Awesome-Deep-Camera-Calibration
Awesome-Deep-Camera-Calibration 是一个专注于深度学习相机标定领域的开源资源汇总项目,旨在为研究人员和开发者提供一份全面、前沿的学术指南。它核心解决了传统相机标定方法在复杂场景下适应性不足的问题,系统梳理了如何利用深度学习技术实现更精准的参数估计、姿态推算乃至三维重建。
该项目不仅收录了经典的几何视觉理论,更构建了一套完整的深度学习标定分类体系,涵盖了从基础原理、最新算法模型到专用数据集和基准测试(Benchmark)的全方位内容。其独特亮点在于持续更新的文献综述,已纳入超过 100 篇 2023 至 2024 年的最新论文,并深入探讨了神经辐射场(NeRF)等新兴技术与标定任务的结合。此外,项目还提出了具有潜力的新型标定表示方法,有望替代传统的神经网络优化目标。
无论是从事计算机视觉、摄影测量、具身智能研究的学者,还是希望深入了解相机成像原理的工程师,都能从中获得宝贵的参考。通过结构化的知识整理和开放的社区维护,Awesome-Deep-Camera-Calibration 降低了进入该专业领域的门槛,是推动空间智能与多模态视觉技术发展的重要基础设施。
使用场景
某自动驾驶初创团队正在开发基于多目视觉的感知系统,急需在复杂光照和动态场景下获取高精度的相机内外参数以重建 3D 环境。
没有 Awesome-Deep-Camera-Calibration 时
- 标定流程繁琐低效:工程师需人工打印棋盘格并在不同位置拍摄大量照片,一旦光线变化或镜头微调,必须重新采集数据并运行传统算法(如 Zhang 氏标定法)。
- 极端场景失效:在夜间、强反光或纹理缺失的道路上,传统特征点检测极易失败,导致标定参数误差大,直接影响深度估计精度。
- 技术选型迷茫:面对层出不穷的深度学习标定论文,团队难以快速梳理出适合车载嵌入式设备的轻量级模型,研发周期被文献调研严重拖慢。
- 缺乏统一基准:自测数据与公开数据集格式不一,无法客观评估新算法相对于现有 SOTA(最先进)方法的真实性能提升。
使用 Awesome-Deep-Camera-Calibration 后
- 端到端智能标定:团队直接复用综述中推荐的深度学习方案,仅需少量自然图像即可实现端到端参数回归,无需依赖特定标定板,大幅缩短部署时间。
- 鲁棒性显著增强:引入基于神经网络的标定表示方法,即使在低光照或运动模糊条件下,也能保持亚像素级的标定精度,提升了感知系统的稳定性。
- 研发路径清晰:利用其完善的分类体系(Taxonomy)和统计图表,团队迅速锁定了兼顾精度与速度的模型架构,避免了重复造轮子。
- 标准化性能评估:直接使用项目提供的 Benchmark 数据集和评估脚本,量化验证了算法改进效果,确保模型上线前的可靠性。
Awesome-Deep-Camera-Calibration 通过整合前沿理论与标准化基准,将相机标定从耗时的人工实验转变为高效、鲁棒的智能化流程,加速了 3D 视觉应用的落地。
运行环境要求
未说明
未说明
快速开始
高效深度相机标定
![]()
![]()
![]()
![]()

更多内容和详细信息,请参阅我们的调查论文:基于深度学习的相机标定及其拓展:一份调查。
🚩目录
📢新闻
