Llama-Chinese
Llama-Chinese 是专注于构建中文大模型开源生态的社区平台,致力于让全球开发者都能轻松使用和优化 Llama 系列模型。它解决了原生 Llama 模型在中文语境下理解与生成能力不足、国内开发者获取高质量中文微调资源困难等痛点。
无论是希望快速上手的初学者,还是深耕算法的研究人员,亦或是需要部署落地方案的企业开发者,都能在这里找到所需支持。平台不仅实时汇总最新的 Llama 学习资料与论文解读,更提供了从数据准备、环境搭建到模型微调(支持 LoRA 及全量参数)、量化加速及多框架部署(如 vLLM、TensorRT-LLM)的全流程指南。
其独特亮点在于推出了基于 Llama 架构深度优化的中文预训练模型"Atom",显著提升了中文处理性能;同时社区由资深 NLP 工程师团队维护,提供低于市场价的算力资源、丰富的中文训练数据集以及专业的技术咨询。通过开放共享的代码库与活跃的论坛交流,Llama-Chinese 正推动着中文 NLP 技术的普惠发展,助力用户高效构建属于自己的中文大模型应用。
使用场景
某电商初创公司的算法团队急需构建一个能精准理解中文网络用语和客服话术的智能问答机器人,以应对大促期间的高并发咨询。
没有 Llama-Chinese 时
- 语言水土不服:直接加载原生 Llama 模型,面对“亲”、“种草”、“拔草”等中文特有词汇时理解偏差大,回答生硬且充满翻译腔。
- 资料分散难寻:团队需花费数天在 GitHub、Hugging Face 和各技术博客间碎片化搜集中文微调教程、数据集和适配代码,效率极低。
- 部署门槛过高:缺乏针对中文场景优化的量化方案和推理加速指南,导致模型在有限算力下响应缓慢,难以落地生产环境。
- 商用合规风险:难以快速确认不同版本模型的开源协议细节,担心陷入版权纠纷,阻碍项目正式上线。
使用 Llama-Chinese 后
- 原生中文增强:直接调用社区提供的 Atom 中文预训练模型或经过中文指令微调的 Llama3 版本,模型瞬间掌握本土化表达,回复自然流畅。
- 资源一站聚合:通过社区汇总的最新学习资料和现成脚本,团队在几小时内即可完成从数据准备到 LoRA 微调的全流程,研发周期缩短 70%。
- 高效部署加速:利用社区整理的 TensorRT-LLM 和 vLLM 中文适配方案,轻松实现模型量化与加速,在低成本显卡上也能支撑高并发请求。
- 生态安全无忧:依托社区明确的完全开源可商用声明及活跃的技术支持论坛,团队放心大胆地推进商业化应用,遇到问题能迅速获得高级工程师解答。
Llama-Chinese 通过提供深度优化的中文模型底座与全链路开源生态,让开发者从繁琐的适配工作中解放,专注于业务价值的创造。
运行环境要求
- Linux
- macOS
- Windows
- 推理和微调通常需要 NVIDIA GPU
- 具体显存需求取决于模型大小:7B 模型量化后需 6-8GB,全量微调 7B 建议 16GB+,70B 模型需多卡或高显存(80GB+)
- 支持 CUDA 加速及 TensorRT-LLM、vLLM 等后端
最低 16GB(小模型量化推理),推荐 32GB-64GB+(大模型加载或全量微调)

快速开始
English | 中文
Llama中文社区

最好的Llama大模型开源社区
🤗 Hugging Face • 🤖 ModelScope • ✡️ WiseModel
🗂️ 目录
📌 Llama中文社区
🔥 社区介绍
欢迎来到Llama中文社区!Llama模型的开源无疑极大促进了大模型技术的发展,我们致力于构建一个开放平台,能够让所有的开发者与技术爱好者一起共创Llama开源生态。从大模型到小模型,从文本到多模态,从软件到硬件算法优化,我们期望开源能够带给全人类以AI普惠。在一个科技爆发的时代,加入Llama Family,与技术一同进步,与社区一同前行,一起迈向AGI!
为什么选择Llama中文社区?
🚀 高级工程师团队支持:社区有一批专注为大家服务的NLP高级工程师,我们有着强大的技术支持和丰富的经验,为您提供专业的指导和帮助。
🎯 中文优化:我们致力于在Llama模型的中文处理方面进行优化,探索适用于中文的最佳实践,以提升其性能和适应性【支持Llama2、Llama3、Llama4】。
💡 创新交流:我们拥有一支富有创造力和经验的社区成员团队,定期组织线上活动、技术研讨和经验分享,促进成员间的创新交流。
🌐 全球联结:我们欢迎来自世界各地的开发者加入社区,构建一个开放、多元化的学习和交流平台。
🤝 开放共享:我们鼓励社区成员开源分享代码和模型,推动合作共赢,共同促进中文NLP技术的发展。
社区活动
🗓️ 线上讲座:邀请行业内专家进行线上讲座,分享Llama在中文NLP领域的最新技术和应用,探讨前沿研究成果。
💻 项目展示:成员可展示自己在Llama中文优化方面的项目成果,获得反馈和建议,促进项目协作。
📚 学习资源:社区维护丰富的学习资料库,包括教程、文档和论文解读,为成员提供全面的学习支持。
📝 论文解读:社区成员共同解读与Llama相关的最新研究论文,深入理解前沿算法和方法。
🎉 主题活动:定期举办各类主题活动,包括挑战赛、黑客马拉松和技术沙龙,让社区成员在轻松愉快的氛围中交流和学习。
🌟 奖励计划:我们设立奖励计划,对社区中积极参与、贡献优秀的成员给予荣誉和奖励,激励更多优秀人才的加入。
📈 技术咨询:我们提供技术咨询服务,解答您在Llama开发和优化过程中遇到的问题,助您快速攻克难关。
🚀 项目合作:鼓励成员间的项目合作,共同探索Llama在实际应用中的潜力,打造创新解决方案。
立即加入我们!
📚 愿景:无论您是对Llama已有研究和应用经验的专业开发者,还是对Llama中文优化感兴趣并希望深入探索的新手,我们都热切期待您的加入。在Llama中文社区,您将有机会与行业内顶尖人才共同交流,携手推动中文NLP技术的进步,开创更加美好的技术未来!
🔗 温馨提示:本社区为专业技术交流平台,我们热切期望志同道合的开发者和研究者加入。请遵守社区准则,共同维护积极向上的学习氛围。感谢您的理解和支持!
