Openaibot
Openaibot 是一款专为构建自定义 AI 聊天机器人设计的开源框架,支持快速部署到 Discord、Slack、Kook 和 Telegram 等主流社交平台。它核心解决了开发者在多平台集成大语言模型(如 GPT-4o)时面临的架构复杂与扩展困难问题,提供了一套“开箱即用”的解决方案。
该项目特别适合具备一定 Python 基础的开发者和技术爱好者使用。通过内置的消息队列与快照系统,Openaibot 实现了消息处理逻辑的完全解耦,确保在高并发场景下的稳定性。其独特的技术亮点在于高度模块化的插件生态:用户可通过 pip 轻松安装插件,并拥有细粒度的权限控制能力,包括在执行前进行身份验证及动态配置环境变量。此外,工具原生支持视觉识别、语音合成(TTS)及代码解释器功能,并能灵活适配符合 OpenAI 格式标准的各类模型网关。
尽管目前项目主要处于维护阶段不再规划新功能,但其精简的代码结构和成熟的第四代架构,依然是学习事件驱动型 LLM 应用开发或搭建私有化机器人服务的优秀参考范本。
使用场景
某初创游戏工作室的社区运营团队需要在 Discord、Telegram 和 Kook 等多个平台上,为玩家提供基于 GPT-4o 的 24 小时智能客服及游戏数据查询服务。
没有 Openaibot 时
- 多平台重复开发:团队需为每个社交平台单独编写机器人代码,维护三套不同的逻辑,导致人力成本极高且功能更新不同步。
- 高级功能实现困难:想要让机器人具备“识图分析玩家截图”或“执行代码查询数据库”的能力,需要自行对接复杂的 Vision 模型和沙箱环境,技术门槛过高。
- 插件管理混乱:缺乏统一的插件机制,每次新增功能(如签到、攻略查询)都需修改核心代码,容易引发系统崩溃且无法动态加载。
- 鉴权流程繁琐:难以在不同平台实施统一的用户身份验证,导致付费会员权益无法精准管控,存在数据泄露风险。
使用 Openaibot 后
- 一次部署多端同步:利用 Openaibot 的多平台继承特性,仅需配置一套后端即可同时服务于 Discord、Telegram 和 Kook,新功能上线即时全平台生效。
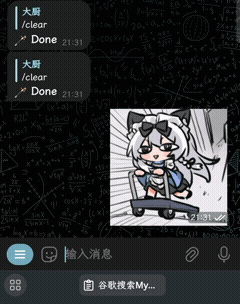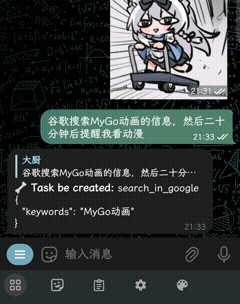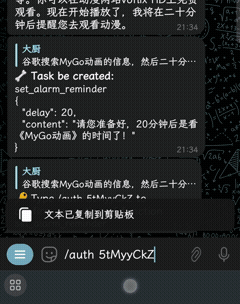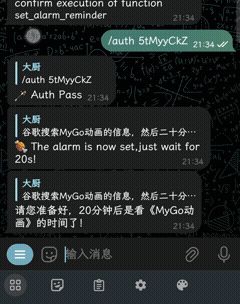
- 开箱即用的高级能力:直接启用内置的 Vision 和代码解释器插件,机器人能自动识别玩家上传的游戏报错截图并运行代码检索日志,无需额外开发。
- 灵活的插件生态:通过
pip安装即可无缝集成社区插件,支持在会话中动态加载特定功能,既丰富了玩法又避免了性能损耗。 - 安全的 URL 鉴权体系:利用独特的 URL 登录机制,轻松实现跨平台的统一身份认证,确保只有授权用户才能调用高阶查询插件,保障数据安全。
Openaibot 将原本需要数周搭建的多模态跨平台机器人工程,简化为小时级的配置任务,让团队能专注于内容运营而非底层架构。
运行环境要求
- Linux
未说明
未说明
快速开始

![]()


Python>=3.9
该项目并未被放弃,只是目前暂无新功能计划。
本项目作为MQ事件驱动LLM的实验性项目而开发。
如遇问题,请提交Issue。
如果您正在寻找类似项目,请查看:https://github.com/AstrBotDevs/AstrBot
它集成了消息队列和快照系统,提供插件机制以及在插件执行前的身份验证功能。
该机器人遵循OpenAI格式规范。请使用gateway或one-api进行独立适配。
| 演示 | 视觉与语音 | 代码解释器 |
|---|---|---|
 |
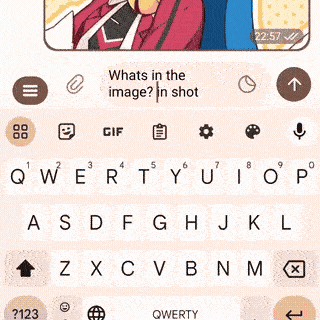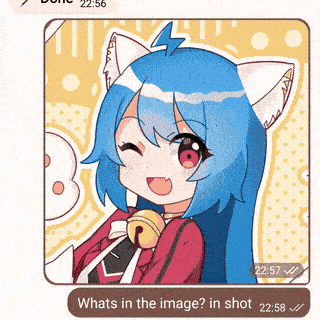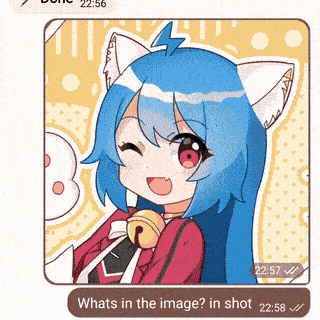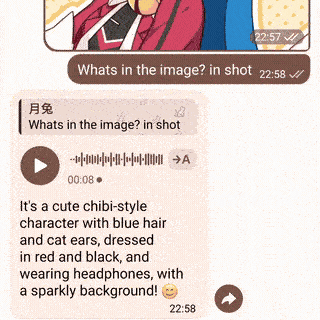 |