我们近期的研究成果——Puffin,能够将以相机为中心的理解(相机标定、姿态估计)与生成能力(相机可控的T2I和I2I生成)统一在一个连贯的多模态框架中。通过我们提出的“用相机思考”方式,Puffin实现了更精准的理解与生成性能,并深入探讨了多模态任务之间有意义的相互作用。如果您对相机相关的3D视觉、摄影、具身人工智能以及空间智能感兴趣,请访问这里了解更多详情。
📝变更记录
- 2025年2月24日:更新了基于学习的相机标定中关于“新型标定表示法”的相关内容,这些表示法展现了替代传统标定目标用于神经网络的潜力。
- 2025年2月24日:更新了2023年和2024年的文献综述(新增100多篇论文!)。更多详细信息请参阅我们的arXiv v3 版本。
- 2024年6月5日:更新了调查论文(补充材料),并对所构建的基准进行了评估。
- 2024年6月5日:更新了调查论文(第3.3.3节:基于重建的标定),并就NeRF进行了更多技术性讨论,尤其是在相机参数初始化方面。
- 2024年6月4日:我们对基准测试中已标定的相机参数进行了进一步的详细说明。
- 2024年1月5日:基准测试正式发布。请参阅数据集链接及更多细节,详见基准测试。
- 2023年3月19日:arXiv版本的调查报告已上线。
📖基础知识
- 计算机视觉中的多视图几何 - Hartley, R., & Zisserman, A. (2004)
- 一种灵活的全新相机标定技术 - Zhang Zhengyou. (2000)
📊分类与统计
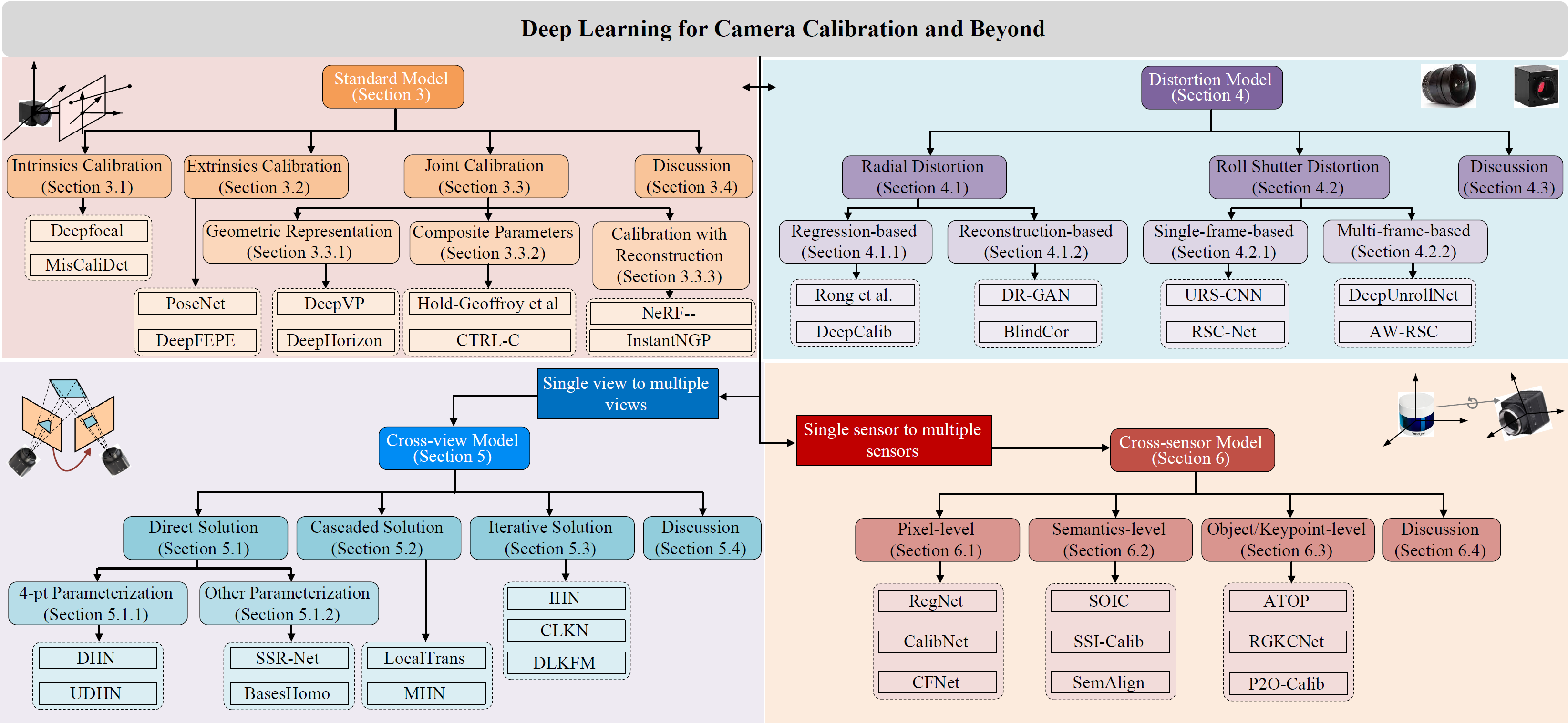

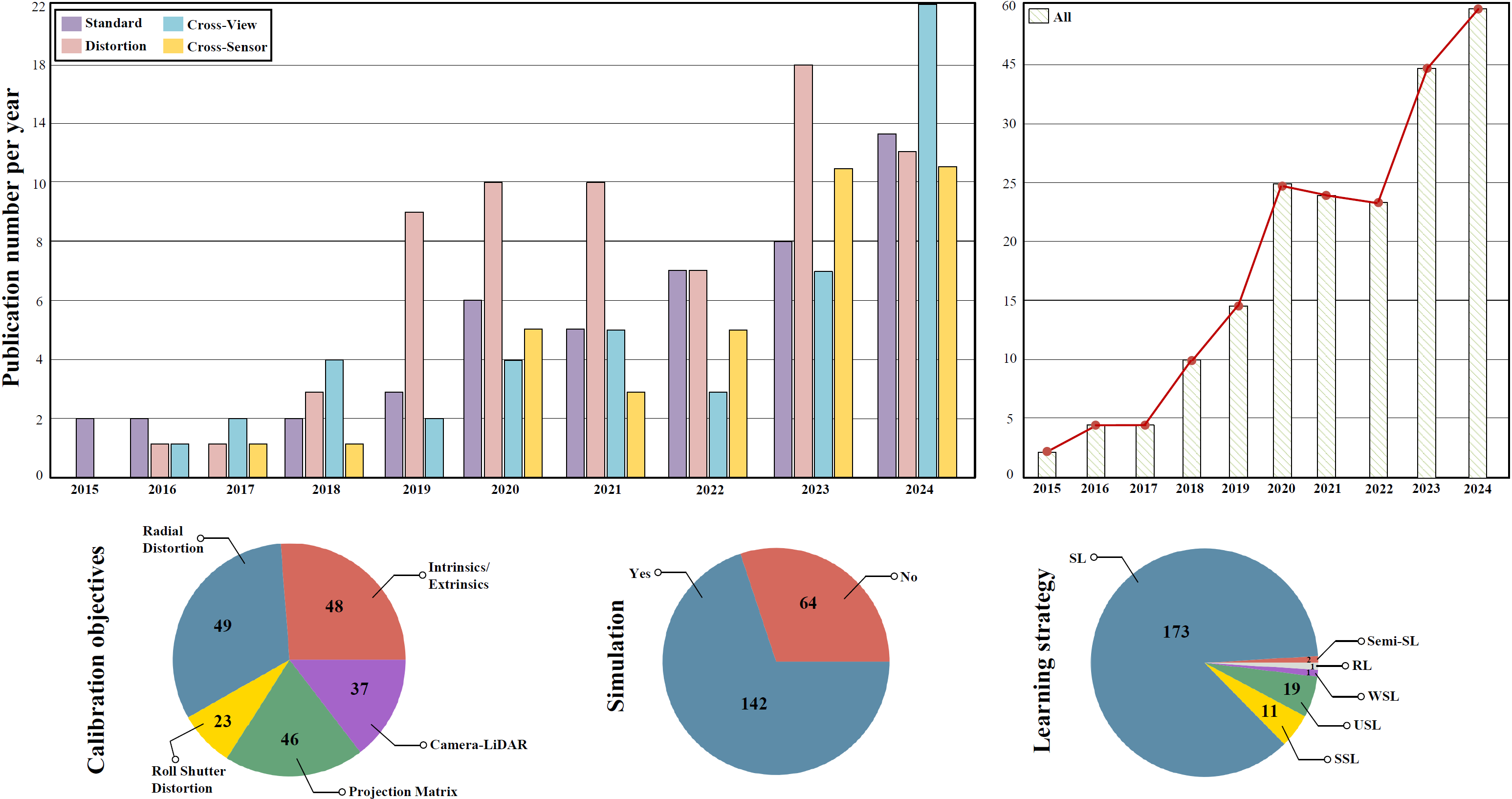
📁基准测试

🏁新型标定表示法
📸方法
| 年份 | 出版物 | 标题 | 缩写 | 目标 | 平台 | 网络 |
|---|---|---|---|---|---|---|
| 2015 | ICIP | Deepfocal:一种直接估算焦距的方法 | DeepFocal | 内参 | Caffe | AlexNet |
| 2015 | ICCV | Posenet:一种用于实时6自由度相机重新定位的卷积神经网络 | PoseNet | 外参 | Caffe | GoogLeNet |
| 2016 | BMVC | 野外环境中的水平线 | DeepHorizon | 外参 | Caffe | GoogLeNet |
| 2016 | CVPR | 利用全局图像上下文在非曼哈顿世界中检测消失点 | DeepVP | 外参 | Caffe | AlexNet |
| 2016 | ACCV | 利用合成图像训练的卷积神经网络进行径向镜头畸变校正 | Rong等 | 畸变系数 | Caffe | AlexNet |
| 2016 | RSSW | 深度图像同构估计 | DHN | 投影矩阵 | Caffe | VGG |
| 2017 | CVPR | Clkn:用于图像对齐的级联Lucas-Kanade网络 | CLKN | 投影矩阵 | Torch | CNN + Lucas-Kanade层 |
| 2017 | ICCVW | 利用层次化卷积神经网络从图像对中估计同构矩阵 | HierarchicalNet | 投影矩阵 | TensorFlow | VGG |
| 2017 | CVPR | Unrolling the Shutter:使用CNN校正运动畸变 | URS-CNN | 去畸变 | Torch | CNNs |
