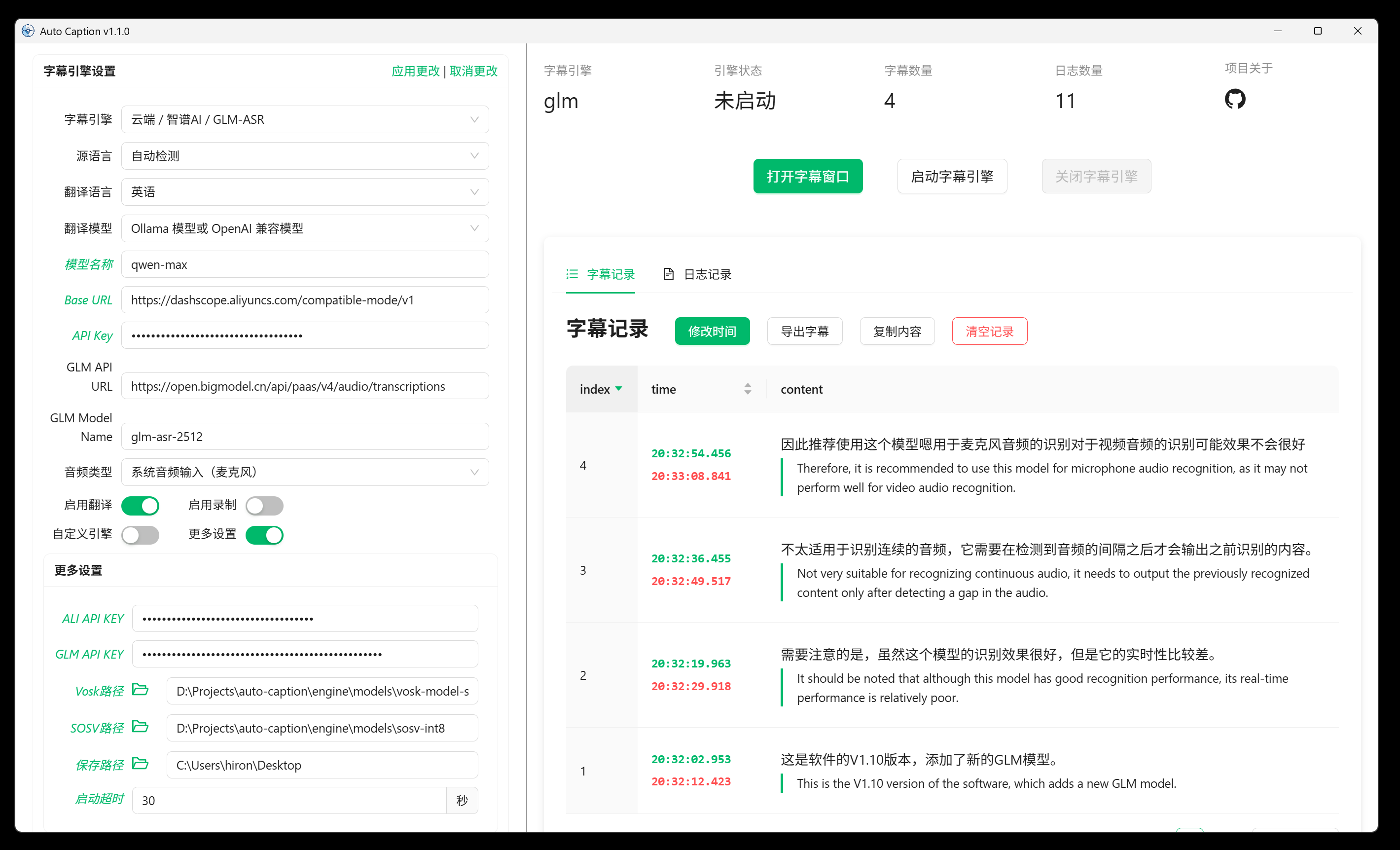
auto-caption
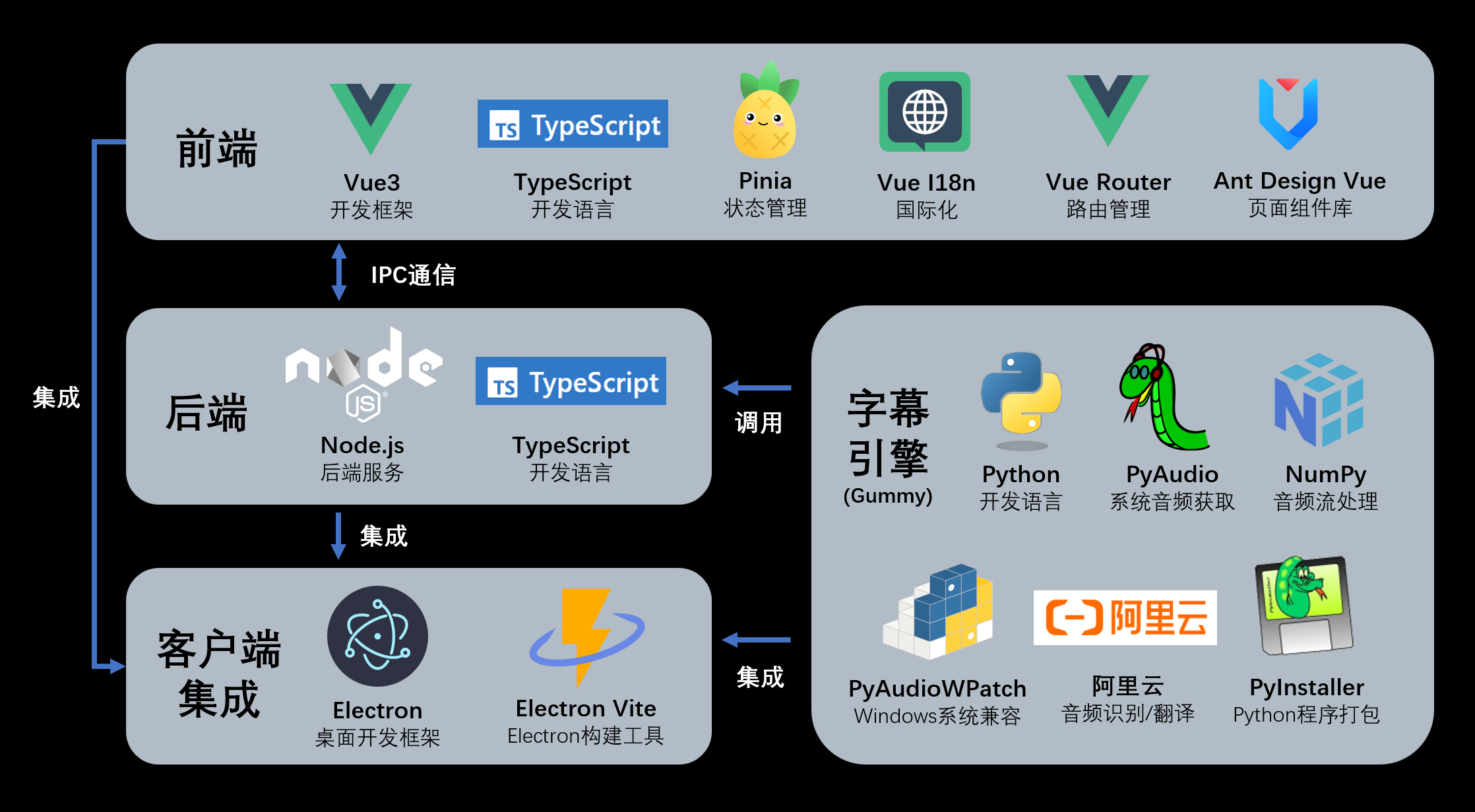
auto-caption 是一款功能强大的跨平台实时字幕显示软件,旨在为 Windows、macOS 和 Linux 用户解决视频观看、在线会议或音频学习中的语言障碍问题。它能够实时捕获系统音频输出或麦克风输入,并迅速将其转化为可视化的字幕文本,让无声或有语言门槛的内容变得易于理解。
这款工具特别适合普通用户、内容创作者以及需要频繁参与跨国会议的专业人士。无论是观看无字幕的外语视频,还是记录重要的语音备忘录,auto-caption 都能提供流畅的辅助体验。对于开发者和技术爱好者而言,其高度的可定制性和开源特性也极具吸引力,支持通过 Python 自行开发扩展模型引擎。
auto-caption 的核心亮点在于其灵活多样的字幕引擎选择与翻译能力。用户既可以选择注重隐私和本地运行的 Vosk 或 SOSV 本地模型,也可以接入阿里云 Gummy、智谱 GLM-ASR 等高精度云端服务。此外,它还支持调用本地 Ollama 大模型或云端 OpenAI 兼容接口进行即时翻译,实现了“识别+翻译”的一站式处理。