InfinityStar
InfinityStar 是一款由字节跳动开源的统一时空自回归视觉生成模型,刚刚荣获 NeurIPS 2025 口头报告奖。它致力于解决传统视频生成中图像与视频模型割裂、生成速度慢以及长视频连贯性差的难题。通过创新的纯离散自回归架构,InfinityStar 能在单一模型中同时捕捉空间细节与时间动态,轻松实现文生图、文生视频、图生视频及超长交互式视频合成。
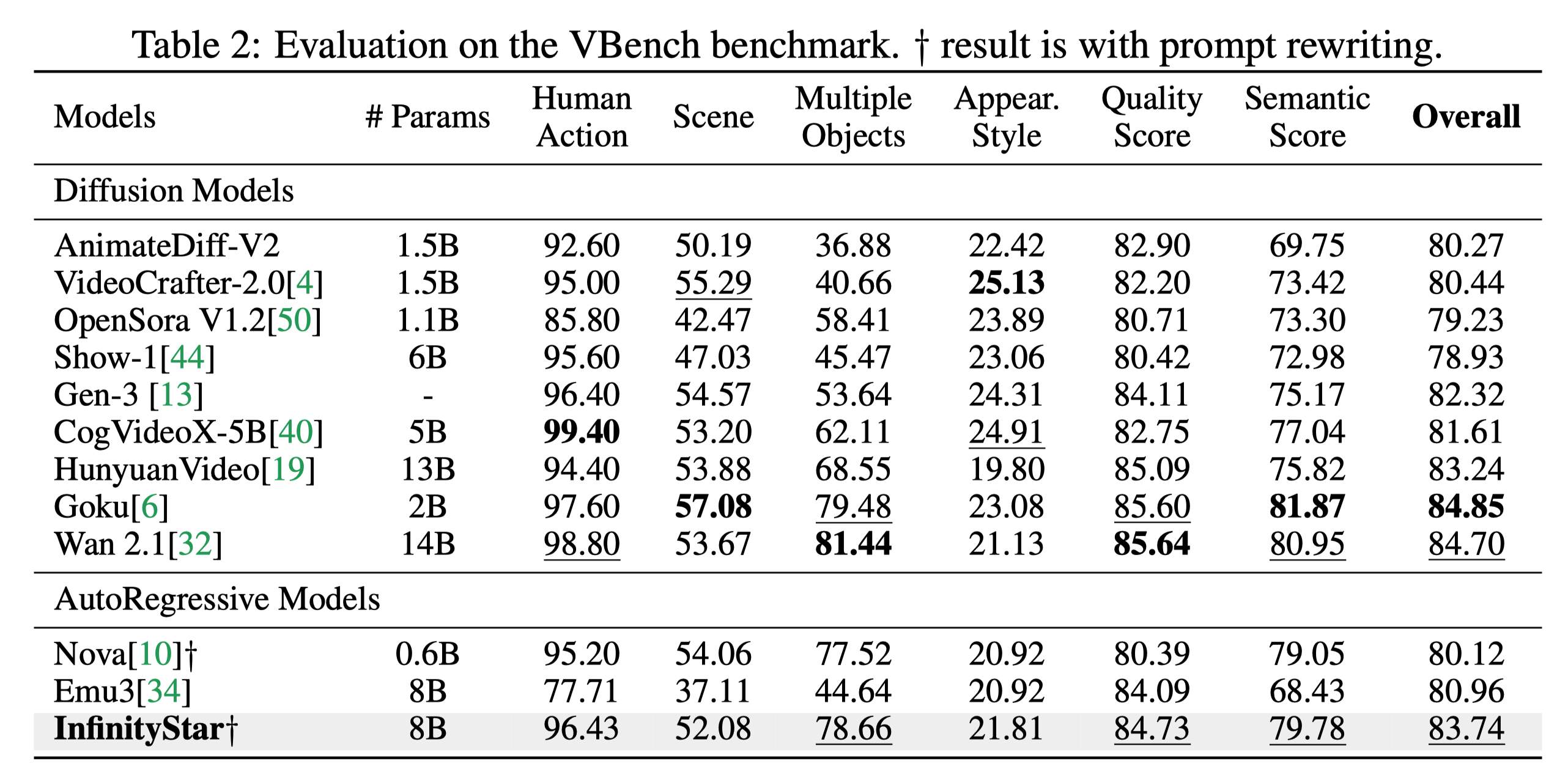
其核心技术亮点在于突破了自回归模型在高分辨率视频生成上的瓶颈,成为业界首个能稳定输出工业级 720p 视频的离散自回归生成器。在性能方面,InfinityStar 在 VBench 基准测试中得分高达 83.74,不仅大幅领先同类自回归模型,甚至超越了 HunyuanVideo 等主流扩散模型,且推理速度约为后者的 10 倍。
这款工具非常适合 AI 研究人员探索下一代生成范式,也适合开发者快速集成高效视频应用,同时能为数字内容创作者和设计师提供高质量、低延迟的视频素材生成能力。无论是追求极致性能的极客,还是需要创意辅助的设计师,InfinityStar 都能提供流畅且强大的视觉创作体验。
使用场景
某独立游戏工作室的主美正急需为一款赛博朋克风格的 RPG 制作高质量的角色技能演示视频,要求画面达到 720p 工业级分辨率且动作连贯自然。
没有 InfinityStar 时
- 画质与帧率难以兼得:传统扩散模型生成 720p 长视频时显存爆炸,被迫降低分辨率至 480p,导致角色边缘模糊,无法满足宣发素材标准。
- 多任务流程割裂:制作静态立绘需用一套模型,生成动态技能又需切换另一套扩散架构,中间还需人工补帧,工作流繁琐且风格易不一致。
