gpt-neox
GPT-NeoX 是 EleutherAI 推出的开源库,专为在 GPU 集群上从头训练超大规模语言模型而设计。它基于 NVIDIA 的 Megatron 框架,并深度融合了 DeepSpeed 技术,旨在解决数十亿参数级模型在分布式训练中面临的显存受限、效率低下及硬件适配复杂等核心难题。
这款工具特别适合需要研发巨型基础模型的研究机构、高校实验室及企业算法团队。如果您仅需使用现成模型进行推理或微调小型模型,Hugging Face transformers 可能是更轻便的选择;但若您致力于探索模型训练的边界,GPT-NeoX 则是理想伙伴。
其独特亮点在于卓越的硬件兼容性与前沿架构支持。它不仅能在 AWS、CoreWeave 等云平台运行,还能完美适配 Summit、Frontier、LUMI 等顶级超级计算机,支持 Slurm、MPI 等多种调度系统。技术上,它集成了 ZeRO 优化、3D 并行策略、旋转位置编码(RoPE)、Flash Attention 以及最新的 Transformer Engine 加速,并提供 Pythia、LLaMA、Falcon 等主流架构的配置模板。此外,它还原生支持 DPO 偏好学习与 RWKV 架构,并能无缝对接 Hugging Face 生态及 WandB 等监控工具,帮助开发者高效推进大模型研究。
使用场景
某国家级实验室的研究团队正试图在 Frontier 超级计算机上从头训练一个拥有数百亿参数的开源大语言模型,以探索特定科学领域的知识边界。
没有 gpt-neox 时
- 硬件适配困难:团队需耗费数周手动修改代码以适配 Slurm 调度器和 MPI 环境,难以直接利用 Frontier 等顶级超算资源。
- 显存瓶颈限制:缺乏高效的 ZeRO 优化和 3D 并行策略,导致单卡显存无法容纳巨大模型,被迫缩小模型规模或降低批次大小。
- 训练稳定性差:缺少内置的 Curriculum Learning(课程学习)和新型位置编码(如 Rotary/Alibi),模型在长序列训练中容易发散或收敛缓慢。
- 生态割裂严重:实验监控、分词器处理与评估流程分散在不同工具链中,数据对接繁琐,难以复现和追踪实验结果。
使用 gpt-neox 后
- 无缝超算集成:gpt-neox 原生支持 Slurm、MPI 及 IBM Job Step Manager,团队可直接在 Frontier 和 Summit 上启动大规模分布式训练。
- 突破显存限制:借助 DeepSpeed 的 ZeRO 技术和 3D 并行架构,成功在有限显存下运行百亿参数模型,显著提升了训练效率。
- 加速收敛与创新:直接调用预置的 Pythia 或 LLaMA 架构配置,结合 Flash Attention 和课程学习策略,大幅缩短了模型达到最优性能的时间。
- 全流程生态打通:一键对接 Hugging Face 分词器与 Transformers 库,并通过 WandB 或 Comet ML 实时监控实验,实现了从训练到评估的闭环管理。
gpt-neox 将原本需要数月攻坚的基础设施难题转化为可配置的选项,让研究人员能专注于算法创新而非工程修补。
运行环境要求
- Linux
- 必需
- 主要支持 NVIDIA GPU (如 A100, H100, Ampere/Hopper 架构)
- 已支持 AMD GPU (MI100, MI250X)
- 需通过 JIT 编译融合内核
- 未明确具体显存大小,但工具专为十亿级参数模型训练设计,通常需要高显存多卡环境
未说明

快速开始

![]()
GPT-NeoX
本仓库记录了 EleutherAI(https://www.eleuther.ai)用于在 GPU 上训练大规模语言模型的库。我们当前的框架基于 NVIDIA 的 Megatron 语言模型(https://github.com/NVIDIA/Megatron-LM),并结合了 DeepSpeed(https://www.deepspeed.ai)的技术以及一些新颖的优化方法。我们的目标是将此仓库打造成为一个集中且易于访问的平台,汇集训练大规模自回归语言模型的技术,并加速大规模训练领域的研究。该库已被广泛应用于学术界、工业界和政府实验室中(https://github.com/EleutherAI/gpt-neox#adoption-and-publications),包括橡树岭国家实验室、CarperAI、Stability AI、Together.ai、韩国大学、卡内基梅隆大学、东京大学等机构的研究人员。与其他类似库相比,GPT-NeoX 的独特之处在于其对多种系统和硬件的支持,例如可通过 Slurm、MPI 和 IBM Job Step Manager 启动,并且已经在 AWS(https://aws.amazon.com/)、CoreWeave(https://www.coreweave.com/)、橡树岭国家实验室的 Summit 超级计算机(https://www.olcf.ornl.gov/summit/)、Frontier 超级计算机(https://www.olcf.ornl.gov/frontier/)、LUMI 超级计算机(https://www.lumi-supercomputer.eu/)等平台上成功运行。
如果您并非打算从头开始训练拥有数十亿参数的模型,那么这可能并不是适合您的库。对于一般的推理需求,我们建议您使用 Hugging Face 的 transformers 库,它同样支持 GPT-NeoX 模型。
为什么选择 GPT-NeoX?
GPT-NeoX 借鉴了广受欢迎的 Megatron-DeepSpeed 库中的许多功能和技术,但在易用性和创新性优化方面有了显著提升。主要特性包括:
- 使用 ZeRO 和 3D 并行化进行分布式训练
- 支持多种系统和硬件,包括通过 Slurm、MPI 和 IBM Job Step Manager 启动;已在 AWS(https://aws.amazon.com/)、CoreWeave(https://www.coreweave.com/)、橡树岭国家实验室的 Summit(https://www.olcf.ornl.gov/summit/)和 Frontier(https://www.olcf.ornl.gov/frontier/)超级计算机、太平洋西北国家实验室(https://hpc.pnl.gov/index.shtml)、阿贡国家实验室的 Polaris 超级计算机(https://docs.alcf.anl.gov/polaris/data-science-workflows/applications/gpt-neox/)、LUMI 超级计算机(https://www.lumi-supercomputer.eu/)等多个平台大规模运行。
- 包含旋转位置嵌入、Alibi 位置嵌入、并行前馈注意力层以及 Flash Attention 等前沿架构创新。
- 预定义了 Pythia、PaLM、Falcon 以及 LLaMA 1 和 2 等流行架构的配置。
- 课程式学习(Curriculum Learning)。
- 与开源生态系统的无缝对接,包括 Hugging Face 的
tokenizers(https://github.com/huggingface/tokenizers)和transformers(https://github.com/huggingface/transformers)库;可通过 WandB(https://wandb.ai/site/)、Comet(https://www.comet.com/site/)、TensorBoard 等工具监控实验;并通过我们的语言模型评估框架(https://github.com/EleutherAI/lm-evaluation-harness)进行模型评估。
最新动态
[2024年10月9日] 现已支持 Transformer Engine(https://github.com/NVIDIA/TransformerEngine)集成。