🪵 社区资源
社区资源的丰富性是社区发展的重要保障,它涵盖了各种方面,其中包括但不限于以下四个方面:算力、数据、论坛和应用。在这些方面的积极发展与充分利用,将为社区成员提供更多的机会和支持,推动整个社区向着更加繁荣的方向发展。更多的内容请看llama.family
💻 算力
- 提供低于市场价格的算力资源,可用于各类计算任务,如深度学习模型的训练、推理等。
- 为社区成员提供专属的在线推理服务,让用户可以快速有效地对模型进行推理操作。
- 提供一键在线微调服务,使用户可以方便地对模型进行微调,以适应不同的任务和数据。
📊 数据
- 开放丰富的训练数据资源,覆盖多个领域和行业,为模型训练提供充足的数据支持。
- 提供高质量、多样化的数据集,以满足不同用户的需求,并支持数据共享和交流,促进数据资源的充分利用。
💬 论坛
- 社区论坛为社区成员提供了一个在线交流和讨论技术问题的平台。
- 在论坛上,用户可以分享经验、提出问题、解答疑惑,促进技术交流和合作。
- 论坛还可以定期举办线上活动、研讨会等,增进社区成员之间的联系和了解。
📱 应用
- 免费提供应用推广展示位,让开发者可以将他们的应用充分展示给社区成员。
- 提供推广的帮助,包括但不限于宣传推广、用户引导等服务,帮助应用获得更多的曝光和用户。
- 通过社区平台,为优秀的应用提供合作机会,促进应用开发者之间的合作和交流,共同推动应用的发展和壮大。
📢 最新动态
【最新】2025年04月05日:原生多模态MoE架构的Llama 4开源!最高达2T参数的Behemoth模型,以及Maverick、Scout。
【最新】2024年12月06日:Llama 3.3模型发布,更新70B Instruct模型。
【最新】2024年09月25日:Llama 3.2模型发布,核心主打1B、3B端侧小模型,以及11B、90B多模态输入模型!
【最新】2024年07月24日:开源最强Llama 3.1模型发布,包含8B、70B和405B!
【最新】2024年07月16日:社区论坛上线,有大模型问题,就找Llama中文社区!
【最新】2024年05月15日:支持ollama运行Llama3-Chinese-8B-Instruct、Atom-7B-Chat,详细使用方法。
【最新】2024年04月23日:社区增加了llama3 8B中文微调模型Llama3-Chinese-8B-Instruct以及对应的免费API调用。
【最新】2024年04月19日:社区增加了llama3 8B、llama3 70B在线体验链接。
【最新】2024年04月14日:社区更新了四个专家角色:心理咨询师、羊驼夸夸 、律师、医生。链接:角色role。
【最新】2024年04月10日:Atom-7B-Chat 模型回答内容相较之前更为丰富、增强了模型的指令遵循能力和回答稳定性、优化了ppo的奖励模型。下载链接modelscope、Huggingface。
【最新】2024年04月01日:社区上线了Llama中文应用平台;同时如果你有优秀的的应用需要推广可以填写申请表。
【最新】2024年03月08日:开放了免费API供大家使用,包含(Atom-1B,7B,13B 3种中文大模型)API使用链接
【最新】2024年04月14日:社区更新了四个专家角色:心理咨询师、羊驼夸夸 、律师、医生。链接:角色role。
【最新】2024年04月10日:Atom-7B-Chat 模型回答内容相较之前更为丰富、增强了模型的指令遵循能力和回答稳定性、优化了ppo的奖励模型。下载链接modelscope、Huggingface。
【最新】2024年04月01日:社区上线了Llama中文应用平台;同时如果你有优秀的的应用需要推广可以填写申请表。
【最新】2024年03月28日:社区免费公开课。
【最新】2024年03月08日:开放了免费API供大家使用,包含(Atom-1B,7B,13B 3种中文大模型)API使用链接
【最新】2023年10月8日:新增清华大学JittorLLMs的推理加速功能JittorLLMs!
2023年9月12日:更新预训练版本Atom-7B和对话版本Atom-7B-Chat模型参数,最新的中文预训练数据量为2.7TB token,训练进程见llama.family!
2023年8月28日:发布基于Llama2进行中文预训练的开源大模型Atom-7B,并将持续更新,详情参考社区公众号文章!
2023年8月26日:提供FastAPI接口搭建脚本!
2023年8月26日:提供将Meta原始模型参数转换为兼容Hugging Face的格式转化脚本!
2023年8月26日:新增Code Llama模型!
2023年8月15日:新增PEFT加载微调模型参数的代码示例!
2023年8月14日:大模型数据共享训练平台上线,没有算力也能参与大模型训练,社区每位成员贡献的数据都将决定模型能力的未来走向!
2023年8月3日:新增FasterTransformer和vLLM的GPU推理加速支持!
2023年7月31日:【重磅】国内首个真正意义上的Llama2中文大模型发布!详情参见社区公众号文章
2023年7月28日:通过Docker部署问答接口!
2023年7月27日:新增LangChain支持!
2023年7月26日:新增Llama2-13B中文微调参数的4bit量化压缩版本!
2023年7月25日:社区微信公众号“Llama中文社区”欢迎大家关注,获取最新分享和动态!
2023年7月24日:FlagAlpha新增Llama2-13B中文微调参数!
2023年7月24日:llama.family新增Llama2-70B在线体验!
2023年7月23日:Llama2中文微调参数发布至Hugging Face仓库FlagAlpha!
2023年7月22日:Llama2在线体验链接llama.family上线,同时包含Meta原版和中文微调版本!
2023年7月21日:评测了Meta原始版Llama2 Chat模型的中文问答能力!
2023年7月21日:新增Llama2模型的Hugging Face版本国内下载地址!
2023年7月20日:新增飞书知识库文档,欢迎大家一起共建!
2023年7月20日:国内Llama2最新下载地址上线!
2023年7月19日:正式启动Llama2模型的中文预训练,关注我们获取实时动态!
2023年7月19日:Llama2国内下载地址正在启动,敬请期待!
2023年7月19日:开启Llama2中文社区,欢迎大家加入!
