mistral.rs
mistral.rs 是一款基于 Rust 构建的高性能大语言模型推理引擎,旨在为用户提供快速、灵活且零配置的本地 AI 体验。它解决了传统推理工具配置繁琐、多模态支持分散以及硬件适配复杂等痛点,让用户只需一条命令即可运行来自 Hugging Face 的各类模型。
无论是希望快速部署本地聊天机器人的开发者、需要高效测试不同量化策略的研究人员,还是想要在不编写代码的情况下体验最新多模态模型的普通用户,mistral.rs 都能满足需求。其核心亮点包括真正的“全模态”支持,能够在一个引擎中处理文本、图像、视频和音频输入;内置智能硬件调优功能,可自动基准测试并选择最适合当前设备的量化方案;同时提供原生 Web 界面和 Python/Rust SDK,方便集成与二次开发。此外,它还支持连续的批处理技术和多种量化格式,确保在消费级显卡上也能获得流畅的推理速度。通过简单的命令行操作,用户即可轻松开启从交互式对话到复杂代理任务的各种应用场景。
使用场景
一家初创公司的算法工程师需要在本地消费级显卡上快速部署支持图文多模态输入的 Qwen3.5 模型,以构建内部文档智能审核原型。
没有 mistral.rs 时
- 环境配置繁琐:需手动匹配 PyTorch、CUDA 版本与模型架构,常因依赖冲突耗费数天调试。
- 多模态支持割裂:处理图像需额外集成视觉编码器,文本与图片输入无法在单一引擎中无缝切换。
- 显存优化困难:缺乏灵活的量化控制,大模型在单卡上极易显存溢出(OOM),被迫降级使用小参数模型。
- 部署流程冗长:从模型加载到提供 Web 服务需编写大量胶水代码,无法即时向产品经理演示效果。
使用 mistral.rs 后
- 零配置启动:仅需一条
mistralrs run -m Qwen/Qwen3.5命令,自动识别架构与聊天模板,即刻开始交互。 - 原生多模态融合:直接通过 CLI 传入
--image参数即可实现图文混合推理,无需额外开发集成逻辑。 - 硬件感知调优:运行
mistralrs tune自动测试并生成最优量化配置(如 MXFP4),在有限显存下跑通更大模型。 - 内置服务界面:执行
mistralrs serve --ui瞬间拉起 Web 聊天界面,团队可立即进行功能验证与演示。
mistral.rs 通过极致的工程化封装,将原本复杂的本地大模型部署转化为“一键式”体验,让开发者能专注于业务逻辑而非基础设施调试。
运行环境要求
- Linux
- macOS
- Windows
- 非绝对必需(支持 CPU),但推荐 NVIDIA GPU (CUDA 支持 FlashAttention V2/V3, PagedAttention) 或 Apple Silicon (Metal)
- 支持多 GPU 张量并行
- 具体显存需求取决于模型大小及量化设置(工具提供自动调优功能 `mistralrs tune` 以匹配硬件)
未说明(取决于模型大小,支持 CPU 卸载)
快速开始

快速、灵活的大型语言模型推理。
| 文档 | Rust SDK | Python SDK | Discord |

最新动态
- Gemma 4: 全模态支持:文本、图像、视频和音频输入。指南 | 视频设置
- MXFP4 ISQ 量化: 使用优化解码内核的 MXFP4,使模型更快、更小。量化文档
- 通义千问 3.5 系列模型: 支持包括视觉在内的通义千问 3.5 系列模型。指南
为什么选择 mistral.rs?
- 无需配置即可运行任何 Hugging Face 模型: 只需
mistralrs run -m user/model。 - 真正的多模态支持: 文本、视觉、视频和音频、语音生成、图像生成以及嵌入功能集成在一个引擎中。
- 完全可控的量化: 选择您想要使用的精确量化方式,或者使用
mistralrs quantize自定义 UQFF。 - 内置 Web UI: 运行
mistralrs serve --ui即可立即获得 Web 界面。 - 硬件感知:
mistralrs tune会基准测试您的系统,并选择最佳的量化方案和设备映射。 - 灵活的 SDK: 提供 Python 包和 Rust crate,方便您构建自己的项目。
- 智能体特性 — 内置工具调用、网页搜索和 MCP 客户端。
快速入门
安装
Linux/macOS:
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.sh | sh
Windows (PowerShell):
irm https://raw.githubusercontent.com/EricLBuehler/mistral.rs/master/install.ps1 | iex
运行您的第一个模型
# 交互式聊天
mistralrs run -m Qwen/Qwen3-4B
# 一次性提示(无交互式会话)
mistralrs run -m Qwen/Qwen3-4B -i "法国的首都是哪里?"
