AlphaFold3
AlphaFold3 是由 Ligo 团队推出的开源项目,旨在复现并开放 Google DeepMind 革命性的生物分子结构预测模型。它核心解决了如何高精度预测蛋白质及其与其他分子(如配体、核酸)复合体三维结构的难题,为药物研发和基础生物学研究提供关键工具。
目前,该项目处于早期活跃研发阶段,优先发布了单链蛋白质的预测与完整训练代码,后续将逐步支持更复杂的复合物预测。由于包含完整的训练流程且尚未达到生产级稳定状态,AlphaFold3 主要面向人工智能研究人员、生物计算开发者以及希望深入探索结构预测算法的科研团队,普通用户建议等待后续成熟版本。
在技术亮点上,AlphaFold3 不仅复用了 OpenFold 的核心模块和 ProteinFlow 的高效数据管道,还引入了由社区贡献者优化的 Triton 内核。这一改进使得多序列比对(MSA)处理的内存效率比原生 PyTorch 实现提升了十倍以上,有效突破了长序列训练的瓶颈。此外,团队修正了原论文伪代码中模块顺序的逻辑缺陷,确保所有计算块都能有效贡献于最终的结构预测结果。作为一个致力于推动生物技术社区自由创新的开源项目,AlphaFold3 正通过公开测试不断迭代完善。
使用场景
某生物医药初创公司的算法团队正致力于开发针对罕见酶缺陷的新型小分子抑制剂,急需快速解析目标蛋白与潜在药物分子的结合构象以指导实验。
没有 AlphaFold3 时
- 复现门槛极高:团队只能依赖 Google DeepMind 发布的伪代码论文,需从零构建复杂的三角注意力机制和数据流水线,耗时数月仍难以跑通基准模型。
- 硬件资源受限:原生实现缺乏针对长序列的内存优化,处理大分子量蛋白时显存极易溢出,迫使团队不得不切割序列或降级使用精度较低的旧版模型。
- 迭代周期漫长:由于缺乏开源的训练代码和预训练权重,每次调整架构或验证新想法都需要重新从头训练,严重拖慢了从假设到验证的研发节奏。
- 社区支持缺失:遇到算法细节(如 MSA 模块顺序)与文献不一致时,无法参考社区已有的修正方案,只能盲目试错,增加了研发的不确定性。
使用 AlphaFold3 后
- 开箱即用加速落地:直接复用 Ligo 团队基于 ProteinFlow 构建的成熟数据流水线和核心模块,几天内即可在本地部署单链蛋白预测环境,立即投入业务测试。
- 突破算力瓶颈:得益于集成的 Triton 自定义算子,内存效率提升超过 10 倍,团队能在有限的 A100 集群上流畅训练和推理更长的蛋白质序列。
- 敏捷研发闭环:利用已开放的训练代码和快速收敛的动态特性,研究人员可在数小时内完成微调实验,快速验证不同突变体对药物结合的影响。
- 透明可控的优化:开源社区已明确修正了原论文中 MSA 模块顺序的逻辑缺陷,团队可直接采用经过验证的架构,确保结构预测结果的可靠性。
AlphaFold3 开源版通过降低技术门槛和优化计算效率,让中小型生物科技公司也能平等地享受前沿 AI 带来的结构生物学革命。
运行环境要求
- 未说明
- 必需 NVIDIA GPU
- 文中提到在 8 张 A100 GPU 上进行训练
- 使用了 Triton 自定义内核以优化显存,表明对高性能 GPU 有强依赖
- 具体显存大小和 CUDA 版本未在片段中明确说明
未说明

快速开始
AlphaFold3 开源实现
简介
