scylla
Scylla 是一款专为人工智能时代设计的智能代理池工具,旨在帮助用户高效地从互联网提取内容,为构建专属的大语言模型提供数据支持。在网络爬虫开发中,IP 被封禁和数据获取不稳定是常见痛点,Scylla 通过自动抓取并实时验证全球代理 IP,确保持续获得可用的高质量节点,从而解决数据采集过程中的连接障碍。
这款工具特别适合开发者、数据科学家及 AI 研究人员使用。无论是需要大规模训练数据的模型构建者,还是进行网络信息收集的技术人员,都能从中受益。Scylla 的技术亮点在于其极简的部署体验:仅需一条命令即可启动服务,同时提供易用的 JSON API 和美观的 Web 界面,让用户能直观查看代理的地理分布与状态。此外,它能无缝集成 Scrapy 和 Requests 等主流框架,只需一行代码即可调用,并支持无头浏览器爬取模式。配合 Docker 一键部署能力,Scylla 让搭建高可用的代理基础设施变得简单而优雅,是数据采集工作中得力的助手。
使用场景
某初创数据团队正致力于构建垂直领域的行业大模型,急需从全球新闻网站和论坛中持续抓取高质量训练语料。
没有 scylla 时
- 代理资源枯竭快:手动寻找的免费代理 IP 存活时间极短,爬虫运行几分钟后便因大量连接超时或封禁而中断。
- 维护成本高昂:开发人员需编写复杂的脚本定期验证 IP 可用性,并花费大量时间清洗无效数据,严重挤占核心算法研发时间。
- 缺乏智能调度:无法根据目标网站的地理位置自动匹配当地代理,导致跨境访问延迟极高,甚至触发风控机制。
- 集成流程繁琐:每次切换代理池都需要修改底层网络配置,难以与 Scrapy 或 Requests 等主流框架快速对接。
使用 scylla 后
- 自动维持高可用池:scylla 后台自动持续爬取并验证全球代理 IP,实时剔除失效节点,确保爬虫任务 7x24 小时稳定运行。
- 零代码运维负担:只需一条 Docker 命令即可部署,scylla 自动处理所有验证逻辑,团队可完全聚焦于数据清洗与模型训练。
- 智能地理路由:通过简单的 API 参数(如
countries=US,GB),scylla 自动分发对应区域的匿名代理,显著降低访问延迟并规避封锁。 - 一行代码集成:在现有 Python 爬虫项目中仅需增加一行配置即可调用 scylla 的 HTTP 转发服务,无缝融入现有技术栈。
scylla 将不稳定的代理获取过程转化为可靠的自动化基础设施,让数据工程师能专注于构建下一代大语言模型的核心价值。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始


![]()

![]()

![]()
Scylla
一个面向人文领域的智能代理池,用于从互联网上提取内容,并在这一人工智能新时代构建您自己的大型语言模型。
主要特性:
- 自动化代理IP抓取与验证
- 易于使用的JSON API
- 简洁美观的Web用户界面(例如代理的地理分布)
- 最少只需一条命令即可快速上手
- 简单的HTTP正向代理服务器
- 仅需一行代码即可与Scrapy和requests集成
- 无头浏览器爬虫
快速开始
安装
使用Docker安装(强烈推荐)
docker run -d -p 8899:8899 -p 8081:8081 -v /var/www/scylla:/var/www/scylla --name scylla wildcat/scylla:latest
直接通过pip安装
pip install scylla
scylla --help
scylla # 运行爬虫和提供JSON API的Web服务器
从源码安装
git clone https://github.com/imWildCat/scylla.git
cd scylla
pip install -r requirements.txt
cd frontend
npm install
cd ..
make assets-build
python -m scylla
使用方法
以下是在本地(localhost)运行服务的示例,使用端口8899。
注意:首次使用Scylla时,可能需要等待1到2分钟,以便数据库中填充一些代理IP。
JSON API
代理IP列表
http://localhost:8899/api/v1/proxies
可选URL参数:
| 参数 | 默认值 | 描述 |
|---|---|---|
page |
1 |
当前页码 |
limit |
20 |
每页显示的代理数量 |
anonymous |
any |
是否显示匿名代理。可选值:true表示仅显示匿名代理;false表示仅显示透明代理 |
https |
any |
是否显示HTTPS代理。可选值:true表示仅显示HTTPS代理;false表示仅显示HTTP代理 |
countries |
无 | 按特定国家筛选代理。格式示例:US,或多国组合:US,GB |
示例结果:
{
"proxies": [{
"id": 599,
"ip": "91.229.222.163",
"port": 53281,
"is_valid": true,
"created_at": 1527590947,
"updated_at": 1527593751,
"latency": 23.0,
"stability": 0.1,
"is_anonymous": true,
"is_https": true,
"attempts": 1,
"https_attempts": 0,
"location": "54.0451,-0.8053",
"organization": "AS57099 Boundless Networks Limited",
"region": "英格兰",
"country": "GB",
"city": "Malton"
}, {
"id": 75,
"ip": "75.151.213.85",
"port": 8080,
"is_valid": true,
"created_at": 1527590676,
"updated_at": 1527593702,
"latency": 268.0,
"stability": 0.3,
"is_anonymous": true,
"is_https": true,
"attempts": 1,
"https_attempts": 0,
"location": "32.3706,-90.1755",
"organization": "AS7922 Comcast Cable Communications, LLC",
"region": "密西西比州",
"country": "US",
"city": "杰克逊"
},
...