软件提供了丰富的界面自定义选项,包括字体、颜色及背景样式,并支持将字幕记录导出为 .srt 或 .json 格式,方便后续整理与归档。尽管 macOS 和 Linux 用户在获取系统音频时可能需要少量额外配置,但其广泛的兼容性和免费开源的特性,使其成为一款值得尝试的实用效率工具。
使用场景
资深前端工程师李明正在参加一场全英文的跨国技术架构评审会,会议通过 Zoom 进行,主讲人是语速较快且带有口音的海外专家。李明需要实时理解复杂的技术细节,并在会后整理会议纪要同步给国内团队。
没有 auto-caption 时
- 听力负担极重:面对专业术语和快速语流,李明必须高度集中注意力猜测词义,极易因漏听关键参数而导致理解偏差,精神消耗巨大。
- 记录效率低下:为了不错过信息,他不得不频繁暂停回放或手忙脚乱地手动记笔记,导致无法紧跟演讲者的逻辑思路,错失上下文关联。
- 会后整理繁琐:会议结束后,李明需要花费数小时反复收听录音来补全笔记,人工转录不仅耗时,还容易因疲劳产生错别字,严重影响文档质量。
- 协作存在壁垒:未参会的同事只能依赖李明模糊的记忆复述,缺乏准确的文字依据,导致技术决策传达出现误差,增加沟通成本。
使用 auto-caption 后