# 带图片的一次性请求
mistralrs run -m google/gemma-4-E4B-it --image photo.jpg -i "请描述这张图片"
# 或者启动带有 Web UI 的服务器
mistralrs serve --ui -m google/gemma-4-E4B-it
然后访问 http://localhost:1234/ui 即可进入 Web 聊天界面。
mistralrs CLI
CLI 设计为 零配置: 只需指向一个模型即可开始使用。
- 自动检测: 自动检测模型架构、量化格式和聊天模板。
- 一体化: 单个二进制文件即可完成聊天、服务、基准测试和 Web UI 功能(
run、serve、bench)。 - 硬件调优: 运行
mistralrs tune自动基准测试并配置适合您硬件的最佳设置。 - 格式无关: 无缝支持 Hugging Face 模型、GGUF 文件以及 UQFF 量化。
# 自动为您的硬件调优并生成配置文件
mistralrs tune -m Qwen/Qwen3-4B --emit-config config.toml
# 使用生成的配置文件运行
mistralrs from-config -f config.toml
# 诊断系统问题(CUDA、Metal、HuggingFace 连接)
mistralrs doctor
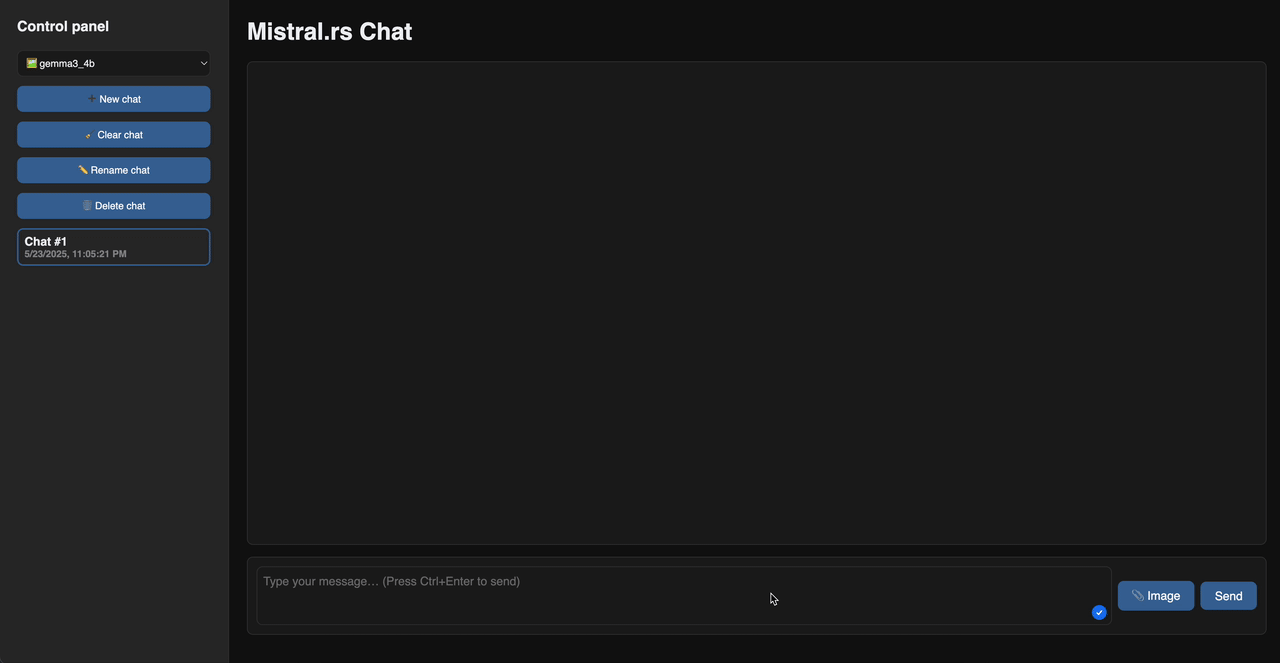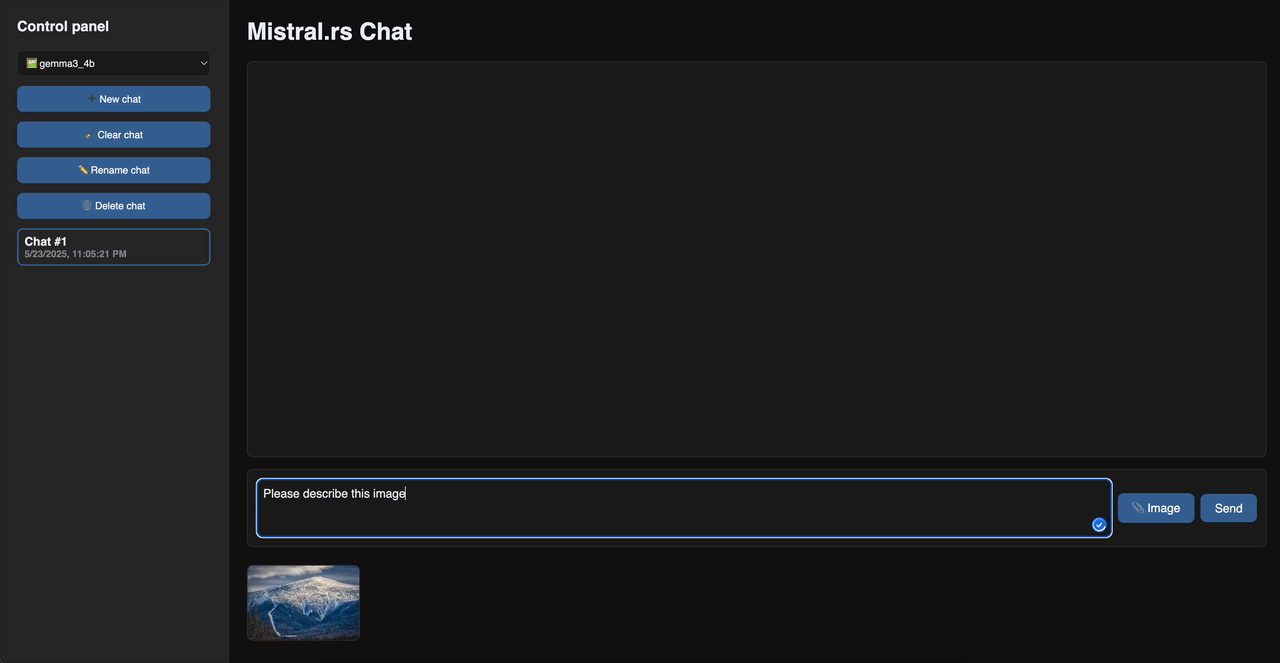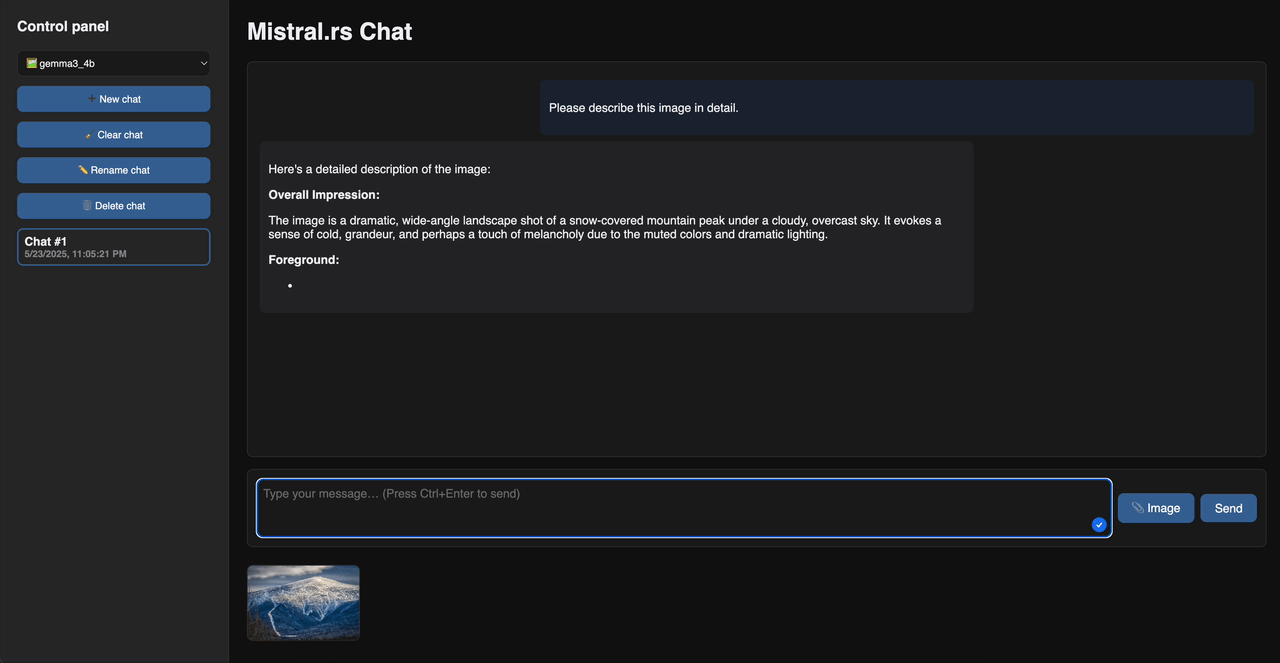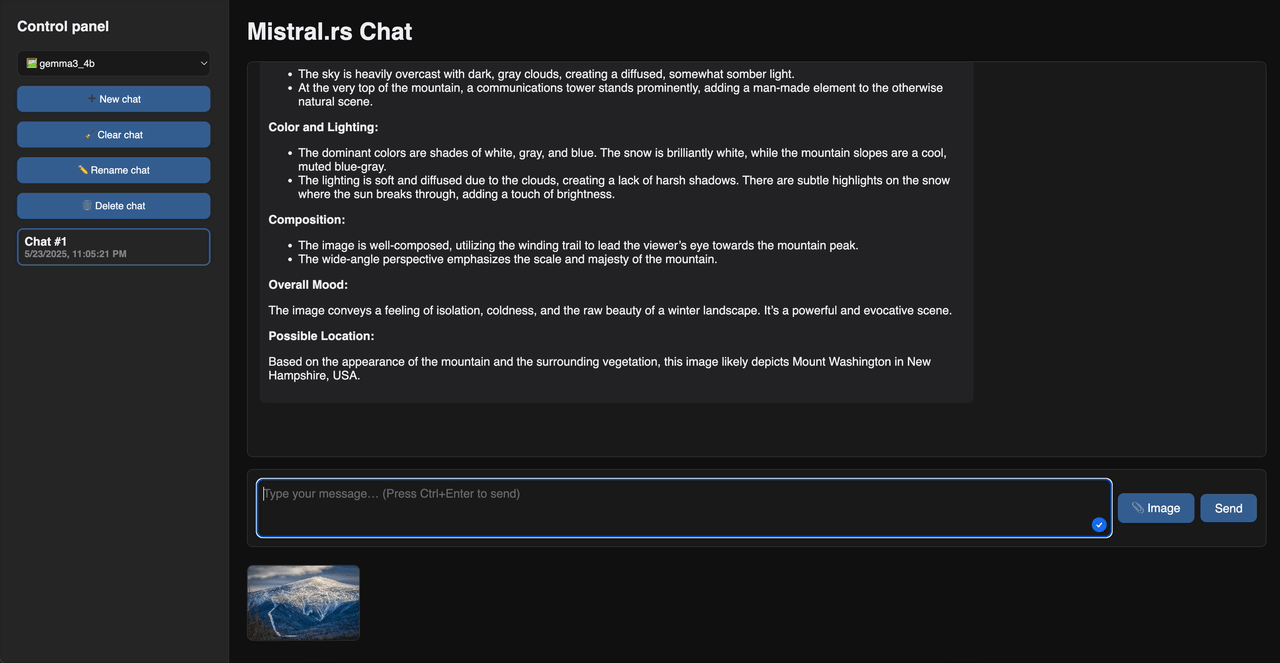
Web 聊天演示
为何如此高效
性能
- 默认在所有设备上支持连续批处理。
- CUDA 配合 FlashAttention V2/V3、Metal 以及 多 GPU 张量并行。
- PagedAttention 用于 CUDA 或 Apple Silicon 上的高吞吐量连续批处理,支持前缀缓存(包括多模态)。