| 2017 | IV | RegNet:利用深度神经网络实现多模态传感器配准 | RegNet | 相机+激光雷达 | Caffe | CNNs |
| 2018 | CVPR | 用于深度单张图像相机标定的感知性指标 | Hold-Geoffroy等 | 内参+外参 | DenseNet | |
| 2018 | CVMP | DeepCalib:一种用于广角相机自动内参校准的深度学习方法 | DeepCalib | 内参+畸变系数 | TensorFlow | Inception-V3 |
| 2018 | ECCV | FishEyeRecNet:一种用于鱼眼图像矫正的多情境协作深度网络 | FishEyeRecNet | 畸变系数 | Caffe | VGG |
| 2018 | ICPR | 通过在卷积神经网络中添加带有反向视网膜模型的权重层来校正径向镜头畸变 | Shi等 | 畸变系数 | PyTorch | ResNet |
| 2018 | ECCV | 深度基础矩阵估计 | DeepFM | 投影矩阵 | PyTorch | ResNet |
| 2018 | ECCVW | 无对应关系下的深度基础矩阵估计 | Poursaeed等 | 投影矩阵 | CNNs | |
| 2018 | RAL | 无监督深度同构:一种快速且鲁棒的同构估计模型 | UDHN | 投影矩阵 | TensorFlow | VGG |
| 2018 | ACCV | 重新思考基于透视场的平面同构估计 | PFNet | 投影矩阵 | TensorFlow | FCN |
| 2018 | IROS | CalibNet:利用三维空间变换网络进行几何监督的外参校准 | CalibNet | 相机+激光雷达 | TensorFlow | ResNet |
| 2018 | ICRA | DeepVP:基于深度学习的100万张街景图像消失点检测 | Chang等 | 标准 | Matconvnet | AlexNet |
| 2019 | CVPR | 利用径向畸变进行深度单张图像相机标定 | Lopez等 | 内参+外参+畸变系数 | PyTorch | DenseNet |
| 2019 | ICCV | UprightNet:基于单张图像的几何感知相机朝向估计 | UprightNet | 外参 | PyTorch | U-Net |
| 2019 | IROS | 重新审视自校准中的退化问题,并为未校准的SLAM提出一种深度学习解决方案 | Zhuang等 | 内参+畸变系数 | PyTorch | ResNet |
| 2019 | PRL | 利用可逆约束的自监督深度同构估计 | SSR-Net | 投影矩阵 | PyTorch | ResNet |
| 2019 | ICCVW | 一种从图像中获取鸟瞰视角的几何方法 | Abbas等 | 投影矩阵 | TensorFlow | CNNs |
| 2019 | TCSVT | DR-GAN:利用条件GAN在实时环境中自动进行径向畸变校正 | DR-GAN | 去畸变 | TensorFlow | GANs |
| 2019 | TCSVT | 从静态到动态的畸变校正:从畸变序列构建的角度来看 | STD | 去畸变 | TensorFlow | GANs |
| 2019 | VR | Deep360Up:一种基于深度学习的自动VR图像直立调整方法 | Deep360Up | 外参 | DenseNet | |