- 实时双语辅助:李明启用 auto-caption 的“系统音频捕获”功能,选择高精度的 GLM-ASR 云端模型并配置 Ollama 本地翻译。屏幕上实时滚动显示中英对照字幕,即使遇到生僻术语也能通过中文译文瞬间理解,听力压力大幅减轻。
- 专注核心逻辑:不再需要手忙脚乱地记录,李明可以将全部精力集中在评估架构方案的可行性上,随时在代码编辑器中备注关键疑点,思维连贯性显著提升。
- 一键导出纪要:会议结束,李明直接导出
.srt和.json格式的字幕文件。原始识别文本准确率高,只需简单校对即可作为正式会议纪要,整理时间从几小时缩短至几分钟。 - 信息无损共享:他将清洗后的字幕文档分享给团队,未参会成员也能通过精确的文字记录复盘会议细节,确保技术决策透明、准确落地。
auto-caption 通过实时语音转写与翻译,将听觉信息转化为可视化的精准文本,极大提升了跨语言技术沟通的效率与准确性。
运行环境要求
- Windows
- macOS
- Linux
- 未说明(本地模型 Vosk/SOSV 基于 CPU 运行
- 云端模型无本地 GPU 需求)
未说明
快速开始

auto-caption
Auto Caption 是一个跨平台的实时字幕显示软件。




v1.1.1 版本已经发布,新增 GLM-ASR 云端字幕模型和 OpenAI 兼容模型翻译...
