train-llm-from-scratch
train-llm-from-scratch 是一个轻量级开源项目,帮你从零开始训练自己的大型语言模型(LLM)。它覆盖了完整流程:下载Pile数据集(825GB书籍、文章等多样化文本)、预处理数据、训练模型,直到生成文本,只需单个GPU就能训练百万或十亿参数的模型。这个工具解决了LLM训练门槛高的问题——传统方法需要昂贵硬件和复杂配置,而它让个人开发者用Colab等免费资源就能实践,无需团队级算力。
特别适合熟悉Python基础、PyTorch框架和神经网络概念的开发者与研究人员。如果你正在学习AI原理或想实验小型模型(如1300万参数级别),它提供清晰的代码拆解:基于"Attention is All You Need"论文,从头实现Transformer核心组件(如多头注意力机制、多层感知机),并配有step-by-step注释,帮助你理解每一步的数学逻辑。技术亮点在于平衡了简洁性与教学性——既避免过度简化损失关键细节,又通过结构化脚本降低学习曲线。无论你是探索LLM底层机制,还是为研究项目打基础,它都能成为实用的入门伙伴。(字数:298)
使用场景
某科技初创公司的数据科学家小李,正尝试为内部知识库训练一个1300万参数的语言模型,用于自动生成技术文档摘要,但缺乏高效训练工具。
没有 train-llm-from-scratch 时
- 手动下载Pile数据集需处理825GB原始数据,清洗JSON格式不一致的文本耗时3天,常因元数据错误中断流程。
- 从头编写Transformer代码时频繁出现维度不匹配和注意力机制bug,仅调试单头注意力模块就花费2周。
- 在Colab免费版GPU上训练总触发内存溢出,被迫反复缩减批次大小,导致训练进度停滞。
- 损失曲线剧烈波动难以解读,需手动添加监控代码排查问题,模型收敛时间延长50%。
- 生成的摘要逻辑混乱,如输出"1978年公园返回工厂板"等无意义片段,无法用于实际产品。
使用 train-llm-from-scratch 后
- 内置数据脚本自动下载Pile子集并标准化预处理,10分钟内完成数据准备,直接跳过清洗陷阱。
- 提供论文级验证的Transformer实现,多头注意力和MLP模块开箱即用,首日即跑通训练流程。
- 优化内存管理仅用Kaggle T4 GPU稳定训练,无需升级硬件,训练速度提升40%。
- 集成实时损失可视化工具,快速定位收敛问题,超参数调优时间缩短至2天。
- 生成的摘要连贯实用,例如"Transformer通过自注意力机制高效处理长文本",可直接集成到文档系统。
train-llm-from-scratch 让开发者用单个消费级GPU在一周内完成从数据到生成的全流程训练,大幅降低LLM定制门槛。
运行环境要求
- 未说明
必须使用 NVIDIA GPU,训练 13M 参数模型需 8GB+ 显存(如 RTX 4060 Ti),训练 2B 参数模型需 24GB+ 显存(如 RTX 3090/4090)
未说明

快速开始
我基于论文 Attention is All You Need(注意力机制就是你需要的一切) 使用 PyTorch 从零实现了一个 Transformer(变换器)模型。你可以使用我的脚本来训练自己的 十亿 或 百万 参数的 LLM(大型语言模型),仅需单个 GPU。
以下是训练完成的 1300 万参数 LLM 的输出:
In ***1978, The park was returned to the factory-plate that
the public share to the lower of the electronic fence that
follow from the Station's cities. The Canal of ancient Western
nations were confined to the city spot. The villages were directly
linked to cities in China that revolt that the US budget and in
Odambinais is uncertain and fortune established in rural areas.
目录
训练数据信息
训练数据来自 Pile 数据集(PILE 数据集,一个多样化的开源大规模语言模型训练数据集)。Pile 数据集是 22 个多样化数据集的集合,包括书籍、文章、网站等文本。Pile 数据集的总大小为 825GB。以下是训练数据的样本:
Line: 0
{
"text": "Effect of sleep quality ... epilepsy.",
"meta": {
"pile_set_name": "PubMed Abstracts"
}
}
Line: 1
{
"text": "LLMops a new GitHub Repository ...",
"meta": {
"pile_set_name": "Github"
}
}
先决条件与训练时间
确保您理解面向对象编程(OOP)、神经网络(NN)和 PyTorch 的基础知识,以便理解代码。以下资源可帮助您入门:
| 主题 | 视频链接 |
|---|---|
| 面向对象编程(OOP) | OOP 视频 |
| 神经网络(NN) | 神经网络视频 |
| PyTorch | PyTorch 视频 |
您需要 GPU 来训练模型。Colab 或 Kaggle T4 可用于训练参数量超过 1300 万的模型,但无法训练十亿级参数模型。参考以下对比:
| GPU 名称 | 显存 | 数据规模 | 20 亿参数 LLM 训练 | 1300 万参数 LLM 训练 | 最大实用 LLM 规模(训练) |
|---|---|---|---|---|---|
| NVIDIA A100 | 40 GB | 大 | ✔ | ✔ | ~60 亿–80 亿 |
| NVIDIA V100 | 16 GB | 中 | ✘ | ✔ | ~20 亿 |
| AMD Radeon VII | 16 GB | 中 | ✘ | ✔ | ~15 亿–20 亿 |
| NVIDIA RTX 3090 | 24 GB | 大 | ✔ | ✔ | ~35 亿–40 亿 |
| Tesla P100 | 16 GB | 中 | ✘ | ✔ | ~15 亿–20 亿 |
| NVIDIA RTX 3080 | 10 GB | 中 | ✘ | ✔ | ~12 亿 |
| AMD RX 6900 XT | 16 GB | 大 | ✘ | ✔ | ~20 亿 |
| NVIDIA GTX 1080 Ti | 11 GB | 中 | ✘ | ✔ | ~12 亿 |
| Tesla T4 | 16 GB | 小 | ✘ | ✔ | ~15 亿–20 亿 |
| NVIDIA Quadro RTX 8000 | 48 GB | 大 | ✔ | ✔ | ~80 亿–100 亿 |
| NVIDIA RTX 4070 | 12 GB | 中 | ✘ | ✔ | ~15 亿 |
| NVIDIA RTX 4070 Ti | 12 GB | 中 | ✘ | ✔ | ~15 亿 |
| NVIDIA RTX 4080 | 16 GB | 中 | ✘ | ✔ | ~20 亿 |
| NVIDIA RTX 4090 | 24 GB | 大 | ✔ | ✔ | ~40 亿 |
| NVIDIA RTX 4060 Ti | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
| NVIDIA RTX 4060 | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
| NVIDIA RTX 4050 | 6 GB | 小 | ✘ | ✔ | ~7.5 亿 |
| NVIDIA RTX 3070 | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
| NVIDIA RTX 3060 Ti | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
| NVIDIA RTX 3060 | 12 GB | 中 | ✘ | ✔ | ~15 亿 |
| NVIDIA RTX 3050 | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
| NVIDIA GTX 1660 Ti | 6 GB | 小 | ✘ | ✔ | ~7.5 亿 |
| AMD RX 7900 XTX | 24 GB | 大 | ✔ | ✔ | ~35 亿–40 亿 |
| AMD RX 7900 XT | 20 GB | 大 | ✔ | ✔ | ~30 亿 |
| AMD RX 7800 XT | 16 GB | 中 | ✘ | ✔ | ~20 亿 |
| AMD RX 7700 XT | 12 GB | 中 | ✘ | ✔ | ~15 亿 |
| AMD RX 7600 | 8 GB | 小 | ✘ | ✔ | ~10 亿 |
1300 万参数 LLM 训练指训练参数量超过 1300 万的模型,20 亿参数 LLM 训练指训练参数量超过 20 亿的模型。数据规模分为小、中、大三类:小规模约 1 GB,中规模约 5 GB,大规模约 10 GB。
代码结构
代码库组织如下:
train-llm-from-scratch/
├── src/
│ ├── models/
│ │ ├── mlp.py # 多层感知机(MLP)模块的定义