[2024年9月9日] 现已支持通过 DPO(https://arxiv.org/abs/2305.18290)、KTO(https://arxiv.org/abs/2402.01306)以及奖励建模进行偏好学习。
[2024年9月9日] 现已支持与机器学习监控平台 Comet ML(https://www.comet.com/site/)集成。
[2024年5月21日] 现已支持 RWKV(https://www.rwkv.com/)的流水线并行化!详情请参阅关于 RWKV 的 PR(https://github.com/EleutherAI/gpt-neox/pull/1198)和 RWKV+流水线并行化的 PR(https://github.com/EleutherAI/gpt-neox/pull/1221)。
[2024年3月21日] 现已支持专家混合(MoE)。
[2024年3月17日] 现已支持 AMD MI250X GPU。
[2024年3月15日] 现已支持 Mamba(https://github.com/state-spaces/mamba)的张量并行化!详情请参阅相关 PR(https://github.com/EleutherAI/gpt-neox/pull/1184)。
[2023年8月10日] 现已支持使用 AWS S3 进行检查点保存!可通过 s3_path 配置选项启用(更多详情请参阅 PR:https://github.com/EleutherAI/gpt-neox/pull/1010)。
[2023年9月20日] 自 https://github.com/EleutherAI/gpt-neox/pull/1035 起,我们已弃用 Flash Attention 0.x 和 1.x 版本,并将支持迁移至 Flash Attention 2.x 版本。我们认为此举不会带来问题,但如果您有特定用例需要旧版 Flash Attention 支持,同时又希望使用最新版本的 GPT-NeoX,请提交 issue。
[2023年8月10日] 我们在 math-lm 项目(https://github.com/EleutherAI/math-lm)中提供了 LLaMA 2 和 Flash Attention v2 的实验性支持,相关内容将于本月晚些时候合并到主分支。
[2023年5月17日] 在修复了一些小 bug 后,我们现在完全支持 bf16 数据类型。
[2023年4月11日] 我们的 Flash Attention 实现现已升级,支持 Alibi 位置嵌入。
[2023年3月9日] 我们发布了 GPT-NeoX 2.0.0 版本,这是一个基于最新 DeepSpeed 构建的升级版本,并将保持定期同步更新。
版本说明
在 2023年3月9日之前,GPT-NeoX 依赖于 DeeperSpeed(https://github.com/EleutherAI/DeeperSpeed),而 DeeperSpeed 则基于旧版 DeepSpeed(0.3.15)。为了迁移到最新的 DeepSpeed 主干版本,同时允许用户继续使用旧版 GPT-NeoX 和 DeeperSpeed,我们为这两个库分别推出了两个版本:
- GPT-NeoX 和 DeeperSpeed 的 2.0 版本是基于最新 DeepSpeed 构建的最新版本,未来将继续维护。
- GPT-NeoX 和 DeeperSpeed 的 1.0 版本则保留了旧稳定版本的快照,这些版本曾被用于训练 GPT-NeoX-20B 和 Pythia 套件。
目录
快速入门
环境与依赖
主机设置
本代码库主要针对 Python 3.8–3.10 和 PyTorch 1.8–2.0 进行开发和测试。但这并非严格要求,其他版本及库的组合也可能适用。
要安装其余基本依赖,请在仓库根目录下运行:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # 可选,若使用 WandB 日志记录
pip install -r requirements/requirements-tensorboard.txt # 可选,若使用 TensorBoard 日志记录
pip install -r requirements/requirements-comet.txt # 可选,若使用 Comet 日志记录
[!警告] 我们的代码库依赖于 DeeperSpeed,这是我们基于 DeepSpeed 库并进行了一些修改后的分支。强烈建议在继续之前使用 Anaconda、虚拟机或其他形式的环境隔离。否则,可能会影响依赖 DeepSpeed 的其他项目正常运行。
融合内核
我们现在通过 JIT 融合内核编译支持 AMD GPU(MI100、MI250X)。融合内核会根据需要构建并加载。为避免作业启动时的等待,您也可以手动预先构建:
python
from megatron.fused_kernels import load
load()
这将自动适应不同 GPU 厂商(AMD、NVIDIA)的构建过程,而无需针对特定平台进行代码修改。要进一步使用 pytest 测试融合内核,请运行 pytest tests/model/test_fused_kernels.py。
Flash Attention
要使用 Flash-Attention,请安装 ./requirements/requirements-flashattention.txt 中的额外依赖,或直接使用已预装该功能的 PyTorch NGC 容器(请注意,使用与我们要求文件不同的版本可能无法保证功能正常)。然后在您的配置中相应地设置注意力类型(参见 configs)。在某些 GPU 架构上,例如 Ampere 架构的 A100 等,Flash Attention 可以显著提升常规注意力机制的速度;更多详情请参阅仓库文档。
Transformer Engine
要使用 Transformer Engine (TE),请安装 ./requirements/requirements-transformer-engine.txt 中的额外依赖,或使用已预装该功能的 PyTorch NGC 容器(请注意,使用与我们要求文件不同的版本可能无法保证功能正常)。可参考 此配置 了解如何在 13 亿参数模型上使用 TE。在某些 GPU 架构上,包括 Ampere 和 Hopper 架构,TE 可以显著提升常规注意力机制的速度;更多信息请参阅仓库文档。
TE 为 A100 和 H100 GPU 提供了非常高效的内核。我们已在 A100 上进行了若干示例消融实验:
以及 H100:
多节点启动
NeoX 和 Deep(er)Speed 支持在多个不同节点上进行训练,并且您可以选择多种不同的启动器来编排多节点任务。
通常情况下,需要在一个可访问的位置提供一个“hostfile”,其格式如下:
node1_ip slots=8
node2_ip slots=8
其中第一列是您设置中每个节点的 IP 地址,而槽位数表示该节点可访问的 GPU 数量。在您的配置中,必须通过 "hostfile": "/path/to/hostfile" 传递 hostfile 的路径。此外,也可以将 hostfile 的路径设置在环境变量 DLTS_HOSTFILE 中。
pdsh
pdsh 是默认的启动器。如果您使用 pdsh,除了确保您的环境中已安装 pdsh 外,只需在配置文件中设置 {"launcher": "pdsh"} 即可。
MPI
如果使用 MPI,则必须指定 MPI 库(目前 DeepSpeed/GPT-NeoX 支持 mvapich、openmpi、mpich 和 impi,但 openmpi 是最常用且经过充分测试的),并在配置文件中添加 deepspeed_mpi 标志:
{
"launcher": "openmpi",
"deepspeed_mpi": true
}
