awesome-production-machine-learning
awesome-production-machine-learning 是一个专注于机器学习工程化的精选开源资源目录。它汇集了众多优秀的开源库,协助开发者完成模型的部署、监控、版本管理及规模化扩展。面对机器学习模型从实验室走向生产环境时的复杂挑战,这个列表有效解决了工具链碎片化和选型困难的问题。
无论是机器学习工程师、数据科学家还是负责 AI 系统落地的开发者,都能从中受益。内容覆盖范围极广,包括自动机器学习、数据管道优化、模型服务化、可解释性以及隐私安全等关键环节。特别值得一提的是,项目提供了便捷的搜索工具,帮助用户快速导航庞大的工具链。社区保持高频更新,每月发布新版本摘要,确保收录的技术始终处于行业前沿。对于正在构建稳定可靠 AI 应用团队而言,这不仅是工具箱,更是通往高效 MLOps 实践的路线图。
使用场景
某金融科技公司的算法团队正在将核心欺诈检测模型从实验环境迁移至生产环境,急需构建稳定可靠的 MLOps 全流程。
没有 awesome-production-machine-learning 时
- 工程师需在海量的 GitHub 项目中盲目筛选,耗费数周评估各库的维护状态与兼容性。
- 缺乏系统化的监控方案,模型上线后出现数据漂移却迟迟未能发现,导致业务损失。
- 实验记录分散在本地 Notebook 中,模型版本与代码版本脱节,难以追溯和复现历史结果。
- 安全与隐私合规工具缺失,面临潜在的数据泄露风险且不知如何加固。
使用 awesome-production-machine-learning 后
- 直接查阅 awesome-production-machine-learning 分类目录,快速锁定经过社区验证的部署、监控及版本管理工具,选型效率提升 80%。
- 采用推荐的监控解决方案,实现对模型预测分布的实时追踪,异常波动秒级告警。
- 引入列表中的实验管理平台,统一存储模型元数据与代码快照,确保每次迭代可审计。
- 依据隐私与安全板块建议,集成加密与脱敏库,满足金融行业的合规要求。
这份精选清单通过聚合工业级最佳实践,帮助团队规避技术陷阱,大幅缩短模型从开发到上线的周期。
运行环境要求
- 未说明
未说明
未说明
快速开始
![]()
优秀生产级机器学习
本仓库包含一份精心策划的开源库列表,将帮助您部署、监控、版本控制、扩展和保障您的生产级机器学习 🚀
您可以通过关注此 GitHub 仓库来保持更新,每月通过 发布 获取新增的生产级机器学习 (Machine Learning, ML) 库摘要 🤩
此外,我们提供了一个 搜索工具包,帮助您快速浏览工具链。
本页各章节的快速链接
贡献列表
提交 PR 时请查看我们的 CONTRIBUTING.md 要求,以帮助我们保持列表整洁和最新 - 感谢社区支持其稳步增长 🚀

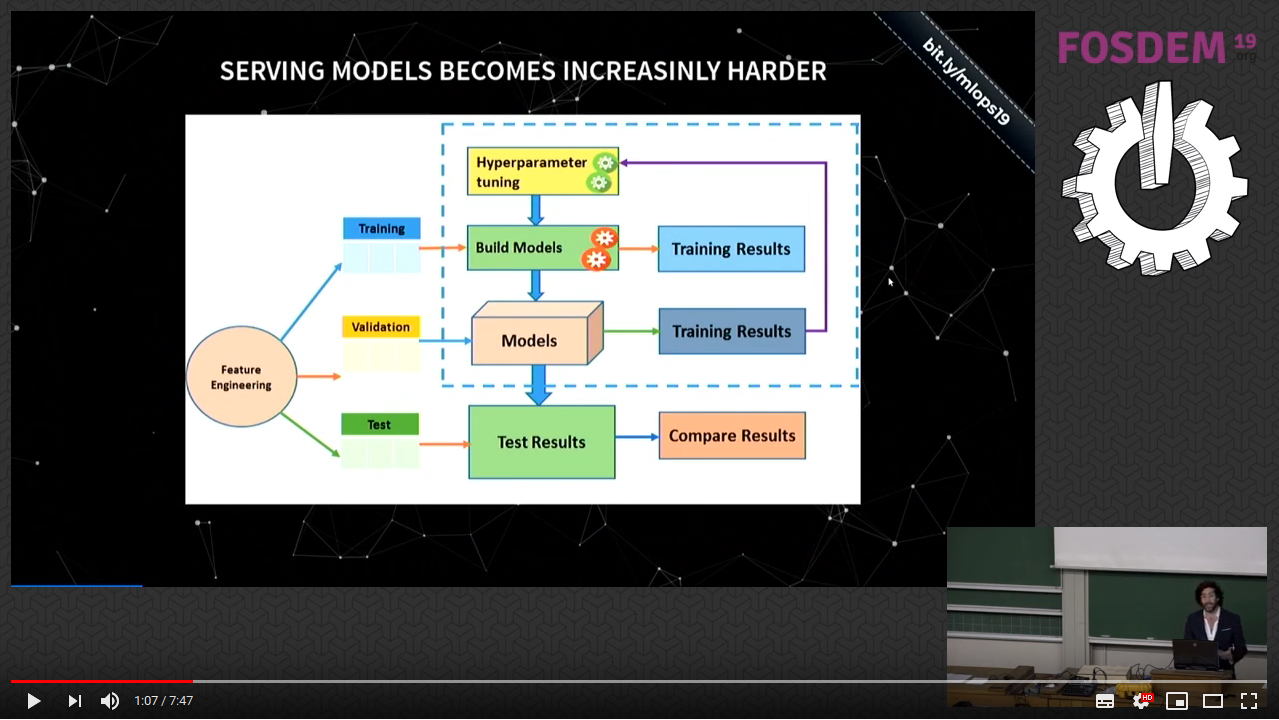
10 分钟视频概览
| 这 10 分钟视频 提供了机器学习运维 (MLOps) 的动机概述,以及对本仓库中部分工具的高层次介绍。这 较新的视频 涵盖了更新后的 2024 年 MLOps 现状。 |
|
想要接收关于此仓库及其他进展的定期更新?
| 您可以加入 [Machine Learning Engineer](https://ethical.institute/mle.html) 通讯。加入超过 70,000 名机器学习专业人士和爱好者,他们每周收到关于生产级机器学习的精选文章和教程。 |

|
| 同时请查看 [Awesome Production GenAI](https://github.com/EthicalML/awesome-production-genai/) 列表,我们旨在映射一份精选的开源库列表,用于部署、监控、版本控制和扩展您的生成式人工智能 (Generative AI) 应用和系统。 |
|
主要内容
自动机器学习 (AutoML)
- AIDE
 - AIDE 是一个开源的机器学习工程代理,使用树搜索算法自主探索、实施和评估机器学习任务的解决方案策略。
- AIDE 是一个开源的机器学习工程代理,使用树搜索算法自主探索、实施和评估机器学习任务的解决方案策略。 - AutoGluon
 - 基于流行的机器学习库(Scikit-Learn, LightGBM, CatBoost, PyTorch, MXNet),为表格、图像和文本数据提供自动化的特征、模型和超参数选择。
- 基于流行的机器学习库(Scikit-Learn, LightGBM, CatBoost, PyTorch, MXNet),为表格、图像和文本数据提供自动化的特征、模型和超参数选择。 - Autokeras
 - 基于 "Auto-Keras: Efficient Neural Architecture Search with Network Morphism" 的 Keras 自动机器学习库。
- 基于 "Auto-Keras: Efficient Neural Architecture Search with Network Morphism" 的 Keras 自动机器学习库。 - auto-sklearn
 - 用于自动化 sklearn 算法和超参数调优的框架。
- 用于自动化 sklearn 算法和超参数调优的框架。 - Ax
 - Ax 是一个易于访问的通用平台,用于理解、管理、部署和自动化自适应实验。
- Ax 是一个易于访问的通用平台,用于理解、管理、部署和自动化自适应实验。 - BoTorch
 - BoTorch 是一个基于 PyTorch 构建的贝叶斯优化库。
- BoTorch 是一个基于 PyTorch 构建的贝叶斯优化库。 - EvalML
 - EvalML 是一个自动机器学习库,它使用领域特定目标函数来构建、优化和评估机器学习流水线。
- EvalML 是一个自动机器学习库,它使用领域特定目标函数来构建、优化和评估机器学习流水线。 - Feature Engine
 - Feature-engine 是一个 Python 库,包含多个转换器,用于为机器学习模型构建特征。
- Feature-engine 是一个 Python 库,包含多个转换器,用于为机器学习模型构建特征。 - Featuretools
 - 一个用于自动化特征工程的开源框架。
- 一个用于自动化特征工程的开源框架。 - FLAML
 - FLAML 是一个用于自动机器学习和调优的快速库。
- FLAML 是一个用于自动机器学习和调优的快速库。 - HEBO
 - 一组开源超参数优化框架,包括在超参数调优任务上测试的 NeurIPS 2020 黑盒优化挑战 获胜提交方案。
- 一组开源超参数优化框架,包括在超参数调优任务上测试的 NeurIPS 2020 黑盒优化挑战 获胜提交方案。 - Katib
 - 一个基于 Kubernetes 的超参数调优和神经架构搜索系统。
- 一个基于 Kubernetes 的超参数调优和神经架构搜索系统。 - keras-tuner
 - Keras Tuner 是一个易于使用、可分发的超参数优化框架,解决了执行超参数搜索的痛点。Keras Tuner 使得定义搜索空间并利用内置算法找到最佳超参数值变得简单。
- Keras Tuner 是一个易于使用、可分发的超参数优化框架,解决了执行超参数搜索的痛点。Keras Tuner 使得定义搜索空间并利用内置算法找到最佳超参数值变得简单。 - Optuna
 - Optuna 是一个自动超参数优化软件框架,特别针对机器学习设计。
- Optuna 是一个自动超参数优化软件框架,特别针对机器学习设计。 - OSS Vizier
 - OSS Vizier 是一个基于 Python 的黑盒优化和研究服务,是首批专为大规模工作设计的超参数调优服务之一。
- OSS Vizier 是一个基于 Python 的黑盒优化和研究服务,是首批专为大规模工作设计的超参数调优服务之一。 - Perpetual
 - 一种不需要超参数优化的梯度提升机,具有一个简单的预算参数来控制模型复杂度。
- 一种不需要超参数优化的梯度提升机,具有一个简单的预算参数来控制模型复杂度。 - TPOT
 - 自动化 sklearn 流水线创建(包括特征选择、预处理等)。
- 自动化 sklearn 流水线创建(包括特征选择、预处理等)。 - tsfresh
 - 从时间序列中自动提取相关特征。
- 从时间序列中自动提取相关特征。
计算与通信优化
- Accelerate
 - Accelerate 抽象并仅抽象与多 GPU(图形处理器)/TPU(张量处理单元)/mixed-precision(混合精度)相关的样板代码,并保持其余代码不变。
- Accelerate 抽象并仅抽象与多 GPU(图形处理器)/TPU(张量处理单元)/mixed-precision(混合精度)相关的样板代码,并保持其余代码不变。 - Adapters

 - Adapters 是一个用于参数高效和模块化 transfer learning(迁移学习)的统一库。
- Adapters 是一个用于参数高效和模块化 transfer learning(迁移学习)的统一库。 - BitBLAS
 - BitBLAS 是一个支持在 GPU 上进行 mixed-precision(混合精度)BLAS(基本线性代数子程序)操作的库。
- BitBLAS 是一个支持在 GPU 上进行 mixed-precision(混合精度)BLAS(基本线性代数子程序)操作的库。 - Colossal-AI
 - 面向大模型时代的统一深度学习系统,帮助用户高效快速地部署大型 AI 模型训练和推理。
- 面向大模型时代的统一深度学习系统,帮助用户高效快速地部署大型 AI 模型训练和推理。 - Composer
 - Composer 是一个 PyTorch 库,使您能够以更低的成本、更高的速度、更高的准确率训练神经网络。
- Composer 是一个 PyTorch 库,使您能够以更低的成本、更高的速度、更高的准确率训练神经网络。 - CuDF
 - 基于 Apache Arrow 列式内存格式构建,cuDF 是一个 GPU DataFrame(数据框)库,用于加载、连接、聚合、过滤以及操纵数据。
- 基于 Apache Arrow 列式内存格式构建,cuDF 是一个 GPU DataFrame(数据框)库,用于加载、连接、聚合、过滤以及操纵数据。 - CuML
 - cuML 是一套实现机器学习算法和数学原始函数的库,与其他 RAPIDS 项目共享兼容的 APIs(应用程序接口)。
- cuML 是一套实现机器学习算法和数学原始函数的库,与其他 RAPIDS 项目共享兼容的 APIs(应用程序接口)。 - CuPy
 - 在 CUDA 上实现的 NumPy 兼容的多维数组。CuPy 由核心多维数组类 cupy.ndarray 及其上的许多函数组成。
- 在 CUDA 上实现的 NumPy 兼容的多维数组。CuPy 由核心多维数组类 cupy.ndarray 及其上的许多函数组成。 - DEAP
 - 一种新颖的进化计算框架,用于快速原型设计和测试想法。它旨在使算法显式化并使数据结构透明化。它与 multiprocessing(多进程)和 SCOOP 等并行化机制完美协作。
- 一种新颖的进化计算框架,用于快速原型设计和测试想法。它旨在使算法显式化并使数据结构透明化。它与 multiprocessing(多进程)和 SCOOP 等并行化机制完美协作。 - DeepEP
 - DeepEP 是专为 Mixture-of-Experts(MoE,专家混合模型)和 expert parallelism(EP,专家并行)定制的通信库。它提供高吞吐量和低延迟的 all-to-all GPU 内核,也称为 MoE dispatch(分发)和 combine(合并)。该库还支持低精度操作,包括 FP8。
- DeepEP 是专为 Mixture-of-Experts(MoE,专家混合模型)和 expert parallelism(EP,专家并行)定制的通信库。它提供高吞吐量和低延迟的 all-to-all GPU 内核,也称为 MoE dispatch(分发)和 combine(合并)。该库还支持低精度操作,包括 FP8。 - DGL
 - DGL 是一个易于使用、高性能且可扩展的 Python 包,用于图上的深度学习。
- DGL 是一个易于使用、高性能且可扩展的 Python 包,用于图上的深度学习。 - DLRover
 - DLRover 使大型 AI 模型的分布式训练变得简单、稳定、快速和绿色。
- DLRover 使大型 AI 模型的分布式训练变得简单、稳定、快速和绿色。 - Dask
 - Pandas 和 NumPy 计算的分布式并行处理框架。
- Pandas 和 NumPy 计算的分布式并行处理框架。 - DeepSpeed
 - DeepSpeed 是一个深度学习优化库,使分布式训练和推理变得简单、高效和有效。
- DeepSpeed 是一个深度学习优化库,使分布式训练和推理变得简单、高效和有效。 - FlagGems
 - FlagGems 是用 OpenAI Triton 实现的高性能通用算子库。它建立在一系列后端中立内核之上,旨在加速跨不同硬件平台的 LLM(大型语言模型)训练和推理。
- FlagGems 是用 OpenAI Triton 实现的高性能通用算子库。它建立在一系列后端中立内核之上,旨在加速跨不同硬件平台的 LLM(大型语言模型)训练和推理。 - Flashlight
 - 一个完全用 C++ 编写的快速、灵活的机器学习库,来自 Facebook AI Research 以及 Torch、TensorFlow、Eigen 和 Deep Speech 的创作者。
- 一个完全用 C++ 编写的快速、灵活的机器学习库,来自 Facebook AI Research 以及 Torch、TensorFlow、Eigen 和 Deep Speech 的创作者。 - Flax
 - 为灵活性而设计的 JAX 神经网络库和生态系统。
- 为灵活性而设计的 JAX 神经网络库和生态系统。 - GPUStack
 - GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
- GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。 - Hivemind
 - PyTorch 中的去中心化深度学习。
- PyTorch 中的去中心化深度学习。 - Horovod
 - Uber 的分布式训练框架,适用于 TensorFlow、Keras 和 PyTorch。
- Uber 的分布式训练框架,适用于 TensorFlow、Keras 和 PyTorch。 - Jax
 - Python+NumPy 程序的组合转换:微分、向量化、JIT 到 GPU/TPU 等。
- Python+NumPy 程序的组合转换:微分、向量化、JIT 到 GPU/TPU 等。 - Kompute
 - 极速、轻量且支持移动端的 Vulkan 计算框架,针对高级 GPU 数据处理用例进行了优化。
- 极速、轻量且支持移动端的 Vulkan 计算框架,针对高级 GPU 数据处理用例进行了优化。 - Lava
 - Lava 是一个开源框架,用于开发适用于神经形态硬件架构的应用程序。
- Lava 是一个开源框架,用于开发适用于神经形态硬件架构的应用程序。 - Liger Kernel
 - Liger Kernel 是一组专门为 LLM 训练设计的 Triton 内核。
- Liger Kernel 是一组专门为 LLM 训练设计的 Triton 内核。 - LightGBM
 - LightGBM 是一种使用基于树的算法的梯度提升框架。
- LightGBM 是一种使用基于树的算法的梯度提升框架。 - MLX
 - MLX 是用于 Apple Silicon 机器学习的数组框架。
- MLX 是用于 Apple Silicon 机器学习的数组框架。 - Modin
 - 通过更改一行代码来加速您的 Pandas 工作流。
- 通过更改一行代码来加速您的 Pandas 工作流。 - NVIDIA TensorRT
 - TensorRT 是一个用于 NVIDIA GPU 和深度学习加速器上进行高性能推理的 C++ 库。
- TensorRT 是一个用于 NVIDIA GPU 和深度学习加速器上进行高性能推理的 C++ 库。 - Nevergrad
 - Nevergrad 是一个无梯度优化平台。
- Nevergrad 是一个无梯度优化平台。 - Norse
 - Norse 旨在利用生物启发式神经组件的优势,它们是稀疏的和事件驱动的——这与人工神经网络有根本区别。
- Norse 旨在利用生物启发式神经组件的优势,它们是稀疏的和事件驱动的——这与人工神经网络有根本区别。 - Numba
 - 用于 Python 数组和数值函数的编译器。
- 用于 Python 数组和数值函数的编译器。 - Optimum
 - Optimum 是 Transformers 和 Diffusers 的扩展,提供一组优化工具,使在目标硬件上训练和运行模型达到最大效率,同时保持易用性。
- Optimum 是 Transformers 和 Diffusers 的扩展,提供一组优化工具,使在目标硬件上训练和运行模型达到最大效率,同时保持易用性。 - PEFT
 - Parameter-Efficient Fine-Tuning(PEFT,参数高效微调)方法使预训练语言模型(PLM,预训练语言模型)能够高效适应各种下游应用,而无需微调模型的所有参数。
- Parameter-Efficient Fine-Tuning(PEFT,参数高效微调)方法使预训练语言模型(PLM,预训练语言模型)能够高效适应各种下游应用,而无需微调模型的所有参数。 - PaddlePaddle
 - PaddlePaddle 是一个用于跨数百个节点分布的数据源进行大规模深度网络训练的框架。
- PaddlePaddle 是一个用于跨数百个节点分布的数据源进行大规模深度网络训练的框架。 - PyG
 - PyG(PyTorch Geometric)是一个基于 PyTorch 的库,用于轻松编写和训练图神经网络(GNN,图神经网络),适用于广泛的与结构化数据相关的应用。
- PyG(PyTorch Geometric)是一个基于 PyTorch 的库,用于轻松编写和训练图神经网络(GNN,图神经网络),适用于广泛的与结构化数据相关的应用。 - PyTorch Lightning
 - PyTorch Lightning 可在多个 GPU、TPU 上预训练、微调并部署 AI 模型,无需更改代码。
- PyTorch Lightning 可在多个 GPU、TPU 上预训练、微调并部署 AI 模型,无需更改代码。 - PyTorch
 - PyTorch 是一个用于开发和训练基于神经网络的深度学习模型的库。
- PyTorch 是一个用于开发和训练基于神经网络的深度学习模型的库。 - Ray
 - Ray 是一个灵活、高性能的机器学习分布式执行框架。
- Ray 是一个灵活、高性能的机器学习分布式执行框架。 - SetFit
 - SetFit 是一个高效且无需提示的 Sentence Transformers 少样本微调框架。
- SetFit 是一个高效且无需提示的 Sentence Transformers 少样本微调框架。 - Sonnet
 - Sonnet 是一个基于 TensorFlow 2 构建的库,旨在为机器学习研究提供简单、可组合的抽象。
- Sonnet 是一个基于 TensorFlow 2 构建的库,旨在为机器学习研究提供简单、可组合的抽象。 - Streaming
 - 用于高效神经网络训练的数据流式传输库。
- 用于高效神经网络训练的数据流式传输库。 - TensorFlow
 - TensorFlow 是一个领先的库,旨在开发和部署最先进的机器学习应用程序。
- TensorFlow 是一个领先的库,旨在开发和部署最先进的机器学习应用程序。 - ThunderKittens
 ThunderKittens 是一个框架,使在 CUDA 中编写快速深度学习内核变得容易。
ThunderKittens 是一个框架,使在 CUDA 中编写快速深度学习内核变得容易。 - TorchOpt
 - TorchOpt 是一个基于 PyTorch 的高效可微优化库。
- TorchOpt 是一个基于 PyTorch 的高效可微优化库。 - Triton
