ChatPaper2Xmind
ChatPaper2Xmind 是一款专为科研工作者打造的智能辅助工具,旨在将复杂的学术论文 PDF 快速转化为结构清晰的 XMind 思维导图。它利用 ChatGPT 等大语言模型,自动提取论文的核心观点、关键公式及图表,并整合成一份带有视觉元素的简要笔记草稿。
面对海量文献阅读效率低、重点难以捕捉的痛点,ChatPaper2Xmind 能帮助研究人员在几分钟内梳理出论文的骨架与精华,大幅缩短初步筛选和理解文献的时间。需要注意的是,受限于当前生成模型的准确性,其产出更适合作为深入阅读的“导航图”或笔记初稿,建议用户在此基础上进行人工校对与完善,而非直接替代原文阅读。
该工具特别适合高校研究生、科研人员及需要频繁处理英文文献的学者使用。其技术亮点在于不仅支持文本摘要,还能通过集成 PDFFigure2 等组件,智能识别并截取论文中的公式与插图(含标题),甚至支持配置本地模型或伪 API 以灵活适应不同的网络环境与成本需求。无论是想要快速把握领域动态,还是希望建立个人知识库,ChatPaper2Xmind 都能成为你高效的科研助手。
使用场景
某高校计算机系研究生李明正在准备开题报告,需要在三天内快速梳理 20 篇关于“大模型推理优化”的最新顶会论文,以构建技术路线图。
没有 ChatPaper2Xmind 时
- 阅读效率低下:面对每篇几十页的 PDF,必须从头到尾通读才能抓住重点,单篇耗时超过 2 小时,难以在规定期限内完成文献综述。
- 笔记整理繁琐:手动摘录核心观点、公式和图片到 Word 或 XMind 中,不仅打字耗时,还容易在复制粘贴过程中弄错公式符号或遗漏图表上下文。
- 逻辑结构混乱:由于缺乏全局视角,初期整理的笔记往往是零散的知识点堆砌,难以快速理清论文内部的层级逻辑和论证脉络。
- 关键信息遗漏:在疲劳阅读状态下,极易忽略隐藏在长段落中的关键实验数据或创新点,导致后续复现或引用时出现偏差。
使用 ChatPaper2Xmind 后
- 极速提取概要:将 PDF 拖入工具,ChatPaper2Xmind 自动调用 GPT 模型在几分钟内生成包含摘要、引言及结论的结构化大纲,单篇处理时间缩短至 10 分钟以内。
- 图文公式完整保留:工具自动识别并截取论文中的关键架构图、实验数据表及核心数学公式,直接嵌入 XMind 节点,无需手动截图或重新录入 LaTeX 代码。
- 逻辑脉络清晰可视:生成的 XMind 文件天然具备树状层级结构,清晰展示“问题定义 - 方法创新 - 实验验证”的逻辑链条,李明可直接在此基础上修改完善。
- 辅助草稿高效迭代:虽然官方提示生成内容需作为草稿校对,但这已解决了 80% 的基础整理工作,让李明能将精力集中在深度思考与批判性分析上。
ChatPaper2Xmind 通过将非结构化的 PDF 论文一键转化为可视化的思维导图草稿,把科研人员从机械的摘录工作中解放出来,实现了文献阅读效率的质的飞跃。
运行环境要求
- Windows
- macOS
- Linux
未说明
未说明

快速开始

ChatPaper2XMind
中文|English
ChatPaper2XMind论文XMind笔记生成工具:使用ChatGPT将PDF转换为带有图片和公式的简洁XMind笔记,提高阅读效率。
注意:受限于ChatGPT生成模型准确性,生成的Xmind笔记更适合作为笔记草稿,在此基础上制作阅读笔记,而不能直接将其当做论文阅读。
目录
功能展示

安装与使用
Release版本
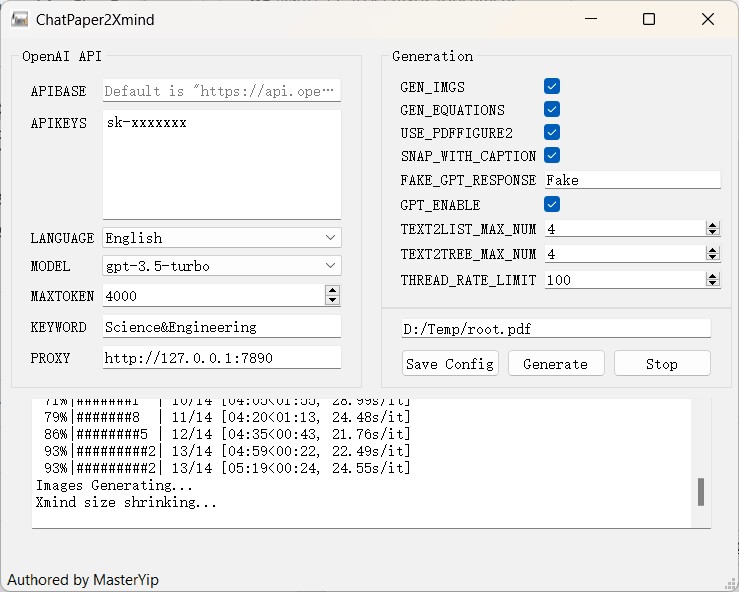
设置选项含义详见源码config.py.
