LiveBench
LiveBench 是一个专为大语言模型(LLM)设计的动态评测基准,旨在提供更具挑战性且无数据污染的评估环境。它主要解决了传统基准测试中常见的“数据污染”难题——即模型因在训练阶段见过测试题而获得虚高分数的问题。通过每月发布基于最新数据集、arXiv 论文、新闻及电影简介的新题目,LiveBench 确保测试内容始终新鲜,真实反映模型的泛化能力。
此外,LiveBench 的所有问题均设有可验证的客观标准答案,无需依赖另一个大模型作为裁判即可实现自动化、高精度的评分,涵盖了编码、推理等六大类共 18 项多样化任务。
这款工具非常适合 AI 研究人员、开发者以及希望客观对比模型性能的技术团队使用。其独特的技术亮点在于持续的月度更新机制与完全客观的评分体系,配合对 Docker 容器化代码执行的支持,能够安全、准确地评估复杂的智能体编程任务。无论是想要验证新模型的性能,还是追踪前沿模型的演进趋势,LiveBench 都提供了一个透明、可靠且不断进化的测试平台。
使用场景
某 AI 初创团队在发布新大模型前,急需向投资人证明其模型具备真实的推理能力,而非仅仅“背题”的高手。
没有 LiveBench 时
- 评估结果虚高:模型在静态榜单上得分很高,但因训练数据污染(见过考题),实际处理新问题时表现糟糕,导致误判模型真实水平。