量化(完整文档)
- 对任何 Hugging Face 模型进行 原位量化 (ISQ)。
- 支持 GGUF(2-8 位)、GPTQ、AWQ、HQQ、FP8、BNB。
- ⭐ 逐层拓扑: 可针对每一层微调量化以达到最佳质量与速度。
- ⭐ 自动选择最适合您硬件的量化方法。
灵活性
- LoRA 和 X-LoRA 支持权重合并。
- AnyMoE: 可在任何基础模型上创建专家混合模型。
- 多模型: 支持运行时加载/卸载。
智能体特性
支持的模型
文本模型
- Granite 4.0
- SmolLM 3
- DeepSeek V3
- GPT-OSS
- DeepSeek V2
- 通义千问 3 Next
- 通义千问 3 MoE
- Phi 3.5 MoE
- 通义千问 3
- GLM 4
- GLM-4.7-Flash
- GLM-4.7(MoE)
- Gemma 2
- 通义千问 2
- Starcoder 2
- Phi 3
- Mixtral
- Phi 2
- Gemma
- Llama
- Mistral
多模态模型
- 通义千问 3.5
- 通义千问 3.5 MoE
- 通义千问 3-VL
- 通义千问 3-VL MoE
- Gemma 3n
- Llama 4
- Gemma 3
- Mistral 3
- Phi 4 多模态
- 通义千问 2.5-VL
- MiniCPM-O
- Llama 3.2 Vision
- 通义千问 2-VL
- Idefics 3
- Idefics 2
- LLaVA Next
- LLaVA
- Phi 3V
语音模型
- Voxtral(ASR/语音转文字)
- Dia
图像生成模型
- FLUX
嵌入模型
- Embedding Gemma
- 通义千问 3 嵌入
Python SDK
pip install mistralrs # 或 mistralrs-cuda、mistralrs-metal、mistralrs-mkl、mistralrs-accelerate
