nlu
NLU 是一个简洁强大的 Python 库,让你只需一行代码就能调用上千个顶尖的自然语言处理模型,支持超过百种语言。无论是情感分析、实体识别、词性标注,还是多语言文本分类,它都能直接在 Pandas、Spark 等数据框上运行,无需复杂配置。它解决了传统 NLP 模型部署繁琐、跨语言支持困难、代码冗长的问题,让开发者和研究人员能快速验证想法、构建原型或集成到生产流程中。特别适合数据科学家、NLP 工程师和需要快速测试文本分析效果的开发者使用。NLU 基于获奖的 Spark NLP 构建,支持模型训练、可视化和一键生成交互式 Web 界面(通过 Streamlit),并兼容多种数据格式。其核心亮点是“一行代码调用 SOTA 模型”,将复杂的技术封装成极简接口,大幅降低使用门槛,同时保留了工业级的性能与可扩展性。
使用场景
一家跨国电商公司正在分析来自日本、德国、巴西等10余国的用户评论,以自动识别产品负面反馈中的具体问题(如“电池续航短”“物流太慢”),并生成中文报告供运营团队快速响应。团队需在一周内完成对20万条多语言评论的语义分析,但缺乏NLP专家和跨语言模型部署经验。
没有 nlu 时
- 需要为每种语言单独寻找、下载并部署不同的预训练模型(如spaCy、Transformers),耗时超过两周。
- 每个模型的输入格式不统一,需为Pandas、Spark DataFrame分别写适配代码,开发复杂度高。
- 模型训练需手动标注数百条样本,再用PyTorch从零搭建分类器,周期长达10天以上。
- 无法可视化实体识别结果,分析师只能看原始JSON,难以快速定位“电池”“物流”等关键实体。
- 部署后无法快速验证效果,测试新模型需重启服务,缺乏交互式调试能力。
使用 nlu 后
- 一行代码
nlu.load('sentiment.multi')即可同时处理日语、德语、葡萄牙语等100+语言的评论,3小时内完成全量分析。 - 直接对Pandas DataFrame调用
.predict(),无需转换数据格式,代码量减少90%。 - 用
nlu.load('ner').fit(comments)仅用50条标注样例训练出精准的“产品问题识别器”,2天内上线。 - 通过
.viz(data)一键生成实体高亮图,清晰看到“电池续航短”被正确识别为产品缺陷实体。 - 用
.viz_streamlit(data)启动交互式仪表盘,运营团队可实时点击评论测试模型效果,即时调整策略。