│ │ ├── attention.py # 注意力机制(单头、多头)的定义
│ │ ├── transformer_block.py # 单个 Transformer 块(Transformer 模型的基本组成单元)的定义
│ │ ├── transformer.py # 主 Transformer 模型的定义
├── config/
│ └── config.py # 包含默认配置(模型参数、文件路径等)
├── data_loader/
│ └── data_loader.py # 包含创建数据加载器/迭代器的函数
├── scripts/
│ ├── train_transformer.py # 训练 Transformer 模型的脚本
│ ├── data_download.py # 下载数据集的脚本
│ ├── data_preprocess.py # 预处理下载数据的脚本
│ ├── generate_text.py # 使用训练模型生成文本的脚本
├── data/ # 存储数据集的目录
│ ├── train/ # 包含训练数据
│ └── val/ # 包含验证数据
├── models/ # 保存训练模型的目录
scripts/ 目录包含下载数据集、预处理数据、训练模型及生成文本的脚本。src/models/ 目录包含 Transformer 模型、多层感知机(MLP)、注意力机制和 Transformer 块的实现。config/ 目录包含含默认参数的配置文件。data_loader/ 目录包含创建数据加载器/迭代器的函数。
使用方法
克隆仓库并进入目录:
git clone https://github.com/FareedKhan-dev/train-llm-from-scratch.git
cd train-llm-from-scratch
若遇到导入问题,请确保将 PYTHONPATH 设置为项目根目录:
export PYTHONPATH="${PYTHONPATH}:/path/to/train-llm-from-scratch"
或者如果你已经在 train-llm-from-scratch 目录中
export PYTHONPATH="$PYTHONPATH:."
安装所需依赖项:
```bash
pip install -r requirements.txt
你可以在 src/models/transformer.py 中修改 Transformer架构(一种神经网络架构),并在 config/config.py 中调整训练配置。
要下载训练数据,请运行:
python scripts/data_download.py
该脚本支持以下参数:
--train_max: 要下载的最大训练文件数量。默认值为 1(最大值为 30)。每个文件约 11 GB。--train_dir: 存储训练数据的目录。默认为data/train。--val_dir: 存储验证数据的目录。默认为data/val。
要预处理下载的数据,请运行:
python scripts/data_preprocess.py
该脚本支持以下参数:
--train_dir: 存储训练数据文件的目录(默认为data/train)。--val_dir: 存储验证数据文件的目录(默认为data/val)。--out_train_file: 以 HDF5 格式存储处理后训练数据的路径(默认为data/train/pile_train.h5)。--out_val_file: 以 HDF5 格式存储处理后验证数据的路径(默认为data/val/pile_dev.h5)。--tokenizer_name: 用于数据处理的分词器(Tokenizer)名称(默认为r50k_base)。--max_data: 从每个数据集(训练和验证)中处理的最大 JSON 对象数量(即行数)。默认值为 1000。
数据预处理完成后,你可以通过将 config/config.py 中的配置修改为以下内容来训练 1300 万参数的 LLM(大型语言模型):
# 定义词汇表大小和 Transformer 配置 (30 亿)
VOCAB_SIZE = 50304 # 词汇表中唯一标记(Token)的数量
CONTEXT_LENGTH = 128 # 模型的最大序列长度
N_EMBED = 128 # 嵌入空间(Embedding Space)的维度
N_HEAD = 8 # 每个 Transformer 块中的注意力头(Attention Head)数量
N_BLOCKS = 1 # 模型中 Transformer 块的数量
要训练模型,请运行:
python scripts/train_transformer.py
它将开始训练模型,并将训练好的模型保存在 models/ 默认目录或配置文件中指定的目录中。
要使用训练好的模型生成文本,请运行:
python scripts/generate_text.py --model_path models/your_model.pth --input_text hi
该脚本支持以下参数:
--model_path: 训练好的模型路径。--input_text: 用于生成新文本的初始文本提示。--max_new_tokens: 要生成的最大标记(Token)数量(默认为 100)。
它将根据输入提示使用训练好的模型生成文本。
逐步代码解析
本节适用于希望详细了解代码的读者。我将从导入库开始,逐步解释代码,直至训练模型和生成文本。
此前,我在 Medium 上写过一篇关于使用 Tiny Shakespeare 数据集创建230+ 万参数 LLM 的文章,但输出结果没有意义。以下是示例输出:
# 230 万参数 LLM 输出
ZELBETH:
Sey solmenter! tis tonguerered if
Vurint as steolated have loven OID the queend refore
Are been, good plmp:
Proforne, wiftes swleen, was no blunderesd a a quain beath!
Tybell is my gateer stalk smend as be matious dazest
我想到,如果让 Transformer 架构更小、更简单,并使用更多样化的训练数据,那么单个人使用性能接近淘汰的 GPU 能创建多大参数规模的模型,使其能正确使用语法并生成有意义的文本?
我发现 1300+ 万参数 的模型已足以在正确语法和标点方面开始产生意义,这是一个积极的信号。这意味着我们可以使用非常特定的数据集进一步微调先前训练的模型,以适应特定任务。最终可能会得到一个低于 10 亿参数甚至约 5 亿参数的模型,该模型非常适合我们的特定用例,尤其是安全地在私有数据上运行。
我建议你首先使用 GitHub 仓库中的脚本训练一个 1300+ 万参数的模型。你将在一天内获得结果,而不是等待更长时间,或者避免因本地 GPU 性能不足而无法训练十亿参数模型的情况。
导入库
让我们导入本教程中将使用的必要库:
# PyTorch 用于深度学习函数和张量(Tensor)
import torch
import torch.nn as nn
import torch.nn.functional as F
# 数值运算和数组处理
import numpy as np
# 处理 HDF5 文件
import h5py
# 操作系统和文件管理
import os
# 命令行参数解析
import argparse
# HTTP 请求和交互
import requests
# 循环进度条
from tqdm import tqdm
# JSON 处理
import json
# Zstandard 压缩库
import zstandard as zstd
# 大型语言模型的分词(Tokenization)库
import tiktoken
# 数学运算(用于高级数学函数)
import math
准备训练数据
我们的训练数据集需要多样化,包含来自不同领域的信息,而 The Pile 是合适的选择。虽然其大小为 825 GB,但我们仅使用其中一小部分,即 5%–10%。首先下载数据集并了解其工作原理。我将下载 HuggingFace 上提供的版本。
# 下载验证数据集
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst
# 下载训练数据集的第一部分
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst
# 下载训练数据集的第二部分
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/01.jsonl.zst
# 下载训练数据集的第三部分
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/02.jsonl.zst
下载需要一些时间,但你也可以将训练数据集限制为仅一个文件 00.jsonl.zst,而不是三个。它已经划分为 train/val/test。完成后,请确保将文件正确放置在相应目录中。
import os
import shutil
import glob
# 定义目录结构
train_dir = "data/train"
val_dir = "data/val"
# 如果目录不存在则创建
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
将所有训练文件(例如 00.jsonl.zst, 01.jsonl.zst, ...)
