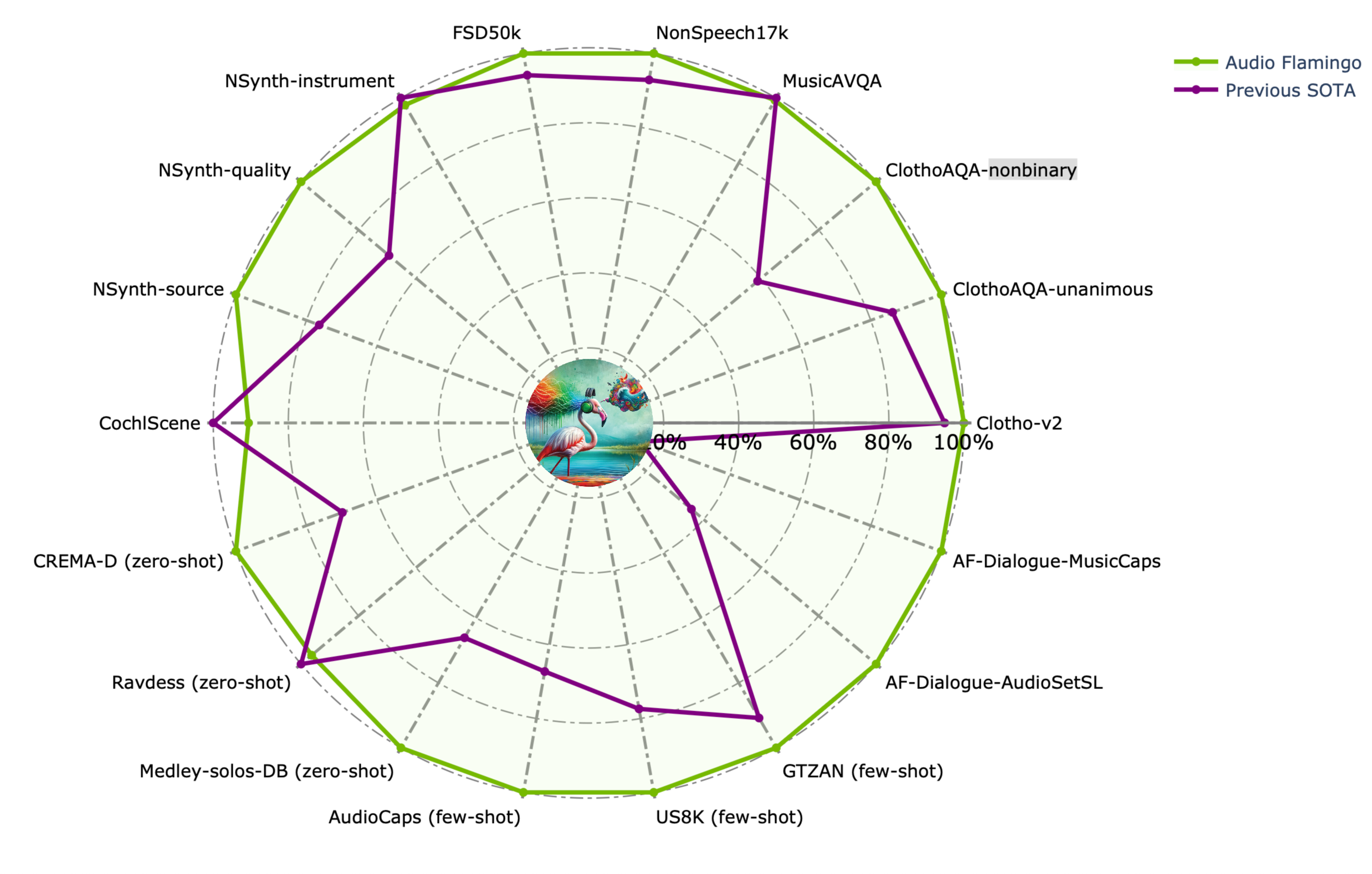
音频火烈鸟 2 在多个方面对原版音频火烈鸟进行了显著改进。首先,我们重新训练了一个性能更优的 CLAP 模型,其文本理解能力更强。其次,我们将训练数据集扩展至约 1000 万对音视频-文本配对,重点覆盖多项理解技能(AudioSkills)以及对长音频的理解(LongAudio)。第三,我们仔细分析了不同的训练方案和课程设置,最终确定了一种三阶段的训练策略,效果最佳。音频火烈鸟 2 基于一个 3B 参数的语言模型,在字幕生成、分类和问答等单项及混合音频理解任务的多个基准测试中均取得了当前最优成绩。此外,它还能理解长达 5 分钟的长音频。
音频火烈鸟(ICML 2024)
音频火烈鸟是我们首个基于 Flamingo 架构的音视频语言模型。它基于一个 1.3B 参数的语言模型,具备上下文少样本学习和多轮对话能力(有关对话数据的详细信息,请参阅 Audio Dialogues)。我们精心构建了约 590 万对音视频-文本配对用于训练该模型。它在字幕生成、分类和问答等零样本、少样本及分布内任务的多个基准测试中均取得了当前最优成绩。
代码结构
每个分支都包含用于训练和推理 Audio Flamingo 的独立代码。
许可证
- 本仓库中的代码采用 MIT 许可证。
- 检查点仅限非商业用途(参见 NVIDIA OneWay 非商业许可)。它们还受到其他限制(参见各分支中的
README和incl_licenses)。 - 注意:Audio Flamingo 基于 OPT-IML 构建,受 OPT-IML 许可证约束。
- 注意:Audio Flamingo 2 和 Audio Flamingo 3 基于 Qwen-2.5 构建。Qwen 受 Qwen 研究许可协议约束,版权归阿里云所有,保留所有权利。
引用
- Audio Flamingo
@inproceedings{kong2024audio,
title={Audio Flamingo: 一种具有少样本学习和对话能力的新型音频语言模型},
author={Kong, Zhifeng 和 Goel, Arushi 和 Badlani, Rohan 和 Ping, Wei 和 Valle, Rafael 和 Catanzaro, Bryan},
booktitle={国际机器学习大会},
pages={25125--25148},
year={2024},
organization={PMLR}
}
- Audio Flamingo 2
@inproceedings{
ghosh2025audio,
title={Audio Flamingo 2:一种具备长音频理解与专家推理能力的音频语言模型},