| 2019 | JVCIR | 通过具有几何先验的双向损失实现无监督鱼眼图像矫正 | UnFishCor | 畸变系数 | TensorFlow | VGG |
| 2019 | CVPR | 通过深度学习实现图像的盲目几何畸变校正 | BlindCor | 去畸变 | PyTorch | U-Net |
| 2019 | CVPR | 学习结构与运动感知的滚动快门校正 | RSC-Net | 去畸变 | PyTorch | ResNet |
| 2019 | CVPR | 学习为鱼眼图像矫正校准直线 | Xue等 | 畸变系数 | PyTorch | ResNet |
| 2019 | ICCV | 学习人物肖像的视角去畸变 | Zhao等 | 内参+去畸变 | VGG + U-Net | |
| 2019 | NeurIPS | NeurVPS:通过圆锥卷积实现神经消失点扫描 | NeurVPS | 标准 | PyTorch | CNNs |
| 2020 | CVPR | 端到端的广播视频相机标定 | Sha等 | 投影矩阵 | TensorFlow | Siamese-Net + U-Net |
| 2020 | ECCV | 单张图像相机标定的神经几何解析器 | Lee等 | 内参+外参 | PointNet + CNNs | |
| 2020 | ICRA | 学习相机误差检测 | MisCaliDet | 平均像素位置差异 | TensorFlow | CNNs |
| 2020 | WACV | DeepPTZ:PTZ相机的深度自校准 | DeepPTZ | 内参+外参+畸变系数 | PyTorch | Inception-V3 |
| 2020 | CVPR | 动态场景下的深度同构估计 | MHN | 投影矩阵 | TensorFlow | VGG |
| 2020 | ACMMM | SRHEN:通过在深层潜在空间中解析几何对应关系,逐步细化同构估计网络 | SRHEN | 投影矩阵 | CNNs | |
| 2020 | ECCV | 通过分割实现360°相机对齐 | Davidson等 | 外参 | FCN | |
| 2020 | ECCV | 内容感知的无监督深度同构估计 | CA-UDHN | 投影矩阵 | PyTorch | FCN + ResNet |
| 2020 | IROS | 基于几何约束的深度关键点相机姿态估计 | DeepFEPE | 外参 | PyTorch | VGG + PointNet |
| 2020 | TIP | 无需模型的畸变校正框架,由畸变分布图桥梁 | DDM | 去畸变 | Tensorflow | GANs |
| 2020 | TIP | 针对360°双鱼眼相机的深度人脸矫正 | Li等 | 去畸变 | CNNs | |
| 2020 | ICPR | 基于位置感知并增强对称性的GAN用于径向畸变校正 | PSE-GAN | 去畸变 | GANs | |
| 2020 | ICIP | 一种简单而有效的径向畸变校正流程 | RDC-Net | 去畸变 | PyTorch | ResNet |
| 2020 | ICASSP | 用于鱼眼图像矫正的自监督深度学习 | FE-GAN | 去畸变 | PyTorch | GANs |
