LLMsPracticalGuide
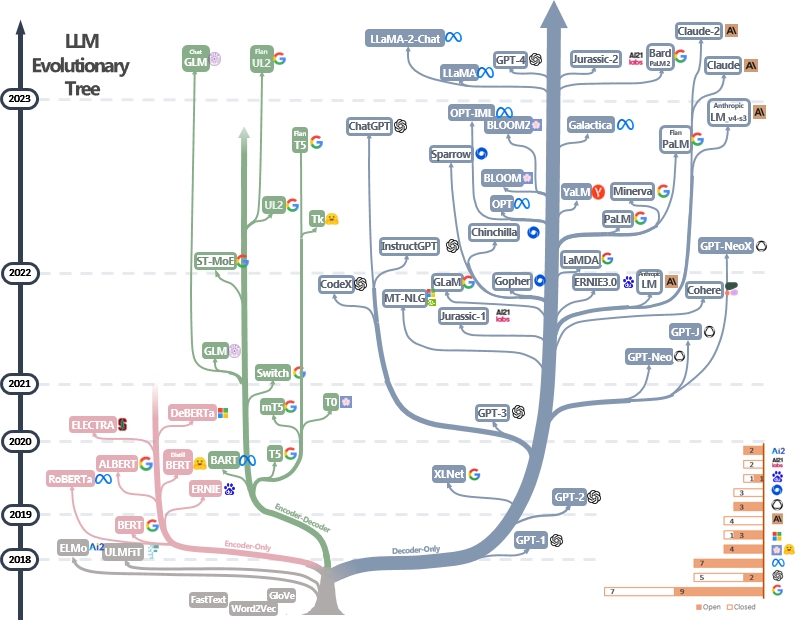
LLMsPracticalGuide 是一份精心整理的大语言模型(LLM)实战指南资源库,旨在帮助从业者 navigating 庞大且快速演进的 LLM 领域。它基于权威综述论文《Harnessing the Power of LLMs in Practice》构建,不仅收录了丰富的学习资源、代码示例和学术论文,还独家绘制了一张“大语言模型演化树”,清晰梳理了从 BERT 到 GPT 等主流模型的发展脉络与技术流派。
面对大模型技术更新快、应用门槛高、许可协议复杂等痛点,LLMsPracticalGuide 提供了系统化的解决方案。它将内容划分为模型架构、数据策略(预训练/微调/测试数据)、NLP 任务应用及效率优化等模块,并特别增加了模型商用与科研的使用限制说明,帮助用户规避法律与合规风险。
这份资源非常适合 AI 开发者、研究人员以及希望将大模型落地到生产环境的技术团队。无论是想深入了解模型原理,还是寻找特定任务的实现方案,亦或是需要确认模型的授权范围,都能在这里找到实用的指引。通过结构化的知识梳理和持续的社区更新,LLMsPracticalGuide 让大模型的学习与应用变得更加直观高效。
使用场景
某初创公司的算法团队正计划为电商客服系统选型并微调一个大语言模型,以处理复杂的售后咨询。
没有 LLMsPracticalGuide 时
- 模型选型迷茫:面对数百个开源模型,团队难以理清 BERT 式与 GPT 式架构的演进脉络,无法快速锁定适合生成任务的基座模型。
- 合规风险隐蔽:在缺乏明确指引的情况下,容易忽略模型的商用许可限制,可能导致后续产品上线面临法律纠纷。
- 数据准备低效:不清楚不同任务(如知识密集型 vs 传统 NLU)对预训练和微调数据的具体要求,导致数据清洗方向错误,浪费算力资源。
- 技术调研碎片化:需要花费数天时间在 arXiv、博客和论坛间拼凑信息,难以形成系统化的落地方案,严重拖慢项目进度。
使用 LLMsPracticalGuide 后
- 路径清晰可视:通过直观的"LLM 进化树”,团队迅速定位到适合对话生成的 Decoder-only 模型家族,大幅缩短选型决策时间。
- 授权一目了然:直接查阅工具整理的“使用与限制”章节,快速筛选出支持商业闭源部署的模型,从源头规避合规隐患。
- 数据策略精准:参考针对特定 NLP 任务的实践指南,团队明确了构建高质量微调数据集的标准,显著提升了模型在售后场景的表现。
- 资源一站获取:依托基于综述论文整理的结构化资源库,团队在几小时内就完成了从理论调研到工程落地的完整路径规划。
LLMsPracticalGuide 将碎片化的大模型知识转化为可执行的导航图,帮助开发者在纷繁的技术浪潮中精准避坑、高效落地。
运行环境要求
快速开始
大型语言模型实用指南
这是一份精心整理(仍在持续更新)的大型语言模型实用指南资源列表。该列表基于我们的综述论文:《在实践中释放大型语言模型的力量:ChatGPT及之后的综述》(arXiv:2304.13712),以及@xinyadu 的贡献。这篇综述部分参考了这篇博客的后半部分内容:Blog。我们还构建了一棵现代大型语言模型的演化树,以追溯近年来语言模型的发展历程,并重点介绍了几款最为知名的模型。
