TokenFormer
TokenFormer 是一个基于注意力机制的开源神经网络架构,其核心创新在于将模型参数本身也转化为可交互的“令牌”。传统 Transformer 主要处理输入数据之间的关联,而 TokenFormer 进一步允许模型参数以令牌形式参与注意力计算,从而在输入、参数乃至外部记忆之间建立灵活的交互。这种设计旨在从根本上重新思考 Transformer 的扩展方式,提升架构的灵活性与表达能力。
它主要试图解决传统模型在扩展性和结构灵活性上的限制。通过“参数令牌化”,模型能够更统一、高效地处理不同规模和类型的任务,为构建动态、数据依赖或具有记忆功能的网络提供了新的基础范式。
TokenFormer 非常适合人工智能领域的研究人员和算法工程师,特别是那些关注模型架构创新、Transformer 改进、大模型缩放律以及动态神经网络设计的专业人士。对于希望探索下一代基础模型可能性的开发者而言,它也提供了极具启发性的代码实现和实验基准。
其技术亮点在于提出了一个“万物皆可令牌化”的统一视角,仅通过数据令牌、参数令牌和记忆令牌之间的点积交互,理论上就能灵活构建多种类型的网络(如类似 RNN、Mamba 或测试时训练 TTT 的网络)。该项目代码简洁、依赖最小,并已在 ICLR 2025 上被接收为 Spotlight 论文,提供了 PyTorch 和 Jax 的完整实现。
使用场景
场景背景:某AI研发团队正在开发一个多模态智能客服系统,需要同时处理文本、语音和图像工单。团队希望用一个统一的模型架构来简化系统设计,但传统Transformer在处理不同类型数据和动态调整模型规模时存在局限。
没有 TokenFormer 时
- 架构僵化:为文本、语音、图像分别设计并维护不同的模型分支,导致代码库复杂,模块间协同困难。
- 扩展低效:当需要针对新出现的“视频工单”增加处理能力时,必须重新设计并训练一个独立的视频模块,周期长、成本高。
- 资源浪费:为应对不同规模的并发请求(如白天文本多、夜间语音多),需预先部署多个不同大小的模型实例,计算资源利用率低。
- 动态适应能力弱:模型参数固定,无法根据当前输入数据的复杂程度(如简单查询 vs. 多步骤故障诊断)动态调整计算路径或“调用”不同的内部知识。
使用 TokenFormer 后
- 架构统一灵活:将模型参数本身也视为可被注意力机制处理的“令牌”,从而能用一套注意力计算框架统一处理文本、语音、图像令牌和参数令牌,用一个简洁的模型结构代替多个分支。
- 扩展便捷:要增加视频处理能力,只需将视频特征作为新的令牌类型引入,并添加或调整对应的参数令牌,模型能通过注意力机制快速学习新旧模态间的关系,实现快速迭代。
- 按需缩放:通过激活或组合不同的参数令牌子集,可以实现在同一个模型框架下,动态地创建出适合处理当前任务规模(如简单回复用小型参数集,复杂分析用大型参数集)的模型,提升资源利用率。
- 数据依赖推理:参数令牌可以“关注”输入数据,使得模型的有效参数能够根据输入内容动态变化,为简单问题选择高效路径,为复杂问题激活更深入的分析能力,提升了响应的智能度和准确性。
TokenFormer 通过将模型参数令牌化,并用注意力机制统一建模数据与参数的交互,为构建可动态扩展、多模态统一的AI系统提供了高度灵活的架构基础。
运行环境要求
- Linux
必需 NVIDIA GPU,CUDA 12,PyTorch 2.2.1+,需安装 apex
未说明
快速开始
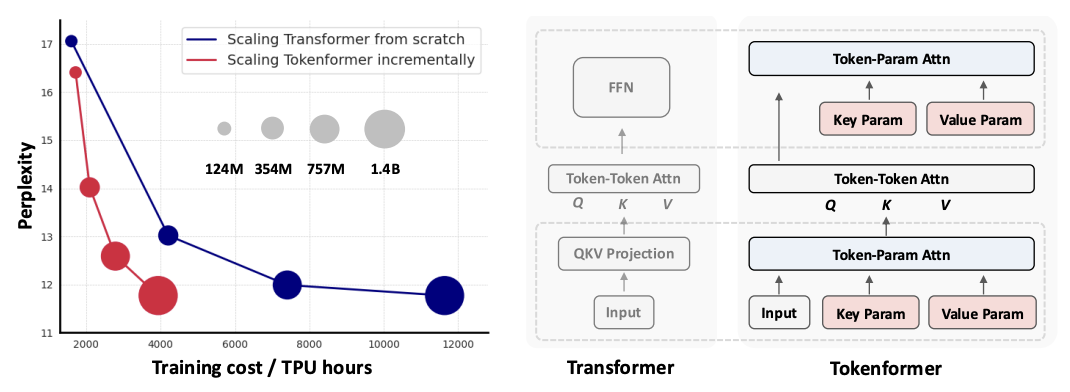
TokenFormer:一个完全基于注意力机制的神经网络,具有令牌化的模型参数。通过令牌化一切来最大化 Transformer 的灵活性。
![]()
![]()
本仓库是我们论文 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 及其后续工作的官方实现。我们的 TokenFormer 是一种原生可扩展的架构,它不仅利用注意力机制进行输入令牌(tokens)之间的计算,还用于令牌与模型参数之间的交互,从而增强了架构的灵活性。我们已尽最大努力确保代码库干净、简洁、易于阅读、保持最先进水平,并且仅依赖于最少的依赖项。
