Free-Auto-GPT
Free-Auto-GPT 是一款旨在降低人工智能使用门槛的开源自主智能体项目。它复刻了 AutoGPT 的核心功能,能够独立规划并执行复杂任务,但其最大特色在于完全摆脱了对付费 API(如 OpenAI、Pinecone 等)的依赖。
长期以来,尝试前沿 AI 技术往往意味着高昂的接口调用费用,这限制了个人开发者和小团队的探索空间。Free-Auto-GPT 通过巧妙利用 Hugging Face 免费资源,以及提取 ChatGPT、Google Bard、Microsoft Bing 等主流平台的网页 Cookie 作为认证凭证,成功实现了“零成本”运行。用户无需购买昂贵的算力或订阅服务,只需简单配置即可在本地或 Google Colab 上立即体验自主 AI 的魅力。
这款工具特别适合预算有限的学生、独立开发者、AI 爱好者以及希望低成本验证创意原型的研究人员。它不仅让普通人也能轻松上手最新的自主代理技术,更体现了推动 AI 技术民主化的理念,让创新不再被资金壁垒所阻挡。如果你渴望探索 AI 自动化潜力却不愿承担高额费用,Free-Auto-GPT 提供了一个友好且高效的入门选择。
使用场景
一位独立开发者希望构建一个能自动搜集竞品动态并生成周报的 AI 助手,但受限于预算无法承担高昂的 API 费用。
没有 Free-Auto-GPT 时
- 资金门槛高:必须预先充值 OpenAI、Pinecone 等付费 API 才能运行自主代理,试错成本极高,小团队难以负担。
- 环境配置复杂:需要自行搭建复杂的本地向量数据库和搜索服务,对硬件配置有特定要求,部署耗时耗力。
- 功能验证受阻:因担心产生意外的高额账单,不敢让 AI 代理进行大规模的多步任务测试,导致创意无法落地。
- 技术依赖单一:被绑定在特定的商业生态中,一旦 API 涨价或服务中断,整个自动化流程即刻瘫痪。
使用 Free-Auto-GPT 后
- 零成本启动:直接利用 HuggingFace Token 或提取 ChatGPT/Bing 的免费 Cookie 即可驱动代理,无需任何预付资金。
- 开箱即用:通过 Google Colab 云端笔记本一键运行,无需本地高性能显卡或繁琐的环境配置,几分钟内即可上线。
- 无顾虑实验:彻底消除计费焦虑,开发者可自由设定复杂的循环任务(如自动搜索、总结、写入文档),充分验证业务逻辑。
- 灵活多源支持:自由切换 ChatGPT、Google Bard 或 Bing Chat 等多种免费模型源,避免单点故障,提升系统鲁棒性。
Free-Auto-GPT 通过消除资金与硬件壁垒,让个人开发者也能零成本拥有强大的自主 AI 代理能力,真正推动了 AI 技术的普惠化。
运行环境要求
- Windows
- macOS
- Linux
不需要特定 GPU(README 明确指出 'does not need any particular hardware',主要通过调用外部 API 运行)
未说明

快速开始
使用AI智能体,如AUTO-GPT或BABYAGI,无需付费API😤 完全免费🤑
厌倦了为OPENAI、PINECONE、GOOGLESEARCH等API付费,才能体验AI领域的最新进展吗? 太棒了,这就是为你准备的仓库!🎁
如有任何问题,请提交ISSUE 🚬,项目非常简单,欢迎任何形式的帮助💸。
觉得阅读无聊😴?想马上试试我们的项目⏳?直接在Colab上打开笔记本吧,一切就绪!
