Intern-S1
Intern-S1 是一款面向科学领域的多模态基础模型,旨在成为科研人员的智能助手。它不仅能处理通用的图文任务,更专注于解决化学、材料、生命科学及地球科学等复杂领域的推理难题,例如解读分子结构、分析蛋白质序列或规划合成路线,有效弥补了通用大模型在专业科学场景中能力不足的短板。
这款工具特别适合科研人员、AI4Science 领域的开发者以及需要处理海量科学数据的研究团队使用。无论是进行前沿科学探索,还是开发专业的科研辅助应用,Intern-S1 都能提供强有力的支持。此外,其轻量版 Intern-S1-mini 也降低了部署门槛,方便资源有限的用户尝试。
在技术层面,Intern-S1-Pro 展现了卓越的架构设计:作为万亿参数规模的混合专家(MoE)模型,它在每次推理时仅激活约 220 亿参数,兼顾了顶尖性能与训练效率。模型引入了独特的动态分词器,能够原生理解分子式和地震信号等非文本数据;结合傅里叶位置编码与升级的时间序列建模技术,它能精准处理从极短到百万级点位的异构物理信号。凭借在 5 万亿 token 数据(含超半数科学专有数据)上的持续预训练,Intern-S1 在多项科学推理基准测试中达到了媲美领先闭源商业模型的水平,是开源社区中不可多得的科学推理利器。
使用场景
某新材料研发团队的博士正在攻关一种新型固态电池电解质,急需从海量文献和实验图谱中筛选出高离子电导率的候选分子结构。
没有 Intern-S1 时
- 研究人员需人工查阅数百篇 PDF 论文,手动提取化学式和晶体结构数据,耗时数天且极易出错。
- 面对复杂的 X 射线衍射图谱和时间序列测试数据,通用大模型无法理解物理信号含义,只能提供泛泛的理论解释。
- 设计合成路线时,缺乏对专业化学反应规则的深度认知,模型常推荐不可行或危险的实验步骤。
- 多模态数据(文本、分子图、波形图)分散在不同文件中,难以进行跨模态关联分析,导致关键线索被遗漏。
使用 Intern-S1 后
- 直接上传包含图表和公式的原始论文,Intern-S1 利用其动态分词器原生解析分子公式与蛋白序列,秒级提取关键参数并生成结构化报告。
- 输入长达百万点的电化学阻抗谱数据,Intern-S1 凭借傅里叶位置编码精准识别物理特征,直接指出材料失效的微观机制。
- 基于万亿级科学语料训练的知识库,Intern-S1 能规划出符合化学逻辑的合成路径,并自动预警潜在的副反应风险。
- 同时处理文本描述、分子结构图和时序信号,Intern-S1 自动关联跨模态信息,快速锁定三个最具潜力的高性能候选材料。
Intern-S1 将原本需要数周的跨模态科学推理工作压缩至小时级,让科研人员从繁琐的数据清洗中解放,专注于核心创新突破。
运行环境要求
未说明(模型包含 FP8、BF16 及 GGUF 版本,暗示需要支持相应精度计算的 NVIDIA GPU 或 CPU 推理环境,具体显存需求取决于加载的模型版本:Intern-S1-Pro 激活参数 22B/总参 1T,Intern-S1 基于 235B MoE,Intern-S1-mini 基于 8B)
未说明

快速开始
Intern-S1

简介
我们推出了 Intern-S1-Pro,这是一款万亿参数规模的MoE多模态科学推理模型。Intern-S1-Pro 总参数量达到1T,拥有512个专家,每个token激活8个专家(激活参数为22B)。该模型在高级推理基准测试中表现出色,在AI4Science的关键领域(化学、材料、生命科学、地球科学等)均取得了领先成果,同时保持了强大的通用多模态和文本处理能力。
特点
最先进的科学推理能力,在AI4Science任务上与领先的闭源模型不相上下。
强大的通用多模态性能,在各类基准测试中表现优异。
万亿级MoE训练效率,采用 STE 路由机制(路由网络训练使用密集梯度)和 分组路由 技术,确保稳定收敛并实现专家间的负载均衡。
傅里叶位置编码(FoPE)+ 升级的时间序列建模,更好地表示物理信号;支持长且异构的时间序列数据(10^0–10^6个时间点)。
Intern-S1简介(点击展开)
我们推出了 Intern-S1,这是我们迄今为止 最先进的开源多模态推理模型。Intern-S1 将 强大的通用任务能力与在广泛科学任务上的顶尖性能 结合在一起,可与领先的闭源商业模型相媲美。