 - Triton 是一种语言和编译器,用于编写高效的自定义深度学习原语。Triton 的目标是提供一个开源环境,以比 CUDA 更高的生产力编写快速代码,同时也比其他现有的 DSL(领域特定语言)具有更高的灵活性。
- Triton 是一种语言和编译器,用于编写高效的自定义深度学习原语。Triton 的目标是提供一个开源环境,以比 CUDA 更高的生产力编写快速代码,同时也比其他现有的 DSL(领域特定语言)具有更高的灵活性。 - Vaex
 Vaex 是一个高性能 Python 库,用于惰性 Out-of-Core(外存)DataFrames(类似于 Pandas),用于可视化和探索大型表格数据集。Vaex 使用内存映射、零内存拷贝策略和惰性计算以获得最佳性能(不浪费内存)。
Vaex 是一个高性能 Python 库,用于惰性 Out-of-Core(外存)DataFrames(类似于 Pandas),用于可视化和探索大型表格数据集。Vaex 使用内存映射、零内存拷贝策略和惰性计算以获得最佳性能(不浪费内存)。 - Vowpal Wabbit
 Vowpal Wabbit 是一个机器学习系统,通过在线、哈希、allreduce、归约、learning2search、主动和交互式学习等技术推动机器学习的前沿。
Vowpal Wabbit 是一个机器学习系统,通过在线、哈希、allreduce、归约、learning2search、主动和交互式学习等技术推动机器学习的前沿。 - XGBoost
 - XGBoost 是一个优化的分布式梯度提升库,设计为高效、灵活和便携。
- XGBoost 是一个优化的分布式梯度提升库,设计为高效、灵活和便携。 - YDF
 - YDF(Yggdrasil Decision Forests)是一个用于训练、评估、解释和部署随机森林、梯度提升决策树、CART(分类与回归树)和孤立森林模型的库。
- YDF(Yggdrasil Decision Forests)是一个用于训练、评估、解释和部署随机森林、梯度提升决策树、CART(分类与回归树)和孤立森林模型的库。 - bitsandbytes
 - Bitsandbytes 库是一个围绕 CUDA 自定义函数的轻量级 Python 封装,特别是 8 位优化器、矩阵乘法(LLM.int8())和 8 & 4 位量化函数。
- Bitsandbytes 库是一个围绕 CUDA 自定义函数的轻量级 Python 封装,特别是 8 位优化器、矩阵乘法(LLM.int8())和 8 & 4 位量化函数。 - einops
 - 用于可读和可靠代码的灵活强大的张量操作。
- 用于可读和可靠代码的灵活强大的张量操作。 - scikit-learn
 - Scikit-learn 是一个功能强大的机器学习库,提供广泛的数据访问、数据准备和统计模型构建模块。
- Scikit-learn 是一个功能强大的机器学习库,提供广泛的数据访问、数据准备和统计模型构建模块。 - snnTorch
 - snnTorch 是一个带有脉冲神经网络的深度和在线学习库。
- snnTorch 是一个带有脉冲神经网络的深度和在线学习库。 - torchdistill
 - torchdistill 提供各种最先进的知识蒸馏方法,并允许您只需编辑声明式 yaml 配置文件而非 Python 代码即可设计(新的)实验。
- torchdistill 提供各种最先进的知识蒸馏方法,并允许您只需编辑声明式 yaml 配置文件而非 Python 代码即可设计(新的)实验。 - torchkeras
 torchkeras 库是一个简单的工具,用于以 Keras 风格在 PyTorch 中训练神经网络。
torchkeras 库是一个简单的工具,用于以 Keras 风格在 PyTorch 中训练神经网络。 - veScale
 - veScale 是一个 PyTorch 原生的 LLM 训练框架。
- veScale 是一个 PyTorch 原生的 LLM 训练框架。 - yellowbrick
 - yellowbrick 是一个基于 matplotlib 的 scikit-learn 和其他机器学习库的模型评估图表。
- yellowbrick 是一个基于 matplotlib 的 scikit-learn 和其他机器学习库的模型评估图表。
数据标注与合成
- Argilla
 - Argilla 帮助领域专家和数据团队在更短的时间内构建更好的 NLP(自然语言处理)数据集。
- Argilla 帮助领域专家和数据团队在更短的时间内构建更好的 NLP(自然语言处理)数据集。 - cleanlab
 - 面向数据驱动的 AI(人工智能)的 Python 库。可自动:查找错误标记的数据、检测异常值、评估多标注者数据集的一致性和标注者质量,并建议下一步最适合(重新)标记的数据。
- 面向数据驱动的 AI(人工智能)的 Python 库。可自动:查找错误标记的数据、检测异常值、评估多标注者数据集的一致性和标注者质量,并建议下一步最适合(重新)标记的数据。 - COCO Annotator
 - 基于 Web 的图像分割工具,用于目标检测、定位和关键点识别
- 基于 Web 的图像分割工具,用于目标检测、定位和关键点识别 - CVAT
 - CVAT(计算机视觉标注工具)是 OpenCV 的基于 Web 的标注工具,适用于计算机算法的视频和图像。
- CVAT(计算机视觉标注工具)是 OpenCV 的基于 Web 的标注工具,适用于计算机算法的视频和图像。 - Doccano
 - 供人类使用的开源文本标注工具,提供情感分析、命名实体识别和机器翻译功能。
- 供人类使用的开源文本标注工具,提供情感分析、命名实体识别和机器翻译功能。 - Gretel Synthetics
 - Gretel Synthetics 是一个结构化和非结构化文本的合成数据生成器,具有差分隐私学习特性。
- Gretel Synthetics 是一个结构化和非结构化文本的合成数据生成器,具有差分隐私学习特性。 - Label Studio
 - 支持多领域的标准化输出格式数据标注工具。
- 支持多领域的标准化输出格式数据标注工具。 - NeMo Curator
 - NeMo Curator 是一个 GPU(图形处理器)加速框架,用于高效的大语言模型(LLM)数据策展。
- NeMo Curator 是一个 GPU(图形处理器)加速框架,用于高效的大语言模型(LLM)数据策展。 - refinery
 - 数据科学家扩展、评估和维护自然语言数据的开源选择。
- 数据科学家扩展、评估和维护自然语言数据的开源选择。 - SDV
 - 合成数据仓库(Synthetic Data Vault,SDV)是一个合成数据生成库生态系统,允许用户轻松学习单表、多表和时间序列数据集,以便随后生成具有与原始数据集相同格式和统计特性的新合成数据。
- 合成数据仓库(Synthetic Data Vault,SDV)是一个合成数据生成库生态系统,允许用户轻松学习单表、多表和时间序列数据集,以便随后生成具有与原始数据集相同格式和统计特性的新合成数据。 - Semantic Segmentation Editor
 - 日立公司用于标注相机和 LIDAR(激光雷达)数据的开源工具。
- 日立公司用于标注相机和 LIDAR(激光雷达)数据的开源工具。 - synthcity
 - synthcity 是一个用于生成和评估合成表格数据的库。
- synthcity 是一个用于生成和评估合成表格数据的库。 - TabGAN
 - 使用 GANs(生成对抗网络)(CTGAN)、扩散模型和 LLMs(大语言模型)进行合成表格数据生成,具备对抗过滤、隐私指标和 sklearn 集成。
- 使用 GANs(生成对抗网络)(CTGAN)、扩散模型和 LLMs(大语言模型)进行合成表格数据生成,具备对抗过滤、隐私指标和 sklearn 集成。 - ViPE
 - ViPE 是一种空间 AI 工具,用于从原始视频中标注相机姿态和密集深度图。
- ViPE 是一种空间 AI 工具,用于从原始视频中标注相机姿态和密集深度图。 - YData Synthetic
 - YData Synthetic 是一个利用最先进生成模型来生成合成表格和时间序列数据的包。
- YData Synthetic 是一个利用最先进生成模型来生成合成表格和时间序列数据的包。
数据流水线
- Apache Airflow
 - 基于 Python 构建的数据流水线框架,包括调度器、DAG(有向无环图)定义和用于可视化的 UI。
- 基于 Python 构建的数据流水线框架,包括调度器、DAG(有向无环图)定义和用于可视化的 UI。 - Apache Nifi
 - Apache NiFi 专为数据流而设计。它支持高度可配置的数据路由、转换和系统中介逻辑的有向图。
- Apache NiFi 专为数据流而设计。它支持高度可配置的数据路由、转换和系统中介逻辑的有向图。 - Apache Oozie
 - Hadoop 作业的工作流调度器。
- Hadoop 作业的工作流调度器。 - Argo Workflows
 - 用于在 Kubernetes 上编排并行作业的开源容器原生工作流引擎。Argo Workflows 实现为 Kubernetes CRD(自定义资源定义)。
- 用于在 Kubernetes 上编排并行作业的开源容器原生工作流引擎。Argo Workflows 实现为 Kubernetes CRD(自定义资源定义)。 - Couler
 - 在不同工作流引擎(如 Argo Workflows、Tekton Pipelines 和 Apache Airflow)上构建和管理机器学习工作流的统一接口。
- 在不同工作流引擎(如 Argo Workflows、Tekton Pipelines 和 Apache Airflow)上构建和管理机器学习工作流的统一接口。 - DataTrove
 - DataTrove 是一个用于在超大规模下处理、过滤和去重文本数据的库。
- DataTrove 是一个用于在超大规模下处理、过滤和去重文本数据的库。 - Dagster
 - 面向机器学习、分析和 ETL(提取、转换、加载)的数据编排工具。
- 面向机器学习、分析和 ETL(提取、转换、加载)的数据编排工具。 - DBT
 - 用于在数据仓库内运行转换的 ETL 工具。
- 用于在数据仓库内运行转换的 ETL 工具。 - Flyte
 - Lyft 的云原生机器学习和数据处理平台 - (演示)。
- Lyft 的云原生机器学习和数据处理平台 - (演示)。 - Genie
 - 作业编排引擎,用于接口并触发基于 Hadoop 系统的作业执行。
- 作业编排引擎,用于接口并触发基于 Hadoop 系统的作业执行。 - Hamilton
 - 用于定义数据流的微编排框架。在任何 Python 运行的地方运行(例如 jupyter, fastAPI, spark, ray, dask)。在不被察觉的情况下引入软件工程最佳实践。用它来定义特征工程转换、端到端模型流水线以及 LLM(大型语言模型)工作流。它补充了宏观编排系统(例如 kedro, luigi, airflow, dbt 等),因为它替换了这些宏任务内的代码。自带可自托管的 UI,捕获血缘与溯源、执行遥测和数据摘要,并构建自填充目录;既可用于开发也可用于生产。
- 用于定义数据流的微编排框架。在任何 Python 运行的地方运行(例如 jupyter, fastAPI, spark, ray, dask)。在不被察觉的情况下引入软件工程最佳实践。用它来定义特征工程转换、端到端模型流水线以及 LLM(大型语言模型)工作流。它补充了宏观编排系统(例如 kedro, luigi, airflow, dbt 等),因为它替换了这些宏任务内的代码。自带可自托管的 UI,捕获血缘与溯源、执行遥测和数据摘要,并构建自填充目录;既可用于开发也可用于生产。 - Instill VDP
 - Instill VDP(多功能数据流水线)旨在简化从开始到完成的数据处理流水线。
- Instill VDP(多功能数据流水线)旨在简化从开始到完成的数据处理流水线。 - Instructor
 - Instructor 让从 GPT-3.5、GPT-4、GPT-4-Vision 和开源模型等 LLM 获取结构化数据(如 JSON)变得简单。
- Instructor 让从 GPT-3.5、GPT-4、GPT-4-Vision 和开源模型等 LLM 获取结构化数据(如 JSON)变得简单。 - Kedro
 - Kedro 是一种工作流开发工具,帮助您构建稳健、可扩展、可部署、可复现且版本化的数据流水线。
- Kedro 是一种工作流开发工具,帮助您构建稳健、可扩展、可部署、可复现且版本化的数据流水线。 - Luigi
 - Luigi 是一个 Python 模块,帮助您构建复杂的批处理作业流水线,处理依赖解析、工作流管理、可视化等。
- Luigi 是一个 Python 模块,帮助您构建复杂的批处理作业流水线,处理依赖解析、工作流管理、可视化等。 - Metaflow
 - 一个供数据科学家轻松构建和管理现实世界数据科学项目的框架。
- 一个供数据科学家轻松构建和管理现实世界数据科学项目的框架。 - Pachyderm
 - 基于 Kubernetes 构建的开源分布式处理框架,主要专注于动态构建生产级机器学习流水线 - (视频)。
- 基于 Kubernetes 构建的开源分布式处理框架,主要专注于动态构建生产级机器学习流水线 - (视频)。 - Ploomber
 - 构建数据流水线的最快方式。迭代开发,随处部署。
- 构建数据流水线的最快方式。迭代开发,随处部署。 - Pixeltable
 – 提供声明式、增量数据基础设施的开源 Python 库,用于构建和管理多模态 AI 工作负载。
– 提供声明式、增量数据基础设施的开源 Python 库,用于构建和管理多模态 AI 工作负载。 - Prefect Core
 - 工作流管理系统,使您能够轻松地将重试、日志记录、动态映射、缓存、失败通知等功能添加到数据流水线中。
- 工作流管理系统,使您能够轻松地将重试、日志记录、动态映射、缓存、失败通知等功能添加到数据流水线中。 - SeqIO
 - SeqIO 是一个用于处理顺序数据以供下游序列模型使用的库。
- SeqIO 是一个用于处理顺序数据以供下游序列模型使用的库。 - Snakemake
 - 用于可复现和可扩展数据分析的工作流管理系统。
- 用于可复现和可扩展数据分析的工作流管理系统。 - Towhee
 - 使用一个或多个 ML 模型生成嵌入向量的通用机器学习流水线。
- 使用一个或多个 ML 模型生成嵌入向量的通用机器学习流水线。 - unstructured
 - unstructured 简化和优化 LLM 的数据处理工作流,摄入和预处理图像和文本文档,如 PDF、HTML、Word 文档等。
- unstructured 简化和优化 LLM 的数据处理工作流,摄入和预处理图像和文本文档,如 PDF、HTML、Word 文档等。 - ZenML
 - ZenML 是一个可扩展的开源 MLOps(机器学习运维)框架,用于创建可复现的 ML 流水线,重点关注自动化元数据跟踪、缓存以及对其他工具的许多集成。
- ZenML 是一个可扩展的开源 MLOps(机器学习运维)框架,用于创建可复现的 ML 流水线,重点关注自动化元数据跟踪、缓存以及对其他工具的许多集成。
数据科学笔记本
- Apache Zeppelin
 - 基于 Web 的笔记本,支持使用 SQL、Scala 等进行数据驱动、交互式数据分析及协作文档。
- 基于 Web 的笔记本,支持使用 SQL、Scala 等进行数据驱动、交互式数据分析及协作文档。 - Deepnote
 - Deepnote 是 Jupyter 的直接替代品,采用以 AI 为首要的设计,拥有流畅的用户界面 (UI)、新的代码块以及原生数据集成。在您喜欢的集成开发环境 (IDE) 中本地使用 Python、R 和 SQL,然后扩展到 Deepnote 云端进行实时协作、使用 Deepnote 智能体 (Agent) 以及部署可运行的数据应用。
- Deepnote 是 Jupyter 的直接替代品,采用以 AI 为首要的设计,拥有流畅的用户界面 (UI)、新的代码块以及原生数据集成。在您喜欢的集成开发环境 (IDE) 中本地使用 Python、R 和 SQL,然后扩展到 Deepnote 云端进行实时协作、使用 Deepnote 智能体 (Agent) 以及部署可运行的数据应用。 - Jupyter Notebooks
 - 用于可重复开发的 Web 界面 Python 沙箱 (Sandbox) 环境
- 用于可重复开发的 Web 界面 Python 沙箱 (Sandbox) 环境 - Marimo
 - 响应式 Python 笔记本——运行可复现的实验,作为脚本执行,作为应用部署,并使用 Git 进行版本控制。
- 响应式 Python 笔记本——运行可复现的实验,作为脚本执行,作为应用部署,并使用 Git 进行版本控制。 - Papermill
 - Papermill 是一个用于对笔记本进行参数化并像 Python 脚本一样执行它们的库。
- Papermill 是一个用于对笔记本进行参数化并像 Python 脚本一样执行它们的库。 - Polynote
 - Polynote 是一个实验性的多语言 (Polyglot) 笔记本环境。目前,它支持 Scala 和 Python(带或不带 Spark)、SQL 和 Vega。
- Polynote 是一个实验性的多语言 (Polyglot) 笔记本环境。目前,它支持 Scala 和 Python(带或不带 Spark)、SQL 和 Vega。 - RMarkdown
 - rmarkdown 包是基于 Pandoc 的下一代 R Markdown 实现。
- rmarkdown 包是基于 Pandoc 的下一代 R Markdown 实现。 - Stencila
 - Stencila 是一个用于创建、协作和共享数据驱动内容的平台。内容透明且可复现。
- Stencila 是一个用于创建、协作和共享数据驱动内容的平台。内容透明且可复现。 - Voilà
 - Voilà 将 Jupyter 笔记本转换为独立的 Web 应用程序,例如可用于仪表板 (Dashboard)。
- Voilà 将 Jupyter 笔记本转换为独立的 Web 应用程序,例如可用于仪表板 (Dashboard)。 - .NET Interactive
 - .NET Interactive 利用 .NET 的强大功能,并将其嵌入到您的交互体验中。
- .NET Interactive 利用 .NET 的强大功能,并将其嵌入到您的交互体验中。
数据存储优化
- AIStore
 - AIStore 是一个轻量级的对象存储系统,具备随每个新增存储节点线性扩展的能力,并特别专注于 PB 级深度学习。
- AIStore 是一个轻量级的对象存储系统,具备随每个新增存储节点线性扩展的能力,并特别专注于 PB 级深度学习。 - Alluxio
 - 一个虚拟分布式存储系统,连接计算框架与存储系统之间的桥梁。
- 一个虚拟分布式存储系统,连接计算框架与存储系统之间的桥梁。 - Apache Arrow
 - 一种内存中的列式数据表示格式,兼容 Pandas、基于 Hadoop 的系统等。
- 一种内存中的列式数据表示格式,兼容 Pandas、基于 Hadoop 的系统等。 - Apache Druid
 - 一款高性能实时分析数据库。查看此 文章 了解介绍。
- 一款高性能实时分析数据库。查看此 文章 了解介绍。 - Apache Hudi
 - Hudi 是一个事务性 (ACID) 数据湖平台,将核心仓库和数据库功能直接带入数据湖。Hudi 非常适合流式工作负载,也允许创建高效的增量批处理管道。支持流行的查询引擎,包括 Spark、Flink、Presto、Trino、Hive 等。更多信息请点击这里。
- Hudi 是一个事务性 (ACID) 数据湖平台,将核心仓库和数据库功能直接带入数据湖。Hudi 非常适合流式工作负载,也允许创建高效的增量批处理管道。支持流行的查询引擎,包括 Spark、Flink、Presto、Trino、Hive 等。更多信息请点击这里。 - Apache Iceberg