这是 Ligo 对 AlphaFold3 的开源实现,是一项持续进行的研究项目,旨在推动开源生物分子结构预测的发展。本次发布实现了完整的 AlphaFold3 模型及其训练代码。我们首先开放单链预测功能,待配体、多聚体和核酸预测功能训练完成后,将陆续加入。在此报名参与测试。
本仓库旨在加速构建忠实且完全开源的 AlphaFold3 实现,供整个生物科技社区免费使用。
演示视频
我们发现该模型的训练动态非常迅速。以下视频展示的是在 8 张 A100 GPU 上无模板条件下训练了 4,000 步、历时 10 小时的模型输出示例。

动画制作:Matthew Clark
致谢
本项目离不开以下项目及个人的贡献:
Google DeepMind 的 AlphaFold3 团队,感谢他们开创性的研究工作以及核心算法的公开。
OpenFold 项目(https://github.com/aqlaboratory/openfold),该项目为开源蛋白质结构预测奠定了基础。我们复用了其许多核心模块,如三角注意力机制和乘法更新机制,以及数据处理流程。
ProteinFlow 库(https://github.com/adaptyvbio/ProteinFlow),尤其是 ProteinFlow 的架构师 Liza Kozlova(@elkoz),她在整个过程中发挥了至关重要的作用。我们的大部分原型模型都是基于 ProteinFlow 进行训练的,因为它提供了一个简洁且文档完善的蛋白质数据处理管道。我们已与 AdaptyvBio 合作,基于 ProteinFlow 构建了支持完整配体和核酸的 AlphaFold3 数据管道。目前,@elkoz 和 @igor-krawczuk 正在开发 ProteinFlow 的下一个版本,以全面支持这些数据模态。
@alexzhang13,感谢他在 Triton 中实现的自定义 MSA 对权重平均核,对于较长序列而言,其内存效率比 PyTorch 实现高出 10 倍以上。这一改进有效缓解了大规模序列训练中的关键性能瓶颈。衷心感谢 Alex 对本项目的贡献!
项目状态
本项目仍处于早期阶段,属于一项活跃的研究工作。我们正致力于为社区准备一个稳定的版本。尽管我们对这项工作的潜力充满期待,但仍需强调,目前它尚未达到生产级工具的标准。我们已针对单链蛋白质训练了一个 AlphaFold3 版本以测试实现效果;下一版将包含完整的配体和核酸支持。我们正在招募少量测试用户,协助我们测试实现并提供反馈。如果您有意参与测试,请 加入我们的候补名单。
与 AlphaFold3 伪代码的差异
在项目推进过程中,我们发现 AlphaFold3 补充资料中描述的一些算法特性与现有的深度学习文献并不一致。具体如下:
MSA 模块顺序:补充资料中,MSA 模块的通信步骤位于 MSA 堆栈之前。这导致最后一个区块的 MSA 堆栈无法参与结构预测,因为所有信息都通过成对表示流出。按照伪代码中的顺序,最后一层的 MSA 堆栈没有机会更新成对表示。为此,我们将 OuterProductMean 操作与 MSA 堆栈的位置互换,以确保所有区块都能对结构预测做出贡献。值得注意的是,这一调整与 AlphaFold2 的 ExtraMSAStack 中的操作顺序一致。DeepMind 提到这些 MSA 模块是“同质的”,但并未明确是指共享权重还是具有相同的架构。若各层确实共享权重,则梯度会流经所有模块,然而最终的 MSA 堆栈计算却未被利用——这部分可以安全跳过(补充资料中未提及)。我们将在收到 DeepMind 的回复后进一步澄清这一问题。