Intern-S1 基于一个235B的MoE语言模型(Qwen3)和一个6B的视觉编码器(InternViT),并在包含超过 2.5万亿个科学领域专用token 的多模态数据上进行了进一步预训练,总数据量达 5万亿token。这使得模型在保持强大通用能力的同时,能够在化学结构解析、蛋白质序列理解以及化合物合成路线规划等专业科学领域表现出色,从而成为现实世界科学研究中的得力助手。
我们还发布了 Intern-S1-mini,这是Intern-S1的轻量级版本,包含一个8B的语言模型和一个0.3B的视觉编码器。
特点
在语言和视觉推理基准测试中表现强劲,尤其在科学任务方面尤为突出。
持续在海量的5T token数据集上进行预训练,其中超过50%为科学领域专用数据,深度融入了各领域的专业知识。
动态分词器能够原生理解分子式、蛋白质序列和地震信号。
模型库
Intern-S1-Pro
| FP8 | |
|---|---|
| 🤗HuggingFace | internlm/Intern-S1-Pro |
 ModelScope ModelScope |
Shanghai_AI_Laboratory/Intern-S1-Pro |
Intern-S1
| BF16 | FP8 | GGUF | |
|---|---|---|---|
| 🤗HuggingFace | internlm/Intern-S1 | internlm/Intern-S1-FP8 | internlm/Intern-S1-GGUF |
| ModelScope |
Shanghai_AI_Laboratory/Intern-S1 | Shanghai_AI_Laboratory/Intern-S1-FP8 | Shanghai_AI_Laboratory/Intern-S1-GGUF |
Intern-S1-mini
| BF16 | FP8 | GGUF | |
|---|---|---|---|
| 🤗HuggingFace | internlm/Intern-S1-mini | internlm/Intern-S1-mini-FP8 | internlm/Intern-S1-mini-GGUF |
| ModelScope |
Shanghai_AI_Laboratory/Intern-S1-mini | Shanghai_AI_Laboratory/Intern-S1-mini-FP8 | - |
性能
我们在包括通用数据集和科学数据集在内的多个基准上对Intern-S1进行了评估。以下是与近期VLM和LLM的性能对比。
Intern-S1-Pro
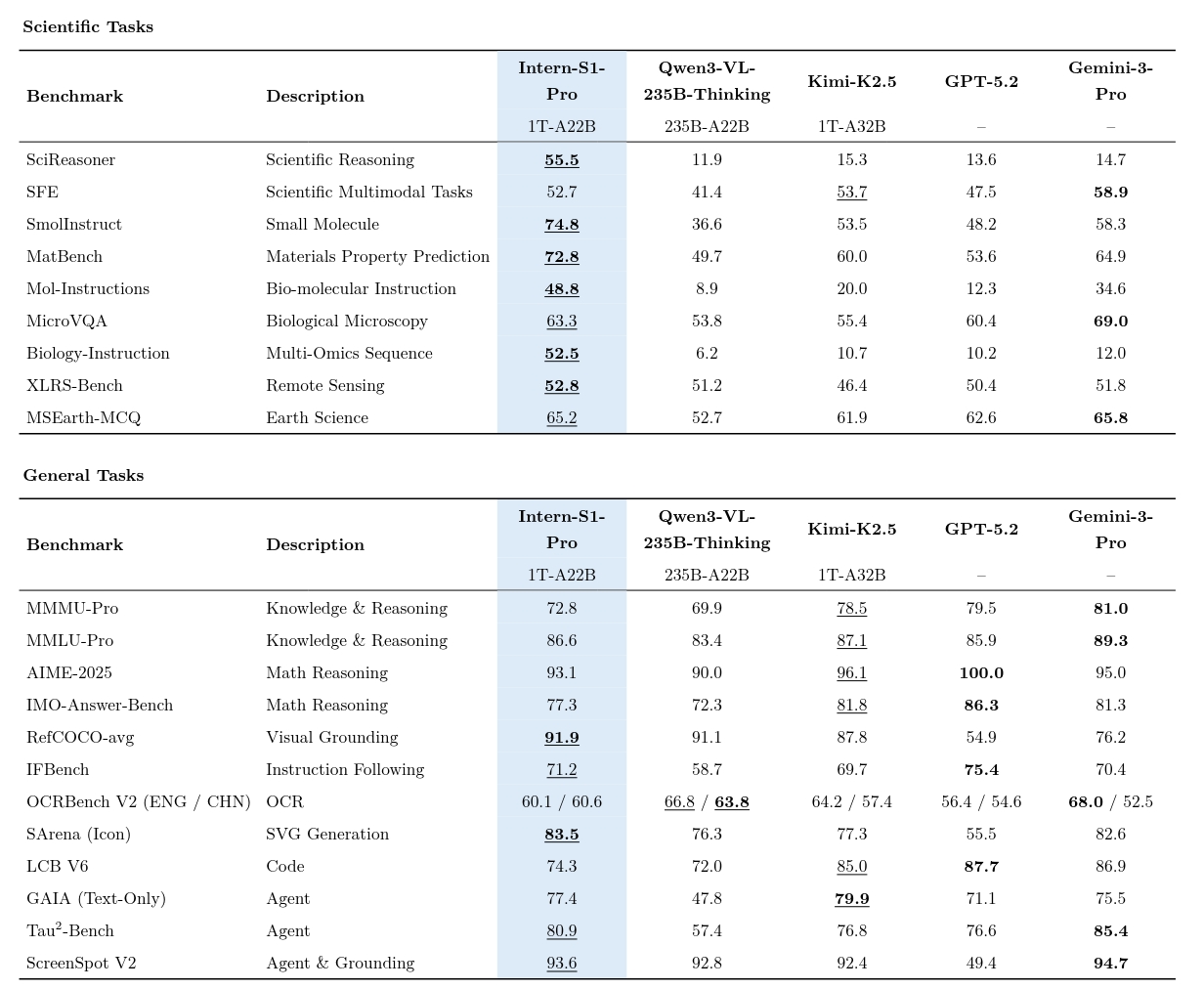
注:下划线表示开源模型中的最佳性能,加粗表示所有模型中的最佳性能。
Intern-S1
| 基准 | Intern-S1 | InternVL3-78B | Qwen2.5-VL-72B | DS-R1-0528 | Qwen3-235B-A22B | Kimi-K2-Instruct | Gemini-2.5 Pro | o3 | Grok-4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 83.5 ✅ | 73.0 | 72.1 | 83.4 | 82.2 | 82.7 | 86.0 | 85.0 | 85.9 | |
| MMMU | 77.7 ✅ | 72.2 | 70.2 | - | - | - | 81.9 | 80.8 | 77.9 | |
| GPQA | 77.3 | 49.9 | 49.0 | 80.6 | 71.1 | 77.8 | 83.8 | 83.3 | 87.5 | |
| MMStar | 74.9 ✅ | 72.5 | 70.8 | - | - | - | 79.3 | 75.1 | 69.6 | |
| MathVista | 81.5 👑 | 79.0 | 74.8 | - | - | - | 80.3 | 77.5 | 72.5 | |
| AIME2025 | 86.0 | 10.7 | 10.9 | 87.5 | 81.5 | 51.4 | 83.0 | 88.9 | 91.7 | |
| MathVision | 62.5 ✅ | 43.1 | 38.1 | - | - | - | 73.0 | 67.7 | 67.3 | |