- 等待时间过长:生成一段 5 秒的技能特效视频需耗时数分钟甚至更久,严重拖慢了“设计 - 反馈 - 修改”的敏捷迭代节奏。
- 长视频逻辑崩坏:尝试生成交互式长镜头时,人物动作常在几秒后出现扭曲或背景闪烁,缺乏时空一致性。
使用 InfinityStar 后
- 原生 720p 高清输出:InfinityStar 作为首个支持工业级 720p 的离散自回归模型,直接生成清晰锐利的技能特写,细节完全达标。
- 统一架构全能生成:利用其统一的时空建模能力,同一套模型即可无缝完成从“角色立绘”到“技能动态视频”的转换,风格高度统一。
- 十倍速即时预览:凭借比主流扩散方法快约 10 倍的推理速度,主美能在几分钟内尝试数十种不同的技能特效方案,极大提升创意效率。
- 超长互动视频稳定:通过简单的时序自回归,InfinityStar 能生成长段且逻辑连贯的交互式战斗视频,人物动作流畅无伪影。
InfinityStar 通过统一的时空自回归架构,将高分辨率视频生成的质量门槛与时间成本同时降低了数量级,让单人创作者也能轻松产出电影级动态内容。
运行环境要求
- 未说明
必需 NVIDIA GPU(因使用 FlexAttention 加速),具体型号和显存大小未说明,需支持 torch>=2.5.1
未说明

快速开始

Infinity**⭐️**: 面向视觉生成的统一时空自回归建模
![]()
🔥 最新动态!!
- 2025年11月7日:🔥 论文、训练与推理代码、检查点及演示网站正式发布!
- 2025年9月18日:🎉 InfinityStar被NeurIPS 2025接收为口头报告。
🕹️ 体验并玩转Infinity⭐️!
我们提供了一个演示网站,供您试用InfinityStar并生成视频。尽情享受基于比特级视频自回归建模的乐趣吧!
