MobiAgent
MobiAgent 是一个专为智能手机设计的智能 GUI 代理系统,旨在让手机能够像人类一样理解屏幕内容并自主执行复杂操作。它通过整合自定义的 MobiMind 模型家族、加速框架 AgentRR 以及评测基准 MobiFlow,构建了一套完整且可定制的移动智能体解决方案。
这一工具主要解决了传统自动化脚本灵活性差、难以应对动态界面及跨应用多步骤任务的问题。无论是需要在小红书查找攻略、去淘宝比价,再将结果通过微信发送给朋友这类复杂的跨应用流程,MobiAgent 都能通过视觉感知与逻辑推理自动完成。其独特的技术亮点包括支持纯端侧推理(无需联网即可在手机本地运行)、具备用户偏好记忆系统以提供个性化服务,以及高效的“记录与回放”加速机制,显著提升了任务执行效率。
MobiAgent 非常适合 AI 研究人员探索移动端智能体架构,也适合开发者用于构建下一代自动化应用或进行数据收集。随着纯端侧推理功能的完善,未来普通用户也能直接利用它在手机上实现高度智能化的个人助理体验,轻松处理繁琐的日常数字任务。
使用场景
一位电商运营人员需要每日跨平台收集竞品数据,整理成报表并通过微信发送给团队负责人。
没有 MobiAgent 时
- 操作繁琐重复:需人工在小红书搜索评测、复制相机型号,再切换至淘宝搜索比价,最后手动录入 Excel,耗时且易出错。
- 多任务中断频繁:在不同 APP 间反复跳转时,容易因消息通知或记忆偏差导致流程中断,难以一次性完成“搜索 - 比对 - 发送”的闭环。
- 缺乏个性化记忆:每次执行任务都需重新输入详细的筛选条件(如"2025 年性价比最高”),系统无法记住用户的偏好习惯。
- 夜间执行困难:若需在非工作时间自动完成任务,传统脚本难以适配动态变化的 GUI 界面,维护成本极高。
使用 MobiAgent 后
- 全自动跨端执行:MobiAgent 能自主理解“查找推荐并比价”的指令,自动在小红书提取关键信息,无缝跳转淘宝完成搜索与价格抓取。
- 复杂任务流闭环:依托多任务执行支持,MobiAgent 可一气呵成地完成从信息检索、数据清洗到通过微信发送报表的全流程,无需人工干预。
- 用户偏好自学习:内置的用户画像记忆系统让 MobiAgent 记住了你对“性价比”的定义和汇报格式,后续任务只需一句简单指令即可精准执行。
- 端侧智能运行:利用纯端侧推理能力,MobiAgent 可直接在手机后台静默运行,即使锁屏也能稳定处理任务,彻底释放人力。
MobiAgent 将原本耗时数小时的跨应用繁琐操作,转化为一次简单的自然语言指令,实现了真正的移动端智能自动化。