损失缩放:补充资料中描述的损失缩放因子在初始化时无法产生单位损失。而单位损失作为初始条件,是 Karras 等人(2022)在训练扩散模型时提出的理想损失函数特性之一;Max Jaderberg 在一次演讲中也提到,他们之所以选择 Karras 等人的框架,正是基于这一特性。我们认为,补充资料中的这一问题可能是一个简单的笔误,即将加法误写为乘法。在我们的实现中,我们采用了与 Karras 等人(2022)一致的损失缩放因子。实测表明,这样可以在初始化时获得单位均方误差损失,而补充资料中的缩放因子在初始化时则大了两到三个数量级。此外,论文中的损失缩放因子在 t=16.0 处存在局部最小值,随后会随噪声水平的增加而增大。这与 Karras 等人(2022)提出的损失函数特性不符——后者强调应在高噪声水平下降低损失权重。我们在仓库中添加了一个 Jupyter 笔记本,展示了我们的实验结果。
DiT 块设计:AttentionPairBias 和 DiffusionTransformer 块的设计似乎紧密遵循 Peebles & Xie(2022)提出的 DiT 块设计。然而,这些模块缺少残差连接。论文并未解释 DeepMind 为何选择省略残差连接。我们分别进行了实验,发现在我们训练的步数范围内,带有残差连接的 DiT 块能够显著加快收敛速度,并改善网络中的梯度流动。需要注意的是,这是我们最不确定的一处差异,如果原始实现确实未使用残差连接,只需在我们的代码中简单修改几行即可。
以上内容旨在提高透明度,并邀请社区共同探讨解决这些问题的最佳方案。
模型效率
本次实现的一个重要侧重点是优化模型各组件的速度和内存效率。AlphaFold3 包含许多类似 Transformer 的组件,但由于 AlphaFold3 中的成对偏置机制,诸如 FlashAttention2 等高效的硬件感知注意力实现无法直接与这些模块无缝集成。所有注意力操作都会从成对表示中投影出一个成对偏置,该偏置会在键—查询点积之后被添加,并且需要将梯度反向传播回去。这并非 FlashAttention2 无法处理的范围,因为该偏置的梯度与缩放后的 QK^T 点积梯度相同,然而当前的实现并不支持这一点。更近期的注意力实现,如 FlexAttention,前景十分可观,但它们目前同样不支持偏置梯度,因为在前向传播过程中对偏置张量执行的广播操作,在反向传播时会变为约简操作,而这一功能尚未在 FlexAttention 的首个版本中实现。
我们尽可能复用 OpenFold 项目中经过实战检验的组件,例如 TriangularAttention 和 TriangularMultiplicativeUpdate。OpenFold 项目的模块化设计使我们能够轻松地将这些模块导入到我们的代码库中。我们正利用 Triton 对这些模块进行效率改进,通过融合操作来提升性能并减少中间张量的分配。
我们观察到,在 PyTorch 中对扩散模块进行朴素实现时,经常会因内存不足而报错,这是因为每个批次中扩散模块会被复制 48 次。为解决这一问题,我们重新利用 Deepspeed4Science 中的 MSARowAttentionWithPairBias 内核,实现了一个内存高效的扩散模块版本,将不同噪声水平下的批次副本视为额外的批次维度。对于 AtomAttentionEncoder 和 AtomAttentionDecoder 模块,我们尝试了自定义的 PyTorch 原生实现,以将内存占用从二次方降低到线性,但与简单地重用 AttentionPairBias 内核相比,收益并不显著。我们在仓库中同时提供了这两种实现,不过为了保持代码简洁,我们仍采用朴素的实现方式。