🤗 模型发布
中文预训练模型Atom
原子大模型Atom由Llama中文社区和原子回声联合打造。
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Atom-7B | FlagAlpha/Atom-7B | HuggingFace | ModelScope | WiseModel |
| Chat | Atom-7B-Chat | FlagAlpha/Atom-7B-Chat | HuggingFace | ModelScope | WiseModel |
Atom系列模型包含Atom-13B、Atom-7B和Atom-1B,基于Llama2做了中文能力的持续优化。Atom-7B和Atom-7B-Chat目前已完全开源,支持商用,可在Hugging Face仓库获取模型,详情见Atom-7B下载。Atom大模型针对中文做了以下优化:
大规模的中文数据预训练
原子大模型Atom在Llama2的基础上,采用大规模的中文数据进行持续预训练,包含百科、书籍、博客、新闻、公告、小说、金融数据、法律数据、医疗数据、代码数据、专业论文数据、中文自然语言处理竞赛数据集等。同时对庞大的数据进行了过滤、打分、去重,筛选出超过1T token的高质量中文数据,持续不断加入训练迭代中。
更高效的中文词表
为了提高中文文本处理的效率,我们针对Llama2模型的词表进行了深度优化。首先,我们基于数百G的中文文本,在该模型词表的基础上扩展词库至65,000个单词。经过测试,我们的改进使得中文编码/解码速度提高了约350%。此外,我们还扩大了中文字符集的覆盖范围,包括所有emoji符号😊。这使得生成带有表情符号的文章更加高效。
自适应上下文扩展
Atom大模型默认支持4K上下文,利用位置插值PI和Neural Tangent Kernel (NTK)方法,经过微调可以将上下文长度扩增到32K。
📝 中文数据详情如下:
| 类型 | 描述 |
|---|---|
| 网络数据 | 互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据。 |
| Wikipedia | 中文Wikipedia的数据 |
| 悟道 | 中文悟道开源的200G数据 |
| Clue | Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 |
| 竞赛数据集 | 近年来中文自然语言处理多任务竞赛数据集,约150个 |
| MNBVC | MNBVC 中清洗出来的部分数据集 |
社区提供预训练版本Atom-7B和基于Atom-7B进行对话微调的模型参数供开放下载,关于模型的进展详见社区官网llama.family。
Llama4官方模型
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Llama-4-Scout-17B-16E | meta-llama/Llama-4-Scout-17B-16E | HuggingFace |
| 对话模型 | Llama-4-Scout-17B-16E-Instruct | meta-llama/Llama-4-Scout-17B-16E-Instruct | HuggingFace |
| 预训练 | Llama-4-Maverick-17B-128E | meta-llama/Llama-4-Maverick-17B-128E | HuggingFace |
| 对话模型 | Llama-4-Maverick-17B-128E-Instruct | meta-llama/Llama-4-Maverick-17B-128E-Instruct | HuggingFace |
Llama3官方模型
注意:仅保留同等参数量级模型的最新版本。
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Llama-3.2-1B | meta-llama/Llama-3.2-1B | HuggingFace |
| 对话模型 | Llama-3.2-1B-Instruct | meta-llama/Llama-3.2-1B-Instruct | HuggingFace |
| 预训练 | Llama-3.2-3B | meta-llama/Llama-3.2-3B | HuggingFace |
| 对话模型 | Llama-3.2-3B-Instruct | meta-llama/Llama-3.2-3B-Instruct | HuggingFace |
| 预训练 | Llama-3.1-8B | meta-llama/Llama-3.1-8B | HuggingFace |
| 对话模型 | Llama-3.1-8B-Instruct | meta-llama/Llama-3.1-8B-Instruct | HuggingFace |
| 预训练 | Llama-3.1-70B | meta-llama/Llama-3.1-70B | HuggingFace |
| 对话模型 | Llama-3.3-70B-Instruct | meta-llama/Llama-3.3-70B-Instruct | HuggingFace |
| 预训练 | Llama-3.1-405B | meta-llama/Llama-3.1-405B | HuggingFace |
| 对话模型 | Llama-3.1-405B-Instruct | meta-llama/Llama-3.1-405B-Instruct | HuggingFace |
| 多模态预训练 | Llama-3.2-11B-Vision | meta-llama/Llama-3.2-11B-Vision | HuggingFace |
| 多模态对话模型 | Llama-3.2-11B-Vision-Instruct | meta-llama/Llama-3.2-11B-Vision-Instruct | HuggingFace |
| 多模态预训练 | Llama-3.2-90B-Vision | meta-llama/Llama-3.2-90B-Vision | HuggingFace |
| 多模态对话模型 | Llama-3.2-90B-Vision-Instruct | meta-llama/Llama-3.2-90B-Vision-Instruct | HuggingFace |
Llama3中文微调模型
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 对话模型 | Llama3-Chinese-8B-Instruct | FlagAlpha/Llama3-Chinese-8B-Instruct | HuggingFace | modelscope | wisemodel |
Llama2官方模型
| 类别 | 模型名称 | 🤗模型加载名称 | 下载地址 |
|---|---|---|---|
| 预训练 | Llama2-7B | meta-llama/Llama-2-7b-hf | HuggingFace | 迅雷网盘 |
| 预训练 | Llama2-13B | meta-llama/Llama-2-13b-hf | HuggingFace | 迅雷网盘 |
| 预训练 | Llama2-70B | meta-llama/Llama-2-70b-hf | HuggingFace |
| Chat | Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | HuggingFace | 迅雷网盘 |
| Chat | Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | HuggingFace | 迅雷网盘 |
| Chat | Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | HuggingFace | 迅雷网盘 |
| Code | CodeLlama-7b | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-7b-Python | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-7b-Instruct | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-13b | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-13b-Python | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-13b-Instruct | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
| Code | CodeLlama-34b | meta-llama/Llama-2-70b-chat-hf | 迅雷网盘 |
