EasyOCR
EasyOCR 是一款开箱即用的光学字符识别(OCR)工具,旨在帮助开发者轻松从图片中提取文字。它支持全球 80 多种语言及主流书写体系,涵盖拉丁文、中文、阿拉伯文、天城文和西里尔文等,能有效解决多语言混合场景下的文字识别难题。
无论是需要处理国际化文档的软件开发人员,还是从事数据标注的研究者,亦或是希望快速集成 OCR 功能的设计师,都能从中受益。只需几行 Python 代码,用户即可加载模型并识别本地图片、内存图像甚至网络链接中的文字内容。
其技术亮点在于极高的易用性与灵活性:首次加载模型后无需重复初始化,支持一次性传入多种兼容语言进行混合识别,并能返回包含坐标框、文本内容及置信度的详细结果,也可简化为纯文本列表输出。此外,项目自动管理模型权重下载,同时提供 Docker 部署方案与 Hugging Face 在线演示,即便在没有 GPU 的环境下也能运行。作为基于 Apache 2.0 协议开源的项目,EasyOCR 让高质量的文字识别技术变得触手可及。
使用场景
某跨境电商运营团队需要每日处理数百张包含中文、英文及阿拉伯文的多语言商品包装图,以提取关键信息录入库存系统。
没有 EasyOCR 时
- 多语言支持割裂:团队需分别部署针对不同语种的识别引擎,无法在单次调用中同时处理混合了拉丁字母、汉字和阿拉伯文的复杂图片。
- 开发门槛高且耗时:工程师需花费数周时间预处理训练数据、调整深度学习模型参数并编写复杂的图像矫正代码,难以快速上线。
- 环境配置繁琐:在不同操作系统(尤其是 Windows)上配置 CUDA 依赖和视觉库极易出错,导致新成员搭建开发环境往往耗费一整天。
- 维护成本高昂:自研或拼凑的脚本稳定性差,遇到倾斜文字或模糊背景时识别率骤降,需人工反复复核修正。
使用 EasyOCR 后
- 开箱即用的多语种能力:仅需一行代码
reader = easyocr.Reader(['ch_sim', 'en', 'ar']),即可精准提取同一张图片中 80 多种语言的混合文本。 - 极速集成与部署:通过
pip install easyocr几分钟内完成安装,直接传入图片路径或 OpenCV 对象即可获得带置信度的结构化结果,项目周期从数周缩短至数小时。 - 跨平台兼容性强:自动处理底层 PyTorch 依赖,无论是在 Linux 服务器还是本地 Windows 笔记本上,均能稳定运行,大幅降低环境调试痛苦。
- 输出灵活可控:支持一键切换“详细模式”(含坐标框与置信度)或“简洁模式”(仅文本),便于后续程序直接清洗入库,显著减少人工干预。
EasyOCR 将复杂的多语言光学字符识别任务简化为几行代码,让开发者能专注于业务逻辑而非底层算法调优。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- 支持 CPU 模式 (gpu=False)
- 若使用 GPU,需安装与系统匹配的 CUDA 版本的 PyTorch(具体版本需参考 pytorch.org),未明确指定显存大小要求,但提到低显存时可切换至 CPU 模式
未说明

快速开始
EasyOCR
![]()
![]()

![]()
开箱即用的 OCR 工具,支持 80 多种语言及所有主流书写系统,包括拉丁字母、中文、阿拉伯文、天城文、西里尔字母等。
集成到 Huggingface Spaces 🤗 中,使用 Gradio。体验在线演示:
最新动态
2024年9月24日 - 版本 1.7.2
- 修复了若干兼容性问题
下一步计划
- 手写文本支持
示例