这些资源旨在帮助从业者更好地理解大型语言模型及其在自然语言处理(NLP)领域的广泛应用。此外,我们还根据模型和数据的许可信息,列出了它们的使用限制。
如果您觉得本仓库中的任何资源对您有所帮助,请随时使用它们(别忘了引用我们的论文哦!😃)。我们也欢迎通过 Pull Request 来不断完善这张图!
@article{yang2023harnessing,
title={Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond},
author={Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu},
year={2023},
eprint={2304.13712},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
最新消息💥
- 我们新增了使用与限制部分。
- 我们使用 PowerPoint 绘制了图表,并发布了源文件 pptx,用于生成 GIF 动画图。[2023年4月27日]
- 我们发布了静态版本的源文件 pptx,并用静态版本替换了仓库中的图片。[2023年4月29日]
- 在图表中添加了 AlexaTM、UniLM 和 UniLMv2,并修正了 Tk 的标志。[2023年4月29日]
- 新增了使用与限制(针对商业和研究用途)部分。特别感谢 Dr. Du 的贡献。[2023年5月8日]
其他大型语言模型实用指南
- 为什么所有公开的 GPT-3 复现都失败了?我们在哪些任务中应该使用 GPT-3.5/ChatGPT? 2023年,博客
- 构建用于生产的大型语言模型应用,2023年,博客
- 以数据为中心的人工智能,2023年,仓库/博客/论文
目录
模型实用指南
BERT 类语言模型:编码器-解码器或仅编码器
- BERT BERT:面向语言理解的深度双向 Transformer 预训练,2018年,论文
- RoBERTa RoBERTa:一种鲁棒优化的 BERT 预训练方法,2019年,论文
- DistilBERT DistilBERT,BERT 的蒸馏版:更小、更快、更便宜、更轻量,2019年,论文
- ALBERT ALBERT:用于自监督语言表示学习的精简版 BERT,2019年,论文
- UniLM 统一语言模型预训练:用于自然语言理解和生成,2019年,论文
- ELECTRA ELECTRA:将文本编码器作为判别器而非生成器进行预训练,2020年,论文
- T5 “探索迁移学习的极限:一种统一的文本到文本 Transformer”。Colin Raffel 等人 JMLR 2019。论文
- GLM “GLM-130B:一个开放的双语预训练模型”。2022年,论文
- AlexaTM “AlexaTM 20B:利用大规模多语言 Seq2Seq 模型进行少样本学习”。Saleh Soltan 等人 arXiv 2022。论文
- ST-MoE ST-MoE:设计稳定且可迁移的稀疏专家模型。2022年,论文
GPT 类语言模型:仅解码器架构
- GPT 通过生成式预训练提升语言理解能力。2018 年。论文
- GPT-2 语言模型是无监督的多任务学习者。2018 年。论文
- GPT-3 “语言模型是少样本学习者”。NeurIPS 2020。论文