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Haiyang Wang*, Yue Fan*, Muhammad Ferjad Naeem, Yongqin Xian, Jan Eric Lenssen, Liwei Wang, Federico Tombari, Bernt Schiele
- 主要联系人:Haiyang Wang
(haiwang@mpi-inf.mpg.de)(wanghaiyang6@stu.pku.edu.cn), Bernt Schiele (schiele@mpi-inf.mpg.de)
📣 新闻
- [25-02-11] 🔥 TokenFormer 被接受为 亮点报告。
- [25-01-22] 🔥 TokenFormer 被 ICLR2025 接收。
- [25-01-12] 在 TPU (GCP-Cloud) 上的 Jax 代码已发布,请参见 此处。
- [24-11-08] 🚀 使用 PyTorch 的训练代码已发布。
- [24-11-02] 如果我遗漏了任何相关论文,请随时通过电子邮件联系我。我将尽力在未来版本中包含所有相关论文。
- [24-10-31] 🚀 使用 PyTorch 的推理代码已发布。
- [24-10-31] 👀 TokenFormer 在 arXiv 上发布。
🔥 一些思考
- 我们旨在为模型提供一个新视角,适用于未来的任何计算图。理论上,通过使用数据令牌、参数令牌和记忆令牌,并通过点积交互,可以灵活地构建任何网络。这里有很多设计可能性。例如,引入记忆令牌可以构建类似于 Mamba 的类 RNN 网络。将参数令牌与记忆令牌合并可以创建类似于 TTT 网络 的东西。参数令牌也可以反向关注输入数据,使网络参数动态地依赖于数据,逐层更新。
概述
💫 我们的目标?
我们介绍了 Tokenformer,一种 完全基于注意力机制 的架构,它通过完全采用注意力机制统一了令牌-令牌和令牌-参数交互的计算,最大化神经网络的灵活性。这一优势使其能够处理可变数量的参数,本质上增强了模型的可扩展性,促进了渐进式高效扩展。
我们不仅对数据进行令牌化,还对模型参数进行令牌化,用数据和参数令牌之间的交互流取代了模型的概念,进一步推动了网络架构的统一。
希望这种架构能够比传统 Transformer 提供更大的灵活性,并将进一步促进基础模型、稀疏推理(MoE)、参数高效调优、设备-云协作、视觉-语言、模型可解释性等领域的发展。
# 给定输入的 Pattention 实现
query, key, value = inputs, key_param_tokens, value_param_tokens
attn_weight = query @ key.transpose(-2, -1) * scale_factor
attn_weight *= attn_masks
# 修改后的 softmax,softmax 等同于 exp + L1 范数
attn_weight = nonlinear_norm_func(attn_weight, self.norm_activation_type, dim=-1)
output = attn_weight @ value
🚀 主要结果
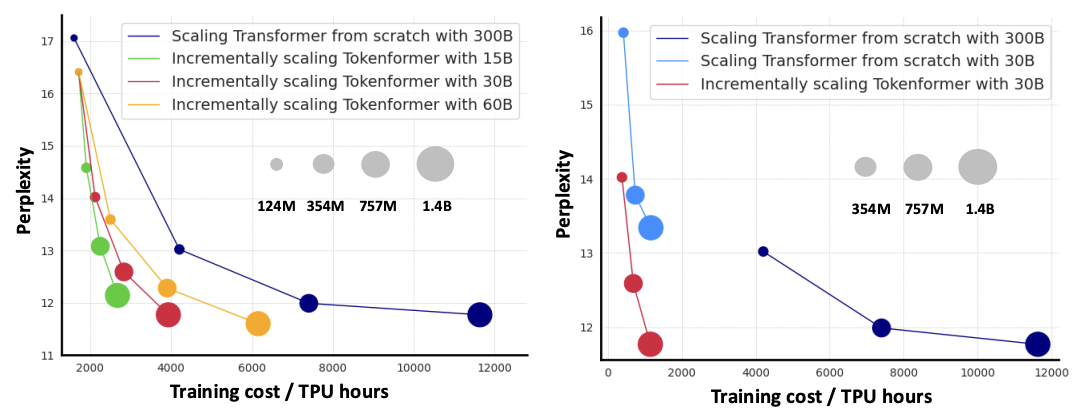
增量模型扩展
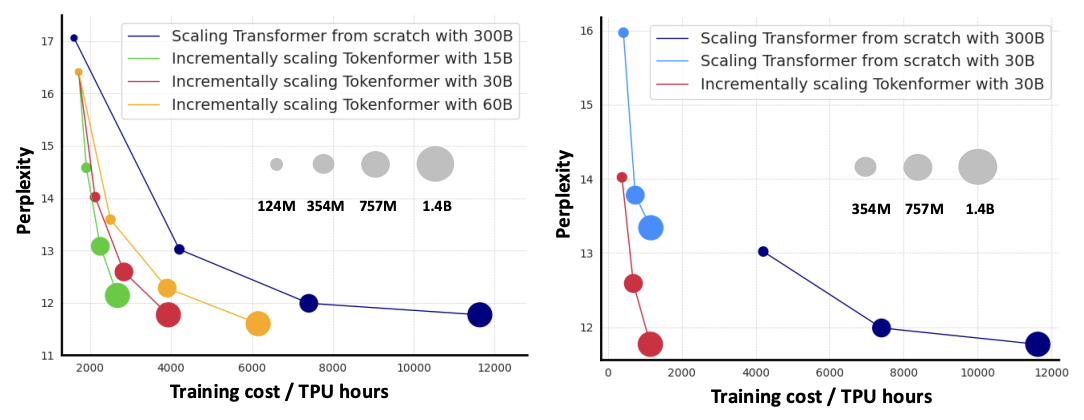
传统上,大型 Transformer 架构是从头开始训练的,没有重用先前较小规模的模型。在本文中,我们提出了一种新颖的完全基于注意力机制的架构,允许增量扩展模型,从而大大降低了训练大型 Transformer 架构的总体成本。
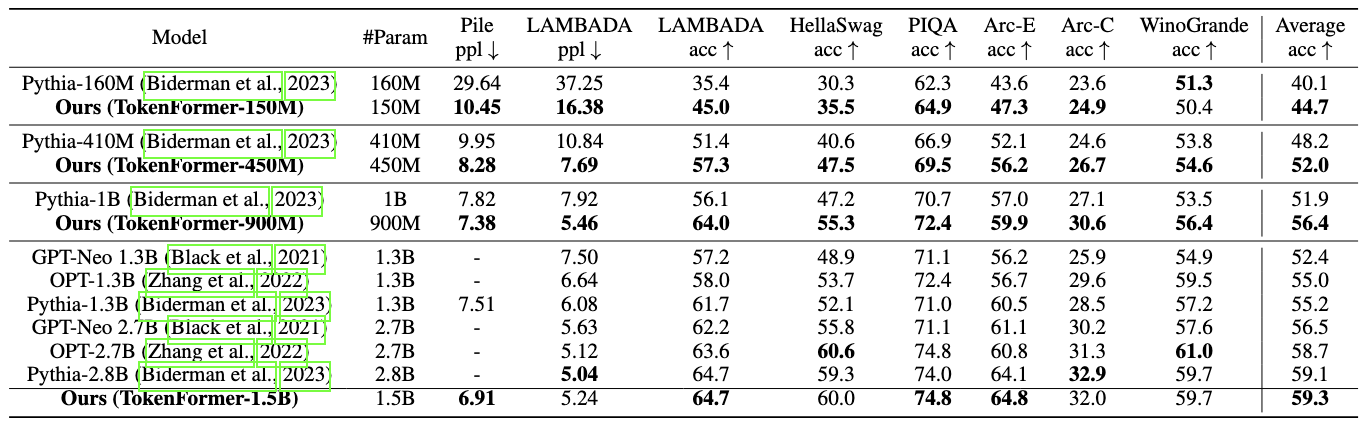
在 Pile 数据集上进行语言建模并进行零样本评估
(零样本评估。) 每个模型大小的最佳性能以粗体突出显示。我们的比较是与使用各种分词器的公开可用的基于 Transformer 的语言模型进行的。遵循 Pythia,我们的模型在 Pile 数据集上训练了高达 300B 个令牌。