在正确设置好环境并准备好相应的配置文件后,您可以像普通 Python 脚本一样使用 deepy.py 来启动训练任务,例如:
python3 deepy.py train.py /path/to/configs/my_model.yml
Slurm
使用 Slurm 可能会稍微复杂一些。与 MPI 类似,您也需要在配置中添加以下内容:
{
"launcher": "slurm",
"deepspeed_slurm": true
}
如果您没有 SSH 访问权限来连接到 Slurm 集群中的计算节点,则需要添加 {"no_ssh_check": true}。
(高级)自定义启动
在许多情况下,上述默认的启动选项并不足以满足需求:
- 许多集群有自己的独特作业调度器,或者有特定的 MPI/Slurm 参数用于启动作业,例如 Summit JSRun 或 LLNL Flux。
- 虽然上述 Slurm/MPI/pdsh 默认选项对于大多数作业运行已经足够,但高级用户可能希望添加参数以进行优化或调试。
在这种情况下,您需要修改 DeepSpeed 的 multinode runner 工具,以支持您的用例。这些增强大致可以分为两类:
1. 添加新的启动器(例如 JSRun、Flux 等)
在这种情况下,您需要在 deepspeed/launcher/multinode_runner.py 中添加一个新的多节点运行器类,并将其作为 GPT-NeoX 中的一个配置选项公开。我们为 Summit JSRun 实现的例子分别见 DeeperSpeed 的这个提交 和 GPT-NeoX 的这个提交。
2. 修改运行命令或环境变量
我们遇到过许多需要修改 MPI/Slurm 运行命令的情况,可能是为了优化或调试(例如修改 Slurm srun CPU 绑定 或为 MPI 日志添加进程 rank 标签)。在这种情况下,您需要修改多节点运行器类的 get_cmd 方法中的运行命令(例如 OpenMPI 的 mpirun_cmd)。我们使用 Slurm 和 OpenMPI 为 Stability 集群提供优化且带有 rank 标签的运行命令的例子,见 DeeperSpeed 的这个分支。
Hostfile 生成
一般来说,您无法使用一个固定的 hostfile,因此需要编写一个脚本来在作业启动时动态生成 hostfile。以下是一个使用 Slurm 并假设每个节点有 8 个 GPU 的动态生成 hostfile 的示例脚本:
#!/bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# 将当前的 Slurm 作业 ID 添加到 hostfile 名称中,以避免追加到之前的 hostfile
hostfile=/sample/path/to/hostfiles/hosts_$SLURM_JOBID
# 确保不会追加到之前的 hostfile
rm $hostfile &> /dev/null
# 遍历节点名称
for i in `scontrol show hostnames $SLURM_NODELIST`
do
# 向 hostfile 中添加一行
echo $i slots=$GPUS_PER_NODE >>$hostfile
done
$SLURM_JOBID 和 $SLURM_NODELIST 是 Slurm 自动为您创建的环境变量。有关作业创建时可用的完整 Slurm 环境变量列表,请参阅 sbatch 文档。
作业启动
然后,您可以创建一个 sbatch 脚本来启动您的 GPT-NeoX 作业。在一个基于 Slurm 的集群上,假设每个节点有 8 个 GPU,一个最基本的 sbatch 脚本可能如下所示:
#!/bin/bash
#SBATCH --job-name="neox"
#SBATCH --partition=your-partition
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:8
# 一些可能有用的分布式环境变量
export HOSTNAMES=`scontrol show hostnames "$SLURM_JOB_NODELIST"`
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_PORT=12802
export COUNT_NODE=`scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l`
# 上面提到的 hostfile 生成脚本
./write_hostfile.sh
# 通过 DLTS_HOSTFILE 告诉 DeepSpeed 我们生成的 hostfile 的位置
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_$SLURM_JOBID
# 启动训练
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
之后,您可以通过执行 sbatch my_sbatch_script.sh 来启动训练任务。
容器化部署
我们在 containers 目录下提供了适用于 Apptainer(原名 Singularity)和 Docker 的容器镜像。
Docker
如果您希望通过 Docker 容器运行 NeoX,我们提供了一个 Dockerfile 和 docker-compose 配置文件。
运行该容器的必要条件包括:安装合适的 GPU 驱动程序、最新版本的 Docker 以及 nvidia-container-toolkit。要测试您的环境是否配置正确,可以使用 NVIDIA 提供的“示例工作负载”:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
如果上述命令能够成功执行,则需要在您的环境中设置 NEOX_DATA_PATH 和 NEOX_CHECKPOINT_PATH 环境变量,以指定数据目录和检查点存储路径:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 # 或您系统中存放数据的实际路径
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
然后,在 gpt-neox/containers/docker 目录下,您可以构建镜像并在容器中启动一个 shell:
docker compose run gpt-neox bash
构建完成后,您应该能够看到类似以下的输出:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
对于长时间运行的任务,您应使用以下命令以分离模式运行容器:
docker compose up -d
随后,在另一个终端会话中,您可以执行以下命令进入正在运行的容器:
docker compose exec gpt-neox bash
之后,您就可以在容器内运行所需的任何任务。
长时间运行或以分离模式运行时需要注意以下几点:
- 当您不再使用容器时,必须手动停止它。
- 如果希望在您的 shell 会话结束后继续运行某些进程,您需要将它们置于后台运行。
- 如果需要日志记录功能,则需确保将日志输出重定向到磁盘,并配置 WandB 和/或 Comet 日志记录。
如果您更倾向于直接使用 Docker Hub 上的预构建镜像,可以在运行 docker-compose 命令时添加 -f docker-compose-dockerhub.yml 参数,例如:
docker compose run -f containers/docker/docker-compose-dockerhub.yml gpt-neox bash
Singularity/Apptainer
我们同样支持 Apptainer(原名 Singularity)部署。部分用户发现 Apptainer 在无法获得 root 权限的系统上非常有用,例如国家实验室和大学中的共享高性能计算集群。
