Memento
Memento 是一款创新的开源框架,旨在让大语言模型(LLM)智能体在不更新模型权重的情况下,通过积累经验实现持续进化。它巧妙地将“微调”转化为基于记忆的在线强化学习过程,解决了传统方法中反复训练模型成本高、效率低且难以实时适应新任务的痛点。
该工具采用独特的“规划器 - 执行器”双阶段架构:规划器利用案例推理(CBR)拆解复杂任务并检索历史成功经验,执行器则通过统一的 MCP 接口调用各类工具完成子任务。所有成功或失败的交互轨迹都会被存入“案例库”,供后续任务按需读取和复用,真正实现“从经验中学习而非依赖梯度更新”。
Memento 特别适合 AI 研究人员、开发者以及需要构建自适应智能体的技术团队使用。其核心亮点在于无需修改模型参数即可显著提升智能体在 GAIA 等基准测试中的表现,并具备优秀的泛化能力。此外,它还内置了丰富的工具生态,支持网页搜索、代码执行及多模态分析等功能,帮助用户以低成本快速搭建具备持续学习能力的智能应用。
使用场景
某电商数据团队需要构建一个智能助手,每日自动从多个新闻源和财报中抓取竞品动态,并生成结构化分析报告。
没有 Memento 时
- 重复犯错:模型每次遇到新的网站反爬策略或复杂的表格格式时都会重新“试错”,无法记住之前的成功破解方案,导致任务频繁中断。
- 成本高昂:为了提升准确率,团队不得不频繁对大模型进行微调(Fine-tuning),消耗大量 GPU 算力和时间,且难以实时生效。
