RepDistiller
RepDistiller 是一个面向知识蒸馏研究的 PyTorch 开源工具包,由 ICLR 2020 论文《Contrastive Representation Distillation》的作者团队维护。它既实现了对比表征蒸馏(CRD)这一创新方法,也系统整合了 12 种主流知识蒸馏算法的基准测试,包括经典的 KD、FitNet、Attention Transfer 等。
知识蒸馏的核心挑战在于:如何让一个轻量级的"学生"模型高效学习大型"教师"模型的知识,从而在保持推理速度的同时提升准确率。RepDistiller 通过提供统一、可复现的实验框架,解决了研究者在对比不同蒸馏方法时面临的代码实现不一致、超参数设置混乱等问题。
这款工具特别适合深度学习研究人员和算法工程师使用。如果你正在探索模型压缩、边缘设备部署,或需要为特定任务寻找最优的蒸馏策略,RepDistiller 提供了开箱即用的对比基准。其技术亮点在于 CRD 方法引入了对比学习思想,通过拉近正样本对、推远负样本对来传递结构化的表征知识,突破了传统基于软标签或特征匹配的局限。
工具支持 CIFAR-100 等标准数据集,命令行接口设计清晰,可灵活组合多种蒸馏损失,方便研究者快速验证新想法或复现经典结果。
使用场景
某边缘 AI 创业公司正在开发一款智能安防摄像头,需要在低功耗芯片上实时运行人员检测与识别模型,但原始 ResNet-50 模型体积过大、推理延迟过高。
没有 RepDistiller 时
- 团队尝试手动剪枝和量化,但精度从 92% 暴跌至 78%,无法满足商用标准,反复调参耗费 3 周仍无突破
- 调研知识蒸馏方法时发现论文实现分散在各处,代码风格差异大,复现 CRD、RKD 等 5 种方法花了 2 周,还因环境冲突导致结果不可比
- 不确定哪种蒸馏策略最适合安防场景的小模型,只能逐个试错,每次完整训练需 2 天,决策成本极高
- 最终选定的 KD 基线方案精度仅恢复至 85%,与目标差距明显,产品上线被迫推迟
使用 RepDistiller 后
- 直接调用 CRD(对比表征蒸馏),利用对比学习机制捕捉教师网络的深层语义关系,学生模型 ResNet-8 精度达到 90.3%,满足商用阈值
- 12 种 SOTA 方法统一在 PyTorch 框架下实现,一行命令切换蒸馏策略,3 天内完成全量基准测试
- 开箱即用的脚本和预训练教师模型支持快速验证,团队清晰对比出 CRD+KD 组合在安防数据集上最优,训练周期压缩至 1.5 天
- 模型体积缩减 87%,推理速度提升 4 倍,顺利部署到海思 Hi3519 芯片,产品按期交付
RepDistiller 将知识蒸馏从"论文复现工程"转变为"标准化模型压缩方案",让边缘 AI 团队在有限算力约束下快速获得高精度轻量模型。
运行环境要求
- Linux
需要 NVIDIA GPU,CUDA 9.0+(测试环境为 CUDA 9.0),支持 PyTorch >=0.4.0
未说明

快速开始
RepDistiller
本仓库:
(1) 包含以下 ICLR 2020 论文的实现:
"Contrastive Representation Distillation"(对比表示蒸馏,CRD)。论文,项目主页。
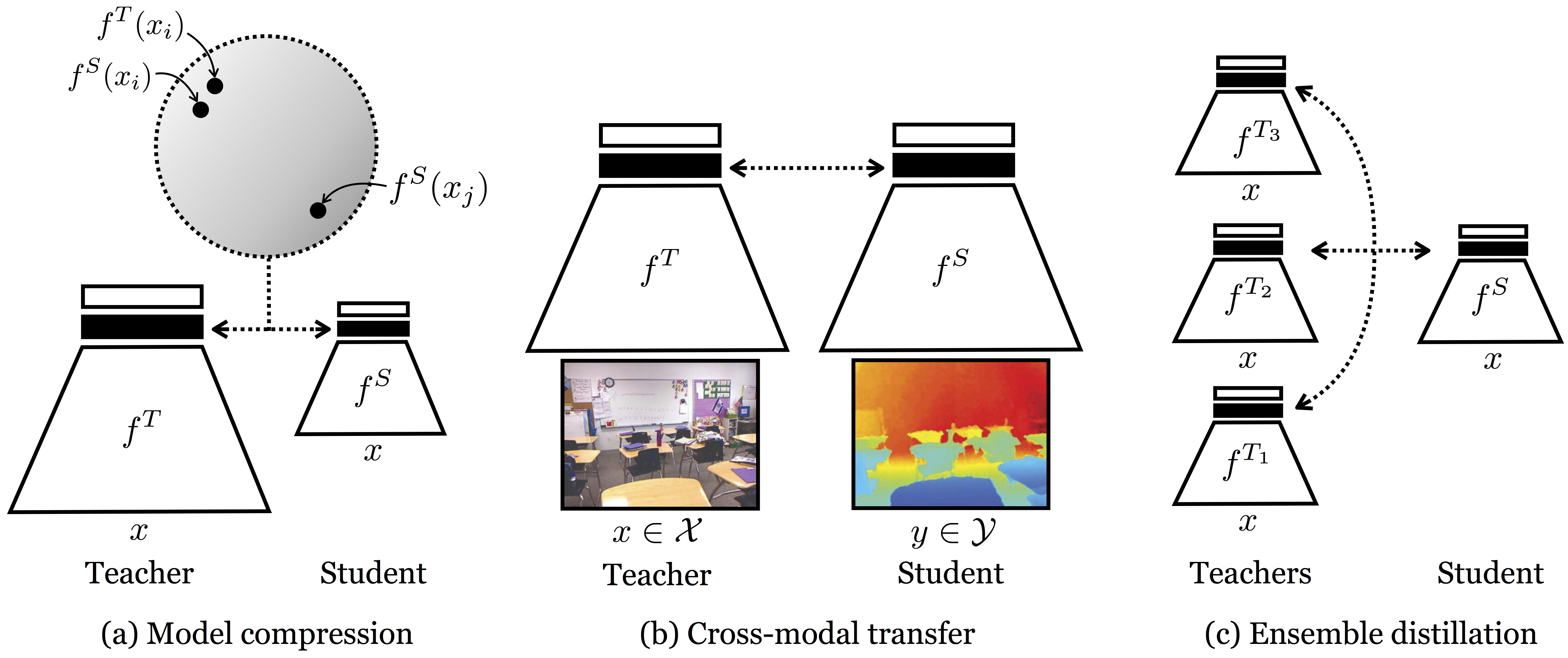
(2) 在 PyTorch 中基准测试了 12 种最先进的知识蒸馏(Knowledge Distillation,KD)方法,包括:
(KD) - Distilling the Knowledge in a Neural Network
(FitNet) - Fitnets: hints for thin deep nets
(AT) - Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks
via Attention Transfer
(SP) - Similarity-Preserving Knowledge Distillation
(CC) - Correlation Congruence for Knowledge Distillation
(VID) - Variational Information Distillation for Knowledge Transfer
(RKD) - Relational Knowledge Distillation
(PKT) - Probabilistic Knowledge Transfer for deep representation learning
