Science-Star
Science-Star 是一个专为构建、扩展和实验科学类 AI 智能体(Scientific Agents)而设计的开源平台。它致力于解决科研场景中智能体开发门槛高、工具集成复杂以及评估流程繁琐的痛点,让研究者能零摩擦地将想法快速转化为可运行的实验。
该平台非常适合人工智能研究人员、开发者以及对科学自动化感兴趣的工程师使用。其核心基于强大的 ReAct 引擎,内置了规划、行动、记忆与反思四大模块,能够模拟人类科学家的推理过程。技术亮点在于其丰富的工具箱,集成了搜索、网页爬取、PDF 解析、浏览器操作及代码执行等多种能力,并原生支持 Humanity's Last Exam (HLE) 和 GAIA 等权威基准测试。
Science-Star 采用模块化架构,支持单智能体与多智能体(如代码代理 + 搜索代理)模式的灵活切换,用户无需改动核心逻辑即可自定义模型或工具。此外,项目还配备了端到端的可视化仪表盘,方便直观地分析实验数据与结果。无论是想要复现前沿论文,还是希望构建专属的科学探索助手,Science-Star 都能提供高效、开放的基础设施支持。
使用场景
某生物信息学研究员正试图构建一个能自动查阅最新文献、解析 PDF 数据并编写分析代码的智能体,以加速癌症标志物的筛选工作。
没有 Science-Star 时
- 重复造轮子:需手动集成 SerpAPI 搜索、PDF 解析器和代码执行环境,花费数周搭建基础框架而非专注科研逻辑。
- 架构僵化:若想从单智能体切换为“搜索 + 编码”多智能体协作模式,必须重构核心代码,极易引入 Bug。
- 评估困难:缺乏内置的 HLE 或 GAIA 基准测试支持,难以量化智能体在复杂科学任务中的真实表现。
- 黑盒调试:缺少端到端的可视化面板,无法直观追踪智能体的规划、记忆与反思过程,排查错误如同大海捞针。
使用 Science-Star 后
- 开箱即用:直接调用内置的丰富工具箱(如 Jina 爬取、PDF 解析、RAG 检索),一天内即可部署具备完整能力的科学智能体。
- 灵活切换:仅通过修改配置文件,即可无缝在单智能体与多智能体架构间切换,核心业务逻辑无需任何改动。
- 一键评测:利用集成的 HLE/GAIA 加载器和评分器,瞬间完成基准测试,并通过 Streamlit 仪表盘直观分析实验数据。
- 透明可溯:借助原生可视化功能,清晰复盘智能体的每一步推理与行动轨迹,快速定位并优化决策短板。
Science-Star 让科研人员从零摩擦地构建、扩展和验证科学 AI 智能体,将原本数月的工程搭建期缩短为几天的实验迭代期。
运行环境要求
- 未说明
未说明
未说明

快速开始
🌟 Science-Star — 您的科学AI智能体
构建、扩展并实验科学智能体。一个平台,零摩擦。



由通义万相生成。
📢 新闻
近期更新
- [2026.02] 重大更新: 更多基准支持,多智能体架构(CodeAgent + 搜索智能体),重构运行脚本(
run_multi_agent.py/run_single_agent.py),以及更 streamlined的项目结构。 - [2025.08] Science-Star 启动: 我们发布了 Science-Star — 一个用于构建、扩展和实验科学智能体的开源平台。
🧠 概述
Science-Star 是您的开源科学AI智能体平台。基于带有规划、行动、记忆和反思功能的 ReAct 引擎构建,它自带 人类最后考试 (HLE) 和 GAIA 基准测试、丰富的工具集(搜索、爬取、PDF、浏览器、RAG)以及端到端可视化功能。只需一条命令即可运行,一个平台即可扩展——无论您是研究人员还是开发者,Science-Star 都能让您快速从想法走向实验。
