SentimentAnalysis
SentimentAnalysis 是一个基于深度学习技术的开源项目,旨在对文本内容进行情感倾向识别。它能够自动分析输入的文字,将其精准分类为“积极”、“中性”或“消极”三种情感状态,帮助机器理解人类语言背后的情绪色彩。
该工具主要解决了非结构化文本难以被计算机量化理解的难题。在传统方法中,简单的关键词匹配往往无法处理复杂的语义转折或多义词汇,而 SentimentAnalysis 通过结合 Word2Vec 词向量技术与 LSTM(长短期记忆)神经网络模型,有效捕捉了词语间的上下文关联及长距离依赖关系。这种架构不仅将文字转化为高维数学向量以保留语义信息,还能像处理图像一样高效编码句子特征,从而显著提升了情感判断的准确率。
该项目非常适合自然语言处理领域的开发者、算法研究人员以及需要构建舆情监控、用户评论分析系统的数据工程师使用。对于希望快速搭建情感分析基线模型或深入探索 RNN 序列处理机制的学习者而言,它也是一份极具参考价值的实践代码。虽然目前定位为基准模型,但其清晰的架构设计为后续优化预留了充足空间,是入门与进阶文本情感分析任务的理想选择。
使用场景
某电商运营团队每天需处理数万条用户商品评论,急需从海量反馈中快速识别用户情绪以优化产品策略。
没有 SentimentAnalysis 时
- 人工逐条阅读评论效率极低,面对突发舆情无法做到实时响应,往往滞后数小时甚至数天。
- 仅靠关键词匹配(如搜索“不好”)无法识别反讽或转折语境(例如“价格虽贵但质量真好”),导致情感判断严重失真。
- 缺乏对“中性”评价的细分能力,将所有非极端评价笼统归类,丢失了大量关于用户体验细节的潜在洞察。
- 数据无法量化,难以生成可视化的情感趋势报表,管理层决策只能依赖模糊的直觉而非数据支撑。
使用 SentimentAnalysis 后
- 基于 LSTM 模型实现自动化批量处理,秒级完成数万条评论的 Positive、Neutral、Negative 三分类,实时监控舆情波动。
- 利用 Word2Vec 词向量技术深度理解语义关联,精准识别包含转折词的复杂句式,大幅降低误判率。
- 独立划分出“中性”情感类别,帮助团队筛选出那些态度温和但隐含改进建议的用户反馈,挖掘长尾需求。
- 输出结构化的情感标签数据,直接对接 BI 系统生成动态情感走势图,为产品迭代和营销活动提供精确的数据依据。
SentimentAnalysis 将非结构化的文本噪音转化为可量化的决策资产,让团队从繁琐的人工阅读中解放出来,真正实现数据驱动的用户体验优化。
运行环境要求
- 未说明
未说明
未说明
快速开始
基于LSTM三分类的文本情感分析
背景介绍
文本情感分析作为自然语言处理中的常见任务,具有极高的实际应用价值。本文将采用LSTM模型,训练一个能够识别文本中“积极”、“中性”和“消极”三种情感的分类器。
