deep-residual-networks
deep-residual-networks 是微软亚洲研究院何恺明等人开源的深度学习模型库,实现了经典的 ResNet(残差网络)架构,包括 ResNet-50、ResNet-101 和 ResNet-152 三种规格。
这个工具主要解决了深层神经网络训练中的"退化问题"——当网络层数增加到一定程度后,准确率反而下降,并非过拟合导致,而是优化困难。ResNet 通过引入"跳跃连接"(Skip Connection)让网络学习残差映射,使得训练上百层甚至上千层的网络成为可能,大幅提升了图像识别精度。
这套模型特别适合计算机视觉领域的研究人员和开发者使用。它在 ImageNet 2015 和 COCO 2015 竞赛中包揽了图像分类、目标检测、图像定位等多个项目的第一名,是深度学习领域的里程碑工作。模型基于 Caffe 框架,提供了预训练权重,可用于测试或迁移学习。
技术亮点在于其简洁而有效的残差学习思想:不再让网络直接拟合期望的映射 H(x),而是学习残差 F(x) = H(x) - x,再通过跳跃连接将输入 x 与残差相加。这种设计既保证了网络深度,又避免了梯度消失问题,成为后续众多视觉模型的基础组件。
使用场景
某医疗影像科技公司正在开发一款辅助诊断系统,需要训练深度学习模型来自动识别CT影像中的早期肺结节,以帮助放射科医生提高筛查效率。
没有 deep-residual-networks 时
- 网络深度受限:团队尝试堆叠超过20层的卷积网络,但模型出现严重的梯度消失问题,深层网络反而比浅层网络准确率更低,无法有效提取肺结节的细微纹理特征
- 训练效率低下:为追求更高精度,不得不设计复杂的网络架构和手工调优的初始化策略,单次实验周期长达2-3周,迭代成本极高
- 模型性能瓶颈:在1000张验证集上测试,假阳性率高达15%,对直径小于5mm的微小结节漏检率超过30%,难以满足临床辅助诊断的精度要求
- 硬件资源浪费:为缓解深层网络的训练困难,被迫使用更宽的层结构,导致GPU显存占用翻倍,8卡集群训练时频繁出现OOM错误
使用 deep-residual-networks 后
- 突破深度限制:直接采用ResNet-50架构,通过残差连接让梯度顺畅回传,轻松训练50层以上的网络,深层特征提取能力显著提升,微小结节的纹理模式捕捉更加精准
- 快速收敛复现:基于ImageNet预训练权重进行迁移学习,配合论文提供的标准超参数,模型在3天内完成收敛,研发迭代周期缩短80%
- 精度大幅提升:在相同验证集上测试,假阳性率降至4.2%,微小结节漏检率控制在8%以内,达到放射科住院医师水平的诊断能力
- 资源高效利用:残差结构参数效率更高,显存占用降低40%,单卡即可承载更大batch size训练,8卡集群稳定运行无OOM
deep-residual-networks通过残差学习机制,让医疗影像团队能够训练更深、更准、更高效的神经网络,将AI辅助诊断从实验室原型快速推进到临床可用产品。
运行环境要求
- Linux
必需,多GPU训练(原论文使用8块GPU),单GPU显存可能不足,未说明具体型号和CUDA版本
未说明
快速开始
深度残差网络(Deep Residual Networks)
微软亚洲研究院(Microsoft Research Asia, MSRA)。
目录
简介
本仓库包含论文《Deep Residual Learning for Image Recognition》(http://arxiv.org/abs/1512.03385)中描述的原始模型(ResNet-50、ResNet-101 和 ResNet-152)。这些模型曾用于 ILSVRC 和 COCO 2015 竞赛,并在以下任务中获得第一名:ImageNet 分类、ImageNet 检测、ImageNet 定位、COCO 检测和 COCO 分割。
注意
- Facebook AI Research (FAIR) 提供的包含训练代码的复现版本:博客、代码
- 我们新论文中改进的 1000 层 ResNet 代码,在 CIFAR-10 上达到 4.62% 的测试误差:https://github.com/KaimingHe/resnet-1k-layers
引用
如果您在研究中使用了这些模型,请引用:
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
免责声明与已知问题
- 这些模型是从我们自己的实现转换到较新版本的 Caffe(2016/2/3, b590f1d)。使用此代码得到的数值结果如下表所示。
- 这些模型仅用于测试或微调(fine-tuning)。
- 这些模型并非使用此版本的 Caffe 训练得到。
- 如果您希望在不修改的情况下使用此版本 Caffe 训练这些模型,请注意:
- 对于极深的模型,GPU 显存可能不足。
- 小批量(mini-batch)大小的变化会影响准确率(我们在 8 个 GPU 上使用大小为 256 的小批量,即每个 GPU 32 张图像)。