 - Iceberg 是一种符合 ACID 规范的高性能格式,专为超大规模分析表(包含数十 PB 数据)构建,它将 SQL 表的可靠性和简洁性带入大数据领域,同时使得 Spark、Trino、Flink、Presto、Hive 和 Impala 等引擎能够安全地同时操作相同的表。更多信息请点击这里。
- Iceberg 是一种符合 ACID 规范的高性能格式,专为超大规模分析表(包含数十 PB 数据)构建,它将 SQL 表的可靠性和简洁性带入大数据领域,同时使得 Spark、Trino、Flink、Presto、Hive 和 Impala 等引擎能够安全地同时操作相同的表。更多信息请点击这里。 - Apache Ignite
 - 一个以内存为中心的分布式数据库、缓存和处理平台,适用于事务性、分析和流式工作负载,在 PB 级规模下提供内存速度 - 演示。
- 一个以内存为中心的分布式数据库、缓存和处理平台,适用于事务性、分析和流式工作负载,在 PB 级规模下提供内存速度 - 演示。 - Apache Parquet
 - 一种磁盘上的列式数据表示格式,兼容 Pandas、基于 Hadoop 的系统等。
- 一种磁盘上的列式数据表示格式,兼容 Pandas、基于 Hadoop 的系统等。 - Apache Pinot
 - 一个实时分布式 OLAP (联机分析处理) 数据存储。关于大数据开源 OLAP 系统的比较:ClickHouse、Druid 和 Pinot 可在 此处 找到。
- 一个实时分布式 OLAP (联机分析处理) 数据存储。关于大数据开源 OLAP 系统的比较:ClickHouse、Druid 和 Pinot 可在 此处 找到。 - Casibase
 - Casibase 是一个类似 LangChain 的 RAG (检索增强生成) 知识库,带有 Web UI 和企业级单点登录 (SSO)。
- Casibase 是一个类似 LangChain 的 RAG (检索增强生成) 知识库,带有 Web UI 和企业级单点登录 (SSO)。 - Chroma
 - Chroma 是一个开源的嵌入 (Embedding) 数据库。
- Chroma 是一个开源的嵌入 (Embedding) 数据库。 - ClickHouse
 - ClickHouse 是一个开源的列式数据库管理系统。
- ClickHouse 是一个开源的列式数据库管理系统。 - Delta Lake
 - Delta Lake 是一个存储层,为 Apache Spark 和其他大数据引擎带来可扩展的 ACID 事务。
- Delta Lake 是一个存储层,为 Apache Spark 和其他大数据引擎带来可扩展的 ACID 事务。 - EdgeDB
 - Gel 通过现代数据模型、图查询、身份验证与 AI 解决方案等,增强了 Postgres 的功能。
- Gel 通过现代数据模型、图查询、身份验证与 AI 解决方案等,增强了 Postgres 的功能。 - GPTCache
 - GPTCache 是一个用于为大语言模型查询创建语义缓存的库。
- GPTCache 是一个用于为大语言模型查询创建语义缓存的库。 - InfluxDB
 用于指标、事件和实时分析的可扩展数据存储。
用于指标、事件和实时分析的可扩展数据存储。 - Milvus
 Milvus 是一个云原生、开源的向量数据库,旨在管理由机器学习和神经网络生成的嵌入向量。
Milvus 是一个云原生、开源的向量数据库,旨在管理由机器学习和神经网络生成的嵌入向量。 - Marqo
 Marqo 是一个端到端的向量搜索引擎。
Marqo 是一个端到端的向量搜索引擎。 - pgvector
 pgvector 帮助 Postgres 进行向量相似度搜索。
pgvector 帮助 Postgres 进行向量相似度搜索。 - PostgresML
 PostgresML 是 PostgreSQL 的一个机器学习扩展,允许您使用 SQL 查询对文本和表格数据进行训练和推理。
PostgresML 是 PostgreSQL 的一个机器学习扩展,允许您使用 SQL 查询对文本和表格数据进行训练和推理。 - Redis
 Redis 是一个开源的内存数据存储,支持向量相似度搜索,使其适用于 AI/ML 应用,如语义搜索和推荐系统。
Redis 是一个开源的内存数据存储,支持向量相似度搜索,使其适用于 AI/ML 应用,如语义搜索和推荐系统。 - Safetensors
 一种简单、安全的方式来存储和分发张量 (Tensor)。
一种简单、安全的方式来存储和分发张量 (Tensor)。 - TimescaleDB
 一个开源的时间序列 (Time-series) SQL 数据库,针对快速摄入和复杂查询进行了优化,作为 PostgreSQL 扩展包发布 - (视频)。
一个开源的时间序列 (Time-series) SQL 数据库,针对快速摄入和复杂查询进行了优化,作为 PostgreSQL 扩展包发布 - (视频)。 - Weaviate
 - 一个低延迟的向量搜索引擎(支持 GraphQL、RESTful),开箱即用支持不同的媒体类型。模块包括语义搜索、问答、分类、可定制模型(PyTorch/TensorFlow/Keras)等。
- 一个低延迟的向量搜索引擎(支持 GraphQL、RESTful),开箱即用支持不同的媒体类型。模块包括语义搜索、问答、分类、可定制模型(PyTorch/TensorFlow/Keras)等。 - Zarr
 - 专为并行计算设计的分块、压缩、N 维数组的 Python 实现。
- 专为并行计算设计的分块、压缩、N 维数组的 Python 实现。
数据流处理
- Apache Beam
 Apache Beam 是一个用于批处理和流处理的统一编程模型。
Apache Beam 是一个用于批处理和流处理的统一编程模型。 - Apache Flink
 - 开源流处理框架,具有强大的流处理和批处理能力。
- 开源流处理框架,具有强大的流处理和批处理能力。 - Apache Kafka
 - Kafka 客户端库,用于构建输入和输出存储在 Kafka 集群中的应用和微服务。
- Kafka 客户端库,用于构建输入和输出存储在 Kafka 集群中的应用和微服务。 - Apache Samza
 - 分布式流处理框架。它使用 Apache Kafka 进行消息传递,并使用 Apache Hadoop YARN 提供容错、处理器隔离、安全和资源管理。
- 分布式流处理框架。它使用 Apache Kafka 进行消息传递,并使用 Apache Hadoop YARN 提供容错、处理器隔离、安全和资源管理。 - Apache Spark
 - 使用 Apache Spark 框架作为后端支持有状态精确一次语义的流式微批处理。
- 使用 Apache Spark 框架作为后端支持有状态精确一次语义的流式微批处理。 - Bytewax
 - 基于 Rust 引擎构建的灵活以 Python 为中心的有状态流处理框架。
- 基于 Rust 引擎构建的灵活以 Python 为中心的有状态流处理框架。 - FastStream
 - 一个现代的中间件无关流式 Python 框架,支持 Apache Kafka、RabbitMQ 和 NATS 协议,受 FastAPI 启发,易于与其他 Web 框架集成。
- 一个现代的中间件无关流式 Python 框架,支持 Apache Kafka、RabbitMQ 和 NATS 协议,受 FastAPI 启发,易于与其他 Web 框架集成。 - MOA
 - MOA(大规模在线分析)是一个用于大数据流挖掘的开源框架。
- MOA(大规模在线分析)是一个用于大数据流挖掘的开源框架。 - MosaicML Streaming - 从云存储快速、确定性地流式传输大型数据集,用于分布式模型训练。
- RisingWave
 - 一个统一的流处理和低延迟服务的分布式 SQL 流数据库,非常适合构建和提供在线机器学习功能。
- 一个统一的流处理和低延迟服务的分布式 SQL 流数据库,非常适合构建和提供在线机器学习功能。 - TensorStore
 - 用于读写大型多维数组的库。
- 用于读写大型多维数组的库。
部署与服务
- Agenta
 - Agenta 提供用于整个 LLMOps (大语言模型运维) 工作流的端到端工具:构建(LLM (大语言模型) 游乐场、评估)、部署(提示词和配置管理),以及(LLM 可观测性和追踪)。
- Agenta 提供用于整个 LLMOps (大语言模型运维) 工作流的端到端工具:构建(LLM (大语言模型) 游乐场、评估)、部署(提示词和配置管理),以及(LLM 可观测性和追踪)。 - AirLLM
 - AirLLM 优化推理内存使用,允许 70B 大语言模型在单张 4GB GPU (图形处理器) 卡上运行推理,无需量化 (Quantization)、蒸馏 (Distillation) 和剪枝 (Pruning)。
- AirLLM 优化推理内存使用,允许 70B 大语言模型在单张 4GB GPU (图形处理器) 卡上运行推理,无需量化 (Quantization)、蒸馏 (Distillation) 和剪枝 (Pruning)。 - AITemplate
 - AITemplate (AIT) 是一个 Python 框架,可将深度神经网络转换为 CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ 代码,以实现闪电般的快速推理服务。
- AITemplate (AIT) 是一个 Python 框架,可将深度神经网络转换为 CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ 代码,以实现闪电般的快速推理服务。 - BentoML
 - BentoML 是一个用于高性能机器学习模型服务的开源框架。
- BentoML 是一个用于高性能机器学习模型服务的开源框架。 - BISHENG
 - BISHENG 是一个面向企业场景的开源 LLM 应用 DevOps (开发运维) 平台。
- BISHENG 是一个面向企业场景的开源 LLM 应用 DevOps (开发运维) 平台。 - DeepDetect
 - 由 Jolibrain 维护的用于 TensorFlow、XGBoost 和 Cafe 模型的 C++ 机器学习生产服务器。
- 由 Jolibrain 维护的用于 TensorFlow、XGBoost 和 Cafe 模型的 C++ 机器学习生产服务器。 - Dynamo
 - NVIDIA Dynamo 是一个高吞吐、低延迟的推理框架,专为在多节点分布式环境中服务生成式 AI 和推理模型而设计。
- NVIDIA Dynamo 是一个高吞吐、低延迟的推理框架,专为在多节点分布式环境中服务生成式 AI 和推理模型而设计。 - exo
 - exo 帮助你使用日常设备在家中运行 AI 集群。
- exo 帮助你使用日常设备在家中运行 AI 集群。 - Genkit
 - Genkit 是一个用于使用熟悉的以代码为中心的模式构建 AI 驱动应用的开源框架。Genkit 使得利用可观测性 (Observability) 和评估轻松开发、集成和测试 AI 功能变得简单。
- Genkit 是一个用于使用熟悉的以代码为中心的模式构建 AI 驱动应用的开源框架。Genkit 使得利用可观测性 (Observability) 和评估轻松开发、集成和测试 AI 功能变得简单。 - Inference
 - 一个快速、生产就绪的计算机视觉推理服务器,支持部署许多流行的模型架构和微调模型。使用 Inference,你可以使用 Docker 在自己的硬件上部署 YOLOv5、YOLOv8、CLIP、SAM 和 CogVLM 等模型。
- 一个快速、生产就绪的计算机视觉推理服务器,支持部署许多流行的模型架构和微调模型。使用 Inference,你可以使用 Docker 在自己的硬件上部署 YOLOv5、YOLOv8、CLIP、SAM 和 CogVLM 等模型。 - Infinity
 - Infinity 是一个用于服务文本嵌入 (Text-embeddings)、重排序模型 (Reranking models) 和 clip 的高吞吐、低延迟 REST API。
- Infinity 是一个用于服务文本嵌入 (Text-embeddings)、重排序模型 (Reranking models) 和 clip 的高吞吐、低延迟 REST API。 - IPEX-LLM
 - IPEX-LLM 是一个 PyTorch 库,用于在 Intel CPU (中央处理器) 和 GPU (例如带有集成显卡的本地 PC、Arc、Flex 和 Max 等独立显卡) 上运行 LLM,具有极低的延迟。
- IPEX-LLM 是一个 PyTorch 库,用于在 Intel CPU (中央处理器) 和 GPU (例如带有集成显卡的本地 PC、Arc、Flex 和 Max 等独立显卡) 上运行 LLM,具有极低的延迟。 - LiteLLM
 - LiteLLM 是一个 Python SDK (软件开发工具包)、代理服务器 (LLM 网关),用于以 OpenAI 格式调用 100+ LLM API (应用程序接口) - Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq。
- LiteLLM 是一个 Python SDK (软件开发工具包)、代理服务器 (LLM 网关),用于以 OpenAI 格式调用 100+ LLM API (应用程序接口) - Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq。 - LitServe
 - LitServe 是一个基于 FastAPI 构建的 AI 模型灵活服务引擎。它支持为模型、智能体、多模态系统、RAG (检索增强生成) 和复杂机器学习流水线定制推理引擎。
- LitServe 是一个基于 FastAPI 构建的 AI 模型灵活服务引擎。它支持为模型、智能体、多模态系统、RAG (检索增强生成) 和复杂机器学习流水线定制推理引擎。 - Jina-serve
 - Jina-serve 是一个用于构建和部署通过 gRPC、HTTP 和 WebSockets 通信的 AI 服务的框架。
- Jina-serve 是一个用于构建和部署通过 gRPC、HTTP 和 WebSockets 通信的 AI 服务的框架。 - Kiln
 - Kiln 是一个用于微调 LLM 模型、合成数据生成 (Synthetic Data Generation) 和协作处理数据集的 OSS (开源软件) 工具。
- Kiln 是一个用于微调 LLM 模型、合成数据生成 (Synthetic Data Generation) 和协作处理数据集的 OSS (开源软件) 工具。 - KServe
 - KServe 为服务预测性和生成式机器学习提供了一个 Kubernetes (K8s) 自定义资源定义 (Custom Resource Definition)。
- KServe 为服务预测性和生成式机器学习提供了一个 Kubernetes (K8s) 自定义资源定义 (Custom Resource Definition)。 - KTransformers
 - KTransformers 是一个体验前沿 LLM 推理优化的灵活框架。
- KTransformers 是一个体验前沿 LLM 推理优化的灵活框架。 - Langtrace
 - Langtrace 是一个基于 OpenTelemetry 的开源、端到端 LLM 应用可观测性工具,为流行的 LLM、LLM 框架、VectorDB (向量数据库) 等提供实时追踪、评估和指标 (Metrics)。
- Langtrace 是一个基于 OpenTelemetry 的开源、端到端 LLM 应用可观测性工具,为流行的 LLM、LLM 框架、VectorDB (向量数据库) 等提供实时追踪、评估和指标 (Metrics)。 - Lepton AI
 - LeptonAI Python 库让你能够轻松地从 Python 代码构建 AI 服务。
- LeptonAI Python 库让你能够轻松地从 Python 代码构建 AI 服务。 - LightLLM
 - LightLLM 是一个基于 Python 的 LLM (大语言模型) 推理和服务框架,以其轻量级设计、易于扩展和高速性能而闻名。
- LightLLM 是一个基于 Python 的 LLM (大语言模型) 推理和服务框架,以其轻量级设计、易于扩展和高速性能而闻名。 - llama.cpp
 - llama.cpp 是一个开源软件库,可在各种大语言模型(如 Llama)上执行推理。
- llama.cpp 是一个开源软件库,可在各种大语言模型(如 Llama)上执行推理。 - llmfit
 - 一个终端工具,可为你的系统的 RAM、CPU 和 GPU 匹配合适大小的 LLM 模型。检测你的硬件,根据质量、速度、适配度和上下文维度对每个模型进行评分,并告诉你哪些实际上能在你的机器上运行良好。
- 一个终端工具,可为你的系统的 RAM、CPU 和 GPU 匹配合适大小的 LLM 模型。检测你的硬件,根据质量、速度、适配度和上下文维度对每个模型进行评分,并告诉你哪些实际上能在你的机器上运行良好。 - LMDeploy
 - LMDeploy 是一个用于压缩、部署和服务 LLM 的工具包。
- LMDeploy 是一个用于压缩、部署和服务 LLM 的工具包。 - LM Studio
 - LM Studio 是一个用于在计算机上本地部署 LLM 模型的工具,即使是在相对普通的机器上,只要满足最低要求即可。
- LM Studio 是一个用于在计算机上本地部署 LLM 模型的工具,即使是在相对普通的机器上,只要满足最低要求即可。 - LocalAI
 - LocalAI 是一个即用型替代 REST API,兼容 OpenAI API 规范,用于本地推理。
- LocalAI 是一个即用型替代 REST API,兼容 OpenAI API 规范,用于本地推理。 - MindsDB
 - MindsDB 是一个从你的数据库、向量存储和应用数据中实时创建、服务和微调模型的平台。
- MindsDB 是一个从你的数据库、向量存储和应用数据中实时创建、服务和微调模型的平台。 - mini-sglang
 - mini-sglang 是一个轻量级且高效的大语言模型服务框架。
- mini-sglang 是一个轻量级且高效的大语言模型服务框架。 - MLRun
 - MLRun 是一个开源 MLOps (机器学习运维) 框架,用于在其整个生命周期内快速构建和管理持续的机器学习和生成式 AI 应用。
- MLRun 是一个开源 MLOps (机器学习运维) 框架,用于在其整个生命周期内快速构建和管理持续的机器学习和生成式 AI 应用。 - MLServer
 - 用于你的机器学习模型的推理服务器,包括支持多种框架、多模型服务等更多功能。
- 用于你的机器学习模型的推理服务器,包括支持多种框架、多模型服务等更多功能。 - Model Runner
 - Docker Model Runner 使得使用 Docker 管理、运行和服务 AI 模型变得容易,支持直接从 Docker Hub 或任何符合 OCI (开放容器倡议) 标准的注册表拉取的 LLM 和其他 AI 模型。
- Docker Model Runner 使得使用 Docker 管理、运行和服务 AI 模型变得容易,支持直接从 Docker Hub 或任何符合 OCI (开放容器倡议) 标准的注册表拉取的 LLM 和其他 AI 模型。 - Mosec
 - 一个由 Rust 驱动的多阶段流水线模型服务器,提供动态批处理等功能。作为微服务 (Micro-services) 实施和部署非常容易。
- 一个由 Rust 驱动的多阶段流水线模型服务器,提供动态批处理等功能。作为微服务 (Micro-services) 实施和部署非常容易。 - nano-vllm
 - nano-vllm 是一个从头构建的轻量级 vLLM 实现,提供具有前缀缓存 (Prefix Caching)、张量并行 (Tensor Parallelism) 和 CUDA 图 (CUDA Graph) 等优化技术的快速离线推理。
- nano-vllm 是一个从头构建的轻量级 vLLM 实现,提供具有前缀缓存 (Prefix Caching)、张量并行 (Tensor Parallelism) 和 CUDA 图 (CUDA Graph) 等优化技术的快速离线推理。 - nndeploy
 - 一个易用且高性能的 AI 部署框架。