- 缺乏积累:助手无法将处理过的成功案例转化为经验,面对相似的新任务(如分析另一家竞品)时,仍需从头开始规划,效率低下。
- 工具调度僵化:在调用搜索、代码解释器等工具时,一旦某步出错,系统缺乏基于历史经验的自我修正机制,只能报错停止。
使用 Memento 后
- 经验复用:Memento 将成功的抓取策略和失败的教训存入“案例库”,遇到类似反爬或格式问题时,直接检索历史最佳实践,一次性通过。
- 零权重更新:无需修改模型参数,仅通过读写记忆即可实现持续学习,大幅降低了算力成本,且新经验能秒级生效。
- 越用越聪明:随着运行次数增加,案例库不断丰富,Memento 能自动迁移过往经验到新竞品分析中,规划路径更精准,执行速度显著提升。
- 自愈能力强:基于案例推理(CBR),当子任务执行受阻时,Planner 能参考历史相似场景的修复方案,自动调整工具调用顺序或参数,完成闭环。
Memento 让 AI 代理像人类专家一样通过“积累经验”而非“重新训练”来进化,实现了低成本、实时的持续能力提升。
运行环境要求
- Linux
- macOS
- Windows
- 可选(参数化记忆模式推荐)
- 需支持 CUDA 11.8 或 12.1 的 NVIDIA GPU
- CPU 模式亦可运行但功能受限
未说明
快速开始