✨ 概述
我们提出了InfinityStar,这是一个用于高分辨率图像和动态视频合成的统一时空自回归框架。
🧠 统一时空模型:一种纯离散的自回归方法,在单一而优雅的架构中联合捕捉空间和时间依赖关系。
🎬 多任务生成:这种统一的设计自然支持多种生成任务,如文本到图像、文本到视频、图像到视频,以及通过简单的时间自回归实现的长时交互式视频合成。
🏆 领先的性能与速度:通过大量实验,InfinityStar在VBench上取得了83.74分的成绩,大幅超越所有自回归模型,甚至优于扩散模型竞争对手如HunyuanVideo,且速度约为领先扩散方法的10倍。
📖 开创性高分辨率自回归生成:据我们所知,InfinityStar是首个能够生成工业级720p视频的离散自回归视频生成器,为其类别树立了新的质量标准。
🔥 统一建模,适用于图像、视频生成及长时交互式视频合成 📈:
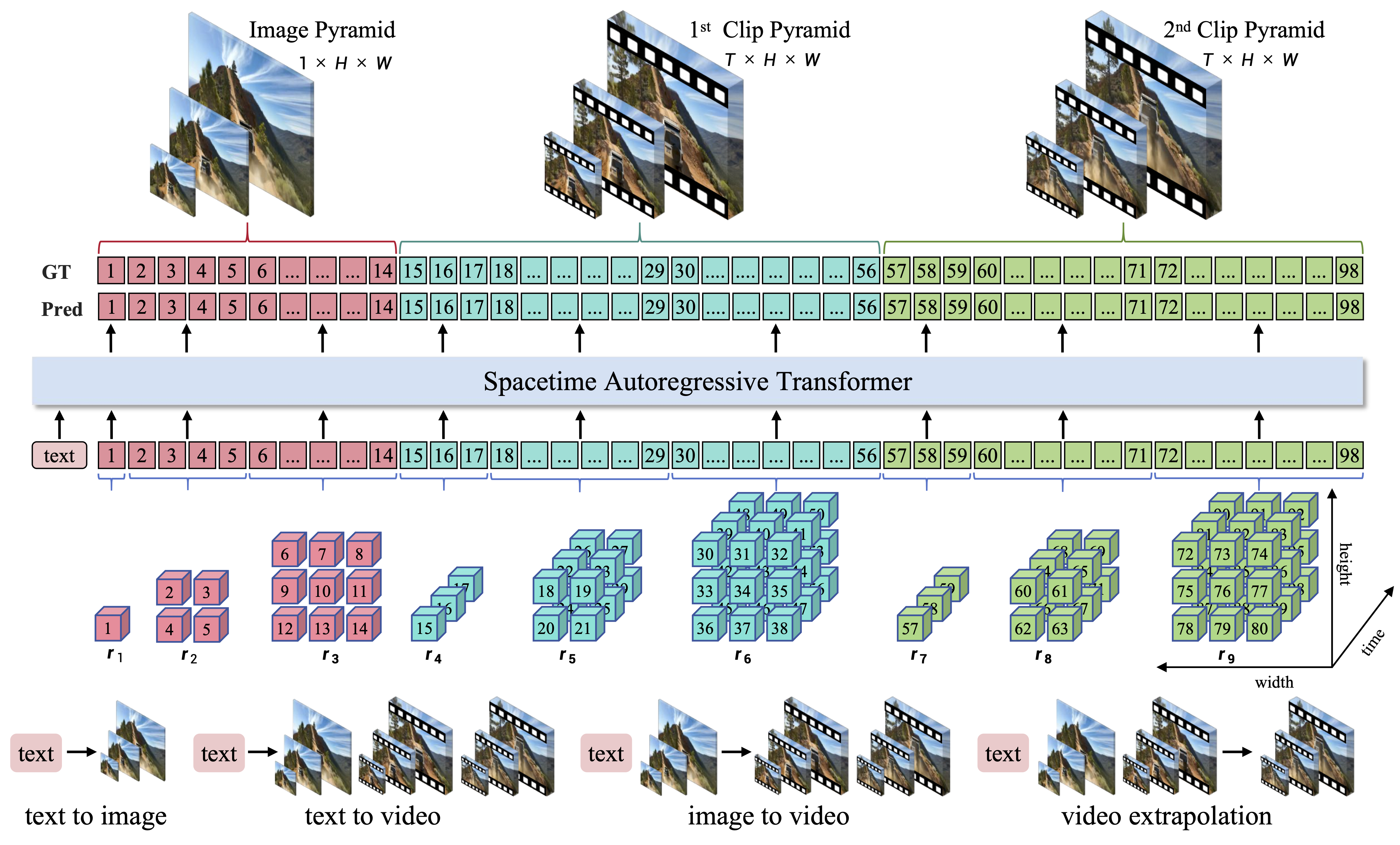
🎬 视频演示
一般美学
动漫与3D动画
运动效果
扩展应用:长时交互式视频
基准测试
在图像生成基准上达到SOTA性能:
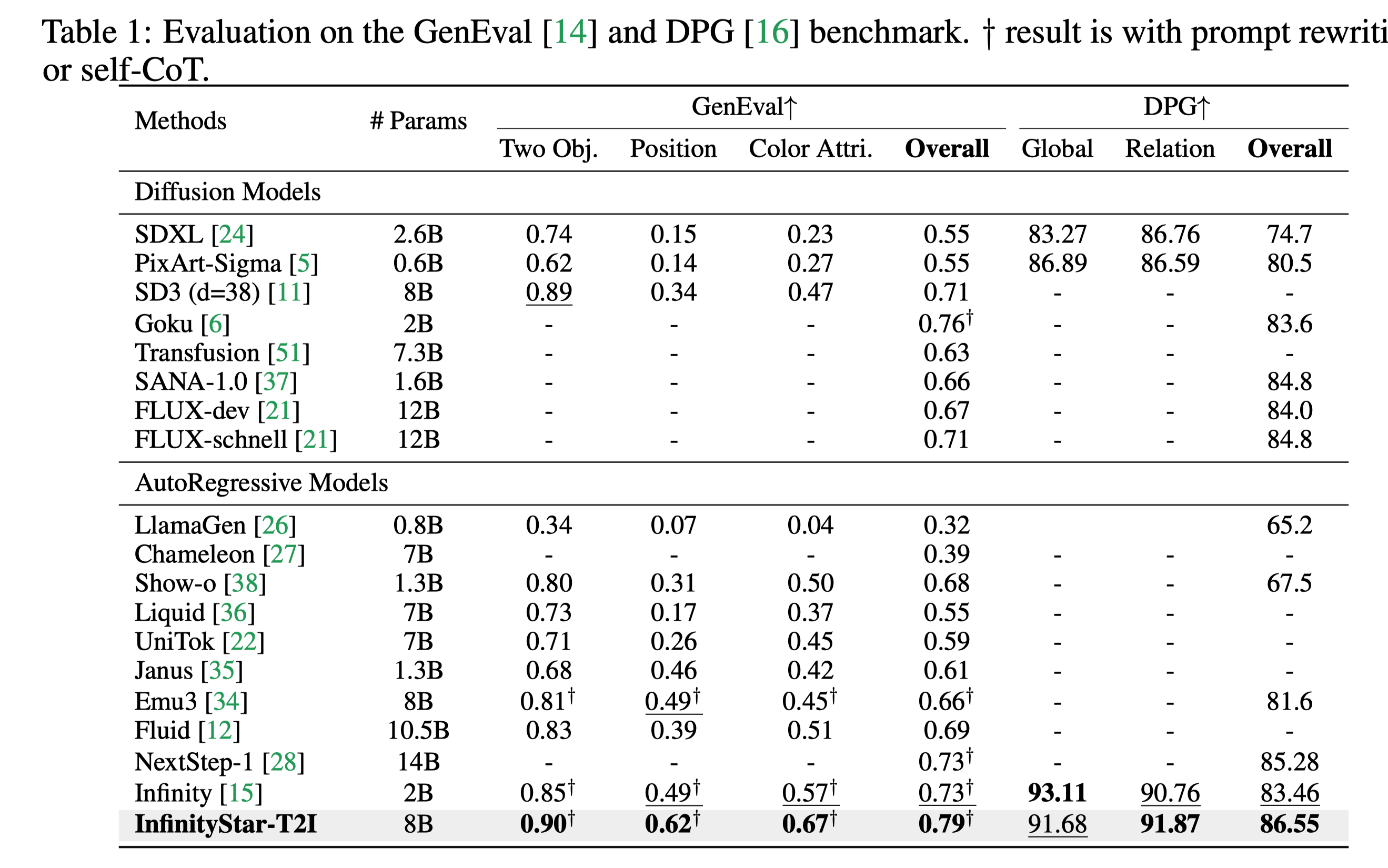
在视频生成基准上达到SOTA性能:
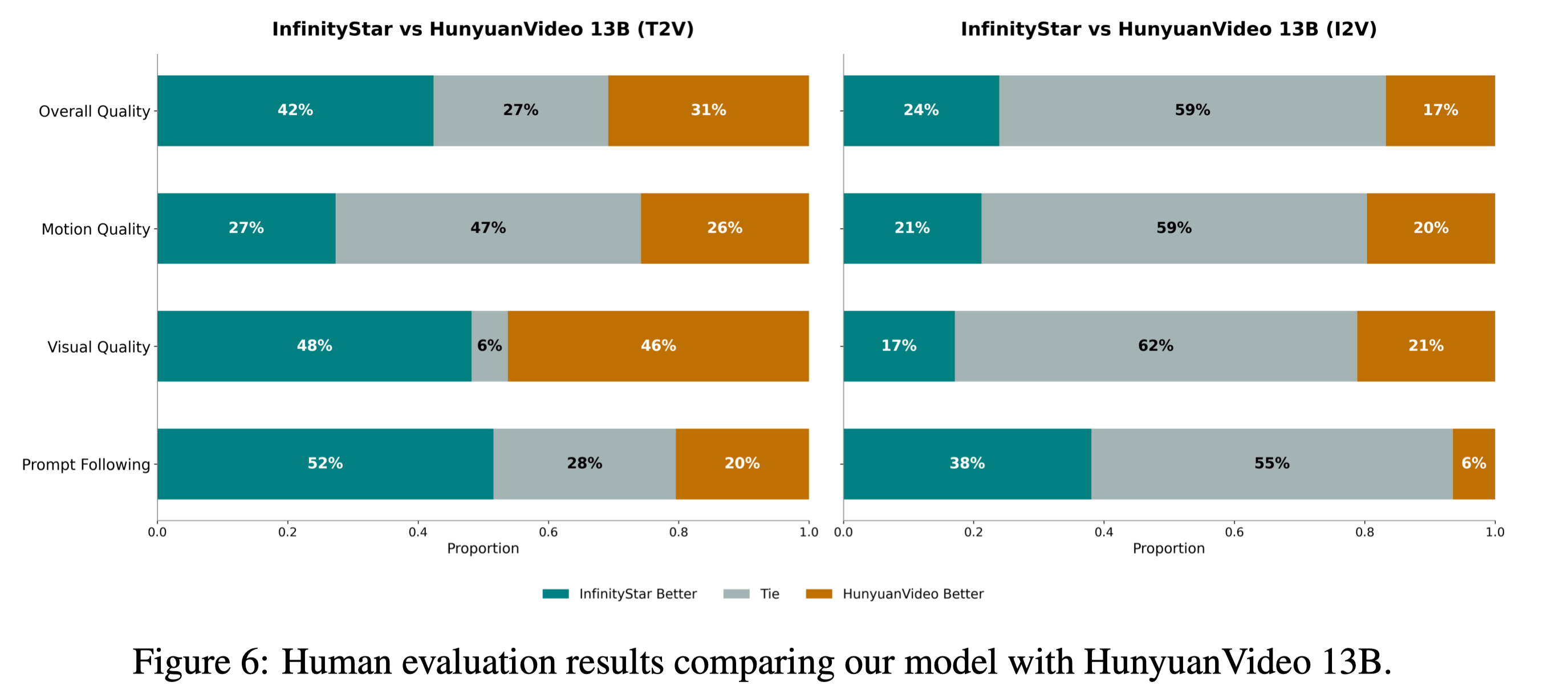
超越扩散模型竞争对手如HunyuanVideo*:
可视化
文本到图像示例

图像到视频示例

视频外推示例

📑 开源计划
- 训练代码
- 网页演示
- InfinityStar推理代码
- InfinityStar模型检查点
- InfinityStar-Interact推理代码
- InfinityStar-Interact检查点
安装
- 我们使用FlexAttention加速训练,这需要
torch>=2.5.1。 - 通过
pip3 install -r requirements.txt安装其他pip包。
训练脚本
我们提供了一套完整的模型训练和微调流程,涵盖数据组织、特征提取以及训练脚本。详细说明请参阅data/README.md。