运行该容器的必要条件包括安装合适的 GPU 驱动程序以及最新版本的 Apptainer。您可以通过运行以下命令从我们的 Apptainer 文件构建镜像:
cd containers/apptainer/
apptainer build gpt-neox.sif gpt-neox.def
构建完成后,您可以通过以下几种方式使用新镜像:
- 在容器内启动一个 shell:
apptainer shell --nv --bind /path/to/data:/data,/path/to/code:/code gpt-neox.sif
使用 --nv 标志启用 NVIDIA GPU 支持。
2. 直接执行一条命令:
apptainer exec --nv gpt-neox.sif python your_script.py
对于第二种方法,您需要在构建过程中使依赖文件和 fused_kernels 目录可用,具体可通过以下方式实现:
- 在构建时使用
--bind选项; - 将这些文件添加到定义文件的
%files部分; - 在构建过程中将其复制到特定位置。
默认情况下,Apptainer/Singularity 容器会使用用户的 UID/GID 运行,因此部分用户创建步骤可能是多余的。此外,默认情况下,用户的主目录会被自动挂载到 Apptainer/Singularity 容器中,这与 Docker 的行为有所不同。有关 Apptainer 部署的更多信息,建议参考其用户指南。
使用方法
所有功能都应通过 deepy.py 启动,它是对 deepspeed 启动脚本的封装。
目前我们提供三个主要功能:
train.py用于训练和微调模型;eval.py用于使用 语言模型评估框架评估已训练好的模型;generate.py用于从已训练好的模型中采样文本。
这些功能可以通过以下命令启动:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]
例如,要启动训练,您可以运行:
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.yml
有关每个入口点的详细信息,请参阅相应的训练与微调、推理和评估部分。
配置
GPT-NeoX 的参数由 YAML 配置文件定义,并传递给 deepy.py 启动脚本。我们在 configs 目录中提供了一些示例 .yml 文件,展示了多种功能和不同规模的模型。
这些配置文件通常是完整的,但可能并非最优。例如,根据您的 GPU 配置,您可能需要调整一些设置,如 pipe-parallel-size 和 model-parallel-size 来增加或减少并行度,或者调整 train_micro_batch_size_per_gpu 和 gradient-accumulation-steps 来修改批次大小相关的参数,又或者调整 zero_optimization 字典来改变优化器状态在各工作节点之间的并行化方式。
有关可用功能及其配置方法的详细指南,请参阅 配置说明文档,而所有可能参数的详细说明则可在 configs/neox_arguments.md 中找到。
混合专家模型
GPT-NeoX 通过 megablocks 库支持无丢弃混合专家模型(DMoE)。它与现有的 Megatron 张量并行和 DeepSpeed 流水线并行设置兼容。
该实现利用现有的张量并行组来同时划分专家权重,并采用 Sinkhorn 路由算法避免负载均衡损失的引入。
有关基本完整配置的示例,请参阅 configs/125M-dmoe.yml 文件。
大多数与 MoE 相关的配置参数都以 moe 为前缀。要启用 MoE,您至少需要在配置文件中添加以下内容:
moe_num_experts: 1 # 1 表示禁用 MoE。8 是常见值。
数据集
预配置数据集
提供了多个预配置的数据集,包括 The Pile 中的大多数组件,以及 The Pile 的训练集本身,以便使用 prepare_data.py 入口点进行直接的分词处理。
例如,要下载并使用 GPT2 分词器对 enwik8 数据集进行分词,然后将其保存到 ./data 目录下,可以运行以下命令:
python prepare_data.py -d ./data
或者对 The Pile 的单个分片 (pile_subset) 使用 GPT-NeoX-20B 分词器(假设你已将其保存在 ./20B_checkpoints/20B_tokenizer.json):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
分词后的数据将被保存为两个文件:[data-dir]/[dataset-name]/[dataset-name]_text_document.bin 和 [data-dir]/[dataset-name]/[dataset-name]_text_document.idx。你需要将这两个文件共有的前缀添加到你的训练配置文件中的 data-path 字段中。例如:
"data-path": "./data/enwik8/enwik8_text_document",
使用自定义数据
要准备自己的数据集以用于自定义数据的训练,需将其格式化为一个大型的 jsonl 格式文件,其中列表中的每个字典项代表一个单独的文档。文档文本应归于一个 JSON 键下,即 "text"。存储在其他字段中的任何辅助数据将不会被使用。
接下来,请确保下载 GPT2 分词器的词汇表,并从以下链接合并文件:
- 词汇表:https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json
- 合并文件:https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt
或者使用 20B 分词器(仅需一个词汇表文件):
(此外,你也可以提供任何能够通过 Hugging Face 的分词器库使用 Tokenizer.from_pretrained() 命令加载的分词器文件)
现在你可以使用 tools/datasets/preprocess_data.py 对数据进行预分词,其参数说明如下:
用法:preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
可选参数:
-h, --help 显示此帮助信息并退出
输入数据:
--input INPUT 输入 jsonl 文件或 lmd 归档文件的路径;如果使用多个归档文件,请用逗号分隔。
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
从 jsonl 中提取的键名列表,以空格分隔。默认值:text
--num-docs NUM_DOCS 可选:输入数据中的文档数量(如果已知),以便显示准确的进度条。
分词器:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
要使用的分词器类型。
--vocab-file VOCAB_FILE
词汇表文件的路径。
--merge-file MERGE_FILE
BPE 合并文件的路径(如果需要)。
--append-eod 在文档末尾添加 <eod> 标记。
--ftfy 使用 ftfy 清理文本。
输出数据:
--output-prefix OUTPUT_PREFIX
二进制输出文件的路径,不带后缀。
--dataset-impl {lazy,cached,mmap}
要使用的数据集实现方式。默认:mmap。
运行时:
--workers WORKERS 启动的工作进程数量。
--log-interval LOG_INTERVAL
进度更新的时间间隔。
例如:
python tools/datasets/preprocess_data.py \