安装
使用 pip 进行安装
对于最新稳定版:
pip install easyocr
对于最新开发版:
pip install git+https://github.com/JaidedAI/EasyOCR.git
注意 1:对于 Windows 用户,请先按照官方指南 https://pytorch.org 安装 PyTorch 和 torchvision。在 PyTorch 官网中,请确保选择与您显卡匹配的 CUDA 版本。如果您仅打算在 CPU 上运行,请选择 CUDA = None。
注意 2:我们还提供了一个 Dockerfile 在这里。
使用方法
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # 此步骤只需执行一次,用于将模型加载到内存中
result = reader.readtext('chinese.jpg')
输出将以列表形式呈现,每个元素分别包含检测到的文本框坐标、识别出的文本内容以及置信度。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
注意 1:['ch_sim','en'] 是您希望识别的语言列表。您可以同时指定多种语言,但并非所有语言都能组合使用。英语可以与任何语言搭配使用,而具有共同字符的语言通常也能相互兼容。
注意 2:除了文件路径 'chinese.jpg' 外,您还可以传入 OpenCV 图像对象(numpy 数组)或以字节形式表示的图像文件。直接指向原始图像的 URL 也是可行的。
注意 3:语句 reader = easyocr.Reader(['ch_sim','en']) 用于将模型加载到内存中。这需要一些时间,但只需执行一次即可。
您也可以通过设置 detail=0 来获得更简洁的输出。
reader.readtext('chinese.jpg', detail = 0)
结果:
['愚园路', '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']
所选语言的模型权重将会自动下载;您也可以从 模型中心 手动下载,并将其放置在 ~/.EasyOCR/model 文件夹中。
如果您的设备没有 GPU,或者 GPU 内存不足,可以通过添加 gpu=False 参数以纯 CPU 模式运行模型。
reader = easyocr.Reader(['ch_sim','en'], gpu=False)
命令行运行
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
训练/使用自定义模型
关于识别模型,请参阅 此处。
关于检测模型(CRAFT),请参阅 此处。
实施路线图
- 手写文本支持
- 重构代码以支持可替换的检测和识别算法 API 应该简单易用,例如:
reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
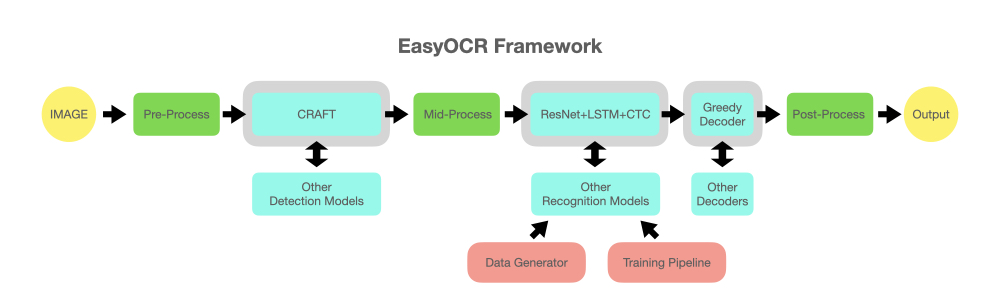
我们的目标是能够将任何最先进的模型无缝集成到 EasyOCR 中。许多天才正在努力开发更好的检测和识别模型,但我们并不追求成为这些领域的专家。我们只想让这些优秀成果快速、免费地惠及大众……(毕竟,大多数天才都希望自己的工作能尽快、尽可能广泛地产生积极影响)。整个流程应类似于下图所示,灰色部分为可更换的浅蓝色模块。
致谢与参考文献
本项目基于多篇论文及开源仓库中的研究和代码。
所有深度学习的执行均基于 Pytorch。:heart:
检测部分采用了来自此 官方仓库 的 CRAFT 算法及其 论文(感谢来自 @clovaai 的 @YoungminBaek)。我们还使用了他们提供的预训练模型。训练脚本由 @gmuffiness 提供。
识别模型为 CRNN(论文),由三个主要组件构成:特征提取(目前我们使用 Resnet 和 VGG)、序列标注(LSTM)以及解码(CTC)。识别部分的训练流程是对 deep-text-recognition-benchmark 框架的修改版本。(感谢来自 @clovaai 的 [@ku21fan])该仓库堪称瑰宝,值得更多关注。
Beam search 的代码基于此 仓库 及其 博客。(感谢 @githubharald)
数据合成基于 TextRecognitionDataGenerator。(感谢 @Belval)
此外,distill.pub 上有一篇关于 CTC 的优秀文章,可在此查阅:链接。
想要贡献吗?
让我们携手推动人工智能普惠化,共同造福人类!
有三种方式可以参与贡献:
开发者: 请针对小问题或改进提交 Pull Request。若涉及较大改动,请先通过新建 Issue 与我们讨论。我们已将一些可能的 Bug 或改进问题标记为 'PR WELCOME',欢迎随时提出。
用户: 请告诉我们 EasyOCR 如何帮助了您或您的组织,以激励我们持续开发。同时,也欢迎您在 Issue 栏 中分享遇到的失败案例,这将有助于我们优化未来的模型。
技术领袖/专家: 如果您认为本库很有价值,请帮忙宣传!(参见 Yann LeCun 关于 EasyOCR 的 帖子)
新语言请求指南
如需申请支持新语言,您需要提交一个包含以下两个文件的 PR:
在 easyocr/character 文件夹中,我们需要一个名为 'yourlanguagecode_char.txt' 的文件,其中列出该语言的所有字符。请参考该文件夹内其他文件的格式示例。
在 easyocr/dict 文件夹中,我们需要一个名为 'yourlanguagecode.txt' 的文件,其中包含该语言的所有词汇。通常每种语言约有 30,000 个词汇,较为流行的语言则超过 50,000 个。文件中词汇越多越好。
如果您的语言具有特殊性(例如:1. 阿拉伯语:字母连接时会改变形状,且从右向左书写;2. 泰语:部分字母需置于基线上方,部分则在下方),请尽可能详细地向我们说明,或提供相关参考资料。只有充分考虑这些细节,才能构建出真正可用的系统。
最后,请理解我们的优先级将倾向于那些使用广泛的语言,或是与其他语言共享大量字符的语言组合(请告知我们您的语言是否属于此类)。开发一个新的语言模型至少需要一周时间,因此您可能需要耐心等待新模型的发布。
更多正在开发的语言列表,请参阅 此处。
GitHub Issues
由于资源有限,超过 6 个月未更新的 Issue 将被自动关闭。若问题仍至关重要,请重新打开新的 Issue。
商务咨询
对于企业级支持,Jaided AI 提供 OCR/AI 系统的全方位定制服务,涵盖实施、训练/微调及部署等环节。请点击 这里 联系我们。
版本历史
v1.7.22024/09/24v1.7.12023/09/04v1.7.02023/05/25v1.6.22022/09/15v1.6.12022/09/01v1.6.02022/08/24v1.5.02022/06/02v1.4.22022/04/09v1.4.12021/09/11v1.42021/06/29v1.3.22021/05/30v1.3.12021/04/24v1.32021/03/21v1.2.52021/02/23v1.2.42021/02/071.2.32021/02/011.2.22021/01/05v1.22020/11/171.1.102020/10/14v1.1.82020/08/23常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。