Meta官方在2023年8月24日发布了Code Llama,基于代码数据对Llama2进行了微调,提供三个不同功能的版本:基础模型(Code Llama)、Python专用模型(Code Llama - Python)和指令跟随模型(Code Llama - Instruct),包含7B、13B、34B三种不同参数规模。不同模型能力区别如下表所示:
| 模型类别 | 模型名称 | 代码续写 | 代码填充 | 指令编程 |
|---|---|---|---|---|
| Code Llama | CodeLlama-7b | ✅ | ✅ | ❌ |
| CodeLlama-13b | ✅ | ✅ | ❌ | |
| CodeLlama-34b | ✅ | ❌ | ❌ | |
| Code Llama - Python | CodeLlama-7b-Python | ✅ | ❌ | ❌ |
| CodeLlama-13b-Python | ✅ | ❌ | ❌ | |
| CodeLlama-34b-Python | ✅ | ❌ | ❌ | |
| Code Llama - Instruct | CodeLlama-7b-Instruct | ❌ | ✅ | ✅ |
| CodeLlama-13b-Instruct | ❌ | ✅ | ✅ | |
| CodeLlama-34b-Instruct | ❌ | ❌ | ✅ |
关于Code Llama的详细信息可以参考官方Github仓库codellama。
Llama2中文微调模型
我们基于中文指令数据集对Llama2-Chat模型进行了微调,使得Llama2模型有着更强的中文对话能力。LoRA参数以及与基础模型合并的参数均已上传至Hugging Face,目前包含7B和13B的模型。
| 类别 | 模型名称 | 🤗模型加载名称 | 基础模型版本 | 下载地址 |
|---|---|---|---|---|
| 合并参数 | Llama2-Chinese-7b-Chat | FlagAlpha/Llama2-Chinese-7b-Chat | meta-llama/Llama-2-7b-chat-hf | HuggingFace |
| 合并参数 | Llama2-Chinese-13b-Chat | FlagAlpha/Llama2-Chinese-13b-Chat | meta-llama/Llama-2-13b-chat-hf | HuggingFace |
| LoRA参数 | Llama2-Chinese-7b-Chat-LoRA | FlagAlpha/Llama2-Chinese-7b-Chat-LoRA | meta-llama/Llama-2-7b-chat-hf | HuggingFace |
| LoRA参数 | Llama2-Chinese-13b-Chat-LoRA | FlagAlpha/Llama2-Chinese-13b-Chat-LoRA | meta-llama/Llama-2-13b-chat-hf | HuggingFace |
📌 如何使用Llama模型
你可以选择下面的快速上手的任一种方式,开始使用 Llama 系列模型。推荐使用中文预训练对话模型进行使用,对中文的效果支持更好。
快速上手-使用Anaconda
第 0 步:前提条件
- 确保安装了 Python 3.10 以上版本。
第 1 步:准备环境
如需设置环境,安装所需要的软件包,运行下面的命令。
git clone https://github.com/LlamaFamily/Llama-Chinese.git
cd Llama-Chinese
pip install -r requirements.txt
第 2 步:下载模型
你可以从以下来源下载Atom-7B-Chat模型。
第 3 步:进行推理
使用Atom-7B-Chat模型进行推理 创建一个名为 quick_start.py 的文件,并将以下内容复制到该文件中。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B-Chat',device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
运行 quick_start.py 代码。
python quick_start.py
快速上手-使用Docker
详情参见:Docker部署
第 1 步:准备docker镜像,通过docker容器启动chat_gradio.py
git clone https://github.com/LlamaFamily/Llama-Chinese.git
cd Llama-Chinese
docker build -f docker/Dockerfile -t flagalpha/llama2-chinese:gradio .
第 2 步:通过docker-compose启动chat_gradio
cd Llama-Chinese/docker
docker-compose up -d --build
快速上手-使用llama.cpp
详情参见:使用llama.cpp
快速上手-使用gradio
基于gradio搭建的问答界面,实现了流式的输出,将下面代码复制到控制台运行,以下代码以Atom-7B-Chat模型为例,不同模型只需修改一下面的model_name_or_path对应的模型名称就好了😊
python examples/chat_gradio.py --model_name_or_path FlagAlpha/Atom-7B-Chat
快速上手-构建API服务
使用FastChat构建和OpenAI一致的推理服务接口。
第 0 步:前提条件
安装fastchat
pip3 install "fschat[model_worker,webui]"
第 1 步:启动Restful API
开启三个控制台分别执行下面的三个命令
- 首先启动controler
python3 -m fastchat.serve.controller \
--host localhost \
--port 21001
- 启动模型
CUDA_VISIBLE_DEVICES="0" python3 -m fastchat.serve.model_worker --model-path /path/Atom-7B-Chat \
--host localhost \
--port 21002 \
--worker-address "http://localhost:21002" \
--limit-worker-concurrency 5 \
--stream-interval 2 \
--gpus "1" \
--load-8bit
- 启动RESTful API 服务
python3 -m fastchat.serve.openai_api_server \
--host localhost \
--port 21003 \
--controller-address http://localhost:21001
第 2 步:测试api服务
执行下面的python代码测试上面部署的api服务
# coding=utf-8
import json
import time
import urllib.request
import sys
import requests
def test_api_server(input_text):
header = {'Content-Type': 'application/json'}
data = {
"messages": [{"role": "system", "content": ""}, {"role": "user", "content": input_text}],
"temperature": 0.3,
"top_p" : 0.95,
"max_tokens": 512,
"model": "LLama2-Chinese-13B",
"stream" : False,
"n" : 1,
"best_of": 1,
"presence_penalty": 1.2,
"frequency_penalty": 0.2,
"top_k": 50,
"use_beam_search": False,
"stop": [],
"ignore_eos" :False,
"logprobs": None
}
response = requests.post(
url='http://127.0.0.1:21003/v1/chat/completions',
headers=header,
data=json.dumps(data).encode('utf-8')
)
result = None
try:
result = json.loads(response.content)
print(json.dumps(data, ensure_ascii=False, indent=2))
print(json.dumps(result, ensure_ascii=False, indent=2))
except Exception as e:
print(e)
return result
if __name__ == "__main__":
test_api_server("如何去北京?")