重要提示:在不微调大型语言模型(LLMs)的情况下,对 LLM 代理进行精细调优
一种基于记忆的持续学习框架,可帮助 LLM 代理从经验中不断改进,而无需更新模型权重。
规划器-执行器架构 • 基于案例的推理 • MCP 工具集 • 增强记忆的学习
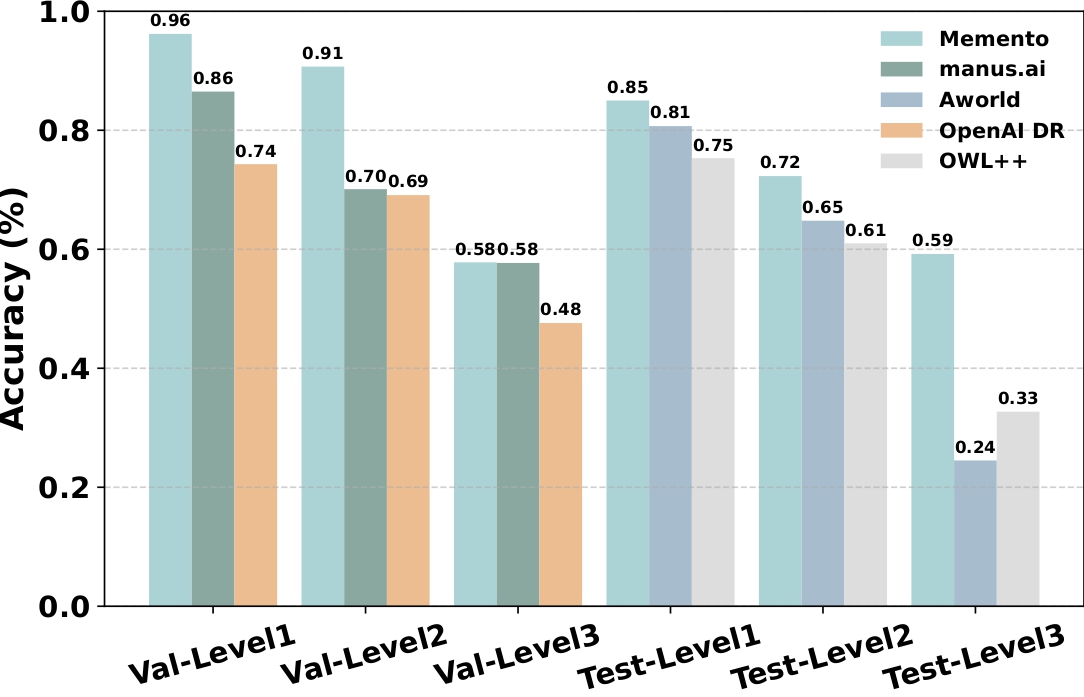
与基线相比,Memento 在 GAIA 验证集和测试集上的表现。 |
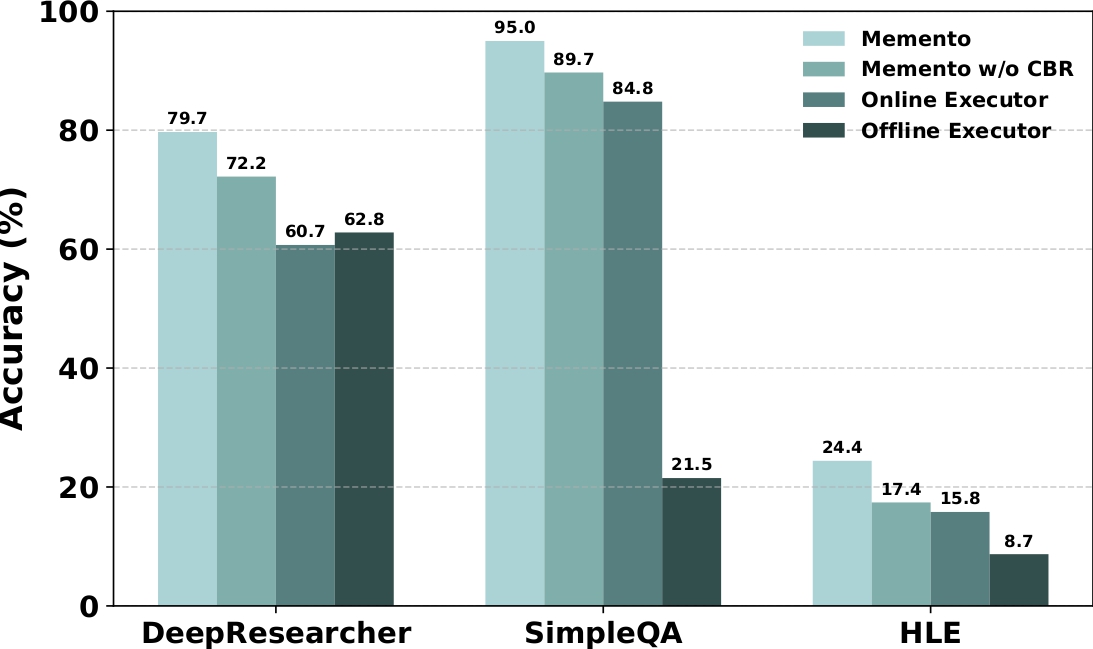
对 Memento 在各类基准测试中的消融研究。 |
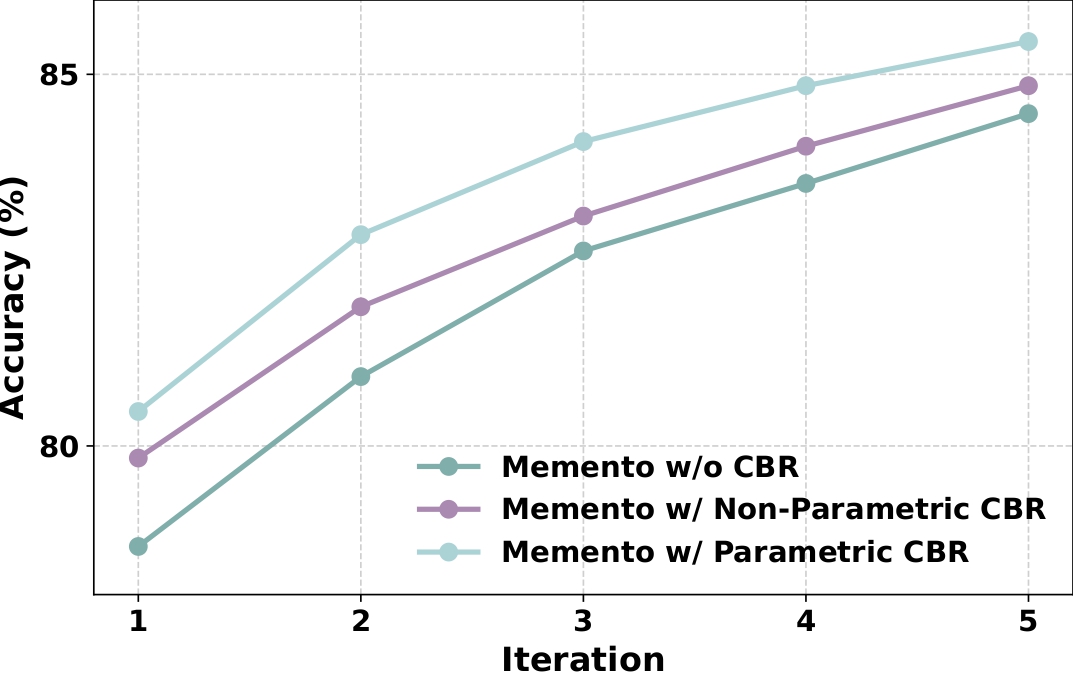
不同记忆设计下的持续学习曲线。 |
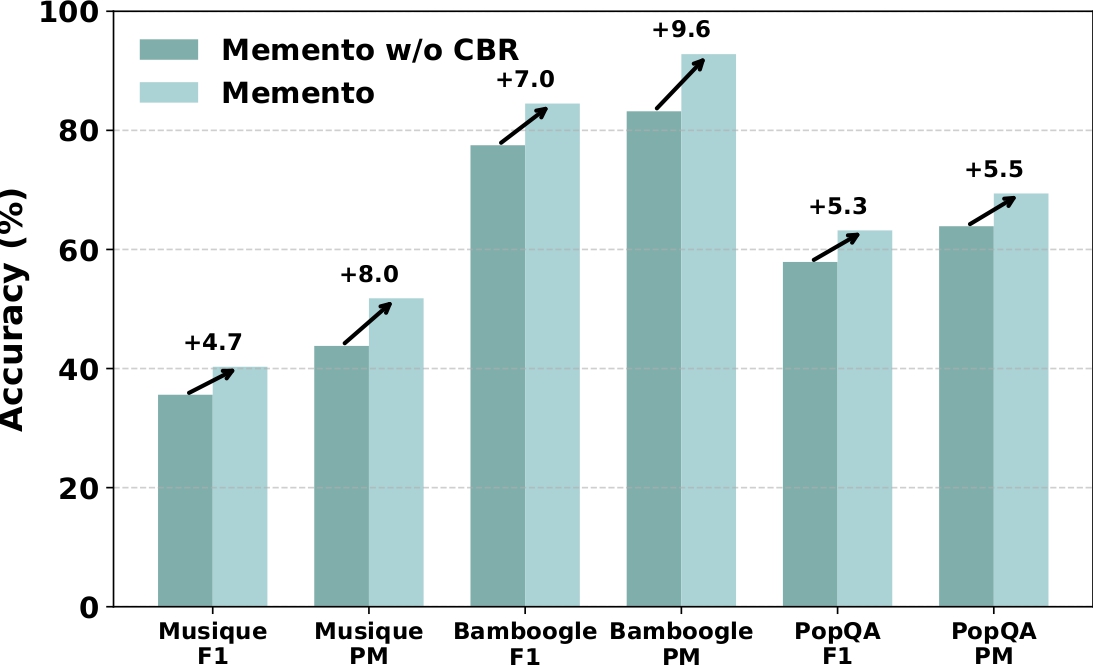
Memento 在未见过的数据集上所取得的准确率提升。 |
📰 新闻
- [2025.10.05] 我们很高兴地宣布,我们的参数化基于案例的推理推理代码现已正式开源!🎉
- [2025.09.05] 我们新增了支持,可通过 vLLM 将本地 LLM 作为执行器进行部署,请参阅 client/agent_local_server.py。🎉
- [2025.09.03] 我们建立了微信群,以便更轻松地开展协作并交流本项目的相关想法。欢迎加入该群,分享您的见解、提出问题或贡献您的创意!🔥 🔥 🔥 立即加入我们的微信群!