nlu 让非NLP团队在一周内完成原本需要数月的多语言文本分析任务,真正实现“一行代码,全球洞察”。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始
NLU:Spark NLP的强大功能,Python的简洁易用
John Snow Labs 的 NLU 是一个 Python 库,可直接在任何数据框上应用最先进的文本挖掘技术,只需一行代码即可实现。 作为屡获殊荣的 Spark NLP 库的前端接口,它内置了 1000 多个 预训练模型,涵盖 100 多种语言,全部具备生产级质量、可扩展性和可训练性,且所有操作仅需一行代码。
NLU 实战演示
看看如何轻松地用一行代码调用数千种模型中的任意一种。我们提供了数百个教程和简单示例,你可以直接复制粘贴到自己的项目中,轻松实现最先进水平的自然语言处理效果。
NLU 与 Streamlit 实战演示
只需一行代码,你就能可视化并玩转 1000 多种 SOTA NLU 和 NLP 模型,支持 200 种语言。
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.py
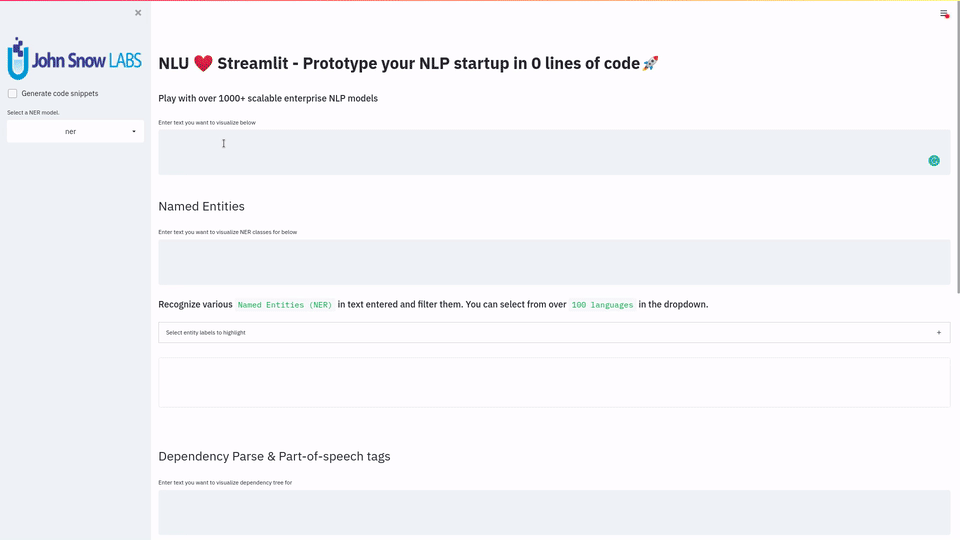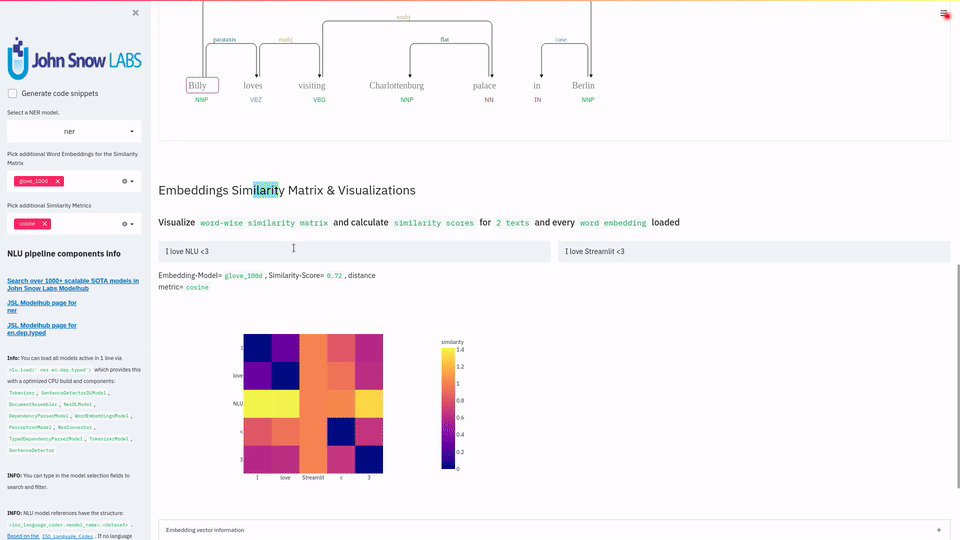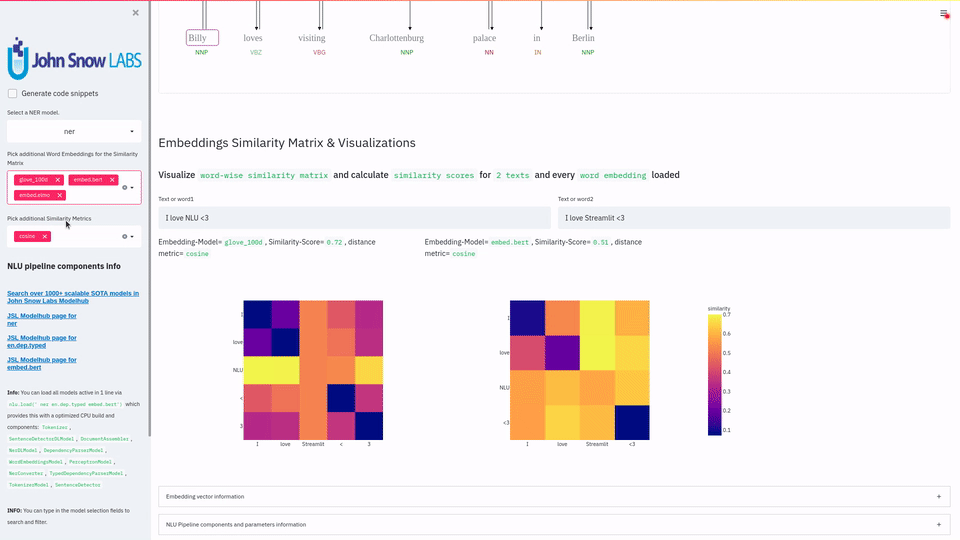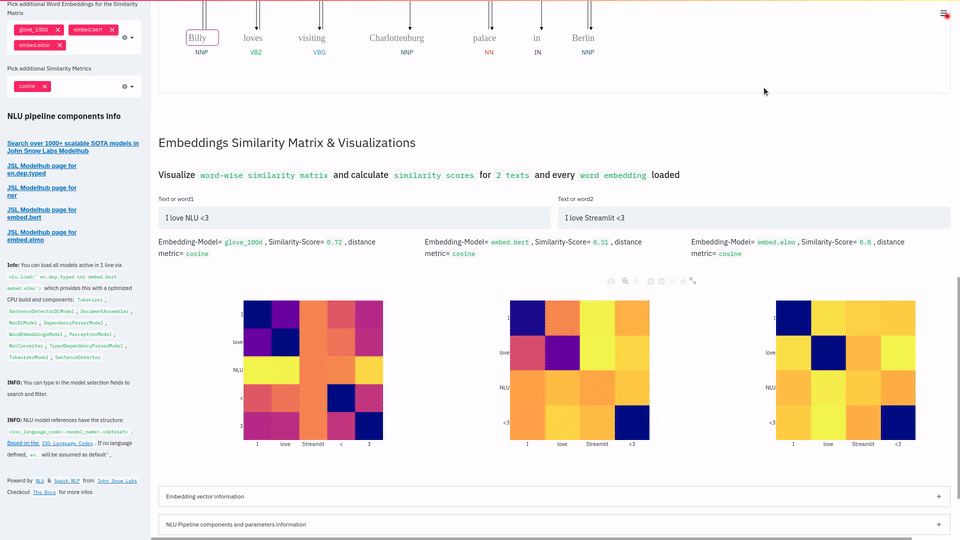
NLU 提供了与 Streamlit 的紧密而简单的集成,让你只需一行代码就能构建功能强大的 Web 应用程序,充分展示其强大能力。
查看NLU 与 Streamlit 文档或NLU 与 Streamlit 示例部分。
整个 GIF 演示和
NLU 全部资源概览
请访问我们的官方 NLU 页面:https://nlu.johnsnowlabs.com/ 获取用户文档和示例。
| 资源 | 描述 |
|---|---|
| 安装 NLU | 只需运行 pip install nlu pyspark==3.0.2 |
| NLU 命名空间 | 查找所有可通过 nlu.load() 加载的模型名称 |
| nlu.load( |
用一行代码加载 1000 多种模型中的任意一种 |
| nlu.load( |
对 字符串、字符串列表、NumPy 数组、Pandas、Modin 和 Spark 数据框进行预测 |