| IFEval | 86.7 | 75.6 | 83.9 | 79.7 | 85.0 | 90.2 | 91.5 | 92.2 | 92.8 | |
| SFE | 44.3 👑 | 36.2 | 30.5 | - | - | - | 43.0 | 37.7 | 31.2 | |
| Physics | 44.0 ✅ | 23.1 | 15.7 | - | - | - | 40.0 | 47.9 | 42.8 | |
| SmolInstruct | 51.0 👑 | 19.4 | 21.0 | 30.7 | 28.7 | 48.1 | 40.4 | 43.9 | 47.3 | |
| ChemBench | 83.4 👑 | 61.3 | 61.6 | 75.6 | 75.8 | 75.3 | 82.8 | 81.6 | 83.3 | |
| MatBench | 75.0 👑 | 49.3 | 51.5 | 57.7 | 52.1 | 61.7 | 61.7 | 67.9 | ||
| MicroVQA | 63.9 👑 | 59.1 | 53.0 | - | - | - | 63.1 | 58.3 | 59.5 | |
| ProteinLMBench | 63.1 | 61.6 | 61.0 | 61.4 | 59.8 | 66.7 | 62.9 | 67.7 | 66.2 | |
| MSEarthMCQ | 65.7 👑 | 57.2 | 37.6 | - | - | - | 59.9 | 61.0 | 58.0 | |
| XLRS-Bench | 55.0 👑 | 49.3 | 50.9 | - | - | - | 45.2 | 43.6 | 45.4 | |
注:✅表示开源模型中的最佳性能,👑表示所有模型中的最佳性能。
Intern-S1-mini
| 基准测试 | Intern-S1-mini | Qwen3-8B | GLM-4.1V | MiMo-VL-7B-RL-2508 |
|---|---|---|---|---|
| MMLU-Pro | 74.78 | 73.7 | 57.1 | 73.93 |
| MMMU | 72.33 | - | 69.9 | 70.4 |
| MMStar | 65.2 | - | 71.5 | 72.9 |
| GPQA | 65.15 | 62 | 50.32 | 60.35 |
| AIME2024 | 84.58 | 76 | 36.2 | 72.6 |
| AIME2025 | 80 | 67.3 | 32 | 64.4 |
| MathVision | 51.41 | - | 53.9 | 54.5 |
| MathVista | 70.3 | - | 80.7 | 79.4 |
| IFEval | 81.15 | 85 | 71.53 | 71.4 |
| SFE | 35.84 | - | 43.2 | 43.9 |
| Physics | 28.76 | - | 28.3 | 28.2 |
| SmolInstruct | 32.2 | 17.6 | 18.1 | 16.11 |
| ChemBench | 76.47 | 61.1 | 56.2 | 66.78 |
| MatBench | 61.55 | 45.24 | 54.3 | 46.9 |
| MicroVQA | 56.62 | - | 50.2 | 50.96 |
| ProteinLMBench | 58.47 | 59.1 | 58.3 | 59.8 |
| MSEarthMCQ | 58.12 | - | 50.3 | 47.3 |
| XLRS-Bench | 51.63 | - | 49.8 | 12.29 |
我们使用 OpenCompass 和 VLMEvalKit 来评估所有模型。 请参考 此页面 以快速开始纯文本评估任务。
用户指南
InternS1 可以使用以下任一 LLM 推理框架进行部署:
- LMDeploy
- vLLM
- SGLang
这些框架的详细部署示例可在以下文档中找到:
微调
更多详情请参阅此 文档。
许可证
本项目采用 Apache 2.0 许可证发布。
引用
如果您觉得这项工作有用,请随时引用我们。
@misc{bai2025interns1scientificmultimodalfoundation,