运行环境要求
- Linux
- 可选但推荐
- 若需 OCR GPU 加速,需安装 paddlepaddle-gpu(示例支持 CUDA 11.8)
- 运行 vLLM 部署模型通常也需要 NVIDIA GPU,具体显存取决于模型大小(如 4B/7B 模型)
未说明

快速开始

MobiAgent:可定制移动智能体的系统化框架
| MobiAgent论文 | MobiMem论文 | Huggingface | App |
English | 中文
关于
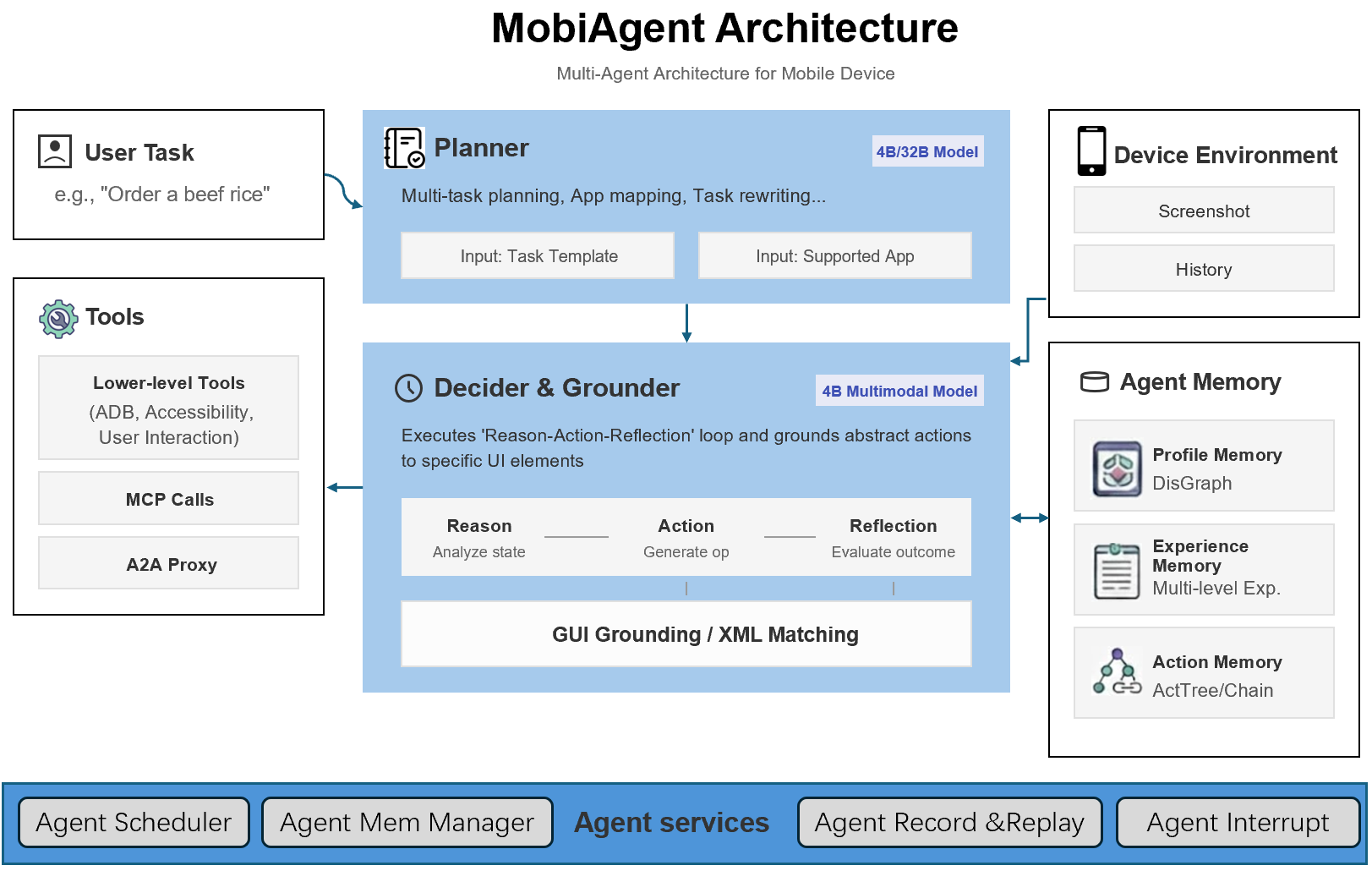
MobiAgent 是一个功能强大且可定制的移动智能体系统,包含:
- 智能体模型家族:MobiMind
- 智能体加速框架:AgentRR
- 智能体基准测试:MobiFlow
系统架构:
新闻
- [2026.3.14] 🔥 我们很高兴地宣布发布 MobiClaw,这是我们首个基于GUI的移动“爪子”工具,以及新的GUI模型:MobiMind-1.5-4B。
- [2025.12.26] 📱 现已支持在智能手机上进行纯设备端推理! 请参阅
phone_runner/README.md开始使用。 - [2025.12.25] 🛠️ 我们发布了 统一GUI智能体运行器,支持一键配置多种模型(
MobiAgent、UI-TARS、AutoGLM、Qwen-VL、Gemini等)。请参阅 Unify Runner README 开始使用。 - [2025.12.08] 我们发布了 MobiMind-Reasoning-4B 及其量化版本 MobiMind-Reasoning-4B-AWQ。
- [2025.11.03] 增加了多任务执行支持。详情请参阅 Multi-task README。
- [2025.11.03] 引入了用户画像记忆系统,可通过
--user_profile on启用。详情请参阅 User Profile README。
完整新闻
- [2025.10.31] 我们基于 Qwen3-VL-4B-Instruct 更新了 MobiMind-Mixed 模型!请前往 MobiMind-Mixed-4B-1031 下载。
- [2025.9.30] 增加了经验记忆模块。
- [2025.9.29] 我们开源了 MobiMind 的混合版本,能够同时完成决策和接地任务!请前往 MobiMind-Mixed-7B 下载。
- [2025.8.30] 我们开源了 MobiAgent!