train_files = glob.glob("*.jsonl.zst") for file in train_files: if file.startswith("val"): # 移动验证文件 dest = os.path.join(val_dir, file) else: # 移动训练文件 dest = os.path.join(train_dir, file) shutil.move(file, dest)
我们的数据集采用 .jsonl.zst 格式(一种常用于存储大型数据集的压缩文件格式,结合了 JSON Lines 格式(.jsonl,每行代表一个有效的 JSON 对象)和 Zstandard 压缩(.zst))。下面我们读取一个下载文件的样例查看其结构。
in_file = "data/val/val.jsonl.zst" # 验证文件路径
with zstd.open(in_file, 'r') as in_f: for i, line in tqdm(enumerate(in_f)): # 读取前 5 行 data = json.loads(line) print(f"行 {i}: {data}") # 打印原始数据用于检查 if i == 2: break
上述代码的输出如下:
```python
#### OUTPUT ####
行: 0
{
"text": "Effect of sleep quality ... epilepsy.",
"meta": {
"pile_set_name": "PubMed Abstracts"
}
}
行: 1
{
"text": "LLMops a new GitHub Repository ...",
"meta": {
"pile_set_name": "Github"
}
}
现在我们需要对数据集进行编码(分词,tokenize)。目标是训练一个能正确输出单词的基础大语言模型(LLM),因此需要使用现成的分词器。我们将采用 OpenAI 开源的 tiktoken 分词器(tokenizer),具体使用 r50k_base 分词方案(ChatGPT/GPT-3 模型所用的分词器)来处理数据集。
为避免重复代码(需同时处理训练集和验证集),我们创建如下函数:
def process_files(input_dir, output_file):
"""
处理指定输入目录中的所有 .zst 文件,并将编码后的 tokens 保存至 HDF5 文件。
参数:
input_dir (str): 包含输入 .zst 文件的目录。
output_file (str): 输出 HDF5 文件路径。
"""
with h5py.File(output_file, 'w') as out_f:
# 在 HDF5 文件中创建可扩展的数据集 'tokens'
dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')
start_index = 0
# 遍历输入目录中的所有 .zst 文件
for filename in sorted(os.listdir(input_dir)):
if filename.endswith(".jsonl.zst"):
in_file = os.path.join(input_dir, filename)
print(f"处理中: {in_file}")
# 读取 .zst 压缩文件
with zstd.open(in_file, 'r') as in_f:
# 遍历压缩文件中的每一行
for line in tqdm(in_f, desc=f"处理 {filename}"):
# 将行内容解析为 JSON
data = json.loads(line)
# 在文本末尾添加结束标记并进行编码
text = data['text'] + "<|endoftext|>"
encoded = enc.encode(text, allowed_special={'<|endoftext|>'})
encoded_len = len(encoded)
# 计算新 tokens 的结束索引
end_index = start_index + encoded_len
# 扩展数据集大小并存储编码后的 tokens
dataset.resize(dataset.shape[0] + encoded_len, axis=0)
dataset[start_index:end_index] = encoded
# 更新下一批 tokens 的起始索引
start_index = end_index
关于此函数的两个关键点:
我们将分词后的数据存储在 HDF5(分层数据格式)文件中,这为模型训练期间的快速数据访问提供了灵活性。
添加
|<endoftext|>标记(结束文本标记)用于标识每个文本序列的结尾,向模型指示已到达有意义上下文的终点,有助于生成连贯的输出。
现在我们可以直接对训练集和验证集进行编码:
# 定义分词后数据的输出目录
out_train_file = "data/train/pile_train.h5"
out_val_file = "data/val/pile_dev.h5"
# 加载 GPT-3/GPT-2 模型的分词器
enc = tiktoken.get_encoding('r50k_base')
# 处理训练数据
process_files(train_dir, out_train_file)
# 处理验证数据
process_files(val_dir, out_val_file)
查看分词后数据的样例:
with h5py.File(out_val_file, 'r') as file:
# 访问 'tokens' 数据集
tokens_dataset = file['tokens']
# 打印数据集的数据类型
print(f"'tokens' 数据集的 dtype: {tokens_dataset.dtype}")
# 加载并打印数据集的前几个元素
print("前几个 'tokens' 数据集元素:")
print(tokens_dataset[:10]) # 前 10 个 token
上述代码的输出如下:
#### OUTPUT ####
'tokens' 数据集的 dtype: int32
前几个 'tokens' 数据集元素:
[ 2725 6557 83 23105 157 119 229 77 5846 2429]
我们已完成训练数据集的准备工作。接下来将实现 Transformer 架构并深入探讨其理论原理。
Transformer 概览
让我们快速了解 Transformer 架构如何处理和理解文本。它通过将文本拆分为更小的单元(称为 tokens(标记))并预测序列中的下一个标记来实现。Transformer 由多层堆叠而成,这些层称为 transformer blocks(Transformer 块),顶部还有一个最终层用于预测。
每个 Transformer 块包含两个主要组件:
自注意力头(Self-Attention Heads):这些组件确定输入中哪些部分对模型最重要。例如,在处理句子时,注意力头可以突出显示词语之间的关系,比如代词与其所指代的名词之间的关联。
MLP(多层感知机,Multi-Layer Perceptron):这是一个简单的前馈神经网络。它接收注意力头强调的信息并进行进一步处理。MLP 包含一个接收注意力头数据的输入层、一个增加处理复杂度的隐藏层,以及一个将结果传递给下一个 Transformer 块的输出层。
自注意力头共同构成“思考内容”部分,而 MLP 则是“思考方式”部分。堆叠多个 Transformer 块使模型能够理解文本中的复杂模式和关系,但这并非总是能保证。
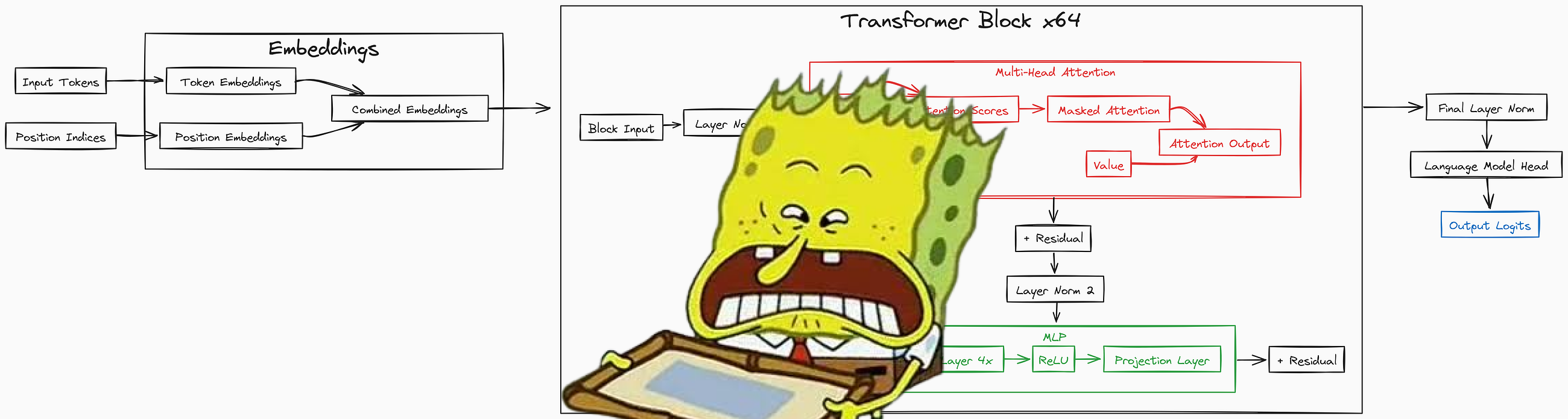
与其查看原始论文中的图示,不如可视化一个更简单易懂的架构图,我们将基于此进行编码。
](https://cdn-images-1.medium.com/max/11808/1*QXmeA-H52C-p82AwawslbQ.png)
让我们阅读即将编码的架构流程:
输入标记(tokens)被转换为嵌入向量(embeddings)并与位置信息结合。
模型包含 64 个相同的 Transformer 块,按顺序处理数据。
每个块首先运行多头注意力(multi-head attention)以分析标记间的关系。
每个块随后通过 MLP 处理数据,该 MLP 先扩展再压缩数据。
每一步使用残差连接(residual connections)帮助信息流动。
全程使用层归一化(layer normalization)稳定训练过程。
注意力机制计算哪些标记应相互关注。
MLP 将数据扩展至 4 倍大小,应用 ReLU 激活函数,再压缩回原尺寸。
模型使用 16 个注意力头捕获不同类型的关联。
最终层将处理后的数据转换为词汇表大小的预测结果。
模型通过重复预测下一个最可能的标记生成文本。
多层感知机(Multi Layer Perceptron, MLP)
MLP 是 Transformer 前馈网络中的基础构建模块。其作用是引入非线性并学习嵌入表示中的复杂关系。定义 MLP 模块时,关键参数是 n_embed(嵌入维度),它定义了输入嵌入的维度。