快速上手-使用ollama运行
- 首先需要安装ollama工具
安装方法参考:https://ollama.com
- ollama运行Llama3-Chinese-8B-Instruct、Atom-7B-Chat
ollama运行基于Llama3进行中文微调的大模型Llama3-Chinese-8B-Instruct
打开命令行执行命令
ollama run llamafamily/llama3-chinese-8b-instruct
ollama运行基于Llama2进行中文预训练的开源大模型Atom-7B-Chat
打开命令行执行命令
ollama run llamafamily/atom-7b-chat
🤖 模型预训练
模型迭代日新月异,虽然Llama2现在使用已经不多,在这里我们还是作为一个学习样例,展示如何做基座模型的预训练与微调。Llama2的预训练数据相对于第一代LLaMA扩大了一倍,但是中文预训练数据的比例依然非常少,仅占0.13%,这也导致了原始Llama2的中文能力较弱。为了能够提升模型的中文能力,可以采用微调和预训练两种路径,其中:
微调需要的算力资源少,能够快速实现一个中文Llama的雏形。但缺点也显而易见,只能激发基座模型已有的中文能力,由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本。
基于大规模中文语料进行预训练,成本高,不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力。
我们为社区提供了Llama模型的预训练代码,以及中文测试语料,更多数据可以参考中文语料。具体代码和配置如下:
- 模型预训练脚本:train/pretrain/pretrain.sh
- 预训练实现代码:train/pretrain/pretrain_clm.py
- DeepSpeed加速:
- 对于单卡训练,可以采用ZeRO-2的方式,参数配置见 train/pretrain/ds_config_zero2.json
- 对于多卡训练,可以采用ZeRO-3的方式,参数配置见 train/pretrain/ds_config_zero3.json
- 训练效果度量指标:train/pretrain/accuracy.py
💡 模型微调
本仓库中同时提供了LoRA微调和全量参数微调代码,关于LoRA的详细介绍可以参考论文“LoRA: Low-Rank Adaptation of Large Language Models”以及微软Github仓库LoRA。
Step1: 环境准备
根据requirements.txt安装对应的环境依赖。
Step2: 数据准备
在data目录下提供了一份用于模型sft的数据样例:
- 训练数据:data/train_sft.csv
- 验证数据:data/dev_sft.csv
每个csv文件中包含一列“text”,每一行为一个训练样例,每个训练样例按照以下格式将问题和答案组织为模型输入,您可以按照以下格式自定义训练和验证数据集:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案+"\n"</s>
例如,
<s>Human: 用一句话描述地球为什么是独一无二的。</s><s>Assistant: 因为地球是目前为止唯一已知存在生命的行星。</s>