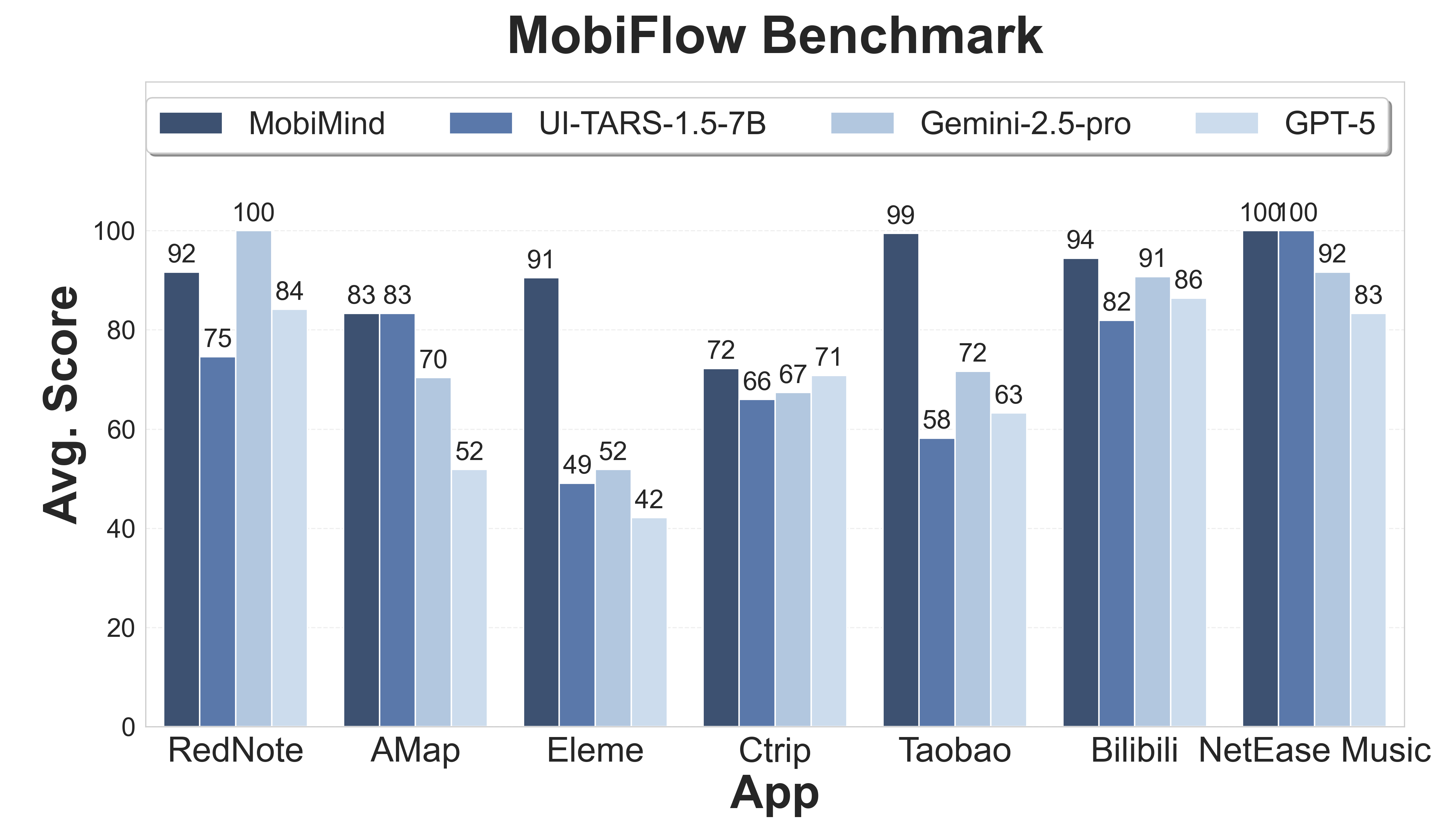
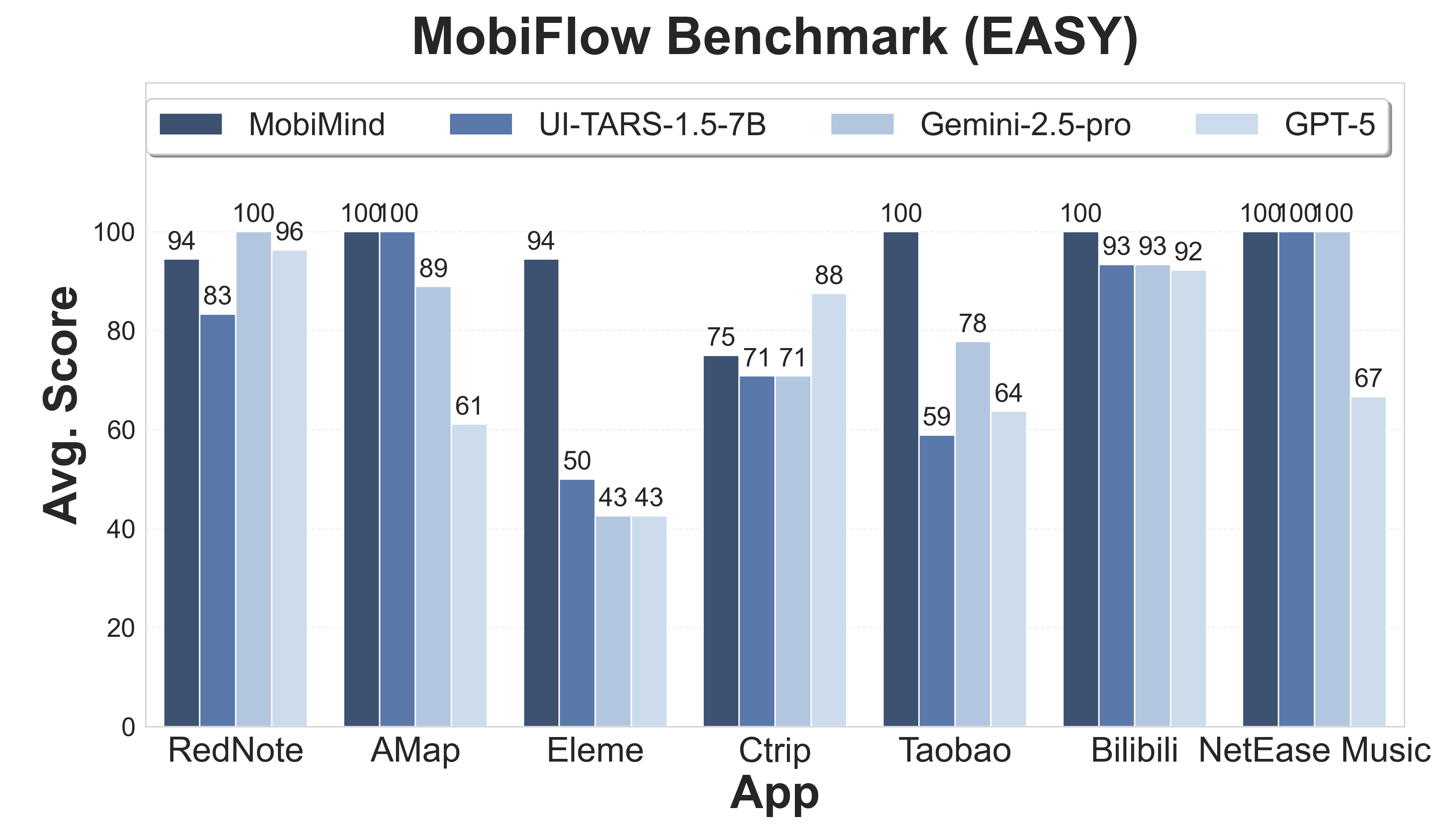
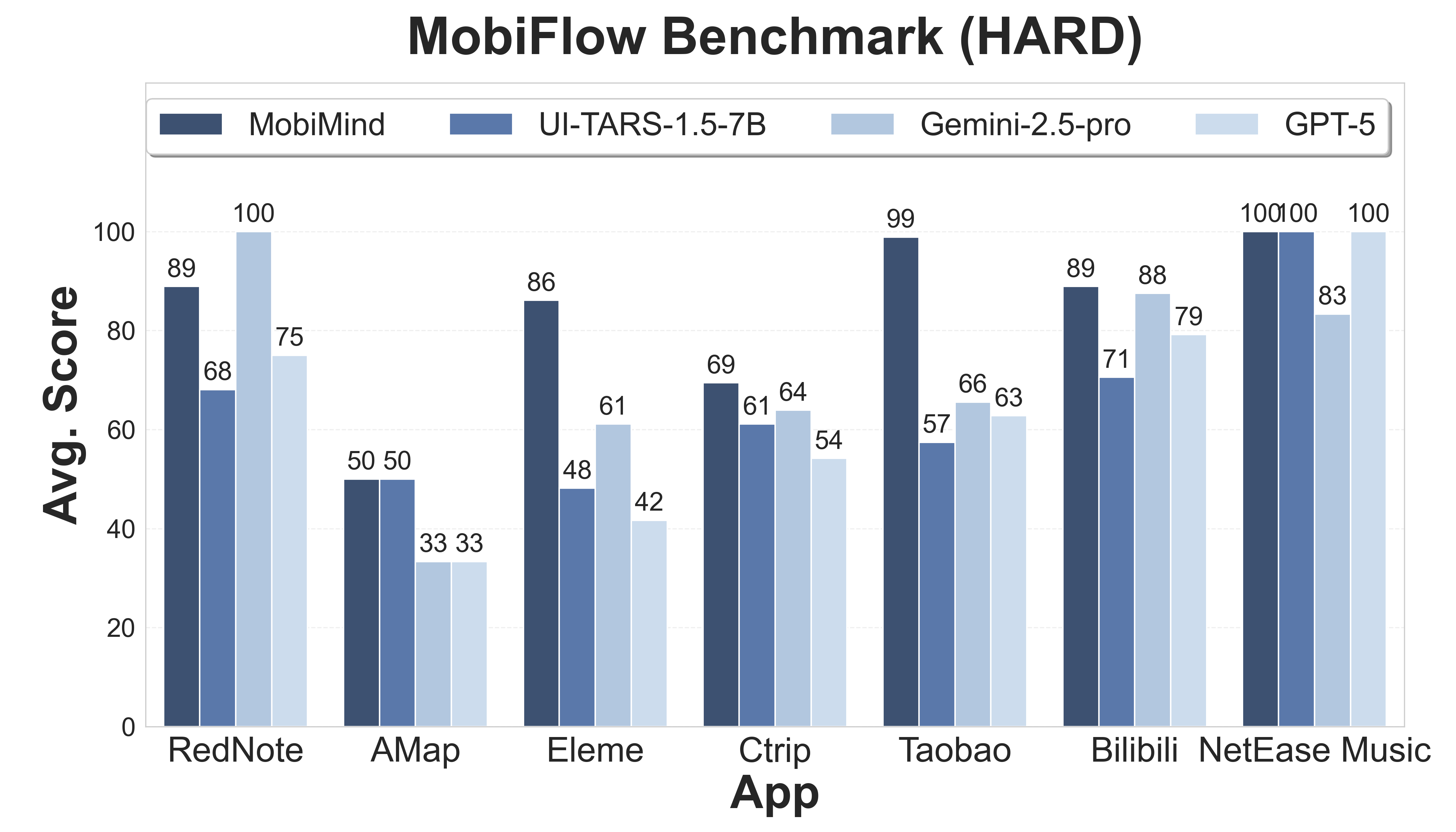