立即在Colab运行😮 ![]() ⚠️ 滥用此工具需自行承担风险
⚠️ 滥用此工具需自行承担风险

顺带一提,非常感谢
为什么需要这个仓库?🤔
大家好 :smiling_face_with_three_hearts: ,
我想先谈谈让AI民主化的重要性。不幸的是,该领域的大多数新应用或发现最终都让一些大公司获利,而小型企业或个人项目却被抛在后面。一个典型的例子就是Autogpt,它是一种能够自主执行任务的AI智能体。
Autogpt以及类似BabyAGI的项目都依赖于付费API,这并不公平。因此,我尝试重新实现一个更简单但同样有趣且开源的Autogpt版本,不需要任何API,也不需要特定的硬件设备。
我相信,通过提供免费且开源的AI工具,我们可以让小型企业和个人有机会在无需大量资金投入的情况下,创造出新颖且富有创新性的项目。这将有助于实现更加公平和多元化的AI技术获取途径,而这是推动整个社会进步的关键。
如何完全免费获取Token和Cookies 🔑🔐
获取HuggingFace Token 🤗
- HUGGINGFACE TOKEN:请访问这份简单的官方指南
获取HuggingChat Cookie🍪
- 将你的邮箱和密码复制到.env文件中
获取ChatGPT Cookie🍪
- (可选但效果更好)ChatGPT🖥:
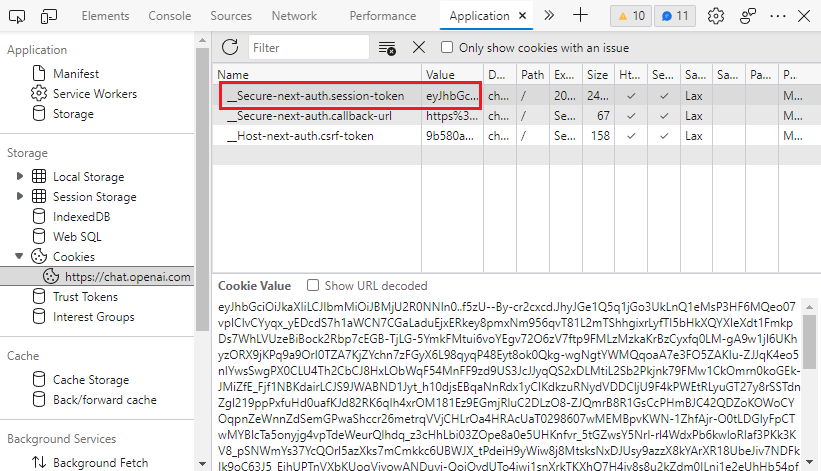
- 前往https://chat.openai.com/chat,按下`F12`打开开发者工具。
- 在“Application” > “Storage” > “Cookies” > “https://chat.openai.com”中找到`__Secure-next-auth.session-token`Cookie。
- 将“Cookie Value”栏中的值复制到.env文件中。
- 如果你有Plus订阅,可以使用GPT4。在.env文件中编辑这一行:
USE_GPT4 = True
获取Google Bard Cookie🍪
- (可选)Google Bard🖥:
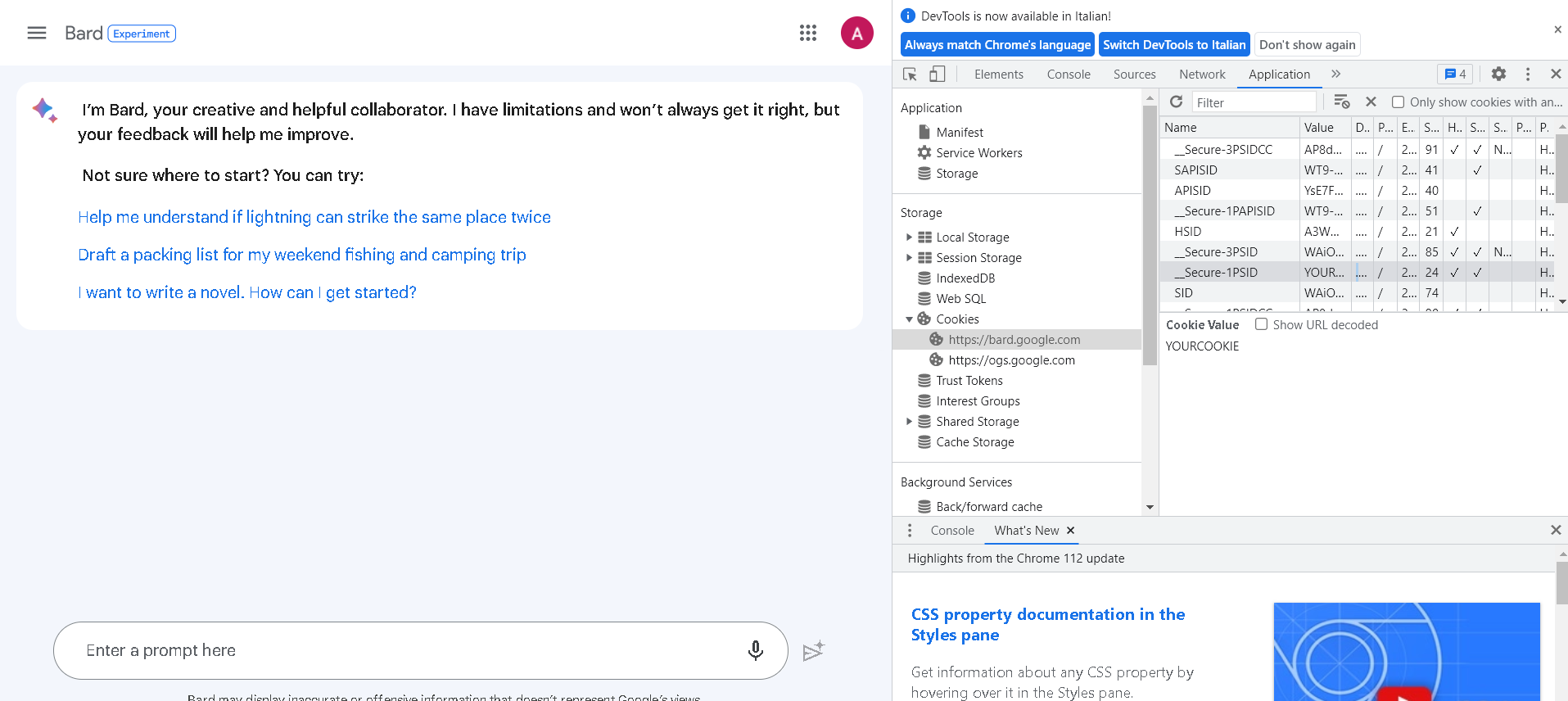
- 前往https://bard.google.com/,按下`F12`打开开发者工具。
- 在“Application” > “Storage” > “Cookies”中找到