尽管进行了上述优化,我们的性能分析实验表明,模型超过 60% 的操作都受内存限制。我们正在基于 ScaleFold 的思路,开发一种更为高效且可扩展的实现方案,这将使我们能够达到原始 AlphaFold3 的训练规模。
MSA 成对平均效率
@alexzhang13 使用 Triton 实现了一个快速且内存高效的自定义 MSA 成对加权平均内核。
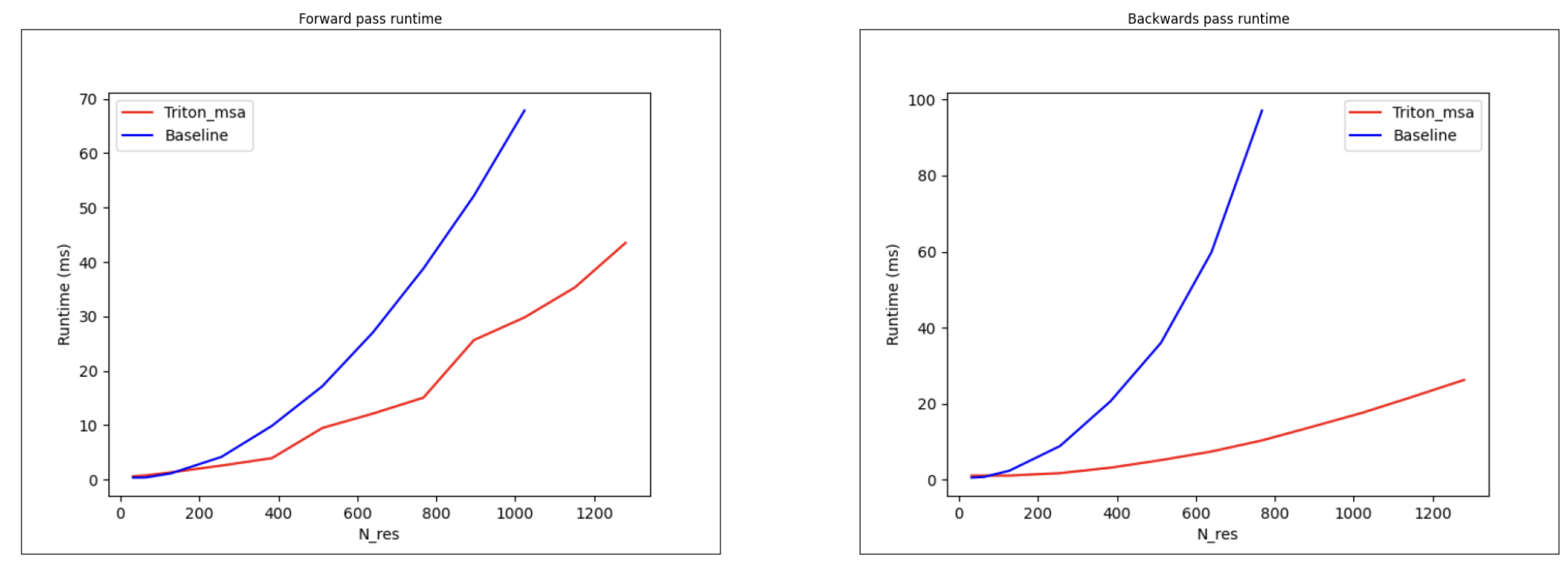
我们曾注意到,MSA 成对加权平均操作是关键的内存瓶颈之一。AlphaFold3 论文中指出,该操作用一种“更廉价”的成对加权平均替代了 MSARowAttentionWithPairBias 操作,但在 PyTorch 中以朴素方式实现时,其内存使用量却比 Deepspeed4Science 的 MSARowAttentionWithPairBias 内核高出四倍。我们推测,这是由于 FlashAttention 中的分块和重计算技巧所带来的内存效率提升,而这些技巧也被整合到了 Deepspeed4Science 的 MSARowAttentionWithPairBias 内核中。
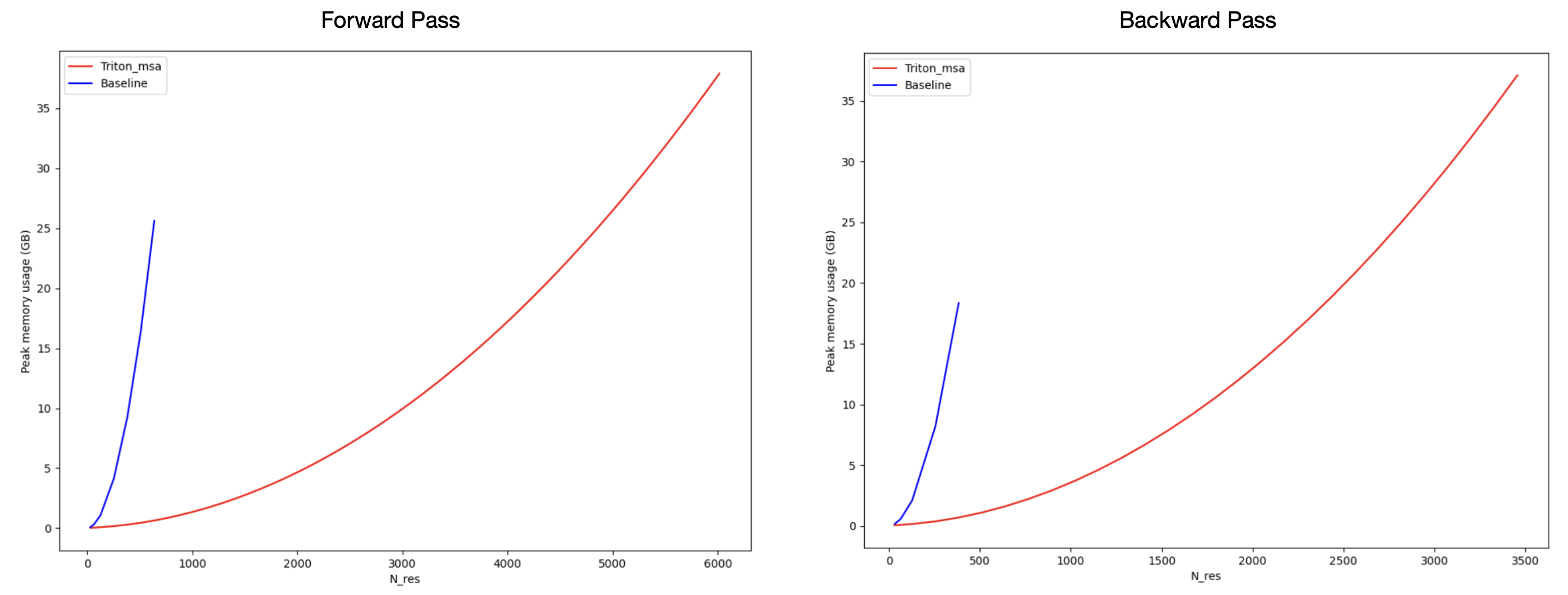
朴素的成对加权平均实现会分配一个 (*, N_seq, N_res, N_res, heads, c_hidden) 形状的中间张量,即使对于中等长度的序列,这个张量也大到无法容纳在 GPU 内存中。
Alex 的内核使得网络能够在单个 GPU 上扩展到数千个 token!
PyTorch 与 Triton 内核的内存使用对比
PyTorch 与 Triton 内核的运行时间对比
快速入门
我们目前尚未提供采样代码,因为配体—蛋白质及核酸预测功能仍有待训练。研究人员可以使用 PyTorch Lightning 的检查点加载功能来加载预训练权重,进行实验和模型修改。当前模型仅能预测单链蛋白质,其功能与原始 AlphaFold2 相同。模型组件的设计具有高度的可重用性和模块化,便于研究者将其轻松集成到自己的项目中。 如需参与配体—蛋白质及核酸预测功能的测试,请加入我们的候补名单:加入候补名单
使用说明
目前,本仓库的主要用途是科研与开发。待配体—蛋白质及核酸预测功能准备就绪后,我们将逐步增加面向用户的实用功能。
贡献指南
我们欢迎社区的贡献!我们的代码中很可能存在许多 bug 和细微的实现错误。深度学习训练往往会出现静默失败的情况,即虽然网络仍能收敛,但性能会因此略有下降。如果您有意贡献代码,可以通过 GitHub 提交包含问题描述的 issue,或者直接 fork 本仓库,创建新分支并提交带有清晰变更说明的 pull request。
如有其他意见或建议,请通过电子邮件 alphafold3@ligo.bio 与我们联系。
引用
如果您在研究中使用此代码,请引用以下论文:
@article{Abramson2024-fj,
title = {利用{AlphaFold} 3 准确预测生物分子相互作用的结构},