Step3: 微调脚本
LoRA微调
LoRA微调脚本见:train/sft/finetune_lora.sh,关于LoRA微调的具体实现代码见train/sft/finetune_clm_lora.py,单机多卡的微调可以通过修改脚本中的--include localhost:0来实现。
全量参数微调
全量参数微调脚本见:train/sft/finetune.sh,关于全量参数微调的具体实现代码见train/sft/finetune_clm.py。
Step4: 加载微调模型
LoRA微调
基于LoRA微调的模型参数见:基于Llama2的中文微调模型,LoRA参数需要和基础模型参数结合使用。
通过PEFT加载预trained模型参数和微trained model parameters,以下示例代码中,base_model_name_or_path为 pretrained model parameter save path,finetune_model_path为 microtrained model parameter save path。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel,PeftConfig
# 例如: finetune_model_path='FlagAlpha/Llama2-Chinese-7b-Chat-LoRA'
finetune_model_path=''
config = PeftConfig.from_pretrained(finetune_model_path)
# 例如: base_model_name_or_path='meta-llama/Llama-2-7b-chat'
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path,device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model = PeftModel.from_pretrained(model, finetune_model_path, device_map={"": 0})
model =model.eval()
input_ids = tokenizer(['<s>Human: 介绍一下北京\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
全量参数微调
对于全量参数微调的模型,调用方式同模型调用代码示例,只需要修改其中的模型名称或者保存路径即可。
🍄 模型量化
我们对中文微调的模型参数进行了量化,方便以更少的计算资源运行。目前已经在Hugging Face上传了13B中文微调模型FlagAlpha/Llama2-Chinese-13b-Chat的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit,具体调用方式如下:
环境准备:
pip install git+https://github.com/PanQiWei/AutoGPTQ.git
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized('FlagAlpha/Llama2-Chinese-13b-Chat-4bit', device="cuda:0")