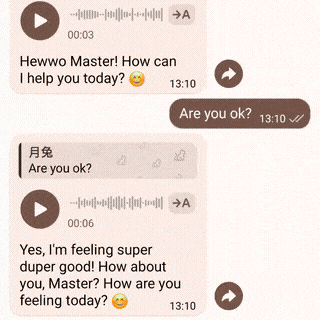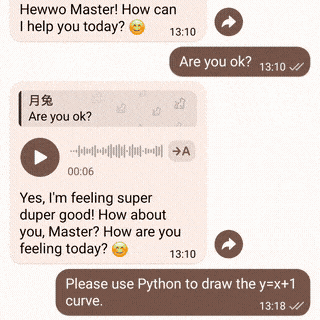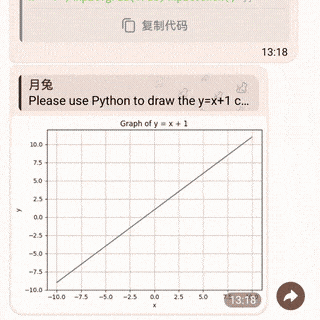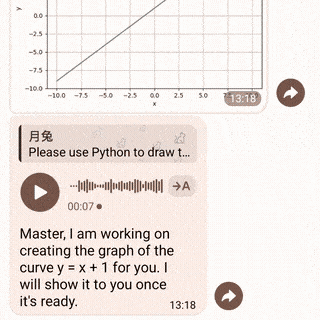 |
🔨 路线图
程序已迭代至第四代。
- 移除遗留代码
- 删除度量系统
- 删除模型选择系统,统一为OpenAI Schema
- 实现更健壮的插件系统
- 简化项目结构
- 取消Provider系统
- 支持钩子
- 接入TTS
- 增加对gpt-4-turbo和视觉功能的独立支持
- 在插件环境中添加LLM引用支持。(文本提取&&搜索)
📦 特性
- 🍪 全面的插件开发生态,采用经典设计,可通过
pip安装无缝集成插件 - 📝 无时间与发送者限制的消息系统,逻辑完全解耦
- 📬 提供URL登录机制,为身份验证开发提供灵活且可扩展的解决方案
- 🍰 允许用户授权插件执行。用户可自行配置插件环境变量
- 📦 支持插件访问文件
- 🍟 多平台支持——通过继承基类即可扩展新平台
- 🍔 插件可在新会话中动态决定自身是否加载,从而避免因插件数量过多而导致性能下降
🍔 登录方式
URL登录: 使用/login <一个token>$<类似https://provider.com/login的东西>进行登录。程序会将token发送到接口以获取配置信息,如何开发此功能。直接登录: 使用/login https://<api端点>/v1$<api密钥>$<模型>$<工具模型如gpt-3.5-turbo>进行登录。
🧀 插件能做的事更多
| 贴纸转换 | 定时功能(内置) |
|---|---|
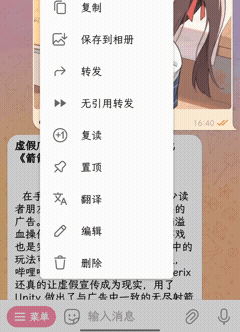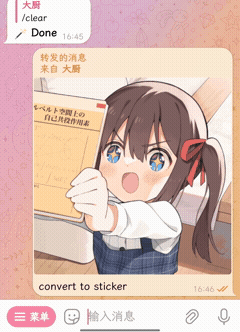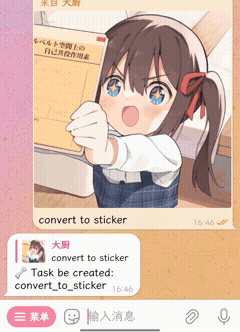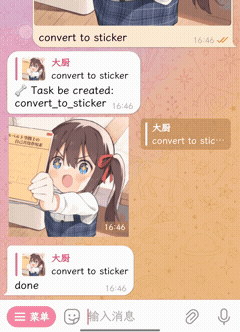 |
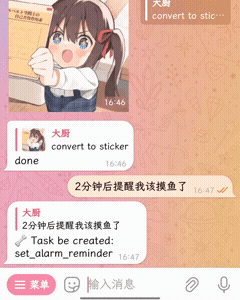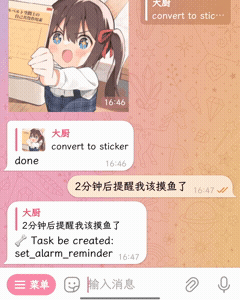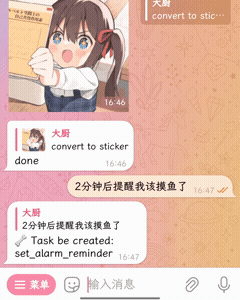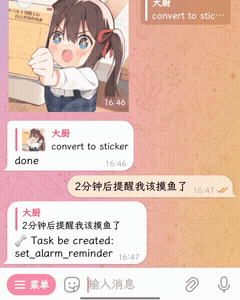 |
🎬 平台支持
| 平台 | 支持 | 文件系统 | 备注 |
|---|---|---|---|
| Telegram | ✅ | ✅ | |
| Discord | ✅ | ✅ | |
| Kook | ✅ | ✅ | 不支持“回复触发” |
| Slack | ✅ | ✅ | 不支持“回复触发” |
| Line | ❌ | ||
| ❌ | |||
| ❌ | |||
| ❌ | |||
| Matrix | ❌ | ||
| IRC | ❌ | ||
| ... | 请创建Issue/PR |
📦 快速开始
更多信息请参阅🧀 部署文档。
📦 一键部署
如果您使用的是全新服务器,可以使用以下Shell脚本自动安装本项目。
curl -sSL https://raw.githubusercontent.com/LLMKira/Openaibot/main/deploy.sh | bash
📦 手动安装
# 安装语音依赖
apt install ffmpeg
# 安装RabbitMQ
docker pull rabbitmq:3.10-management
docker run -d -p 5672:5672 -p 15672:15672 \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=8a8a8a \
--hostname myRabbit \
--name rabbitmq \
rabbitmq:3.10-management
docker ps -l