| nlu.load(<train.Model>).fit(data) 函数 | 训练文本分类器,适用于 二分类、多分类、多标签分类、命名实体识别 或 词性标注 |
| nlu.load( |
可视化 词嵌入相似度矩阵、命名实体识别器、依存句法树与词性、实体消歧、实体链接 或 实体状态断言 的结果 |
| nlu.load( |
展示交互式 GUI,让你只需一键就能探索和测试 NLU 中的每种模型和功能。 |
| 通用概念 | NLU 中的通用概念 |
| 最新版本说明 | NLU 新增的最新增功能 |
| NLU 1 行代码示例概览 | 最常用的模型及其结果 |
| 医疗健康领域 NLU 1 行代码示例概览 | 医疗健康领域最常用的模型及其结果 |
| NLU 所有教程与示例概览 | 100 多个关于如何在各种问题上使用 NLU 处理文本数据集的教程,涵盖 Twitter、中文新闻、加密货币新闻标题、航空交通通信、产品评论分类器训练等不同来源的数据 |
| 加入 Slack 与我们交流 | 遇到问题、疑问或建议?我们拥有一个非常活跃且乐于助人的社区,超过 2000 名 AI 爱好者正积极利用 NLU、Spark NLP 和 Spark OCR |
| 讨论论坛 | 想与社区进行更深入的讨论?在我们的讨论论坛发帖 |
| John Snow Labs Medium | 关于 NLU、Spark NLP 和 Spark OCR 的文章与教程 |
| John Snow Labs Youtube | 关于 NLU、Spark NLP 和 Spark OCR 的视频与教程 |
| NLU 官网 | NLU 官方网站 |
| Github 问题 | 报告 Bug |
开始使用 NLU
要体验 NLU 的强大功能,只需通过 pip 安装它,并确保已正确安装和配置 Java 8。查看快速入门指南获取更多信息。
pip install nlu pyspark==3.0.2
用一行 Python 代码加载并预测任意模型
import nlu
nlu.load('sentiment').predict('我爱 NLU!<3')
用一行代码加载并预测多个模型
只需一行代码即可获得 6 种不同的词嵌入,并将其用于下游数据科学任务!
nlu.load('bert elmo albert xlnet glove use').predict('我爱 NLU!<3')
