AttGAN-Tensorflow
AttGAN-Tensorflow 是一个基于 TensorFlow 实现的人脸属性编辑开源项目,源自发表于 IEEE TIP 2019 的研究工作。它能对人脸图像进行精准的语义级编辑——比如添加眼镜、改变发色、调整年龄感等——同时尽可能保留其他无关特征不变,真正做到“只改你想改的部分”。传统方法在修改某一属性时容易影响面部其他区域,而 AttGAN 通过引入注意力机制和对抗训练策略,显著提升了编辑的局部性和可控性。该项目适合计算机视觉领域的研究人员和 AI 开发者使用,尤其适用于对生成模型、人脸编辑或 GAN 技术感兴趣的技术人群。虽然普通用户也可尝试运行示例,但需具备一定 Python 和深度学习环境配置经验。代码支持 CelebA 数据集,并提供了包含多达 40 种属性的高分辨率编辑效果,是探索可控图像生成的实用起点。
使用场景
某影视后期工作室正在为一部年代剧制作角色年龄变化特效,需要将同一演员在不同年龄段的面部特征(如皱纹、发色、胡须等)进行精准调整,同时保留其原始五官结构和表情。
没有 AttGAN-Tensorflow 时
- 只能依赖传统图像编辑软件手动绘制或使用通用滤镜,难以精准控制单一属性(如仅添加胡须而不改变肤色或发型)。
- 若使用早期GAN模型,往往导致面部整体失真,例如修改“年轻化”时连带改变了眼睛形状或脸型,破坏角色辨识度。
- 需要大量人工反复调试参数,单帧图像处理耗时长达数小时,严重影响项目进度。
- 缺乏对多属性组合编辑的支持,无法高效生成“棕发+戴眼镜+无胡须”等复合效果。
- 团队需额外聘请专业美工人员配合,人力成本高且风格难以统一。
使用 AttGAN-Tensorflow 后
- 可通过指定属性标签(如 Young=0, Mustache=1)精确编辑目标特征,其余面部区域几乎无扰动,保持角色一致性。
- 基于预训练模型快速生成高质量结果,单张图像处理仅需几秒,大幅提升制作效率。
- 支持40种面部属性自由组合,轻松实现复杂年代造型需求,无需逐项手动合成。
- 开源代码便于集成到现有自动化流水线中,减少对外部美术资源的依赖。