📥 下载
软件下载:GitHub Releases
Vosk 模型下载:Vosk Models
SOSV 模型下载: Shepra-ONNX SenseVoice Model
📚 相关文档
👁️🗨️ 预览
https://github.com/user-attachments/assets/9c188d78-9520-4397-bacf-4c8fdcc54874
✨ 特性
- 生成音频输出或麦克风输入的字幕
- 支持调用本地 Ollama 模型、云端 OpenAI 兼容模型、或云端 Google 翻译 API 进行翻译
- 跨平台(Windows、macOS、Linux)、多界面语言(中文、英语、日语)支持
- 丰富的字幕样式设置(字体、字体大小、字体粗细、字体颜色、背景颜色等)
- 灵活的字幕引擎选择(阿里云 Gummy 云端模型、GLM-ASR 云端模型、本地 Vosk 模型、本地 SOSV 模型、还可以自己开发模型)
- 多语言识别与翻译(见下文“⚙️ 自带字幕引擎说明”)
- 字幕记录展示与导出(支持导出
.srt和.json格式)
📖 基本使用
⚠️ 注意:目前只维护了 Windows 平台的软件的最新版本,其他平台的最后版本停留在 v1.0.0。
软件已经适配了 Windows、macOS 和 Linux 平台。测试过的主流平台信息如下:
| 操作系统版本 | 处理器架构 | 获取系统音频输入 | 获取系统音频输出 |
|---|---|---|---|
| Windows 11 24H2 | x64 | ✅ | ✅ |
| macOS Sequoia 15.5 | arm64 | ✅ 需要额外配置 | ✅ |
| Ubuntu 24.04.2 | x64 | ✅ | ✅ |
macOS 平台和 Linux 平台获取系统音频输出需要进行额外设置,详见 Auto Caption 用户手册。
下载软件后,需要根据自己的需求选择对应的模型,然后配置模型。
| 准确率 | 实时性 | 部署类型 | 支持语言 | 翻译 | 备注 | |
|---|---|---|---|---|---|---|
| Gummy | 很好😊 | 很好😊 | 云端 / 阿里云 | 10 种 | 自带翻译 | 收费,识别0.54CNY / 小时,识别+翻译1.08CNY/小时 |
| glm-asr-2512 | 很好😊 | 较差😞 | 云端 / 智谱 AI | 4 种 | 需额外配置 | 收费,约 0.72CNY / 小时 |
| Vosk | 较差😞 | 很好😊 | 本地 / CPU | 超过 30 种 | 需额外配置 | 支持的语言非常多 |
| SOSV | 一般😐 | 一般😐 | 本地 / CPU | 5 种 | 需额外配置 | 仅有一个模型 |
| 自己开发 | 🤔 | 🤔 | 自定义 | 自定义 | 自定义 | 根据文档使用 Python 自己开发 |
如果你选择的不是 Gummy 模型,你还需要配置自己的翻译模型。
配置翻译模型

注意:翻译不是实时的,翻译模型只会在每句话识别完成后再调用。
Ollama 本地模型
注意:使用参数量过大的模型会导致资源消耗和翻译延迟较大。建议使用参数量小于 1B 的模型,比如:
qwen2.5:0.5b,qwen3:0.6b.