本文旨在快速熟悉LSTM在情感分析任务中的应用,因此文中仅展示了一个基础模型,并在最后对其优缺点进行了详细分析。对于真正的文本情感分析而言,在本文所提及的模型基础上,还可以开展大量工作。未来若有空闲时间,笔者将对模型进行进一步优化与改进。
理论介绍
RNN的应用场景
与传统神经网络相比,RNN允许我们对向量序列进行操作:输入序列、输出序列,或大部分的输入输出序列。如图所示,每一个矩形代表一个向量,箭头则表示函数(例如矩阵乘法)。输入向量用红色标出,输出向量用蓝色标出,绿色的矩形则表示RNN的状态(后续将详细介绍)。从左至右依次为:(1)未使用RNN的“Vanilla”模型,从固定大小的输入得到固定大小的输出(如图像分类);(2)序列输出(如图片字幕,输入一张图片后输出一段文字序列);(3)序列输入(如情感分析,输入一段文字并将其分类为积极或消极情感);(4)序列输入与序列输出(如机器翻译:RNN读取一条英文语句,然后以法语形式输出);(5)同步序列输入与输出(如视频分类,对视频中的每一帧进行标签标注)。值得注意的是,在上述每一种场景中,序列长度并未被预先设定为固定值,因为递归变换(绿色部分)是固定的,且我们可以多次重复使用。

Word2Vec算法
在建模环节中,特征提取是最关键的一步,自然语言处理领域也不例外。在自然语言处理中,最核心的问题在于:如何将一句话高效地转化为数字形式?若能完成这一步骤,句子的分类问题便迎刃而解。显然,一种最初的思路是:为每个词赋予唯一的编号1、2、3、4……,然后将句子视为一个编号集合。假设1、2、3、4分别代表“我”、“你”、“爱”、“恨”,那么“我爱你”可以表示为[1, 3, 2],“我恨你”则为[1, 4, 2]。这种思路看似有效,但实际上存在诸多问题:例如,一个稳定的模型可能会认为3和4非常接近,因此[1, 3, 2]与[1, 4, 2]应给出相近的分类结果;然而,按照我们的编号规则,3和4所代表的词语含义却截然相反,分类结果自然不可能一致。因此,这种编码方式难以取得理想的分类效果。
读者或许会想到:是否可以将意思相近的词归为一类,即赋予它们相近的编号呢?确实,如果能够将相近的词归为一组,模型的准确率无疑会大幅提升。然而问题在于,若为每个词赋予唯一的编号,并将相近的词归为相近,实际上我们是在假定语义具有单一性——也就是说,语义仅仅是一维的。然而事实并非如此,语义本应是多维的。
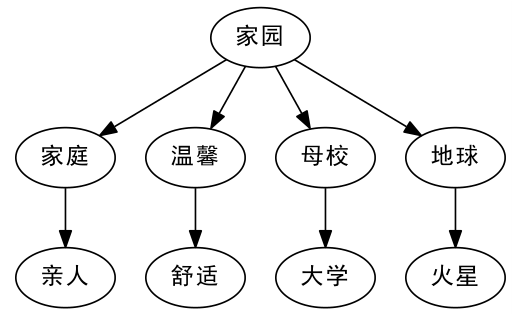
以“家园”为例,有些人会联想到近义词“家庭”,而“家庭”又可能让人联想到“亲人”。这些词虽然意思相近,但“亲人”与“火星”之间并无明显的联系。同样地,“家园”与“地球”之间也存在类似的关联,但“亲人”与“火星”之间的关系却并不紧密。此外,从语义的角度来看,“大学”与“舒适”也可以被视为“家园”的二级近似,然而“亲人”与“火星”本身却并无直接的语义联系。
Word2Vec:高维来了
