Tabular-data-generation
TabGAN 是一款专注于生成高质量合成表格数据的开源工具。它旨在解决现实场景中原始数据稀缺、分布不均或涉及隐私敏感无法直接共享的难题,通过算法创造出既保留真实数据统计特征又具备多样性的“虚拟”数据。
这款工具非常适合数据科学家、机器学习工程师以及需要构建测试数据集的研究人员使用。无论是处理金融风控中的不平衡样本,还是为医疗研究生成脱敏数据,TabGAN 都能提供强有力的支持。
其核心亮点在于统一的调用接口,让用户能轻松切换多种前沿生成技术:包括擅长处理混合数据类型的条件表格生成对抗网络(CTGAN)、适用于结构化数据的高保真扩散模型(ForestDiffusion),以及能捕捉语义依赖的大语言模型框架(GReaT)。此外,TabGAN 内置了基于 LightGBM 的对抗过滤机制,自动剔除不符合真实分布的异常样本,确保生成数据的可靠性。它还支持一键对比原始与合成数据的分布差异,并能自动评估不同生成器的效果以推荐最佳方案。对于希望快速验证想法或保护数据隐私的团队来说,TabGAN 是一个高效且灵活的选择。
使用场景
某金融科技公司风控团队急需构建反欺诈模型,但受限于隐私法规,无法直接使用包含用户敏感信息的真实交易数据,且现有样本中欺诈案例极少,导致模型训练困难。
没有 Tabular-data-generation 时
- 数据获取受阻:因合规限制,无法将生产环境的真实脱敏数据用于外部开发或共享,导致算法迭代停滞。
- 样本严重失衡:真实数据中欺诈交易占比不足 1%,传统过采样方法(如 SMOTE)生成的数据缺乏多样性,模型极易过拟合。
- 混合类型处理繁琐:数据集中同时包含连续金额、离散类别及自由文本备注,需编写大量自定义代码进行预处理和分布对齐。
- 验证成本高昂:缺乏自动化工具评估合成数据与原始数据的分布一致性,只能依靠人工统计抽查,效率低下且不可靠。
使用 Tabular-data-generation 后
- 隐私安全合规:利用 CTGAN 或 ForestDiffusion 生成高保真合成数据,完全保留原始统计特征却不包含任何真实用户信息,轻松通过合规审查。
- 解决长尾分布:通过条件生成功能,定向扩充稀有的欺诈样本,使正负样本比例达到平衡,显著提升模型对异常交易的识别率。
- 统一接口提效:借助统一 API 自动处理数值、类别及文本列的混合类型,无需手动编写复杂的清洗逻辑,一键完成数据生成与后处理。
- 自动化质量把关:内置基于 LightGBM 的对抗性过滤机制,自动剔除分布异常的合成样本,并提供量化指标对比,确保数据可用性。
Tabular-data-generation 通过生成高质量、合规且分布均衡的合成表格数据,彻底打破了数据隐私与模型性能之间的僵局,让风控模型训练不再受限于真实数据的匮乏。
运行环境要求
- 未说明
- 未说明 (支持纯 CPU 运行,如 Random sampling 和 BayesianGenerator
- LLM 和 Diffusion 模型建议使用 GPU 加速但未强制要求)
未说明

快速开始

TabGAN
高质量合成表格数据生成



![]()
![]()

![]()
![]()
概述
TabGAN 提供了一个统一的 Python 接口,用于使用多种最先进的生成方法生成合成表格数据:
| 方法 | 后端 | 优势 |
|---|---|---|
| GANs | 条件表格 GAN (CTGAN) | 混合数据类型,复杂多变量分布 |
| 扩散模型 | ForestDiffusion(基于树的梯度提升) | 针对结构化数据的高保真生成 |
| 大型语言模型 | GReaT 框架 | 捕捉语义依赖关系,条件文本生成 |
| 基准 | 带重置的随机采样 | 快速基准测试和比较 |
所有生成器都共享一个通用流程:生成 → 后处理 → 对抗性过滤,确保合成数据与真实数据分布保持一致。
基于论文:不均衡分布下的表格 GAN (arXiv:2010.00638)
核心特性
- 统一 API — 通过更改单个参数即可在 GAN、扩散模型和 LLM 之间切换
- 对抗性过滤 — 内置基于 LightGBM 的验证机制,使合成样本分布一致
- 混合数据类型 — 原生支持连续、分类和自由文本列
- 条件生成 — 通过 LLM 提示生成基于分类属性的文本
- LLM API 支持 — 可与 LM Studio、OpenAI、Ollama 或任何兼容 OpenAI 的端点集成
- 质量验证 — 通过一次函数调用即可比较原始和合成分布
- AutoSynth — 自动运行所有生成器,比较质量和隐私,选择最佳方案
- HuggingFace 集成 — 一键合成任意 HF 数据集,并将结果推回 Hub
- 在线演示 — 在 HuggingFace Spaces 中浏览器体验
安装
pip install tabgan
快速入门
import pandas as pd
import numpy as np
from tabgan.sampler import GANGenerator
train = pd.DataFrame(np.random.randint(-10, 150, size=(150, 4)), columns=list("ABCD"))
target = pd.DataFrame(np.random.randint(0, 2, size=(150, 1)), columns=list("Y"))
test = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD"))
new_train, new_target = GANGenerator().generate_data_pipe(train, target, test)
可用生成器
| 生成器 | 描述 | 最适用场景 |
|---|---|---|
GANGenerator |
基于 CTGAN 的生成 | 具有混合类型的通用表格数据 |
ForestDiffusionGenerator |
基于树状方法的扩散模型 | 复杂的表格结构 |
BayesianGenerator |