# 安装项目
git clone https://github.com/LlmKira/Openaibot/
cd Openaibot
pip install pdm
pdm install -G bot
cp .env.exp .env && nano .env
# 测试
pdm run python3 start_sender.py
pdm run python3 start_receiver.py
# 上线
apt install npm
npm install pm2 -g
pm2 start pm2.json
请务必更改默认密码,或关闭开放端口,以防止数据库被扫描和攻击。
🥣 Docker
构建中心:sudoskys/llmbot
请注意,如果您使用 Docker 运行该项目,将会启动 Redis、MongoDB 和 RabbitMQ。但如果您在本地运行,则只需启动 RabbitMQ。
手动 Docker-compose 安装
git clone https://github.com/LlmKira/Openaibot.git
cd Openaibot
cp .env.exp .env&&nano .env
docker-compose -f docker-compose.yml up -d
Docker 配置文件 docker-compose.yml 包含所有数据库。实际上,Redis 和 MongoDB 并不是必需的。您可以自行移除这些数据库,并使用本地文件系统。
使用 docker-compose pull 更新镜像。
使用 docker exec -it llmbot /bin/bash 进入 Docker 中的 Shell,输入 exit 退出。
🍪 斜杠命令
clear - 删除聊天记录
login - 登录机器人
help - 显示文档
chat - 对话
task - 使用功能进行对话
ask - 禁用基于功能的对话
tool - 列出所有功能
auth - 授权某个功能
env - 功能的环境变量
learn - 学习您的指令,/learn reset 可以清空
💻 如何开发插件?
请参考 plugins 目录中的示例插件,以及 🧀 插件开发文档 获取插件开发的相关说明。
钩子
钩子用于控制发送者和接收者之间的 EventMessage。例如,我们内置了 voice_hook 钩子。
您可以通过在 .env 文件中设置 VOICE_REPLY_ME=true 来启用它。
/env VOICE_REPLY_ME=yes
# 必须
/env REECHO_VOICE_KEY=<key in dev.reecho.ai>
# 不必
使用 /env VOICE_REPLY_ME=NONE 可以禁用此环境变量。
请查看 llmkira/extra/voice_hook.py 中的源代码,学习如何编写您自己的钩子。
🧀 赞助

📜 注意事项
本项目名为 OpenAiBot,意为“开放人工智能机器人”,与 OpenAI 并无官方关联。

版本历史
pypi_1.0.52024/04/29pypi_1.0.42024/04/22app_4.0.42024/04/20pypi_1.0.32024/04/20app_4.0.32024/04/19pypi_1.0.22024/04/18app_4.0.22024/04/18app_4.0.12024/04/18pypi_1.0.12024/04/17app_4.0.0_patch2024/04/17pypi_1.0.02024/04/17app_4.0.02024/04/17pypi0.27.32024/01/17pypi0.27.22023/11/14lib0.27.12023/11/12nolib0.27.0_52023/11/12nolib0.27.0_42023/11/12nolib0.27.0_32023/11/12nolib0.27.0_12023/11/11lib0.27.02023/11/11常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。