NLU 提供哪些类型的模型?
NLU 用一行代码就能满足数据科学家的所有需求!
- NLU 用一行代码就能满足数据科学家的所有需求!
- 1000 多个预训练模型
- 100 多种最新的自然语言处理词嵌入(BERT、ELMO、ALBERT、XLNET、GLOVE、BIOBERT、ELECTRA、COVIDBERT)及其不同变体
- 50 多种最新的自然语言处理句子嵌入(BERT、ELECTRA、USE)及其不同变体
- 100 多种分类器(命名实体识别、词性标注、情感分析、讽刺识别、问题检测、垃圾邮件检测)
- 支持 300 多种语言
- 使用 T5 总结文本并回答问题
- 标注与未标注的依存句法分析
- 各种文本清洗与预处理方法,如词干提取、词形还原、规范化、过滤、清洗流水线等
基于多种不同数据集训练的分类器
为合适的任务选择合适的工具!无论你是分析电影还是推特,NLU 都有适合你的模型!
- trec6 分类器
- trec10 分类器
- 垃圾邮件分类器
- 假新闻分类器
- 情感分类器
- 网络欺凌分类器
- 讽刺分类器
- 电影情感分类器
- IMDB 电影情感分类器
- 推特情感分类器
- 在 ONTO notes 上预训练的命名实体识别
- 在 CONLL 上训练的命名实体识别
- 在 wiki 20 lang 数据集上针对 20 种语言的语言分类器
数据科学 NLU 应用的实用工具
处理文本数据有时会是一项相当繁琐的工作。NLU 通过提供一系列组件,帮你摆脱数据工程中繁重的任务,让你的手保持干净。
- 日期时间匹配器
- 模式匹配器
- 片段匹配器
- 短语匹配器
- 停用词清理器
- 模式清理器
- 俚语清理器
我可以在哪里查看 NLU 中所有可用的模型?
要加载 NLU 模型,请参阅 NLU 命名空间 或 John Snow Labs Modelshub,或者直接访问 源文件。
支持的数据类型
- Pandas DataFrame 和 Series
- Spark DataFrames
- 使用 Ray 后端的 Modin
- 使用 Dask 后端的 Modin
- NumPy 数组
- 字符串和字符串列表
使用 NLU 库的所有教程概览
以下表格列出了所有使用 NLU 的可用教程。这些教程将帮助你了解 NLU 库的用法,以及如何将其应用于自己的任务。NLU 可以完成的一些任务包括:将任何语言翻译成英语、词形还原、分词、清除符号或不需要的语法、拼写检查、实体识别、情感分析等等!