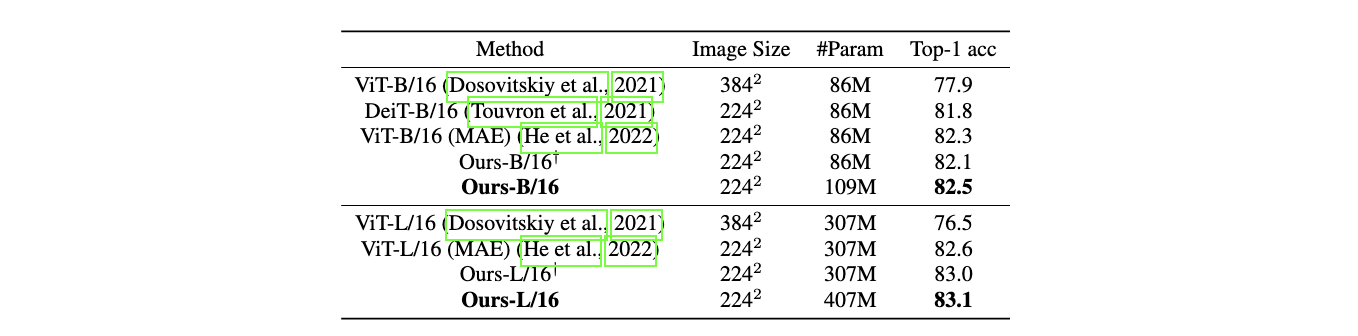
在 ImageNet-1k 分类上进行视觉建模
(图像分类。) 在 ImageNet-1K 上标准视觉 Transformer 的比较。
📘 模型库
语言建模基准测试(Pile)
预训练模型已上传至 huggingface,包括 TokenFormer-150M、TokenFormer-450M、TokenFormer-900M 和 TokenFormer-1-5B,这些模型在 Pile 数据集上训练了 300B 个 token。
这些模型在 Pile 数据集上训练,遵循 Transformer 的标准模型维度,并在 mamba 描述的零样本(zero-shot)基准测试上进行了评估:
| 模型 | 参数 | 层数 | 模型维度 | 检查点 | 配置 | 日志 |
|---|---|---|---|---|---|---|
| TokenFormer-150M | 150M | 12 | 768 | 检查点 | 配置 | 日志 |
| TokenFormer-450M | 450M | 24 | 1024 | 检查点 | 配置 | 日志 |
| TokenFormer-900M | 900M | 32 | 1280 | 检查点 | 配置 | 日志 |
| TokenFormer-1-5B | 1-5B | 40 | 1536 | 检查点 | 配置 | 日志 |
注意:这些是仅训练了 300B token 的基础模型,未经过任何形式的下游修改(如指令微调等)。预期性能与其他在相似数据上训练的架构相当或更优,但无法与更大规模或经过微调的模型相比。
视觉建模基准测试(基于 CLIP 方法的 DataComp-1B)
稍后发布。
🛠️ 快速开始
安装
首先确保您处于 Python 3.8 和 CUDA 12 的环境中,并安装了适当版本的 PyTorch 1.8 或更高版本。注意: 我们的 TokenFormer 基于 GPT-NeoX,GPT-NeoX 依赖的一些库尚未更新以兼容 Python 3.10+。Python 3.9 似乎可以工作,但本代码库是在 Python 3.8 上开发和测试的。
要安装其余的基本依赖项,请运行:
conda create -n TokenFormer python=3.8
git clone https://github.com/Haiyang-W/TokenFormer.git
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
### raven module load gcc/10
### 如果在运行 pip install -r requirements/requirements.txt 时遇到 cargo 问题,请执行以下命令
# curl https://sh.rustup.rs -sSf | sh
# export PATH="$HOME/.cargo/bin:$PATH"
# source ~/.profile
# source ~/.cargo/env
### 如果在运行 pip install -r requirements/requirements.txt 时遇到 mpi4py 问题,请执行:
# conda install -c conda-forge mpi4py=3.0.3
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-flashattention.txt # 需要 gcc > 9
pip install -r requirements/requirements-wandb.txt # 可选,如果使用 WandB 记录日志
pip install -r requirements/requirements-tensorboard.txt # 可选,如果使用 tensorboard 记录日志
pip install -r requirements/requirements-comet.txt # 可选,如果使用 Comet 记录日志