- [2025.08.30] 我们很高兴地宣布,我们的非参数化基于案例的推理推理代码现已正式开源!🎉
- [2025.08.28] 我们创建了一个 Discord 服务器,以使围绕本项目的讨论与协作更加便捷。欢迎加入并分享您的想法、提出问题或贡献创意!🔥 🔥 🔥 加入我们的 Discord!
- [2025.08.27] 感谢您对我们工作的关注!我们将在下周发布 CBR 代码,并在下个月发布参数化记忆代码。我们将持续更新本项目的最新进展。
- [2025.08.27] 我们在
server/ai_crawler.py中新增了一项新的爬虫 MCP,用于网络爬取以及查询感知的内容压缩,以降低 token 成本。 - [2025.08.26] 我们新增了 SerpAPI(https://serpapi.com/search-api)MCP 工具,帮助您避免使用搜索 Docker,从而加快开发速度。
{kind=link}
🔥 核心功能
- 无需更新 LLM 权重。 Memento 将持续学习重新构想为基于记忆的在线强化学习,其基础是增强记忆的 MDP。通过神经网络的案例选择策略来指导行动;经验则通过高效且快速的读写操作被存储并重复利用。
- 两阶段的规划器-执行器循环。 由 CBR 驱动的规划器会将任务分解并检索相关案例;执行器则以 MCP 客户端的身份运行每个子任务,协调工具并回传执行结果。
- 全面的工具生态系统。 通过统一的 MCP 界面,内置支持网页搜索、文档处理、代码执行、图像/视频分析等多种功能。
- 卓越的基准测试表现。 在 GAIA、DeepResearcher、SimpleQA 和 HLE 等基准测试中均取得了具有竞争力的成绩。
🧠 核心概念
从经验中学习,而非依赖梯度。 Memento 会将成功与失败的轨迹记录到案例库中,并按值进行检索,以引导规划与执行——从而实现低成本、可迁移且在线的持续学习。
🏗️ 架构
核心组件
- 元规划器:利用 GPT-4.1 将高阶查询分解为可执行的子任务。
- 执行器:通过 MCP 工具,使用 o3 或其他模型执行各个子任务。
- 案例记忆:存储最终步骤的元组 (s_T, a_T, r_T),用于经验回放。
- MCP 工具层:为外部工具和服务提供统一的接口。
工具生态系统
- 网络搜索:通过 SearxNG 实现实时搜索与受控爬取。
- 文档处理:支持多种格式(PDF、Office 文档、图片、音频、视频)。
- 代码执行:配备沙盒化的 Python 工作区,并具备安全管控机制。
- 数据分析:支持 Excel 处理、数学计算。
- 媒体分析:图像标题生成、视频旁白、音频转录。
🚀 快速入门
前提条件
- Python 3.11+
- OpenAI API 密钥(或兼容的 API 端点)
- SearxNG 实例用于网络搜索
- FFmpeg(系统级二进制文件,用于视频处理)
- PyTorch 2.0+ 并支持 CUDA(适用于参数化记忆)
📖 如需详细安装指南,请参阅 INSTALL.md
安装
方法 1:使用 uv(推荐方案——快速又现代)
# 克隆仓库
git clone https://github.com/Agent-on-the-Fly/Memento
cd Memento
# 如果尚未安装 uv,可直接运行以下命令
curl -LsSf https://astral.sh/uv/install.sh | sh
# 自动同步依赖并创建虚拟环境
uv sync
# 激活虚拟环境
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
方法 2:使用 pip 与 requirements.txt
# 克隆仓库
git clone https://github.com/Agent-on-the-Fly/Memento
cd Memento
# 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate # 在 Windows 上:.venv\Scripts\activate
# 安装依赖
pip install -r requirements.txt
PyTorch 安装
针对 GPU 支持(参数化记忆推荐方案):
# CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 仅支持 CPU
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
如需更多 PyTorch 安装选项,请访问:https://pytorch.org/get-started/locally/
系统依赖安装
FFmpeg 安装(必需)
FFmpeg 是视频处理功能所必需的。 我们的依赖中包含的 ffmpeg-python 包需要一个系统级的 FFmpeg 二进制文件。
Windows:
# 方法 1:使用 Conda(推荐用于隔离环境)
conda install -c conda-forge ffmpeg
# 方法 2:从官方网站下载
# 访问 https://ffmpeg.org/download.html 并将其添加到 PATH 中
macOS:
# 使用 Homebrew
brew install ffmpeg
Linux:
# Debian/Ubuntu
sudo apt-get update && sudo apt-get install ffmpeg
网页爬取与搜索设置
# 安装并配置 crawl4ai
crawl4ai-setup
crawl4ai-doctor
# 安装 Playwright 浏览器
playwright install
环境变量配置
在创建 .env 文件后,您需要配置以下 API 密钥和服务端点:
#===========================================
# OpenAI API 配置
#===========================================
USE_AZURE_OPENAI=False
OPENAI_API_KEY=your_openai_api_key_here
OPENAI_BASE_URL=https://api.openai.com/v1 # 或者使用您自定义的 API 端点
AZURE_OPENAI_API_KEY=your_azure_openai_api_key_here
AZURE_OPENAI_API_VERSION=your_azure_openai_api_version_here
AZURE_OPENAI_ENDPOINT=your_azure_openai_endpoint_here
#===========================================
# 工具与服务 API
#===========================================
# Chunkr API(https://chunkr.ai/)
CHUNKR_API_KEY=your_chunkr_api_key_here
# Jina API
JINA_API_KEY=your_jina_api_key_here
# ASSEMBLYAI API
ASSEMBLYAI_API_KEY=your_assemblyai_api_key_here
注意:请将 your_*_api_key_here 替换为您的实际 API 密钥。部分服务为可选,具体取决于您计划使用的工具。
SearxNG 设置
若需实现网页搜索功能,请配置 SearxNG: 您可以参考 https://github.com/searxng/searxng-docker/ 来设置 Docker 并使用我们的配置方案。
# 在新终端中
cd ./Memento/searxng-docker
docker compose up -d
基本用法
交互式模式
python client/agent.py
参数化记忆模式(高级模式——带记忆检索器)
参数化记忆使代理能够借助训练有素的神经检索器模型,从过往经验中进行学习。
步骤 1:训练记忆检索器
首先,您需要使用初始训练数据来训练检索器模型:
cd memory
# 训练检索器模型
python train_memory_retriever.py \
--train training_data.jsonl \
--output_dir ./ckpts/retriever \
--use_plan \
--val_ratio 0.1 \
--batch_size 32 \
--lr 2e-5 \
--epochs 10 \
--save_best
步骤 2:配置环境变量
在您的 .env 文件中添加以下内容:
# 记忆配置
MEMORY_JSONL_PATH=../memory/memory.jsonl
TRAINING_DATA_PATH=../memory/training_data.jsonl
RETRIEVER_MODEL_PATH=../memory/ckpts/retriever/best.pt
MEMORY_TOP_K=8
MEMORY_MAX_POS_EXAMPLES=8
MEMORY_MAX_NEG_EXAMPLES=8
步骤 3:运行参数化记忆代理
cd client
python parametric_memory.py
🔧 配置
模型选择
- 规划器模型:默认采用
gpt-4.1以支持任务分解 - 执行器模型:默认采用
o3以实现任务执行 - 自定义模型:支持任何兼容 OpenAI 的 API
工具配置
- 搜索:配置 SearxNG 实例的 URL
- 代码执行:自定义导入白名单及安全设置
- 文档处理:设置缓存目录及处理限制
📊 性能
基准测试结果
- GAIA:87.88%(验证集,Pass@3 Top-1)和 79.40%(测试集)
- DeepResearcher:66.6% F1 / 80.4% PM,在 OOD 数据集上实现了 +4.7–9.6 的绝对性能提升
- SimpleQA:95.0%
- HLE:24.4% PM(接近 GPT-5,达到 25.32%)
关键洞察
- 小型、高质量的记忆效果最佳:当检索器的 K=4 时,F1/PM 值达到峰值
- 规划 + CBR 能持续提升性能
- 简洁、结构化的规划方式,优于冗长的决策过程
🛠️ 开发
项目结构
Memento/
├── client/ # 主要代理实现
│ ├── agent.py # 分层客户端,结合规划器与执行器
│ ├── no_parametric_cbr.py # 非参数化基于案例推理
│ ├── parametric_memory.py # 带神经检索器的参数化记忆