{:.table2}
| Tutorial Description | NLU Spells Used | Open In Colab | Dataset and Paper References |
|---|---|---|---|
| Albert Word Embeddings with NLU | albert, sentiment pos albert emotion |
Albert-Paper, Albert on Github, Albert on TensorFlow, T-SNE, T-SNE-Albert, Albert_Embedding | |
| Bert Word Embeddings with NLU | bert, pos sentiment emotion bert |
Bert-Paper, Bert Github, T-SNE, T-SNE-Bert, Bert_Embedding | |
| BIOBERT Word Embeddings with NLU | biobert , sentiment pos biobert emotion |
BioBert-Paper, Bert Github , BERT: Deep Bidirectional Transformers, Bert Github, T-SNE, T-SNE-Biobert, Biobert_Embedding | |
| COVIDBERT Word Embeddings with NLU | covidbert, sentiment covidbert pos |
CovidBert-Paper, Bert Github, T-SNE, T-SNE-CovidBert, Covidbert_Embedding | |
| ELECTRA Word Embeddings with NLU | electra, sentiment pos en.embed.electra emotion |
Electra-Paper, T-SNE, T-SNE-Electra, Electra_Embedding | |
| ELMO Word Embeddings with NLU | elmo, sentiment pos elmo emotion |
ELMO-Paper, Elmo-TensorFlow, T-SNE, T-SNE-Elmo, Elmo-Embedding | |
| GLOVE Word Embeddings with NLU | glove, sentiment pos glove emotion |
Glove-Paper, T-SNE, T-SNE-Glove , Glove_Embedding | |
| XLNET Word Embeddings with NLU | xlnet, sentiment pos xlnet emotion |
XLNet-Paper, Bert Github, T-SNE, T-SNE-XLNet, Xlnet_Embedding | |
| Multiple Word-Embeddings and Part of Speech in 1 Line of code | bert electra elmo glove xlnet albert pos |
Bert-Paper, Albert-Paper, ELMO-Paper, Electra-Paper, XLNet-Paper, Glove-Paper | |
| Normalzing with NLU | norm |
- | |
| Detect sentences with NLU | sentence_detector.deep, sentence_detector.pragmatic, xx.sentence_detector |
Sentence Detector | |
| Spellchecking with NLU | n.a. | n.a. | - |
| Stemming with NLU | en.stem, de.stem |
- | |
| Stopwords removal with NLU | stopwords |
Stopwords | |
| Tokenization with NLU | tokenize |
- | |
| Normalization of Documents | norm_document |
- | |
| Open and Closed book question answering with Google's T5 | en.t5 , answer_question |
T5-Paper, T5-Model | |
| Overview of every task available with T5 | en.t5.base |
T5-Paper, T5-Model | |
| Translate between more than 200 Languages in 1 line of code with Marian Models | tr.translate_to.fr, en.translate_to.fr ,fr.translate_to.he , en.translate_to.de |
Marian-Papers, Translation-Pipeline (En to Fr), Translation-Pipeline (En to Ger) | |
| BERT Sentence Embeddings with NLU | embed_sentence.bert, pos sentiment embed_sentence.bert |
Bert-Paper, Bert Github, Bert-Sentence_Embedding | |
| ELECTRA Sentence Embeddings with NLU | embed_sentence.electra, pos sentiment embed_sentence.electra |
Electra Paper, Sentence-Electra-Embedding | |
| USE Sentence Embeddings with NLU | use, pos sentiment use emotion |
Universal Sentence Encoder, USE-TensorFlow, Sentence-USE-Embedding | |
| Sentence similarity with NLU using BERT embeddings | embed_sentence.bert, use en.embed_sentence.electra embed_sentence.bert |
Bert-Paper, Bert Github, Bert-Sentence_Embedding | |
| Part of Speech tagging with NLU | pos |
Part of Speech | |
| NER Aspect Airline ATIS | en.ner.aspect.airline |
NER Airline Model, Atis intent Dataset | |
| NLU-NER_CONLL_2003_5class_example | ner |
NER-Piple | |
| Named-entity recognition with Deep Learning ONTO NOTES | ner.onto |
NER_Onto | |
| Aspect based NER-Sentiment-Restaurants | en.ner.aspect_sentiment |