- 一个易用且高性能的 AI 部署框架。 - Nuclio
 - 一个专注于数据、I/O 和计算密集型工作负载的高性能“无服务器” (Serverless) 框架。它与流行的数据科学工具(如 Jupyter 和 Kubeflow)集成良好;支持多种数据和流式数据源 (Streaming Sources);并支持在 CPU 和 GPU 上执行。
- 一个专注于数据、I/O 和计算密集型工作负载的高性能“无服务器” (Serverless) 框架。它与流行的数据科学工具(如 Jupyter 和 Kubeflow)集成良好;支持多种数据和流式数据源 (Streaming Sources);并支持在 CPU 和 GPU 上执行。 - OpenLLM
 - OpenLLM 允许开发者使用单个命令运行任何开源 LLM(Llama 3.1, Qwen2, Phi3 等)或自定义模型,作为兼容 OpenAI 的 API。
- OpenLLM 允许开发者使用单个命令运行任何开源 LLM(Llama 3.1, Qwen2, Phi3 等)或自定义模型,作为兼容 OpenAI 的 API。 - OpenVINO
 - OpenVINO 是一个用于优化和部署 AI 推理的开源工具包。
- OpenVINO 是一个用于优化和部署 AI 推理的开源工具包。 - Open WebUI
 - Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器(如 Ollama)和兼容 OpenAI 的 API,内置 RAG 推理引擎,使其成为强大的 AI 部署解决方案。
- Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器(如 Ollama)和兼容 OpenAI 的 API,内置 RAG 推理引擎,使其成为强大的 AI 部署解决方案。 - OptiLLM
 - OptiLLM 是一个兼容 OpenAI API 的优化推理代理,实现了 20 多种最先进技术,在不要求任何模型训练或微调的情况下,显著提高 LLM 在推理任务上的准确性和性能。
- OptiLLM 是一个兼容 OpenAI API 的优化推理代理,实现了 20 多种最先进技术,在不要求任何模型训练或微调的情况下,显著提高 LLM 在推理任务上的准确性和性能。 - PowerInfer
 - PowerInfer 是一个利用激活局部性 (Activation Locality) 为你的设备提供的 CPU/GPU LLM 推理引擎。
- PowerInfer 是一个利用激活局部性 (Activation Locality) 为你的设备提供的 CPU/GPU LLM 推理引擎。 - Prompt2Model
 - Prompt2Model 是一个系统,它接受自然语言任务描述(如用于 ChatGPT 等 LLM 的提示词),以训练一个小型专用模型,便于部署。
- Prompt2Model 是一个系统,它接受自然语言任务描述(如用于 ChatGPT 等 LLM 的提示词),以训练一个小型专用模型,便于部署。 - RamaLama
 - RamaLama 是一个开源工具,通过 OCI 容器简化 AI 模型的本地使用和推理服务,消除了配置主机系统的需求。
- RamaLama 是一个开源工具,通过 OCI 容器简化 AI 模型的本地使用和推理服务,消除了配置主机系统的需求。 - RunAnywhere
 - RunAnywhere 是一个生产就绪的 SDK,用于在 iOS、Android、React Native 和 Flutter 的设备上运行 AI 模型(LLM、语音转文本、文本转语音)—— enabling 私有、离线且快速的移动 AI 应用。
- RunAnywhere 是一个生产就绪的 SDK,用于在 iOS、Android、React Native 和 Flutter 的设备上运行 AI 模型(LLM、语音转文本、文本转语音)—— enabling 私有、离线且快速的移动 AI 应用。 - Seldon Core
 - 用于在 Kubernetes 中部署和管理机器学习模型的开源平台 - (视频)。
- 用于在 Kubernetes 中部署和管理机器学习模型的开源平台 - (视频)。 - SGLang
 - SGLang 是一个用于大语言模型和视觉语言模型的快速服务框架。
- SGLang 是一个用于大语言模型和视觉语言模型的快速服务框架。 - SkyPilot
 - SkyPilot 是一个在任何云上运行 LLM、AI 和批处理作业 (Batch Jobs) 的框架,提供最大成本节省、最高 GPU 可用性和托管执行。
- SkyPilot 是一个在任何云上运行 LLM、AI 和批处理作业 (Batch Jobs) 的框架,提供最大成本节省、最高 GPU 可用性和托管执行。 - Tensorflow Serving
 - 通过 grpc 协议服务 TensorFlow 模型的高性能框架,每核心每秒能处理 10 万次请求。
- 通过 grpc 协议服务 TensorFlow 模型的高性能框架,每核心每秒能处理 10 万次请求。 - text-generation-inference
 - 大语言模型文本生成推理。
- 大语言模型文本生成推理。 - TorchServe - TorchServe 是一个灵活且易于使用的用于服务 PyTorch 模型的工具。
- torchtune
 - torchtune 是一个 PyTorch 库,用于轻松编写、后训练 (Post-training) 和实验 LLM。
- torchtune 是一个 PyTorch 库,用于轻松编写、后训练 (Post-training) 和实验 LLM。 - Transformer Lab
 - Transformer Lab 是一个开源 LLM 工作区,用于在推理引擎和平台上本地微调、评估、导出和测试模型。
- Transformer Lab 是一个开源 LLM 工作区,用于在推理引擎和平台上本地微调、评估、导出和测试模型。 - Triton Inference Server
 - Triton 是一个高性能开源服务软件,用于在 GPU 和 CPU 上部署来自任何框架的 AI 模型,同时最大化利用率。
- Triton 是一个高性能开源服务软件,用于在 GPU 和 CPU 上部署来自任何框架的 AI 模型,同时最大化利用率。 - Vercel AI
 - Vercel AI 是一个 TypeScript 工具包,旨在帮助你使用 Next.js、React、Svelte、Vue 等流行框架和 Node.js 等运行时构建 AI 驱动的应用。
- Vercel AI 是一个 TypeScript 工具包,旨在帮助你使用 Next.js、React、Svelte、Vue 等流行框架和 Node.js 等运行时构建 AI 驱动的应用。 - Vespa
 - 在服务时间和任何规模下搜索、推理并整理向量 (Vectors)、张量 (Tensors)、文本和结构化数据。
- 在服务时间和任何规模下搜索、推理并整理向量 (Vectors)、张量 (Tensors)、文本和结构化数据。 - vLLM
 - vLLM 是一个用于 LLM 的高吞吐和内存高效的推理和服务引擎。
- vLLM 是一个用于 LLM 的高吞吐和内存高效的推理和服务引擎。
{kind=link}
您尚未提供需要翻译的 README 原文内容。请补充提供具体内容,以便我为您完成翻译任务。
评估与监控
- AlpacaEval
 - AlpacaEval 是一个用于评估遵循指令的语言模型的自动评估工具。
- AlpacaEval 是一个用于评估遵循指令的语言模型的自动评估工具。 - ANN-Benchmarks
 - ANN-Benchmarks 是近似最近邻(Approximate Nearest Neighbor, ANN)算法搜索的基准测试环境。
- ANN-Benchmarks 是近似最近邻(Approximate Nearest Neighbor, ANN)算法搜索的基准测试环境。 - ARES
 - ARES 是一个用于自动评估检索增强生成(Retrieval-Augmented Generation, RAG)模型的框架。
- ARES 是一个用于自动评估检索增强生成(Retrieval-Augmented Generation, RAG)模型的框架。 - BEIR
 - BEIR 是一个包含多样化信息检索(Information Retrieval, IR)任务的异构基准测试集。它还提供了一个通用且易于使用的框架,用于在基准测试中评估基于自然语言处理(Natural Language Processing, NLP)的检索模型。
- BEIR 是一个包含多样化信息检索(Information Retrieval, IR)任务的异构基准测试集。它还提供了一个通用且易于使用的框架,用于在基准测试中评估基于自然语言处理(Natural Language Processing, NLP)的检索模型。 - Code Generation LM Evaluation Harness
 - Code Generation LM Evaluation Harness 是一个用于评估代码生成模型的框架。
- Code Generation LM Evaluation Harness 是一个用于评估代码生成模型的框架。 - COMET
 - COMET 是一个开源的机器学习评估框架。
- COMET 是一个开源的机器学习评估框架。 - C-Eval
 - C-Eval 是一个面向基础模型的综合性中文评估套件。
- C-Eval 是一个面向基础模型的综合性中文评估套件。 - Deepchecks
 - Deepchecks 是一个全面的开源解决方案,满足您所有的 AI 和机器学习(ML)验证需求,使您能够彻底测试从研究到生产的数据和模型。
- Deepchecks 是一个全面的开源解决方案,满足您所有的 AI 和机器学习(ML)验证需求,使您能够彻底测试从研究到生产的数据和模型。 - DeepEval
 - DeepEval 是一个简单易用的开源框架,用于大语言模型(Large Language Model, LLM)应用的评估。
- DeepEval 是一个简单易用的开源框架,用于大语言模型(Large Language Model, LLM)应用的评估。 - DomainBed
 - DomainBed 是一个测试套件,包含用于领域泛化的基准数据集和算法。
- DomainBed 是一个测试套件,包含用于领域泛化的基准数据集和算法。 - EvalAI
 - EvalAI 是一个开源平台,用于大规模评估和比较 AI 算法。
- EvalAI 是一个开源平台,用于大规模评估和比较 AI 算法。 - Evalchemy
 - Evalchemy 是一个统一且易于使用的工具包,用于评估后训练语言模型。
- Evalchemy 是一个统一且易于使用的工具包,用于评估后训练语言模型。 - EvalPlus
 - EvalPlus 是一个针对 LLM4Code 的稳健评估框架,具有扩展的 HumanEval+ 和 MBPP+ 基准、效率评估(EvalPerf)以及安全、可扩展的评估工具包。
- EvalPlus 是一个针对 LLM4Code 的稳健评估框架,具有扩展的 HumanEval+ 和 MBPP+ 基准、效率评估(EvalPerf)以及安全、可扩展的评估工具包。 - Evals
 - Evals 是一个用于评估 OpenAI 模型的框架,也是一个开源的基准注册表。
- Evals 是一个用于评估 OpenAI 模型的框架,也是一个开源的基准注册表。 - EvalScope
 - EvalScope 是一个精简且可定制的框架,用于高效的大模型评估和性能基准测试。
- EvalScope 是一个精简且可定制的框架,用于高效的大模型评估和性能基准测试。 - Evaluate
 - Evaluate 是一个库,使评估和比较模型及其性能报告变得更加容易和标准化。
- Evaluate 是一个库,使评估和比较模型及其性能报告变得更加容易和标准化。 - Evidently
 - Evidently 是一个开源框架,用于评估、测试和监控由机器学习和大语言模型驱动的系统。
- Evidently 是一个开源框架,用于评估、测试和监控由机器学习和大语言模型驱动的系统。 - GAOKAO-Bench
 - GAOKAO-Bench 是一个评估框架,使用中国高考(GAOKAO)题目作为数据集来评估大模型的语言理解和逻辑推理能力。
- GAOKAO-Bench 是一个评估框架,使用中国高考(GAOKAO)题目作为数据集来评估大模型的语言理解和逻辑推理能力。 - Giskard
 - Giskard 是一个开源 Python 库,可自动检测 AI 应用中的性能、偏差和安全问题。
- Giskard 是一个开源 Python 库,可自动检测 AI 应用中的性能、偏差和安全问题。 - guidellm
 - guidellm 是大语言模型推理系统的基准测试和性能评估工具。
- guidellm 是大语言模型推理系统的基准测试和性能评估工具。 - HumanEval
 - HumanEval 是一个基准测试,使用带有单元测试的 Python 编程问题来评估代码生成模型的功能正确性。
- HumanEval 是一个基准测试,使用带有单元测试的 Python 编程问题来评估代码生成模型的功能正确性。 - Helicone
 - Helicone 是一个全功能的开源大语言模型开发者平台。
- Helicone 是一个全功能的开源大语言模型开发者平台。 - HELM
 - HELM(语言模型综合评估)提供了用于语言模型综合评估的工具,包括标准化数据集、各种模型的统一 API、多样化的指标、鲁棒性(Robustness)和公平性扰动、提示构建框架以及用于统一模型访问的代理服务器。
- HELM(语言模型综合评估)提供了用于语言模型综合评估的工具,包括标准化数据集、各种模型的统一 API、多样化的指标、鲁棒性(Robustness)和公平性扰动、提示构建框架以及用于统一模型访问的代理服务器。 - Inspect
 - Inspect 是一个用于大语言模型评估的框架。
- Inspect 是一个用于大语言模型评估的框架。 - JiWER
 - JiWER 是一个简单快速的 Python 包,用于评估自动语音识别系统。
- JiWER 是一个简单快速的 Python 包,用于评估自动语音识别系统。 - Laminar
 - Laminar 是一个开源平台,用于追踪、评估、标记和分析 AI 产品的大语言模型数据。
- Laminar 是一个开源平台,用于追踪、评估、标记和分析 AI 产品的大语言模型数据。 - Langfuse
 - Langfuse 是为基于大语言模型的应用提供的可观测性(Observability)与分析解决方案。
- Langfuse 是为基于大语言模型的应用提供的可观测性(Observability)与分析解决方案。 - LangTest
 - LangTest 是一个用于自然语言处理模型的全面评估工具包。
- LangTest 是一个用于自然语言处理模型的全面评估工具包。 - Language Model Evaluation Harness
 - Language Model Evaluation Harness 是一个框架,用于在大量不同的评估任务上测试生成式语言模型。
- Language Model Evaluation Harness 是一个框架,用于在大量不同的评估任务上测试生成式语言模型。 - LangWatch
 - LangWatch 是 DSPy 的可视化界面,也是一个完整的大语言模型运维(LLM Ops)平台,用于监控、实验、测量和改进大语言模型管道,采用公平代码分发模式。
- LangWatch 是 DSPy 的可视化界面,也是一个完整的大语言模型运维(LLM Ops)平台,用于监控、实验、测量和改进大语言模型管道,采用公平代码分发模式。 - LightEval
 - LightEval 是一个轻量级的大语言模型评估套件。
- LightEval 是一个轻量级的大语言模型评估套件。 - LLMPerf
 - LLMPerf 是一个用于评估大语言模型 API 性能的工具。
- LLMPerf 是一个用于评估大语言模型 API 性能的工具。 - lmms-eval
 - lmms-eval 是一个精心打造的评估框架,用于一致且高效地评估多模态大语言模型(Large Multimodal Models, LMM)。
- lmms-eval 是一个精心打造的评估框架,用于一致且高效地评估多模态大语言模型(Large Multimodal Models, LMM)。 - Melting Pot
 - Melting Pot 是一套用于多智能体强化学习的测试场景套件。
- Melting Pot 是一套用于多智能体强化学习的测试场景套件。 - Meta-World
 - Meta-World 是一个开源模拟基准,用于元强化学习和多任务学习,包含 50 种不同的机器人操作任务。
- Meta-World 是一个开源模拟基准,用于元强化学习和多任务学习,包含 50 种不同的机器人操作任务。 - mir_eval
 - mir_eval 是一个 Python 库,提供了一种透明、标准化且直接的方式来评估音乐信息检索系统。
- mir_eval 是一个 Python 库,提供了一种透明、标准化且直接的方式来评估音乐信息检索系统。 - MLPerf Inference
 - MLPerf Inference 是一套基准测试套件,用于衡量系统在各种部署场景中运行模型的速度。
- MLPerf Inference 是一套基准测试套件,用于衡量系统在各种部署场景中运行模型的速度。 - Massive Text Embedding Benchmark - 大规模文本嵌入基准(Massive Text Embedding Benchmark, MTEB)是一个全面的评估框架,评估文本嵌入模型在不同任务和语言上的性能,涵盖 8 个嵌入任务、58 个数据集和 112 种语言。
- NannyML
 - NannyML 是一个库,允许您估算部署后的模型性能(无需访问目标值),检测数据漂移(Data Drift),并智能地将数据漂移警报链接回模型性能的变化。
- NannyML 是一个库,允许您估算部署后的模型性能(无需访问目标值),检测数据漂移(Data Drift),并智能地将数据漂移警报链接回模型性能的变化。 - OGB
 - 开放图基准(Open Graph Benchmark, OGB)是用于图机器学习的基准数据集、数据加载器和评估器的集合。
- 开放图基准(Open Graph Benchmark, OGB)是用于图机器学习的基准数据集、数据加载器和评估器的集合。 - Ollama Grid Search
 - Ollama Grid Search 自动化了为给定用例选择最佳模型、提示或推理参数的过程,允许您迭代它们的组合并直观地检查结果。
- Ollama Grid Search 自动化了为给定用例选择最佳模型、提示或推理参数的过程,允许您迭代它们的组合并直观地检查结果。 - OpenCompass
 - OpenCompass 是一个大语言模型评估平台,支持广泛的模型(LLaMA, LLaMa2, ChatGLM2, ChatGPT, Claude 等)在 50 多个数据集上的评估。
- OpenCompass 是一个大语言模型评估平台,支持广泛的模型(LLaMA, LLaMa2, ChatGLM2, ChatGPT, Claude 等)在 50 多个数据集上的评估。 - OpenLIT
 - OpenLIT 是一个开源 AI 工程平台,通过可观测性、监控、护栏机制(Guardrails)、评估和无缝集成简化大语言模型工作流程。
- OpenLIT 是一个开源 AI 工程平台,通过可观测性、监控、护栏机制(Guardrails)、评估和无缝集成简化大语言模型工作流程。 - OpenLLMetry
 - OpenLLMetry 通过性能监控、执行跟踪和调试功能,为开发人员提供对大语言模型应用的深入可见性。
- OpenLLMetry 通过性能监控、执行跟踪和调试功能,为开发人员提供对大语言模型应用的深入可见性。 - Opik
 - Opik 是一个用于评估、测试和监控大语言模型应用的开源平台。
- Opik 是一个用于评估、测试和监控大语言模型应用的开源平台。 - Overcooked-AI