| 2020 | CVPR | RDCFace:用于人脸识别的径向畸变校正 | RDCFace | 去畸变 | ResNet | |
| 2020 | arXiv | 从深邃的直线中校正鱼眼畸变 | LaRecNet | 畸变系数 | PyTorch | ResNet |
| 2020 | CVPR | 从单个视角进行3D预测时的高度和垂直度不变性 | Baradad等 | 内参+外参 | PyTorch | CNNs |
| 2020 | CVPR | 玻璃板究竟揭示了关于相机标定的哪些信息? | Zheng等 | 内参+外参 | CNNs | |
| 2020 | ECCV | 野外环境中的单视角计量 | Zhu等 | 内参+外参 | PyTorch | CNNs + PointNet |
| 2020 | CVPR | 深度快门展开网络 | DeepUnrollNet | 去畸变 | PyTorch | FCN |
| 2020 | RAL | RGGNet:通过几何深度学习和生成模型实现的容差感知激光雷达-相机在线校准 | RGGNet | 相机+激光雷达 | Tensorflow | ResNet |
| 2020 | IROS | CalibRCNN:通过递归卷积神经网络和几何约束校准相机与激光雷达 | CalibRCNN | 相机+激光雷达 | Tensorflow | RNN |
| 2020 | ICRA | 通过传感器语义信息实现的在线相机-激光雷达校准 | SSI-Calib | 相机-激光雷达 | Tensorflow | CNNs |
| 2020 | arXiv | SOIC:用于激光雷达和相机的语义在线初始化与校准 | SOIC | 相机-激光雷达 | - | ResNet+PointRCNN |
| 2020 | ICPR | NetCalib:一种基于深度学习的新型激光雷达-相机自动校准方法 | NetCalib | 相机-激光雷达 | PyTorch | CNNs |
| 2021 | TCI | 利用单目深度估计进行立体自校准的在线训练 | StereoCaliNet | 外参 | PyTorch | U-Net |
| 2021 | ICCV | CTRL-C:带线条分类的相机校准TRansformer | CTRL-C | 内参+外参 | PyTorch | Transformer |
| 2021 | ICCVW | 深度单鱼眼图像相机校准,适用于视野超过180度的投影 | Wakai等 | 内参+外参 | DenseNet | |
| 2021 | TIP | 一种用于畸变校正的深度序数畸变估计方法 | OrdianlDistortion | 畸变系数 | TensorFlow | CNNs |
| 2021 | TCSVT | 重新审视极坐标系下的径向畸变校正:一种全新且高效的学习视角 | PolarRecNet | 去畸变 | PyTorch | VGG + U-Net |
| 2021 | PRL | 基于DQN的渐进式鱼眼图像矫正 | DQN-RecNet | 去畸变 | PyTorch | VGG |
| 2021 | CVPR | 利用深度结构化模型进行实用的广角人像矫正 | Tan等 | 去畸变 | PyTorch | U-Net |
| 2021 | CVPR | 利用外观流进行的渐进式互补网络,用于鱼眼图像矫正 | PCN | 去畸变 | PyTorch | U-Net |
