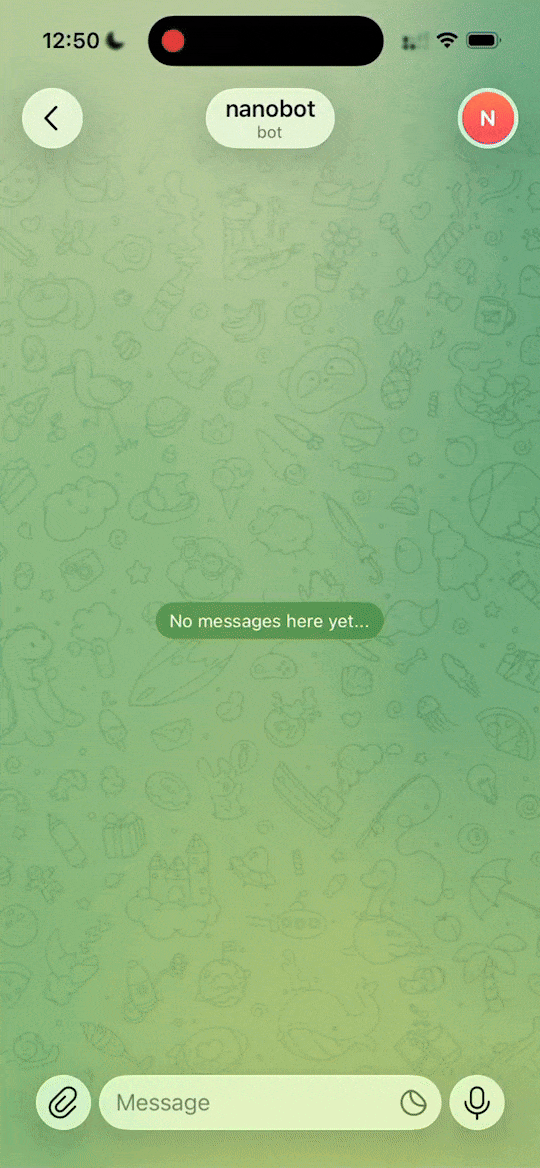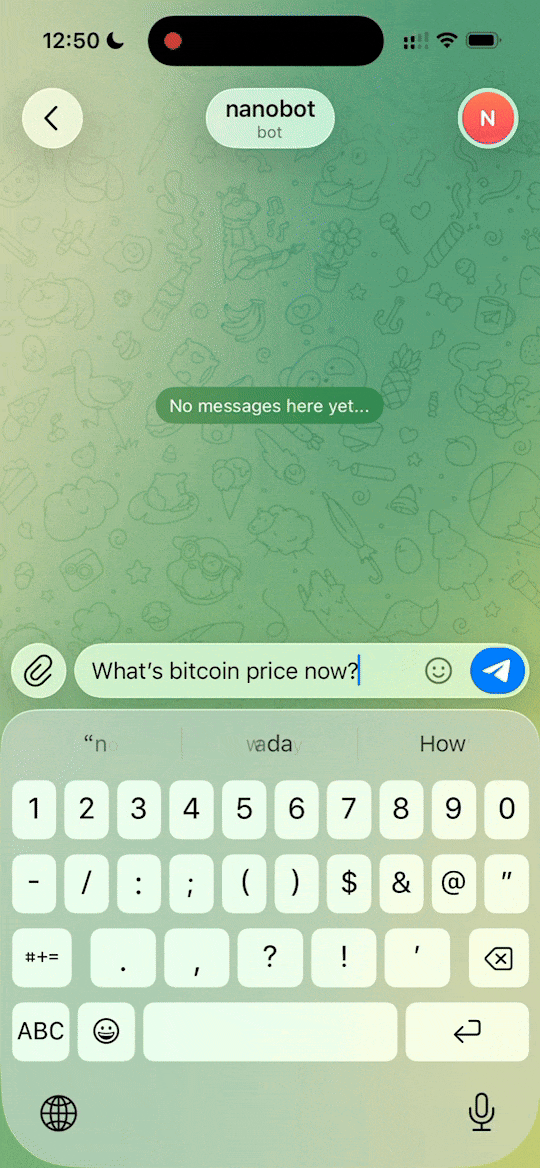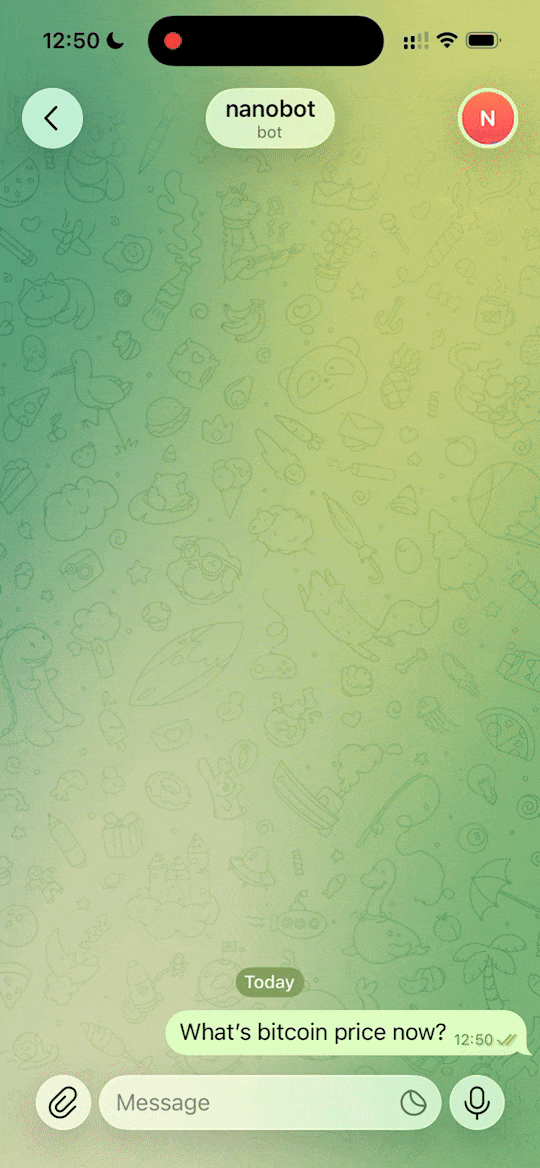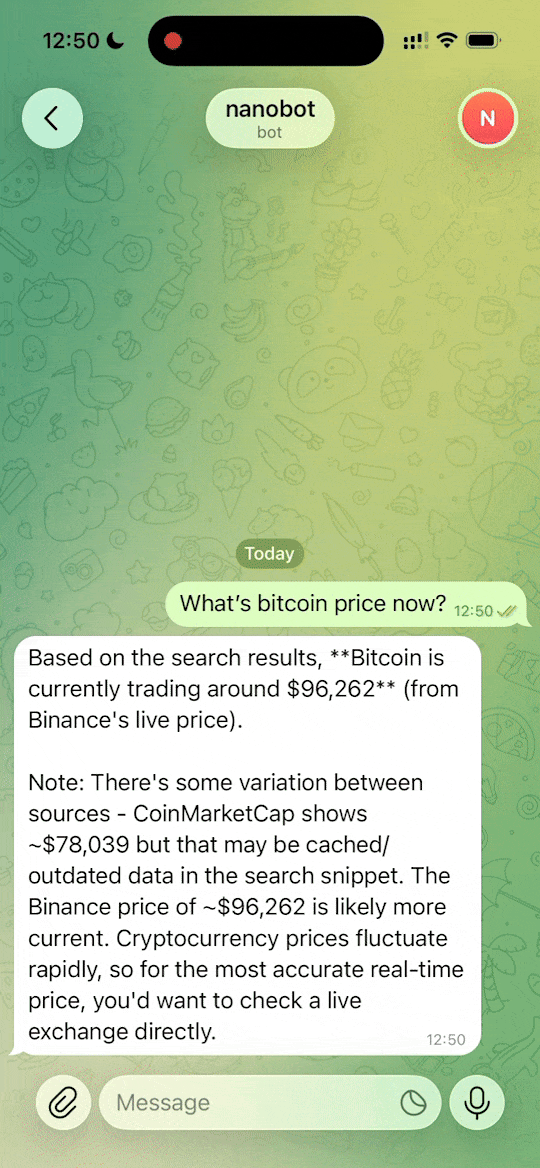
nanobot
nanobot 是一款受 OpenClaw 启发打造的超轻量级个人 AI 助手。它旨在解决现有 AI 代理框架代码冗余、部署复杂的问题,通过极致精简的架构,用比 OpenClaw 少 99% 的代码量实现了核心智能体功能,让运行更高效、维护更简单。
这款工具特别适合开发者和技术研究人员使用,尤其是那些希望快速搭建私有化 AI 助手、深入理解智能体底层逻辑,或需要在资源受限环境中部署应用的用户。普通用户若具备基础编程能力,也可通过其交互式向导轻松配置属于自己的 AI 伙伴。
nanobot 的技术亮点在于其“轻量化”与“高兼容性”。它不仅支持 OpenAI、Anthropic 等主流模型原生接入,还无缝集成了微信、飞书、Telegram、Slack 等多种通讯渠道,甚至支持端到端流式输出和媒体文件处理。近期更新中,项目团队移除了存在供应链风险的依赖库,进一步提升了安全性与稳定性。无论是用于日常任务自动化,还是作为学习 AI Agent 架构的教学案例,nanobot 都是一个简洁而强大的选择。
使用场景
某独立开发者希望为个人项目快速接入一个支持微信、飞书和 Telegram 的多渠道 AI 助手,用于自动处理用户反馈和定时任务通知。
没有 nanobot 时
- 代码臃肿难维护:参考类似 OpenClaw 的框架,需要理解和维护数千行核心代码,仅为了实现基础的消息路由功能。
- 环境安全隐患:依赖复杂的第三方库(如曾受供应链投毒影响的 litellm),需花费大量时间排查安全漏洞和版本冲突。
- 多渠道开发繁琐:为微信、飞书等不同平台分别编写适配层,处理媒体发送、流式响应和格式渲染的工作量巨大且易出错。
- 部署配置复杂:缺乏交互式引导,手动配置模型提供商、API 密钥和时区参数容易出错,启动门槛高。
使用 nanobot 后
- 极致轻量精简:nanobot 将核心代理功能压缩至原框架 1% 的代码量,开发者可瞬间读懂逻辑并按需修改,维护成本极低。
- 原生安全架构:nanobot 移除了高风险依赖,直接采用原生 OpenAI 和 Anthropic SDK,从根源上消除了供应链中毒风险。
- 全渠道一键打通:通过 nanobot 内置插件,无需额外编码即可在微信、飞书和 Telegram 间实现流式消息、代码块渲染及媒体文件的统一收发。
- 向导式极速启动:利用 nanobot 的交互式设置向导,几分钟内即可完成模型选择、密钥配置和多渠道登录,立即投入运行。
nanobot 以极致的轻量化和安全架构,让个人开发者能以最小代价构建生产级的多渠道 AI 助手。
运行环境要求
- Linux
- macOS
- Windows
未说明
未说明

快速开始

nanobot:超轻量级个人AI助手


🐈 nanobot 是一款受 OpenClaw 启发的 超轻量级 个人AI助手。
⚡️ 以比 OpenClaw 少 99% 的代码行数 实现核心代理功能。
📏 实时代码行数统计:随时运行 bash core_agent_lines.sh 进行核对。
📢 最新消息
[!重要] 安全提示: 由于
litellm供应链污染,请 尽快检查您的 Python 环境,并参考此 公告 获取详细信息。自 v0.1.4.post6 起,我们已完全移除litellm。
- 2026年3月27日 🚀 发布 v0.1.4.post6 — 架构解耦、移除 litellm、端到端流式传输、微信渠道及一项安全修复。详情请参阅 发布说明。
- 2026年3月26日 🏗️ 提取代理运行器并统一生命周期钩子;在边界处合并流式增量。
- 2026年3月25日 🌏 StepFun 提供商、可配置时区、Gemini 思考签名。
- 2026年3月24日 🔧 微信兼容性、飞书 CardKit 流式传输、测试套件重构。