],
"count": 1025,
"per_page": 20,
"page": 1,
"total_page": 52
}
系统统计信息
http://localhost:8899/api/v1/stats
示例结果:
{
"median": 181.2566407083,
"valid_count": 1780,
"total_count": 9528,
"mean": 174.3290085201
}
HTTP正向代理服务器
默认情况下,Scylla会在端口8081启动一个HTTP正向代理服务器。该服务器会从数据库中随机选择一个最近更新的代理作为转发代理。每当有HTTP请求到达时,代理服务器就会随机挑选一个代理进行转发。
注意:目前不支持HTTPS请求。
以下是使用此代理服务器的curl示例:
curl http://api.ipify.org -x http://127.0.0.1:8081
您也可以通过requests库使用此功能:
requests.get('http://api.ipify.org', proxies={'http': 'http://127.0.0.1:8081'})
Web 界面
在浏览器中打开 http://localhost:8899 即可查看该项目的 Web 界面。
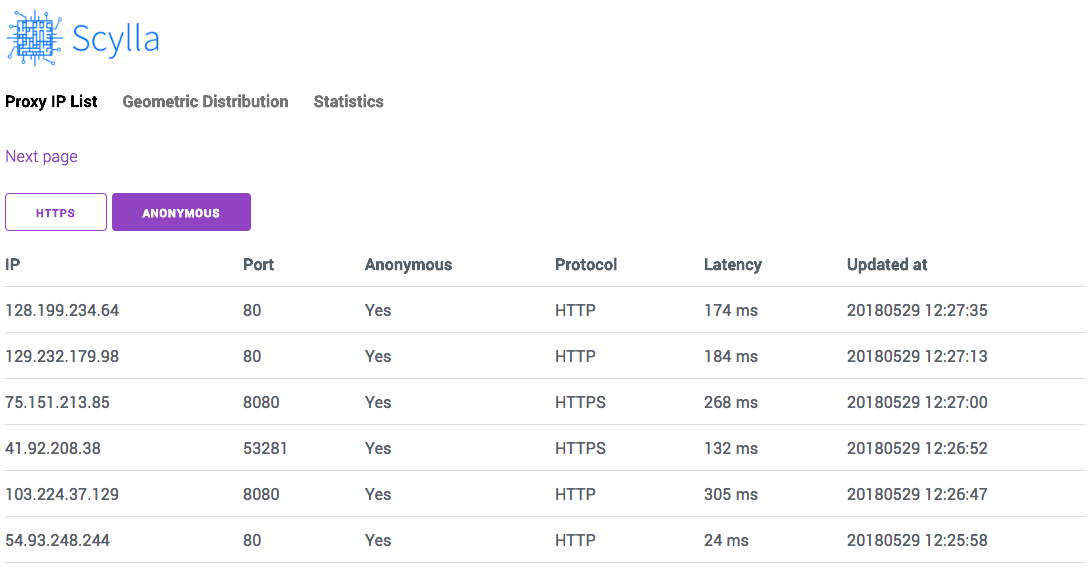
代理 IP 列表
http://localhost:8899/
截图:
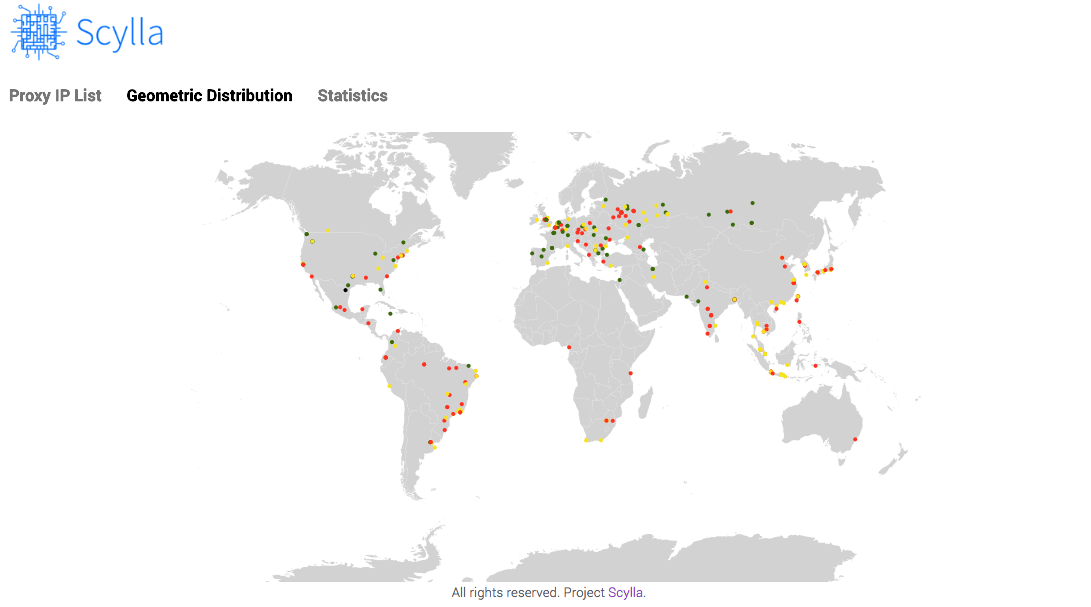
全球地理分布图
http://localhost:8899/#/geo
截图:
API 文档
请阅读 模块索引。
路线图
请参阅 项目。
开发与贡献
git clone https://github.com/imWildCat/scylla.git
cd scylla
pip install -r requirements.txt
npm install
make assets-build
测试
如果您希望在本地运行测试,命令如下:
pip install -r tests/requirements-test.txt
pytest tests/
欢迎您为该项目添加更多测试用例,以提高项目的健壮性。
项目命名
Scylla 源自美国电视剧《越狱》(Prison Break) 中一组内存芯片的名称。本项目以此美剧命名,以向其致敬。
帮助
捐赠
如果您觉得这个项目很有用,请考虑为它捐赠一些资金吗?
