VideoChat
VideoChat 是一款开源的实时语音交互数字人项目,旨在让虚拟形象能够像真人一样与你进行流畅对话。它解决了传统数字人反应迟钝、声音单一且难以定制的痛点,实现了从听到用户说话到数字人开口回答的首包延迟低至 3 秒,带来近乎实时的互动体验。
该项目非常适合开发者、研究人员以及希望构建智能客服、虚拟主播或个性化助手的企业团队使用。无论是需要快速验证原型的工程师,还是追求高拟真效果的内容创作者,都能从中找到适合的方案。
VideoChat 的技术亮点在于其灵活的架构设计:既支持“语音识别 - 大模型 - 语音合成 - 口型生成”的级联模式,也支持基于 GLM-4-Voice 的端到端多模态大模型方案。用户不仅可以自由定制数字人的外貌和音色,还能通过少量样本实现音色克隆,让数字人拥有独特的声音特征。在部署上,它兼容本地运行与云端 API 调用,针对不同显存条件的硬件提供了优化选项,让高性能数字人交互触手可及。
使用场景
某跨境电商企业希望为海外用户提供 24 小时不间断的个性化视频客服,以解决时差导致的响应滞后问题。
没有 VideoChat 时
- 形象僵硬单一:只能使用预录制的通用视频或静态头像,无法根据用户提问实时生成口型匹配的回答,缺乏真实感。
- 声音缺乏温度:依赖传统机械式 TTS 合成音,语调平淡且无法复刻品牌专属代言人的音色,难以建立情感连接。
- 响应延迟严重:采用传统的“语音转文字 - 大模型思考 - 文字转语音 - 渲染视频”串行流程,首包等待时间往往超过 10 秒,用户体验断裂。
- 定制成本高昂:若要更换不同国家或风格的客服形象,需重新拍摄真人视频或购买昂贵的商业授权,迭代周期长达数周。
使用 VideoChat 后
- 交互自然逼真:利用 MuseTalk 技术驱动自定义数字人,唇形与表情能实时跟随回答内容变化,实现端到端的流畅对话。
- 音色高度拟人:通过 GPT-SoVITS 或 CosyVoice 克隆品牌代言人声音,输出富有情感的语音,显著提升用户信任度。
- 低延迟实时响应:得益于优化的级联架构(ASR-LLM-TTS-THG),首包延迟低至 3 秒,让用户感觉像是在与真人面对面交流。
- 灵活快速部署:仅需少量素材即可在本地或云端快速克隆新形象与新音色,支持按需切换多语言客服,大幅降低运营门槛。
VideoChat 将原本高成本、高延迟的视频交互转化为可实时定制的低门槛服务,让企业能以极低成本构建具备“真人质感”的全球化智能客服体系。
运行环境要求
- Linux (Ubuntu 22.04)
- 必需 NVIDIA GPU
- 级联方案需约 8GB 显存,端到端方案需约 20GB 显存(参考单张 A100)
- 需 CUDA 12.2
未说明

快速开始
数字人对话demo
实时语音交互数字人,支持端到端(MLLM - THG)和级联(ASR-LLM-TTS-THG)。可自定义形象与音色,支持音色克隆,首包延迟低至3s。
技术介绍:量子位推文
中文简体 | English
Star History

技术选型
- ASR (Automatic Speech Recognition): FunASR
- LLM (Large Language Model): Qwen
- End-to-end MLLM (Multimodal Large Language Model): GLM-4-Voice
- TTS (Text to speech): GPT-SoVITS, CosyVoice, edge-tts
- THG (Talking Head Generation): MuseTalk
本地部署
0. 显存需求
级联方案(ASR-LLM-TTS-THG):约8G,首包约3s(单张A100)。
端到端语音方案(MLLM-THG):约20G,首包约7s(单张A100)。
如果不需要使用端到端 MLLM,请选择仅包含级联方案的cascade_only分支。
$ git checkout cascade_only
1. 环境配置
- ubuntu 22.04
- python 3.10
- CUDA 12.2
$ git lfs install
$ git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git
$ conda create -n metahuman python=3.10
$ conda activate metahuman
$ cd video_chat
$ pip install -r requirements.txt
requirements中的版本仅供参考,最新依赖请查看对应模块的Repo说明
2. 权重下载
2.1 创空间下载(推荐)
创空间仓库已设置git lfs追踪权重文件,如果是通过git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git克隆,则无需额外配置
2.2 手动下载
2.2.1 MuseTalk
参考这个链接
目录如下:
./weights/
├── dwpose
│ └── dw-ll_ucoco_384.pth
├── face-parse-bisent
│ ├── 79999_iter.pth
│ └── resnet18-5c106cde.pth
├── musetalk
│ ├── musetalk.json
│ └── pytorch_model.bin