- 2026年3月23日 🔧 针对插件、WhatsApp/微信媒体以及统一渠道登录 CLI 重新设计命令路由。
- 2026年3月22日 ⚡ 端到端流式传输、微信渠道、Anthropic 缓存优化以及
/status命令。 - 2026年3月21日 🔒 用原生
openai+anthropicSDK 替代litellm。详情请参阅 提交记录。 - 2026年3月20日 🧙 交互式设置向导——选择提供商、模型自动补全,即可开始使用。
- 2026年3月19日 💬 Telegram 在高负载下更加稳定;飞书现在能正确渲染代码块。
- 2026年3月18日 📷 Telegram 现可通过 URL 发送媒体文件。Cron 定时任务显示更易读的详细信息。
- 2026年3月17日 ✨ 飞书格式焕然一新,Slack 在完成时会有响应,自定义端点支持额外头信息,图像处理也更为可靠。
往期新闻
- 2026-03-16 🚀 发布了 v0.1.4.post5 — 一个以优化为重点的版本,提升了可靠性和渠道支持,让日常使用更加稳定。详情请参阅 发布说明。
- 2026-03-15 🧩 支持钉钉富媒体、内置技能更智能,模型兼容性更清晰。
- 2026-03-14 💬 渠道插件、飞书回复,以及更稳定的MCP、QQ和媒体处理。
- 2026-03-13 🌐 多提供商网络搜索、LangSmith集成,以及更广泛的可靠性改进。
- 2026-03-12 🚀 支持火山引擎、Telegram回复上下文、
/restart命令,以及更稳固的内存管理。 - 2026-03-11 🔌 支持企业微信、Ollama,发现功能更简洁,工具行为更安全。
- 2026-03-10 🧠 基于Token的内存管理、共享重试机制,以及网关和Telegram行为的优化。
- 2026-03-09 💬 Slack线程功能优化,飞书音频兼容性更好。
- 2026-03-08 🚀 发布了 v0.1.4.post4 — 一个注重可靠性的新版本,包含更安全的默认设置、更好的多实例支持、更稳健的MCP,以及对各大渠道和提供商的重大改进。详情请参阅 发布说明。
- 2026-03-07 🚀 支持Azure OpenAI提供商、WhatsApp媒体消息、QQ群聊,以及对Telegram和飞书的进一步优化。
- 2026-03-06 🪄 提供商模块更轻量、媒体处理更智能,内存管理和CLI兼容性更强。
- 2026-03-05 ⚡️ Telegram草稿流式传输、MCP SSE支持,以及更全面的渠道可靠性修复。
- 2026-03-04 🛠️ 依赖清理、更安全的文件读取,以及新一轮的测试和Cron任务修复。
- 2026-03-03 🧠 用户消息合并更干净、多模态数据保存更安全,Cron守护机制更强。
- 2026-03-02 🛡️ 默认访问控制更安全、Cron重新加载更稳定,Matrix媒体处理更整洁。
- 2026-03-01 🌐 支持Web代理、更智能的Cron提醒,以及飞书富文本解析的改进。
- 2026-02-28 🚀 发布了 v0.1.4.post3 — 上下文更清晰、会话历史更健壮,代理功能更智能。详情请参阅 发布说明。
- 2026-02-27 🧠 支持实验性思维模式、钉钉媒体消息,以及飞书和QQ渠道的修复。
- 2026-02-26 🛡️ 修复会话污染问题、WhatsApp去重、Windows路径保护,以及与Mistral的兼容性改进。
- 2026-02-25 🧹 新增Matrix频道、会话上下文更整洁,自动同步工作区模板。
- 2026-02-24 🚀 发布了 v0.1.4.post2 — 一个以可靠性为核心的版本,重新设计了心跳机制、优化了提示缓存,并增强了提供商和渠道的稳定性。详情请参阅 发布说明。
- 2026-02-23 🔧 虚拟工具调用心跳机制、提示缓存优化,以及Slack Markdown修复。
- 2026-02-22 🛡️ Slack线程隔离、Discord打字状态修复,以及代理可靠性提升。
- 2026-02-21 🎉 发布了 v0.1.4.post1 — 新增提供商、跨渠道媒体支持,以及重大稳定性改进。详情请参阅 发布说明。