- 评分主观且昂贵:缺乏标准答案的开放性问题依赖另一个大模型(LLM Judge)来打分,不仅成本高,还引入了评分偏差和不一致性。
- 迭代反馈滞后:基准测试集更新缓慢,无法及时反映模型对最新新闻、论文或代码库的理解能力,难以指导快速迭代。
- 自动化程度低:需要人工编写脚本处理不同任务的评分逻辑,尤其是代码生成任务,环境配置复杂且容易出错。
使用 LiveBench 后
- 杜绝数据污染:利用每月更新的基于最新论文、新闻和电影简介的题目,确保模型无法通过“死记硬背”作弊,真实暴露其泛化能力。
- 客观自动评分:所有问题均设有可验证的客观标准答案,无需引入裁判模型即可实现精准、低成本的自动化打分。
- 紧跟前沿动态:测试内容实时涵盖最新发布的数据集和技术文章,能立即检验模型对前沿知识的掌握情况,为优化提供即时反馈。
- 一站式评估流程:通过
run_livebench.py脚本一键完成从答案生成到代码沙箱运行评分的全流程,大幅降低评估门槛和维护成本。
LiveBench 通过持续更新的防污染题库和客观自动评分机制,让大模型的能力评估从“猜题游戏”回归到真实的智力较量。
运行环境要求
- Linux
- macOS
- 未说明 (主要依赖 API 调用
- 若使用 vllm 部署本地模型,需参考 vllm 的 GPU 要求)