保留边缘分布的高斯 Copula | 快速且保持相关性的生成 |
LLMGenerator |
基于大型语言模型 | 语义依赖关系,文本列 |
OriginalGenerator |
基准随机采样 | 基准测试和比较 |
API 参考
常见参数
所有生成器均接受以下参数:
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
gen_x_times |
float |
1.1 |
合成样本数量相对于训练集大小的倍数 |
cat_cols |
list |
None |
视为分类列的列名 |
bot_filter_quantile |
float |
0.001 |
后处理过滤的下分位数 |
top_filter_quantile |
float |
0.999 |
后处理过滤的上分位数 |
is_post_process |
bool |
True |
启用基于分位数的后处理过滤 |
pregeneration_frac |
float |
2 |
过滤前的过采样系数 |
only_generated_data |
bool |
False |
仅返回合成行(排除原始数据) |
gen_params |
dict |
见下文 | 生成器特定的超参数 |
生成器特定参数 (gen_params)
GANGenerator:
{"batch_size": 500, "patience": 25, "epochs": 500}
LLMGenerator:
{"batch_size": 32, "epochs": 4, "llm": "distilgpt2", "max_length": 500}
generate_data_pipe 方法
new_train, new_target = generator.generate_data_pipe(
train_df, # pd.DataFrame - 训练特征
target, # pd.DataFrame - 目标变量(或 None)
test_df, # pd.DataFrame - 测试特征,用于分布对齐
deep_copy=True, # bool - 复制输入 DataFrame
only_adversarial=False, # bool - 跳过生成,仅进行过滤
use_adversarial=True, # bool - 启用对抗性过滤
)
返回值: Tuple[pd.DataFrame, pd.DataFrame] — (new_train, new_target)
数据格式
TabGAN 接受 pandas.DataFrame 输入,包含:
- 连续列 — 任何实数值的数值数据
- 分类列 — 具有有限取值集合的离散列
注意: TabGAN 内部以浮点数处理数值。若需整数输出,请在生成后进行四舍五入。
示例
所有生成器的基本用法
from tabgan.sampler import (
OriginalGenerator, GANGenerator, ForestDiffusionGenerator,
BayesianGenerator, LLMGenerator,
)
import pandas as pd
import numpy as np
train = pd.DataFrame(np.random.randint(-10, 150, size=(150, 4)), columns=list("ABCD"))
target = pd.DataFrame(np.random.randint(0, 2, size=(150, 1)), columns=list("Y"))
test = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list("ABCD"))
new_train1, new_target1 = OriginalGenerator().generate_data_pipe(train, target, test)
new_train2, new_target2 = GANGenerator(
gen_params={"batch_size": 500, "epochs": 10, "patience": 5}
).generate_data_pipe(train, target, test)
new_train3, new_target3 = ForestDiffusionGenerator().generate_data_pipe(train, target, test)
new_train4, new_target4 = BayesianGenerator().generate_data_pipe(train, target, test)
new_train5, new_target5 = LLMGenerator(
gen_params={"batch_size": 32, "epochs": 4, "llm": "distilgpt2", "max_length": 500}
).generate_data_pipe(train, target, test)
完整参数示例
new_train, new_target = GANGenerator(
gen_x_times=1.1,
cat_cols=None,
bot_filter_quantile=0.001,
top_filter_quantile=0.999,
is_post_process=True,
adversarial_model_params={
"metrics": "AUC", "max_depth": 2, "max_bin": 100,
"learning_rate": 0.02, "random_state": 42, "n_estimators": 100,
},
pregeneration_frac=2,
only_generated_data=False,
gen_params={"batch_size": 500, "patience": 25, "epochs": 500},
).generate_data_pipe(