拖拽pdf文件或包含pdf的文件夹至输入框中,即可一键生成。
源码运行
1. 环境设置
git clone --recursive https://github.com/MasterYip/ChatPaper2Xmind.git
cd <work-dir>
pip install -r requirements.txt
pip install -r ./XmindCopilot/requirements.txt
2. Config配置(config.py)
OpenAI API设置
"""OpenAI API"""
APIBASE = "" # OpenAI API base, default is "https://api.openai.com/v1" for now (Leave it as empty if you are not sure)
APIKEYS = [""] # Your OpenAI API keys
MODEL = "gpt-3.5-turbo" # GPT model name
LANGUAGE = "English" # Only partially support Chinese
KEYWORD = "Science&Engineering" # Keyword for GPT model (What field you want the model to focus on)
PROXY = None # Your proxy address
# Note: If you are in China, you may need to use a proxy to access OpenAI API
# (If your system's global proxy is set, you can leave it as None)
# PROXY = "http://127.0.0.1:7890"
- APIBASE: OpenAI模型请求服务器URL
- 可以更换为任意支持openai请求格式的模型(ChatGLM/LLaMA等)
- APIKEYS(必须配置): 用于OpenAI模型请求的APIKEY
- 可添加多个APIKEY,支持多线程请求
- 如使用其他模型,APIKEYS的列表长度决定了请求线程数量,内容可为任意值
- 没有APIKEY的同学可以参考ChatGPT_API_NoKey配置伪API服务器,并更改openai.api_base来实现伪API访问,此情况下APIKEY需设置任意值(不能为空)
- MODEL: OpenAI模型选择
- LANGUAGE: 生成语言
- KEYWORD: 论文所属领域
- PROXY: 代理服务器
- 如果你在中国地区,可能需要使用代理访问OpenAI官网
- 保留为None时,将跟随系统全局代理
生成格式设置
"""Generation"""
GEN_IMGS = True
GEN_EQUATIONS = True
# PDFFigure2
USE_PDFFIGURE2 = True # Use PDFFigure2 to generate images & tables (This requires you to install JVM)
SNAP_WITH_CAPTION = True # Generate images & tables with caption (Only valid when USE_PDFFIGURE2 is True)
# Max generation item number
TEXT2LIST_MAX_NUM = 4 # Max number of items for each list
TEXT2TREE_MAX_NUM = 4 # Max number of subtopics for each topic
FAKE_GPT_RESPONSE = "Fake" # Fake GPT response when GPT_ENABLE is False
if True: # Use true GPT model
GPT_ENABLE = True
THREAD_RATE_LIMIT = 100 # Each APIKEY can send 3 requests per minute (limited by OpenAI)
else: # Use fake GPT model
GPT_ENABLE = False
THREAD_RATE_LIMIT = 6000
- GEN_IMGS: 捕获并生成论文图片
- GEN_EQUATIONS: 捕获并生成论文公式
- USE_PDFFIGURE2: 使用PDFFIGURE2来捕获论文图片 (需要Java环境,如没有安装Java环境,请设置为False)
- SNAP_WITH_CAPTION: USE_PDFFIGURE2为True时,截取图片以及图片标题
- TEXT2LIST_MAX_NUM(暂时无效)
- TEXT2TREE_MAX_NUM(暂时无效)
- FAKE_GPT_RESPONSE: 不使用ChatGPT时的伪GPT响应
- GPT_ENABLE: 是否使用GPT
- 如不使用ChatGPT生成文本概要,仅生成论文目录以及图片公式,可将其设置为False
- THREAD_RATE_LIMIT: 单个线程(单个APIKEY)的每分钟请求次数
- OpenAI对请求频率存在限制,普通套餐通常为3/min