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Llama2-Chinese-13b-Chat-4bit',use_fast=False)
input_ids = tokenizer(['<s>Human: 怎么登上火星\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
🚀 部署加速
随着大模型参数规模的不断增长,在有限的算力资源下,提升模型的推理速度逐渐变为一个重要的研究方向。常用的推理加速框架包含 lmdeploy、TensorRT-LLM、vLLM和JittorLLMs 等。
TensorRT-LLM
TensorRT-LLM由NVIDIA开发,高性能推理框架
详细的推理文档见:inference-speed/GPU/TensorRT-LLM_example
vLLM
vLLM由加州大学伯克利分校开发,核心技术是PageAttention,吞吐量比HuggingFace Transformers高出24倍。相较与FasterTrainsformer,vLLM更加的简单易用,不需要额外进行模型的转换,支持fp16推理。
详细的推理文档见:inference-speed/GPU/vllm_example
JittorLLMs
JittorLLMs由非十科技领衔,与清华大学可视媒体研究中心合作研发,通过动态swap机制大幅降低硬件配置要求(减少80%),并且Jittor框架通过零拷贝技术,大模型加载相比Pytorch开销降低40%,同时,通过元算子自动编译优化,计算性能提升20%以上。
详细的推理文档见:inference-speed/GPU/JittorLLMs
lmdeploy
lmdeploy 由上海人工智能实验室开发,推理使用 C++/CUDA,对外提供 python/gRPC/http 接口和 WebUI 界面,支持 tensor parallel 分布式推理、支持 fp16/weight int4/kv cache int8 量化。
详细的推理文档见:inference-speed/GPU/lmdeploy_example
💪 外延能力
除了持续增强大模型内在的知识储备、通用理解、逻辑推理和想象能力等,未来,我们也会不断丰富大模型的外延能力,例如知识库检索、计算工具、WolframAlpha、操作软件等。 我们首先集成了LangChain框架,可以更方便地基于Llama2开发文档检索、问答机器人和智能体应用等,关于LangChain的更多介绍参见LangChain。
LangChain
针对LangChain框架封装的Llama2 LLM类见examples/llama2_for_langchain.py,简单的调用代码示例如下:
from llama2_for_langchain import Llama2
# 这里以调用FlagAlpha/Atom-7B-Chat为例
llm = Llama2(model_name_or_path='FlagAlpha/Atom-7B-Chat')
while True:
human_input = input("Human: ")