- OPT “OPT:开放的预训练 Transformer 语言模型”。2022 年。论文
- PaLM “PaLM:通过 Pathways 扩展语言建模”。Aakanksha Chowdhery 等人 arXiv 2022。论文
- BLOOM “BLOOM:一个拥有 1760 亿参数的开源多语言语言模型”。2022 年。论文
- MT-NLG “使用 DeepSpeed 和 Megatron 训练 Megatron-Turing NLG 530B,一个大规模生成式语言模型”。2021 年。论文
- GLaM “GLaM:基于专家混合的高效语言模型扩展方法”。ICML 2022。论文
- Gopher “语言模型的扩展:方法、分析及从 Gopher 训练中获得的洞见”。2021 年。论文
- chinchilla “训练计算最优的大规模语言模型”。2022 年。论文
- LaMDA “LaMDA:面向对话应用的语言模型”。2021 年。论文
- LLaMA “LLaMA:开放且高效的基座语言模型”。2023 年。论文
- GPT-4 “GPT-4 技术报告”。2023 年。论文
- BloombergGPT BloombergGPT:用于金融的大规模语言模型,2023 年,论文
- GPT-NeoX-20B:“GPT-NeoX-20B:一个开源的自回归语言模型”。2022 年。论文
- PaLM 2:“PaLM 2 技术报告”。2023 年。技术报告
- LLaMA 2:“Llama 2:开放的基础模型和微调后的聊天模型”。2023 年。论文
- Claude 2:“Claude 模型的模型卡片与评估”。2023 年。模型卡片
数据实用指南
预训练数据
- RedPajama,2023 年。仓库
- The Pile:用于语言建模的 800GB 多样化文本数据集,Arxiv 2020。论文
- 预训练目标如何影响大型语言模型对语言特性的学习? ACL 2022。论文
- 神经网络语言模型的缩放法则,2020 年。论文
- 以数据为中心的人工智能:综述,2023 年。论文
- GPT 是如何获得其能力的?追溯语言模型涌现能力的来源,2022 年。博客
微调数据
- 零样本文本分类基准测试:数据集、评估与蕴含方法,EMNLP 2019。论文
- 语言模型是少样本学习者,NIPS 2020。论文
- LLM 的合成数据生成是否有助于临床文本挖掘? Arxiv 2023 论文
测试数据/用户数据
- 自然语言理解中大型语言模型的捷径学习:综述,Arxiv 2023。论文
- 关于 ChatGPT 的鲁棒性:对抗性和分布外视角,Arxiv 2023。论文
- SuperGLUE:一个更具挑战性的通用语言理解系统基准测试,Arxiv 2019。论文
NLP 任务实用指南
我们为用户的 NLP 应用构建了一个选择 LLM 或微调模型的决策流程~\protect\footnotemark。该决策流程帮助用户评估其下游 NLP 任务是否满足特定条件,并根据评估结果确定 LLM 还是微调模型更适合其应用。
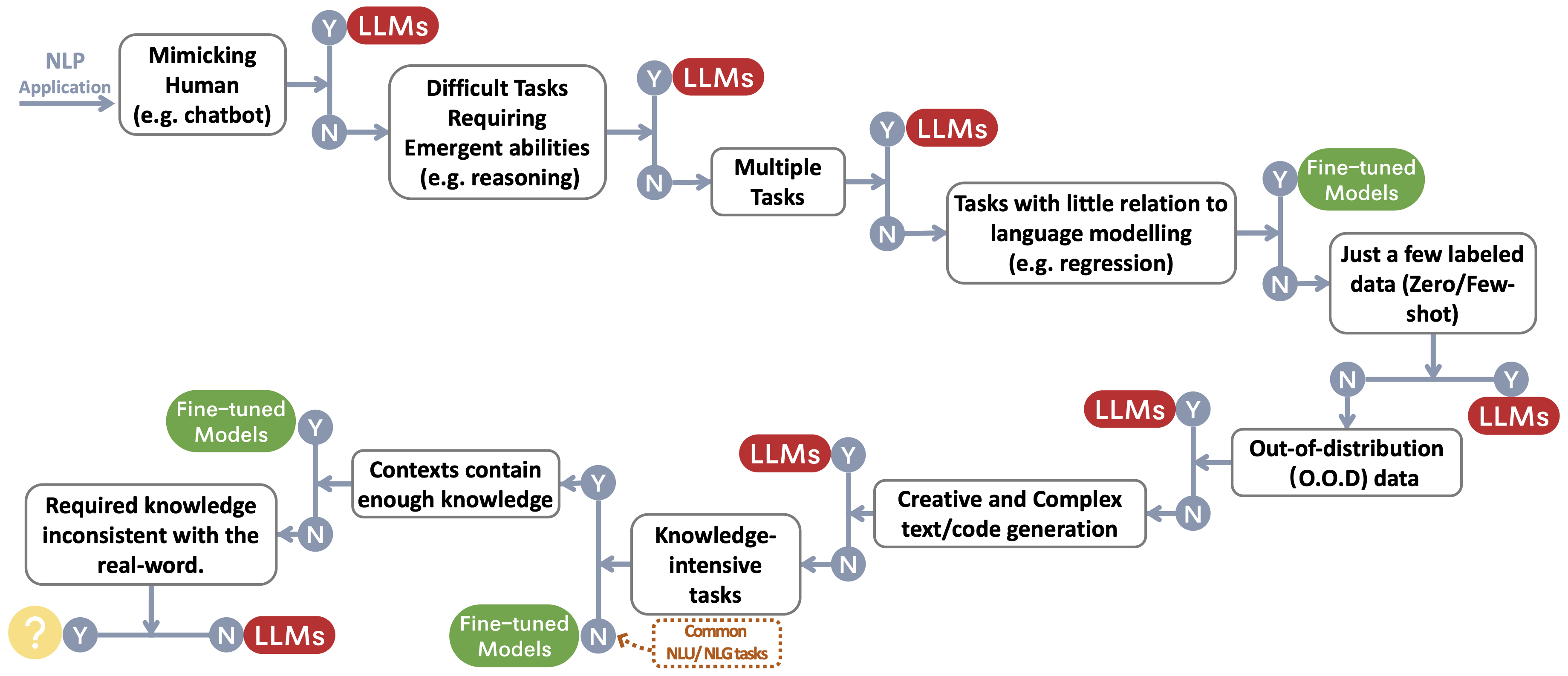
传统 NLU 任务
- 针对 civil comments 数据集的毒性评论分类基准测试 Arxiv 2023 论文