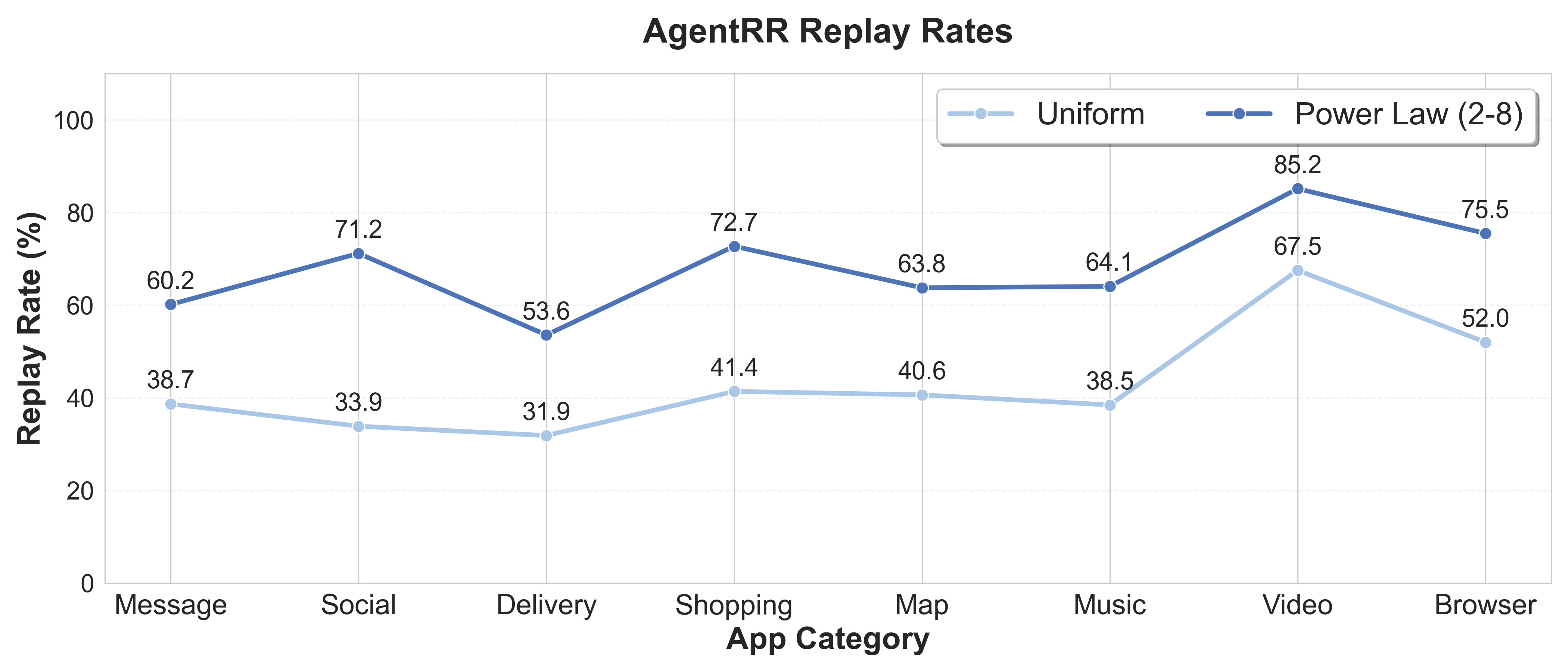
评估结果
演示
移动端演示:
AgentRR 演示(左:首次任务;右:后续任务)
多任务演示
任务:在小红书查找2025年性价比最高的单反相机推荐,然后在淘宝搜索该相机,并将淘宝中的相机品牌、名称和价格通过微信发送给小赵。
项目结构
agent_rr/- 智能体记录与回放框架collect/- 数据收集、标注、处理和导出工具runner/- 智能体执行器,通过 ADB 连接到手机,执行任务并记录执行轨迹MobiFlow/- 基于里程碑DAG的智能体评估基准app/- MobiAgent 安卓应用deployment/- MobiAgent 移动应用的服务部署
快速入门
使用 MobiAgent 应用
如果您想直接通过我们的APP体验MobiAgent,请在 下载链接 下载并尽情享受吧!