--input ./data/mydataset.jsonl.zst \
--output-prefix ./data/mydataset \
--vocab ./data/gpt2-vocab.json \
--merge-file gpt2-merges.txt \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--append-eod
随后,你可以在配置文件中添加以下设置来启动训练:
"data-path": "data/mydataset_text_document",
训练与微调
训练通过 deepy.py 启动,它是 DeepSpeed 启动器的封装工具,可在多块 GPU 或多个节点上并行启动相同的脚本。
一般的使用模式是:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...
你可以传递任意数量的配置文件,它们将在运行时被合并。
你还可以选择性地传递一个配置文件前缀,这样系统会假定所有配置文件都在同一个文件夹中,并将该前缀附加到它们的路径上。
例如:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml
这将在所有节点上部署 train.py 脚本,每块 GPU 上运行一个进程。工作节点和 GPU 数量在 /job/hostfile 文件中指定(参见 参数文档),或者如果是在单节点设置中运行,可以直接通过 num_gpus 参数指定。
虽然这不是严格必需的,但我们发现将模型参数定义在一个配置文件中(如 configs/125M.yml),而将数据路径参数定义在另一个配置文件中(如 configs/local_setup.yml)会很有帮助。
预训练模型
GPT-NeoX-20B
GPT-NeoX-20B 是一个拥有 200 亿参数的自回归语言模型,基于 The Pile 数据集训练而成。有关 GPT-NeoX-20B 的技术细节,请参阅相关论文。该模型的配置文件既可在 ./configs/20B.yml 中找到,也包含在下方的下载链接中。
【精简权重】(https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/) - (不含优化器状态,适用于推理或微调,39GB)
若要通过命令行将文件下载到名为 20B_checkpoints 的文件夹中,可使用以下命令:
wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpoints
【完整权重】(https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/) - (包含优化器状态,268GB)
若要通过命令行将文件下载到名为 20B_checkpoints 的文件夹中,可使用以下命令:
wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpoints
此外,也可以使用 BitTorrent 客户端下载权重。种子文件可在此处下载:【精简权重】(https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights.torrent),【完整权重】(https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights.torrent)。
我们还在训练过程中保存了 150 个检查点,每 1,000 步保存一个。目前我们正在研究如何以最佳方式大规模提供这些检查点,但在此期间,有兴趣使用部分训练好的检查点的研究人员可以通过 contact@eleuther.ai 与我们联系,以安排访问权限。
Pythia
Pythia 扩展系列是一套从 7000 万参数到 120 亿参数不等的模型,基于 The Pile 训练而成,旨在促进对大型语言模型可解释性和训练动态的研究。有关该项目的更多详细信息及模型链接,请参阅论文和项目 GitHub 页面。
Polyglot
Polyglot 项目致力于训练强大的非英语预训练语言模型,以提升机器学习领域之外的研究人员对该技术的可及性。EleutherAI 已经训练并发布了 13 亿、38 亿和 58 亿参数的韩语语言模型,其中最大的模型在韩语任务上表现优于所有其他公开可用的语言模型。有关该项目的更多详细信息及模型链接,请参阅此处。
推理
对于大多数用途,我们建议通过 Hugging Face Transformers 库部署使用 GPT-NeoX 库训练的模型,因为该库针对推理进行了更好的优化。
我们支持三种类型的预训练模型生成:
- 无条件生成
- 基于从文件读取的输入进行的条件生成
- 交互式生成,允许用户通过命令行界面与语言模型进行多轮对话。
这三种文本生成方式均可通过 python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml 启动,并在 configs/text_generation.yml 中设置相应的参数。
评估
GPT-NeoX 支持通过 语言模型评估框架 对下游任务进行评估。
要使用评估框架评估已训练的模型,只需运行:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn
其中 --eval_tasks 是由空格分隔的评估任务列表,例如 --eval_tasks lambada hellaswag piqa sciq。有关所有可用任务的详细信息,请参阅 lm-evaluation-harness 仓库。
导出至 Hugging Face
GPT-NeoX 主要针对训练进行了高度优化,因此 GPT-NeoX 模型检查点无法直接与其他深度学习库兼容。为了使模型易于加载和与最终用户共享,并进一步导出到其他框架,GPT-NeoX 支持将检查点转换为 Hugging Face Transformers 格式。
尽管 NeoX 支持多种不同的架构配置,包括 AliBi 位置嵌入,但并非所有这些配置都能无缝映射到 Hugging Face Transformers 支持的架构中。
NeoX 支持将兼容的模型导出为以下架构:
- GPTNeoXForCausalLM
- LlamaForCausalLM
- MistralForCausalLM
如果训练的模型无法完全适配上述 Hugging Face Transformers 架构之一,则需要为导出的模型编写自定义建模代码。
要将 GPT-NeoX 库中的检查点转换为 Hugging Face 可加载格式,可运行:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}
然后,要将模型上传到 Hugging Face Hub,可运行:
huggingface-cli login
python ./tools/ckpts/upload.py
并输入所需信息,包括 Hugging Face 用户令牌。
将模型导入 GPT-NeoX
NeoX 提供了若干工具,用于将预训练模型检查点转换为可在该库中训练的格式。
以下模型或模型家族可以加载到 GPT-NeoX 中:
- Llama 1
- Llama 2
- CodeLlama
- Mistral-7b-v0.1
我们提供了两种工具,分别用于将两种不同格式的检查点转换为与 GPT-NeoX 兼容的格式。
要将 Meta AI 发布的 Llama 1 或 Llama 2 检查点从其原始文件格式(可从 这里 或 这里 下载)转换为 GPT-NeoX 库格式,可运行:
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
要将 Hugging Face 模型转换为 NeoX 可加载格式,可运行 tools/ckpts/convert_hf_to_sequential.py。更多选项请参阅该文件中的文档说明。