(AB) - Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
(FT) - Paraphrasing Complex Network: Network Compression via Factor Transfer
(FSP) - A Gift from Knowledge Distillation:
Fast Optimization, Network Minimization and Transfer Learning
(NST) - Like what you like: knowledge distill via neuron selectivity transfer
安装
本仓库在 Ubuntu 16.04.5 LTS、Python 3.5、PyTorch 0.4.0 和 CUDA 9.0 环境下测试通过。但应该可以在 PyTorch >=0.4.0 的较新版本上运行。
运行
通过以下命令获取预训练的教师模型:
sh scripts/fetch_pretrained_teachers.sh该命令将下载模型并保存到
save/models目录按照
scripts/run_cifar_distill.sh中的命令运行蒸馏。运行 Geoffrey 原始知识蒸馏(KD)的示例如下:python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill kd --model_s resnet8x4 -r 0.1 -a 0.9 -b 0 --trial 1各参数说明如下:
--path_t:指定教师模型的路径--model_s:指定学生模型,查看models/__init__.py了解可用的模型类型--distill:指定蒸馏方法-r:logit 与真实标签之间交叉熵损失的权重,默认值:1-a:KD 损失的权重,默认值:None-b:其他蒸馏损失的权重,默认值:None--trial:指定实验 ID,用于区分多次运行
因此,运行 CRD 的命令如下:
python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill crd --model_s resnet8x4 -a 0 -b 0.8 --trial 1将蒸馏目标与 KD 结合使用,只需将
-a设为非零值,示例如下(CRD 与 KD 结合):python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill crd --model_s resnet8x4 -a 1 -b 0.8 --trial 1(可选)从头开始训练教师网络。示例命令见
scripts/run_cifar_vanilla.sh
注意:默认设置为单 GPU 训练。如需使用多 GPU 运行本仓库,可能需要调整学习率,根据经验,学习率需要随批量大小(batch size)线性放大,详见此论文。
CIFAR-100 基准测试结果:
性能以分类准确率(%)衡量
- 教师和学生模型为相同架构类型。
| 教师 学生 |
wrn-40-2 wrn-16-2 |
wrn-40-2 wrn-40-1 |
resnet56 resnet20 |
resnet110 resnet20 |
resnet110 resnet32 |
resnet32x4 resnet8x4 |
vgg13 vgg8 |
|---|---|---|---|---|---|---|---|
| 教师 学生 |
75.61 73.26 |
75.61 71.98 |
72.34 69.06 |
74.31 69.06 |
74.31 71.14 |
79.42 72.50 |
74.64 70.36 |
| KD | 74.92 | 73.54 | 70.66 | 70.67 | 73.08 | 73.33 | 72.98 |
| FitNet | 73.58 | 72.24 | 69.21 | 68.99 | 71.06 | 73.50 | 71.02 |
| AT | 74.08 | 72.77 | 70.55 | 70.22 | 72.31 | 73.44 | 71.43 |
| SP | 73.83 | 72.43 | 69.67 | 70.04 | 72.69 | 72.94 | 72.68 |
| CC | 73.56 | 72.21 | 69.63 | 69.48 | 71.48 | 72.97 | 70.71 |