- 2026-02-20 🐦 飞书现在可以接收用户发送的多模态文件。后台内存管理更可靠。
- 2026-02-19 ✨ Slack现在可以发送文件,Discord会自动分割长消息,子代理也可以在CLI模式下运行。
- 2026-02-18 ⚡️ nanobot现在支持火山引擎、MCP自定义认证头,以及Anthropic提示缓存。
- 2026-02-17 🎉 发布了 v0.1.4 — 支持MCP、进度流式传输、新增提供商,并对多个渠道进行了改进。详情请参阅 发布说明。
- 2026-02-16 🦞 nanobot现已集成ClawHub技能——可搜索并安装公开的代理技能。
- 2026-02-15 🔑 nanobot现支持OpenAI Codex提供商,并加入OAuth登录支持。
- 2026-02-14 🔌 nanobot现已支持MCP!详情请参阅MCP模型上下文协议。
- 2026-02-13 🎉 发布了 v0.1.3.post7 — 包含安全加固及多项改进。请升级至最新版本以解决安全问题。更多详情请参阅 发布说明。
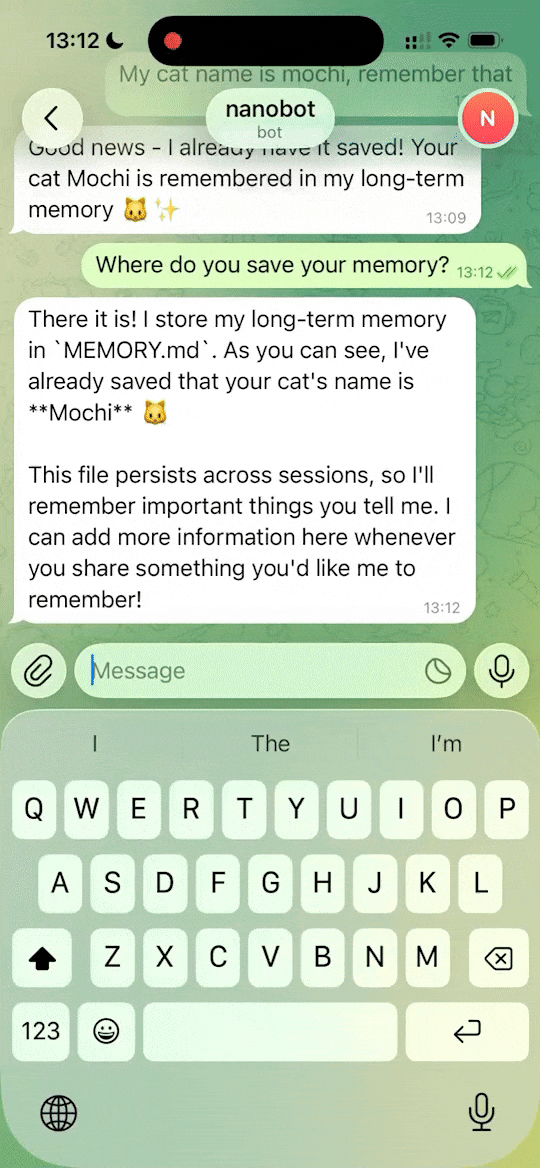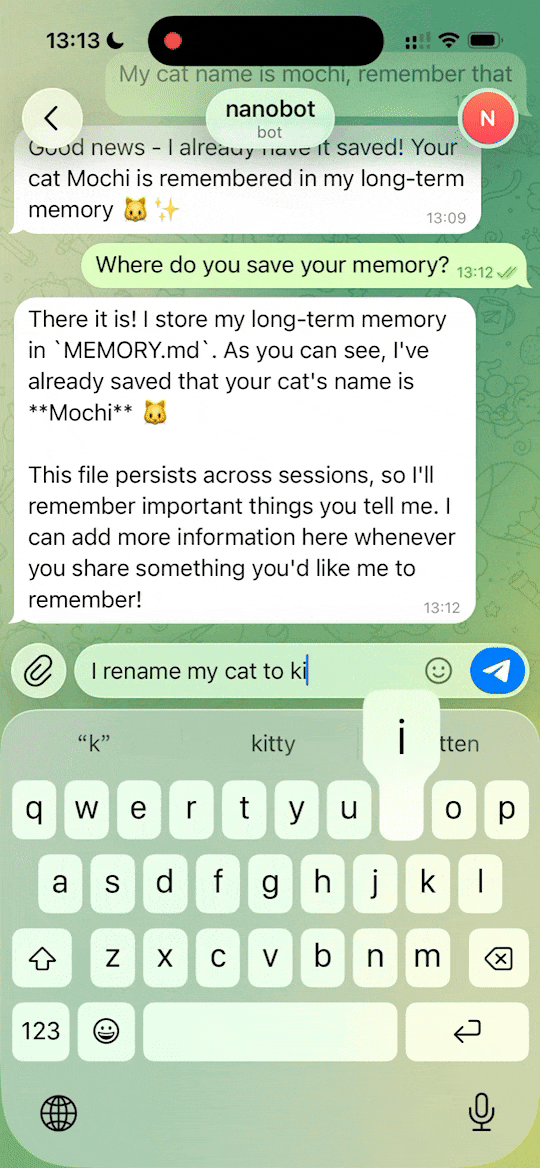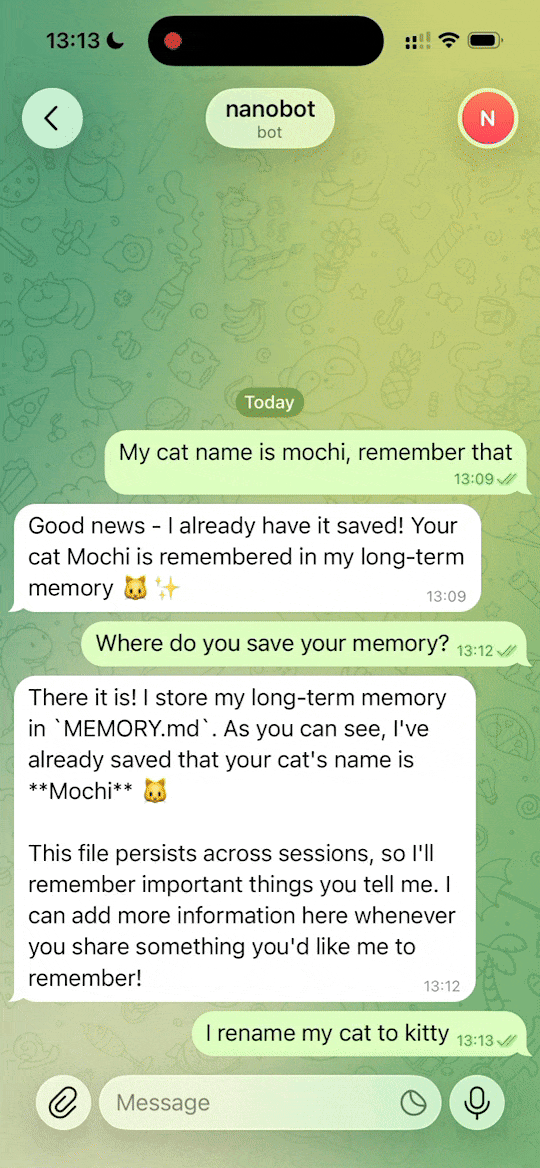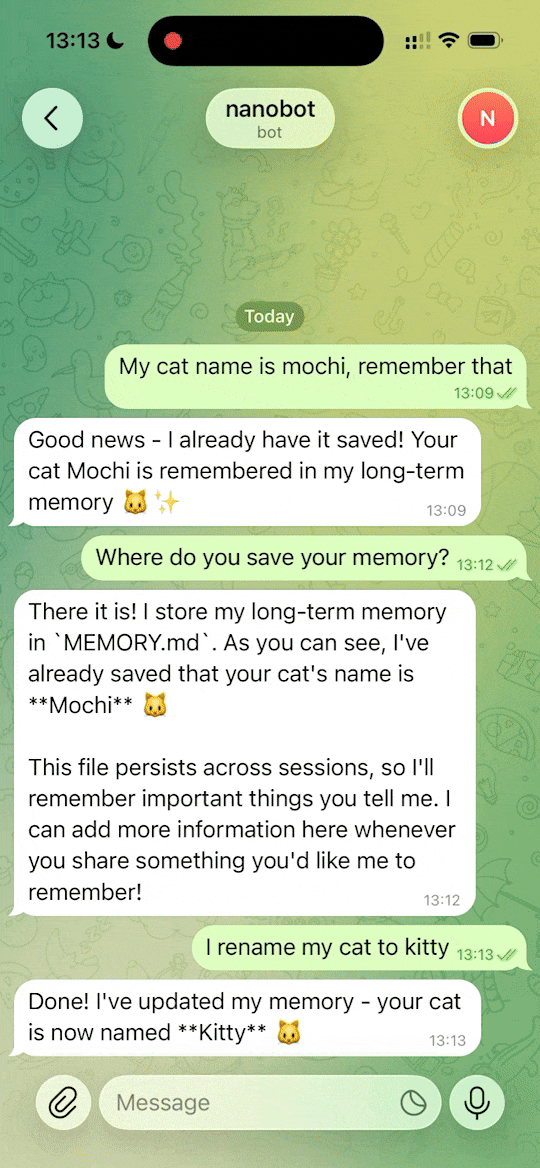
- 2026-02-12 🧠 重新设计了内存系统——代码更少,可靠性更高。欢迎参与关于此话题的 讨论!
- 2026-02-11 ✨ CLI体验增强,并新增MiniMax支持!
- 2026-02-10 🎉 发布了 v0.1.3.post6,包含多项改进!请查看更新 说明以及我们的 路线图。
- 2026-02-09 💬 新增Slack、Email和QQ支持——nanobot现已支持多个聊天平台!
- 2026-02-08 🔧 重构了提供商模块——现在只需简单两步即可添加新的LLM提供商!详情请见 这里。
- 2026-02-07 🚀 发布了 v0.1.3.post5,新增通义千问支持及多项关键改进!详情请参阅 这里。
- 2026-02-06 ✨ 新增Moonshot/Kimi提供商、Discord集成,并进一步强化了安全防护!
- 2026-02-05 ✨ 新增飞书频道、DeepSeek提供商,并增强了定时任务支持!
- 2026-02-04 🚀 发布了 v0.1.3.post4,支持多提供商和Docker!详情请参阅 这里。
- 2026-02-03 ⚡ 集成了vLLM,用于本地LLM支持,并改进了自然语言任务调度!
- 2026-02-02 🎉 nanobot正式上线!欢迎体验猫咪机器人!
🐈 nanobot仅用于教育、研究和技术交流目的。它与加密货币无关,不涉及任何官方代币或硬币。
nanobot的核心特性:
🪶 超轻量级:OpenClaw的极简实现——体积缩小99%,速度大幅提升。
🔬 科研友好:代码简洁易懂,便于理解、修改和扩展,适合科研使用。
⚡️ 极速响应:极小的资源占用意味着更快的启动速度、更低的资源消耗和更高效的迭代。
💎 易于使用:一键部署,即刻上手。
🏗️ 架构
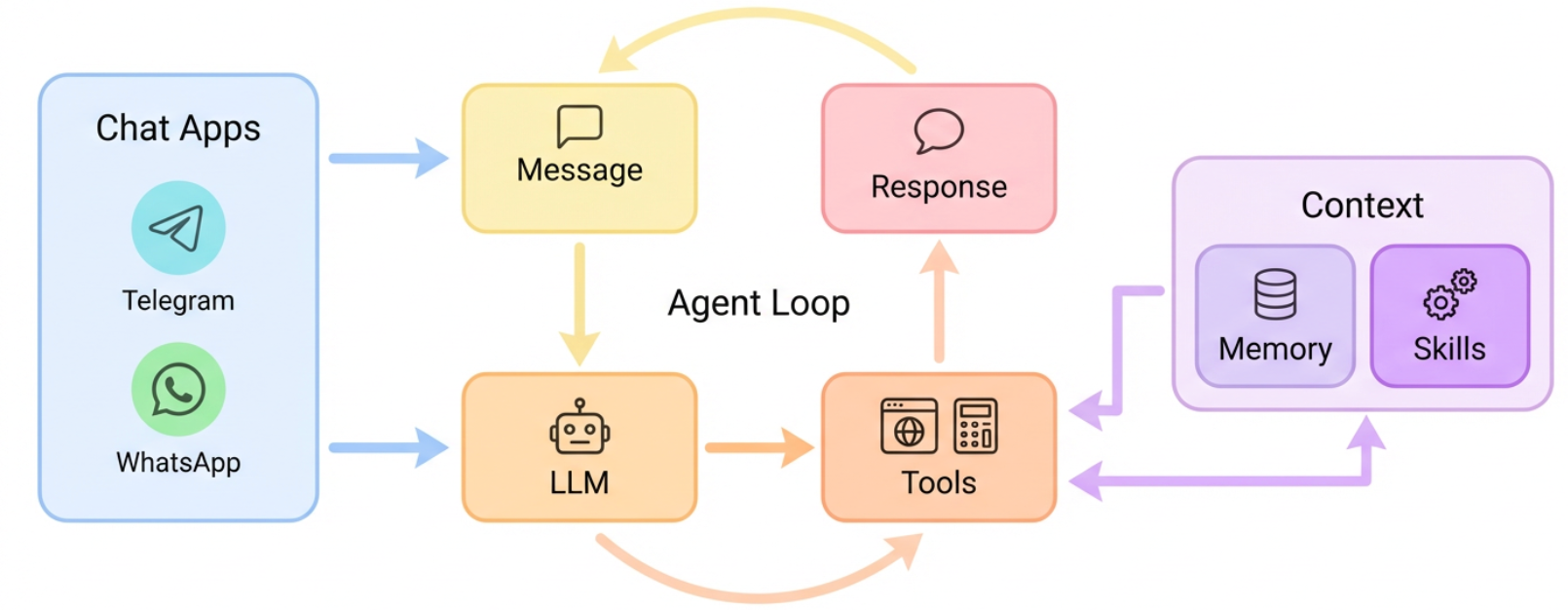
目录
- 新闻
- 核心特性
- 架构
- 功能
- 安装
- 快速入门
- 聊天应用
- 代理社交网络
- 配置
- 多实例
- CLI参考
- Python SDK
- OpenAI兼容API
- Docker
- Linux服务
- 项目结构
- 贡献与路线图
- 星标历史
✨ 功能
📈 全天候实时市场分析 |
🚀 全栈软件工程师 |
📅 智能日常事务管理器 |
📚 个人知识助手 |
|---|---|---|---|
|
|
|
|
| 发现 • 洞察 • 趋势 | 开发 • 部署 • 扩展 | 计划 • 自动化 • 整理 | 学习 • 记忆 • 推理 |


📦 安装
从源码安装(最新功能,推荐用于开发)
git clone https://github.com/HKUDS/nanobot.git
cd nanobot
pip install -e .