通过上述讨论可知,许多词的意思往往呈多向扩散状态,而非单一指向。因此,单一的编号并不能完全满足需求。那么,如何实现多维度的编号呢?换句话说,能否将词对应一个高维向量?答案是肯定的——这正是非常正确的思路。
为什么多维向量可行呢?首先,多维向量解决了词义多方向扩散的问题:仅需二维向量,就能实现360度全方位旋转,更何况是更高维度的向量(实际应用中,通常为数百维)。其次,还有一个更为现实的问题:多维向量使我们能够用变化较小的数字来表征词义。具体来说,中文词汇数量多达数十万,若为每个词赋予唯一的编号,那么编号范围将从1到数十万不等,这样的变化幅度极大,模型的稳定性难以保证。而若采用高维向量,比如20维,只需0和1即可表达2^20 = 1048576220 = 1048576(100万)个词。由于变化较小,模型的稳定性得以保障。
尽管已经阐述了诸多内容,但我们仍未真正触及核心问题。如今,思路已清晰:接下来要解决的问题是:如何将这些词映射到合适的高维向量中?更重要的是,我们是否能在没有语言背景的情况下完成这一任务?(换句话说,如果我想处理英语任务,其实无需先学好英语,只需收集大量的英语文章,该有多方便啊!)在这里,我们无法也不必深入探讨更多理论原理,而是要重点介绍:基于这一思路,Google开源了一款著名的工具——Word2Vec。
简单来说,Word2Vec实现了我们之前所追求的目标——用高维向量(词向量,Word Embedding)来表示词义,并将意思相近的词放置在相近的位置,而且使用的是一种实数向量(而非局限于整数)。只要我们拥有足够多的某语言语料,便可利用这些语料训练模型,从而获得词向量。词向量的优点前面已有所提及,或者说,它正是为了解决前文所提到的问题而诞生的。此外,词向量还具备其他优势:借助词向量,我们能够轻松进行聚类分析,通过欧氏距离或余弦相似度,可以迅速找出意思相近的词。这相当于解决了“一词多义”的问题(遗憾的是,似乎并没有什么有效的办法来解决一词多义的问题)。
关于Word2Vec的数学原理,读者可参考相关系列文章。Word2Vec的实现,Google官方提供了C语言的源代码,读者可自行编译。此外,Python的Gensim库中也提供现成的Word2Vec子库(事实上,这个版本似乎比官方版本更强大)。
句向量
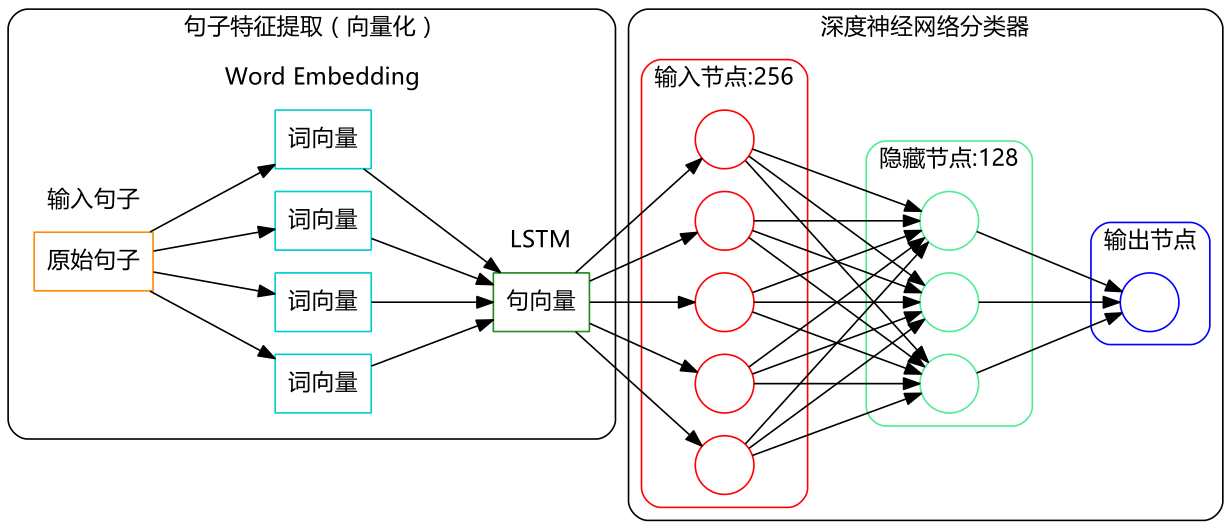
接下来要解决的问题是:我们已经将词分好,并将词转换为高维向量,那么句子就对应着词向量的集合,也就是一个矩阵——类似于图像处理,图像数字化后也会形成一个像素矩阵;然而,模型的输入一般只接受一维特征,那该怎么办呢?一个较为简单的想法是将矩阵展平,即将词向量逐一排列,组成一个更长的向量。这一思路虽可行,但会导致输入维度高达数千维甚至数万维,事实上,这在现实中几乎难以实现。(如果说数万维对今天的计算机来说不是问题,那么对于1000×1000的图像,其维度甚至高达100万维!)