使用 Python 脚本
如果您希望通过利用 Android Debug Bridge (ADB) 控制手机的 Python 脚本来尝试 MobiAgent,请按照以下步骤操作:
1. 环境设置
创建虚拟环境,例如使用 conda:
conda create -n MobiMind python=3.10
conda activate MobiMind
最简单的环境设置(如果您只想单独运行智能体运行器):
# 安装最简依赖
pip install -r requirements_simple.txt
完整的环境设置(如果您想运行整个流程):
pip install -r requirements.txt
# 下载 OmniParser 模型权重
for f in icon_detect/{train_args.yaml,model.pt,model.yaml} ; do huggingface-cli download microsoft/OmniParser-v2.0 "$f" --local-dir weights; done
# 下载嵌入模型工具
huggingface-cli download BAAI/bge-small-zh --local-dir ./utils/experience/BAAI/bge-small-zh
# 安装 OCR 工具(可选)
sudo apt install tesseract-ocr tesseract-ocr-chi-sim
# 如果需要 GPU 加速 OCR,请根据您的 CUDA 版本安装 paddlepaddle-gpu
# 详情请参考 https://www.paddlepaddle.org.cn/install/quick,以 CUDA 11.8 为例:
python -m pip install paddlepaddle-gpu>=3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
2. 移动设备设置
- 在您的安卓设备上下载并安装 ADBKeyboard
- 在您的安卓设备上启用开发者选项并允许 USB 调试
- 使用 USB 数据线将您的手机连接到电脑
3. 模型部署
下载模型检查点后,使用 vLLM 部署模型推理服务:
下载链接:
- MobiMind-1.5-4B:
vllm serve MobiMind-Reasoning-4B --port <decider/grounder port>
vllm serve Qwen/Qwen3-4B-Instruct --port <planner port>
4. 智能体记忆设置(可选)
MobiAgent 支持三种记忆系统来提升智能体性能:
4.1 用户画像记忆
用户偏好记忆系统(Mem0)为规划提供个性化上下文。要启用它,请设置后端存储:
Milvus(向量数据库)——用于向量搜索:
# 下载安装脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# 启动 Docker 容器
bash standalone_embed.sh start
将以下内容添加到你的 .env 文件中:
MILVUS_URL=http://localhost:19530
EMBEDDING_MODEL=BAAI/bge-small-zh
EMBEDDING_MODEL_DIMS=384
OPENAI_API_KEY=your_key_here
OPENAI_BASE_URL=your_llm_endpoint_here
Neo4j(GraphRAG)——基于图的检索功能为可选:
docker run -d --name neo4j \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/testpassword \
neo4j:5.23.0
将以下内容添加到你的 .env 文件中:
NEO4J_URL=neo4j://localhost:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=testpassword
有关详细配置,请参阅 runner README。
4.2 经验记忆
经验记忆使规划器能够检索并使用类似的过往任务执行经验。在启动代理运行程序时,通过添加 --use_experience 标志来启用该功能。
4.3 行动记忆
行动记忆(AgentRR)会缓存并重用成功的动作序列,以加速任务执行。有关 ActTree 的复现和评估,请参阅 AgentRR README (ActTree)。对于正在作为实验性功能集成到 Agent Runner 中的 ActChain(基于经验的动作记忆),请参阅 #49。
5. 启动代理运行程序
将你想要测试的任务列表写入 runner/mobiagent/task.json,然后启动代理运行程序:
基本启动:
python -m runner.mobiagent.mobiagent \