使用该模型之前你需要确定本机安装了 Ollama 软件,并已经下载了需要的大语言模型。只需要将需要调用的大模型名称添加到设置中的 模型名称 字段中,并保证 Base URL 字段为空。
OpenAI 兼容模型
如果觉得本地 Ollama 模型的翻译效果不佳,或者不想在本地安装 Ollama 模型,那么可以使用云端的 OpenAI 兼容模型。
以下是一些模型提供商的 Base URL:
- OpenAI: https://api.openai.com/v1
- DeepSeek:https://api.deepseek.com
- 阿里云:https://dashscope.aliyuncs.com/compatible-mode/v1
API Key 需要在对应的模型提供商处获取。
Google 翻译 API
注意:Google 翻译 API 在无法访问国际网络的地区无法使用。
无需任何配置,联网即可使用。
使用 Gummy 模型
国际版的阿里云服务似乎并没有提供 Gummy 模型,因此目前非中国用户可能无法使用 Gummy 字幕引擎。
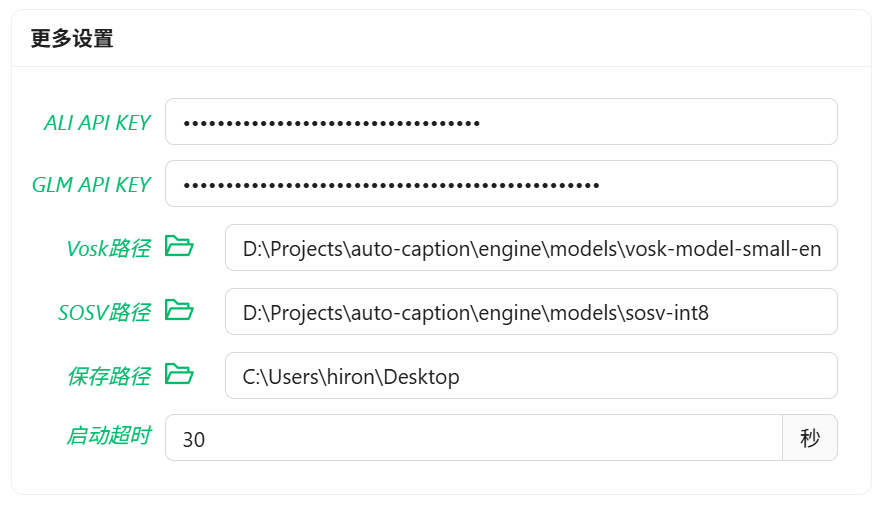
如果要使用默认的 Gummy 字幕引擎(使用云端模型进行语音识别和翻译),首先需要获取阿里云百炼平台的 API KEY,然后将 API KEY 添加到软件设置中(在字幕引擎设置的更多设置中)或者配置到环境变量中(仅 Windows 平台支持读取环境变量中的 API KEY),这样才能正常使用该模型。相关教程:
使用 GLM-ASR 模型
使用前需要获取智谱 AI 平台的 API KEY,并添加到软件设置中。
API KEY 获取相关链接:快速开始。
使用 Vosk 模型
Vosk 模型的识别效果较差,请谨慎使用。
如果要使用 Vosk 本地字幕引擎,首先需要在 Vosk Models 页面下载你需要的模型,并将模型解压到本地,并将模型文件夹的路径添加到软件的设置中。
使用 SOSV 模型
使用 SOSV 模型的方式和 Vosk 一样,下载地址如下:https://github.com/HiMeditator/auto-caption/releases/tag/sosv-model
⌨️ 在终端中使用
软件采用模块化设计,可用分为软件主体和字幕引擎两部分,软件主体通过图形界面调用字幕引擎。核心的音频获取和音频识别功能都在字幕引擎中实现,而字幕引擎是可用脱离软件主体单独使用的。
字幕引擎使用 Python 开发,通过 PyInstaller 打包为可执行文件。因此字幕引擎有两种使用方式:
- 使用项目字幕引擎部分的源代码,使用安装了对应库的 Python 环境进行运行
- 使用打包好的字幕引擎的可执行文件,通过终端运行
运行参数和详细使用介绍请参考用户手册。
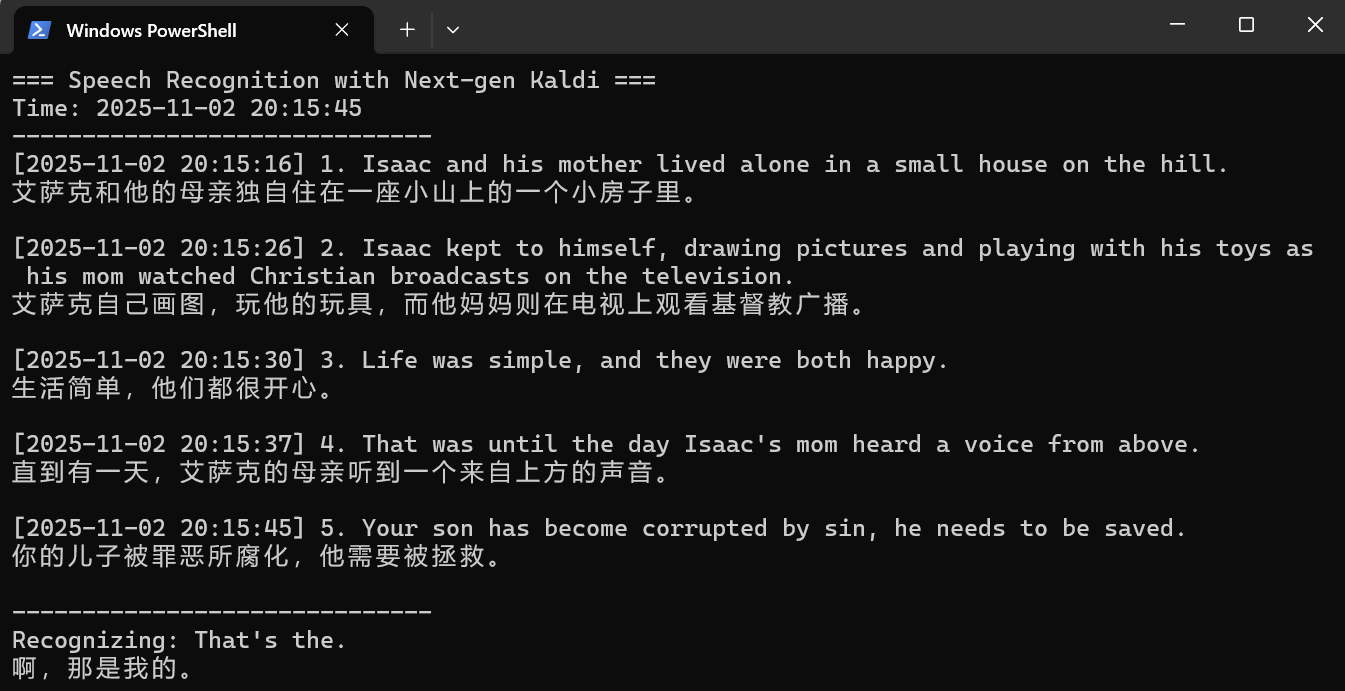
python main.py \
-e gummy \
-k sk-******************************** \
-a 0 \
-d 1 \
-s en \
-t zh
⚙️ 自带字幕引擎说明
目前软件自带 4 个字幕引擎。它们的详细信息如下。
Gummy 字幕引擎(云端)