| 2021 | ICCV | 用于训练畸变感知桶形畸变校正模型的多级课程 | DaRecNet | 去畸变 | TensorFlow | U-Net |
| 2021 | CVPR | 用于多模态图像对齐的深度Lucas-Kanade同构 | DLKFM | 投影矩阵 | TensorFlow | Siamese-Net |
| 2021 | ICCV | LocalTrans:用于跨分辨率同构估计的多尺度局部变压器网络 | LocalTrans | 投影矩阵 | PyTorch | Transformer |
| 2021 | ICCV | 利用子空间投影进行无监督深度同构估计的运动基学习 | BasesHomo | 投影矩阵 | PyTorch | ResNet |
| 2021 | ICIP | 利用可扩展压缩网络实现快速且精确的同构估计 | ShuffleHomoNet | 投影矩阵 | TensorFlow | ShuffleNet |
| 2021 | TCSVT | 基于深度感知的多网格深度同构估计,结合上下文相关性 | DAMG-Homo | 投影矩阵 | TensorFlow | CNNs |
| 2021 | BMVC | 一种利用自注意力MobileNet的智能手机简单图像倾斜校正方法 | SA-MobileNet | 外参 | TensorFlow | MobileNet |
| 2021 | ICCV | SPEC:利用估计的相机在野外“看见”人们 | SPEC | 内参+外参 | PyTorch | ResNet |
| 2021 | CVPR | 利用方向性学习的宽基线相对相机姿态估计 | DirectionNet | 外参 | TensorFlow | U-Net |
| 2021 | CVPR | 迈向动态场景中的滚动快门校正与去模糊 | JCD | 去畸变 | PyTorch | FCN |
| 2021 | CVPRW | LCCNet:利用成本体积网络实现激光雷达与相机的自校准 | LCCNet | 相机+激光雷达 | PyTorch | CNNs |
| 2021 | Sensors | CFNet:利用校准流网络实现激光雷达-相机配准 | CFNet | 相机+激光雷达 | PyTorch | FCN |
| 2021 | ICCV | 反转滚动快门相机:将滚动快门图像转化为高帧率的全局快门视频 | Fan等 | 畸变 | PyTorch | U-Net |
| 2021 | ICCV | SUNet:用于滚动快门校正的对称去畸变网络 | SUNet | 畸变 | PyTorch | DenseNet+ResNet |
| 2021 | IROS | SemAlign:无标注的相机-激光雷达校准,采用语义对齐损失 | SemAlign | 相机-激光雷达 | PyTorch | CNNs |
| 2022 | CVPR | 深度消失点检测:几何先验让数据集的变化变得微不足道 | DVPD | 外参 | PyTorch | CNNs |
| 2022 | ICRA | 基于视频的自监督相机自校准 | Fang等 | 内参+外参 | PyTorch | CNNs |
| 2022 | ICASSP | 通过相机投影损失进行相机标定 | CPL | 内参+外参 | TensorFlow | Inception-V3 |