- ChatGPT 是不是通用的自然语言处理任务求解器? Arxiv 2023 论文
- 大型语言模型在新闻摘要方面的基准测试 Arxiv 2022 论文
生成任务
- GPT-3 时代的新闻摘要与评估 Arxiv 2022 论文
- ChatGPT 是不是优秀的翻译工具?是的,以 GPT-4 为引擎 Arxiv 2023 论文
- 微软为 WMT21 共享任务提供的多语言机器翻译系统,WMT2021 论文
- ChatGPT 能否也理解?ChatGPT 与微调后 BERT 的比较研究,Arxiv 2023,论文
知识密集型任务
- 衡量大规模多任务语言理解能力,ICLR 2021 论文
- 超越模仿游戏:量化并推断语言模型的能力,Arxiv 2022 论文
- 逆向缩放奖,2022 链接
- Atlas:基于检索增强的语言模型的少样本学习,Arxiv 2022 论文
- 大型语言模型编码了临床知识,Arxiv 2022 论文
具有规模效应的能力
- 训练计算最优的大语言模型,NeurIPS 2022 论文
- 神经语言模型的规模定律,Arxiv 2020 论文
- 通过过程与结果反馈解决数学应用题,Arxiv 2022 论文
- 思维链提示在大语言模型中激发推理能力,NeurIPS 2022 论文
- 大语言模型的涌现能力,TMLR 2022 论文
- 反向缩放可能呈现U型曲线,Arxiv 2022 论文
- 迈向大语言模型中的推理:综述,Arxiv 2022 论文
具体任务
- 图像作为外语:BEiT预训练用于所有视觉及视觉-语言任务,Arixv 2022 论文
- PaLI:联合规模化的多语言语言-图像模型,Arxiv 2022 论文
- AugGPT:利用ChatGPT进行文本数据增强,Arxiv 2023 论文
- GPT-3是优秀的数据标注者吗?,Arxiv 2022 论文
- 想降低标注成本吗?GPT-3可以帮忙,EMNLP findings 2021 论文
- GPT3Mix:利用大规模语言模型进行文本增强,EMNLP findings 2021 论文
- 用于患者试验匹配的LLM:面向隐私保护的数据增强以提升性能和泛化能力,Arxiv 2023 论文
- ChatGPT在文本标注任务中优于众包工作者,Arxiv 2023 论文
- G-Eval:使用GPT-4进行更符合人类期望的NLG评估,Arxiv 2023 论文
- GPTScore:按您需求进行评估,Arxiv 2023 论文
- 大语言模型是当前最先进的翻译质量评估工具,Arxiv 2023 论文
- ChatGPT是优秀的NLG评估者吗?一项初步研究,Arxiv 2023 论文
真实世界的“任务”
- 通用人工智能的火花:GPT-4的早期实验,Arxiv 2023 论文
效率
- 成本
- OpenAI的GPT-3语言模型:技术概述,2020年。博客文章
- 衡量云实例中人工智能的碳强度,FaccT 2022。论文
- 在人工智能领域,越大是否总是越好?,Nature文章 2023年。文章
- 语言模型是少样本学习者,NeurIPS 2020。论文
- 定价,OpenAI。博客文章
- 延迟
- HELM:语言模型的整体评估,Arxiv 2022。论文
- 参数高效的微调
- LoRA:大语言模型的低秩适应,Arxiv 2021。论文