 - Overcooked-AI 是一个完全协作的人机任务绩效基准环境,基于广受欢迎的电子游戏《煮糊了》(Overcooked)。
- Overcooked-AI 是一个完全协作的人机任务绩效基准环境,基于广受欢迎的电子游戏《煮糊了》(Overcooked)。 - Phoenix
 - Phoenix 是一个开源 AI 可观测性平台,专为实验、评估和故障排除而设计。
- Phoenix 是一个开源 AI 可观测性平台,专为实验、评估和故障排除而设计。 - PromptBench
 - PromptBench 是一个用于大语言模型的统一评估框架。
- PromptBench 是一个用于大语言模型的统一评估框架。 - Promptfoo
 - 用于测试越狱(Jailbreaks)、提示词注入(Prompt Injection)和其他漏洞的大语言模型红队测试(Red Teaming)和评估框架,支持持续集成/持续部署(CI/CD)集成。
- 用于测试越狱(Jailbreaks)、提示词注入(Prompt Injection)和其他漏洞的大语言模型红队测试(Red Teaming)和评估框架,支持持续集成/持续部署(CI/CD)集成。 - Prometheus-Eval
 - RagaAI Catalyst 是一个综合平台,旨在增强大语言模型项目的管理和优化。
- RagaAI Catalyst 是一个综合平台,旨在增强大语言模型项目的管理和优化。 - RagaAI Catalyst
 - Prometheus-Eval 是一套工具集合,用于训练、评估和使用专门用于评估其他语言模型的语言模型。
- Prometheus-Eval 是一套工具集合,用于训练、评估和使用专门用于评估其他语言模型的语言模型。 - Ragas
 - Ragas 是一个用于评估检索增强生成管道的框架。
- Ragas 是一个用于评估检索增强生成管道的框架。 - RewardBench
 - RewardBench 是一个旨在评估奖励模型能力和安全的基准测试。
- RewardBench 是一个旨在评估奖励模型能力和安全的基准测试。 - RLBench
 - RLBench 是一个雄心勃勃的大规模基准和学习环境,旨在促进多个视觉引导操作研究领域的研究,包括:强化学习、模仿学习、多任务学习、几何计算机视觉,特别是少样本学习(Few-shot Learning)。
- RLBench 是一个雄心勃勃的大规模基准和学习环境,旨在促进多个视觉引导操作研究领域的研究,包括:强化学习、模仿学习、多任务学习、几何计算机视觉,特别是少样本学习(Few-shot Learning)。 - SimplerEnv
 - SimplerEnv 是用于真实机器人设置的模拟操作策略评估环境。
- SimplerEnv 是用于真实机器人设置的模拟操作策略评估环境。 - SwanLab
 - SwanLab 是一个 AI 训练跟踪和可视化工具。
- SwanLab 是一个 AI 训练跟踪和可视化工具。 - Speech-to-Text Benchmark
 - Speech-to-Text Benchmark 是一个极简且可扩展的框架,用于对不同语音转文本引擎进行基准测试。
- Speech-to-Text Benchmark 是一个极简且可扩展的框架,用于对不同语音转文本引擎进行基准测试。 - TensorFlow Model Analysis
 - TensorFlow Model Analysis (TFMA) 是一个库,用于以分布式方式在大量数据上评估 TensorFlow 模型,使用训练器中定义的相同指标。
- TensorFlow Model Analysis (TFMA) 是一个库,用于以分布式方式在大量数据上评估 TensorFlow 模型,使用训练器中定义的相同指标。 - TorchBench
 - TorchBench 是一组用于评估 PyTorch 性能的开源基准测试集合。
- TorchBench 是一组用于评估 PyTorch 性能的开源基准测试集合。 - TruLens
 - TruLens 提供了一套用于评估和跟踪大语言模型实验的工具。
- TruLens 提供了一套用于评估和跟踪大语言模型实验的工具。 - TrustLLM
 - TrustLLM 是一个全面的框架,用于评估大语言模型的可信度,包括原则、调查和基准测试。
- TrustLLM 是一个全面的框架,用于评估大语言模型的可信度,包括原则、调查和基准测试。 - VBench
 - VBench 是一个用于视频生成模型的综合性基准测试套件。
- VBench 是一个用于视频生成模型的综合性基准测试套件。 - VLMEvalKit
 - VLMEvalKit 是一个用于大型视觉语言模型(Large Vision-Language Models, LVLMs)的开源评估工具包。
- VLMEvalKit 是一个用于大型视觉语言模型(Large Vision-Language Models, LVLMs)的开源评估工具包。
可解释性与公平性
- Aequitas
 - 一个开源的偏差审计工具包,供数据科学家、机器学习研究人员和政策制定者用于审计机器学习模型是否存在歧视和偏差,并围绕开发和部署预测风险评估工具做出知情且公平的决策。
- 一个开源的偏差审计工具包,供数据科学家、机器学习研究人员和政策制定者用于审计机器学习模型是否存在歧视和偏差,并围绕开发和部署预测风险评估工具做出知情且公平的决策。 - AI Explainability 360
 - 数据和机器学习模型的解释性(Interpretability)与可解释性(Explainability),包含一套全面的算法,覆盖不同维度的解释以及代理可解释性指标。
- 数据和机器学习模型的解释性(Interpretability)与可解释性(Explainability),包含一套全面的算法,覆盖不同维度的解释以及代理可解释性指标。 - AI Fairness 360
 - 针对数据集和机器学习模型的一套全面的公平性指标,这些指标的说明,以及减轻数据集和模型中偏差的算法。
- 针对数据集和机器学习模型的一套全面的公平性指标,这些指标的说明,以及减轻数据集和模型中偏差的算法。 - Alibi
 - Alibi 是一个面向机器学习模型检查和解释的开源 Python 库。该库最初的焦点在于基于实例的黑盒模型解释。
- Alibi 是一个面向机器学习模型检查和解释的开源 Python 库。该库最初的焦点在于基于实例的黑盒模型解释。 - captum
 - 由 Facebook 开发的 PyTorch 模型解释和理解库。它包含集成梯度(integrated gradients)、显著性图(saliency maps)、smoothgrad、vargrad 等针对 PyTorch 模型的通用实现。
- 由 Facebook 开发的 PyTorch 模型解释和理解库。它包含集成梯度(integrated gradients)、显著性图(saliency maps)、smoothgrad、vargrad 等针对 PyTorch 模型的通用实现。 - Fairlearn
 - Fairlearn 是一个 Python 工具包,用于评估和减轻机器学习模型中的不公平性。
- Fairlearn 是一个 Python 工具包,用于评估和减轻机器学习模型中的不公平性。 - InterpretML
 - InterpretML 是一个开源软件包,用于训练可解释模型并解释黑盒系统。
- InterpretML 是一个开源软件包,用于训练可解释模型并解释黑盒系统。 - Lightly
 - 一个用于图像自监督学习(self-supervised learning)的 Python 框架。学习到的表示可用于分析未标记数据中的分布并重新平衡数据集。
- 一个用于图像自监督学习(self-supervised learning)的 Python 框架。学习到的表示可用于分析未标记数据中的分布并重新平衡数据集。 - LOFO Importance
 - LOFO(Leave One Feature Out,留一特征法)重要性计算一组特征的重要性,基于所选指标,针对所选模型,通过迭代地从集合中移除每个特征,并使用所选验证方案基于所选指标评估模型性能。
- LOFO(Leave One Feature Out,留一特征法)重要性计算一组特征的重要性,基于所选指标,针对所选模型,通过迭代地从集合中移除每个特征,并使用所选验证方案基于所选指标评估模型性能。 - mljar-supervised
 - 一个用于表格数据的 AutoML 的 Python 包,具有特征工程、超参数调优、解释和自动文档功能。
- 一个用于表格数据的 AutoML 的 Python 包,具有特征工程、超参数调优、解释和自动文档功能。 - Quantus
 - Quantus 是一个可解释人工智能(eXplainable AI)工具包,用于负责任地评估神经网络解释。
- Quantus 是一个可解释人工智能(eXplainable AI)工具包,用于负责任地评估神经网络解释。 - SHAP
 - SHapley Additive exPlanations(SHAP)是一种统一的解释任何机器学习模型输出的方法。
- SHapley Additive exPlanations(SHAP)是一种统一的解释任何机器学习模型输出的方法。 - SHAPash
 - Shapash 是一个 Python 库,提供多种可视化类型,显示每个人都能理解的显式标签。
- Shapash 是一个 Python 库,提供多种可视化类型,显示每个人都能理解的显式标签。 - WhatIf
 - 一个易于使用的界面,用于扩展对黑盒分类或回归 ML 模型的理解。
- 一个易于使用的界面,用于扩展对黑盒分类或回归 ML 模型的理解。
特征存储
- FEAST
 - Feast(特征存储)是机器学习的开源特征存储。Feast 是将现有基础设施管理到生产环境的最快途径,用于模型训练的分析和在线推理数据的生产化。
- Feast(特征存储)是机器学习的开源特征存储。Feast 是将现有基础设施管理到生产环境的最快途径,用于模型训练的分析和在线推理数据的生产化。 - Featureform
 - 一个虚拟特征存储。与您现有的基础设施即插即用。数据科学家批准。发现、治理、血缘和协作只需 pip install 即可。支持 pandas、Python、spark、SQL + 与主要云供应商的集成。
- 一个虚拟特征存储。与您现有的基础设施即插即用。数据科学家批准。发现、治理、血缘和协作只需 pip install 即可。支持 pandas、Python、spark、SQL + 与主要云供应商的集成。 - Hopsworks Feature Store
 - 机器学习离线/在线特征存储 (视频)。
- 机器学习离线/在线特征存储 (视频)。
工业级异常检测
- Alibi Detect
 - alibi-detect 是一个专注于离群点、对抗样本和概念漂移检测的 Python 包。
- alibi-detect 是一个专注于离群点、对抗样本和概念漂移检测的 Python 包。 - Darts
 - Darts 是一个用于时间序列友好型预测和异常检测的库。
- Darts 是一个用于时间序列友好型预测和异常检测的库。 - Deequ
 - 一个构建在 Apache Spark 之上的库,用于定义“数据的单元测试”,以衡量大型数据集中的数据质量。
- 一个构建在 Apache Spark 之上的库,用于定义“数据的单元测试”,以衡量大型数据集中的数据质量。 - PyOD
 - 一个用于可扩展离群点检测(异常检测)的 Python 工具箱。
- 一个用于可扩展离群点检测(异常检测)的 Python 工具箱。 - TFDV
 - TFDV(Tensorflow Data Validation)是一个用于探索和验证机器学习数据的库。
- TFDV(Tensorflow Data Validation)是一个用于探索和验证机器学习数据的库。
工业级计算机视觉
- CameraTraps
 - CameraTraps (PyTorch Wildlife) 是一个用于野生动物图像分析的协作式深度学习框架,提供在大规模相机陷阱数据集上训练的检测和分类模型。
- CameraTraps (PyTorch Wildlife) 是一个用于野生动物图像分析的协作式深度学习框架,提供在大规模相机陷阱数据集上训练的检测和分类模型。 - Deep Lake
 - Deep Lake 是专为计算机视觉优化的数据基础设施。
- Deep Lake 是专为计算机视觉优化的数据基础设施。 - DeepForest
 - DeepForest 是一个 Python 包,用于使用深度学习从航空 RGB 图像中训练和预测单个树冠及物种。
- DeepForest 是一个 Python 包,用于使用深度学习从航空 RGB 图像中训练和预测单个树冠及物种。 - Detectron2
 - Detectron2 是 Facebook AI Research 的下一代库,提供最先进的检测和分割算法。
- Detectron2 是 Facebook AI Research 的下一代库,提供最先进的检测和分割算法。 - KerasCV
 - KerasCV 是一套面向计算机视觉的模块化 Keras 组件库。
- KerasCV 是一套面向计算机视觉的模块化 Keras 组件库。 - Kornia
 - Kornia 是一个基于 PyTorch 构建的可微分计算机视觉库,提供丰富的可微分图像处理与几何视觉算法。
- Kornia 是一个基于 PyTorch 构建的可微分计算机视觉库,提供丰富的可微分图像处理与几何视觉算法。 - LAVIS
 - LAVIS 是一个用于语言与视觉智能研究和应用的深度学习库。
- LAVIS 是一个用于语言与视觉智能研究和应用的深度学习库。 - libcom
 - libcom 是一个图像合成工具箱。
- libcom 是一个图像合成工具箱。 - LightlyTrain
 - 在未标记数据上预训练计算机视觉模型,适用于工业应用。
- 在未标记数据上预训练计算机视觉模型,适用于工业应用。 - MMCV
 - MMCV 是 OpenMMLab 的基础计算机视觉库,提供图像和视频处理、数据转换与增强、CNN 架构以及优化的 CUDA 操作等核心功能。
- MMCV 是 OpenMMLab 的基础计算机视觉库,提供图像和视频处理、数据转换与增强、CNN 架构以及优化的 CUDA 操作等核心功能。 - SuperGradients
 - SuperGradients 是一个用于训练基于 PyTorch 的计算机视觉模型的开源库。
- SuperGradients 是一个用于训练基于 PyTorch 的计算机视觉模型的开源库。 - supervision
 - Supervision 是一个旨在高效管理计算机视觉流程的 Python 库,提供用于模型标注、可视化和监控的工具。
- Supervision 是一个旨在高效管理计算机视觉流程的 Python 库,提供用于模型标注、可视化和监控的工具。 - VideoSys
 - VideoSys 支持多种扩散模型,通过我们的各种加速技术,使这些模型运行更快且消耗更少的内存。
- VideoSys 支持多种扩散模型,通过我们的各种加速技术,使这些模型运行更快且消耗更少的内存。
工业级信息检索
- AutoRAG
 - AutoRAG 是一个 RAG(检索增强生成)AutoML(自动机器学习)工具,用于为您的数据自动寻找最佳的 RAG 流水线。
- AutoRAG 是一个 RAG(检索增强生成)AutoML(自动机器学习)工具,用于为您的数据自动寻找最佳的 RAG 流水线。 - BGE
 - BGE 为搜索和 RAG(检索增强生成)构建了一站式检索工具包。
- BGE 为搜索和 RAG(检索增强生成)构建了一站式检索工具包。 - Cognita
 - Cognita 是一个 RAG(检索增强生成)框架,用于构建模块化和生产就绪的应用程序。
- Cognita 是一个 RAG(检索增强生成)框架,用于构建模块化和生产就绪的应用程序。 - DocArray
 - DocArray 是一个用于处理嵌套、非结构化、多模态传输数据的库,包括文本、图像、音频、视频、3D 网格等。它允许深度学习工程师通过 Pythonic(符合 Python 风格)API 高效地处理、嵌入、搜索、推荐、存储和传输多模态数据。
- DocArray 是一个用于处理嵌套、非结构化、多模态传输数据的库,包括文本、图像、音频、视频、3D 网格等。它允许深度学习工程师通过 Pythonic(符合 Python 风格)API 高效地处理、嵌入、搜索、推荐、存储和传输多模态数据。 - EmbedAnything
 - EmbedAnything 是一个用 Rust 构建的极简、轻量且高性能的嵌入流水线,用于从文本、图像、音频、PDF 和其他媒体生成嵌入,支持稠密、稀疏、ONNX 和后期交互嵌入。
- EmbedAnything 是一个用 Rust 构建的极简、轻量且高性能的嵌入流水线,用于从文本、图像、音频、PDF 和其他媒体生成嵌入,支持稠密、稀疏、ONNX 和后期交互嵌入。 - Faiss
 - Faiss 是一个用于稠密向量高效相似度搜索和聚类的库。
- Faiss 是一个用于稠密向量高效相似度搜索和聚类的库。 - fastRAG
 - fastRAG 是一个研究框架,用于构建高效优化的检索增强生成流水线,结合了最先进的 LLM(大语言模型)和信息检索技术。
- fastRAG 是一个研究框架,用于构建高效优化的检索增强生成流水线,结合了最先进的 LLM(大语言模型)和信息检索技术。 - GraphRAG
 - GraphRAG 是一套数据流水线和转换套件,旨在利用 LLM(大语言模型)的能力从非结构化文本中提取有意义的结构化数据。
- GraphRAG 是一套数据流水线和转换套件,旨在利用 LLM(大语言模型)的能力从非结构化文本中提取有意义的结构化数据。 - HippoRAG
 - HippoRAG 是一种新颖的检索增强生成(RAG)框架,受人类长期记忆神经生物学启发,使 LLM(大语言模型)能够跨外部文档持续整合知识。
- HippoRAG 是一种新颖的检索增强生成(RAG)框架,受人类长期记忆神经生物学启发,使 LLM(大语言模型)能够跨外部文档持续整合知识。 - JamAI Base
 - JamAI Base 是一个开源 RAG(检索增强生成)后端平台,集成了嵌入式数据库(SQLite)和嵌入式向量数据库(LanceDB),具备托管内存和 RAG 功能。它具有内置的 LLM、向量嵌入和重排序编排与管理功能,所有功能均可通过便捷直观的类电子表格 UI 和简单的 REST API 访问。
- JamAI Base 是一个开源 RAG(检索增强生成)后端平台,集成了嵌入式数据库(SQLite)和嵌入式向量数据库(LanceDB),具备托管内存和 RAG 功能。它具有内置的 LLM、向量嵌入和重排序编排与管理功能,所有功能均可通过便捷直观的类电子表格 UI 和简单的 REST API 访问。 - LangExtract
 - LangExtract 是一个 Python 库,使用 LLM(大语言模型)根据用户定义的指令从非结构化文本文档中提取结构化信息。它处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。
- LangExtract 是一个 Python 库,使用 LLM(大语言模型)根据用户定义的指令从非结构化文本文档中提取结构化信息。它处理临床笔记或报告等材料,识别并组织关键细节,同时确保提取的数据与源文本对应。 - LightRAG
 - 一个简单快速的检索增强生成框架。
- 一个简单快速的检索增强生成框架。 - llmware
 - llmware 提供了一个统一框架,用于构建基于 LLM(大语言模型)的应用程序(例如,RAG、Agents(智能体)),使用小型专用模型,可以私有部署,安全地与企业知识库集成,并经济高效地针对任何业务流程进行微调和适配。
- llmware 提供了一个统一框架,用于构建基于 LLM(大语言模型)的应用程序(例如,RAG、Agents(智能体)),使用小型专用模型,可以私有部署,安全地与企业知识库集成,并经济高效地针对任何业务流程进行微调和适配。 - Mem0
 - Mem0 通过智能记忆层增强 AI 助手和智能体,实现个性化的 AI 交互。
- Mem0 通过智能记忆层增强 AI 助手和智能体,实现个性化的 AI 交互。 - NGT
 - NGT 提供命令和库,用于在高维向量数据空间中对大量数据进行高速近似最近邻搜索。