MLP 通常包含一个将输入维度扩展若干倍(通常为 4 倍,我们也将采用此比例)的隐藏线性层,后接非线性激活函数(常用 ReLU)。此结构使网络能够学习更复杂的特征。最后,投影线性层将扩展后的表示映射回原始嵌入维度。这种变换序列使 MLP 能够优化注意力机制学习到的表示。
](https://cdn-images-1.medium.com/max/4866/1*GXxiLMW4kUXqOEimBA7g0A.png)
# --- MLP (Multi-Layer Perceptron) Class ---
class MLP(nn.Module):
"""
A simple Multi-Layer Perceptron with one hidden layer.
This module is used within the Transformer block for feed-forward processing.
It expands the input embedding size, applies a ReLU activation, and then projects it back
to the original embedding size.
"""
def __init__(self, n_embed):
super().__init__()
self.hidden = nn.Linear(n_embed, 4 * n_embed) # Linear layer to expand embedding size
self.relu = nn.ReLU() # ReLU activation function
self.proj = nn.Linear(4 * n_embed, n_embed) # Linear layer to project back to original size
def forward(self, x):
"""
Forward pass through the MLP.
Args:
x (torch.Tensor): Input tensor of shape (B, T, C), where B is batch size,
T is sequence length, and C is embedding size.
Returns:
torch.Tensor: Output tensor of the same shape as the input.
"""
x = self.forward_embedding(x)
x = self.project_embedding(x)
return x
def forward_embedding(self, x):
"""
Applies the hidden linear layer followed by ReLU activation.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output after the hidden layer and ReLU.
"""
x = self.relu(self.hidden(x))
return x
def project_embedding(self, x):
"""
Applies the projection linear layer.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output after the projection layer.
"""
x = self.proj(x)
return x
我们刚刚完成了 MLP 部分的编码。__init__ 方法初始化了一个扩展输入嵌入尺寸(n_embed)的隐藏线性层和一个将其还原的投影层,并在隐藏层后应用 ReLU 激活函数。forward 方法定义了数据流经这些层的过程:通过 forward_embedding 应用隐藏层和 ReLU,通过 project_embedding 应用投影层。
单头注意力(Single Head Attention)
注意力头是模型的核心部分,其作用是聚焦于输入序列的相关部分。定义 Head 模块时,关键参数包括 head_size(头尺寸)、n_embed(嵌入维度)和 context_length(上下文长度)。head_size 参数决定键(key)、查询(query)和值(value)投影的维度,影响注意力机制的表示能力。
输入嵌入维度 n_embed 定义了这些投影层的输入大小。context_length 用于创建因果掩码(causal mask),确保模型仅关注先前的标记。
在 Head 内部,键、查询和值的线性层(nn.Linear)初始化时无偏置。一个大小为 context_length × context_length 的下三角矩阵(tril)被注册为缓冲区以实现因果掩码,防止注意力机制关注未来标记。
](https://cdn-images-1.medium.com/max/5470/1*teNwEhicq9ebVURiMS8WkA.png)
--- 注意力头类(Attention Head Class)---
class Head(nn.Module): """ 单个注意力头(Attention Head)。
该模块计算注意力分数并将其应用于值(values)。它包含键(key)、查询(query)和值(value)的投影层,
并使用因果掩码(causal masking)防止关注未来标记(tokens)。
"""
def __init__(self, head_size, n_embed, context_length):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias=False) # 键投影
self.query = nn.Linear(n_embed, head_size, bias=False) # 查询投影
self.value = nn.Linear(n_embed, head_size, bias=False) # 值投影
# 用于因果掩码的下三角矩阵
self.register_buffer('tril', torch.tril(torch.ones(context_length, context_length)))
def forward(self, x):
"""
通过注意力头的前向传播。
参数:
x (torch.Tensor): 输入张量,形状为 (B, T, C)。
返回:
torch.Tensor: 应用注意力后的输出张量。
"""
B, T, C = x.shape
k = self.key(x) # (B, T, head_size)
q = self.query(x) # (B, T, head_size)
scale_factor = 1 / math.sqrt(C)
# 计算注意力权重: (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
attn_weights = q @ k.transpose(-2, -1) * scale_factor
# 应用因果掩码
attn_weights = attn_weights.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
attn_weights = F.softmax(attn_weights, dim=-1)
v = self.value(x) # (B, T, head_size)
# 将注意力权重应用于值
out = attn_weights @ v # (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
return out
我们的注意力头类的 `__init__` 方法初始化了键、查询和值的线性投影层,每个层将输入嵌入(n_embed)投影到 head_size 维度。基于 context_length 创建的下三角矩阵用于因果掩码(causal masking)。`forward` 方法通过缩放查询和键的点积计算注意力权重,应用因果掩码,使用 softmax 归一化权重,并计算值的加权和以生成注意力输出。
### 多头注意力机制(Multi-Head Attention)
为了捕获输入序列中的多样化关系,我们将使用多头注意力机制(Multi-Head Attention)的概念。`MultiHeadAttention` 模块管理多个并行运行的独立注意力头。
关键参数是 `n_head`,它决定了并行注意力头的数量。输入嵌入维度(n_embed)和上下文长度(context_length)对于实例化各个注意力头也是必需的。每个头独立处理输入,将其投影到维度为 `n_embed // n_head` 的低维子空间。通过使用多个头,模型可以同时关注输入的不同方面。
](https://cdn-images-1.medium.com/max/6864/1*fa-YjrZdtbpuCLp7An99dg.png)
```python