- | |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Chinese | zh.segment_words, zh.pos, zh.ner, zh.translate_to.en |
Translation-Pipeline (Zh to En) | |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Japanese | ja.segment_words, ja.pos, ja.ner, ja.translate_to.en |
Translation-Pipeline (Ja to En) | |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Korean | ko.segment_words, ko.pos, ko.ner.kmou.glove_840B_300d, ko.translate_to.en |
- | |
| Date Matching | match.datetime |
- | |
| Typed Dependency Parsing with NLU | dep |
Dependency Parsing | |
| Untyped Dependency Parsing with NLU | dep.untyped |
- | |
| E2E Classification with NLU | e2e |
e2e-Model | |
| Language Classification with NLU | lang |
- | |
| Cyberbullying Classification with NLU | classify.cyberbullying |
Cyberbullying-Classifier | |
| Sentiment Classification with NLU for Twitter | emotion |
Emotion detection | |
| Fake News Classification with NLU | en.classify.fakenews |
Fakenews-Classifier | |
| Intent Classification with NLU | en.classify.intent.airline |
Airline-Intention classifier, Atis-Dataset | |
| Question classification based on the TREC dataset | en.classify.questions |
Question-Classifier | |
| Sarcasm Classification with NLU | en.classify.sarcasm |
Sarcasm-Classifier | |
| Sentiment Classification with NLU for Twitter | en.sentiment.twitter |
Sentiment_Twitter-Classifier | |
| Sentiment Classification with NLU for Movies | en.sentiment.imdb |
Sentiment_imdb-Classifier | |
| Spam Classification with NLU | en.classify.spam |
Spam-Classifier | |
| Toxic text classification with NLU | en.classify.toxic |
Toxic-Classifier | |
| Unsupervised keyword extraction with NLU using the YAKE algorithm | yake |
- | |
| Grammatical Chunk Matching with NLU | match.chunks |
- | |
| Getting n-Grams with NLU | ngram |
- | |
| Assertion | en.med_ner.clinical en.assert, en.med_ner.clinical.biobert en.assert.biobert, ... |
Healthcare-NER, NER_Clinical-Classifier, Toxic-Classifier | |
| De-Identification Model overview | med_ner.jsl.wip.clinical en.de_identify, med_ner.jsl.wip.clinical en.de_identify.clinical, ... |
NER-Clinical | |
| Drug Normalization | norm_drugs |
- | |
| Entity Resolution | med_ner.jsl.wip.clinical en.resolve_chunk.cpt_clinical, med_ner.jsl.wip.clinical en.resolve.icd10cm, ... |
NER-Clinical, Entity-Resolver clinical | |
| Medical Named Entity Recognition | en.med_ner.ade.clinical, en.med_ner.ade.clinical_bert, en.med_ner.anatomy,en.med_ner.anatomy.biobert, ... |
- | |
| Relation Extraction | en.med_ner.jsl.wip.clinical.greedy en.relation, en.med_ner.jsl.wip.clinical.greedy en.relation.bodypart.problem, ... |
- | |
| Visualization of NLP-Models with Spark-NLP and NLU | ner, dep.typed, med_ner.jsl.wip.clinical resolve_chunk.rxnorm.in, med_ner.jsl.wip.clinical resolve.icd10cm |
NER-Piple, Dependency Parsing, NER-Clinical, Entity-Resolver (Chunks) clinical | |
| NLU Covid-19 Emotion Showcase | emotion |
Emotion detection | |
| NLU Covid-19 Sentiment Showcase | sentiment |
Sentiment classification | |
| NLU Airline Emotion Demo | emotion |
Emotion detection | |
| NLU Airline Sentiment Demo | sentiment |
Sentiment classification | |
| Bengali NER Hindi Embeddings for 30 Models | bn.ner, bn.lemma, ja.lemma, am.lemma, bh.lemma, en.ner.onto.bert.small_l2_128,.. |