# 安装 apex
pip install -r requirements/requirements-apex-pip.txt # pip > 23.1
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
从仓库根目录执行。
评估
要运行模型的零样本评估(对应论文中的表 1),我们使用 lm-evaluation-harness 库。
首先,您需要从 huggingface 下载预训练权重到本地目录。例如,相对于仓库根目录的路径是 ./TokenFormer-150M/pytorch_model.bin。
# 单 GPU 评估(目前仅在单 GPU 上测试过。)
cd ./TokenFormer
python ./deepy.py eval.py -d configs tokenformer/150M_eval.yml --eval_tasks lambada_openai hellaswag piqa arc_challenge arc_easy winogrande
用于训练的预配置数据集
提供了几个预配置的数据集,包括来自 openwebtext 和 Pile 的大部分组件。
例如,使用 GPT-NeoX 20B Tokenizer 下载并分词 openwebtext2 数据集。您可以先尝试这个小数据集。
python prepare_data.py -d ./data -t HFTokenizer --vocab-file tokenizer.json openwebtext2
预处理后的数据将位于 ./data/openwebtext2。
对于 Pile 300B(非官方且未复制的版本):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file tokenizer.json pile
预处理后的数据将位于 ./data/pile。
分词后的数据将保存为两个文件:[data-dir]/[dataset-name]/[dataset-name]_text_document.bin 和 [data-dir]/[dataset-name]/[dataset-name]_text_document.idx。您需要在训练配置文件的 data-path 字段中添加这两个文件共享的前缀。例如:
"data-path": "./data/pile/pile_0.87_deduped_text_document",
如果您想轻松上手,可以尝试 enwik8。
训练
单节点启动
注意,这是针对单节点的。适用于您可以直接 SSH 登录到一台 8-GPU 机器并直接运行程序的情况。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python deepy.py train.py configs/tokenformer/150M_train_pile.yml
多节点启动
请参考 multi-node-launching。我使用 slurm 并提供以下指导。
首先,修改您的训练配置
{
"launcher": "slurm",
"deepspeed_slurm": true,
}
然后,我提供一个使用 16 个 GPU 的 slurm 脚本作为示例。
#!/bin/bash
#SBATCH --job-name="150M_16gpus"
#SBATCH --constraint="gpu"
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:8
#SBATCH --cpus-per-task=4 # 每个任务使用 4 个核心。
#SBATCH --time=24:00:00
#SBATCH -o /tmp/150M_%A_%a.out
conda activate TokenFormer
一些可能用到的分布式环境变量
export HOSTNAMES=scontrol show hostnames "$SLURM_JOB_NODELIST"