使用 uv 安装(稳定、快速)
uv tool install nanobot-ai
从 PyPI 安装(稳定)
pip install nanobot-ai
更新到最新版本
PyPI / pip
pip install -U nanobot-ai
nanobot --version
uv
uv tool upgrade nanobot-ai
nanobot --version
使用 WhatsApp 吗? 升级后请重建本地桥接:
rm -rf ~/.nanobot/bridge
nanobot channels login whatsapp
🚀 快速入门
[!TIP] 请在
~/.nanobot/config.json中设置您的 API 密钥。 获取 API 密钥:OpenRouter(全球)如需其他 LLM 提供商,请参阅【提供商】部分。
如需设置网络搜索功能,请参阅【网络搜索】部分。
1. 初始化
nanobot onboard
如果您希望使用交互式设置向导,可以使用 nanobot onboard --wizard。
2. 配置(~/.nanobot/config.json)
在配置文件中需设置以下 两部分(其他选项已有默认值)。
设置您的 API 密钥(例如 OpenRouter,推荐给全球用户):
{
"providers": {
"openrouter": {
"apiKey": "sk-or-v1-xxx"
}
}
}
设置您的模型(可选择固定某个提供商 — 默认为自动检测):
{
"agents": {
"defaults": {
"model": "anthropic/claude-opus-4-5",
"provider": "openrouter"
}
}
}
3. 聊天
nanobot agent
就是这样!您只需 2 分钟即可拥有一个可用的 AI 助手。
💬 聊天应用
将 nanobot 连接到您最喜欢的聊天平台。想自己搭建吗?请参阅频道插件指南。
| 频道 | 所需信息 |
|---|---|
| Telegram | 来自 @BotFather 的机器人令牌 |
| Discord | 机器人令牌 + 消息内容权限 |
扫描二维码(nanobot channels login whatsapp) |
|
| WeChat (微信) | 扫描二维码(nanobot channels login weixin) |
| 飞书 | 应用程序 ID + 应用程序密钥 |
| 钉钉 | 应用程序 Key + 应用程序 Secret |
| Slack | 机器人令牌 + 应用级别令牌 |
| Matrix | 宿主服务器 URL + 访问令牌 |
| 电子邮件 | IMAP/SMTP 凭证 |
| 应用程序 ID + 应用程序密钥 | |
| 企业微信 | 机器人 ID + 机器人密钥 |
| Mochat | Claw 令牌(支持自动配置) |
Telegram(推荐)
1. 创建机器人
- 打开 Telegram,搜索
@BotFather - 发送
/newbot,按照提示操作 - 复制令牌
2. 配置
{
"channels": {
"telegram": {
"enabled": true,
"token": "YOUR_BOT_TOKEN",
"allowFrom": ["YOUR_USER_ID"]
}
}
}
您可以在 Telegram 设置中找到您的 用户 ID,显示为
@yourUserId。 请复制此值 不带@符号,并粘贴到配置文件中。
3. 运行
nanobot gateway
Mochat(Claw IM)
默认使用 Socket.IO WebSocket,并回退到 HTTP 轮询。
1. 让 nanobot 为您设置 Mochat
只需向 nanobot 发送以下消息(将 xxx@xxx 替换为您的真实邮箱):
阅读 https://raw.githubusercontent.com/HKUDS/MoChat/refs/heads/main/skills/nanobot/skill.md,并在 MoChat 上注册。我的邮箱是 xxx@xxx,请将我绑定为您的所有者,并通过 MoChat 私信联系我。
nanobot 将自动注册、配置 ~/.nanobot/config.json,并连接到 Mochat。
2. 重启网关
nanobot gateway
就这样——剩下的就由 nanobot 自动处理了!
手动配置(高级)
如果您更倾向于手动配置,请将以下内容添加到 ~/.nanobot/config.json:
请务必保密
claw_token。它应仅通过X-Claw-Token头发送到您的 Mochat API 端点。
{
"channels": {
"mochat": {
"enabled": true,
"base_url": "https://mochat.io",
"socket_url": "https://mochat.io",
"socket_path": "/socket.io",
"claw_token": "claw_xxx",
"agent_user_id": "6982abcdef",
"sessions": ["*"],
"panels": ["*"],
"reply_delay_mode": "non-mention",
"reply_delay_ms": 120000
}
}
}
Discord
1. 创建机器人
- 访问 https://discord.com/developers/applications
- 创建应用程序 → 机器人 → 添加机器人
- 复制机器人令牌
2. 启用权限
- 在机器人设置中,启用 MESSAGE CONTENT INTENT
- (可选)如果您计划根据成员数据使用允许列表,也可启用 SERVER MEMBERS INTENT
3. 获取您的用户 ID
- Discord 设置 → 高级 → 启用 开发者模式
- 右键单击您的头像 → 复制用户 ID
4. 配置
{
"channels": {
"discord": {
"enabled": true,
"token": "YOUR_BOT_TOKEN",
"allowFrom": ["YOUR_USER_ID"],
"groupPolicy": "mention"
}
}
}
groupPolicy控制机器人在群组频道中的响应方式:
"mention"(默认)— 仅在被提及时回复"open"— 回复所有消息 私信始终会在发信人位于allowFrom列表中时回复。- 如果您将群组策略设置为 open,请创建新线程作为私有线程,然后@机器人进入该线程。否则,线程本身以及您发起它的频道都会启动一个机器人会话。
5. 邀请机器人
- OAuth2 → URL 生成器
- 范围:
bot - 机器人权限:
发送消息、读取消息历史 - 打开生成的邀请链接,将机器人添加到您的服务器
6. 运行
nanobot gateway
Matrix(Element)
首先安装 Matrix 的依赖项:
pip install nanobot-ai[matrix]
1. 创建或选择一个 Matrix 账户
- 在您的宿主服务器上创建或重复使用一个 Matrix 账户(例如
matrix.org)。 - 确认您可以使用 Element 登录。
2. 获取凭证
- 您需要:
userId(示例:@nanobot:matrix.org)accessTokendeviceId(建议使用,以便在重启后恢复同步令牌)
- 您可以从您的宿主服务器登录 API(
/_matrix/client/v3/login)或从客户端的高级会话设置中获取这些信息。
3. 配置
{
"channels": {
"matrix": {
"enabled": true,
"homeserver": "https://matrix.org",
"userId": "@nanobot:matrix.org",
"accessToken": "syt_xxx",
"deviceId": "NANOBOT01",
"e2eeEnabled": true,
"allowFrom": ["@your_user:matrix.org"],
"groupPolicy": "open",
"groupAllowFrom": [],
"allowRoomMentions": false,
"maxMediaBytes": 20971520
}
}
}
请保持持久化的
matrix-store和稳定的deviceId——如果这些在重启时发生变化,加密会话状态就会丢失。
| 选项 | 描述 |
|---|---|
allowFrom |
允许互动的用户 ID。为空则拒绝所有人;使用 ["*"] 允许所有人。 |
groupPolicy |
open(默认)、mention 或 allowlist。 |
groupAllowFrom |
房间允许列表(当策略为 allowlist 时使用)。 |
allowRoomMentions |
在提及模式下接受 @room 提及。 |
e2eeEnabled |
E2EE 支持(默认为 true)。设置为 false 以仅使用明文。 |
maxMediaBytes |
最大附件大小(默认为 20MB)。设置为 0 以阻止所有媒体。 |
4. 运行
nanobot gateway
需要 Node.js ≥18。
1. 链接设备
nanobot channels login whatsapp
# 使用 WhatsApp 扫描 QR 码 → 设置 → 已链接设备
2. 配置
{
"channels": {
"whatsapp": {
"enabled": true,
"allowFrom": ["+1234567890"]
}
}
}
3. 运行(两个终端)
# 终端 1
nanobot channels login whatsapp
# 终端 2
nanobot gateway
对于现有安装,WhatsApp 桥接更新不会自动应用。 升级 nanobot 后,请通过以下命令重建本地桥接:
rm -rf ~/.nanobot/bridge && nanobot channels login whatsapp
飞书
使用 WebSocket 长连接——无需公网 IP。
1. 创建飞书机器人
- 访问 飞书开放平台
- 创建新应用 → 启用 Bot 能力
- 权限:
im:message(发送消息)和im:message.p2p_msg:readonly(接收消息)- 流式回复(nanobot 默认启用):添加
cardkit:card:write(在飞书开发者控制台中通常标记为 创建与更新卡片)。这是 CardKit 实体和流式助手文本所必需的。较旧的应用可能尚未具备此权限——请打开 权限管理,启用该范围,然后如果控制台要求,再 发布 新的应用版本。 - 如果你 无法 添加
cardkit:card:write,则在channels.feishu下将"streaming": false。机器人仍然可以工作;回复将使用普通的交互式卡片,而不进行逐 token 的流式传输。
- 事件:添加
im.message.receive_v1(接收消息)- 选择 长连接 模式(需要先运行 nanobot 建立连接)
- 从“凭证与基本信息”中获取 App ID 和 App Secret
- 发布应用
2. 配置
{
"channels": {
"feishu": {
"enabled": true,
"appId": "cli_xxx",
"appSecret": "xxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": ["ou_YOUR_OPEN_ID"],
"groupPolicy": "mention",
"streaming": true
}
}
}
streaming默认为true。如果你的应用没有cardkit:card:write权限(见上文权限说明),则使用false。encryptKey和verificationToken在长连接模式下是可选的。allowFrom:添加你的 open_id(可在你向机器人发送消息时的 nanobot 日志中找到)。使用["*"]可允许所有用户。groupPolicy:“mention”(默认——仅在被提及时回复)、“open”(回复所有群聊消息)。私聊始终会回复。
3. 运行
nanobot gateway
[!TIP] 飞书使用 WebSocket 接收消息——无需 Webhook 或公网 IP!