response = llm(human_input)
print(f"Llama2: {response}")
🥇 模型评测
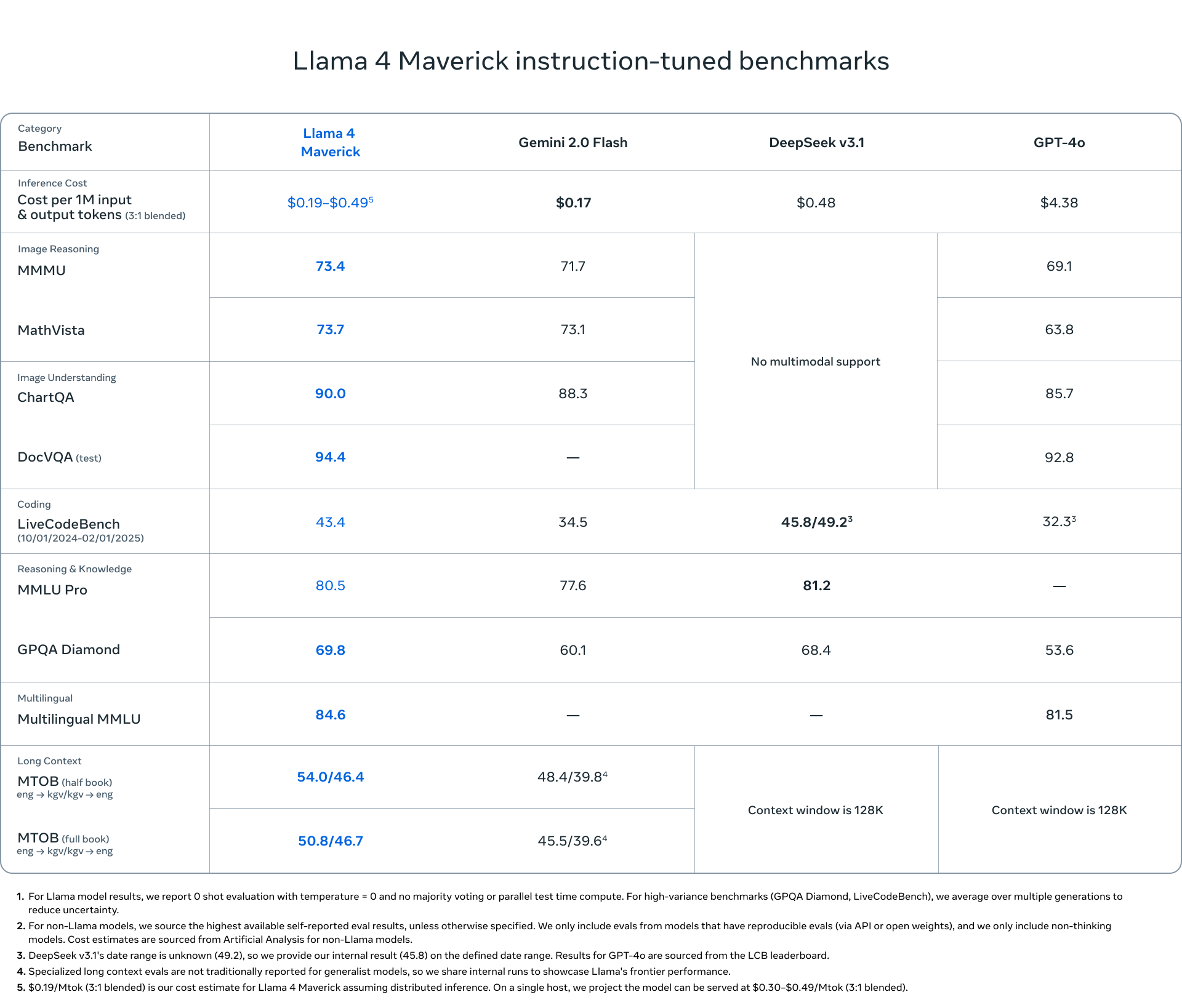
Llama4模型评测
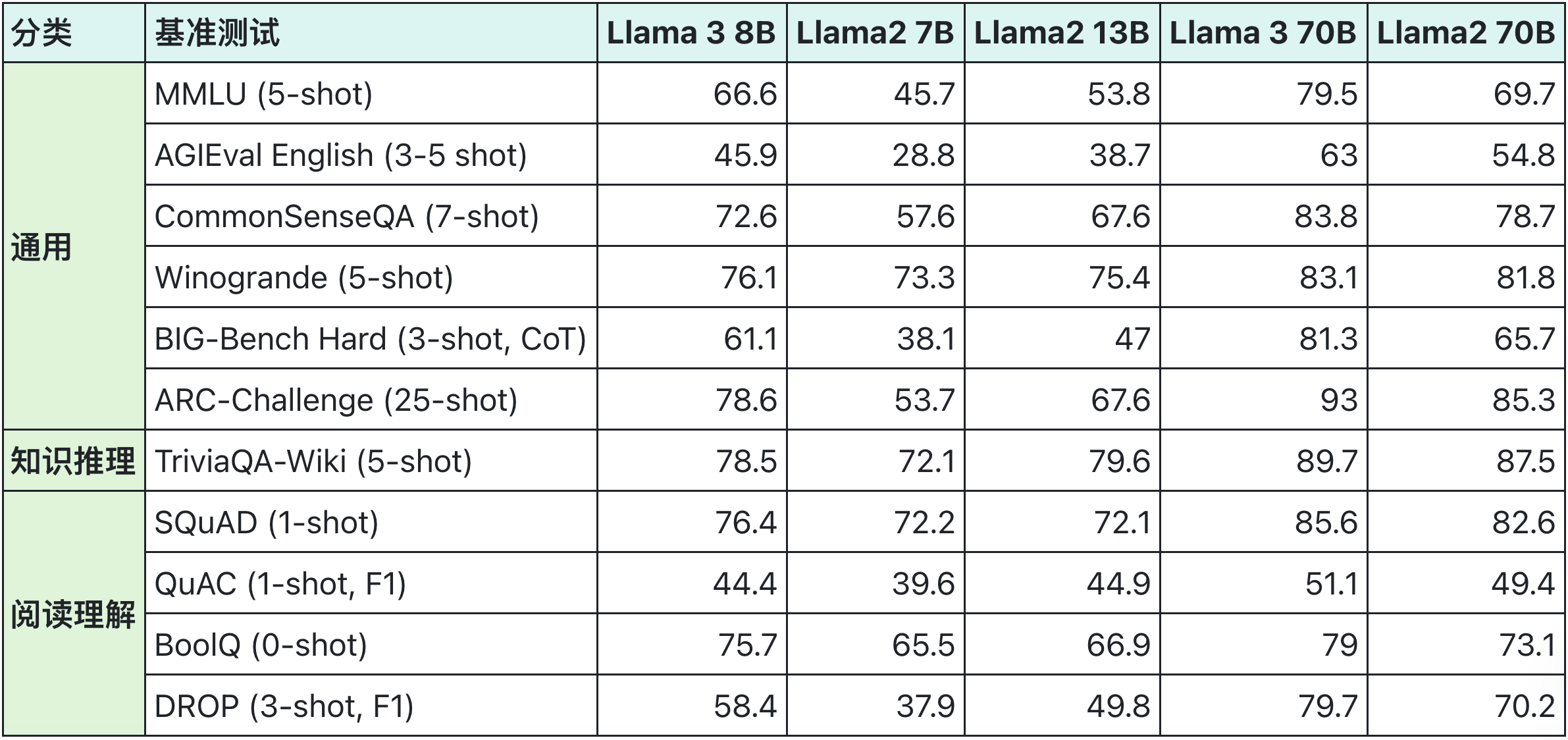
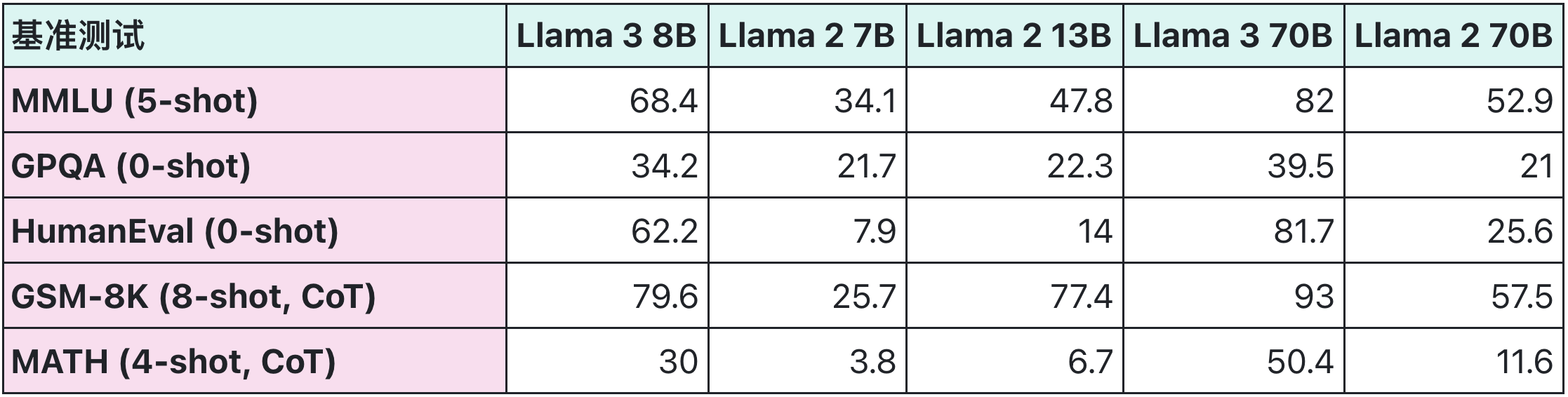
Llama2和Llama3对比评测
基础模型对比
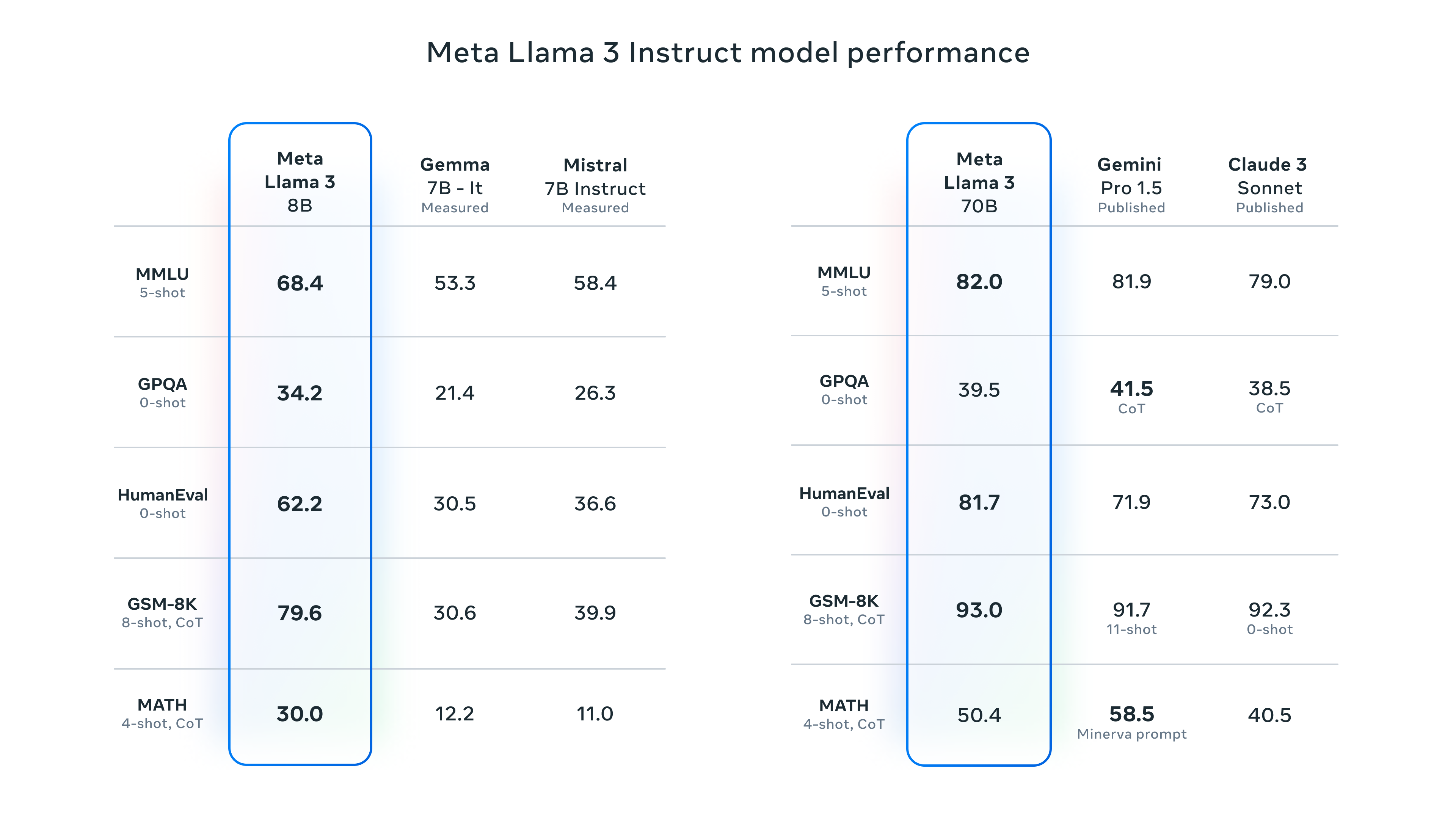
Llama3模型评测
Llama2模型评测
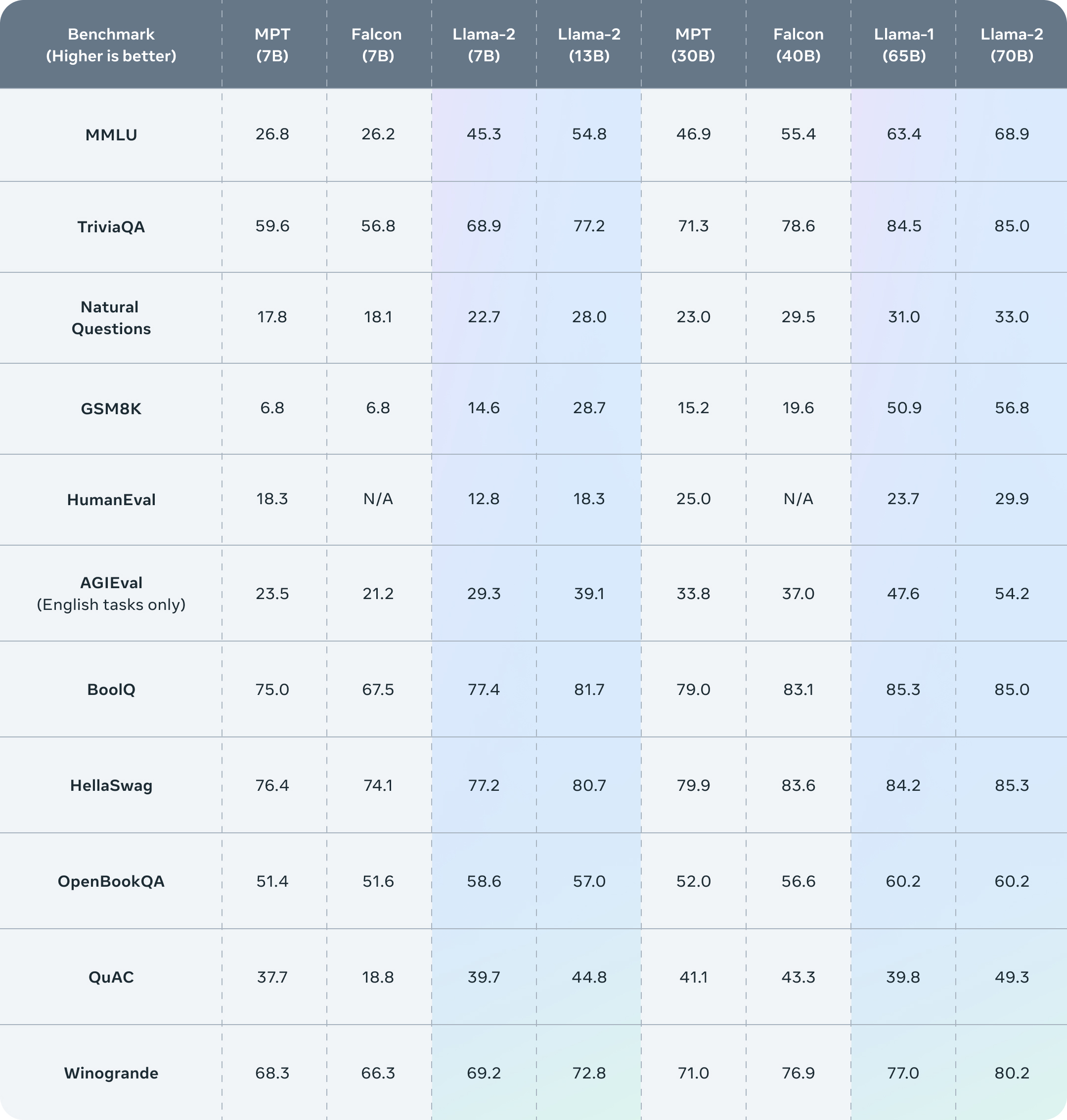
为了能够更加清晰地了解Llama模型的中文问答能力,我们筛选了一些具有代表性的中文问题,对Llama模型进行提问。我们测试的模型包含Meta公开的Llama2-7B-Chat和Llama2-13B-Chat两个版本,没有做任何微调和训练。测试问题筛选自AtomBulb,共95个测试问题,包含:通用知识、语言理解、创作能力、逻辑推理、代码编程、工作技能、使用工具、人格特征八个大的类别。
测试中使用的Prompt如下,例如对于问题“列出5种可以改善睡眠质量的方法”:
[INST]
<<SYS>>
你是一位乐于助人、尊重他人且诚实的助手。在确保安全的前提下,始终尽可能提供有帮助的回答。你的回答不应包含任何有害、不道德、种族主义、性别歧视、有毒、危险或非法的内容。请确保你的回应是社会上公正且积极向上的。答案始终翻译成中文。
如果一个问题毫无意义或在事实上不连贯,你应该解释原因,而不是给出错误的答案。如果你不知道问题的答案,切勿提供虚假信息。
答案始终翻译成中文。
<</SYS>>
列出5种可以改善睡眠质量的方法
[/INST]
Llama2-7B-Chat的测试结果见meta_eval_7B.md,Llama2-13B-Chat的测试结果见meta_eval_13B.md。
通过测试我们发现,Meta原始的Llama2 Chat模型对于中文问答的对齐效果一般,大部分情况下都不能给出中文回答,或者是中英文混杂的形式。当然,随着基座模型多语种语料的扩充,这些问题将很快被解决。比如,在Llama4当中,预训练数据包含200种语言,其中100种语言的语料超过了1B tokens。
📖 学习中心
官方文档
Meta Llama全系列模型官方文档:https://www.llama.com/docs/get-started
Meta Llama官方网站:https://www.llama.com
社区文档
Llama相关论文
📌 其它
🎉 致谢
感谢原子回声AtomEcho团队的技术和资源支持!
感谢芯格Coremesh团队的技术和资源支持!
感谢 福州连天教育科技有限公司 对Llama中文社区的贡献!
感谢 @Z Potentials社区对Llama中文社区的支持!
🤔 问题反馈
如有问题,请在GitHub Issue中提交,在提交问题之前,请先查阅以往的issue是否能解决你的问题。
礼貌地提出问题,构建和谐的讨论社区。
加入飞书知识库,一起共建社区文档。
加入微信群讨论😍😍


常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。