title={Intern-S1:科学多模态基础模型},
author={Lei Bai and Zhongrui Cai and Maosong Cao and Weihan Cao and Chiyu Chen and Haojiong Chen and Kai Chen and Pengcheng Chen and Ying Chen and Yongkang Chen and Yu Cheng and Yu Cheng and Pei Chu and Tao Chu and Erfei Cui and Ganqu Cui and Long Cui and Ziyun Cui and Nianchen Deng and Ning Ding and Nanqin Dong and Peijie Dong and Shihan Dou and Sinan Du and Haodong Duan and Caihua Fan and Ben Gao and Changjiang Gao and Jianfei Gao and Songyang Gao and Yang Gao and Zhangwei Gao and Jiaye Ge and Qiming Ge and Lixin Gu and Yuzhe Gu and Aijia Guo and Qipeng Guo and Xu Guo and Conghui He and Junjun He and Yili Hong and Siyuan Hou and Caiyu Hu and Hanglei Hu and Jucheng Hu and Ming Hu and Zhouqi Hua and Haian Huang and Junhao Huang and Xu Huang and Zixian Huang and Zhe Jiang and Lingkai Kong and Linyang Li and Peiji Li and Pengze Li and Shuaibin Li and Tianbin Li and Wei Li and Yuqiang Li and Dahua Lin and Junyao Lin and Tianyi Lin and Zhishan Lin and Hongwei Liu and Jiangning Liu and Jiyao Liu and Junnan Liu and Kai Liu and Kaiwen Liu and Kuikun Liu and Shichun Liu and Shudong Liu and Wei Liu and Xinyao Liu and Yuhong Liu and Zhan Liu and Yinquan Lu and Haijun Lv and Hongxia Lv and Huijie Lv and Qidang Lv and Ying Lv and Chengqi Lyu and Chenglong Ma and Jianpeng Ma and Ren Ma and Runmin Ma and Runyuan Ma and Xinzhu Ma and Yichuan Ma and Zihan Ma and Sixuan Mi and Junzhi Ning and Wenchang Ning and Xinle Pang and Jiahui Peng and Runyu Peng and Yu Qiao and Jiantao Qiu and Xiaoye Qu and Yuan Qu and Yuchen Ren and Fukai Shang and Wenqi Shao and Junhao Shen and Shuaike Shen and Chunfeng Song and Demin Song and Diping Song and Chenlin Su and Weijie Su and Weigao Sun and Yu Sun and Qian Tan and Cheng Tang and Huanze Tang and Kexian Tang and Shixiang Tang and Jian Tong and Aoran Wang and Bin Wang and