未说明 (评估代理编码任务时,存储 Docker 镜像可能需高达 150GB 磁盘空间)
快速开始
LiveBench

LiveBench 作为 Spotlight Paper 出现在 ICLR 2025 上。
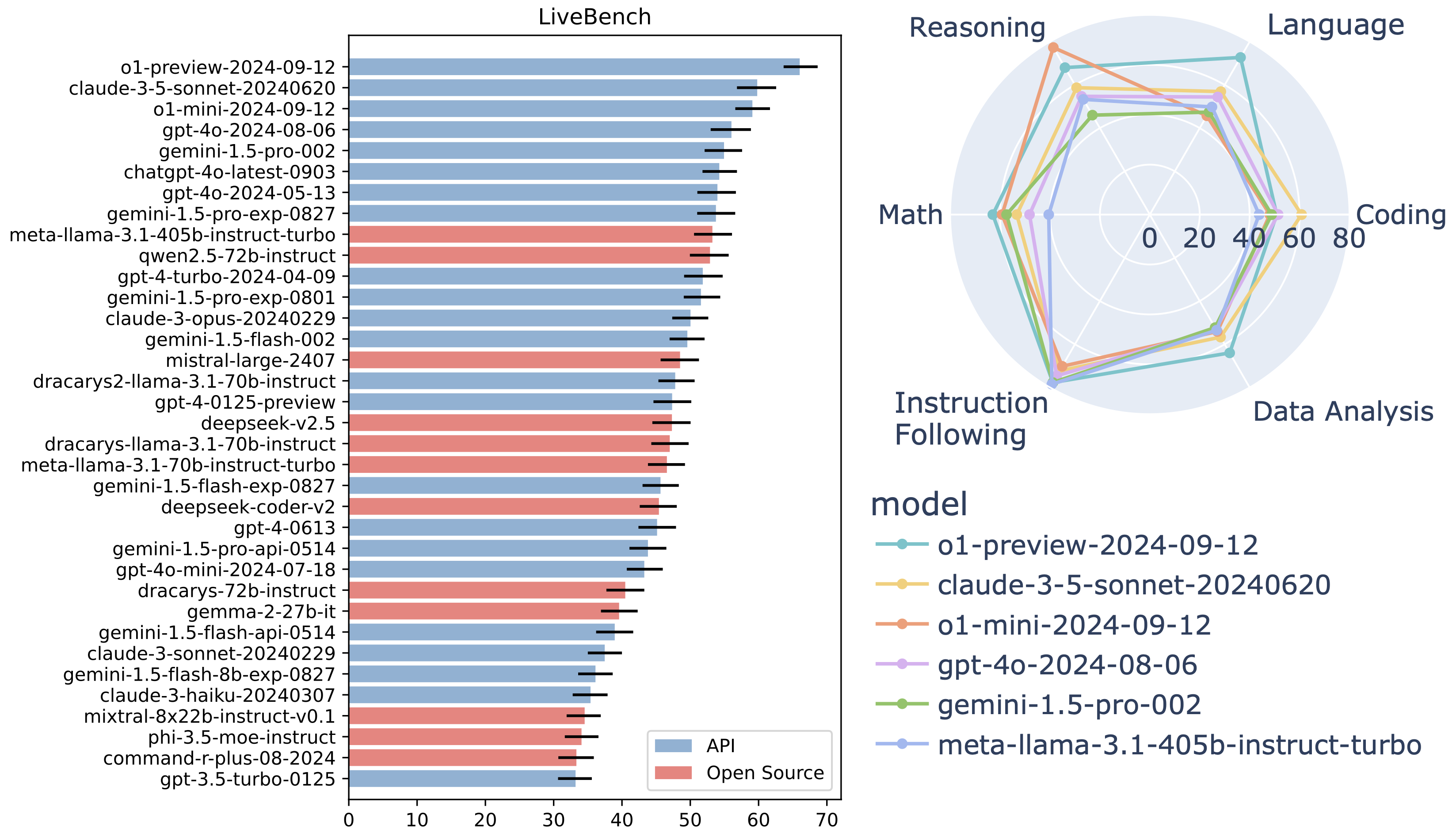
截至 2024 年 9 月 30 日的顶级模型(完整且最新的排行榜请见 这里):
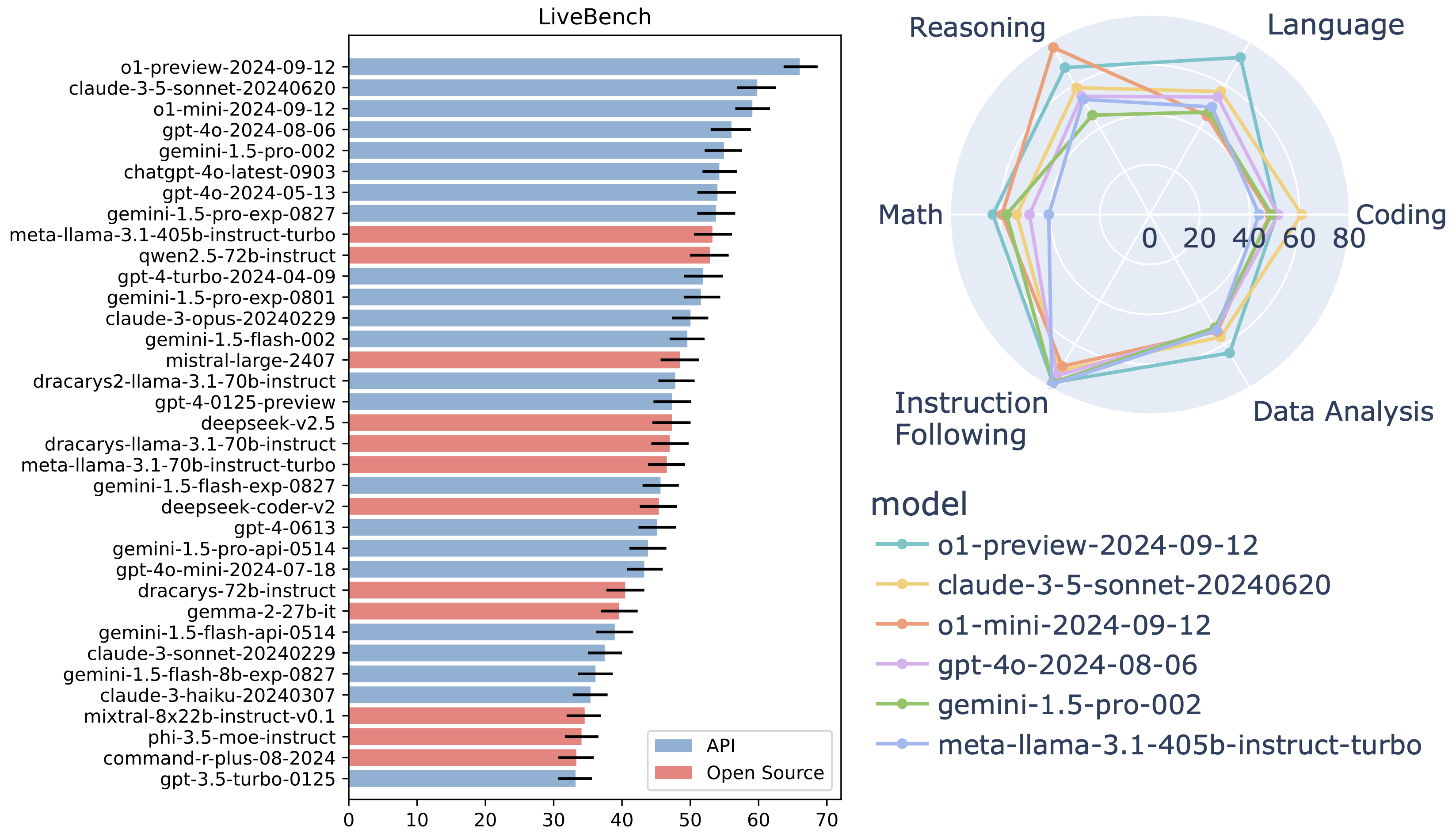
有关每次 LiveBench 发布的详细信息,请参阅 changelog。
目录
简介
隆重推出 LiveBench:一个专为 LLM 设计的基准测试,旨在解决测试集污染问题,并实现客观评估。
LiveBench 具有以下特点:
- LiveBench 每月发布新问题,以减少潜在的测试集污染;同时,问题基于近期发布的数据集、arXiv 论文、新闻文章以及 IMDb 电影梗概。
- 每道题都配有可验证的客观标准答案,因此即使难度较高的题目也能被准确、自动地评分,无需借助 LLM 作为评判者。
- LiveBench 目前包含 6 个类别下的 18 项多样化任务,未来我们将陆续推出更多难度更高的任务。
我们愿意为您评估模型! 请在 GitHub 上提交一个问题,或发送邮件至 livebench@livebench.ai!