基于通义实验室Gummy语音翻译大模型进行开发,基于阿里云百炼的 API 进行调用该云端模型。
模型详细参数:
- 音频采样率支持:16kHz及以上
- 音频采样位数:16bit
- 音频通道数支持:单通道
- 可识别语言:中文、英文、日语、韩语、德语、法语、俄语、意大利语、西班牙语
- 支持的翻译:
- 中文 → 英文、日语、韩语
- 英文 → 中文、日语、韩语
- 日语、韩语、德语、法语、俄语、意大利语、西班牙语 → 中文或英文
网络流量消耗:
字幕引擎使用原生采样率(假设为 48kHz)进行采样,样本位深为 16bit,上传音频为为单通道,因此上传速率约为:
$$ 48000\ \text{samples/second} \times 2\ \text{bytes/sample} \times 1\ \text{channel} = 93.75\ \text{KB/s} $$
而且引擎只会获取到音频流的时候才会上传数据,因此实际上传速率可能更小。模型结果回传流量消耗较小,没有纳入考虑。
GLM-ASR 字幕引擎(云端)
https://docs.bigmodel.cn/cn/guide/models/sound-and-video/glm-asr-2512
Vosk 字幕引擎(本地)
基于 vosk-api 开发。该字幕引擎的优点是可选的语言模型非常多(超过 30 种),缺点是识别效果比较差,且生成内容没有标点符号。
SOSV 字幕引擎(本地)
SOSV 是一个整合包,该整合包主要基于 Shepra-ONNX SenseVoice,并添加了端点检测模型和标点恢复模型。该模型支持识别的语言有:英语、中文、日语、韩语、粤语。
🚀 项目运行
安装依赖
npm install
构建字幕引擎
首先进入 engine 文件夹,执行如下指令创建虚拟环境(需要使用大于等于 Python 3.10 的 Python 运行环境,建议使用 Python 3.12):
cd ./engine
# in ./engine folder
python -m venv .venv
# 或者
python3 -m venv .venv
然后激活虚拟环境:
# Windows
.venv/Scripts/activate
# Linux 或 macOS
source .venv/bin/activate
接着安装依赖(这一步在 macOS 和 Linux 上可能会报错,通常是因为构建失败,需要根据错误信息进行处理):
pip install -r requirements.txt
之后使用 pyinstaller 构建项目:
pyinstaller ./main.spec
注意 main.spec 文件中 vosk 库的路径可能不正确,需要根据实际情况进行配置(与 Python 环境的版本相关)。
# Windows
vosk_path = str(Path('./.venv/Lib/site-packages/vosk').resolve())
# Linux 或 macOS
vosk_path = str(Path('./.venv/lib/python3.x/site-packages/vosk').resolve())
此时项目构建完成,进入 engine/dist 文件夹即可看到对应的可执行文件。接下来就可以进行后续操作。