PDF标题/公式/图片/表格匹配设置
"""PDF Parser - Regular Expression"""
# Special title
ABS_MATCHSTR = "ABSTRACT|Abstract|abstract"
INTRO_MATCHSTR = "I.[\s]{1,3}(INTRODUCTION|Introduction|introduction)"
REF_MATCHSTR = "Reference|REFERENCE|Bibliography"
APD_MATCHSTR = "APPENDIX|Appendix" # Not used for now
# General title
# FIXME: Misidentification exists
SECTION_TITLE_MATCHSTR = ["[IVX1-9]{1,4}[\.\s][\sA-Za-z]{1,}|[1-9]{1,2}[\s\.\n][\sA-Za-z]{1,}", # Level 1
"[A-M]{1}\.[\sA-Za-z]{1,}|[1-9]\.[1-9]\.[\sA-Za-z]{1,}"] # Level 2
# Equation & Image
EQUATION_MATCHSTR = '[\s]{0,}\([\d]{1,}[a-zA-Z]{0,1}\)'
IMG_MATCHSTR = 'Fig.[\s]{1,3}[\d]{1,2}|Figure[\s]{1,3}[\d]{1,2}|Tab.[\s]{1,3}[\dIVX]{1,3}|Table[\s]{1,3}[\dIVX]{1,3}' # Figure & Table
Xmind风格模板
"""Xmind Sytle Template"""
TEMPLATE_XMIND_PATH = 'template.xmind'
调试信息
"""Debuging"""
DEBUG_MODE = False
3. 开箱使用
将PDF论文转换为XMind
cd <root-dir>
python paper2xmind.py --path <pdf路径或pdf文件夹路径>
运行演示
python paper2xmind.py
常见错误
1.'PDFFigure2PaperParser' object has no attribute 'pdf'
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
Exception ignored in: <function PDFPaperParser.del at 0x000001F4388C2C00>
Traceback (most recent call last):
File "D:\git\ChatPaper2Xmind\pdf_parser.py", line 31, in del
self.pdf.close()
^^^^^^^^
AttributeError: 'PDFFigure2PaperParser' object has no attribute 'pdf'
- PDF输入路径有误
- PDF文件不存在
- 输入路径包含空格,没有用双引号括起来
- 没有安装Java环境,且使用PDFFIGURE2生成图片
- 设置USE_PDFFIGURE2=False 或 安装Java环境并添加至系统环境变量PATH
2.ImportError: cannot import name 'xmind' from 'XmindCopilot' (unknown location)
Traceback (most recent call last):
File "D:\academic chatgpt series\ChatPaper2Xmind-main\paper2xmind.py", line 3, in
from XmindCopilot import xmind, fileshrink
ImportError: cannot import name 'xmind' from 'XmindCopilot' (unknown location)
- Git未正常拉取XmindCopilot仓库
- 需正确执行环境配置
git clone --recursive https://github.com/MasterYip/ChatPaper2Xmind.git
cd <work-dir>
pip install -r requirements.txt
pip install -r ./XmindCopilot/requirements.txt
未来工作
- 减少GPT请求次数以加快XMind生成速度
- 添加元数据和资源解析功能
- 添加Markdown笔记生成功能
- 优化公式检测(边界检测)
鸣谢
感谢以下项目对本项目的宝贵贡献:
以及其他不小心被忽略的项目 :)
特别感谢开源社区和所有为该项目作出贡献的贡献者。
许可证
本项目在MIT许可下发布。有关详细信息,请参阅LICENSE文件。
作者
Master Yip
电子邮件:2205929492@qq.com
GitHub:Master Yip
QQ 交流群:

加群验证问题答案:Github
版本历史
ChatPaper2Xmind-x64-v1.0.0-alpha2023/10/08常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。