监控
除了在本地存储日志外,我们还内置支持两种流行的实验监控框架:Weights & Biases、TensorBoard 和 Comet。
权重与偏差
Weights & Biases 用于记录我们的实验 是一个机器学习监控平台。要使用 Wandb 监控你的 GPT-NeoX 实验,请按照以下步骤操作:
- 在 https://wandb.ai/site 上创建一个账户以生成你的 API 密钥。
- 在你的机器上登录 Weights & Biases——你可以通过执行
wandb login来完成——你的运行将自动被记录。 - Wandb 监控所需的依赖项可以在
./requirements/requirements-wandb.txt中找到,并从中安装。示例配置文件位于./configs/local_setup_wandb.yml。 - Weights & Biases 有两个可选字段:
<code><var>wandb_group</var></code>允许你为运行分组命名,而<code><var>wandb_team</var></code>允许你将运行分配到某个组织或团队账户。示例配置文件同样位于./configs/local_setup_wandb.yml。
TensorBoard
我们支持通过 <code><var>tensorboard-dir</var></code> 字段使用 TensorBoard。TensorBoard 监控所需的依赖项可以在 ./requirements/requirements-tensorboard.txt 中找到,并从中安装。
Comet
Comet 是一个机器学习监控平台。要使用 Comet 监控你的 GPT-NeoX 实验,请按照以下步骤操作:
- 在 https://www.comet.com/login 上创建一个账户以生成你的 API 密钥。
- 生成后,在运行时通过执行
comet login或者设置环境变量export COMET_API_KEY=<your-key-here>来关联你的 API 密钥。 - 使用
pip install -r requirements/requirements-comet.txt安装comet_ml及其依赖库。 - 启用 Comet:设置
use_comet: True。你还可以通过comet_workspace和comet_project自定义数据的记录位置。启用 Comet 的完整示例配置文件位于configs/local_setup_comet.yml。 - 运行你的实验,并在你指定的 Comet 工作空间中监控指标!
多节点运行
如果你需要为基于 MPI 的 DeepSpeed 启动器提供主机文件,可以设置环境变量 DLTS_HOSTFILE 指向该主机文件。
性能分析
我们支持使用 Nsight Systems、PyTorch Profiler 和 PyTorch 内存分析工具进行性能分析。
Nsight Systems 性能分析
要使用 Nsight Systems 进行性能分析,需设置配置选项 profile、profile_step_start 和 profile_step_stop(有关参数用法请参阅 这里,示例配置请参阅 这里)。
要生成 nsys 指标,可以使用以下命令启动训练:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true \
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py \
$TRAIN_PATH/train.py --conf_dir configs <config files>
生成的输出文件随后可以通过 Nsight Systems GUI 查看:
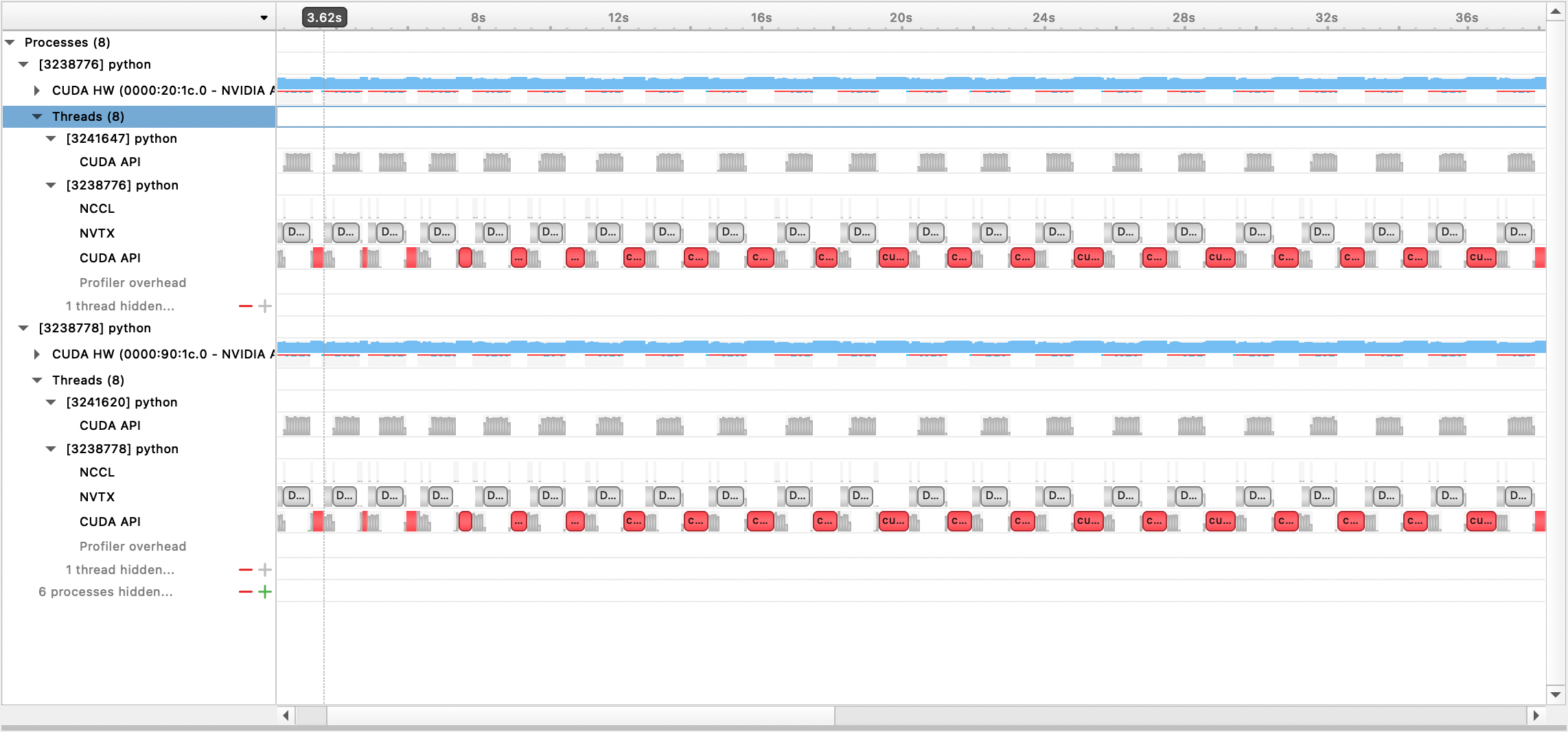
PyTorch 性能分析
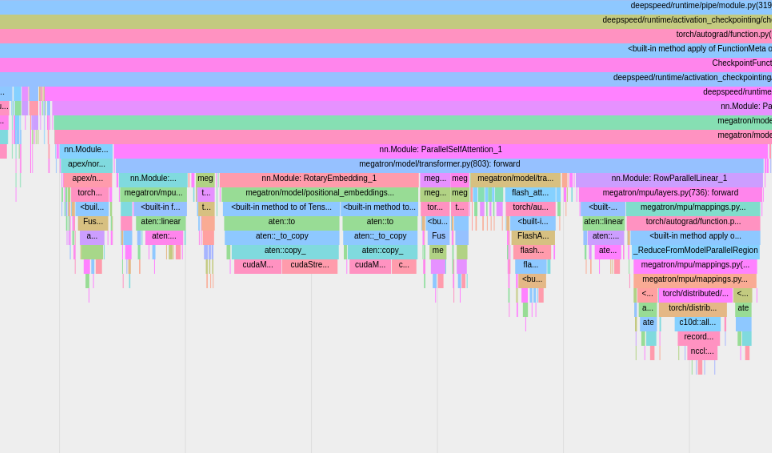
要使用 PyTorch 内置的性能分析工具,需设置配置选项 profile、profile_step_start 和 profile_step_stop(有关参数用法请参阅 这里,示例配置请参阅 这里)。
PyTorch 性能分析工具会将跟踪信息保存到你的 TensorBoard 日志目录中。你可以按照 这里 的步骤,在 TensorBoard 中查看这些跟踪信息。
PyTorch 内存分析
要使用 PyTorch 内存分析工具,需设置配置选项 memory_profiling 和 memory_profiling_path(有关参数用法请参阅 这里,示例配置请参阅 这里)。
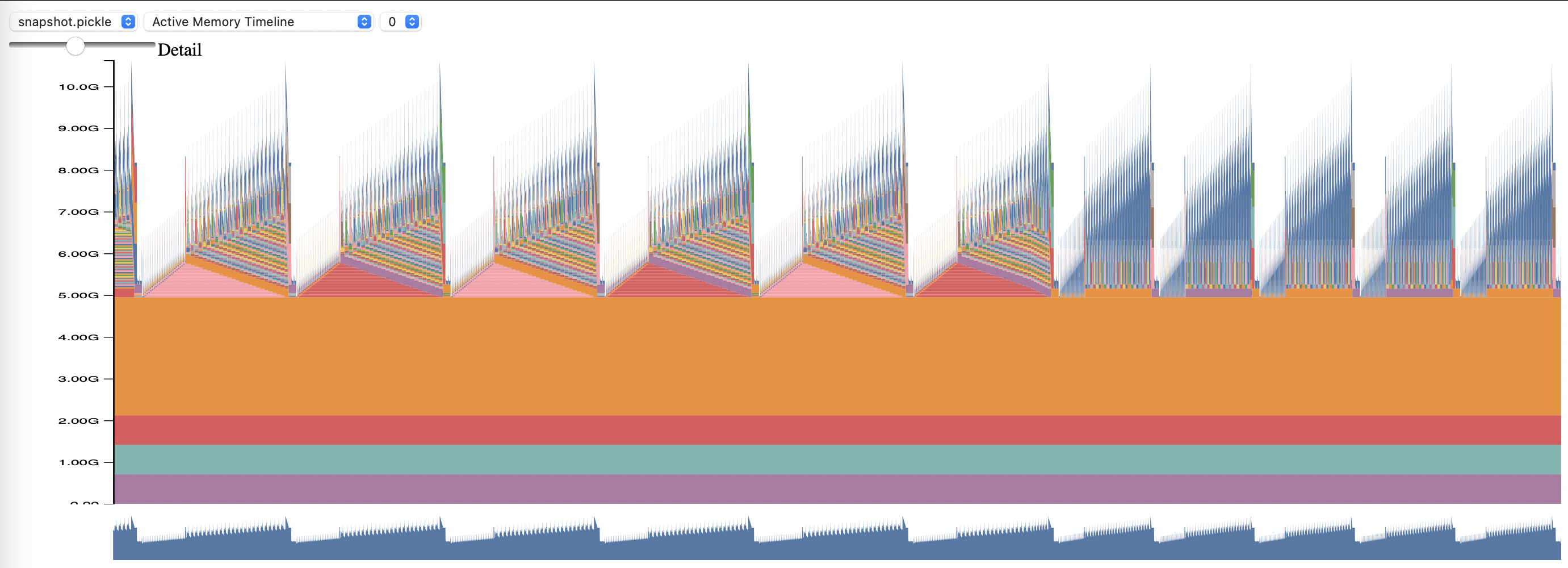
使用 memory_viz.py 脚本查看生成的内存分析报告。运行命令如下:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
采用与发表论文
GPT-NeoX 库已被学术界和工业界的众多研究人员广泛采用,并移植到了许多高性能计算系统上。
如果你在研究中发现这个库很有用,请随时联系我们告知我们!我们非常乐意将你加入我们的名单。
出版物
EleutherAI 及其合作者已在以下出版物中使用了该模型:
- Sid Black、Stella Biderman、Eric Hallahan、Quentin Anthony、Leo Gao、Laurence Golding、Horace He、Connor Leahy、Kyle McDonell、Jason Phang、Michael Pieler、Shivanshu Purohit、Laria Reynolds、Jon Tow、Ben Wang 和 Samuel Weinbach。“GPT-NeoX-20B:一个开源的自回归语言模型”。载于《ACL 大型语言模型构建中的挑战与展望研讨会论文集》,2022 年。
- Stella Biderman、Hailey Schoelkopf、Quentin Anthony、Herbie Bradley、Kyle O'Brien、Eric Hallahan、Mohammad Aflah Khan、Shivanshu Purohit、USVSN Sai Prashanth、Edward Raff、Aviya Skowron、Lintang Sutawika、Oskar van der Wal。“Pythia:一套用于跨训练与规模扩展分析大型语言模型的工具”。载于《国际机器学习大会》,第 2397–2430 页。PMLR,2023 年。
- Zhangir Azerbayev、Bartosz Piotrowski、Hailey Schoelkopf、Edward W. Ayers、Dragomir Radev 和 Jeremy Avigad。“Proofnet:自动形式化并形式化证明本科水平数学”。arXiv 预印本 arXiv:2302.12433,2023 年。
- Stella Biderman、USVSN Sai Prashanth、Lintang Sutawika、Hailey Schoelkopf、Quentin Anthony、Shivanshu Purohit 和 Edward Raff。“大型语言模型中的涌现式与可预测性记忆”。载于《神经信息处理系统》,2023 年。
- Hyunwoong Ko、Kichang Yang、Minho Ryu、Taekyoon Choi、Seungmu Yang 和 Sungho Park。“Polyglot-Ko 技术报告:开源大规模韩语语言模型”。arXiv 预印本 arXiv:2306.02254,2023 年。
- Kshitij Gupta、Benjamin Thérien、Adam Ibrahim、Mats Leon Richter、Quentin Anthony、Eugene Belilovsky、Irina Rish 和 Timothée Lesort。“大型语言模型的持续预训练:如何重新‘唤醒’你的模型?”载于《ICML 基础模型高效系统研讨会》,2023 年。