train, target, test,
deep_copy=True,
only_adversarial=False,
use_adversarial=True,
)
LLM 条件文本生成
根据分类属性生成包含新颖文本值的合成行:
import pandas as pd
from tabgan.sampler import LLMGenerator
train = pd.DataFrame({
"Name": ["Anna", "Maria", "Ivan", "Sergey", "Olga", "Boris"],
"Gender": ["F", "F", "M", "M", "F", "M"],
"Age": [25, 30, 35, 40, 28, 32],
"Occupation": ["Engineer", "Doctor", "Artist", "Teacher", "Manager", "Pilot"],
})
new_train, _ = LLMGenerator(
gen_x_times=1.5,
text_generating_columns=["Name"], # 需要生成新颖文本的列
conditional_columns=["Gender"], # 用于条件化文本生成的列
gen_params={"batch_size": 32, "epochs": 4, "llm": "distilgpt2", "max_length": 500},
is_post_process=False,
).generate_data_pipe(train, target=None, test_df=None, only_generated_data=True)
工作原理:
- 从条件列的经验分布中采样值。
- 使用拟合的 GReaT 模型插补其余非文本列。
- 通过基于提示的生成方式生成新颖的文本。
- 确保生成的文本值与原始数据不同。
基于 LLM API 的文本生成
使用外部 LLM API(LM Studio、OpenAI、Ollama)代替本地模型:
import pandas as pd
from tabgan.sampler import LLMGenerator
from tabgan.llm_config import LLMAPIConfig
train = pd.DataFrame({
"Name": ["Anna", "Maria", "Ivan", "Sergey", "Olga", "Boris"],
"Gender": ["F", "F", "M", "M", "F", "M"],
"Age": [25, 30, 35, 40, 28, 32],
"Occupation": ["Engineer", "Doctor", "Artist", "Teacher", "Manager", "Pilot"],
})
# LM Studio
api_config = LLMAPIConfig.from_lm_studio(
base_url="http://localhost:1234",
model="google/gemma-3-12b",
timeout=90,
)
# 或 OpenAI:LLMAPIConfig.from_openai(api_key="...", model="gpt-4")
# 或 Ollama:LLMAPIConfig.from_ollama(model="llama3")
new_train, _ = LLMGenerator(
gen_x_times=1.5,
text_generating_columns=["Name"],
conditional_columns=["Gender"],
gen_params={"batch_size": 32, "epochs": 4, "llm": "distilgpt2", "max_length": 500},
llm_api_config=api_config,
is_post_process=False,
).generate_data_pipe(train, target=None, test_df=None, only_generated_data=True)
LLM API 配置选项
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
base_url |
str |
"http://localhost:1234" |
API 服务器基础 URL |
model |
str |
"google/gemma-3-12b" |
模型标识符 |
api_key |
str |
None |
用于身份验证的 API 密钥 |
timeout |
int |
90 |
请求超时时间(秒) |
max_tokens |
int |
256 |
最大生成标记数 |
temperature |
float |
0.7 |
采样温度 |
system_prompt |
str |
None |
用于生成的系统提示 |
测试连接:
from tabgan.llm_config import LLMAPIConfig
from tabgan.llm_api_client import LLMAPIClient
config = LLMAPIConfig.from_lm_studio()
with LLMAPIClient(config) as client:
print(f"API 可用:{client.check_connection()}")
print(f"生成结果:{client.generate('生成一个女性名字:')}")
提升模型性能
import sklearn
import pandas as pd
from tabgan.sampler import GANGenerator
def evaluate(clf, X_train, y_train, X_test, y_test):
clf.fit(X_train, y_train)
return sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:, 1])