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_PORT=12856
export COUNT_NODE=scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l
运行之前编写的 hostfile 创建脚本
bash ./write_hostfile.sh
通过 DLTS_HOSTFILE 告诉 DeepSpeed 在哪里找到我们生成的 hostfile,你可以自定义任何路径。
export DLTS_HOSTFILE=/tmp/hosts_$SLURM_JOBID
python3 deepy.py train.py ./configs/tokenformer/150M_train_pile.yml
这里的所有路径都可以自定义;你可以将上述脚本和 `write_hostfile.sh` 中的 `/tmp` 替换为你想要的任何路径。然后运行脚本
sbatch scripts.sh
#### 训练后的零样本评估
进入你的检查点目录,例如 150M
cd ./work_dirs/150M_TokenFormer_Pile/checkpoints python zero_to_fp32.py . pytorch_model.bin
然后用该路径替换 `150M_eval.yml` 中的 **[eval_ckpt](https://github.com/Haiyang-W/TokenFormer/blob/79a02d8a2f847e8bbc627f7cb1632a2f24f3f826/configs/tokenformer/150M_eval.yml#L98)**。
cd ./TokenFormer python ./deepy.py eval.py -d configs tokenformer/150M_eval.yml --eval_tasks lambada_openai hellaswag piqa arc_challenge arc_easy winogrande
`注意:` 我目前只运行了前 1000 次迭代的训练代码来检查损失,看起来没问题,所以先发布出来供大家使用。我不能保证完全没有问题。如果你愿意等待,我可以做最终检查,但这可能需要一些时间。
### 增量训练
请从 [huggingface:354M_TokenFormer_Openwebtext2.zip](https://huggingface.co/Haiyang-W/TokenFormer-354M-Openwebtext2/tree/main) 下载在 openwebtext2 数据集上预训练的 354M TokenFormer,并将其解压到你的本地目录。例如,相对于仓库根目录的相对路径是 ``./354M_TokenFormer_Openwebtext2/``。然后,将 [语言数据集](https://github.com/Haiyang-W/TokenFormer/blob/ab93c3de1805a6a7a2733c462068d68e83c849b5/configs/incremental_scaling_openwebtext2/354M_to_757M_train_openwebtext2_60k.yml#L110) 和 [预训练检查点](https://github.com/Haiyang-W/TokenFormer/blob/ab93c3de1805a6a7a2733c462068d68e83c849b5/configs/incremental_scaling_openwebtext2/354M_to_757M_train_openwebtext2_60k.yml#L33) 的路径正确配置为你的本地路径。这里的预训练检查点是在 OpenWebText2 上训练 TokenFormer 354M 模型 60 万步的结果。对应的配置文件在[这里](https://github.com/Haiyang-W/TokenFormer/blob/main/configs/incremental_scaling_openwebtext2/354M_train_openwebtext2_basemodel.yml)。