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── whisper
└── tiny.pt
2.2.2 GPT-SoVITS
参考这个链接
2.2.3 GLM-4-Voice
在app.py中添加如下代码即可完成下载。
from modelscope import snapshot_download
snapshot_download('ZhipuAI/glm-4-voice-tokenizer',cache_dir='./weights')
snapshot_download('ZhipuAI/glm-4-voice-decoder',cache_dir='./weights')
snapshot_download('ZhipuAI/glm-4-voice-9b',cache_dir='./weights')
3. 其他配置
LLM模块和TTS模块提供了多种方式,可自行选择推理方式
3.1 使用API-KEY(默认)
对于LLM模块和TTS模块,如果本地机器性能有限,可使用阿里云大模型服务平台百炼提供的Qwen API和CosyVoice API,请在app.py(line 14)中配置API-KEY。
参考这个链接完成API-KEY的获取与配置。
os.environ["DASHSCOPE_API_KEY"] = "INPUT YOUR API-KEY HERE"
3.2 不使用API-KEY
如果不使用API-KEY,请参考以下说明修改相关代码。
3.2.1 LLM模块
src/llm.py中提供了Qwen和Qwen_API两个类分别处理本地推理和调用API。若不使用API-KEY,有以下两种方式进行本地推理:
- 使用
Qwen完成本地推理。 Qwen_API默认调用API完成推理,若不使用API-KEY,还可以使用vLLM加速LLM推理。可参考如下方式安装vLLM:
安装完成后,参考这个链接进行部署,使用$ git clone https://github.com/vllm-project/vllm.git $ cd vllm $ python use_existing_torch.py $ pip install -r requirements-build.txt $ pip install -e . --no-build-isolationQwen_API(api_key="EMPTY",base_url="http://localhost:8000/v1")初始化实例调用本地推理服务。
3.2.2 TTS模块
src/tts.py中提供了GPT_SoVits_TTS和CosyVoice_API分别处理本地推理和调用API。若不使用API-KEY,可直接删除CosyVoice_API相关的内容,使用Edge_TTS调用Edge浏览器的免费TTS服务进行推理。
4. 启动服务
$ python app.py
5. 使用自定义数字人(可选)
5.1 自定义数字人形象
- 在
/data/video/中添加录制好的数字人形象视频 - 修改
/src/thg.py中Muse_Talk类的avatar_list,加入(形象名, bbox_shfit),关于bbox_shift的说明参考这个链接 - 在
/app.py中Gradio的avatar_name中加入数字人形象名后重新启动服务,等待完成初始化即可。
5.2 自定义数字人音色
GPT-SoVits支持自定义音色。demo中可使用音色克隆功能,上传任意语音内容的参考音频后开始对话,或将音色永久添加到demo中:
- 在
/data/audio中添加音色参考音频,音频长度3-10s,命名格式为x.wav - 在
/app.py中Gradio的avatar_voice中加入音色名(命名格式为x (GPT-SoVits))后重新启动服务。 - TTS选型选择
GPT-SoVits,开始对话
6. 已知问题
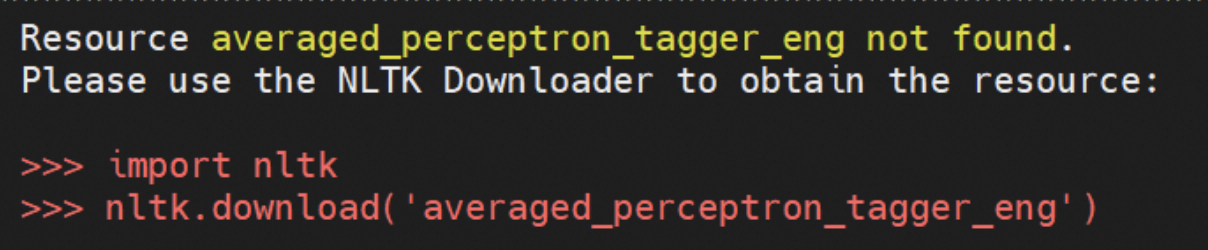
报错无法找到某资源:按照报错提示下载对应的资源即可
右侧视频流播放卡顿:需等待Gradio优化Video Streaming效果
与模型加载相关:检查权重是否下载完整
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
cs-video-courses
cs-video-courses 是一个精心整理的计算机科学视频课程清单,旨在为自学者提供系统化的学习路径。它汇集了全球知名高校(如加州大学伯克利分校、新南威尔士大学等)的完整课程录像,涵盖从编程基础、数据结构与算法,到操作系统、分布式系统、数据库等核心领域,并深入延伸至人工智能、机器学习、量子计算及区块链等前沿方向。 面对网络上零散且质量参差不齐的教学资源,cs-video-courses 解决了学习者难以找到成体系、高难度大学级别课程的痛点。该项目严格筛选内容,仅收录真正的大学层级课程,排除了碎片化的简短教程或商业广告,确保用户能接触到严谨的学术内容。 这份清单特别适合希望夯实计算机基础的开发者、需要补充特定领域知识的研究人员,以及渴望像在校生一样系统学习计算机科学的自学者。其独特的技术亮点在于分类极其详尽,不仅包含传统的软件工程与网络安全,还细分了生成式 AI、大语言模型、计算生物学等新兴学科,并直接链接至官方视频播放列表,让用户能一站式获取高质量的教育资源,免费享受世界顶尖大学的课堂体验。