Dong Wang and Lintao Wang and Rui Wang and Weiyun Wang and Wenhai Wang and Yi Wang and Ziyi Wang and Ling-I Wu and Wen Wu and Yue Wu and Zijian Wu and Linchen Xiao and Shuhao Xing and Chao Xu and Huihui Xu and Jun Xu and Ruiliang Xu and Wanghan Xu and GanLin Yang and Yuming Yang and Haochen Ye and Jin Ye and Shenglong Ye and Jia Yu and Jiashuo Yu and Jing Yu and Fei Yuan and Bo Zhang and Chao Zhang and Chen Zhang and Hongjie Zhang and Jin Zhang and Qiaosheng Zhang and Qiuyinzhe Zhang and Songyang Zhang and Taolin Zhang and Wenlong Zhang and Wenwei Zhang and Yechen Zhang and Ziyang Zhang and Haiteng Zhao and Qian Zhao and Xiangyu Zhao and Bowen Zhou and Dongzhan Zhou and Peiheng Zhou and Yuhao Zhou and Yunhua Zhou and Dongsheng Zhu and Lin Zhu and Yicheng Zou},
year={2025},
eprint={2508.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.15763},
}
@misc{zou2026interns1proscientificmultimodalfoundation,
title={Intern-S1-Pro:万亿规模的科学多模态基础模型},
author={Yicheng Zou and Dongsheng Zhu and Lin Zhu and Tong Zhu and Yunhua Zhou and Peiheng Zhou and Xinyu Zhou and Dongzhan Zhou and Zhiwang Zhou and Yuhao Zhou and Bowen Zhou and Zhanping Zhong and Zhijie Zhong and Haiteng Zhao and Penghao Zhao and Xiaomeng Zhao and Zhiyuan Zhao and Yechen Zhang and Jin Zhang and Wenwei Zhang and Hongjie Zhang and Zhuo Zhang and Wenlong Zhang and Bo Zhang and Chao Zhang and Chen Zhang and Yuhang Zang and Fei Yuan and Jiakang Yuan and Jiashuo Yu and Jinhui Yin and Haochen Ye and Qian Yao and Bowen Yang and Danni Yang and Kaichen Yang and Ziang Yan and Jun Xu and Yicheng Xu and Wanghan Xu and Xuenan Xu and Chao Xu and Ruiliang Xu and Shuhao Xing and Long Xing and Xinchen Xie and Ling-I Wu and Zijian Wu and Zhenyu Wu and Lijun Wu and Yue Wu and Jianyu Wu and Wen Wu and Fan Wu and Xilin Wei and Qi Wei and Bingli Wang and Rui Wang and Ziyi Wang and Zun Wang and Yi Wang