__Secure-1PSIDCookie。 - 将“Cookie Value”栏中的值复制到.env文件中。
⚠️ 设置.env文件 ⚠️
打开名为`.env`的文件。
如果看不到该文件,请打开文件管理器并勾选**“显示隐藏文件”**。
现在将你的Cookie和Token添加到.env文件中。
使用VSCode中的Dev Container进行本地部署,由@FlamingFury00提供🚀
🚀新增了使用Docker镜像并通过VSCode的Dev Container运行的功能。操作方法如下:
- 安装Docker Desktop
- 安装Visual Studio Code
- 打开Visual Studio,进入Extensions -> 搜索Dev Container -> 安装
- 重启Visual Studio
- 进入项目文件夹,右键点击并选择**“在Visual Studio Code中打开”**
- 系统会提示你是否要在Docker容器中重新打开
- 点击**“Reopen”,等待完成即可(需确保Docker Desktop已启动)**
如何运行BABY AGI 👶
立即在Colab运行😮 ![]() ⚠️ 滥用此工具需自行承担风险
⚠️ 滥用此工具需自行承担风险
或者在本地运行:
- 下载仓库免费AUTOGPT仓库
- 使用VSCode中的Dev Container安装,或运行
python3 -m pip install -r requirements.txt - 插入包含你Token的**.env文件**
- 如果看不到**.env文件**,请检查文件管理器中的“显示隐藏文件”选项
- 运行命令:python BABYAGI.py
如何运行 AUTOGPT 🤖
立即在 Colab 上运行😮 ![]() ⚠️ 滥用此工具需自行承担风险
⚠️ 滥用此工具需自行承担风险
或在本地使用:
- 下载仓库 免费 AUTOGPT 仓库
- 使用 VSCode 中的 Dev Container 或
python3 -m pip install -r requirements.txt进行安装 - 插入包含您 Token 的 .env 文件
- 如果看不到 .env 文件,请在文件管理器中启用“显示隐藏文件”
- 使用方法:python AUTOGPT.py
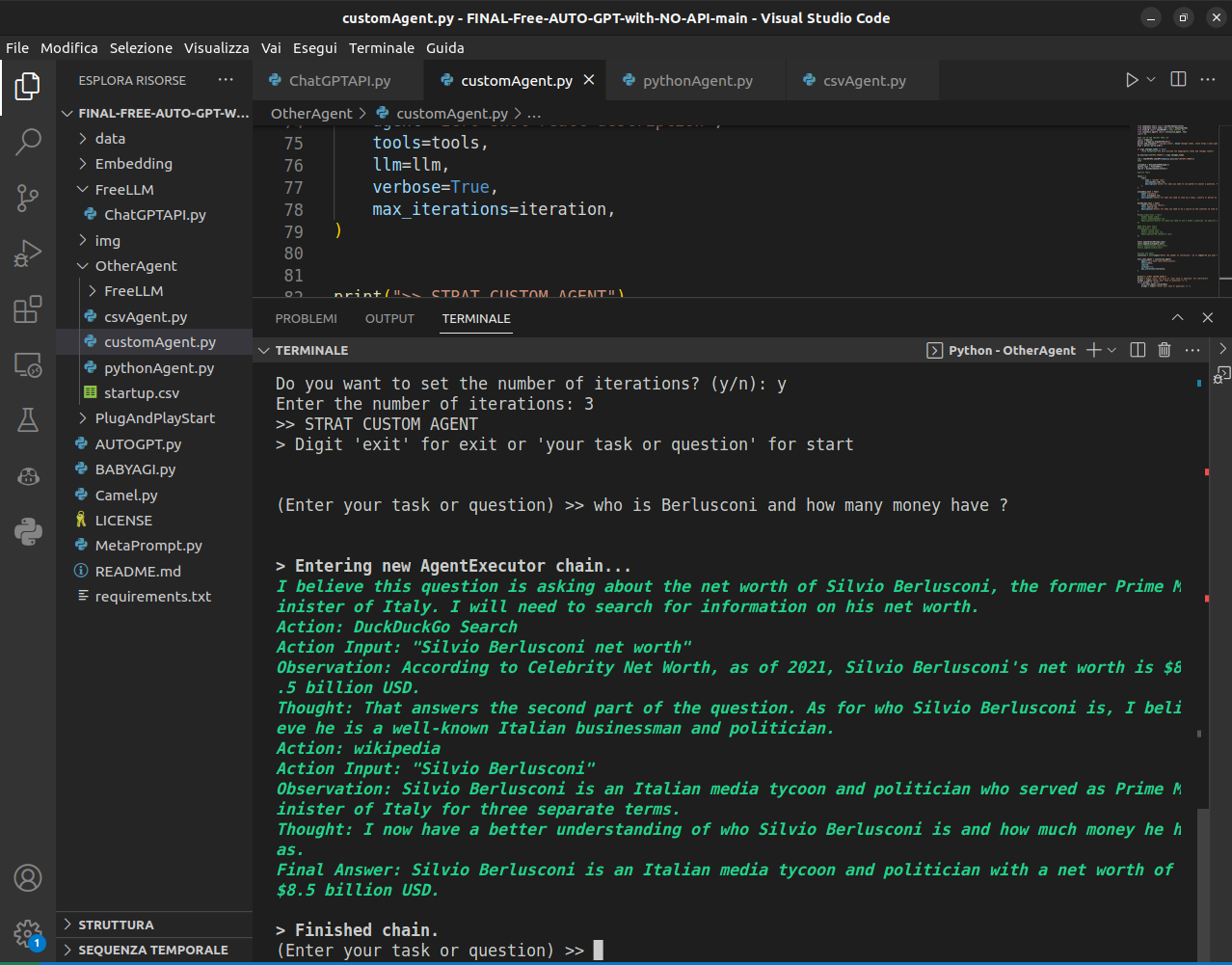