# --- 多头注意力类(Multi-Head Attention Class)---
class MultiHeadAttention(nn.Module):
"""
多头注意力模块。
该模块并行组合多个注意力头。每个头的输出沿最后一维拼接形成最终输出。
"""
def __init__(self, n_head, n_embed, context_length):
super().__init__()
self.heads = nn.ModuleList([Head(n_embed // n_head, n_embed, context_length) for _ in range(n_head)])
def forward(self, x):
"""
通过多头注意力的前向传播。
参数:
x (torch.Tensor): 输入张量,形状为 (B, T, C)。
返回:
torch.Tensor: 拼接所有头输出后的张量。
"""
# 沿最后一维(C)拼接每个头的输出
x = torch.cat([h(x) for h in self.heads], dim=-1)
return x
现在我们已经定义了 MultiHeadAttention 类(它组合了多个注意力头),__init__ 方法初始化了一个包含 n_head 个 Head 实例的列表,每个头的 head_size 为 n_embed // n_head。forward 方法将每个注意力头应用于输入 x,并沿最后一维拼接它们的输出,合并每个头学到的信息。
Transformer 块(Transformer Block)
要构建十亿参数模型,我们肯定需要深层架构。为此,我们需要编写 Transformer 块并堆叠它们。块的关键参数是 n_head、n_embed 和 context_length。每个块包含一个多头注意力层和一个前馈神经网络(MLP),并在每个组件前应用层归一化(layer normalization),在每个组件后添加残差连接(residual connections)。
层归一化(layer normalization)由嵌入维度 n_embed 参数化,有助于稳定训练过程。多头注意力机制如前所述,需要 n_head、n_embed 和 context_length。MLP 同样使用嵌入维度 n_embed。这些组件协同工作以处理输入并学习复杂模式。
](https://cdn-images-1.medium.com/max/6942/1*uLWGajZc6StnQHfZjcb6eA.png)
--- Transformer块类(Transformer Block Class)---
class Block(nn.Module): """ 单个Transformer块。
该块包含一个多头注意力层(multi-head attention layer)后接一个MLP(多层感知机,MLP),
并带有层归一化(layer normalization)和残差连接(residual connections)。
"""
def __init__(self, n_head, n_embed, context_length):
super().__init__()
self.ln1 = nn.LayerNorm(n_embed)
self.attn = MultiHeadAttention(n_head, n_embed, context_length)
self.ln2 = nn.LayerNorm(n_embed)
self.mlp = MLP(n_embed)
def forward(self, x):
"""
通过Transformer块的前向传播。
参数:
x (torch.Tensor): 输入张量。
返回:
torch.Tensor: 块处理后的输出张量。
"""
# 应用带残差连接的多头注意力
x = x + self.attn(self.ln1(x))
# 应用带残差连接的MLP
x = x + self.mlp(self.ln2(x))
return x
def forward_embedding(self, x):
"""
专注于嵌入和注意力部分的前向传播。
参数:
x (torch.Tensor): 输入张量。
返回:
tuple: 包含MLP嵌入后输出和残差的元组。
"""
res = x + self.attn(self.ln1(x))
x = self.mlp.forward_embedding(self.ln2(res))
return x, res
我们的Block类表示单个Transformer块。`__init__`方法初始化层归一化层(ln1, ln2)、一个多头注意力模块(MultiHeadAttention)和一个MLP模块,所有模块均由n_head(注意力头数)、n_embed(嵌入维度)和context_length(上下文长度)参数化。
`forward`方法实现了块的前向传播:先应用层归一化和带残差连接的多头注意力,再应用另一层归一化和MLP(同样带残差连接)。`forward_embedding`方法提供了一种替代前向传播路径,专注于注意力和初始MLP嵌入阶段。
### 最终模型
到目前为止,我们已编写了Transformer模型的小型组件。接下来,我们将词元嵌入(token embeddings)和位置嵌入(position embeddings)与一系列Transformer块集成,以执行序列到序列任务。为此,我们需要定义几个关键参数:n_head(注意力头数)、n_embed(嵌入维度)、context_length(上下文长度)、vocab_size(词汇表大小)和N_BLOCKS(块数量)。
vocab_size(词汇表大小)决定了词元嵌入层的规模,将每个词元映射为维度为n_embed的稠密向量。context_length(上下文长度)对位置嵌入层至关重要,该层编码输入序列中每个词元的位置信息,维度同样为n_embed。注意力头数(n_head)和块数量(N_BLOCKS)共同决定了网络的深度和复杂度。
这些参数共同定义了Transformer模型的架构和容量,现在开始编码实现。
](https://cdn-images-1.medium.com/max/5418/1*0XXd_R2EOhkKCQDfqUQg0w.png)
```python
# --- Transformer模型类(Transformer Model Class)---
class Transformer(nn.Module):
"""
主Transformer模型。
该类将词元嵌入(token embeddings)和位置嵌入(position embeddings)与一系列Transformer块结合,
并添加一个用于语言建模的最终线性层。
"""
def __init__(self, n_head, n_embed, context_length, vocab_size, N_BLOCKS):
super().__init__()
self.context_length = context_length
self.N_BLOCKS = N_BLOCKS
self.token_embed = nn.Embedding(vocab_size, n_embed)
self.position_embed = nn.Embedding(context_length, n_embed)
self.attn_blocks = nn.ModuleList([Block(n_head, n_embed, context_length) for _ in range(N_BLOCKS)])
self.layer_norm = nn.LayerNorm(n_embed)
self.lm_head = nn.Linear(n_embed, vocab_size)
self.register_buffer('pos_idxs', torch.arange(context_length))
def _pre_attn_pass(self, idx):
"""
合并词元嵌入和位置嵌入。
参数:
idx (torch.Tensor): 输入词元索引。
返回:
torch.Tensor: 词元嵌入与位置嵌入之和。
"""
B, T = idx.shape
tok_embedding = self.token_embed(idx)
pos_embedding = self.position_embed(self.pos_idxs[:T])
return tok_embedding + pos_embedding
def forward(self, idx, targets=None):
"""
通过Transformer的前向传播。
参数:
idx (torch.Tensor): 输入词元索引。
targets (torch.Tensor, 可选): 用于损失计算的目标词元索引。默认为None。
返回:
tuple: 逻辑值(logits)和损失(若提供目标)。
"""
x = self._pre_attn_pass(idx)
for block in self.attn_blocks:
x = block(x)
x = self.layer_norm(x)
logits = self.lm_head(x)