- Prefix-Tuning:优化连续提示以进行生成,ACL 2021。论文
- P-Tuning:提示调优在不同规模和任务上可与微调相媲美,ACL 2022。论文
- P-Tuning v2:提示调优在不同规模和任务上均可与微调相媲美,Arxiv 2022。论文
- 预训练系统
- ZeRO:面向万亿参数模型训练的内存优化,Arxiv 2019。论文
- Megatron-LM:利用模型并行性训练数十亿参数的语言模型,Arxiv 2019。论文
- 使用Megatron-LM在GPU集群上高效训练大规模语言模型,Arxiv 2021。论文
- 减少大型Transformer模型中的激活重计算,Arxiv 2021。论文
可信度
- 鲁棒性和校准
- 虚假偏见
- 大语言模型可能是懒惰的学习者:分析上下文学习中的捷径,ACL 2023发现 论文
- 自然语言理解中大语言模型的捷径学习:综述,2023年 论文
- 缓解字幕系统中的性别偏见,WWW 2020 论文
- 使用前先校准:提升语言模型的少样本性能,ICML 2021 论文
- 深度神经网络中的捷径学习,Nature Machine Intelligence 2020 论文
- 基于提示的模型真的理解其提示的含义吗?,NAACL 2022 论文
- 安全问题
- GPT-4系统卡片,2023年 论文
- 检测LLM生成文本的科学,Arxiv 2023 论文
- 刻板印象如何通过语言传播:社会类别与刻板印象沟通(SCSC)框架的回顾与介绍,传播学研究评论,2019年 论文
- 性别阴影:商业性别分类中的交叉准确性差异,FaccT 2018 论文
基准指令微调
- FLAN:微调后的语言模型是零样本学习者,Arxiv 2021 论文
- T0:多任务提示训练实现零样本任务泛化,Arxiv 2021 论文
- 通过自然语言众包指令实现跨任务泛化,ACL 2022 论文
- Tk-INSTRUCT:Super-NaturalInstructions:基于1600多种NLP任务的声明式指令实现泛化,EMNLP 2022 论文
- FLAN-T5/PaLM:扩展指令微调语言模型,Arxiv 2022 论文
- FLAN数据集:为有效指令微调设计数据与方法,Arxiv 2023 论文
- OPT-IML:从泛化的视角扩展语言模型指令元学习,Arxiv 2023 论文
对齐
- 基于人类偏好深度强化学习,NIPS 2017 论文
- 从人类反馈中学习总结,Arxiv 2020 论文
- 通用语言助手作为对齐的实验室,Arxiv 2021 论文
- 利用人类反馈强化学习训练有益且无害的助手,Arxiv 2022 论文
- 教导语言模型用经过验证的引文支持答案,Arxiv 2022 论文
- InstructGPT:通过人类反馈训练语言模型遵循指令,Arxiv 2022 论文
- 通过有针对性的人类判断改进对话代理的对齐性,Arxiv 2022 论文
- 奖励模型过度优化的规模定律,Arxiv 2022 论文
- 可扩展监督:衡量大型语言模型可扩展监督的进展,Arxiv 2022 论文
安全性对齐(无害)
- 用语言模型对抗语言模型,Arxiv 2022 论文
- Constitutional AI:来自AI反馈的无害性,Arxiv 2022 论文
- 大型语言模型的道德自我修正能力,Arxiv 2023 论文