QQ(QQ单聊)
使用 botpy SDK 结合 WebSocket——无需公网 IP。目前仅支持 私人消息。
1. 注册并创建机器人
- 访问 QQ开放平台 → 注册成为开发者(个人或企业)
- 创建新的机器人应用
- 进入 开发设置 → 复制 AppID 和 AppSecret
2. 设置沙盒用于测试
- 在机器人管理控制台中,找到 沙箱配置
- 在 在消息列表配置 下,点击 添加成员 并添加你自己的 QQ 号码
- 添加成功后,用手机 QQ 扫描机器人的二维码→打开机器人资料页→点击“发消息”即可开始聊天。
3. 配置
allowFrom:添加你的 openid(可在你向机器人发送消息时的 nanobot 日志中找到)。使用["*"]可公开访问。msgFormat:可选。使用"plain"(默认)以获得与旧版 QQ 客户端的最大兼容性,或使用"markdown"以在较新客户端上实现更丰富的格式。- 生产环境:在机器人控制台提交审核并发布。完整发布流程请参阅 QQ Bot 文档。
{
"channels": {
"qq": {
"enabled": true,
"appId": "YOUR_APP_ID",
"secret": "YOUR_APP_SECRET",
"allowFrom": ["YOUR_OPENID"],
"msgFormat": "plain"
}
}
}
4. 运行
nanobot gateway
现在你可以从 QQ 向机器人发送消息——它应该会回复!
钉钉
使用 流模式——无需公网 IP。
1. 创建钉钉机器人
- 访问 钉钉开放平台
- 创建新应用 → 添加 Robot 能力
- 配置:
- 开启 流模式
- 权限:添加发送消息所需的必要权限
- 从“凭证”中获取 AppKey(Client ID)和 AppSecret(Client Secret)
- 发布应用
2. 配置
{
"channels": {
"dingtalk": {
"enabled": true,
"clientId": "YOUR_APP_KEY",
"clientSecret": "YOUR_APP_SECRET",
"allowFrom": ["YOUR_STAFF_ID"]
}
}
}
allowFrom:添加你的员工 ID。使用["*"]可允许所有用户。
3. 运行
nanobot gateway
Slack
使用 Socket 模式——无需公共 URL。
1. 创建 Slack 应用
- 访问 Slack API → 创建新应用 → “从头开始”
- 选择一个名称并选定你的工作区
2. 配置应用
- Socket 模式:开启 → 生成具有
connections:write范围的 应用级令牌 → 复制该令牌(xapp-...) - OAuth 与权限:添加机器人权限:
chat:write、reactions:write、app_mentions:read - 事件订阅:开启 → 订阅机器人事件:
message.im、message.channels、app_mention→ 保存更改 - App Home:滚动到 显示选项卡 → 启用 消息选项卡 → 勾选 “允许用户从消息选项卡发送 Slash 命令和消息”
- 安装应用:点击 安装到工作区 → 授权 → 复制 机器人令牌(
xoxb-...)
3. 配置 nanobot
{
"channels": {
"slack": {
"enabled": true,
"botToken": "xoxb-...",
"appToken": "xapp-...",
"allowFrom": ["YOUR_SLACK_USER_ID"],
"groupPolicy": "mention"
}
}
}
4. 运行
nanobot gateway
直接给机器人发私信,或在频道中@提及它——它应该会回复!
[!TIP]
groupPolicy:“mention”(默认——仅在被提及时回复)、“open”(回复所有频道消息),或“allowlist”(限制于特定频道)。- 私信政策默认为开放。若要禁用私信,可设置
"dm": {"enabled": false}。
电子邮件
为 nanobot 准备一个独立的邮箱账号。它通过 IMAP 轮询收件箱,并通过 SMTP 回复邮件——就像一位私人邮件助理一样。
1. 获取凭据(以 Gmail 为例)
- 为你的机器人创建一个专用的 Gmail 账号(例如
my-nanobot@gmail.com) - 启用两步验证 → 创建一个 应用密码
- 使用此应用密码同时进行 IMAP 和 SMTP 操作
2. 配置
consentGranted必须为true才能允许访问邮箱。这是一个安全机制——将其设为false可完全禁用。allowFrom:添加你的邮箱地址。使用["*"]可接受来自任何人的邮件。smtpUseTls和smtpUseSsl分别默认为true和false,这对 Gmail(端口 587 + STARTTLS)来说是正确的,无需显式设置。- 如果你只想读取/分析邮件而不想自动回复,则可将
"autoReplyEnabled": false。
{
"channels": {
"email": {
"enabled": true,
"consentGranted": true,
"imapHost": "imap.gmail.com",
"imapPort": 993,
"imapUsername": "my-nanobot@gmail.com",
"imapPassword": "your-app-password",
"smtpHost": "smtp.gmail.com",
"smtpPort": 587,
"smtpUsername": "my-nanobot@gmail.com",
"smtpPassword": "your-app-password",
"fromAddress": "my-nanobot@gmail.com",
"allowFrom": ["your-real-email@gmail.com"]
}
}
}
3. 运行
nanobot gateway
微信 (WeChat / Weixin)
使用 ilinkai 个人微信 API,通过二维码登录实现 HTTP 长轮询。无需本地安装微信桌面客户端。
1. 安装支持微信的版本
pip install "nanobot-ai[weixin]"
2. 配置
{
"channels": {
"weixin": {
"enabled": true,
"allowFrom": ["YOUR_WECHAT_USER_ID"]
}
}
}
allowFrom: 添加你在 nanobot 日志中看到的微信账号发送者 ID。使用["*"]可允许所有用户。token: 可选。若省略,则需交互式登录,nanobot 会为你保存 token。routeTag: 可选。当你的上游微信部署需要请求路由时,nanobot 会将其作为SKRouteTag头发送。stateDir: 可选。默认为 nanobot 的运行目录,用于存储微信状态。pollTimeout: 可选,长轮询超时时间(单位:秒)。
3. 登录
nanobot channels login weixin
使用 --force 强制重新认证,并忽略已保存的 token:
nanobot channels login weixin --force
4. 运行
nanobot gateway
企业微信 (Wecom)
我们这里使用 wecom-aibot-sdk-python(社区版 Python SDK,对应官方 @wecom/aibot-node-sdk)。
使用 WebSocket 长连接——无需公网 IP。
1. 安装可选依赖
pip install nanobot-ai[wecom]
2. 创建企业微信 AI 机器人
前往企业微信管理后台 → 智能机器人 → 创建机器人 → 选择 API 模式 并启用 长连接。复制机器人 ID 和密钥。
3. 配置
{
"channels": {
"wecom": {
"enabled": true,
"botId": "your_bot_id",
"secret": "your_bot_secret",
"allowFrom": ["your_id"]
}
}
}
4. 运行
nanobot gateway
🌐 代理社交网络
🐈 nanobot 能够接入代理社交网络(代理社区)。只需发送一条消息,你的 nanobot 就会自动加入!
| 平台 | 如何加入(向你的机器人发送此消息) |
|---|---|
| Moltbook | 阅读 https://moltbook.com/skill.md 并按照说明加入 Moltbook |
| ClawdChat | 阅读 https://clawdchat.ai/skill.md 并按照说明加入 ClawdChat |
只需通过 CLI 或任何聊天渠道将上述命令发送给你的 nanobot,剩下的步骤它会自动完成。
⚙️ 配置
配置文件:~/.nanobot/config.json
Providers
[!TIP]
- Groq provides free voice transcription via Whisper. If configured, Telegram voice messages will be automatically transcribed.