- NGT 提供命令和库,用于在高维向量数据空间中对大量数据进行高速近似最近邻搜索。 - NMSLIB
 - 非度量空间库(NMSLIB):一个高效的相似度搜索库,以及用于评估通用非度量空间中 k-NN(k-近邻)方法的工具包。
- 非度量空间库(NMSLIB):一个高效的相似度搜索库,以及用于评估通用非度量空间中 k-NN(k-近邻)方法的工具包。 - Qdrant
 - 一个具有扩展过滤支持的开源向量相似度搜索引擎。
- 一个具有扩展过滤支持的开源向量相似度搜索引擎。 - R2R
 - R2R(RAG to Riches)是一个综合平台,用于构建、部署和扩展 RAG(检索增强生成)应用程序,支持混合搜索、多模态支持和高级可观测性。
- R2R(RAG to Riches)是一个综合平台,用于构建、部署和扩展 RAG(检索增强生成)应用程序,支持混合搜索、多模态支持和高级可观测性。 - RAGFlow
 - RAGFlow 是一个基于深度文档理解的 RAG(检索增强生成)引擎。
- RAGFlow 是一个基于深度文档理解的 RAG(检索增强生成)引擎。 - RAGxplorer
 - RAGxplorer 是构建 RAG(检索增强生成)可视化的工具。
- RAGxplorer 是构建 RAG(检索增强生成)可视化的工具。 - RAG-FiT
 - RAG-FiT 是一个库,旨在通过在专门创建的 RAG 增强数据集上微调模型来提高 LLM(大语言模型)使用外部信息的能力。
- RAG-FiT 是一个库,旨在通过在专门创建的 RAG 增强数据集上微调模型来提高 LLM(大语言模型)使用外部信息的能力。 - TextWorld
 - TextWorld 是一个基于文本的游戏生成器和可扩展的沙箱学习环境,用于训练和测试强化学习(RL)智能体。
- TextWorld 是一个基于文本的游戏生成器和可扩展的沙箱学习环境,用于训练和测试强化学习(RL)智能体。 - Vanna
 - Vanna 是一个用于 SQL 生成及相关功能的 RAG(检索增强生成)框架。
- Vanna 是一个用于 SQL 生成及相关功能的 RAG(检索增强生成)框架。
工业级自然语言处理 (NLP)
- aisuite
 - aisuite 是一个简单的、统一的接口,用于连接多个生成式 AI (Generative AI) 提供商。
- aisuite 是一个简单的、统一的接口,用于连接多个生成式 AI (Generative AI) 提供商。 - Align-Anything
 - Align-Anything 旨在将任何模态的大模型 (Large Models)(任意到任意模型),包括大语言模型 (LLMs)、视觉语言模型 (VLMs) 等与人类的意图和价值观对齐。
- Align-Anything 旨在将任何模态的大模型 (Large Models)(任意到任意模型),包括大语言模型 (LLMs)、视觉语言模型 (VLMs) 等与人类的意图和价值观对齐。 - BERTopic
 - BERTopic 是一种主题建模技术,利用 transformers 和 c-TF-IDF 创建密集聚类,从而生成易于解释的主题,同时保留主题描述中的重要词汇。
- BERTopic 是一种主题建模技术,利用 transformers 和 c-TF-IDF 创建密集聚类,从而生成易于解释的主题,同时保留主题描述中的重要词汇。 - Burr
 - Burr 帮助您开发做出决策的应用程序(聊天机器人、智能体 (Agent)、模拟)。它具备生产就绪的功能(遥测、持久化、部署等)以及开源、免费且本地优先的 Burr UI。
- Burr 帮助您开发做出决策的应用程序(聊天机器人、智能体 (Agent)、模拟)。它具备生产就绪的功能(遥测、持久化、部署等)以及开源、免费且本地优先的 Burr UI。 - CodeTF
 - CodeTF 是一个一站式基于 Python 的 transformer 库,用于代码大语言模型 (Code LLMs) 和代码智能,为代码摘要、翻译、代码生成等代码智能任务的训练和推理提供无缝接口。
- CodeTF 是一个一站式基于 Python 的 transformer 库,用于代码大语言模型 (Code LLMs) 和代码智能,为代码摘要、翻译、代码生成等代码智能任务的训练和推理提供无缝接口。 - Dify
 - Dify 是一个开源的大语言模型 (LLM) 应用开发平台,其直观的界面结合了代理 AI (Agentic AI) 工作流、RAG (检索增强生成) 管道、智能体 (Agent) 能力、模型管理、可观测性功能等,让您能迅速从原型走向生产环境。
- Dify 是一个开源的大语言模型 (LLM) 应用开发平台,其直观的界面结合了代理 AI (Agentic AI) 工作流、RAG (检索增强生成) 管道、智能体 (Agent) 能力、模型管理、可观测性功能等,让您能迅速从原型走向生产环境。 - dspy
 - 一个用于使用基础模型 (Foundation Models) 进行编程的框架。
- 一个用于使用基础模型 (Foundation Models) 进行编程的框架。 - Dust
 - Dust 协助设计和部署大语言模型应用程序。
- Dust 协助设计和部署大语言模型应用程序。 - ESPnet
 - ESPnet 是一个端到端语音处理工具包。
- ESPnet 是一个端到端语音处理工具包。 - FastChat
 - FastChat 是一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台。
- FastChat 是一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台。 - Flair
 - 由 Zalando 开发的简单框架,用于最先进的自然语言处理 (NLP),直接基于 PyTorch 构建。
- 由 Zalando 开发的简单框架,用于最先进的自然语言处理 (NLP),直接基于 PyTorch 构建。 - Gensim
 - Gensim 是一个用于大型语料库的主题建模、文档索引和相似度检索的 Python 库。
- Gensim 是一个用于大型语料库的主题建模、文档索引和相似度检索的 Python 库。 - gpt-fast
 - 简单高效的原生 PyTorch transformer 文本生成。
- 简单高效的原生 PyTorch transformer 文本生成。 - h2oGPT
 - h2oGPT 是一个开源生成式 AI,赋予像您这样的组织拥有大语言模型的能力,同时保留您的数据所有权。
- h2oGPT 是一个开源生成式 AI,赋予像您这样的组织拥有大语言模型的能力,同时保留您的数据所有权。 - Haystack
 - Haystack 是一个开源自然语言处理 (NLP) 框架,用于使用 Transformer 模型和LLMs (GPT-3 等) 与您的数据进行交互。Haystack 提供生产就绪的工具,可快速构建类似 ChatGPT 的问答、语义搜索、文本生成等功能。
- Haystack 是一个开源自然语言处理 (NLP) 框架,用于使用 Transformer 模型和LLMs (GPT-3 等) 与您的数据进行交互。Haystack 提供生产就绪的工具,可快速构建类似 ChatGPT 的问答、语义搜索、文本生成等功能。 - Interactive Composition Explorer
 - ICE 是用于语言模型程序的 Python 库和追踪可视化工具。
- ICE 是用于语言模型程序的 Python 库和追踪可视化工具。 - Jan
 - Jan 是一个开源的 ChatGPT 替代品,可在您的计算机上 100% 离线运行,允许您下载并在本地运行 LLMs,享有完全的控制权和隐私保护。
- Jan 是一个开源的 ChatGPT 替代品,可在您的计算机上 100% 离线运行,允许您下载并在本地运行 LLMs,享有完全的控制权和隐私保护。 - Lamini
 - Lamini 是一个LLM 引擎,用于快速定制模型。
- Lamini 是一个LLM 引擎,用于快速定制模型。 - LangChain
 - LangChain 通过组合性协助构建基于LLMs 的应用程序。
- LangChain 通过组合性协助构建基于LLMs 的应用程序。 - LlamaIndex
 - LlamaIndex (GPT Index) 是您的 LLM 应用程序的数据框架。
- LlamaIndex (GPT Index) 是您的 LLM 应用程序的数据框架。 - LLaMA
 - LLaMA 旨在作为一个最小化、可修改且易读的示例,用于加载 LLaMA (arXiv) 模型并运行推理。
- LLaMA 旨在作为一个最小化、可修改且易读的示例,用于加载 LLaMA (arXiv) 模型并运行推理。 - LLaMA-Factory
 - LLaMA-Factory 使得无需代码的 CLI 和 Web UI 即可轻松微调 100 多种大语言模型。
- LLaMA-Factory 使得无需代码的 CLI 和 Web UI 即可轻松微调 100 多种大语言模型。 - LLMBox
 - LLMBox 是一个实现 LLMs 的综合库,包括统一的训练管道和全面的模型评估。
- LLMBox 是一个实现 LLMs 的综合库,包括统一的训练管道和全面的模型评估。 - LLaMA2-Accessory
 - LLaMA2-Accessory 是一个用于大语言模型 (LLMs) 和多模态 LLM 预训练、微调和部署的开源工具包。
- LLaMA2-Accessory 是一个用于大语言模型 (LLMs) 和多模态 LLM 预训练、微调和部署的开源工具包。 - LMFlow
 - LMFlow 是一个可扩展、便捷且高效的工具箱,用于微调大型机器学习模型。
- LMFlow 是一个可扩展、便捷且高效的工具箱,用于微调大型机器学习模型。 - Megatron-LM
 - Megatron-LM 是一个高度优化且高效的用于训练大语言模型的库。
- Megatron-LM 是一个高度优化且高效的用于训练大语言模型的库。 - MindNLP
 - MindNLP 是一个基于 MindSpore 的易用且高性能的自然语言处理 (NLP) 和 LLM 框架,兼容 Huggingface 的模型和数据集。
- MindNLP 是一个基于 MindSpore 的易用且高性能的自然语言处理 (NLP) 和 LLM 框架,兼容 Huggingface 的模型和数据集。 - MLC LLM
 - MLC LLM 是一个通用解决方案,允许任何语言模型在多样化的硬件后端和本地应用程序上原生部署,并为每个人提供一个高效框架,以便针对各自用例进一步优化模型性能。
- MLC LLM 是一个通用解决方案,允许任何语言模型在多样化的硬件后端和本地应用程序上原生部署,并为每个人提供一个高效框架,以便针对各自用例进一步优化模型性能。 - mlx-lm
 - MLX LM 是一个 Python 包,用于在 Apple Silicon 上使用 MLX 生成文本和微调大语言模型,具有与 Hugging Face Hub 的集成以及对量化和分布式推理的支持。
- MLX LM 是一个 Python 包,用于在 Apple Silicon 上使用 MLX 生成文本和微调大语言模型,具有与 Hugging Face Hub 的集成以及对量化和分布式推理的支持。 - Ollama
 - 在本地快速上手大语言模型。
- 在本地快速上手大语言模型。 - olmOCR
 - olmOCR 是一个用于训练语言模型以处理真实环境中 PDF 文档的工具包。
- olmOCR 是一个用于训练语言模型以处理真实环境中 PDF 文档的工具包。 - PaddleNLP
 - PaddleNLP 是基于 PaddlePaddle 深度学习框架的大型语言模型 (LLM) 开发套件,支持高效的大模型训练、无损压缩以及各种硬件设备上的高性能推理。
- PaddleNLP 是基于 PaddlePaddle 深度学习框架的大型语言模型 (LLM) 开发套件,支持高效的大模型训练、无损压缩以及各种硬件设备上的高性能推理。 - PyLLMs
 - PyLLMs 是一个极简 Python 库,用于连接各种语言模型 (LLMs),并内置了模型性能基准测试。
- PyLLMs 是一个极简 Python 库,用于连接各种语言模型 (LLMs),并内置了模型性能基准测试。 - Semantic Kernel
 - Semantic Kernel 是一个 SDK,它将 OpenAI、Azure OpenAI 和 Hugging Face 等大型语言模型 (LLMs) 与 C#、Python 和 Java 等传统编程语言集成。Semantic Kernel 通过允许您定义插件来实现这一点,这些插件只需几行代码即可链接在一起。
- Semantic Kernel 是一个 SDK,它将 OpenAI、Azure OpenAI 和 Hugging Face 等大型语言模型 (LLMs) 与 C#、Python 和 Java 等传统编程语言集成。Semantic Kernel 通过允许您定义插件来实现这一点,这些插件只需几行代码即可链接在一起。 - Sentence Transformers
 - Sentence Transformers 提供了一种简单的方法来计算句子、段落和图像的密集向量表示。
- Sentence Transformers 提供了一种简单的方法来计算句子、段落和图像的密集向量表示。 - SpaCy
 - spaCy 是一个用于 Python 和 Cython 的高级自然语言处理库。
- spaCy 是一个用于 Python 和 Cython 的高级自然语言处理库。 - SWIFT
 - SWIFT 是一个可扩展的轻量级深度学习模型微调基础设施。
- SWIFT 是一个可扩展的轻量级深度学习模型微调基础设施。 - Tensorflow Lingvo
 - 一个用于在 TensorFlow 中构建神经网络的框架,特别是序列模型。
- 一个用于在 TensorFlow 中构建神经网络的框架,特别是序列模型。 - Tensorflow Text
 - TensorFlow Text 提供了一系列与文本相关的类和操作,可直接用于 TensorFlow 2.0。
- TensorFlow Text 提供了一系列与文本相关的类和操作,可直接用于 TensorFlow 2.0。 - ToolBench
 - ToolBench 是一个用于训练、服务和评估用于工具学习的大语言模型的开放平台。
- ToolBench 是一个用于训练、服务和评估用于工具学习的大语言模型的开放平台。 - Transformers
 - Huggingface 的自然语言处理 (NLP) 最先进预训练模型库。
- Huggingface 的自然语言处理 (NLP) 最先进预训练模型库。
工业级推荐系统
- EasyRec
 - EasyRec 是一个用于大规模推荐算法的框架。
- EasyRec 是一个用于大规模推荐算法的框架。 - Gorse
 - Gorse 旨在成为一款通用的开源推荐系统,能够快速集成到多种在线服务中。
- Gorse 旨在成为一款通用的开源推荐系统,能够快速集成到多种在线服务中。 - Merlin
 - NVIDIA Merlin 是一个开源库,提供端到端的 GPU 加速推荐系统,涵盖从特征工程、预处理到训练深度学习模型以及在生产环境中进行推理的全过程。
- NVIDIA Merlin 是一个开源库,提供端到端的 GPU 加速推荐系统,涵盖从特征工程、预处理到训练深度学习模型以及在生产环境中进行推理的全过程。 - Recommenders
 - Recommenders 包含构建推荐系统的基准测试和最佳实践,以 Jupyter 笔记本的形式提供。
- Recommenders 包含构建推荐系统的基准测试和最佳实践,以 Jupyter 笔记本的形式提供。 - TorchRec
 - TorchRec 是一个面向 PyTorch 的领域库,旨在为大规模推荐系统(RecSys)提供所需的常见稀疏性和并行性原语。
- TorchRec 是一个面向 PyTorch 的领域库,旨在为大规模推荐系统(RecSys)提供所需的常见稀疏性和并行性原语。
工业级强化学习 (Reinforcement Learning)
- Acme
 - Acme 是一个强化学习 (RL) 构建块库,致力于提供简单、高效且可读性强的智能体。
- Acme 是一个强化学习 (RL) 构建块库,致力于提供简单、高效且可读性强的智能体。 - AReaL
 - AReaL 是一个强化学习库。
- AReaL 是一个强化学习库。 - ChatLearn
 - ChatLearn 是一个面向大语言模型 (LLM) 的灵活高效的强化学习 (RL) 训练框架,支持分布式训练引擎 (FSDP2, Megatron) 和推理引擎 (vLLM, SGLang),并采用 GRPO 和 GSPO 等现代强化学习算法。
- ChatLearn 是一个面向大语言模型 (LLM) 的灵活高效的强化学习 (RL) 训练框架,支持分布式训练引擎 (FSDP2, Megatron) 和推理引擎 (vLLM, SGLang),并采用 GRPO 和 GSPO 等现代强化学习算法。 - CleanRL
 - CleanRL 是一个深度强化学习库,提供高质量的文件级实现,具备对研究友好的特性。该实现简洁明了,但我们可以利用 AWS Batch 扩展以运行数千个实验。
- CleanRL 是一个深度强化学习库,提供高质量的文件级实现,具备对研究友好的特性。该实现简洁明了,但我们可以利用 AWS Batch 扩展以运行数千个实验。 - CompilerGym
 - CompilerGym 是一个用于编译器任务的易于使用且高性能的强化学习 (RL) 环境库。
- CompilerGym 是一个用于编译器任务的易于使用且高性能的强化学习 (RL) 环境库。 - d3rlpy
 - d3rlpy 是供从业者和研究人员使用的离线深度强化学习库。
- d3rlpy 是供从业者和研究人员使用的离线深度强化学习库。 - D4RL
 - D4RL 是一个用于离线强化学习 (RL) 的开源基准。
- D4RL 是一个用于离线强化学习 (RL) 的开源基准。 - Dopamine
 - Dopamine 是一个用于快速原型开发强化学习 (RL) 算法的研究框架。它旨在满足对小型、易于理解的代码库的需求,用户可以在其中自由地尝试各种大胆的想法(推测性研究)。
- Dopamine 是一个用于快速原型开发强化学习 (RL) 算法的研究框架。它旨在满足对小型、易于理解的代码库的需求,用户可以在其中自由地尝试各种大胆的想法(推测性研究)。 - EvoTorch
 - EvoTorch 是在 NNAISENSE 开发的开源进化计算库,基于 PyTorch 构建。
- EvoTorch 是在 NNAISENSE 开发的开源进化计算库,基于 PyTorch 构建。 - FinRL
 - FinRL 是首个展示金融强化学习 (RL) 巨大潜力的开源框架。
- FinRL 是首个展示金融强化学习 (RL) 巨大潜力的开源框架。 - Gymnasium
 - Gymnasium 是一个开源 Python 库,通过提供标准 API 来连接学习算法与环境,以及一套符合该 API 的标准环境集,从而用于开发和比较强化学习 (RL) 算法。
- Gymnasium 是一个开源 Python 库,通过提供标准 API 来连接学习算法与环境,以及一套符合该 API 的标准环境集,从而用于开发和比较强化学习 (RL) 算法。 - Gymnasium-Robotics
 - Gymnasium-Robotics 包含一系列使用 Gymnasium API 的强化学习 (RL) 机器人环境。这些环境使用 MuJoCo 物理引擎和维护的 mujoco python 绑定运行。
- Gymnasium-Robotics 包含一系列使用 Gymnasium API 的强化学习 (RL) 机器人环境。这些环境使用 MuJoCo 物理引擎和维护的 mujoco python 绑定运行。 - Jumanji
 - Jumanji 是一套用 JAX 编写的强化学习 (RL) 环境套件,为行业驱动的研究提供干净、硬件加速的环境。
- Jumanji 是一套用 JAX 编写的强化学习 (RL) 环境套件,为行业驱动的研究提供干净、硬件加速的环境。 - MARLlib