loss = None
if targets is not None:
B, T, C = logits.shape
flat_logits = logits.view(B * T, C)
targets = targets.view(B * T).long()
loss = F.cross_entropy(flat_logits, targets)
return logits, loss
def forward_embedding(self, idx):
"""
专注于嵌入和注意力块的前向传播。
参数:
idx (torch.Tensor): 输入词元索引。
返回:
tuple: 注意力块后的输出和残差。
"""
x = self._pre_attn_pass(idx)
residual = x
for block in self.attn_blocks:
x, residual = block.forward_embedding(x)
return x, residual
def generate(self, idx, max_new_tokens):
"""
根据起始序列生成新词元。
参数:
idx (torch.Tensor): 初始词元索引序列。
max_new_tokens (int): 需生成的词元数量。
返回:
torch.Tensor: 扩展后的词元序列。
"""
for _ in range(max_new_tokens):
idx_cond = idx[:, -self.context_length:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
我们的Transformer类__init__方法初始化了词元嵌入层(token_embed)、位置嵌入层(position_embed)、一系列Block模块(attn_blocks)、最终层归一化层(layer_norm)以及用于语言建模的线性层(lm_head)。
_pre_attn_pass方法合并词元嵌入和位置嵌入。forward方法通过嵌入层和Transformer块序列处理输入序列,应用最终层归一化并生成逻辑值;若提供目标,则计算损失。forward_embedding方法提供中间前向传播路径(至注意力块输出),generate方法实现词元生成逻辑。
批量处理
当我们使用大数据训练深度学习模型时,由于GPU资源限制,我们需要以批量(batch)方式处理数据。因此,让我们创建一个get_batch_iterator函数,该函数接收指向HDF5文件的data_path、所需的batch_size、每个序列的context_length(上下文长度),以及用于加载数据的device(设备)。
batch_size(批量大小)决定了训练过程中并行处理的序列数量,而context_length(上下文长度)指定了每个输入序列的长度。data_path(数据路径)指向训练数据的位置。
# --- Data Loading Utility ---
def get_batch_iterator(data_path, batch_size, context_length, device="gpu"):
"""
Creates an iterator for generating batches of data from an HDF5 file.
Args:
data_path (str): Path to the HDF5 file containing tokenized data.
batch_size (int): Number of sequences in each batch.
context_length (int): Length of each sequence.
device (str, optional): Device to load the data onto ('cpu' or 'cuda'). Defaults to "cpu".
Yields:
tuple: A tuple containing input sequences (xb) and target sequences (yb).
"""
# Open the HDF5 file in read mode
with h5py.File(data_path, 'r') as hdf5_file:
# Extract the dataset of tokenized sequences
dataset = hdf5_file['tokens']
# Get the total size of the dataset
dataset_size = dataset.shape[0]
# Calculate the number of examples (sequences) that can be made from the data
n_examples = (dataset_size - 1) // context_length
# Create an array of indices for examples and shuffle them for randomness
example_idxs = np.arange(n_examples)
np.random.shuffle(example_idxs)
# Initialize epoch counter and example counter
epochs = 0
counter = 0
while True:
# Check if the current batch exceeds the number of available examples
if counter + batch_size > n_examples:
# Shuffle the indices again and reset the counter to 0
np.random.shuffle(example_idxs)
counter = 0
print(f"Finished epoch {epochs}") # Print epoch number when an epoch finishes
epochs += 1 # Increment the epoch counter
# Select a batch of random indices to generate sequences
random_indices = example_idxs[counter:counter+batch_size] * context_length
# Retrieve sequences from the dataset based on the random indices
random_samples = torch.tensor(np.array([dataset[idx:idx+context_length+1] for idx in random_indices]))
# Separate the input sequences (xb) and target sequences (yb)
xb = random_samples[:, :context_length].to(device) # Input sequence (first half of the random sample)
yb = random_samples[:, 1:context_length+1].to(device) # Target sequence (second half of the random sample)
# Increment the counter to move to the next batch
counter += batch_size
# Yield the input and target sequences as a tuple for the current batch
yield xb, yb
我们的get_batch_iterator函数负责加载和批处理训练数据。它接收data_path、batch_size、context_length和device作为输入。该函数打开HDF5文件,打乱数据,然后进入一个无限循环以生成批次。在每次迭代中,它选择数据的一个随机子集来形成输入序列(xb)及其对应的目标序列(yb)。
训练参数
现在我们已经编写了模型,需要定义训练参数,例如注意力头(heads)的数量、块(blocks)的数量等,以及数据路径。
# --- Configuration ---
# Define vocabulary size and transformer configuration
VOCAB_SIZE = 50304 # Number of unique tokens in the vocabulary
CONTEXT_LENGTH = 512 # Maximum sequence length for the model
N_EMBED = 2048 # Dimension of the embedding space
N_HEAD = 16 # Number of attention heads in each transformer block