Bengali-NER, Bengali-Lemmatizer, Japanese-Lemmatizer, Amharic-Lemmatizer | |
| Entity Resolution | med_ner.jsl.wip.clinical en.resolve.umls, med_ner.jsl.wip.clinical en.resolve.loinc, med_ner.jsl.wip.clinical en.resolve.loinc.biobert |
- | |
| NLU 20 Minutes Crashcourse - the fast Data Science route | spell, sentiment, pos, ner, yake, en.t5, emotion, answer_question, en.t5.base ... |
T5-Model, Part of Speech, NER-Piple, Emotion detection , Spellchecker, Sentiment classification | |
| Chapter 0: Intro: 1-liners | sentiment, pos, ner, bert, elmo, embed_sentence.bert |
Part of Speech, NER-Piple, Sentiment classification, Elmo-Embedding, Bert-Sentence_Embedding | |
| Chapter 1: NLU base-features with some classifiers on testdata | emotion, yake, stem |
Emotion detection | |
| Chapter 2: Translation between 300+ languages with Marian | tr.translate_to.en, en.translate_to.fr, en.translate_to.he |
Translation-Pipeline (En to Fr), Translation (En to He) | |
| Chapter 3: Answer questions and summarize Texts with T5 | answer_question, en.t5, en.t5.base |
T5-Model | |
| Chapter 4: Overview of T5-Tasks | en.t5.base |
T5-Model | |
| Graph NLU 20 Minutes Crashcourse - State of the Art Text Mining for Graphs | spell, sentiment, pos, ner, yake, emotion, med_ner.jsl.wip.clinical, ... |
Part of Speech, NER-Piple, Emotion detection, Spellchecker, Sentiment classification | |
| Healthcare with NLU | med_ner.human_phenotype.gene_biobert, med_ner.ade_biobert, med_ner.anatomy, med_ner.bacterial_species,... |
- | |
| Part 0: Intro: 1-liners | spell, sentiment, pos, ner, bert, elmo, embed_sentence.bert |
Bert-Paper, Bert Github, T-SNE, T-SNE-Bert , Part of Speech, NER-Piple, Spellchecker, Sentiment classification, Elmo-Embedding , Bert-Sentence_Embedding | |
| Part 1: NLU base-features with some classifiers on Testdata | yake, stem, ner, emotion |
NER-Piple, Emotion detection | |
| Part 2: Translate between 200+ Languages in 1 line of code with Marian-Models | en.translate_to.de, en.translate_to.fr, en.translate_to.he |
Translation-Pipeline (En to Fr), Translation-Pipeline (En to Ger), Translation (En to He) | |
| Part 3: More Multilingual NLP-translations for Asian Languages with Marian | en.translate_to.hi, en.translate_to.ru, en.translate_to.zh |
Translation (En to Hi), Translation (En to Ru), Translation (En to Zh) | |
| Part 4: Unsupervise Chinese Keyword Extraction, NER and Translation from chinese news | zh.translate_to.en, zh.segment_words, yake, zh.lemma, zh.ner |
Translation-Pipeline (Zh to En), Zh-Lemmatizer | |
| Part 5: Multilingual sentiment classifier training for 100+ languages | train.sentiment, xx.embed_sentence.labse train.sentiment |
n.a. | Sentence_Embedding.Labse |
| Part 6: Question-answering and Text-summarization with T5-Modell | answer_question, en.t5, en.t5.base |
T5-Paper | |
| Part 7: Overview of all tasks available with T5 | en.t5.base |
T5-Paper | |
| Part 8: Overview of some of the Multilingual modes with State Of the Art accuracy (1-liner) | bn.lemma, ja.lemma, am.lemma, bh.lemma, zh.segment_words, ... |
Bengali-Lemmatizer, Japanese-Lemmatizer , Amharic-Lemmatizer | |
| Overview of some Multilingual modes avaiable with State Of the Art accuracy (1-liner) | bn.ner.cc_300d, ja.ner, zh.ner, th.ner.lst20.glove_840B_300D, ar.ner |
Bengali-NER | |
| NLU 20 Minutes Crashcourse - the fast Data Science route | - | - |
需要帮助吗?