推理
720p视频生成: 使用
tools/infer_video_720p.py可生成分辨率为720p、时长5秒的视频。由于训练成本较高,我们发布的720p模型仅针对5秒视频生成进行训练。该脚本还支持通过指定图像路径进行图像到视频的转换。python3 tools/infer_video_720p.py480p可变长度视频生成: 我们还提供了一个480p分辨率的中间检查点,可用于生成5秒或10秒的视频。由于该模型并未专门针对文本到视频(T2V)优化,我们建议使用实验性的图像到视频(I2V)和视频到视频(V2V)模式以获得更好的效果。要指定视频时长,可在
tools/infer_video_480p.py中将generation_duration变量修改为5或10。该脚本同样支持通过提供图像或视频路径来进行图像到视频以及视频续写。python3 tools/infer_video_480p.py480p长时交互式视频生成: 使用
tools/infer_interact_480p.py可生成480p分辨率的长时交互式视频。该脚本支持交互式视频生成,您可以提供参考视频和多个提示词,模型将在您的协助下交互式地生成视频。python3 tools/infer_interact_480p.py
引用
如果我们的工作对您的研究有所帮助,欢迎您给我们点个赞 ⭐ 或者使用以下格式引用我们:
@Article{VAR,
title={视觉自回归建模:通过下一尺度预测实现可扩展的图像生成},
author={田科宇、蒋毅、袁泽寰、彭冰悦、王立伟},
year={2024},
eprint={2404.02905},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{Infinity,
title={Infinity:面向高分辨率图像合成的位级自回归建模扩展},
author={韩健、刘金来、蒋毅、闫斌、张宇奇、袁泽寰、彭冰悦、刘晓兵},
year={2024},