│ ├── run_parametric.sh # 用于参数化模式的便捷脚本
│ └── PARAMETRIC_MEMORY_GUIDE.md # 详细参数化记忆指南
├── server/ # MCP 工具服务器
│ ├── code_agent.py # 代码执行与工作区管理
│ ├── search_tool.py # 通过 SearxNG 进行网页搜索
│ ├── serp_search.py # 基于 SERP 的搜索工具
│ ├── documents_tool.py # 多格式文档处理
│ ├── image_tool.py # 图片分析与标注
│ ├── video_tool.py # 视频处理与旁白生成
│ ├── excel_tool.py # 电子表格处理
│ ├── math_tool.py # 数学计算
│ ├── craw_page.py # 网页抓取
│ └── ai_crawler.py # 查询感知压缩爬虫
├── interpreters/ # 代码执行后端
│ ├── docker_interpreter.py
│ ├── e2b_interpreter.py
│ ├── internal_python_interpreter.py
│ └── subprocess_interpreter.py
├── memory/ # 记忆组件 / 数据
│ ├── parametric_memory.py # 基于案例的检索器,用于推理
│ ├── train_memory_retriever.py # 检索器训练脚本
│ ├── np_memory.py # 非参数化记忆实用工具
│ ├── retrain.sh # 用于重新训练的便捷脚本
│ ├── memory.jsonl # 记忆池(带有标签的案例)
│ ├── training_data.jsonl # 检索器的训练数据
│ └── ckpts/ # 模型检查点
│ └── retriever/
│ ├── best.pt # 最佳性能模型
│ └── last.pt # 上一阶段的模型
├── data/ # 样本数据 / 案例
├── searxng-docker/ # SearxNG Docker 配置
├── Figure/ # 用于 README/论文的图表
├── README.md
├── requirements.txt
├── pyproject.toml
└── LICENSE
添加新工具
- 在
server/目录下创建一个新的 FastMCP 服务器 - 实现您的工具函数,并确保具备完善的错误处理机制
- 将工具注册到 MCP 协议中
- 更新
agent.py中客户端的服务器列表
自定义解释器
扩展 interpreters/ 模块,以新增多种执行后端:
from interpreters.base import BaseInterpreter
class CustomInterpreter(BaseInterpreter):
async def execute(self, code: str) -> str:
# 您的自定义执行逻辑
pass
📋 待办事项
已完成的功能 ✅
- 增加案例库推理:已实现基于参数化记忆的案例检索,并结合神经检索器
- 持续学习流程:自动化收集训练数据并进行模型重新训练
即将推出的功能与改进方向
- 加入用户个人记忆机制:实现用户偏好搜索功能
- 优化工具,新增更多工具:完善现有工具,拓展工具生态系统
- 测试更多新基准:在更多基准数据集上评估性能
- 内存压缩:实施高效的内存剪枝与压缩策略
- 多模态记忆:将记忆扩展至支持图片、视频及其他模态
局限性
- 长周期任务:GAIA 第三级任务仍具有挑战性,因为存在复合误差
- 前沿知识:HLE 的性能仅受限于工具本身
- 开源覆盖范围:完全开放的管道中,执行器的验证尚显不足
🙏 感谢
- 一些工具包和解释器中的代码源自 Camel-AI。
📚 引用
如果《Memento》对您的工作有所帮助,请务必进行引用:
@article{zhou2025mementofinetuningllmagents,
title={Memento:在不微调大语言模型的前提下,对大语言模型代理进行微调},
author={周虎驰、陈一航、郭思远、严雪、李金黑、王梓涵、李家耀、张古春、邵坤、杨林毅、王俊},
journal={arXiv预印本 arXiv: 2508.16153},
url={https://arxiv.org/abs/2508.16153},
year={2025}
}
@article{huang2025deep,
title={深度研究代理:系统性考察与路线图},
author={黄宇轩、陈一航、张浩政、李康、方萌、杨林毅、李小光、尚立峰、徐松岑、郝建业等},
journal={arXiv预印本 arXiv:2506.18096},
year={2025}
}
如需更全面的概览,请参阅我们的调查:GitHub
🤝 贡献
我们热烈欢迎各位的贡献!请查看我们的贡献指南,了解以下内容:
- 错误报告与功能请求
- 代码贡献与拉取请求
- 文档改进
- 工具与解释器扩展
星星历史

常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。