author = {Abramson, Josh 和 Adler, Jonas 和 Dunger, Jack 和 Evans, Richard 和 Green, Tim 和 Pritzel, Alexander 和 Ronneberger, Olaf 和 Willmore, Lindsay 和 Ballard, Andrew J 和 Bambrick, Joshua 和 Bodenstein, Sebastian W 和 Evans, David A 和 Hung, Chia-Chun 和 O'Neill, Michael 和 Reiman, David 和 Tunyasuvunakool, Kathryn 和 Wu, Zachary 和 {\v Z}emgulyt{\.e}, Akvil{\.e} 和 Arvaniti, Eirini 和 Beattie, Charles 和 Bertolli, Ottavia 和 Bridgland, Alex 和 Cherepanov, Alexey 和 Congreve, Miles 和 Cowen-Rivers, Alexander I 和 Cowie, Andrew 和 Figurnov, Michael 和 Fuchs, Fabian B 和 Gladman, Hannah 和 Jain, Rishub 和 Khan, Yousuf A 和 Low, Caroline M R 和 Perlin, Kuba 和 Potapenko, Anna 和 Savy, Pascal 和 Singh, Sukhdeep 和 Stecula, Adrian 和 Thillaisundaram, Ashok 和 Tong, Catherine 和 Yakneen, Sergei 和 Zhong, Ellen D 和 Zielinski, Michal 和 {\v Z}{\'\i}dek, Augustin 和 Bapst, Victor 和 Kohli, Pushmeet 和 Jaderberg, Max 和 Hassabis, Demis 和 Jumper, John M},
journal = {Nature},
month = {5月},
year = 2024
}
@article {Ahdritz2022.11.20.517210,
author = {Ahdritz, Gustaf 和 Bouatta, Nazim 和 Floristean, Christina 和 Kadyan, Sachin 和 Xia, Qinghui 和 Gerecke, William 和 O{\textquoteright}Donnell, Timothy J 和 Berenberg, Daniel 和 Fisk, Ian 和 Zanichelli, Niccol{\`o} 和 Zhang, Bo 和 Nowaczynski, Arkadiusz 和 Wang, Bei 和 Stepniewska-Dziubinska, Marta M 和 Zhang, Shang 和 Ojewole, Adegoke 和 Guney, Murat Efe 和 Biderman, Stella 和 Watkins, Andrew M 和 Ra, Stephen 和 Lorenzo, Pablo Ribalta 和 Nivon, Lucas 和 Weitzner, Brian 和 Ban, Yih-En Andrew 和 Sorger, Peter K 和 Mostaque, Emad 和 Zhang, Zhao 和 Bonneau, Richard 和 AlQuraishi, Mohammed},