安装快速入门
建议使用虚拟环境来安装 LiveBench。
python -m venv .venv
source .venv/bin/activate
若要通过 API 模型生成答案(即使用 gen_api_answer.py)、进行判断并展示结果:
cd LiveBench
pip install -e .
若需对编码任务(代码补全和代码生成)的结果进行评分,还需安装必要的依赖项:
cd livebench/code_runner
pip install -r requirements_eval.txt
请注意,要评估代理式编码问题,您需要安装并可用 Docker(即运行 docker --version 命令应能成功)。在执行此类任务之前,系统会检查是否已安装 Docker。
关于本地模型的说明:本地模型推理功能已不再维护。我们强烈建议您使用 vllm 将您的模型部署为兼容 OpenAI 的 API,并通过 run_livebench.py 进行推理。
我们的仓库包含了来自 LiveCodeBench 和 IFEval 的代码。
使用方法
cd livebench
运行评估
运行 LiveBench 推理与评分最简单的方式是使用 run_livebench.py 脚本,该脚本会处理整个评估流程,包括生成答案、评分并展示结果。
基本用法:
python run_livebench.py --model gpt-4o --bench-name live_bench/coding --livebench-release-option 2024-11-25
一些常用选项:
--bench-name:指定要使用的子集问题(例如live_bench表示所有问题,live_bench/coding表示仅编码任务)--model:要评估的模型--max-tokens:模型响应的最大 token 数量(默认为 4096,除非针对特定模型覆盖)--api-base:用于兼容 OpenAI 服务器的自定义 API 端点--api-key-name:包含 API 密钥的环境变量名称(默认为 OpenAI 模型的 OPENAI_API_KEY)--api-key:API 密钥的原始值--parallel-requests:并发 API 请求数量(适用于具有高速率限制的模型)--resume:从上次中断的地方继续运行--retry-failures:重试之前运行失败的问题--livebench-release-option:评估特定 LiveBench 版本中的问题
运行 python run_livebench.py --help 可查看所有可用选项。
完成上述操作后,请按照 查看结果 部分查看评估结果。
注意:当前 LiveBench 的最新版本是 2025-04-25;然而,该版本的所有问题尚未在 Huggingface 上公开。为了评估所有类别,您需要在所有脚本中添加 --livebench-release-option 2024-11-25 参数,以使用最近公开的问题。
注意:代理式编码任务的评估需要构建特定于任务的 Docker 镜像。存储所有这些镜像可能占用高达 150GB 的空间。这些镜像既用于推理也用于评估。未来我们将致力于优化此任务的评估流程,以尽量减少存储需求。
并行评估选项
LiveBench 提供了两个不同的参数来并行化评估,这两个参数可以单独使用,也可以结合使用:
--mode parallel:通过创建多个 tmux 会话,并行运行不同的任务或类别。每个类别或任务都在独立的终端会话中运行,从而实现跨不同基准子集的同时评估。此选项也会并行化真值评估阶段。默认情况下,它会为每个类别创建一个会话;如果提供了--bench-name参数,则会为--bench-name的每个值创建一个会话。--parallel-requests:设置在一个任务评估实例中同时回答的问题数量。这控制着针对特定任务同时发出的 API 请求数量。
何时使用哪个选项:
对于高速率限制(例如吞吐量高的商业 API):
- 在评估整个基准时,建议同时使用这两个选项以获得最大吞吐量。
- 例如:
python run_livebench.py --model gpt-4o --bench-name live_bench --mode parallel --parallel-requests 10
对于较低的速率限制:
- 在运行整个 LiveBench 套件时,建议使用
--mode parallel来实现跨类别的并行化,即使--parallel-requests必须保持较低。 - 对于小型任务子集,
--parallel-requests可能更高效,因为创建多个 tmux 会话所带来的额外开销较小。 - 低速率限制下运行完整基准的示例:
python run_livebench.py --model claude-3-5-sonnet --bench-name live_bench --mode parallel --parallel-requests 2
- 在运行整个 LiveBench 套件时,建议使用
对于单个任务的评估:
- 当只运行一两个任务时,只需使用
--parallel-requests:python run_livebench.py --model gpt-4o --bench-name live_bench/coding --parallel-requests 10
- 当只运行一两个任务时,只需使用
请注意,--mode parallel 需要您的系统上已安装 tmux。创建的 tmux 会话数量将取决于正在评估的类别或任务数量。
查看结果
您可以使用 show_livebench_result.py 脚本查看评估结果:
python show_livebench_result.py --bench-name <bench-name> --model-list <model-list> --question-source <question-source> --livebench-release-option 2024-11-25
<model-list> 是一个以空格分隔的模型 ID 列表,用于指定要显示的模型。例如,要查看 gpt-4o 和 claude-3-5-sonnet 在编码任务上的结果,请运行:
python show_livebench_result.py --bench-name live_bench/coding --model-list gpt-4o claude-3-5-sonnet
您还可以提供多个 --bench-name 参数,以查看特定基准子集上的得分:
python show_livebench_result.py --bench-name live_bench/coding live_bench/math --model-list gpt-4o
如果未提供 --model-list 参数,则会显示所有模型的结果。--question-source 参数默认为 huggingface,但应与评估时使用的来源一致,同样地,--livebench-release-option 也应匹配。
排行榜将显示在终端中。您还可以在 all_groups.csv 文件中找到按类别划分的详细结果,在 all_tasks.csv 文件中找到按任务划分的详细结果。
错误检查
scripts/error_check.py 脚本会打印出模型输出为 $ERROR$ 的问题,这表示 API 调用多次失败。您可以使用 scripts/rerun_failed_questions.py 脚本重新运行这些失败的问题,或者正常运行 run_livebench.py 并添加 --resume 和 --retry-failures 参数。
默认情况下,LiveBench 会重试 API 调用三次,并在每次尝试之间加入延迟以应对速率限制。如果评估过程中出现的错误是由于速率限制导致的,您可能需要切换到 --mode single 或 --mode sequential 模式,并减少 --parallel-requests 的值。如果经过多次尝试后,模型的输出仍然是 $ERROR$,则很可能是该问题触发了模型提供商的内容过滤机制(Gemini 模型尤其容易出现这种情况,错误信息为 RECITATION)。在这种情况下,通常无法进一步处理。我们视此类失败为不正确的回答。
数据
各个类别的问题可以在以下链接中找到:
要下载排行榜中的 question.jsonl 文件(用于检查)以及答案和判断文件,可以使用以下命令:
python download_questions.py
python download_leaderboard.py
问题将被下载到 livebench/data/<category>/question.jsonl 目录下。
评估新问题
如果您想创建自己的问题集,或尝试不同的提示等,可以按照以下步骤操作:
- 创建一个
question.jsonl文件,路径如下(或者运行python download_questions.py并更新下载的文件):livebench/data/live_bench/<category>/<task>/question.jsonl。例如,livebench/data/reasoning/web_of_lies_new_prompt/question.jsonl。以下是question.jsonl文件的格式示例(来自 web_of_lies_v2 的前几道题):
{"question_id": "0daa7ca38beec4441b9d5c04d0b98912322926f0a3ac28a5097889d4ed83506f", "category": "reasoning", "ground_truth": "no, yes, yes", "turns": ["在这个问题中,假设每个人要么总是说真话,要么总是说谎话。塔拉在电影院。餐厅里的人说水族馆里的人在说谎。阿扬在水族馆。瑞安在植物园。公园里的人说艺术画廊里的人在说谎。博物馆里的人说的是真话。扎拉在博物馆。杰克在艺术画廊。艺术画廊里的人说剧院里的人在说谎。贝亚特丽斯在公园。电影院里的人说火车站的人在说谎。纳迪娅在露营地。露营地里的人说艺术画廊的人说的是真话。剧院里的人在说谎。游乐场里的人说水族馆的人说的是真话。格蕾丝在餐厅。水族馆里的人认为他的朋友在说谎。尼亚在剧院。凯欣德在火车站。剧院里的人认为他的朋友在说谎。植物园里的人说火车站的人说的是真话。水族馆里的人说露营地的人说的是真话。水族馆里的人看到了一辆消防车。火车站里的人说游乐场的人在说谎。马特奥在游乐场。那么,火车站的人说的是真话吗?游乐场的人说的是真话吗?水族馆的人说的是真话吗?请一步一步思考,然后用粗体字将你的答案写成一个由三个词组成的列表,分别是“是”或“否”(例如:“是,否,是”)。如果你不知道答案,就猜一猜。"], "task": "web_of_lies_v2"}