- OpenAI:我们的人工智能安全方法,2023 博客
真实性对齐(诚实)
- 语言模型的强化学习,2023 博客
提示工程实用指南(有益)
开源社区的对齐努力
- Self-Instruct:使用自生成指令对齐语言模型,Arxiv 2022 论文
- Alpaca。仓库
- Vicuna。仓库
- Dolly。博客
- DeepSpeed-Chat。博客
- GPT4All。仓库
- OpenAssitant。仓库
- ChatGLM。仓库
- MOSS。仓库
- Lamini。仓库 / 博客
使用与限制
我们制作了一张表格,总结了LLM的使用限制(例如商业用途和研究用途)。特别是,我们从模型及其预训练数据的角度提供了相关信息。 我们敦促社区用户参考公开模型和数据的许可信息,并以负责任的方式使用它们。 我们还敦促开发者特别关注许可问题,确保其透明且全面,以防止任何不希望发生或未预料到的使用情况。
| 大语言模型 | 模型 | 数据 | |||
|---|---|---|---|---|---|
| 许可证 | 商业用途 | 其他值得注意的限制 | 许可证 | 语料库 | |
| 仅编码器 | |||||
| BERT系列模型(通用领域) | Apache 2.0 | ✅ | 公开 | BooksCorpus、英文维基百科 | |
| RoBERTa | MIT许可证 | ✅ | 公开 | BookCorpus、CC-News、OpenWebText、STORIES | |
| ERNIE | Apache 2.0 | ✅ | 公开 | 英文维基百科 | |
| SciBERT | Apache 2.0 | ✅ | 公开 | BERT语料库、来自Semantic Scholar的114万篇论文 | |
| LegalBERT | CC BY-SA 4.0 | ❌ | 公开(除来自Case Law Access Project的数据外) | 欧盟立法、美国法院案例等 | |
| BioBERT | Apache 2.0 | ✅ | PubMed | PubMed、PMC | |
| 编码器-解码器 | |||||
| T5 | Apache 2.0 | ✅ | 公开 | C4 | |
| Flan-T5 | Apache 2.0 | ✅ | 公开 | C4、任务混合体(论文图2) | |
| BART | Apache 2.0 | ✅ | 公开 | RoBERTa语料库 | |
| GLM | Apache 2.0 | ✅ | 公开 | BooksCorpus和英文维基百科 | |
| ChatGLM | ChatGLM许可证 | ❌ | 不得用于非法目的或军事研究,不得损害社会公共利益 | N/A | 中英文语料共1T tokens |
| 仅解码器 | |||||
| GPT2 | 修改后的MIT许可证 | ✅ | 应负责任地使用GPT-2,并明确注明内容由GPT-2生成。 | 公开 | WebText |
| GPT-Neo | MIT许可证 | ✅ | 公开 | Pile | |
| GPT-J | Apache 2.0 | ✅ | 公开 | Pile | |
| ---> Dolly | CC BY NC 4.0 | ❌ | CC BY NC 4.0,受OpenAI生成数据使用条款约束 | Pile、Self-Instruct | |