title = {{O}pen{F}old: 重新训练 {A}lpha{F}old2 能够带来对其学习机制和泛化能力的新见解},
elocation-id = {2022.11.20.517210},
year = {2022},
doi = {10.1101/2022.11.20.517210},
publisher = {Cold Spring Harbor Laboratory},
URL = {https://www.biorxiv.org/content/10.1101/2022.11.20.517210},
eprint = {https://www.biorxiv.org/content/early/2022/11/22/2022.11.20.517210.full.pdf},
journal = {bioRxiv}
}
@article{kozlova_2023_proteinflow,
author = {Kozlova, Elizaveta 和 Valentin, Arthur 和 Khadhraoui, Aous 和 Gutierrez, Daniel Nakhaee-Zadeh},
month = {09},
title = {ProteinFlow:用于深度学习应用的蛋白质结构数据预处理 Python 库},
doi = {https://doi.org/10.1101/2023.09.25.559346},
year = {2023},
journal = {bioRxiv}
}
@misc{ahdritz2023openproteinset,
title={{O}pen{P}rotein{S}et:大规模结构生物学的训练数据},
author={Gustaf Ahdritz 和 Nazim Bouatta 和 Sachin Kadyan 和 Lukas Jarosch 和 Daniel Berenberg 和 Ian Fisk 和 Andrew M. Watkins 和 Stephen Ra 和 Richard Bonneau 和 Mohammed AlQuraishi},
year={2023},
eprint={2308.05326},
archivePrefix={arXiv},
primaryClass={q-bio.BM}
}
@article{Peebles2022DiT,
title={基于 Transformer 的可扩展扩散模型},
author={William Peebles 和 Saining Xie},
year={2022},
journal={arXiv 预印本 arXiv:2212.09748},
}
@inproceedings{Karras2022edm,
author = {Tero Karras 和 Miika Aittala 和 Timo Aila 和 Samuli Laine},
title = {阐明基于扩散的生成模型的设计空间},
booktitle = {NeurIPS 会议论文集},
year = {2022}
}
许可证
本项目采用 Apache License 2.0 许可证授权——详情请参阅 LICENSE 文件。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。