请按照[此处](https://github.com/Haiyang-W/TokenFormer/tree/main?tab=readme-ov-file#preconfigured-datasets-for-training)的说明准备 openwebtext2 数据集。
cd ./TokenFormer python deepy.py train.py configs/incremental_scaling_openwebtext2/354M_to_757M_train_openwebtext2_60k.yml
模型的性能如下:
| 模型 | 训练策略 | 层数 | 模型维度 | 迭代次数 |验证集困惑度|配置文件|
|---------|---------|---------|--------|--------|---------|---------|
| TokenFormer-354M | 从头训练 | 24 | 1024 | 600k |11.9|[配置文件](https://github.com/Haiyang-W/TokenFormer/blob/main/configs/incremental_scaling_openwebtext2/354M_train_openwebtext2_basemodel.yml) |
| TransFormer-757M | 从头训练 | 24 | 1536 | 60k |12.0 | - |
| TransFormer-757M | 从头训练 | 24 | 1536 | 120k |11.3 | - |
| TransFormer-757M | 从头训练 | 24 | 1536 | 600k |10.5 | - |
| TokenFormer-757M | 增量训练 | 24 | 1024 | 60k |10.9|[配置文件](https://github.com/Haiyang-W/TokenFormer/blob/main/configs/incremental_scaling_openwebtext2/354M_to_757M_train_openwebtext2_60k.yml) |
| TokenFormer-757M | 增量训练 | 24 | 1024 | 120k |10.7|[配置文件](https://github.com/Haiyang-W/TokenFormer/blob/main/configs/incremental_scaling_openwebtext2/354M_to_757M_train_openwebtext2_120k.yml) |
## 👀 待办事项
- [x] 发布 [arXiv](https://arxiv.org/abs/2410.23168) 版本。
- [x] 发布大语言模型的推理代码和模型权重。
- [x] 发布大语言模型的训练代码。
- [x] 发布大语言模型的增量缩放训练代码。
## 📘 引用
如果我们的工作对你有帮助,请考虑按如下方式引用。
@inproceedings{ wang2025tokenformer, title={TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters}, author={Haiyang Wang and Yue Fan and Muhammad Ferjad Naeem and Liwei Wang and Yongqin Xian and Jan Eric Lenssen and Federico Tombari and Bernt Schiele}, booktitle={The Thirteenth International Conference on Learning Representations}, year={2025}, url={https://openreview.net/forum?id=oQ4igHyh3N} } ```
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。