- MiniMax Coding Plan: Exclusive discount links for the nanobot community: Overseas · Mainland China
- MiniMax (Mainland China): If your API key is from MiniMax's mainland China platform (minimaxi.com), set
"apiBase": "https://api.minimaxi.com/v1"in your minimax provider config.- VolcEngine / BytePlus Coding Plan: Use dedicated providers
volcengineCodingPlanorbyteplusCodingPlaninstead of the pay-per-usevolcengine/byteplusproviders.- Zhipu Coding Plan: If you're on Zhipu's coding plan, set
"apiBase": "https://open.bigmodel.cn/api/coding/paas/v4"in your zhipu provider config.- Alibaba Cloud BaiLian: If you're using Alibaba Cloud BaiLian's OpenAI-compatible endpoint, set
"apiBase": "https://dashscope.aliyuncs.com/compatible-mode/v1"in your dashscope provider config.- Step Fun (Mainland China): If your API key is from Step Fun's mainland China platform (stepfun.com), set
"apiBase": "https://api.stepfun.com/v1"in your stepfun provider config.
| Provider | Purpose | Get API Key |
|---|---|---|
custom |
Any OpenAI-compatible endpoint | — |
openrouter |
LLM (recommended, access to all models) | openrouter.ai |
volcengine |
LLM (VolcEngine, pay-per-use) | Coding Plan · volcengine.com |
byteplus |
LLM (VolcEngine international, pay-per-use) | Coding Plan · byteplus.com |
anthropic |
LLM (Claude direct) | console.anthropic.com |
azure_openai |
LLM (Azure OpenAI) | portal.azure.com |
openai |
LLM (GPT direct) | platform.openai.com |
deepseek |
LLM (DeepSeek direct) | platform.deepseek.com |
groq |
LLM + Voice transcription (Whisper) | console.groq.com |
minimax |
LLM (MiniMax direct) | platform.minimaxi.com |
gemini |
LLM (Gemini direct) | aistudio.google.com |
aihubmix |
LLM (API gateway, access to all models) | aihubmix.com |
siliconflow |
LLM (SiliconFlow/硅基流动) | siliconflow.cn |
dashscope |
LLM (Qwen) | dashscope.console.aliyun.com |
moonshot |
LLM (Moonshot/Kimi) | platform.moonshot.cn |
zhipu |
LLM (Zhipu GLM) | open.bigmodel.cn |
ollama |
LLM (local, Ollama) | — |
mistral |
LLM | docs.mistral.ai |
stepfun |
LLM (Step Fun/阶跃星辰) | platform.stepfun.com |
ovms |
LLM (local, OpenVINO Model Server) | docs.openvino.ai |
vllm |
LLM (local, any OpenAI-compatible server) | — |
openai_codex |
LLM (Codex, OAuth) | nanobot provider login openai-codex |
github_copilot |
LLM (GitHub Copilot, OAuth) | nanobot provider login github-copilot |
OpenAI Codex (OAuth)
Codex uses OAuth instead of API keys. Requires a ChatGPT Plus or Pro account.
No providers.openaiCodex block is needed in config.json; nanobot provider login stores the OAuth session outside config.
1. Login:
nanobot provider login openai-codex
2. Set model (merge into ~/.nanobot/config.json):
{
"agents": {
"defaults": {
"model": "openai-codex/gpt-5.1-codex"
}
}
}
3. Chat:
nanobot agent -m "Hello!"
# Target a specific workspace/config locally
nanobot agent -c ~/.nanobot-telegram/config.json -m "Hello!"
# One-off workspace override on top of that config
nanobot agent -c ~/.nanobot-telegram/config.json -w /tmp/nanobot-telegram-test -m "Hello!"
Docker users: use
docker run -itfor interactive OAuth login.
GitHub Copilot (OAuth)
GitHub Copilot uses OAuth instead of API keys. Requires a GitHub account with a plan configured.
No providers.githubCopilot block is needed in config.json; nanobot provider login stores the OAuth session outside config.
1. Login:
nanobot provider login github-copilot
2. Set model (merge into ~/.nanobot/config.json):
{
"agents": {
"defaults": {
"model": "github-copilot/gpt-4.1"
}
}
}
3. Chat:
nanobot agent -m "Hello!"
# Target a specific workspace/config locally
nanobot agent -c ~/.nanobot-telegram/config.json -m "Hello!"
# One-off workspace override on top of that config
nanobot agent -c ~/.nanobot-telegram/config.json -w /tmp/nanobot-telegram-test -m "Hello!"
Docker users: use
docker run -itfor interactive OAuth login.
Custom Provider (Any OpenAI-compatible API)
Connects directly to any OpenAI-compatible endpoint — LM Studio, llama.cpp, Together AI, Fireworks, Azure OpenAI, or any self-hosted server. Model name is passed as-is.
{
"providers": {
"custom": {
"apiKey": "your-api-key",
"apiBase": "https://api.your-provider.com/v1"
}
},
"agents": {
"defaults": {
"model": "your-model-name"
}
}
}
For local servers that don't require a key, set
apiKeyto any non-empty string (e.g."no-key").
Ollama (local)
Run a local model with Ollama, then add to config:
1. Start Ollama (example):
ollama run llama3.2
2. Add to config (partial — merge into ~/.nanobot/config.json):
{
"providers": {
"ollama": {
"apiBase": "http://localhost:11434"
}
},
"agents": {
"defaults": {
"provider": "ollama",
"model": "llama3.2"
}
}
}
provider: "auto"also works whenproviders.ollama.apiBaseis configured, but setting"provider": "ollama"is the clearest option.
OpenVINO Model Server (local / OpenAI-compatible)
Run LLMs locally on Intel GPUs using OpenVINO Model Server. OVMS exposes an OpenAI-compatible API at /v3.
Requires Docker and an Intel GPU with driver access (
/dev/dri).
1. Pull the model (example):
mkdir -p ov/models && cd ov
docker run -d \
--rm \
--user $(id -u):$(id -g) \
-v $(pwd)/models:/models \
openvino/model_server:latest-gpu \
--pull \
--model_name openai/gpt-oss-20b \
--model_repository_path /models \
--source_model OpenVINO/gpt-oss-20b-int4-ov \
--task text_generation \
--tool_parser gptoss \
--reasoning_parser gptoss \
--enable_prefix_caching true \
--target_device GPU
This downloads the model weights. Wait for the container to finish before proceeding.
2. Start the server (example):
docker run -d \
--rm \
--name ovms \
--user $(id -u):$(id -g) \
-p 8000:8000 \
-v $(pwd)/models:/models \
--device /dev/dri \
--group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) \
openvino/model_server:latest-gpu \
--rest_port 8000 \
--model_name openai/gpt-oss-20b \
--model_repository_path /models \
--source_model OpenVINO/gpt-oss-20b-int4-ov \
--task text_generation \
--tool_parser gptoss \
--reasoning_parser gptoss \
--enable_prefix_caching true \
--target_device GPU
3. Add to config (partial — merge into ~/.nanobot/config.json):
{
"providers": {
"ovms": {
"apiBase": "http://localhost:8000/v3"
}
},
"agents": {
"defaults": {
"provider": "ovms",
"model": "openai/gpt-oss-20b"
}
}
}
OVMS is a local server — no API key required. Supports tool calling (
--tool_parser gptoss), reasoning (--reasoning_parser gptoss), and streaming. See the official OVMS docs for more details.
vLLM (local / OpenAI-compatible)
Run your own model with vLLM or any OpenAI-compatible server, then add to config:
1. Start the server (example):
vllm serve meta-llama/Llama-3.1-8B-Instruct --port 8000
2. Add to config (partial — merge into ~/.nanobot/config.json):
Provider (key can be any non-empty string for local):
{
"providers": {
"vllm": {
"apiKey": "dummy",
"apiBase": "http://localhost:8000/v1"
}
}
}
Model:
{
"agents": {
"defaults": {
"model": "meta-llama/Llama-3.1-8B-Instruct"
}
}
}
Adding a New Provider (Developer Guide)
nanobot uses a Provider Registry (nanobot/providers/registry.py) as the single source of truth.
Adding a new provider only takes 2 steps — no if-elif chains to touch.
Step 1. Add a ProviderSpec entry to PROVIDERS in nanobot/providers/registry.py:
ProviderSpec(
name="myprovider", # config field name
keywords=("myprovider", "mymodel"), # model-name keywords for auto-matching
env_key="MYPROVIDER_API_KEY", # env var name
display_name="My Provider", # shown in `nanobot status`
default_api_base="https://api.myprovider.com/v1", # OpenAI-compatible endpoint
)
Step 2. Add a field to ProvidersConfig in nanobot/config/schema.py:
class ProvidersConfig(BaseModel):
...
myprovider: ProviderConfig = ProviderConfig()
That's it! Environment variables, model routing, config matching, and nanobot status display will all work automatically.