| 2022 | CVPR | 迭代深度同构估计 | IHN | 投影矩阵 | PyTorch | Siamese-Net |
| 2022 | CVPR | 无监督同构估计,结合共面性感知的GAN | HomoGAN | 投影矩阵 | PyTorch | GANs |
| 2022 | CVPR | 基于多尺度转换器的半监督广角人像矫正 | SS-WPC | 去畸变 | PyTorch | Transformer |
| 2022 | CVPR | 学习用于现实世界滚动快门校正的自适应扭曲 | AW-RSC | 去畸变 | CNNs | |
| 2022 | CVPR | EvUnroll:基于神经形态事件的滚动快门图像校正 | EvUnroll | 去畸变 | PyTorch | U-Net |
| 2022 | CVPR | 学习用于相机定位的场景地标检测 | Do等 | 外参 | PyTorch | ResNet |
| 2022 | CVPR | DiffPoseNet:直接可微的相机姿态估计 | DiffPoseNet | 外参 | PyTorch | CNNs + LSTM |
| 2022 | CVPR | SceneSqueezer:学习为相机重新定位压缩场景 | SceneSqueezer | 外参 | PyTorch | Transformer |
| 2022 | arXiv | FishFormer:基于环状切分的变压器,用于鱼眼矫正,并探索效能域 | FishFormer | 去畸变 | PyTorch | Transformer |
| 2022 | CVPR | 通过渲染与比较估计焦距和物体姿态 | FocalPose | 内参+外参 | PyTorch | CNNs |
| 2022 | arXiv | DXQ-Net:利用质量感知流动实现的可微激光雷达-相机外参校准 | DXQ-Net | 相机+激光雷达 | PyTorch | CNNs + RNNs |
| 2022 | ITSC | SST-Calib:同时实现激光雷达与相机的空间-时间参数校准 | SST-Calib | 相机+激光雷达 | PyTorch | CNNs |
| 2022 | IROS | 基于学习的相机校准框架,兼具畸变校正与高精度特征检测 | CCS-Net | 去畸变 | PyTorch | UNet |
| 2022 | TIP | SIR:通过多种不同镜头“看见”同一场景,实现自监督图像矫正 | SIR | 去畸变 | PyTorch | ResNet |
| 2022 | TIV | ATOP:一种以注意为导向的优化方法,用于通过跨模态对象匹配实现激光雷达-相机自动校准 | ATOP | 相机+激光雷达 | CNNs | |
| 2022 | ICRA | FusionNet:基于层次化点-像素融合的激光雷达与相机粗细校准网络 | FusionNet | 相机+激光雷达 | PyTorch | CNNs+PointNet |
| 2022 | TIM | 基于关键点的激光雷达-相机在线校准,采用稳健的几何网络 | RGKCNet | 相机+激光雷达 | PyTorch | CNNs+PointNet |
| 2022 | ECCV | 重新思考通用相机模型,用于深度单张图像相机标定,以恢复旋转和鱼眼畸变 | GenCaliNet | 内参+外参+畸变系数 | DenseNet | |