author={Ghosh, Sreyan 和 Kong, Zhifeng 和 Kumar, Sonal 和 Sakshi, S 和 Kim, Jaehyeon 和 Ping, Wei 和 Valle, Rafael 和 Manocha, Dinesh 和 Catanzaro, Bryan},
booktitle={第四十二届国际机器学习大会},
year={2025},
url={https://openreview.net/forum?id=xWu5qpDK6U}
}
- Audio Flamingo 3
@inproceedings{
ghosh2025audio,
title={Audio Flamingo 3:通过完全开放的大规模音频语言模型推进音频智能},
author={Sreyan Ghosh 和 Arushi Goel 和 Jaehyeon Kim 和 Sonal Kumar 和 Zhifeng Kong 和 Sang-gil Lee 和 Chao-Han Huck Yang 和 Ramani Duraiswami 和 Dinesh Manocha 和 Rafael Valle 和 Bryan Catanzaro},
booktitle={第三十九届神经信息处理系统年度会议},
year={2025},
url={https://openreview.net/forum?id=FjByDpDVIO}
}
- Audio Flamingo Sound-CoT
@article{kong2025audio,
title={Audio Flamingo Sound-CoT 技术报告:改进声音理解中的思维链推理},
author={Kong, Zhifeng 和 Goel, Arushi 和 Santos, Joao Felipe 和 Ghosh, Sreyan 和 Valle, Rafael 和 Ping, Wei 和 Catanzaro, Bryan},
journal={arXiv 预印本 arXiv:2508.11818},
year={2025}
}
- Music Flamingo
@article{ghosh2025music,
title={Music Flamingo:在音频语言模型中扩展音乐理解能力},
author={Ghosh, Sreyan 和 Goel, Arushi 和 Koroshinadze, Lasha 和 Lee, Sang-gil 和 Kong, Zhifeng 和 Santos, Joao Felipe 和 Duraiswami, Ramani 和 Manocha, Dinesh 和 Ping, Wei 和 Shoeybi, Mohammad 和 Catanzaro, Bryan},
journal={arXiv 预印本 arXiv},
year={2025}
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。