如何运行您的自定义智能体 🤖
立即在 Colab 上运行😮 ![]() ⚠️ 滥用此工具需自行承担风险
⚠️ 滥用此工具需自行承担风险
或在本地使用:
- 下载仓库 免费 AUTOGPT 仓库
- 使用 VSCode 中的 Dev Container 或
python3 -m pip install -r requirements.txt进行安装 - 切换到 OtherAgent/ 目录
- 选择或开发您的智能体 [ csvAgent.py ; pythonAgent.py ; customAgent.py ]
- 使用方法:python YourAgent.py
如何运行 CAMEL 🐫
立即在 Colab 上运行😮 ![]() ⚠️ 滥用此工具需自行承担风险
⚠️ 滥用此工具需自行承担风险
或在本地使用:
- 下载仓库 免费 AUTOGPT 仓库
python3 -m pip install -r requirements.txtstreamlit run Camel.py
它是如何工作的? 🔨🔩
为了创建一个无需付费 API 或特定硬件的开源版 Autogpt,我们对 OpenAI 开发的语言模型 ChatGPT 进行了逆向工程。通过这种方式,我们得以免费使用 LangChain 的智能体和新技术。
随后,我们利用 LangChain 创建了一个自定义的 LLM 封装器,它可以作为即插即用的解决方案,与任何 LangChain 函数或工具配合使用 💡。
from FreeLLM import ChatGPTAPI
# 使用您的 token 实例化一个 ChatGPT 对象
llm = ChatGPTAPI.ChatGPT((token="YOURTOKEN") #用于开始新对话
# 如果您有 Plus 订阅,可以使用 GPT-4 模型
llm = ChatGPTAPI.ChatGPT((token="YOURTOKEN", model="gpt4") # 需要 ChatGPT Plus 订阅
# 或者如果您想从现有对话开始
# llm = ChatGPTAPI.ChatGPT(token = "YOUR-TOKEN", conversation = "Add-XXXX-XXXX-Convesation-ID")
# 根据给定的提示生成回复
response = llm("你好,最近怎么样?")