| ---> GPT4ALL-J | Apache 2.0 | ✅ | 公开 | GPT4All-J数据集 | |
| Pythia | Apache 2.0 | ✅ | 公开 | Pile | |
| ---> Dolly v2 | MIT许可证 | ✅ | 公开 | Pile、databricks-dolly-15k | |
| OPT | OPT-175B许可协议 | ❌ | 不得从事监控研究和军事相关开发,不得损害社会公共利益 | 公开 | RoBERTa语料库、Pile、PushShift.io Reddit |
| ---> OPT-IML | OPT-175B许可协议 | ❌ | 与OPT相同 | 公开 | OPT语料库、Super-NaturalInstructions扩展版 |
| YaLM | Apache 2.0 | ✅ | 未指定 | Pile、俄语团队收集的文本 | |
| BLOOM | BigScience RAIL许可证 | ✅ | 不得利用该模型生成可验证的虚假信息以伤害他人; 内容需明确声明并非机器生成 |
公开 | ROOTS语料库(Lauren¸con等人,2022年) |
| ---> BLOOMZ | BigScience RAIL许可证 | ✅ | 与BLOOM相同 | 公开 | ROOTS语料库、xP3 |
| Galactica | CC BY-NC 4.0 | ❌ | N/A | Galactica语料库 | |
| LLaMA | 非商业定制许可证 | ❌ | 不得从事监控研究和军事相关开发,不得损害社会公共利益 | 公开 | CommonCrawl、C4、Github、维基百科等 |
| ---> Alpaca | CC BY NC 4.0 | ❌ | CC BY NC 4.0,受OpenAI生成数据使用条款约束 | LLaMA语料库、Self-Instruct | |
| ---> Vicuna | CC BY NC 4.0 | ❌ | 受OpenAI生成数据使用条款及ShareGPT隐私政策约束 | LLaMA语料库、来自ShareGPT.com的7万条对话 | |
| ---> GPT4ALL | GPL授权的LLaMa | ❌ | 公开 | GPT4All数据集 | |
| OpenLLaMA | Apache 2.0 | ✅ | 公开 | RedPajama | |
| CodeGeeX | CodeGeeX许可证 | ❌ | 不得用于非法目的或军事研究 | 公开 | Pile、CodeParrot等 |
| StarCoder | BigCode OpenRAIL-M v1许可证 | ✅ | 不得利用该模型生成可验证的虚假信息以伤害他人; 内容需明确声明并非机器生成 |
公开 | The Stack | MPT-7B | Apache 2.0 | ✅ | 公开 | mC4(英语)、The Stack、RedPajama、S2ORC |
| falcon | TII Falcon LLM许可证 | ✅/❌ | 可在允许商业使用的许可下使用 | 公开 | RefinedWeb |
星标历史

常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。