简单的 NLU 演示
NLU 功能概览
- 分词
- 可训练的分词
- 停用词去除
- 令牌规范化
- 文档规范化
- 词干提取器
- 词形还原器
- n-gram
- 正则表达式匹配
- 文本匹配
- 分块
- 日期匹配器
- 句子检测器
- 深度句子检测器(深度学习)
- 依存句法分析(带标签/不带标签)
- 词性标注
- 情感分析(机器学习模型)
- 拼写检查器(机器学习和深度学习模型)
- 词嵌入(GloVe 和 Word2Vec)
- BERT 嵌入(TF Hub 模型)
- ELMO 嵌入(TF Hub 模型)
- ALBERT 嵌入(TF Hub 模型)
- XLNet 嵌入
- 通用句子编码器(TF Hub 模型)
- BERT 句子嵌入(42 个 TF Hub 模型)
- 句子嵌入
- 分块嵌入
- 无监督关键词提取
- 语言检测与识别(支持多达 375 种语言)
- 多分类情感分析(深度学习)
- 多标签情感分析(深度学习)
- 多分类文本分类(深度学习)
- 神经机器翻译
- 文本到文本转换变压器(Google T5)
- 命名实体识别(深度学习)
- 易于 TensorFlow 集成
- GPU 支持
- 与 Spark ML 函数完全集成
- 超过 200 种语言的 1000 个预训练模型!
- 多语言 NER 模型:阿拉伯语、中文、丹麦语、荷兰语、英语、芬兰语、法语、德语、希伯来语、意大利语、日语、韩语、挪威语、波斯语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、乌尔都语等
- 自然语言推理
- 共指消解
- 句子补全
- 词义消歧
- 临床实体识别
- 临床实体链接
- 实体规范化
- 断言状态检测
- 去标识化
- 关系抽取
- 临床实体消解
引用
我们发表了一篇关于 NLU 库的论文,您可以引用:
@article{KOCAMAN2021100058,
title = {Spark NLP: 大规模自然语言理解},
journal = {Software Impacts},
pages = {100058},
year = {2021},
issn = {2665-9638},
doi = {https://doi.org/10.1016/j.simpa.2021.100058},
url = {https://www.sciencedirect.com/science/article/pii/S2665963821000063},
author = {Veysel Kocaman 和 David Talby},
keywords = {Spark, 自然语言处理, 深度学习, Tensorflow, 集群},
abstract = {Spark NLP 是一个基于 Apache Spark ML 构建的自然语言处理(NLP)库。它为机器学习流水线提供了简单、高效且准确的 NLP 注释,可在分布式环境中轻松扩展。Spark NLP 拥有超过 1100 个预训练流水线和模型,涵盖 192 种以上语言。它几乎支持所有 NLP 任务和模块,可无缝地应用于集群环境。自 2020 年 1 月以来,Spark NLP 下载量已超过 270 万次,增长了 9 倍,目前已有 54% 的医疗保健机构将其作为全球企业中最广泛使用的 NLP 库。}
}
}
版本历史
5412024/10/245402024/07/135.3.22024/05/215312024/04/305302024/04/305142024/02/085132024/01/225122024/01/205112024/01/085042023/11/095032023/10/09v5022023/10/085012023/09/11v5.0.02023/08/114222023/06/144212023/06/07v4.2.02023/03/20v4.0.02022/07/17v3.4.42022/05/20v3.4.32022/04/22常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。