from mistralrs import Runner, Which, ChatCompletionRequest
runner = Runner(
which=Which.Plain(model_id="Qwen/Qwen3-4B"),
in_situ_quant="4",
)
res = runner.send_chat_completion_request(
ChatCompletionRequest(
model="default",
messages=[{"role": "user", "content": "你好!"}],
max_tokens=256,
)
)
print(res.choices[0].message.content)
Python SDK | 安装指南 | 示例 | 烹饪书
Rust SDK
cargo add mistralrs
use anyhow::Result;
use mistralrs::{IsqType, TextMessageRole, TextMessages, MultimodalModelBuilder};
#[tokio::main]
async fn main() -> Result<()> {
let model = MultimodalModelBuilder::new("google/gemma-4-E4B-it")
.with_isq(IsqType::Q4K)
.with_logging()
.build()
.await?;
let messages = TextMessages::new().add_message(
TextMessageRole::User,
"Hello!",
);
let response = model.send_chat_request(messages).await?;
println!("{:?}", response.choices[0].message.content);
Ok(())
}
Docker
用于快速容器化部署:
docker pull ghcr.io/ericlbuehler/mistral.rs:latest
docker run --gpus all -p 1234:1234 ghcr.io/ericlbuehler/mistral.rs:latest \
serve -m Qwen/Qwen3-4B
对于生产环境,我们建议直接安装 CLI,以获得最大的灵活性。
文档
有关完整文档,请参阅 文档。
快速链接:
- CLI 参考 - 所有命令和选项
- HTTP API - 兼容 OpenAI 的端点
- 量化 - ISQ、GGUF、GPTQ 等
- 设备映射 - 多 GPU 和 CPU 卸载
- MCP 集成 - MCP 集成文档
- 故障排除 - 常见问题及解决方案
- 配置 - 用于配置的环境变量
贡献
欢迎贡献!请 提交议题 讨论新功能或报告 bug。如果您想添加新模型,请通过议题与我们联系,我们将进行协调。
致谢
没有 Candle 的出色工作,本项目将无法实现。感谢所有 贡献者!
mistral.rs 与 Mistral AI 无关联。
版本历史
v0.8.02026/04/02v0.7.02026/01/28v0.6.02025/06/10v0.5.02025/03/24v0.4.02025/01/22v0.3.42024/11/28v0.3.22024/10/28v0.3.12024/09/29v0.3.02024/09/02v0.2.52024/08/16v0.2.42024/08/01v0.2.32024/07/28v0.2.22024/07/24v0.2.12024/07/23v0.2.02024/07/19v0.1.262024/07/05v0.1.252024/07/03v0.1.242024/06/30v0.1.232024/06/29v0.1.222024/06/24常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。