eprint={2412.04431},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.04431},
}
@misc{InfinityStar,
title={InfinityStar:用于视觉生成的统一时空自回归建模},
author={刘金来、韩健、闫斌、吴辉、朱峰达、王星、蒋毅、彭冰悦、袁泽寰},
year={2025},
eprint={2511.04675},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.04675},
}
许可证
本项目采用 MIT 许可证授权——详情请参阅 LICENSE 文件。
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
MoneyPrinterTurbo
MoneyPrinterTurbo 是一款利用 AI 大模型技术,帮助用户一键生成高清短视频的开源工具。只需输入一个视频主题或关键词,它就能全自动完成从文案创作、素材匹配、字幕合成到背景音乐搭配的全过程,最终输出完整的竖屏或横屏短视频。 这款工具主要解决了传统视频制作流程繁琐、门槛高以及素材版权复杂等痛点。无论是需要快速产出内容的自媒体创作者,还是希望尝试视频生成的普通用户,无需具备专业的剪辑技能或昂贵的硬件配置(普通电脑即可运行),都能轻松上手。同时,其清晰的 MVC 架构和对多种主流大模型(如 DeepSeek、Moonshot、通义千问等)的广泛支持,也使其成为开发者进行二次开发或技术研究的理想底座。 MoneyPrinterTurbo 的独特亮点在于其高度的灵活性与本地化友好性。它不仅支持中英文双语及多种语音合成,允许用户精细调整字幕样式和画面比例,还特别优化了国内网络环境下的模型接入方案,让用户无需依赖 VPN 即可使用高性能国产大模型。此外,工具提供批量生成模式,可一次性产出多个版本供用户择优,极大地提升了内容创作的效率与质量。
oh-my-openagent