如果要添加新任务,需在
process_results文件夹中创建新的评分方法。如果新任务与现有任务类似,可以直接复制现有任务的评分函数。例如,livebench/process_results/reasoning/web_of_lies_new_prompt/utils.py可以直接复制web_of_lies_v2的评分方法。将评分函数添加到
gen_ground_truth_judgment.py中的相应位置:此处。使用
--question-source jsonl并指定您的任务来运行并评估模型。例如:
python gen_api_answer.py --bench-name live_bench/reasoning/web_of_lies_new_prompt --model claude-3-5-sonnet --question-source jsonl
python gen_ground_truth_judgment.py --bench-name live_bench/reasoning/web_of_lies_new_prompt --question-source jsonl
python show_livebench_result.py --bench-name live_bench/reasoning/web_of_lies_new_prompt
评估新模型及配置 API 参数dee
任何具备 OpenAI 兼容端点的基于 API 的模型,只需使用 --api-base 和 --api-key(或 --api-key-name)参数即可开箱即用。若希望为本地文件覆盖模型名称(例如将保存名为 deepseek-v3 而非 deepseek-chat),可使用 --model-display-name 参数。此外,您还可以分别通过 --force-temperature 和 --max-tokens 参数来覆盖温度和最大标记数的值。
若希望实现持久化的模型配置而无需每次指定命令行参数,可在 livebench/model/model_configs 目录下创建一个 YAML 格式的模型配置文件。请参考该目录下的其他文件以了解所需格式。其中重要的字段包括 model_display_name,它决定了答案 .jsonl 文件名以及供其他脚本使用的模型 ID;还有 api_name,用于建立 API 提供商与该 API 中模型名称之间的映射关系。例如,Deepseek R1 可以通过 Deepseek API 以 deepseek-reasoner 作为名称进行评估,也可以通过 Together API 以 deepseek-ai/deepseek-r1 作为名称进行评估。api_kwargs 允许您为所有提供商或特定提供商设置温度、最大标记数和 top p 等参数的覆盖值。完成上述配置后,在运行 run_livebench.py 时,即可使用 --model <model_name>,其中 <model_name> 应与 YAML 文件中填写的 model_display_name 值一致。
在执行推理时,可使用 --model-provider-override 参数来覆盖您希望为该模型使用的提供商。
我们还实现了对 Anthropic、Cohere、Mistral、Together 和 Google 模型的推理支持,因此这些模型同样可以通过使用 --model-provider-override 或向相应配置文件添加新条目而立即投入使用。
若要使用与 OpenAI 不兼容的新提供商的模型,则需要在 completions.py 中实现一个新的补全函数,并将其添加到该文件中的 get_api_function 函数中;随后,您便可在模型配置中使用该函数。
文档
在此,我们介绍我们的数据集文档。相关信息亦可在我们的论文中找到。
引用
@inproceedings{livebench,
title={LiveBench: 一个具有挑战性且无污染的 {LLM} 基准测试},
author={Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, Micah Goldblum},
booktitle={第十三届国际学习表征会议},
year={2025},
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。