 - MARLlib 是一个基于 RLlib 的综合多智能体强化学习 (MARL) 算法库。它为 MARL 研究社区提供了一个统一的平台,用于构建、训练和评估多智能体强化学习算法。
- MARLlib 是一个基于 RLlib 的综合多智能体强化学习 (MARL) 算法库。它为 MARL 研究社区提供了一个统一的平台,用于构建、训练和评估多智能体强化学习算法。 - Mava
 - Mava 是一个用于 JAX 中分布式多智能体强化学习 (MARL) 的框架。
- Mava 是一个用于 JAX 中分布式多智能体强化学习 (MARL) 的框架。 - Melting Pot - Melting Pot 是一套用于多智能体强化学习 (MARL) 的测试场景套件。
- MetaDrive
 - MetaDrive 是一个驾驶模拟器,由多种可泛化的强化学习 (RL) 驾驶场景组成。
- MetaDrive 是一个驾驶模拟器,由多种可泛化的强化学习 (RL) 驾驶场景组成。 - Minigrid
 - Minigrid 库包含一系列离散网格世界环境,用于进行强化学习 (RL) 研究。这些环境遵循 Gymnasium 标准 API,设计为轻量级、快速且易于定制。
- Minigrid 库包含一系列离散网格世界环境,用于进行强化学习 (RL) 研究。这些环境遵循 Gymnasium 标准 API,设计为轻量级、快速且易于定制。 - MiniWorld
 - MiniWorld 是一个用于强化学习 (RL) 和机器人研究的极简主义 3D 室内环境模拟器。
- MiniWorld 是一个用于强化学习 (RL) 和机器人研究的极简主义 3D 室内环境模拟器。 - ML-Agents
 - ML-Agents 是一个开源项目,使游戏和模拟能够作为训练强化学习 (RL) 智能体的环境。
- ML-Agents 是一个开源项目,使游戏和模拟能够作为训练强化学习 (RL) 智能体的环境。 - MLGym
 - MLGym 是一个 Gym 环境,支持针对机器学习任务训练此类智能体的强化学习 (RL) 算法研究。
- MLGym 是一个 Gym 环境,支持针对机器学习任务训练此类智能体的强化学习 (RL) 算法研究。 - MushroomRL
 - MushroomRL 是一个 Python 强化学习 (RL) 库,其模块化允许轻松使用知名的 Python 张量计算库(例如 PyTorch, Tensorflow)和强化学习基准(例如 OpenAI Gym, PyBullet, Deepmind Control Suite)。
- MushroomRL 是一个 Python 强化学习 (RL) 库,其模块化允许轻松使用知名的 Python 张量计算库(例如 PyTorch, Tensorflow)和强化学习基准(例如 OpenAI Gym, PyBullet, Deepmind Control Suite)。 - OmniSafe
 - OmniSafe 是一个旨在加速安全强化学习 (RL) 研究的架构框架。
- OmniSafe 是一个旨在加速安全强化学习 (RL) 研究的架构框架。 - OpenRLHF
 - OpenRLHF 是一个用于人类反馈强化学习 (RLHF) 的开源框架。
- OpenRLHF 是一个用于人类反馈强化学习 (RLHF) 的开源框架。 - PARL
 - PARL 是一个灵活且高效的强化学习 (RL) 框架。
- PARL 是一个灵活且高效的强化学习 (RL) 框架。 - PettingZoo
 - PettingZoo 是一个用于多智能体强化学习 (MARL) 研究的 Python 库,类似于多智能体版本的 Gymnasium。
- PettingZoo 是一个用于多智能体强化学习 (MARL) 研究的 Python 库,类似于多智能体版本的 Gymnasium。 - ranx
 - ranx 是一个用 Python 实现的快速排名评估指标库,利用 Numba 进行高速向量运算和自动并行化。
- ranx 是一个用 Python 实现的快速排名评估指标库,利用 Numba 进行高速向量运算和自动并行化。 - RL4CO
 - RL4CO 是一个 PyTorch 库,涵盖组合优化 (CO) 相关的所有强化学习 (RL) 内容。
- RL4CO 是一个 PyTorch 库,涵盖组合优化 (CO) 相关的所有强化学习 (RL) 内容。 - RL2
 - RL2 是一个强化学习 (RL) 库。
- RL2 是一个强化学习 (RL) 库。 - RLinf
 - RLinf 是一个强化学习 (RL) 库。
- RLinf 是一个强化学习 (RL) 库。 - ROLL
 - ROLL 是一个强化学习 (RL) 库。
- ROLL 是一个强化学习 (RL) 库。 - skrl
 - skrl 是一个用 Python(使用 PyTorch)编写的开源模块化强化学习 (RL) 库,设计重点在于算法实现的易读性、简单性和透明度。
- skrl 是一个用 Python(使用 PyTorch)编写的开源模块化强化学习 (RL) 库,设计重点在于算法实现的易读性、简单性和透明度。 - slime
 - slime 是一个用于 RL 扩展的大语言模型 (LLM) 后训练框架。
- slime 是一个用于 RL 扩展的大语言模型 (LLM) 后训练框架。 - Stable Baselines
 - OpenAI Baselines 的一个分支,实现了强化学习 (RL) 算法。
- OpenAI Baselines 的一个分支,实现了强化学习 (RL) 算法。 - TF-Agents
 - 一个可靠、可扩展且易于使用的 TensorFlow 库,用于上下文赌博机和强化学习 (RL)。
- 一个可靠、可扩展且易于使用的 TensorFlow 库,用于上下文赌博机和强化学习 (RL)。 - TorchRL
 - TorchRL 是一个用于 PyTorch 的开源强化学习 (RL) 库。
- TorchRL 是一个用于 PyTorch 的开源强化学习 (RL) 库。 - TRL
 - 使用强化学习 (RL) 训练 Transformer 语言模型。
- 使用强化学习 (RL) 训练 Transformer 语言模型。 - veRL
 - veRL (HybridFlow) 是一个专为大语言模型 (LLM) 设计的灵活、高效且工业级的强化学习 (HF) 训练框架。
- veRL (HybridFlow) 是一个专为大语言模型 (LLM) 设计的灵活、高效且工业级的强化学习 (HF) 训练框架。
工业级机器人
- AI2-THOR
 - AI2-THOR 是一个面向 AI 智能体(AI agents)的近照片级真实可交互框架。
- AI2-THOR 是一个面向 AI 智能体(AI agents)的近照片级真实可交互框架。 - Habitat-Sim
 - Habitat-Sim 是一个用于具身人工智能(Embodied AI)研究的灵活、高性能 3D 模拟器。
- Habitat-Sim 是一个用于具身人工智能(Embodied AI)研究的灵活、高性能 3D 模拟器。 - IsaacLab
 - IsaacLab 是一个统一且模块化的机器人学习框架,依托 NVIDIA Isaac Sim 构建。
- IsaacLab 是一个统一且模块化的机器人学习框架,依托 NVIDIA Isaac Sim 构建。 - robosuite
 - robosuite 是一个由 MuJoCo 物理引擎驱动的仿真框架,用于机器人学习。
- robosuite 是一个由 MuJoCo 物理引擎驱动的仿真框架,用于机器人学习。 - RoboVerse
 - RoboVerse 是一个拥有多样化环境的综合性机器人仿真平台。
- RoboVerse 是一个拥有多样化环境的综合性机器人仿真平台。
工业级可视化
- Apache ECharts
 - Apache ECharts 是一个功能强大、交互式的浏览器图表和数据可视化库。
- Apache ECharts 是一个功能强大、交互式的浏览器图表和数据可视化库。 - Apache Superset
 - 一款现代化的、面向企业的商业智能 (Business Intelligence) Web 应用程序。
- 一款现代化的、面向企业的商业智能 (Business Intelligence) Web 应用程序。 - Bokeh
 - Bokeh 是一个 Python 交互式可视化库,能够在现代 Web 浏览器中实现美观且有意义的可视化展示。
- Bokeh 是一个 Python 交互式可视化库,能够在现代 Web 浏览器中实现美观且有意义的可视化展示。 - Bread Dataset Viewer - 一个 VS Code 扩展,用于在编辑器内直接查看和探索大型机器学习 (Machine Learning) 数据集(CSV、JSON、Parquet 等),而不会导致集成开发环境 (IDE) 崩溃。
- Bread WandB Viewer - 一个用于在 IDE 内查看 Weights & Biases 实验、日志和工件的 VS Code 扩展,消除了切换到 Web 用户界面 (Web UI) 的需求,并通过 100% 离线运行来保护数据隐私。
- Data Formulator
 - 利用人工智能 (AI) 迭代地转换数据并创建丰富的可视化效果。
- 利用人工智能 (AI) 迭代地转换数据并创建丰富的可视化效果。 - ggplot2
 - R 语言的图形语法实现。
- R 语言的图形语法实现。 - gradio
 - 仅通过编写 Python 即可快速创建和分享模型演示。在浏览器中交互式调试模型,获取协作人员反馈,并生成公开链接,无需部署任何内容。
- 仅通过编写 Python 即可快速创建和分享模型演示。在浏览器中交互式调试模型,获取协作人员反馈,并生成公开链接,无需部署任何内容。 - Kangas
 - Kangas 是用于探索、分析和可视化大规模多媒体数据的工具。它提供直观的 Python API 用于记录大型数据表,以及直观可视化界面以针对数据集执行复杂查询。
- Kangas 是用于探索、分析和可视化大规模多媒体数据的工具。它提供直观的 Python API 用于记录大型数据表,以及直观可视化界面以针对数据集执行复杂查询。 - matplotlib
 - 一个 Python 2D 绘图库,可在跨平台的多种硬拷贝格式和交互式环境中生成出版级图表。
- 一个 Python 2D 绘图库,可在跨平台的多种硬拷贝格式和交互式环境中生成出版级图表。 - Netron
 - Netron 是神经网络 (Neural Network)、深度学习 (Deep Learning) 和机器学习的模型查看器。
- Netron 是神经网络 (Neural Network)、深度学习 (Deep Learning) 和机器学习的模型查看器。 - Perspective
 通过 WebAssembly 进行流式透视可视化。
通过 WebAssembly 进行流式透视可视化。 - Plotly
 - Python 交互式、开源且基于浏览器的绘图库。
- Python 交互式、开源且基于浏览器的绘图库。 - Redash
 - Redash 是一个开源可视化框架,旨在允许轻松访问利用多个后端的大数据集。
- Redash 是一个开源可视化框架,旨在允许轻松访问利用多个后端的大数据集。 - Rerun
 - Rerun 是用于记录、存储、查询和可视化多模态数据的开源软件开发工具包 (SDK),专为机器人学 (Robotics)、计算机视觉 (Computer Vision) 和空间人工智能 (Spatial AI) 设计。
- Rerun 是用于记录、存储、查询和可视化多模态数据的开源软件开发工具包 (SDK),专为机器人学 (Robotics)、计算机视觉 (Computer Vision) 和空间人工智能 (Spatial AI) 设计。 - seaborn
 - Seaborn 是基于 matplotlib 的 Python 可视化库。它提供了绘制精美统计图形的高级接口。
- Seaborn 是基于 matplotlib 的 Python 可视化库。它提供了绘制精美统计图形的高级接口。 - Spotlight
 - Spotlight 帮助您识别关键数据段和模型故障模式。它使您能够通过策划高质量数据集来构建和维护可靠的机器学习模型。
- Spotlight 帮助您识别关键数据段和模型故障模式。它使您能够通过策划高质量数据集来构建和维护可靠的机器学习模型。 - Streamlit
 - 让您使用看似简单的 Python 脚本为机器学习项目创建应用程序。它支持热重载 (hot-reloading),因此您在编辑和保存文件时,应用程序会实时更新。
- 让您使用看似简单的 Python 脚本为机器学习项目创建应用程序。它支持热重载 (hot-reloading),因此您在编辑和保存文件时,应用程序会实时更新。 - tensorboardX
 - 通过简单的函数调用编写 TensorBoard 事件。
- 通过简单的函数调用编写 TensorBoard 事件。 - TensorBoard
 - TensorBoard 是机器学习实验的可视化工具包,使得托管、跟踪和共享机器学习实验变得简单。
- TensorBoard 是机器学习实验的可视化工具包,使得托管、跟踪和共享机器学习实验变得简单。 - Transformer Explainer
 - Transformer Explainer 是一款交互式可视化工具,旨在帮助任何人了解基于 Transformer 的模型(如 GPT)的工作原理。
- Transformer Explainer 是一款交互式可视化工具,旨在帮助任何人了解基于 Transformer 的模型(如 GPT)的工作原理。 - Vega-Altair
 - Vega-Altair 是 Python 的声明式统计可视化库。
- Vega-Altair 是 Python 的声明式统计可视化库。 - ydata-profiling
 - ydata-profiling 提供了一行代码完成探索性数据分析 (EDA) 的一致且快速的解决方案。
- ydata-profiling 提供了一行代码完成探索性数据分析 (EDA) 的一致且快速的解决方案。
元数据管理
- Amundsen
 - Amundsen 是一个元数据驱动 (Metadata-driven) 的应用程序,旨在提高数据分析师、数据科学家和工程师在与数据交互时的生产力。
- Amundsen 是一个元数据驱动 (Metadata-driven) 的应用程序,旨在提高数据分析师、数据科学家和工程师在与数据交互时的生产力。 - Apache Atlas
 - Apache Atlas 框架是一套可扩展的核心基础治理服务 (Governance Services),使企业能够在 Hadoop 内有效且高效地满足其合规要求,并允许与整个企业数据生态系统集成。
- Apache Atlas 框架是一套可扩展的核心基础治理服务 (Governance Services),使企业能够在 Hadoop 内有效且高效地满足其合规要求,并允许与整个企业数据生态系统集成。 - DataHub
 - DataHub 是 LinkedIn 开发的通用元数据搜索与发现工具 (Metadata Search & Discovery Tool)。
- DataHub 是 LinkedIn 开发的通用元数据搜索与发现工具 (Metadata Search & Discovery Tool)。 - Marquez
 - Marquez 是一个开源元数据服务,用于收集、聚合和可视化数据生态系统的元数据。
- Marquez 是一个开源元数据服务,用于收集、聚合和可视化数据生态系统的元数据。 - Metacat
 - Metacat 是一个统一的元数据探索 API 服务。Metacat 专注于解决以下问题:1) 元数据系统的联邦视图 (Federated Views);2) 关于数据集的任意元数据存储;3) 元数据发现。
- Metacat 是一个统一的元数据探索 API 服务。Metacat 专注于解决以下问题:1) 元数据系统的联邦视图 (Federated Views);2) 关于数据集的任意元数据存储;3) 元数据发现。 - ML Metadata
 - 一个用于记录和检索与机器学习 (ML) 开发者和数据科学家工作流相关联的元数据的库。
- 一个用于记录和检索与机器学习 (ML) 开发者和数据科学家工作流相关联的元数据的库。
模型、数据与实验管理
- Aim
 - 一种超级简单的方式来记录、搜索和比较人工智能 (AI) 实验。
- 一种超级简单的方式来记录、搜索和比较人工智能 (AI) 实验。 - ClearML
 - 人工智能的自动化实验管理与版本控制 (Version Control)(前身为 Trains)。
- 人工智能的自动化实验管理与版本控制 (Version Control)(前身为 Trains)。 - DataHub - DataHub 是现代数据栈 (Modern Data Stack) 的开源数据目录。
- Dolt
 - Dolt 是一个 SQL 数据库,你可以像 Git 仓库一样对其进行分叉 (Fork)、克隆 (Clone)、分支 (Branch)、合并 (Merge)、推送 (Push) 和拉取 (Pull)。
- Dolt 是一个 SQL 数据库,你可以像 Git 仓库一样对其进行分叉 (Fork)、克隆 (Clone)、分支 (Branch)、合并 (Merge)、推送 (Push) 和拉取 (Pull)。 - DVC
 - DVC (Data Version Control,数据版本控制) 是一个 Git 分支,允许对模型进行版本管理。
- DVC (Data Version Control,数据版本控制) 是一个 Git 分支,允许对模型进行版本管理。 - HuggingFace Model Downloader
 - HuggingFace Model Downloader 是一个用于从 HuggingFace 网站下载模型和数据集的实用工具。它提供 LFS 文件的多线程下载,并通过 SHA256 校验和验证确保下载模型的完整性。
- HuggingFace Model Downloader 是一个用于从 HuggingFace 网站下载模型和数据集的实用工具。它提供 LFS 文件的多线程下载,并通过 SHA256 校验和验证确保下载模型的完整性。 - Keepsake
 - 机器学习的版本控制。
- 机器学习的版本控制。 - KitOps
 - KitOps 是一个基于开放标准的 AI/ML 项目打包和版本控制系统,可与所有你正在使用的 AI/ML、开发和 DevOps 工具配合使用。
- KitOps 是一个基于开放标准的 AI/ML 项目打包和版本控制系统,可与所有你正在使用的 AI/ML、开发和 DevOps 工具配合使用。 - lakeFS
 - 建立在对象存储之上的可重复、原子化且带版本的数据湖。
- 建立在对象存储之上的可重复、原子化且带版本的数据湖。 - MLflow
 - 用于管理机器学习 (ML) 生命周期的开源平台,包括实验、可复现性和部署。
- 用于管理机器学习 (ML) 生命周期的开源平台,包括实验、可复现性和部署。 - Neptune
 - Neptune 是为训练基础模型 (Foundation Models) 的团队提供的可扩展实验追踪器。
- Neptune 是为训练基础模型 (Foundation Models) 的团队提供的可扩展实验追踪器。 - Polyaxon
 - 一个用于在 Kubernetes 上进行可复现和可扩展的机器学习及深度学习的平台 - (视频)。
- 一个用于在 Kubernetes 上进行可复现和可扩展的机器学习及深度学习的平台 - (视频)。 - Quilt
 - 数据和模型的版本控制、可复现性和部署。
- 数据和模型的版本控制、可复现性和部署。 - Sacred
 - 帮助你配置、组织、记录并复现机器学习实验的工具。
- 帮助你配置、组织、记录并复现机器学习实验的工具。 - TerminusDB
 - 一个像 Git 一样存储数据的图数据库管理系统。
- 一个像 Git 一样存储数据的图数据库管理系统。 - Weights & Biases
 - Weights & Biases 是一个机器学习实验追踪、数据集版本控制、超参数搜索、可视化和协作平台。
- Weights & Biases 是一个机器学习实验追踪、数据集版本控制、超参数搜索、可视化和协作平台。
模型训练与编排
- AutoTrain Advanced