oh-my-openagent(简称 omo)是一款强大的开源智能体编排框架,前身名为 oh-my-opencode。它致力于打破单一模型供应商的生态壁垒,解决开发者在构建 AI 应用时面临的“厂商锁定”难题。不同于仅依赖特定模型的封闭方案,omo 倡导开放市场理念,支持灵活调度多种主流大模型:利用 Claude、Kimi 或 GLM 进行任务编排,调用 GPT 处理复杂推理,借助 Minimax 提升响应速度,或发挥 Gemini 的创意优势。 这款工具特别适合希望摆脱平台限制、追求极致性能与成本平衡的开发者及研究人员使用。通过统一接口,用户可以轻松组合不同模型的长处,构建更高效、更具适应性的智能体系统。其独特的技术亮点在于“全模型兼容”架构,让用户不再受制于某一家公司的策略变动或定价调整,真正实现对前沿模型资源的自由驾驭。无论是构建自动化编码助手,还是开发多步骤任务处理流程,oh-my-openagent 都能提供灵活且稳健的基础设施支持,助力用户在快速演进的 AI 生态中保持技术主动权。
onlook
Onlook 是一款专为设计师打造的开源 AI 优先设计工具,被誉为“设计师版的 Cursor”。它旨在打破设计与开发之间的壁垒,让用户能够以可视化的方式直接构建、样式化和编辑 React 应用。通过 Onlook,用户无需深入编写复杂代码,即可在类似 Figma 的直观界面中完成网页原型的搭建与调整,并实时预览最终效果。 这款工具主要解决了传统工作流中设计稿到代码转换效率低、沟通成本高的问题。以往,设计师使用 Figma 等工具完成设计后,需要开发人员手动将其转化为代码,过程繁琐且容易出错。Onlook 允许用户直接在浏览器 DOM 中进行可视化编辑,底层自动生成基于 Next.js 和 TailwindCSS 的高质量代码,实现了“所见即所得”的开发体验。它不仅支持从文本或图像快速生成应用,还具备分支管理、资源管理及一键部署等功能,极大地简化了从创意到成品的流程。 Onlook 特别适合前端开发者、UI/UX 设计师以及希望快速验证产品创意的独立开发者使用。对于设计师而言,它降低了参与前端开发的门槛;对于开发者来说,它提供了一个高效的视觉化调试和原型构建环境。其核心技术亮点在于