- 输出结果自然逼真,在高清镜头下仍保持细节真实感,满足影视级视觉要求。
AttGAN-Tensorflow 让影视团队以极低成本实现精准、高效的面部属性编辑,真正做到了“只改想要的部分”。
运行环境要求
- Linux
- macOS
- Windows
推荐 NVIDIA GPU(使用 tensorflow-gpu=1.15),显存未明确说明,CUDA 版本需兼容 TensorFlow 1.15(通常为 CUDA 10.0 或 10.1)
未说明

快速开始



AttGAN
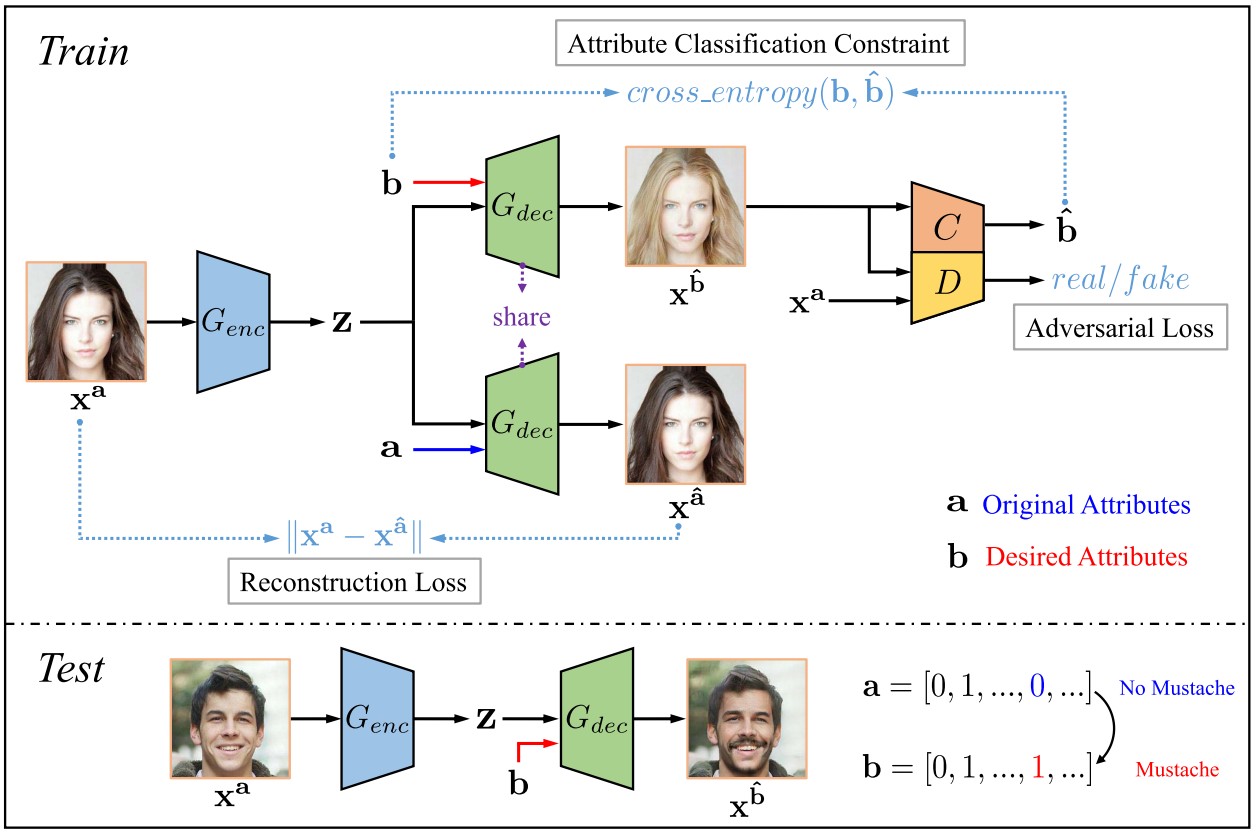
AttGAN: Facial Attribute Editing by Only Changing What You Want(仅修改你想要的面部属性)
Zhenliang He1,2, Wangmeng Zuo4, Meina Kan1, Shiguang Shan1,3, Xilin Chen1
1中国科学院计算技术研究所智能信息处理重点实验室,中国
2中国科学院大学,中国
3中国科学院脑科学与智能技术卓越创新中心,中国
4哈尔滨工业大学计算机科学与技术学院,中国
相关项目
AttGAN 的其他实现
AttGAN-PyTorch by Yu-Jing Lin
AttGAN-PaddlePaddle by ceci3 和 zhumanyu(AttGAN 是 PaddlePaddle 官方复现模型之一)
密切相关的研究工作
基于我们代码的优秀工作 - STGAN (CVPR 2019) by Ming Liu
Changing-the-Memorability (CVPR 2019 MBCCV Workshop) by acecreamu
Fashion-AttGAN (CVPR 2019 FSS-USAD Workshop) by Qing Ping
王一凡制作的非官方 演示视频
示例结果
更多结果请参见 results.md,我们尝试了更高分辨率和更多属性(全部 40 个属性!!!)