- 数据增强(data augmentation)的实现可能不同(请参阅我们论文中关于所使用数据增强的说明)。
- 我们在每个 epoch 开始时随机打乱数据。
- 可能存在其他未测试的问题。
- 在我们的 BN(Batch Normalization,批归一化)层中,提供的均值和方差是在训练结束后,使用足够大的训练批次通过平均计算(而非移动平均)严格得到的。数值结果非常稳定(验证误差变化 < 0.1%)。使用移动平均可能会导致不同的结果。
- 在 BN 论文中,BN 层学习 gamma/beta 参数。为了在此版本 Caffe 中实现 BN,我们使用其提供的 "batch_norm_layer"(不学习 gamma/beta),后接 "scale_layer"(学习 gamma/beta)。
- 我们使用 Caffe 的带动量 SGD(Stochastic Gradient Descent,随机梯度下降)实现:v := momentum*v + lr*g。如果您想将这些模型移植到其他库(如 Torch、CNTK),请仔细注意带动量 SGD 可能存在的不同实现:v := momentum*v + (1-momentum)*lr*g,这会改变有效的学习率。
模型
网络结构可视化(工具来自 ethereon):
模型文件:
实验结果
ImageNet 上的训练曲线(实线:单裁剪验证误差;虚线:训练误差):
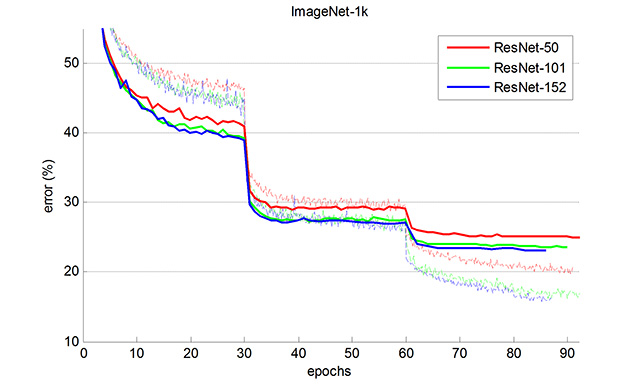
ImageNet 单裁剪(1-crop)验证误差(从短边调整为 256 像素的图像中裁剪中心 224×224 区域):
model top-1 top-5 VGG-16 28.5% 9.9% ResNet-50 24.7% 7.8% ResNet-101 23.6% 7.1% ResNet-152 23.0% 6.7% ImageNet 十裁剪(10-crop)验证误差(从短边调整为 256 像素的图像中裁剪 10 个 224×224 区域并平均 softmax 分数),与论文中的结果相同:
model top-1 top-5 ResNet-50 22.9% 6.7% ResNet-101 21.8% 6.1% ResNet-152 21.4% 5.7%
第三方重新实现
深度残差网络(Deep Residual Networks)非常容易实现和训练。我们建议同时查看以下第三方重新实现和扩展:
- 由 Facebook AI 研究院(Facebook AI Research, FAIR)提供,包含 Torch 训练代码以及针对 ImageNet 的预训练 ResNet-18/34/50/101 模型:博客,代码
- Torch, CIFAR-10,包含 ResNet-20 到 ResNet-110、训练代码及训练曲线:代码
- Lasagne, CIFAR-10,包含 ResNet-32 和 ResNet-56 及训练代码:代码
- Neon, CIFAR-10,包含预训练的 ResNet-32 到 ResNet-110 模型、训练代码及训练曲线:代码
- Torch, MNIST,100 层:博客,代码
- Kaggle 露脊鲸识别挑战赛的获胜方案:博客,代码
- Neon, Place2 (mini),40 层:博客,代码
- MatConvNet, CIFAR-10,包含 ResNet-20 到 ResNet-110、训练代码及训练曲线:代码
- TensorFlow, CIFAR-10,包含 ResNet-32、110、182 的训练代码及训练曲线:代码
- MatConvNet,复现 CIFAR-10 和 ImageNet 实验(支持官方 MatConvNet),包含训练代码及训练曲线:博客,代码
- Keras, ResNet-50:代码
转换器:
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
tesseract
Tesseract 是一款历史悠久且备受推崇的开源光学字符识别(OCR)引擎,最初由惠普实验室开发,后由 Google 维护,目前由全球社区共同贡献。它的核心功能是将图片中的文字转化为可编辑、可搜索的文本数据,有效解决了从扫描件、照片或 PDF 文档中提取文字信息的难题,是数字化归档和信息自动化的重要基础工具。 在技术层面,Tesseract 展现了强大的适应能力。从版本 4 开始,它引入了基于长短期记忆网络(LSTM)的神经网络 OCR 引擎,显著提升了行识别的准确率;同时,为了兼顾旧有需求,它依然支持传统的字符模式识别引擎。Tesseract 原生支持 UTF-8 编码,开箱即用即可识别超过 100 种语言,并兼容 PNG、JPEG、TIFF 等多种常见图像格式。输出方面,它灵活支持纯文本、hOCR、PDF、TSV 等多种格式,方便后续数据处理。 Tesseract 主要面向开发者、研究人员以及需要构建文档处理流程的企业用户。由于它本身是一个命令行工具和库(libtesseract),不包含图形用户界面(GUI),因此最适合具备一定编程能力的技术人员集成到自动化脚本或应用程序中