N_BLOCKS = 64 # Number of transformer blocks in the model
# Paths to training and development datasets
TRAIN_PATH = "data/train/pile_val.h5" # File path for the training dataset
DEV_PATH = "data/val/pile_val.h5" # File path for the validation dataset
# Transformer training parameters
T_BATCH_SIZE = 32 # Number of samples per training batch
T_CONTEXT_LENGTH = 16 # Context length for training batches
T_TRAIN_STEPS = 200000 # Total number of training steps
T_EVAL_STEPS = 1000 # Frequency (in steps) to perform evaluation
T_EVAL_ITERS = 250 # Number of iterations to evaluate the model
T_LR_DECAY_STEP = 50000 # Step at which to decay the learning rate
T_LR = 5e-4 # Initial learning rate for training
T_LR_DECAYED = 5e-5 # Learning rate after decay
T_OUT_PATH = "models/transformer_B.pt" # Path to save the trained model
# Device configuration
DEVICE = 'cuda'
# Store all configurations in a dictionary for easy access and modification
default_config = {
'vocab_size': VOCAB_SIZE,
'context_length': CONTEXT_LENGTH,
'n_embed': N_EMBED,
'n_head': N_HEAD,
'n_blocks': N_BLOCKS,
'train_path': TRAIN_PATH,
'dev_path': DEV_PATH,
't_batch_size': T_BATCH_SIZE,
't_context_length': T_CONTEXT_LENGTH,
't_train_steps': T_TRAIN_STEPS,
't_eval_steps': T_EVAL_STEPS,
't_eval_iters': T_EVAL_ITERS,
't_lr_decay_step': T_LR_DECAY_STEP,
't_lr': T_LR,
't_lr_decayed': T_LR_DECAYED,
't_out_path': T_OUT_PATH,
'device': DEVICE,
}
对于大多数参数,我使用了最常见的值,并将它们存储在字典中以便于访问。这里的参数适用于一个十亿参数(billion-parameter)模型。如果你想训练一个百万参数(million-parameter)模型,可以减少主要参数,包括CONTEXT_LENGTH、N_EMBED、N_HEAD和N_BLOCKS。不过,你也可以在我的GitHub仓库中运行百万参数模型的脚本。
训练模型
让我们初始化我们的Transformer模型并检查其总参数数量。
# --- Initialize the Model and Print Parameters ---
model = Transformer(
n_head=config['n_head'],
n_embed=config['n_embed'],
context_length=config['context_length'],
vocab_size=config['vocab_size'],
N_BLOCKS=config['n_blocks']
).to(config['device'])
# Print the total number of parameters
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters in the model: {total_params:,}")
#### OUTPUT ####
2,141,346,251
现在我们有了一个20亿参数的模型,需要定义Adam优化器(Adam optimizer)和损失跟踪函数(loss tracking function),这将帮助我们在整个训练过程中跟踪模型的进展。
--- 优化器设置与损失跟踪 ---
设置AdamW优化器(一种改进的Adam优化算法),使用指定学习率。
optimizer = torch.optim.AdamW(model.parameters(), lr=config['t_lr'])
用于跟踪训练过程中损失值的列表。
losses = []
在训练循环中定义用于平均近期损失的窗口大小。
AVG_WINDOW = 64
辅助函数:估算训练和开发数据的平均损失。
@torch.no_grad() def estimate_loss(steps): """ 在训练集和开发集上评估模型并计算平均损失。
Args:
steps (int): 评估的步数。
Returns:
dict: 包含'train'和'dev'数据集平均损失的字典。
"""
out = {}
model.eval() # 将模型设置为评估模式。
for split in ['train', 'dev']:
# 为当前数据集选择适当的数据路径。
data_path = config['train_path'] if split == 'train' else config['dev_path']
# 创建用于评估的批次迭代器。
batch_iterator_eval = get_batch_iterator(
data_path, config['t_batch_size'], config['t_context_length'], device=config['device']
)
# 初始化张量以跟踪每次评估步骤的损失值。
losses_eval = torch.zeros(steps)
for k in range(steps):
try:
# 获取批次数据并计算损失。
xb, yb = next(batch_iterator_eval)
_, loss = model(xb, yb)
losses_eval[k] = loss.item()
except StopIteration:
# 处理数据迭代器提前结束的情况。
print(f"警告:{split}的迭代器提前结束。")
break
# 计算当前数据集的平均损失。
out[split] = losses_eval[:k + 1].mean()
model.train() # 将模型恢复为训练模式。
return out
现在我们将初始化批次处理函数和训练循环,开始训练过程。
```python
# --- 训练循环 ---
# 为训练数据创建批次迭代器。
batch_iterator = get_batch_iterator(
config['train_path'],
config['t_batch_size'],
config['t_context_length'],
device=config['device']
)
# 创建进度条以监控训练进度。
pbar = tqdm(range(config['t_train_steps']))
for step in pbar:
try:
# 获取输入和目标数据的批次。
xb, yb = next(batch_iterator)
# 执行前向传播并计算损失。
_, loss = model(xb, yb)
# 记录损失值用于跟踪。
losses.append(loss.item())
pbar.set_description(f"训练损失:{np.mean(losses[-AVG_WINDOW:]):.4f}")
# 反向传播损失并更新模型参数。
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# 定期在训练集和开发集上评估模型。
if step % config['t_eval_steps'] == 0:
train_loss, dev_loss = estimate_loss(config['t_eval_iters']).values()
print(f"步骤:{step},训练损失:{train_loss:.4f},开发损失:{dev_loss:.4f}")
# 在指定步骤衰减学习率。
if step == config['t_lr_decay_step']:
print('衰减学习率')