 - AutoTrain Advanced 是一个无代码解决方案,允许您只需几次点击即可训练机器学习 (Machine Learning) 模型。
- AutoTrain Advanced 是一个无代码解决方案,允许您只需几次点击即可训练机器学习 (Machine Learning) 模型。 - Avalanche
 - Avalanche 是一个端到端 (End-to-End) 持续学习 (Continual Learning) 库,旨在提供一个共享且协作的开源(MIT 许可)代码库,用于快速原型设计、训练和可复现地评估持续学习算法。
- Avalanche 是一个端到端 (End-to-End) 持续学习 (Continual Learning) 库,旨在提供一个共享且协作的开源(MIT 许可)代码库,用于快速原型设计、训练和可复现地评估持续学习算法。 - Axolotl
 - Axolotl 是一款旨在简化各种人工智能 (AI) 模型微调 (Fine-tuning) 的工具,支持多种配置和架构。
- Axolotl 是一款旨在简化各种人工智能 (AI) 模型微调 (Fine-tuning) 的工具,支持多种配置和架构。 - BindsNET
 - BindsNET 是一个脉冲神经网络 (Spiking Neural Network) 仿真库,专注于开发用于机器学习的生物启发式算法。
- BindsNET 是一个脉冲神经网络 (Spiking Neural Network) 仿真库,专注于开发用于机器学习的生物启发式算法。 - CML
 - 持续机器学习 (Continuous Machine Learning, CML) 是一个开源库,用于在机器学习项目中实施持续集成与交付 (CI/CD)。
- 持续机器学习 (Continuous Machine Learning, CML) 是一个开源库,用于在机器学习项目中实施持续集成与交付 (CI/CD)。 - CoreNet
 - CoreNet 是一个深度神经网络 (Deep Neural Network) 工具包,允许研究人员和工程师训练标准和新型的小规模及大规模模型,适用于各种任务,包括基础模型(例如 CLIP 和 大语言模型 (LLM))、物体分类、物体检测和语义分割。
- CoreNet 是一个深度神经网络 (Deep Neural Network) 工具包,允许研究人员和工程师训练标准和新型的小规模及大规模模型,适用于各种任务,包括基础模型(例如 CLIP 和 大语言模型 (LLM))、物体分类、物体检测和语义分割。 - Determined
 - 深度学习 (Deep Learning) 训练平台,集成了分布式训练、超参数调优和模型管理的支持(支持 TensorFlow 和 PyTorch)。
- 深度学习 (Deep Learning) 训练平台,集成了分布式训练、超参数调优和模型管理的支持(支持 TensorFlow 和 PyTorch)。 - dstack
 - dstack 是一个开源容器编排器,简化了工作负载编排,并提高了机器学习团队的 GPU (图形处理器) 利用率。
- dstack 是一个开源容器编排器,简化了工作负载编排,并提高了机器学习团队的 GPU (图形处理器) 利用率。 - envd
 - 面向数据科学和人工智能 (AI)/机器学习工程团队的机器学习开发环境。
- 面向数据科学和人工智能 (AI)/机器学习工程团队的机器学习开发环境。 - Fairseq
 - Fairseq(-py) 是一个序列建模工具包,允许研究人员和开发者为翻译、摘要、语言建模和其他文本生成任务训练自定义模型。
- Fairseq(-py) 是一个序列建模工具包,允许研究人员和开发者为翻译、摘要、语言建模和其他文本生成任务训练自定义模型。 - Fire-Flyer File System
 - Fire-Flyer 文件系统(3FS)是一种高性能分布式文件系统,旨在解决人工智能 (AI) 训练和推理工作负载的挑战。它利用现代 SSD (固态硬盘) 和 RDMA (远程直接内存访问) 网络提供共享存储层,简化分布式应用程序的开发。
- Fire-Flyer 文件系统(3FS)是一种高性能分布式文件系统,旨在解决人工智能 (AI) 训练和推理工作负载的挑战。它利用现代 SSD (固态硬盘) 和 RDMA (远程直接内存访问) 网络提供共享存储层,简化分布式应用程序的开发。 - H2O-3
 - 用于更智能应用的快速可扩展机器学习平台:深度学习、梯度提升与 XGBoost、随机森林、广义线性建模(逻辑回归、弹性网络)、K-Means、PCA、堆叠集成、自动机器学习 (AutoML) 等。
- 用于更智能应用的快速可扩展机器学习平台:深度学习、梯度提升与 XGBoost、随机森林、广义线性建模(逻辑回归、弹性网络)、K-Means、PCA、堆叠集成、自动机器学习 (AutoML) 等。 - Hopsworks - Hopsworks 是一个数据密集型平台,用于设计和运行机器学习流水线。
- Ignite
 - Ignite 是一个高级库,旨在灵活且透明地帮助在 PyTorch 中训练和评估神经网络。
- Ignite 是一个高级库,旨在灵活且透明地帮助在 PyTorch 中训练和评估神经网络。 - Kubeflow
 - 基于 Google 内部机器学习流水线的云原生 (Cloud-Native) 机器学习平台。
- 基于 Google 内部机器学习流水线的云原生 (Cloud-Native) 机器学习平台。 - Ludwig
 - Ludwig 是一个低代码框架,用于构建自定义人工智能 (AI) 模型,如 大语言模型 (LLM) 和其他深度神经网络。
- Ludwig 是一个低代码框架,用于构建自定义人工智能 (AI) 模型,如 大语言模型 (LLM) 和其他深度神经网络。 - MFTCoder
 - MFTCoder 是 CodeFuse 的一个开源项目,用于在大语言模型 (LLM) 上准确高效地进行多任务微调 (MFT),特别是在代码大语言模型(Code-LLM,用于代码任务的大语言模型)上。
- MFTCoder 是 CodeFuse 的一个开源项目,用于在大语言模型 (LLM) 上准确高效地进行多任务微调 (MFT),特别是在代码大语言模型(Code-LLM,用于代码任务的大语言模型)上。 - MLeap
 - 针对 Spark、TensorFlow 和 sklearn 的流水线 (Pipeline) 和模型序列化标准化。
- 针对 Spark、TensorFlow 和 sklearn 的流水线 (Pipeline) 和模型序列化标准化。 - Nanotron
 - Nanotron 提供分布式原语,使用 3D 并行性高效训练各种模型。
- Nanotron 提供分布式原语,使用 3D 并行性高效训练各种模型。 - NeMo
 - NVIDIA NeMo 是一个可扩展的云原生生成式人工智能 (AI) 框架,专为从事大语言模型 (LLM)、多模态模型 (MM)、自动语音识别 (ASR)、文本转语音 (TTS) 和计算机视觉 (CV) 领域的研究人员和 PyTorch 开发者打造。它旨在通过利用现有代码和预训练模型检查点,帮助您高效地创建、定制和部署新的生成式 AI 模型。
- NVIDIA NeMo 是一个可扩展的云原生生成式人工智能 (AI) 框架,专为从事大语言模型 (LLM)、多模态模型 (MM)、自动语音识别 (ASR)、文本转语音 (TTS) 和计算机视觉 (CV) 领域的研究人员和 PyTorch 开发者打造。它旨在通过利用现有代码和预训练模型检查点,帮助您高效地创建、定制和部署新的生成式 AI 模型。 - Prime
 - Prime 是一个框架,用于在互联网上高效地全球分布式训练人工智能 (AI) 模型。
- Prime 是一个框架,用于在互联网上高效地全球分布式训练人工智能 (AI) 模型。 - PyCaret
 - 用于训练和部署模型的 低代码 (Low-code) 库(scikit-learn, XGBoost, LightGBM, spaCy)
- 用于训练和部署模型的 低代码 (Low-code) 库(scikit-learn, XGBoost, LightGBM, spaCy) - Sematic
 - 使用简单的 Python 构建资源密集型流水线的平台。
- 使用简单的 Python 构建资源密集型流水线的平台。 - Skaffold
 - Skaffold 是一个命令行工具,促进 Kubernetes 应用的持续开发。您可以在本地迭代应用程序源代码,然后部署到本地或远程 Kubernetes 集群。
- Skaffold 是一个命令行工具,促进 Kubernetes 应用的持续开发。您可以在本地迭代应用程序源代码,然后部署到本地或远程 Kubernetes 集群。 - TFX
 - Tensorflow Extended (TFX) 是一个基于 TensorFlow 的生产导向型机器学习配置框架,包括监控和模型版本管理。
- Tensorflow Extended (TFX) 是一个基于 TensorFlow 的生产导向型机器学习配置框架,包括监控和模型版本管理。 - unsloth
 - 针对 大语言模型 (LLM) 的微调与强化学习。以 2 倍速度和 70% 更少的显存 (VRAM) 训练 OpenAI gpt-oss, DeepSeek-R1, Qwen3, Gemma 3, TTS。
- 针对 大语言模型 (LLM) 的微调与强化学习。以 2 倍速度和 70% 更少的显存 (VRAM) 训练 OpenAI gpt-oss, DeepSeek-R1, Qwen3, Gemma 3, TTS。
模型存储优化
- AutoAWQ
 - AutoAWQ 是一个易于使用的工具包,用于 4 位量化模型。
- AutoAWQ 是一个易于使用的工具包,用于 4 位量化模型。 - AutoGPTQ
 - 一个易于使用的大语言模型(LLMs)量化工具包,拥有用户友好的 API(应用程序接口),基于 GPTQ 算法。
- 一个易于使用的大语言模型(LLMs)量化工具包,拥有用户友好的 API(应用程序接口),基于 GPTQ 算法。 - AWQ
 - 面向大语言模型(LLM)压缩与加速的感知激活权重量化(Activation-aware Weight Quantization)。
- 面向大语言模型(LLM)压缩与加速的感知激活权重量化(Activation-aware Weight Quantization)。 - GGML
 - GGML 是一个高性能的机器学习张量库,支持在 CPU(中央处理器)上进行高效推理,特别针对大语言模型进行了优化。
- GGML 是一个高性能的机器学习张量库,支持在 CPU(中央处理器)上进行高效推理,特别针对大语言模型进行了优化。 - neural-compressor
 - Intel® Neural Compressor 旨在主流框架上提供流行的模型压缩技术,如量化、剪枝(稀疏性)、蒸馏和神经架构搜索。
- Intel® Neural Compressor 旨在主流框架上提供流行的模型压缩技术,如量化、剪枝(稀疏性)、蒸馏和神经架构搜索。 - NNEF - 神经网络交换格式(Neural Network Exchange Format, NNEF)是一种开放标准,用于表示神经网络模型,以实现不同机器学习框架和平台之间的互操作性和可移植性。
- ONNX
 - ONNX(开放神经网络交换,Open Neural Network Exchange)是一种开源格式,旨在促进不同框架和平台之间机器学习模型的互操作性和可移植性。
- ONNX(开放神经网络交换,Open Neural Network Exchange)是一种开源格式,旨在促进不同框架和平台之间机器学习模型的互操作性和可移植性。 - PFA - PFA(分析便携格式,Portable Format for Analytics)格式是一种标准,用于以便携式、基于 JSON 的格式表示和交换预测模型和分析工作流。
- PMML - PMML(预测模型标记语言,Predictive Model Markup Language)是一种基于 XML 的标准,用于在不同应用程序之间表示和共享预测模型。
- Quanto
 - Quanto 旨在简化深度学习模型的量化过程。
- Quanto 旨在简化深度学习模型的量化过程。
隐私与安全
- AI Gateway
 - AI Gateway 是一个集成安全护栏(Guardrails)的极速 AI 网关。
- AI Gateway 是一个集成安全护栏(Guardrails)的极速 AI 网关。 - AI Job Displacement Tracker
 - 结构化、有来源支持的数据集,追踪了 96 起归因于 AI 的人员缩减(影响 45.7 万名员工,涉及 13 个国家、13 个行业)。每个条目均包含来源 URL、归因层级和职能。
- 结构化、有来源支持的数据集,追踪了 96 起归因于 AI 的人员缩减(影响 45.7 万名员工,涉及 13 个国家、13 个行业)。每个条目均包含来源 URL、归因层级和职能。 - ART
 - ART(对抗鲁棒性工具箱,Adversarial Robustness Toolbox)提供工具,使开发者和研究人员能够防御和评估机器学习(Machine Learning)模型及应用免受逃避(Evasion)、投毒(Poisoning)、提取(Extraction)和推理(Inference)等对抗威胁。
- ART(对抗鲁棒性工具箱,Adversarial Robustness Toolbox)提供工具,使开发者和研究人员能够防御和评估机器学习(Machine Learning)模型及应用免受逃避(Evasion)、投毒(Poisoning)、提取(Extraction)和推理(Inference)等对抗威胁。 - CipherChat
 - CipherChat 是一个用于评估大型语言模型(LLMs)安全对齐泛化能力的框架。
- CipherChat 是一个用于评估大型语言模型(LLMs)安全对齐泛化能力的框架。 - DeepTeam
 - DeepTeam 是一个简单易用的开源大型语言模型(LLM)红队测试(red teaming)框架,用于渗透测试和保护大型语言模型系统。
- DeepTeam 是一个简单易用的开源大型语言模型(LLM)红队测试(red teaming)框架,用于渗透测试和保护大型语言模型系统。 - FATE
 - FATE(联邦人工智能技术赋能器,Federated AI Technology Enabler)是全球首个工业级联邦学习(Federated Learning)开源框架,旨在使企业和机构能够在保护数据安全与隐私的同时进行数据协作。
- FATE(联邦人工智能技术赋能器,Federated AI Technology Enabler)是全球首个工业级联邦学习(Federated Learning)开源框架,旨在使企业和机构能够在保护数据安全与隐私的同时进行数据协作。 - FedML
 - FedML 为任何规模、任何地点的联邦/分布式机器学习提供了研究与生产一体化的边缘云平台。
- FedML 为任何规模、任何地点的联邦/分布式机器学习提供了研究与生产一体化的边缘云平台。 - Flower
 - Flower 是一个具有统一方法的联邦学习框架。它支持任何机器学习工作负载与任何机器学习框架及编程语言的联合。
- Flower 是一个具有统一方法的联邦学习框架。它支持任何机器学习工作负载与任何机器学习框架及编程语言的联合。 - Google's Differential Privacy
 - 这是一个包含 ε-差分隐私(ε-differentially private)算法的 C++ 库,可用于生成包含私有或敏感信息的数值数据集的聚合统计信息。
- 这是一个包含 ε-差分隐私(ε-differentially private)算法的 C++ 库,可用于生成包含私有或敏感信息的数值数据集的聚合统计信息。 - Guardrails
 - Guardrails 是一个包,允许用户为大语言模型的输出添加结构、类型和质量保证。
- Guardrails 是一个包,允许用户为大语言模型的输出添加结构、类型和质量保证。 - NeMo Guardrails
 - NeMo Guardrails 是一个开源工具包,用于轻松地为基于大型语言模型的对话系统添加可编程的安全护栏。
- NeMo Guardrails 是一个开源工具包,用于轻松地为基于大型语言模型的对话系统添加可编程的安全护栏。 - Opacus
 - Opacus 是一个库,支持使用差分隐私(Differential Privacy)训练 PyTorch 模型。它支持客户端仅需最小代码更改即可进行训练,对训练性能影响很小,并允许客户端在线跟踪任意时刻消耗的隐私预算。
- Opacus 是一个库,支持使用差分隐私(Differential Privacy)训练 PyTorch 模型。它支持客户端仅需最小代码更改即可进行训练,对训练性能影响很小,并允许客户端在线跟踪任意时刻消耗的隐私预算。 - OpenFL
 - OpenFL 是一个用于联邦学习的 Python 框架。OpenFL 旨在成为数据科学家灵活、可扩展且易于学习的工具。OpenFL 由英特尔物联网组(IOTG)和英特尔实验室开发。
- OpenFL 是一个用于联邦学习的 Python 框架。OpenFL 旨在成为数据科学家灵活、可扩展且易于学习的工具。OpenFL 由英特尔物联网组(IOTG)和英特尔实验室开发。 - PySyft
 - 一个用于安全、私密深度学习(Deep Learning)的 Python 库。PySyft 在 PyTorch 内使用多方计算(Multi-Party Computation, MPC),将私有数据与模型训练解耦。
- 一个用于安全、私密深度学习(Deep Learning)的 Python 库。PySyft 在 PyTorch 内使用多方计算(Multi-Party Computation, MPC),将私有数据与模型训练解耦。 - Tensorflow Privacy
 - 一个 Python 库,包含用于使用差分隐私训练机器学习模型的 TensorFlow 优化器实现。
- 一个 Python 库,包含用于使用差分隐私训练机器学习模型的 TensorFlow 优化器实现。 - TF Encrypted
 - 一个在 TensorFlow 中对加密数据进行机密机器学习的框架。
- 一个在 TensorFlow 中对加密数据进行机密机器学习的框架。
其他精选列表
- Awesome AI Regulation - 涵盖治理、合规性及监管框架,这些对于不同司法管辖区负责任地部署机器学习系统至关重要。
- Awesome Production GenAI - 专注于生成式 AI(Generative AI)的部署,包括大型语言模型运营、提示工程(prompt engineering)和针对生成式 AI 的监控及安全工具。
- Awesome RAG Production - 精心策划的生产级工具和最佳实践列表,用于构建可扩展的检索增强生成(RAG)系统。
版本历史
release-2026-03-012026/03/01release-2026-02-012026/02/01release-2026-01-012026/01/01release-2025-12-012025/12/01release-2025-11-012025/11/01release-2025-10-012025/10/01release-2025-09-012025/09/01release-2025-08-012025/08/01release-2025-07-012025/07/01release-2025-06-012025/06/01release-2025-05-012025/05/01release-2025-04-012025/04/01release-2025-03-012025/03/01release-2025-01-012025/01/01release-2024-12-012024/12/01release-2024-11-012024/11/01release-2024-10-012024/10/01release-2024-09-012024/09/01release-2024-08-012024/08/01release-2024-07-012024/07/01常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。