serena
Serena 是一款专为编程智能体(Coding Agent)打造的强大工具包,被誉为“智能体的集成开发环境(IDE)”。它通过模型上下文协议(MCP)与各类大语言模型及客户端无缝集成,旨在解决传统 AI 在复杂代码库中因依赖行号或简单文本搜索而导致的效率低下和准确性不足的问题。 与传统方法不同,Serena 采用“智能体优先”的设计理念,提供基于语义的代码检索、编辑和重构能力。它能像资深开发者使用 IDE 一样,深入理解代码的符号层级和关联结构,从而让智能体在大型项目中运行得更快、更稳、更可靠。无论是终端用户(如 Claude Code)、IDE 插件(VSCode、Cursor)还是桌面应用,都能轻松接入 Serena 以扩展功能。 Serena 特别适合需要处理大规模代码项目的开发者、研究人员以及希望提升 AI 编码能力的技术团队。其核心技术亮点在于灵活的后端支持:既默认集成了基于语言服务器协议(LSP)的开源方案,支持超过 40 种编程语言;也可选配强大的 JetBrains 插件,利用专业 IDE 的深度分析能力。这让 Serena 成为连接人工智能与复杂软件工程的高效桥
sam2
SAM 2 是 Meta 推出的新一代基础模型,旨在解决图像与视频中的“提示式视觉分割”难题。无论是静态图片还是动态视频,用户只需提供简单的点击、框选等提示,SAM 2 就能精准识别并分割出目标对象。它将单张图像视为单帧视频进行处理,成功打破了以往模型在视频理解上的局限。 这款工具特别适合计算机视觉开发者、AI 研究人员以及需要处理视频内容的设计师使用。对于希望探索多目标跟踪或构建交互式应用的技术团队,SAM 2 提供了强大的底层支持。其核心亮点在于采用了带有流式记忆机制的 Transformer 架构,能够实现实时的视频处理性能。此外,项目配套发布了迄今为止规模最大的视频分割数据集(SA-V),并通过“模型闭环数据引擎”不断自我进化。最新更新的 SAM 2.1 版本不仅提供了更优的预训练权重,还支持全模型编译加速及灵活的多目标独立追踪,让复杂场景下的视频分析变得更加高效与便捷。