Common ProviderSpec options:
| Field | Description | Example |
|---|---|---|
default_api_base |
OpenAI-compatible base URL | "https://api.deepseek.com" |
env_extras |
Additional env vars to set | (("ZHIPUAI_API_KEY", "{api_key}"),) |
model_overrides |
Per-model parameter overrides | (("kimi-k2.5", {"temperature": 1.0}),) |
is_gateway |
Can route any model (like OpenRouter) | True |
detect_by_key_prefix |
Detect gateway by API key prefix | "sk-or-" |
detect_by_base_keyword |
Detect gateway by API base URL | "openrouter" |
strip_model_prefix |
Strip provider prefix before sending to gateway | True (for AiHubMix) |
supports_max_completion_tokens |
Use max_completion_tokens instead of max_tokens; required for providers that reject both being set simultaneously (e.g. VolcEngine) |
True |
频道设置
适用于所有频道的全局设置。可在 ~/.nanobot/config.json 文件中的 channels 部分进行配置:
{
"channels": {
"sendProgress": true,
"sendToolHints": false,
"sendMaxRetries": 3,
"telegram": { ... }
}
}
| 设置 | 默认值 | 描述 |
|---|---|---|
sendProgress |
true |
将代理的文本处理进度流式传输到频道 |
sendToolHints |
false |
流式传输工具调用提示(例如 read_file("…")) |
sendMaxRetries |
3 |
每条出站消息的最大投递尝试次数,包括首次发送(可配置范围为 0–10,实际最少尝试 1 次) |
重试行为
当频道发送操作引发错误时,nanobot 会以指数退避方式重试:
- 第 1 次:初始发送
- 第 2–4 次:重试延迟分别为 1 秒、2 秒、4 秒
- 第 5 次及以上:重试延迟上限为 4 秒
- 临时性失败(网络波动、临时 API 限制):通常重试会成功
- 永久性失败(无效令牌、频道被封禁):所有重试均会失败
[!NOTE] 当某个频道完全不可用时,由于无法通过该频道联系用户,因此无法向用户发出通知。请监控日志中“尝试 N 次后仍无法发送至 {channel}”的信息,以检测持续的投递失败。
网络搜索
[!TIP] 使用
tools.web中的proxy可将所有网络请求(搜索 + 获取)通过代理路由:{ "tools": { "web": { "proxy": "http://127.0.0.1:7890" } } }
nanobot 支持多种网络搜索引擎提供商。可在 ~/.nanobot/config.json 文件的 tools.web.search 部分进行配置。
| 提供商 | 配置字段 | 环境变量回退 | 免费 |
|---|---|---|---|
brave(默认) |
apiKey |
BRAVE_API_KEY |
否 |
tavily |
apiKey |
TAVILY_API_KEY |
否 |
jina |
apiKey |
JINA_API_KEY |
免费层级(10M 个 token) |
searxng |
baseUrl |
SEARXNG_BASE_URL |
是(自托管) |
duckduckgo |
— | — | 是 |
当凭据缺失时,nanobot 会自动回退到 DuckDuckGo。
Brave(默认):
{
"tools": {
"web": {
"search": {
"provider": "brave",
"apiKey": "BSA..."
}
}
}
}
Tavily:
{
"tools": {
"web": {
"search": {
"provider": "tavily",
"apiKey": "tvly-..."
}
}
}
}
Jina(免费层级,10M 个 token):
{
"tools": {
"web": {
"search": {
"provider": "jina",
"apiKey": "jina_..."
}
}
}
}
SearXNG(自托管,无需 API 密钥):
{
"tools": {
"web": {
"search": {
"provider": "searxng",
"baseUrl": "https://searx.example"
}
}
}
}
DuckDuckGo(零配置):
{
"tools": {
"web": {
"search": {
"provider": "duckduckgo"
}
}
}
}
| 选项 | 类型 | 默认值 | 描述 |
|---|---|---|---|
provider |
字符串 | "brave" |
搜索后端:brave、tavily、jina、searxng、duckduckgo |
apiKey |
字符串 | "" |
Brave 或 Tavily 的 API 密钥 |
baseUrl |
字符串 | "" |
SearXNG 的基础 URL |
maxResults |
整数 | 5 |
每次搜索返回的结果数量(1–10) |
MCP(模型上下文协议)
[!TIP] 该配置格式与 Claude Desktop / Cursor 兼容。您可以直接从任何 MCP 服务器的 README 中复制 MCP 服务器配置。
nanobot 支持 MCP — 连接外部工具服务器,并将其用作原生代理工具。
将 MCP 服务器添加到您的 config.json 文件中:
{
"tools": {
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/dir"]
},
"my-remote-mcp": {
"url": "https://example.com/mcp/",
"headers": {
"Authorization": "Bearer xxxxx"
}
}
}
}
}
支持两种传输模式:
| 模式 | 配置 | 示例 |
|---|---|---|
| Stdio | command + args |
通过 npx / uvx 运行本地进程 |
| HTTP | url + headers(可选) |
远程端点(https://mcp.example.com/sse) |
使用 toolTimeout 可覆盖默认的每调用 30 秒超时时间,以适应慢速服务器:
{
"tools": {
"mcpServers": {
"my-slow-server": {
"url": "https://example.com/mcp/",
"toolTimeout": 120
}
}
}
}
使用 enabledTools 可仅注册 MCP 服务器中的部分工具:
{
"tools": {
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/dir"],
"enabledTools": ["read_file", "mcp_filesystem_write_file"]
}
}
}
}
enabledTools 接受原始 MCP 工具名称(例如 read_file)或封装后的 nanobot 工具名称(例如 mcp_filesystem_write_file)。
- 如果省略
enabledTools,或将其设置为["*"],则会注册所有工具。 - 将
enabledTools设置为[],则不会注册该服务器的任何工具。 - 将
enabledTools设置为非空名称列表,则仅注册该子集。
MCP 工具会在启动时自动发现并注册。LLM 可以将其与内置工具一起使用,无需额外配置。
安全性
[!TIP] 对于生产部署,请在配置中设置
"restrictToWorkspace": true,以将代理沙盒化。 在v0.1.4.post3及更早版本中,空的allowFrom允许所有发送者。自v0.1.4.post4起,空的allowFrom默认拒绝所有访问。要允许所有发送者,请设置"allowFrom": ["*"]。
| 选项 | 默认值 | 描述 |
|---|---|---|
tools.restrictToWorkspace |
false |
当设置为 true 时,会将代理的所有工具(shell、文件读写编辑、列表等)限制在工作目录内。防止路径遍历和越界访问。 |
tools.exec.enable |
true |
当设置为 false 时,shell exec 工具将不会被注册。可用于完全禁用 shell 命令执行。 |
tools.exec.pathAppend |
"" |
运行 shell 命令时附加到 PATH 的额外目录(例如 /usr/sbin 用于 ufw)。 |
channels.*.allowFrom |
[](拒绝所有) |
白名单用户 ID 列表。空列表表示拒绝所有;使用 ["*"] 可允许所有人。 |
时区
时间是上下文的一部分。上下文应当精确。
默认情况下,nanobot 使用 UTC 作为运行时的时间上下文。如果你希望代理以你的本地时间思考,请将 agents.defaults.timezone 设置为有效的 IANA 时区名称:
{
"agents": {
"defaults": {
"timezone": "Asia/Shanghai"
}
}
}
这会影响显示给模型的运行时时间字符串,例如运行时上下文和心跳提示。它也会成为 cron 定时任务的默认时区(当 cron 表达式省略 tz 时),以及一次性 at 时间的默认时区(当 ISO 日期时间没有明确的偏移量时)。
常见示例:UTC、America/New_York、America/Los_Angeles、Europe/London、Europe/Berlin、Asia/Tokyo、Asia/Shanghai、Asia/Singapore、Australia/Sydney。
需要其他时区吗?请浏览完整的 IANA 时区数据库。
🧩 多实例
可以同时运行多个 nanobot 实例,每个实例使用独立的配置和运行时数据。使用 --config 作为主要入口点。如果需要为特定实例初始化或更新保存的工作空间,可以在 onboard 时选择性地传递 --workspace。
快速入门
如果你想让每个实例从一开始就拥有自己专用的工作空间,那么在入职时同时传递 --config 和 --workspace。
初始化实例:
# 创建独立的实例配置和工作空间
nanobot onboard --config ~/.nanobot-telegram/config.json --workspace ~/.nanobot-telegram/workspace
nanobot onboard --config ~/.nanobot-discord/config.json --workspace ~/.nanobot-discord/workspace
nanobot onboard --config ~/.nanobot-feishu/config.json --workspace ~/.nanobot-feishu/workspace
配置每个实例:
编辑 ~/.nanobot-telegram/config.json、~/.nanobot-discord/config.json 等文件,设置不同的频道参数。你在 onboard 时传递的工作空间会保存到每个配置中,作为该实例的默认工作空间。
运行实例:
# 实例 A - Telegram 机器人
nanobot gateway --config ~/.nanobot-telegram/config.json
# 实例 B - Discord 机器人
nanobot gateway --config ~/.nanobot-discord/config.json
# 实例 C - Feishu 机器人,自定义端口
nanobot gateway --config ~/.nanobot-feishu/config.json --port 18792
路径解析
当使用 --config 时,nanobot 会根据配置文件的位置推导出其运行时数据目录。工作空间仍然来自 agents.defaults.workspace,除非你用 --workspace 覆盖它。
要在本地针对其中一个实例打开 CLI 会话:
nanobot agent -c ~/.nanobot-telegram/config.json -m "来自 Telegram 实例的问候"
nanobot agent -c ~/.nanobot-discord/config.json -m "来自 Discord 实例的问候"
# 可选的一次性工作空间覆盖
nanobot agent -c ~/.nanobot-telegram/config.json -w /tmp/nanobot-telegram-test
nanobot agent会使用选定的工作空间/配置启动一个本地 CLI 代理,但它不会附加到或代理已经运行的nanobot gateway进程。
| 组件 | 解析来源 | 示例 |
|---|---|---|
| 配置 | --config 路径 |
~/.nanobot-A/config.json |
| 工作空间 | --workspace 或配置 |
~/.nanobot-A/workspace/ |
| Cron 任务 | 配置目录 | ~/.nanobot-A/cron/ |
| 媒体/运行时状态 | 配置目录 | ~/.nanobot-A/media/ |