无论金额多少,您的捐赠都会激励作者持续开发新功能!🎉 谢谢!
捐赠方式如下:
GitHub 赞助
如果您能成为我的赞助者,我将不胜感激。
https://github.com/sponsors/imWildCat
PayPal

许可证
Apache 许可证 2.0。更多详情请参阅 LICENSE 文件。
版本历史
1.2.02022/03/061.2.0-pre2022/03/051.1.72019/08/251.1.62019/08/091.1.52018/12/261.1.42018/06/071.12018/05/301.02018/05/270.1.32018/04/29常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。
crawl4ai
Crawl4AI 是一款专为大语言模型(LLM)设计的开源网络爬虫与数据提取工具。它的核心使命是将纷繁复杂的网页内容转化为干净、结构化的 Markdown 格式,直接服务于检索增强生成(RAG)、智能体构建及各类数据管道,让 AI 能更轻松地“读懂”互联网。 传统爬虫往往面临反爬机制拦截、动态内容加载困难以及输出格式杂乱等痛点,导致后续数据处理成本高昂。Crawl4AI 通过内置自动化的三级反机器人检测、代理升级策略以及对 Shadow DOM 的深度支持,有效突破了这些障碍。它能智能移除同意弹窗,处理深层链接,并具备长任务崩溃恢复能力,确保数据采集的稳定与高效。 这款工具特别适合开发者、AI 研究人员及数据工程师使用。无论是需要为本地模型构建知识库,还是搭建大规模自动化信息采集流程,Crawl4AI 都提供了极高的可控性与灵活性。作为 GitHub 上备受瞩目的开源项目,它完全免费开放,无需繁琐的注册或昂贵的 API 费用,让用户能够专注于数据价值本身而非采集难题。
meilisearch
Meilisearch 是一个开源的极速搜索服务,专为现代应用和网站打造,开箱即用。它能帮助开发者快速集成高质量的搜索功能,无需复杂的配置或额外的数据预处理。传统搜索方案往往需要大量调优才能实现准确结果,而 Meilisearch 内置了拼写容错、同义词识别、即时响应等实用特性,并支持 AI 驱动的混合搜索(结合关键词与语义理解),显著提升用户查找信息的体验。 Meilisearch 特别适合 Web 开发者、产品团队或初创公司使用,尤其适用于需要快速上线搜索功能的场景,如电商网站、内容平台或 SaaS 应用。它提供简洁的 RESTful API 和多种语言 SDK,部署简单,资源占用低,本地开发或生产环境均可轻松运行。对于希望在不依赖大型云服务的前提下,为用户提供流畅、智能搜索体验的团队来说,Meilisearch 是一个高效且友好的选择。
Made-With-ML
Made-With-ML 是一个面向实战的开源项目,旨在帮助开发者系统掌握从设计、开发到部署和迭代生产级机器学习应用的完整流程。它解决了许多人在学习机器学习时“会训练模型但不会上线”的痛点,强调将软件工程最佳实践与 ML 技术结合,构建可靠、可维护的端到端系统。 该项目特别适合三类人群:一是希望将模型真正落地的开发者(包括软件工程师、数据科学家);二是刚毕业、想补齐工业界所需技能的学生;三是需要理解技术边界以更好推动产品的技术管理者或产品经理。 Made-With-ML 的亮点在于注重第一性原理讲解,避免盲目调包;同时覆盖 MLOps 关键环节(如实验跟踪、模型测试、服务部署、CI/CD 等),并支持在 Python 生态内平滑扩展训练与推理任务,无需切换语言或复杂基础设施。课程内容结构清晰,配有详细代码示例和视频导览,兼顾理论深度与工程实用性。