分别对 13 个属性进行编辑
从左到右依次为:输入图像、重建图像、秃头(Bald)、刘海(Bangs)、黑发(Black_Hair)、金发(Blond_Hair)、棕发(Brown_Hair)、浓眉(Bushy_Eyebrows)、眼镜(Eyeglasses)、男性(Male)、微张嘴(Mouth_Slightly_Open)、胡子(Mustache)、无胡须(No_Beard)、苍白皮肤(Pale_Skin)、年轻(Young)

使用方法
环境要求
Python 3.6
TensorFlow 1.15
OpenCV、scikit-image、tqdm、oyaml
我们推荐使用 Anaconda 或 Miniconda,然后通过以下命令创建 AttGAN 环境
conda create -n AttGAN python=3.6 source activate AttGAN conda install opencv scikit-image tqdm tensorflow-gpu=1.15 conda install -c conda-forge oyaml注意:如果你创建了一个新的 conda 环境,请在执行其他任何命令前先激活该环境
source activate AttGAN
数据准备
选项 1: CelebA-unaligned(质量高于对齐版本,10.2GB)
下载数据集
img_celeba.7z(移至 ./data/img_celeba/img_celeba.7z): Google Drive 或 百度网盘(密码 rp0s)
annotations.zip(移至 ./data/img_celeba/annotations.zip): Google Drive
解压并处理数据
7z x ./data/img_celeba/img_celeba.7z/img_celeba.7z.001 -o./data/img_celeba/ unzip ./data/img_celeba/annotations.zip -d ./data/img_celeba/ python ./scripts/align.py
选项 2: CelebA-HQ(我们使用来自 CelebAMask-HQ 的数据,3.2GB)
CelebAMask-HQ.zip(移至 ./data/CelebAMask-HQ.zip): Google Drive 或 百度网盘
解压并处理数据
unzip ./data/CelebAMask-HQ.zip -d ./data/ python ./scripts/split_CelebA-HQ.py
运行 AttGAN
训练(更多训练命令请参见 examples.md)
\\ for CelebA CUDA_VISIBLE_DEVICES=0 \ python train.py \ --load_size 143 \ --crop_size 128 \ --model model_128 \ --experiment_name AttGAN_128 \\ for CelebA-HQ CUDA_VISIBLE_DEVICES=0 \ python train.py \ --img_dir ./data/CelebAMask-HQ/CelebA-HQ-img \ --train_label_path ./data/CelebAMask-HQ/train_label.txt \ --val_label_path ./data/CelebAMask-HQ/val_label.txt \ --load_size 128 \ --crop_size 128 \ --n_epochs 200 \ --epoch_start_decay 100 \ --model model_128 \ --experiment_name AttGAN_128_CelebA-HQ测试
单个属性编辑(反演)
\\ for CelebA CUDA_VISIBLE_DEVICES=0 \ python test.py \ --experiment_name AttGAN_128 \\ for CelebA-HQ CUDA_VISIBLE_DEVICES=0 \ python test.py \ --img_dir ./data/CelebAMask-HQ/CelebA-HQ-img \ --test_label_path ./data/CelebAMask-HQ/test_label.txt \ --experiment_name AttGAN_128_CelebA-HQ多个属性编辑(反演)示例
\\ for CelebA CUDA_VISIBLE_DEVICES=0 \ python test_multi.py \ --test_att_names Bushy_Eyebrows Pale_Skin \ --experiment_name AttGAN_128属性滑动(attribute sliding)示例
\\ for CelebA CUDA_VISIBLE_DEVICES=0 \ python test_slide.py \ --test_att_name Pale_Skin \ --test_int_min -2 \ --test_int_max 2 \ --test_int_step 0.5 \ --experiment_name AttGAN_128
损失可视化
CUDA_VISIBLE_DEVICES='' \ tensorboard \ --logdir ./output/AttGAN_128/summaries \ --port 6006将训练好的模型转换为 .pb 文件
python to_pb.py --experiment_name AttGAN_128
使用预训练权重
其他预训练权重(移至 ./output/*.zip)
AttGAN_128.zip(987.5MB)
- 包含生成器 G、判别器 D 以及优化器的状态
AttGAN_128_generator_only.zip(161.5MB)
- 仅包含生成器 G
AttGAN_384_generator_only.zip(91.1MB)
解压文件(以 AttGAN_128.zip 为例)
unzip ./output/AttGAN_128.zip -d ./output/测试(参见上文)
自定义数据集示例
引用
如果您在研究工作中使用了 AttGAN,请考虑引用以下论文:
@ARTICLE{8718508,
author={Z. {He} and W. {Zuo} and M. {Kan} and S. {Shan} and X. {Chen}},
journal={IEEE Transactions on Image Processing},
title={AttGAN: Facial Attribute Editing by Only Changing What You Want},
year={2019},
volume={28},
number={11},
pages={5464-5478},
keywords={Face;Facial features;Task analysis;Decoding;Image reconstruction;Hair;Gallium nitride;Facial attribute editing;attribute style manipulation;adversarial learning},
doi={10.1109/TIP.2019.2916751},
ISSN={1057-7149},
month={Nov},}
版本历史
v12020/01/03常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中