and Haomin Wang and Yizhou Wang and Lintao Wang and Yiheng Wang and Longjiang Wang and Bin Wang and Jian Tong and Zhongbo Tian and Huanze Tang and Chen Tang and Shixiang Tang and Yu Sun and Qiushi Sun and Xuerui Su and Qisheng Su and Chenlin Su and Demin Song and Jin Shi and Fukai Shang and Yuchen Ren and Pengli Ren and Xiaoye Qu and Yuan Qu and Jiantao Qiu and Yu Qiao and Runyu Peng and Tianshuo Peng and Jiahui Peng and Qizhi Pei and Zhuoshi Pan and Linke Ouyang and Wenchang Ning and Yichuan Ma and Zerun Ma and Ningsheng Ma and Runyuan Ma and Chengqi Lyu and Haijun Lv and Han Lv and Lindong Lu and Kuikun Liu and Jiangning Liu and Yuhong Liu and Kai Liu and Hongwei Liu and Zhoumianze Liu and Mengjie Liu and Ziyu Liu and Wenran Liu and Yang Liu and Liwei Liu and Kaiwen Liu and Junyao Lin and Junming Lin and Tianyang Lin and Dahua Lin and Jianze Liang and Linyang Li and Peiji Li and Zonglin Li and Zehao Li and Pengze Li and Guoyan Li and Lingkai Kong and Linglin Jing and Zhenjiang Jin and Feifei Jiang and Qian Jiang and Junhao Huang and Zixian Huang and Haian Huang and Zhouqi Hua and Han Hu and Linfeng Hou and Yinan He and Conghui He and Tianyao He and Xu Guo and Qipeng Guo and Aijia Guo and Yuzhe Gu and Lixin Gu and Jingyang Gong and Qiming Ge and Jiaye Ge and Songyang Gao and Jianfei Gao and Xinyu Fang and Caihua fan and Yue Fan and Yanhui Duan and Zichen Ding and Shengyuan Ding and Xuanlang Dai and Erfei Cui and Ganqu Cui and Pei Chu and Tao Chu and Guangran Cheng and Yu Cheng and Kai Chen and Yongkang Chen and Chiyu Chen and Guanzhou Chen and Qiaosheng Chen and Sitao Chen and Xin Chen and Haojiong Chen and Yicheng Chen and Weihan Cao and Yuhang Cao and Qinglong Cao and Lei Bai},
year={2026},
eprint={2603.25040},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2603.25040},
}
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。