| VID | 74.11 | 73.30 | 70.38 | 70.16 | 72.61 | 73.09 | 71.23 |
| RKD | 73.35 | 72.22 | 69.61 | 69.25 | 71.82 | 71.90 | 71.48 |
| PKT | 74.54 | 73.45 | 70.34 | 70.25 | 72.61 | 73.64 | 72.88 |
| AB | 72.50 | 72.38 | 69.47 | 69.53 | 70.98 | 73.17 | 70.94 |
| FT | 73.25 | 71.59 | 69.84 | 70.22 | 72.37 | 72.86 | 70.58 |
| FSP | 72.91 | N/A | 69.95 | 70.11 | 71.89 | 72.62 | 70.23 |
| NST | 73.68 | 72.24 | 69.60 | 69.53 | 71.96 | 73.30 | 71.53 |
| CRD | 75.48 | 74.14 | 71.16 | 71.46 | 73.48 | 75.51 | 73.94 |
- 教师和学生模型为不同架构类型。
| 教师 学生 |
vgg13 MobileNetV2 |
ResNet50 MobileNetV2 |
ResNet50 vgg8 |
resnet32x4 ShuffleNetV1 |
resnet32x4 ShuffleNetV2 |
wrn-40-2 ShuffleNetV1 |
|---|---|---|---|---|---|---|
| 教师 学生 |
74.64 64.60 |
79.34 64.60 |
79.34 70.36 |
79.42 70.50 |
79.42 71.82 |
75.61 70.50 |
| KD | 67.37 | 67.35 | 73.81 | 74.07 | 74.45 | 74.83 |
| FitNet | 64.14 | 63.16 | 70.69 | 73.59 | 73.54 | 73.73 |
| AT | 59.40 | 58.58 | 71.84 | 71.73 | 72.73 | 73.32 |
| SP | 66.30 | 68.08 | 73.34 | 73.48 | 74.56 | 74.52 |
| CC | 64.86 | 65.43 | 70.25 | 71.14 | 71.29 | 71.38 |
| VID | 65.56 | 67.57 | 70.30 | 73.38 | 73.40 | 73.61 |
| RKD | 64.52 | 64.43 | 71.50 | 72.28 | 73.21 | 72.21 |
| PKT | 67.13 | 66.52 | 73.01 | 74.10 | 74.69 | 73.89 |
| AB | 66.06 | 67.20 | 70.65 | 73.55 | 74.31 | 73.34 |
| FT | 61.78 | 60.99 | 70.29 | 71.75 | 72.50 | 72.03 |
| NST | 58.16 | 64.96 | 71.28 | 74.12 | 74.68 | 74.89 |
| CRD | 69.73 | 69.11 | 74.30 | 75.11 | 75.65 | 76.05 |
引用
如果本仓库对您的研究有所帮助,请考虑引用该论文:
@inproceedings{tian2019crd,
title={Contrastive Representation Distillation},
author={Yonglong Tian and Dilip Krishnan and Phillip Isola},
booktitle={International Conference on Learning Representations},
year={2020}
}
如有任何问题,请联系 Yonglong Tian(yonglong@mit.edu)。
致谢
感谢 Baoyun Peng 提供 CC(Correlation Congruence,相关性一致性)的代码,以及 Frederick Tung 帮助我们验证 SP(Similarity Preserving,相似性保持)的重新实现。同时感谢其他论文的作者公开他们的代码。
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。