工作原理
--config用于选择加载哪个配置文件。- 默认情况下,工作空间来自该配置中的
agents.defaults.workspace。 - 如果你传递了
--workspace,它会覆盖配置文件中定义的工作空间。
最小化设置
- 将你的基础配置复制到一个新的实例目录。
- 为该实例设置不同的
agents.defaults.workspace。 - 使用
--config启动实例。
示例配置:
{
"agents": {
"defaults": {
"workspace": "~/.nanobot-telegram/workspace",
"model": "anthropic/claude-sonnet-4-6"
}
},
"channels": {
"telegram": {
"enabled": true,
"token": "YOUR_TELEGRAM_BOT_TOKEN"
}
},
"gateway": {
"port": 18790
}
}
启动独立实例:
nanobot gateway --config ~/.nanobot-telegram/config.json
nanobot gateway --config ~/.nanobot-discord/config.json
必要时,可以通过以下方式覆盖工作空间进行一次性运行:
nanobot gateway --config ~/.nanobot-telegram/config.json --workspace /tmp/nanobot-telegram-test
常见用例
- 为 Telegram、Discord、Feishu 等不同平台运行独立的机器人。
- 保持测试和生产实例隔离。
- 为不同团队使用不同的模型或提供商。
- 为多个租户提供服务,每个租户使用独立的配置和运行时数据。
注意事项
- 如果多个实例同时运行,必须使用不同的端口。
- 如果希望内存、会话和技能相互隔离,建议为每个实例使用不同的工作空间。
--workspace会覆盖配置文件中定义的工作空间。- Cron 任务以及运行时的媒体和状态都来自配置目录。
💻 CLI 参考
| 命令 | 描述 |
|---|---|
nanobot onboard |
在 ~/.nanobot/ 初始化配置和工作空间 |
nanobot onboard --wizard |
启动交互式入职向导 |
nanobot onboard -c <config> -w <workspace> |
初始化或刷新特定实例的配置和工作空间 |
nanobot agent -m "..." |
与代理聊天 |
nanobot agent -w <workspace> |
针对特定工作空间聊天 |
nanobot agent -w <workspace> -c <config> |
针对特定工作空间/配置聊天 |
nanobot agent |
交互式聊天模式 |
nanobot agent --no-markdown |
显示纯文本回复 |
nanobot agent --logs |
聊天过程中显示运行日志 |
nanobot serve |
启动兼容 OpenAI 的 API |
nanobot gateway |
启动网关 |
nanobot status |
显示状态 |
nanobot provider login openai-codex |
通过 OAuth 登录提供商 |
nanobot channels login <channel> |
交互式认证某个频道 |
nanobot channels status |
显示频道状态 |
交互模式退出方式:exit、quit、/exit、/quit、:q 或 Ctrl+D。
心跳(周期性任务)
网关每 30 分钟唤醒一次,并检查你工作空间中的 HEARTBEAT.md 文件(~/.nanobot/workspace/HEARTBEAT.md)。如果文件中有任务,代理会执行这些任务,并将结果发送到你最近活跃的聊天频道。
设置: 编辑 ~/.nanobot/workspace/HEARTBEAT.md(由 nanobot onboard 自动创建):
## 周期性任务
- [ ] 检查天气预报并发送摘要
- [ ] 扫描收件箱中的紧急邮件
代理也可以自行管理此文件——只需让它“添加一个周期性任务”,它就会为你更新 HEARTBEAT.md。
注意: 网关必须正在运行(
nanobot gateway),并且你至少与机器人聊过一次,这样它才能知道将结果发送到哪个频道。
🐍 Python SDK
将 nanobot 用作库——无需 CLI,无需网关,只需 Python:
from nanobot import Nanobot
bot = Nanobot.from_config()
result = await bot.run("总结 README")
print(result.content)
每次调用都会携带一个 session_key 来实现对话隔离——不同的密钥会拥有独立的对话历史:
await bot.run("hi", session_key="user-alice")
await bot.run("hi", session_key="task-42")
添加生命周期钩子来观察或自定义代理行为:
from nanobot.agent import AgentHook, AgentHookContext
class AuditHook(AgentHook):
async def before_execute_tools(self, ctx: AgentHookContext) -> None:
for tc in ctx.tool_calls:
print(f"[tool] {tc.name}")
result = await bot.run("Hello", hooks=[AuditHook()])
完整的 SDK 参考请参阅 docs/PYTHON_SDK.md。
🔌 OpenAI 兼容 API
nanobot 可以暴露一个最小化的 OpenAI 兼容端点,用于本地集成:
pip install "nanobot-ai[api]"
nanobot serve
默认情况下,API 绑定到 127.0.0.1:8900。您可以在 config.json 中更改此设置。
行为
- 会话隔离:在请求体中传递
"session_id"以隔离对话;省略则使用共享的默认会话(api:default) - 单消息输入:每个请求必须恰好包含一条
user消息 - 固定模型:省略
model,或传入与/v1/models显示相同的模型 - 不支持流式输出:
stream=true不被支持
端点
GET /healthGET /v1/modelsPOST /v1/chat/completions
curl
curl http://127.0.0.1:8900/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "hi"}],
"session_id": "my-session"
}'
Python (requests)
import requests
resp = requests.post(
"http://127.0.0.1:8900/v1/chat/completions",
json={
"messages": [{"role": "user", "content": "hi"}],
"session_id": "my-session", # 可选:隔离对话
},
timeout=120,
)
resp.raise_for_status()
print(resp.json()["choices"][0]["message"]["content"])
Python (openai)
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8900/v1",
api_key="dummy",
)
resp = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "hi"}],
extra_body={"session_id": "my-session"}, # 可选:隔离对话
)
print(resp.choices[0].message.content)
🐳 Docker
[!TIP]
-v ~/.nanobot:/root/.nanobot标志会将您的本地配置目录挂载到容器中,这样您的配置和工作区会在容器重启后仍然保留。
Docker Compose
docker compose run --rm nanobot-cli onboard # 首次设置
vim ~/.nanobot/config.json # 添加 API 密钥
docker compose up -d nanobot-gateway # 启动网关
docker compose run --rm nanobot-cli agent -m "Hello!" # 运行 CLI
docker compose logs -f nanobot-gateway # 查看日志
docker compose down # 停止
Docker
# 构建镜像
docker build -t nanobot .
# 初始化配置(仅首次)
docker run -v ~/.nanobot:/root/.nanobot --rm nanobot onboard
# 在主机上编辑配置以添加 API 密钥
vim ~/.nanobot/config.json
# 运行网关(连接到已启用的渠道,例如 Telegram/Discord/Mochat)
docker run -v ~/.nanobot:/root/.nanobot -p 18790:18790 nanobot gateway
# 或者运行单个命令
docker run -v ~/.nanobot:/root/.nanobot --rm nanobot agent -m "Hello!"
docker run -v ~/.nanobot:/root/.nanobot --rm nanobot status
🐧 Linux 服务
将网关作为 systemd 用户服务运行,以便它能够自动启动并在发生故障时重启。
1. 查找 nanobot 二进制文件路径:
which nanobot # 例如 /home/user/.local/bin/nanobot
2. 创建服务文件,位于 ~/.config/systemd/user/nanobot-gateway.service(如果需要,请替换 ExecStart 路径):
[Unit]
Description=Nanobot Gateway
After=network.target
[Service]
Type=simple
ExecStart=%h/.local/bin/nanobot gateway
Restart=always
RestartSec=10
NoNewPrivileges=yes
ProtectSystem=strict
ReadWritePaths=%h
[Install]
WantedBy=default.target
3. 启用并启动:
systemctl --user daemon-reload
systemctl --user enable --now nanobot-gateway
常用操作:
systemctl --user status nanobot-gateway # 检查状态
systemctl --user restart nanobot-gateway # 在配置更改后重启
journalctl --user -u nanobot-gateway -f # 实时查看日志
如果您编辑了 .service 文件本身,请在重启之前运行 systemctl --user daemon-reload。
注意: 用户服务仅在您登录时运行。要使网关在注销后继续运行,请启用 linger 功能:
loginctl enable-linger $USER
📁 项目结构
nanobot/
├── agent/ # 🧠 核心代理逻辑
│ ├── loop.py # 代理循环(LLM ↔ 工具执行)
│ ├── context.py # 提示词构建器
│ ├── memory.py # 持久化内存
│ ├── skills.py # 技能加载器
│ ├── subagent.py # 后台任务执行
│ └── tools/ # 内置工具(包括 spawn)
├── skills/ # 🎯 捆绑技能(github、天气、tmux 等)
├── channels/ # 📱 聊天渠道集成(支持插件)
├── bus/ # 🚌 消息路由
├── cron/ # ⏰ 定时任务
├── heartbeat/ # 💓 主动唤醒
├── providers/ # 🤖 LLM 提供商(OpenRouter 等)
├── session/ # 💬 对话会话
├── config/ # ⚙️ 配置
└── cli/ # 🖥️ 命令
🤝 贡献与路线图
欢迎提交 PR!代码库刻意保持小巧且易于阅读。🤗
分支策略
| 分支 | 目的 |
|---|---|
main |
稳定版本——修复 bug 和小幅改进 |
nightly |
实验性功能——新功能和破坏性变更 |
不确定该提交到哪个分支? 请参阅 CONTRIBUTING.md 了解详情。
路线图——选择一项并 提交 PR!
- 多模态——看见和听见(图片、语音、视频)
- 长期记忆——永不忘记重要上下文
- 更好的推理能力——多步规划和反思
- 更多集成——日历等
- 自我改进——从反馈和错误中学习
贡献者

⭐ 星标历史

感谢您的访问 ✨ nanobot!

nanobot 仅用于教育、研究和技术交流目的
版本历史
v0.1.4.post62026/03/27v0.1.4.post52026/03/16v0.1.4.post42026/03/08v0.1.4.post32026/02/28v0.1.4.post22026/02/24v0.1.4.post12026/02/21v0.1.42026/02/18v0.1.3.post72026/02/13v0.1.3.post62026/02/10v0.1.3.post52026/02/07v0.1.3.post42026/02/04常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。