| 2022 | PAMI | 内容感知的无监督深度同构估计及其拓展 | Liu等 | 投影矩阵 | PyTorch | ResNet |
🏗️数据集
| 名称 | 发布版本 | 真实/合成 | 图像/视频 | 目标 | 数据集 |
|---|---|---|---|---|---|
| KITTI | CVPR | 真实 | 视频 | 基础版 | 数据集 |
| MS-COCO | ECCV | 真实 | 图像 | 基础版 | 数据集 |
| SUN360 | CVPR | 真实 | 图像 | 基础版 | 数据集 |
| Places2 | PAMI | 真实 | 图像 | 基础版 | 数据集 |
| CelebA | ICCV | 真实 | 图像 | 基础版 | 数据集 |
| 1DSfM | ECCV | 真实 | 图像 | 焦距 | 数据集 |
| 剑桥地标 | ICCV | 真实 | 视频 | 外参 | 数据集 |
| HLW | BMVC | 真实 | 图像 | 地平线线 | 数据集 |
| YUD | ECCV | 真实 | 图像 | 消失点 | 数据集 |
| ECD | ECCV | 真实 | 图像 | 消失点 | 数据集 |
| SU3 线框图 | ICCV | 合成 | 图像 | 消失点 | 数据集 |
| ScanNet | CVPR | 真实 | 视频 | 外参 | 数据集 |
| 室内-6 | CVPR | 真实 | 图像 | 外参 | 数据集 |
| DeepVP | ICRA | 真实 | 图像 | 消失点 | 数据集 |
| CAHomo | ECCV | 真实 | 视频 | 单应矩阵 | 数据集 |
| MHN | CVPR | 真实 | 视频 | 单应矩阵 | 数据集 |
| UDIS | TIP | 真实 | 视频 | 单应矩阵 | 数据集 |
| Carla-RS | CVPR | 合成 | 视频 | RS 畸变 | 数据集 |
| Fastec-RS | CVPR | 合成 | 视频 | RS 畸变 | 数据集 |
| BS-RSC | CVPR | 真实 | 视频 | RS 畸变 | 数据集 |
| GEV-RS | CVPR | 真实 | 视频 | RS 畸变 | 数据集 |
| LMS | ICASSP | 两者 | 视频 | 径向畸变 | 数据集 |
| SS-WPC | CVPR | 真实 | 图像 | 径向畸变 | 数据集 |
📜许可证
本调查与基准测试仅面向学术研究用途提供。
📚引用格式
@article{kang2023deep,
作者 = {Kang Liao and Lang Nie and Shujuan Huang and Chunyu Lin and Jing Zhang and Yao Zhao and Moncef Gabbouj and Dacheng Tao},
标题 = {深度学习在相机标定及更广泛领域的应用:一项综述},
年份 = {2023},
期刊 = {arXiv:2303.10559}
}
🚩中文手册
🚀使用我们调查的项目与课程
- 相机标定与姿态估计——由美国伦斯勒理工学院的季强教授主讲,课程为ECSE 4961/6650 计算机视觉。
📭联系方式
kang.liao@ntu.edu.sg
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中