运行项目
npm run dev
构建项目
# Windows 版本
npm run build:win
# macOS 版本
npm run build:mac
# Linux 版本
npm run build:linux
版本历史
v.1.1.12026/01/31v1.1.02026/01/10engine2025/11/02v1.0.02025/09/08sosv-model2025/09/06v0.7.02025/08/19v0.6.02025/07/29v0.5.12025/07/17v0.5.02025/07/15v0.4.02025/07/10v0.3.02025/07/08v0.2.02025/07/05v0.1.02025/06/26v0.0.12025/06/21常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
airi
airi 是一款开源的本地化 AI 伴侣项目,旨在将虚拟角色(如“二次元老婆”或赛博生命)带入用户的现实世界。它的核心目标是复刻并超越知名 AI 主播 Neuro-sama 的能力,让用户能够拥有完全自主掌控、可私有化部署的智能伙伴。 airi 主要解决了用户对高度定制化、具备情感交互能力且数据隐私安全的 AI 角色的需求。不同于依赖云端服务的通用助手,airi 允许用户在本地运行,不仅保护了对话隐私,还赋予了用户定义角色性格与灵魂的自由。它支持实时语音聊天,甚至能直接参与《我的世界》(Minecraft)和《异星工厂》(Factorio)等游戏,实现了从单纯对话到共同娱乐的跨越。 这款工具非常适合喜爱虚拟角色的普通用户、希望搭建个性化 AI 陪伴的技术爱好者,以及研究多模态交互的开发者。其独特的技术亮点在于跨平台支持(涵盖 Web、macOS 和 Windows)以及强大的游戏交互能力,让 AI 不仅能“说”,还能“玩”。通过容器化的灵魂设计,airi 为每个人创造专属数字生命提供了可能,让虚拟陪伴变得更加真实且触手可及。
MockingBird
MockingBird 是一款开源的实时语音克隆工具,旨在让用户仅需 5 秒的参考音频,即可快速合成任意内容的语音,并实现逼真的音色复刻。它有效解决了传统语音合成技术中数据采集成本高、训练周期长以及难以实时生成的痛点,让个性化语音生成变得触手可及。 这款工具特别适合开发者、AI 研究人员以及对语音技术感兴趣的技术爱好者使用。无论是用于构建交互式语音应用、进行声学模型研究,还是制作创意内容,MockingBird 都能提供强大的支持。普通用户若具备基础的编程环境配置能力,也可通过其提供的 Web 服务或工具箱体验前沿的变声效果。 在技术亮点方面,MockingBird 基于 PyTorch 框架,不仅完美支持中文普通话及多种主流数据集,还实现了跨平台运行,兼容 Windows、Linux 乃至 M1 架构的 macOS。其独特的架构设计允许复用预训练的编码器与声码器,只需微调合成器即可获得出色效果,大幅降低了部署门槛。此外,项目内置了现成的 Web 服务器功能,方便用户通过远程调用快速集成到自己的应用中。尽管原作者已转向云端优化版本,但 MockingBird 作为经典的本地部署方案