也请查看 Awesome-Agent-Craft:我们精心整理的关于释放科学AI智能体潜力的论文和基准测试合集。
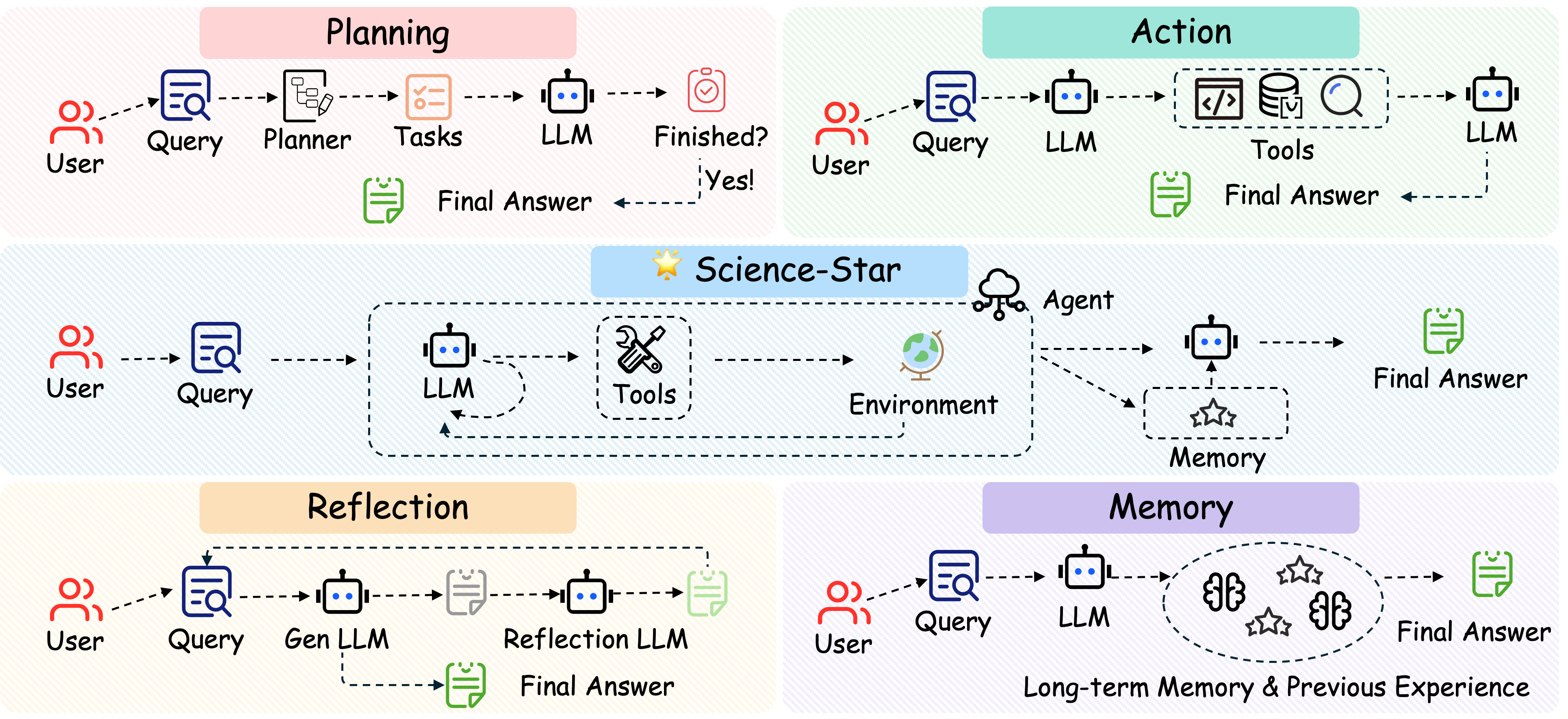
🔥 核心特性
- 🔧 丰富工具箱 — 搜索(SerpAPI、Tavily、DuckDuckGo、Wayback)、爬取(Jina、crawl4ai)、PDF解析器、浏览器使用、检查器(文档/音频/视觉)、检索器(RAG)、代码执行。可通过简洁界面添加您自己的工具。
- 🤖 多智能体与模块化 — 开箱即用的 CodeAgent + 搜索智能体。只需一个配置即可在单智能体与多智能体之间切换。更换加载器、模型、工具时,核心逻辑保持不变。
- 📊 HLE & GAIA + 可视化 — 一键式基准测试,配备加载器和评分器。Streamlit仪表盘用于数据探索和结果分析。无需任何设置。
🚩 路线图
- 领域工具: 化学、生物学及其他科学工具包
- 更多架构: 不止于 ReAct — 新型智能体范式
- 更多基准: 额外的数据集和评估套件
🚀 开始使用
- 配置环境 — conda、smolagents、API密钥及测试。→ 安装指南
- 运行实验 — 一键运行 HLE 和 GAIA,自定义配置,启动可视化仪表盘。→ 快速入门
- 探索架构 — 工具、加载器、RAG、配置及其连接方式。→ 项目结构
🛠️ 扩展
- 工具:
science_star/tools/— 搜索、爬取、PDF、浏览器、检索器 - 加载器:
data/hle_loader.py、data/gaia_loader.py - 可视化:
visualization/vis_dataset.py、visualization/vis_output.py
🧪 实验结果
以 o4-mini-2025-04-16 作为基础模型,我们通过实现一个利用 ReAct 框架并集成 规划、行动、记忆和反思 模块的 端到端流水线,在小规模 HLE 数据集上取得了领先成果。该项目仍需进一步测试和完善。我们诚挚邀请开源社区加入我们,共同塑造这项工作的未来。让我们携手共建!
ℹ️ 反馈
我们欢迎任何形式的反馈!如遇bug、疑问或建议,请提交issue。这将帮助我们的团队高效解决常见问题,并构建更加高效的社区。
🤝 贡献者
学生贡献者: Daoyu Wang、Qingchuan Li、Tian Gao、Shuo Yu、Xiaoyu Tao、Ze Guo
指导老师: Qi Liu、Mingyue Cheng
所属单位: 中国科学技术大学认知智能国家重点实验室
🥰 致谢
我们衷心感谢 OAgent 提供的 OAgent 以及他们在工程方面的辛勤付出。同时,我们也感谢 smolagent 团队提供的基础支持。最后,我们深深感激 Daoyu Wang、Qingchuan Li、Tian Gao、Shuo Yu、Xiaoyu Tao 和 Ze Guo 的富有洞见的讨论与贡献。
✍️ 引用
Science-Star
@misc{Science-Star,
author = {Daoyu Wang, Qingchuan Li, Tian Gao, Shuo Yu, Xiaoyu Tao, Mingyue Cheng, Qi Liu},
title = {Science-Star: 一个用于构建、扩展和实验科学智能体的开源平台。},
year = {2025},
organization = {GitHub},
url = {https://github.com/Melmaphother/Science-Star},
}
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。