- Zhangir Azerbayev、Hailey Schoelkopf、Keiran Paster、Marco Dos Santos、Stephen McAleer、Albert Q Jiang、Jia Deng、Stella Biderman 和 Sean Welleck。“Llemma:一个面向数学的开源语言模型”。载于《NeurIPS 数学—人工智能研讨会》,2023 年。
- Alexander Havrilla、Maksym Zhuravinskyi、Duy Phung、Aman Tiwari、Jonathan Tow、Stella Biderman、Quentin Anthony 和 Louis Castricato。“trlX:一个用于大规模人类反馈强化学习的框架”。载于《2023 年自然语言处理经验方法会议论文集》,2023 年。
- Quentin Anthony、Jacob Hatef、Deepak Narayanan、Stella Biderman、Stas Bekman、Junqi Yin、Aamir Shafi、Hari Subramoni 和 Dhabaleswar Panda。“与硬件协同设计模型架构的理由”。载于 arXiv 预印本,2024 年。
- Adam Ibrahim、Benjamin Thérien、Kshitij Gupta、Mats L. Richter、Quentin Anthony、Timothée Lesort、Eugene Belilovsky 和 Irina Rish。“简单且可扩展的策略以持续预训练大型语言模型”。载于 arXiv 预印本,2024 年。
- Junqi Yin、Avishek Bose、Guojing Cong、Isaac Lyngaas、Quentin Anthony。“前沿领域大型语言模型架构的比较研究”。载于 arXiv 预印本,2024 年。
其他研究团队的以下出版物使用了该库:
- 蔡忠志、范廷翰、彼得·拉马奇和亚历山大·鲁德尼茨基。"KERPLE:用于长度外推的核化相对位置嵌入。" 载于《神经信息处理系统进展》第35卷,2022年。
- 萨米拉·霍拉瓦拉维塔纳、埃琳·艾顿、希瓦姆·夏尔马、斯科特·豪兰德、梅加·苏布拉马尼安、斯科特·巴斯克斯、罗宾·科斯比、玛丽亚·格伦斯基和斯维特兰娜·沃尔科娃。"化学领域的科学知识基础模型:机遇、挑战与经验教训。" 载于《ACL大型语言模型创建中的挑战与展望研讨会论文集》,2022年。
- 索菲娅·科拉克、鲁本·马丁斯、克莱尔·勒古埃斯和文森特·J·赫伦多恩。"利用语言模型生成代码片段:可行性与规模效应"。 载于《ICLR深度学习与代码研讨会论文集》,2022年。
- 弗兰克·F·徐、乌里·阿隆、格雷厄姆·纽比格和文森特·J·赫伦多恩。"大型代码语言模型的系统性评估。" 载于《ICLR深度学习与代码研讨会论文集》,2022年。
- 普永道和威廉·舒勒。"基于Transformer的语言模型惊喜度在约20亿训练token时对人类阅读时间的预测效果最佳。" 载于《计算语言学协会研究成果》,2023年。
- 蔡忠志、范廷翰、亚历山大·鲁德尼茨基和彼得·拉马奇。"通过感受野分析视角剖析Transformer的长度外推能力。" 载于《第61届计算语言学协会年会论文集(第一卷:长文)》,第13522–13537页,2023年。
- 蔡忠志、范廷翰、陈立伟、亚历山大·鲁德尼茨基和彼得·拉马奇。"无位置嵌入的Transformer语言模型中,潜在的位置信息蕴含于自注意力的方差之中。" 载于《第61届计算语言学协会年会论文集(第二卷:短文)》,第13522–13537页,2023年。
- 冯锡东、罗一成、王子言、唐宏瑞、杨梦月、邵坤、大卫·姆古尼、杜雅莉和王军。"ChessGPT:连接策略学习与语言建模。"arXiv预印本 arXiv:2306.09200",2023年。
- 奥里昂·沃克·多勒、萨米拉·霍拉瓦拉维塔纳、斯科特·巴斯克斯、W·詹姆斯·普芬德特纳和斯维特兰娜·沃尔科娃。"MolJET:用于条件性从头分子设计及多属性优化的多模态联合嵌入Transformer。"正在审阅中的预印本",2023年。
- 让·卡杜尔和刘琦。"通过微调大型语言模型实现低资源环境下的文本数据增强。"arXiv:2310.01119",2023年。
- 阿隆·阿尔巴拉克、潘梁明、科林·拉菲尔和威廉·杨·王。"面向语言模型预训练的高效在线数据混合。" 载于《NeurIPS关于R0-FoMo的研讨会:大型基础模型中少样本与零样本学习的鲁棒性》,2023年。
- 埃格巴尔·A·侯赛尼和埃韦丽娜·费多连科。"大型语言模型隐式地学会将神经句法轨迹拉直,从而构建自然语言的预测性表征。" 载于《神经信息处理系统》,2023年。
- 尹俊琪、萨贾尔·达什、王飞翼和马利卡尔君·尚卡尔。"FORGE:面向科学的开放基础模型预训练。" 载于《高性能计算、网络、存储与分析国际会议论文集》,第1–13页,2023年。
- 让·卡杜尔和刘琦。"通过微调大型语言模型实现低资源环境下的文本数据增强。" 载于"arXiv预印本 arXiv:2310.01119",2023年。
- 彭迪、李建国、于航、蒋伟、蔡文婷、曹阳、陈超宇、陈大钧、陈洪伟、陈亮、樊刚、龚杰、龚梓、胡文、郭婷婷、雷志超、李婷、李正、梁明、廖聪、刘炳昌、刘嘉晨、刘志伟、陆绍军、沈敏、王广培、王欢、王志、许兆贵、杨佳伟、叶青、张戈浩、张宇、赵泽林、郑训进、周海莲、朱立夫和朱贤英。"CodeFuse-13B:一个预训练的多语言代码大型语言模型。" 载于"arXiv预印本 arXiv:2310.06266",2023年。
- 尼基塔·拉奥、库什·贾因、乌里·阿隆、克莱尔·勒古埃斯和文森特·J·赫伦多恩。"CAT-LM:在对齐的代码和测试上训练语言模型。" 载于第38届IEEE/ACM自动化软件工程国际会议(ASE),第409–420页。IEEE,2023年。
- 普拉蒂尤什·帕特尔、伊莎·丘克塞、张超杰、伊尼戈·戈伊里、布里杰什·瓦里耶尔、尼提什·马哈林甘和里卡多·比安奇尼。"POLCA:LLM云服务提供商中的功率超额订阅。" 载于"arXiv预印本",2023年。
- 尹俊琪、萨贾尔·达什、约翰·古恩利、王飞翼和乔治娅·图拉斯西。"在领导级超级计算机上预训练大型语言模型的评估。" 载于《超级计算杂志》第79卷第18期,2023年。
- 塔尔·卡多什、尼兰詹·哈萨布尼斯、Vy A. 伍、纳达夫·施耐德、内娃·克里恩、米哈伊·卡波塔、阿卜杜勒·瓦赛、内斯林·艾哈迈德、泰德·威尔克、盖伊·塔米尔、尤瓦尔·平特尔、蒂莫西·马特森和加尔·奥伦。"领域专用代码语言模型:挖掘HPC代码与任务的潜力。" 载于"arXiv预印本",2023年。
- 沈国斌、赵东成、董怡婷、李洋、李金东、孙康和曾毅。"星形胶质细胞助力脉冲神经网络在大型语言模型中的发展。" 载于"arXiv预印本",2023年。
- 埃格巴尔·A·侯赛尼、马丁·A·施林普夫、张彦、塞缪尔·鲍曼、诺加·扎斯拉夫斯基和埃韦丽娜·费多连科。"人工神经网络语言模型即使经过发育阶段上较为现实的训练量,其神经活动与行为表现仍能与人类保持一致。" 载于《语言神经生物学》,2024年。
- 肖雄业、周辰宇、彭恒、曹德富、李亚星、周义卓、李世轩和保罗·博格丹。"从多重分形分析视角探索LLM中的神经元交互与涌现现象。" 载于"arXiv预印本",2024年。
- 曾志远、郭启鹏、费兆业、尹章悦、周云华、李林阳、孙天翔、严航、林大华和邱锡鹏。"变废为宝:修正MoE的Top-k路由器。" 载于"arXiv预印本",2024年。
模型
以下模型是使用该库训练的:
英语大模型
- EleutherAI 的 GPT-NeoX-20B 和 Pythia(70M 至 13B)
- CarperAI 的 FIM-NeoX-1.3B
- StabilityAI 的 StableLM(3B 和 7B)