# 打印回复
print(response)
以上代码片段展示了如何使用我们自定义的 ChatGPT LLM 类与语言模型进行交互。它需要来自 ChatGPT API 的 token,该 token 可以从 https://chat.openai.com/api/auth/session 获取。
请注意,ChatGPT API 对每个账户每小时的请求次数有限制,为 50 次 💣。因此,我们在 ChatGPT 类中实现了一个调用计数器,以防止超出此限制。
现已支持 HuggingChat LLM
from FreeLLM import HuggingChatAPI
# 使用您的 token 实例化一个 HuggingChat 对象
llm = HuggingChatAPI.HuggingChat() #用于开始新对话
# 根据给定的提示生成回复
response = llm("你好,最近怎么样?")
# 打印回复
print(response)
现已支持 Bing CHAT LLM
from FreeLLM import BingChatAPI
# 使用您的 cookie 路径实例化一个 Bing CHAT 对象
llm=BingChatAPI.BingChat(cookiepath="cookie_path") #用于开始新对话
# 如果您想设置对话风格
#llm=BingChatAPI.BingChat(cookiepath=cookie_path, conversation_style="creative") #conversation_style 必须是 precise、creative 或 balanced
# 如果您想启用 Microsoft Bing 的网络访问功能
#llm = =BingChatAPI.BingChat(cookiepath = "YOUR-COOKIE" , conversation_style = "precise" , search_result=True) #具有网络访问功能
# 根据给定的提示生成回复
response = llm("你好,最近怎么样?")
# 打印回复
print(response)
现已支持 Google BARD CHAT LLM
from FreeLLM import BardChatAPI
# 使用您的 cookie 路径实例化一个 Bard CHAT 对象
llm=BardChatAPI.BardChat(cookie="cookie") #用于开始新对话
# 根据给定的提示生成回复
response = llm("你好,最近怎么样?")
# 打印回复
print(response)
我们相信,我们的开源版 Autogpt 将促进公平且多元化的 AI 技术获取途径,并赋能个人和小型企业,在无需大量资金投入的情况下开展创新的 AI 项目。
这是一个自定义智能体的示例,仅用不到 60 行代码即可实现,完全免费,具备以下功能:
- 互联网访问
- Python 代码执行
- 维基百科知识
from langchain.agents import initialize_agent #用于创建新智能体
from langchain.agents import Tool
from langchain.tools import BaseTool, DuckDuckGoSearchRun
from langchain.utilities import PythonREPL #用于执行 Python 脚本
from langchain.utilities import WikipediaAPIWrapper #用于获取维基百科信息
from langchain.tools import DuckDuckGoSearchTool #用于获取实时网络信息 (langchain==0.0.150)
from FreeLLM import ChatGPTAPI # 免费 ChatGPT API
#或者
from FreeLLM import HuggingChatAPI
from FreeLLM import BingChatAPI
from FreeLLM import BardChatAPI
# 使用您的 token 实例化一个 ChatGPT 对象
llm = ChatGPTAPI.ChatGPT((token="YOURTOKEN")
# 或者使用 Bing CHAT
# llm = BingChatAPI.BingChat(cookiepath="cookie_path")
# 或者使用 Google BArd CHAT
# llm=BardChatAPI.BardChat(cookie="cookie")
# 或者使用 HuggingChatAPI,如果您没有 ChatGPT、BING 或 Google 账户
# llm = HuggingChatAPI.HuggingChat()
# 定义工具
wikipedia = WikipediaAPIWrapper()