for g in optimizer.param_groups:
g['lr'] = config['t_lr_decayed']
except StopIteration:
# 处理训练数据迭代器提前结束的情况。
print("训练数据迭代器提前结束。")
break
保存训练好的模型
由于我们的训练循环具备错误处理能力,若循环抛出任何错误,它将保存部分训练的模型以避免损失。训练完成后,我们可以保存训练好的模型用于后续推理。
# --- 保存模型与最终评估 ---
# 在训练集和开发集上对模型进行最终评估。
train_loss, dev_loss = estimate_loss(200).values()
# 确保模型保存路径唯一(若文件已存在)。
modified_model_out_path = config['t_out_path']
save_tries = 0
while os.path.exists(modified_model_out_path):
save_tries += 1
model_out_name = os.path.splitext(config['t_out_path'])[0]
modified_model_out_path = model_out_name + f"_{save_tries}" + ".pt"
# 保存模型状态字典、优化器状态和训练元数据。
torch.save(
{
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'losses': losses,
'train_loss': train_loss,
'dev_loss': dev_loss,
'steps': len(losses),
},
modified_model_out_path
)
print(f"模型已保存至 {modified_model_out_path}")
print(f"训练完成。训练损失:{train_loss:.4f},开发损失:{dev_loss:.4f}")
十亿参数模型的最终训练损失为0.2314,开发损失为0.643。
训练损失分析
当绘制百万参数和十亿参数模型的损失曲线时,它们呈现出显著差异。
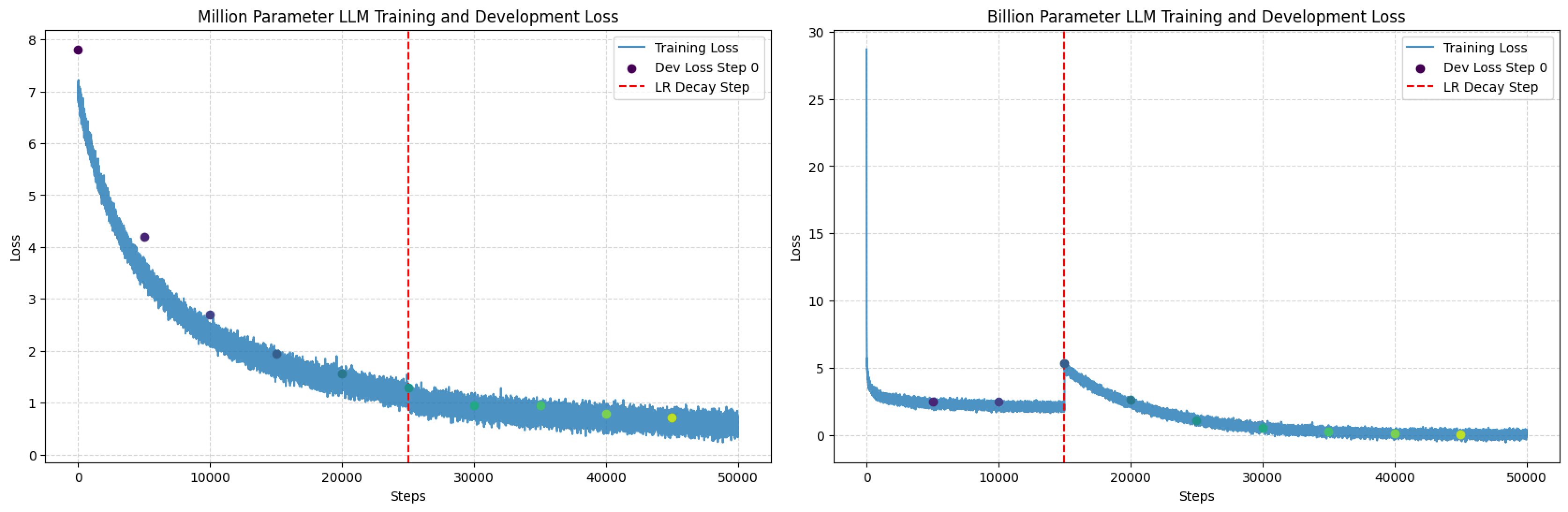
十亿参数模型初始损失较高,且初期波动剧烈。损失值起初快速下降,随后出现震荡,最终趋于平稳。这表明大型模型在训练初期更难找到合适的学习路径,可能需要更多数据和精细的参数设置。当学习率降低(红线处)时,损失值更平稳地下降,说明这有助于模型进行微调。
百万参数模型的损失从开始就更平稳地下降,波动幅度远小于大型模型。学习率衰减对其曲线影响较小,可能是因为小型模型结构更简单,能更快找到优质解。这种显著差异揭示了训练超大规模模型的难度——它们需要不同的训练策略,可能还需要更长时间才能充分学习。
现在我们已保存好模型,终于可以将其用于推理并观察文本生成效果了。 😓
文本生成
让我们创建一个函数,从保存的模型生成文本。该函数接收模型路径和编码器(encoder)作为输入,并返回生成的文本。
def generate_text(model_path, input_text, max_length=512, device="gpu"):
"""
使用预训练模型基于给定输入文本生成文本。
参数:
- model_path (str): 模型检查点路径。
- device (torch.device): 模型加载设备(例如 'cpu' 或 'cuda')。
- input_text (str): 用于启动生成的输入文本。
- max_length (int, 可选): 生成文本的最大长度。默认为 512。
返回:
- str: 生成的文本。
"""
# 加载模型检查点
checkpoint = torch.load(model_path)
# 初始化模型(需确保 Transformer 类已在其他地方定义)
model = Transformer().to(device)
# 加载模型的状态字典
model.load_state_dict(checkpoint['model_state_dict'])
# 加载 GPT 模型的分词器(对 GPT 模型使用 'r50k_base')
enc = tiktoken.get_encoding('r50k_base')
# 对输入文本及文本结束符进行编码
input_ids = torch.tensor(
enc.encode(input_text, allowed_special={'<|endoftext|>'}),
dtype=torch.long
)[None, :].to(device) # 添加批次维度并移至指定设备
# 使用编码后的输入通过模型生成文本
with torch.no_grad():
# 生成最多 'max_length' 个 token 的文本
generated_output = model.generate(input_ids, max_length)
# 将生成的 token 解码回文本
generated_text = enc.decode(generated_output[0].tolist())
return generated_text
此处需要调用先前定义的 Transformer(变换器)来加载架构,然后将保存的模型作为该架构的状态加载。
首先观察百万参数和十亿参数模型在不提供任何输入时的生成结果,查看其随机生成内容。
# 定义预训练模型的文件路径
Billion_model_path = 'models/transformer_B.pt' # 十亿参数模型路径
Million_model_path = 'models/transformer_M.pt' # 百万参数模型路径
# 使用 '<|endoftext|>' 作为模型输入(作为允许模型自由生成文本的提示)
input_text = "<|endoftext|>"
# 调用函数使用十亿参数模型基于输入文本生成文本
B_output = generate_text(Billion_model_path, input_text)
# 调用函数使用百万参数模型基于输入文本生成文本
M_output = generate_text(Million_model_path, input_text)
# 打印两个模型生成的输出
print(B_output) # 十亿参数模型输出
print(M_output) # 百万参数模型输出
| 百万参数模型输出 | 十亿参数模型输出 |
|---|---|
| 1978 年,公园被归还给工厂,公众共享电子围栏的下部,该围栏源自车站所在城市。古代西方国家的运河局限于城市区域。村庄与中国城市直接相连,这些城市反抗美国预算,而 Odambinais 的情况不确定,农村地区已建立财富。 | 东海岸距 1037 年有两英里,7300 万难民(假设)与哈佛和克罗夫特的男性相同。在地中海东部和尼罗河西岸的喷气式飞机上。发现那里有许多政党、铁匠、音乐家和精品酒店业,激励着加拿大人已造成的压力,农村分支与联盟铁路持有者对抗 Abyssy。 |
当上下文简短简单时,两个大语言模型(LLM)都能生成清晰准确的语句。例如,在百万参数模型输出中,“村庄与中国城市直接相连” 这一表述合理且传达了明确含义,易于理解且逻辑连贯。
然而,当上下文变长变复杂时,清晰度开始下降。在十亿参数模型输出中,类似 “东海岸距 1037 年有两英里,7300 万难民(假设)” 和 “铁匠、音乐家和精品酒店业激励着加拿大人已造成的压力” 的句子变得难以理解。观点显得支离破碎,句式结构不自然。尽管用词可能正确,但整体含义变得混乱不清。
积极的一面是,1300 万+ 参数的大语言模型也开始生成具有一定意义且拼写正确的内容。例如,当我使用主题输入文本时,它开始为我生成邮件。虽然显然更长的文本无法提供有意义的结果,但请看以下输出:
# 输入文本
input_text = "Subject: "
# 调用百万参数模型
m_output = generate_text(Million_model_path, input_text)
print(m_output) # 百万参数模型输出
| 百万参数大语言模型输出 |
|---|
| Subject: ClickPaper-summary Study for Interview 早上好,希望这条消息送达时您安好,阳光温柔地透过云层,... |
我们的百万参数模型表明,我们可以拥有一个规模小于 10 亿、目标导向明确的窄域大语言模型;而我们的十亿参数训练模型则表明,架构必须经过深度编码并充分考虑。否则,与百万参数模型相比,它不会提升训练效果或性能,只会导致数据过拟合,除非为十亿级模型设计深度架构。
后续步骤
建议您先创建 1300 万+ 参数的模型,然后通过增加后续 100 个参数逐步扩展,提升其处理短上下文的能力。您可以根据特定任务需求决定训练更多参数的数量。接着,对于 10 亿以下的剩余参数,尝试在特定领域数据(如撰写邮件或论文)上微调模型,并观察其文本生成效果。
想交流?我的 LinkedIn
Star 历史

相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。