- Together.ai 的 RedPajama-INCITE(3B 和 7B)
- 卡内基梅隆大学的 proofGPT(1.3B 和 6.7B)
- Dampish 的 StellarX(2.8B 和 4B)
- 中国科学院的 AstroSNN(1.5B)
非英语大模型
- EleutherAI 的 Polyglot-Ko(1.3B 至 12.8B)(韩语)
- 高丽大学的 KULLM-Polyglot(5.8B 和 12.8B)(韩语)
- Stability AI 的 日语 Stable LM(7B)(日语)
- LearnItAnyway 的 LLaVA-Polyglot-Ko(1.3B)(韩语)
- Rinna 公司的 japanese-gpt-neox-3.6b(日语)和 bilingual-gpt-neox-4b(英日双语)
- CyberAgent 的 Open-CLM(125M 至 7B)(日语)
- 匈牙利语言学研究中心的 PULI GPTrio(6.7B)(匈牙利语 / 英语 / 中文)
- 东京大学的 weblab-10b 和 weblab-10b-instruct(日语)
- nolando.ai 的 Hi-NOLIN(9B)(英语、印地语)
- 中国人民大学的 YuLan(12B)(英语、中文)
- 巴斯克语言技术中心的 Latixna(70B)(巴斯克语)
代码模型
- 卡内基梅隆大学的 PolyCoder(160M 至 2.7B) 和 CAT-LM(2.7B)
- StabilityAI 的 StableCode(1.3B) 和 StableCode-Completion-Alpha(3B)
- CodeFuse AI 的 CodeFuse(13B)
科学领域的人工智能
- EleutherAI 的 LLeMMA(34B)
- 奥克里奇国家实验室的 FORGE(26B)
- 奥克里奇国家实验室的 未命名材料科学领域模型(7B)
- 太平洋西北国家实验室的 MolJet(规模未公开)
其他模态
- Rinna 公司的 PSLM(7B)(语音 / 文本)
- 伦敦大学学院的 ChessGPT-3B
- Gretel 的 Text-to-Table(3B)
行政说明
引用 GPT-NeoX
如果您在工作中发现 GPT-NeoX 库很有帮助,可以按以下方式引用该仓库:
@software{gpt-neox-library,
title = {{GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch}},
author = {Andonian, Alex and Anthony, Quentin and Biderman, Stella and Black, Sid and Gali, Preetham and Gao, Leo and Hallahan, Eric and Levy-Kramer, Josh and Leahy, Connor and Nestler, Lucas and Parker, Kip and Pieler, Michael and Phang, Jason and Purohit, Shivanshu and Schoelkopf, Hailey and Stander, Dashiell and Songz, Tri and Tigges, Curt and Thérien, Benjamin and Wang, Phil and Weinbach, Samuel},
url = {https://www.github.com/eleutherai/gpt-neox},
doi = {10.5281/zenodo.5879544},
month = {9},
year = {2023},
version = {2.0.0},
}
要引用参数量为 200 亿的模型 GPT-NeoX-20B,请使用:
@inproceedings{gpt-neox-20b,
title={{GPT-NeoX-20B}: An Open-Source Autoregressive Language Model},
author={Black, Sid and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, USVSN Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel},
booktitle={Proceedings of the ACL Workshop on Challenges \& Perspectives in Creating Large Language Models},
url={https://arxiv.org/abs/2204.06745},
year={2022}
}
贡献
GPT-NeoX 由开源人工智能社区构建,离不开我们优秀的贡献者!有关我们的 CLA、代码格式化、测试等方面的详细信息,请参阅我们的贡献指南。
许可协议
本仓库托管的是 EleutherAI GPT-NeoX 项目的一部分代码。版权所有 © 2024, EleutherAI。根据 Apache 许可证授权:
根据 Apache 许可证第 2.0 版(“许可证”)进行授权;
除非遵守许可证条款,否则不得使用此文件。
您可以在以下网址获取许可证副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则根据“原样”基础分发软件,
不提供任何形式的保证或条件。
请参阅许可证以了解具体的权限和限制。
本仓库基于 NVIDIA 编写的代码,并根据 Apache 许可证第 2.0 版授权。根据 Apache 许可证的规定,所有对 NVIDIA 原始代码进行修改的文件均保留 NVIDIA 的版权声明。而未包含此类声明的文件则完全归 EleutherAI 所有。当 NVIDIA 的代码被修改时,会在版权声明中注明这一点。本仓库的所有衍生作品都必须按照 Apache 许可证的要求保留这些声明。
此外,本仓库还包含其他作者编写的代码。相关贡献均已标注,并在适当情况下附上了相应的许可信息。
完整条款请参阅 LICENSE 文件。如您对许可有任何疑问、意见或顾虑,请发送电子邮件至 contact@eleuther.ai。
致谢
我们使用 CoreWeave 提供的 Kubernetes 集群以及 Stability AI 提供的 Slurm 集群进行实验。同时,我们也感谢 DeepSpeed 团队提供的建议和咨询。
版本历史
v2.02023/03/10v1.02023/03/09legacy_gptj_residual.1.0.02022/05/16常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。
gpt4all
GPT4All 是一款让普通电脑也能轻松运行大型语言模型(LLM)的开源工具。它的核心目标是打破算力壁垒,让用户无需依赖昂贵的显卡(GPU)或云端 API,即可在普通的笔记本电脑和台式机上私密、离线地部署和使用大模型。 对于担心数据隐私、希望完全掌控本地数据的企业用户、研究人员以及技术爱好者来说,GPT4All 提供了理想的解决方案。它解决了传统大模型必须联网调用或需要高端硬件才能运行的痛点,让日常设备也能成为强大的 AI 助手。无论是希望构建本地知识库的开发者,还是单纯想体验私有化 AI 聊天的普通用户,都能从中受益。 技术上,GPT4All 基于高效的 `llama.cpp` 后端,支持多种主流模型架构(包括最新的 DeepSeek R1 蒸馏模型),并采用 GGUF 格式优化推理速度。它不仅提供界面友好的桌面客户端,支持 Windows、macOS 和 Linux 等多平台一键安装,还为开发者提供了便捷的 Python 库,可轻松集成到 LangChain 等生态中。通过简单的下载和配置,用户即可立即开始探索本地大模型的无限可能。