--service_ip <服务IP> \
--decider_port <决策者服务端口> \
--planner_port <规划者服务端口>
# grounder_port 在 MobiMind-1.5-4B-0313 之后已被弃用
带用户画像记忆:
python -m runner.mobiagent.mobiagent \
--service_ip <服务IP> \
--decider_port <决策者服务端口> \
--planner_port <规划者服务端口> \
--user_profile on \
--use_graphrag off # 使用 'on' 表示启用 GraphRAG(Neo4j),使用 'off' 表示启用向量检索(Milvus)
# grounder_port 在 MobiMind-1.5-4B-0313 之后已被弃用
常用参数:
--service_ip:服务 IP 地址(默认值:localhost)--decider_port:决策者服务端口(默认值:8000)--grounder_port:分组者服务端口(默认值:8001)--planner_port:规划者服务端口(默认值:8002)--e2e:使用端到端模型并消除分组调用以加速执行(默认值:false)--device:设备类型,Android或Harmony(默认值:Android)--user_profile:启用用户画像记忆,on或off(默认值:off)--use_graphrag:是否使用 GraphRAG(Neo4j)进行检索,on或off(默认值:off)--use_experience:启用基于经验的任务重写功能(默认值:False)--data_dir:保存结果数据的目录(默认值:runner/mobiagent/data/)--task_file:任务列表文件的路径(默认值:runner/mobiagent/task.json)
运行程序会自动控制设备,并调用代理模型来完成预定义的任务。
重要提示:如果你部署了 MobiMind-Reasoning-4B 模型推理,则需将决策者和分组者的端口都设置为
<决策者/分组者端口>。
有关所有可用参数,请参阅 runner README。
多任务执行:
对于需要与多个应用交互的复杂任务,可以使用多任务执行器:
python -m runner.mobiagent.multi_task.mobiagent_refactored \
--service_ip <服务IP> \
--decider_port <决策者服务端口> \
--grounder_port <分组者服务端口> \
--planner_port <规划者服务端口> \
--task "你的多步骤任务描述"
有关详细配置、多截图支持、OCR 设置以及经验记忆集成等内容,请参阅 多任务 README。
子模块详细使用说明
有关详细的使用说明,请参阅各个子模块目录中的 README.md 文件。
引用
如果你在研究中发现 MobiAgent 非常有用,请随时引用我们的论文:
@misc{zhang2025mobiagentsystematicframeworkcustomizable,
title={MobiAgent:一种用于可定制移动代理的系统化框架},
author={Cheng Zhang 和 Erhu Feng、Xi Zhao、Yisheng Zhao、Wangbo Gong、Jiahui Sun、Dong Du、Zhichao Hua、Yubin Xia 和 Haibo Chen},
year={2025},
eprint={2509.00531},
archivePrefix={arXiv},
primaryClass={cs.MA},
url={https://arxiv.org/abs/2509.00531},
}
@misc{liu2025trainingenablingselfevolutionagents,
title={超越训练:利用 MOBIMEM 实现代理的自我进化},
author={Zibin Liu、Cheng Zhang、Xi Zhao、Yunfei Feng、Bingyu Bai、Dahu Feng、Erhu Feng、Yubin Xia 和 Haibo Chen},
year={2025},
eprint={2512.15784},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2512.15784},
}
致谢
我们衷心感谢 MobileAgent、UI-TARS、Qwen-VL 等开源项目。同时,我们也感谢国家高端智能家电创新研究院对本项目的大力支持。
星标历史

版本历史
v1.0.12025/12/22v1.02025/08/29常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。