python_repl = PythonREPL()
search = DuckDuckGoSearchTool()
tools = [
Tool(
name = "python repl",
func=python_repl.run,
description="在需要使用Python回答问题时很有用。你应该输入Python代码"
)
]
wikipedia_tool = Tool(
name='wikipedia',
func= wikipedia.run,
description="当你需要在维基百科上查找主题、国家或人物时很有用"
)
duckduckgo_tool = Tool(
name='DuckDuckGo搜索',
func= search.run,
description="当你需要在网络上搜索信息,而其他工具无法找到时很有用。请尽量具体地提供输入内容。"
)
tools.append(duckduckgo_tool)
tools.append(wikipedia_tool)
#创建代理
iteration = (int(input("请输入迭代次数:")) if input("您是否要设置迭代次数?(y/n): ") == "y" else 3)
zero_shot_agent = initialize_agent(
agent="zero-shot-react-description",
tools=tools,
llm=llm,
verbose=True,
max_iterations=iteration,
)
# 循环启动你的自定义代理
print(">> 启动自定义代理")
print("> 输入'exit'退出,或输入您的任务或问题开始\n\n")
prompt = input("(输入您的任务或问题) >> ")
while prompt.toLowerCase() != "exit":
zero_shot_agent.run(prompt)
prompt = input("(输入您的任务或问题) >> ")
# 就这么简单 :)
🤗 让AI民主化 🤗

顺便说一句,非常感谢大家的
待办事项,我需要你的帮助 👥👨💻
- 基于OpenAI反向工程的ChatGPT API 创建免费LLM Langchain封装
- 基于HuggingFace反向工程的HUGGING CHAT API 创建免费LLM Langchain封装
- 基于Microsoft反向工程的Bing CHAT API 创建免费LLM Langchain封装
- 基于Google反向工程的Bard CHAT API 创建免费LLM Langchain封装
- 找到一种方法,用HuggingFace Embeddings推理API替代OpenAIEmbeddings()
- 基于Camel理论 创建CAMEL的简化版本
- 基于Baby AGI 创建BABYAGI的简化版本
- 添加网页搜索工具
- 添加文件写入工具
- 添加维基百科工具
- 添加问答网页工具
- 最终实现无需付费API的AUTOGPT
- 制作一个Colab笔记本,使任何人都可以访问这个仓库
- 使用VSCode中的Dev Container进行本地部署,由@FlamingFury00完成
- 添加其他免费自定义LLM封装 添加这个
- 添加长期记忆功能
- 寻找替代PINECONE API的方法
- 寻找替代官方Google API的方法
我们渴望PR 😋
灵感与致谢 🤗
法律声明 🧑⚖️
本仓库与本GitHub仓库中所包含的API提供商无任何关联,亦未获得其认可。本项目仅用于教育目的。这仅仅是一个个人项目。 请注意以下几点:
免责声明:本仓库中提及的API、服务及商标均属于其各自的所有者。本项目并未声称对它们拥有任何权利,也未与任何提及的提供商建立关联或获得其认可。
责任:本仓库的作者对因使用或滥用本仓库或第三方API所提供的内容而产生的任何后果、损害或损失不承担任何责任。用户对其行为及其可能引发的任何后果负全部责任。我们强烈建议用户遵守各网站的服务条款。
仅限教育用途:本仓库及其内容仅供教育使用。通过使用其中的信息和代码,用户即表示同意自行承担使用这些API和模型的风险,并承诺遵守所有适用的法律和法规。
赔偿责任:用户同意就因使用或滥用本仓库、其内容或相关第三方API而产生或以任何方式与此相关的任何索赔、责任、损害、损失或费用(包括律师费和诉讼成本)对本仓库的作者进行赔偿、辩护并使其免受损害。
更新与变更:作者保留随时修改、更新或删除本仓库中任何内容、信息或功能的权利,恕不另行通知。用户有责任定期查看本仓库的内容及其变更。
通过使用本仓库或与其相关的任何代码,即表示您同意这些条款。作者对其他用户制作的任何复制、分叉或重新上传的内容不承担任何责任。这是作者唯一的账号和仓库。为防止冒充或不负责任的行为,您可以遵守本仓库所采用的MIT许可证。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。