在自然语言处理领域,通常采用递归神经网络或循环神经网络(统称为RNNs)。它们的作用与卷积神经网络相同:将矩阵形式的输入编码为较低维度的一维向量,同时保留大部分有用信息。
展示代码
工程代码主要结合参考资料2,用于实现文本情感分析的三分类任务;
数据预处理与词向量模型训练
参考资料2中包含了详尽的数据处理流程,包括:
- 将不同类别数据整理成输入矩阵
- 使用jieba进行分词
- 训练Word2Vec词向量模型
本文不再赘述重复介绍,若想深入了解相关内容,可前往参考资料2的博客文章中查阅。
除了“积极”和“消极”两种情感外,三分类模型还包含一种“中性”情感。原始数据集中,一些句子蕴含语义转折,例如“然而”和“但”都是关键词。由此,我们能够构建出三个不同语义的数据集。
LSTM三分类模型
代码需要注意的几点是:首先,标签需要使用keras.utils.to_categorical进行编码;其次,LSTM二分类的参数设置与二分类有所不同,我们选用softmax激活函数,并将损失函数改为categorical_crossentropy,代码如下:
def get_data(index_dict, word_vectors, combined, y):
n_symbols = len(index_dict) + 1 # 所有单词的索引数,频数小于10的词语索引为0,所以加1
embedding_weights = np.zeros((n_symbols, vocab_dim)) # 初始化索引为0的词,词向量全为0
for word, index in index_dict.items(): # 从索引为1的词开始,对每个词对应其词向量
embedding_weights[index, :] = word_vectors[word]
x_train, x_test, y_train, y_test = train_test_split(combined, y, test_size=0.2)
y_train = keras.utils.to_categorical(y_train, num_classes=3)
y_test = keras.utils.to_categorical(y_test, num_classes=3)
# print x_train.shape, y_train.shape
return n_symbols, embedding_weights, x_train, y_train, x_test, y_test
## 定义网络结构
def train_lstm(n_symbols, embedding_weights, x_train, y_train, x_test, y_test):
print '定义一个简单的Keras模型...'
model = Sequential() # 或者使用Graph或其它框架
model.add(Embedding(output_dim=vocab_dim,
input_dim=n_symbols,
mask_zero=True,
weights=[embedding_weights],
input_length=input_length)) # 添加输入长度
model.add(LSTM(output_dim=50, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax')) # Dense=>全连接层,输出维度=3
model.add(Activation('softmax'))
print '编译模型...'
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
print "训练..." # batch_size=32
model.fit(x_train, y_train, batch_size=batch_size, epochs=n_epoch, verbose=1)
print "评估..."
score = model.evaluate(x_test, y_test,
batch_size=batch_size)
yaml_string = model.to_yaml()
with open('../model/lstm.yml', 'w') as outfile:
outfile.write(yaml_string)
model.save_weights('../model/lstm.h5')
print '测试得分:', score
测试
代码如下:
def lstm_predict(string):
print '加载模型......'
with open('../model/lstm.yml', 'r') as f:
yaml_string = yaml.load(f)
model = model_from_yaml(yaml_string)
print '加载权重......'
model.load_weights('../model/lstm.h5')
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
data = input_transform(string)
data.reshape(1, -1)
#print data
result = model.predict_classes(data)
# print result # [[1]]
if result[0] == 1:
print string, '为积极'
elif result[0] == 0:
print string, '为中性'
else:
print string, '为消极'
经检测发现,原本在二分类模型中表现不佳的“不是太好”和“不错不错”这类带有前后语义转换的句子,如今均能正确预测。实战效果显著提升,不过仍存在一些不足之处:中性评价的出现概率相对较低。笔者分析原因在于:首先,从数据集的数量和质量入手,中性数据集的数量比另外两个数据集少了一半左右;其次,通过简单的规则“然而”和“但”提取出的中性数据集质量也并不高,因此出现了偏差。总而言之,训练数据的质量至关重要,如何获取高质量且数量充足的训练样本,成为了新的挑战。
- 参考资料
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
OpenHands
OpenHands 是一个专注于 AI 驱动开发的开源平台,旨在让智能体(Agent)像人类开发者一样理解、编写和调试代码。它解决了传统编程中重复性劳动多、环境配置复杂以及人机协作效率低等痛点,通过自动化流程显著提升开发速度。 无论是希望提升编码效率的软件工程师、探索智能体技术的研究人员,还是需要快速原型验证的技术团队,都能从中受益。OpenHands 提供了灵活多样的使用方式:既可以通过命令行(CLI)或本地图形界面在个人电脑上轻松上手,体验类似 Devin 的流畅交互;也能利用其强大的 Python SDK 自定义智能体逻辑,甚至在云端大规模部署上千个智能体并行工作。 其核心技术亮点在于模块化的软件智能体 SDK,这不仅构成了平台的引擎,还支持高度可组合的开发模式。此外,OpenHands 在 SWE-bench 基准测试中取得了 77.6% 的优异成绩,证明了其解决真实世界软件工程问题的能力。平台还具备完善的企业级功能,支持与 Slack、Jira 等工具集成,并提供细粒度的权限管理,适合从个人开发者到大型企业的各类用户场景。