dataset = sklearn.datasets.load_breast_cancer()
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=25, max_depth=6)
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
pd.DataFrame(dataset.data),
pd.DataFrame(dataset.target, columns=["target"]),
test_size=0.33, random_state=42,
)
print("基线:", evaluate(clf, X_train, y_train, X_test, y_test))
new_train, new_target = GANGenerator().generate_data_pipe(X_train, y_train, X_test)
print("使用 GAN 后:", evaluate(clf, new_train, new_target, X_test, y_test))
时间序列数据生成
import pandas as pd
import numpy as np
from tabgan.utils import get_year_mnth_dt_from_date, collect_dates
from tabgan.sampler import GANGenerator
train = pd.DataFrame(np.random.randint(-10, 150, size=(100, 4)), columns=list("ABCD"))
min_date, max_date = pd.to_datetime("2019-01-01"), pd.to_datetime("2021-12-31")
d = (max_date - min_date).days + 1
train["Date"] = min_date + pd.to_timedelta(np.random.randint(d, size=100), unit="d")
train = get_year_mnth_dt_from_date(train, "Date")
new_train, _ = GANGenerator(
gen_x_times=1.1, cat_cols=["year"],
bot_filter_quantile=0.001, top_filter_quantile=0.999,
is_post_process=True, pregeneration_frac=2,
).generate_data_pipe(train.drop("Date", axis=1), None, train.drop("Date", axis=1))
new_train = collect_dates(new_train)
质量报告
生成一份自包含的 HTML 报告,从多个质量维度比较原始数据和合成数据:列统计信息、PSI、相关性热图、分布图以及机器学习效用(TSTR 与 TRTR)。
from tabgan import QualityReport
report = QualityReport(
original_df, synthetic_df,
cat_cols=["gender"],
target_col="target", # 启用机器学习效用评估
).compute()
# 导出为单个 HTML 文件(图表以内嵌 base64 格式)
report.to_html("quality_report.html")
# 或者以编程方式访问指标
summary = report.summary()
print(f"总体评分: {summary['overall_score']}")
print(f"PSI 均值: {summary['psi']['mean']}")
print(f"ML 效用比: {summary['ml_utility']['utility_ratio']}")
若只需快速比较而无需完整报告,可以使用以下代码:
from tabgan.utils import compare_dataframes
score = compare_dataframes(original_df, generated_df) # 0.0(差)至 1.0(优)
约束条件
对生成的数据强制执行业务规则。约束条件在数据生成后应用——无效行会被修复或过滤掉。
from tabgan import GANGenerator, RangeConstraint, UniqueConstraint, FormulaConstraint, RegexConstraint
new_train, new_target = GANGenerator(gen_x_times=1.5).generate_data_pipe(
train, target, test,
constraints=[
RangeConstraint("age", min_val=0, max_val=120),
UniqueConstraint("email"),
FormulaConstraint("end_date > start_date"),
RegexConstraint("zip_code", r"\d{5}"),
],
)
可用约束条件:
| 约束类型 | 描述 | 修复策略 |
|---|---|---|
RangeConstraint |
数值在 [min, max] 范围内 |
将数值截断到边界 |
UniqueConstraint |
列中无重复值 | 删除重复行 |
FormulaConstraint |
通过 df.eval() 的布尔表达式 |
过滤违反条件的行 |
RegexConstraint |
字符串值需匹配正则表达式 | 过滤不匹配的行 |
ConstraintEngine 支持两种策略:“fix”(先修复再过滤)和“filter”(仅丢弃违规行):
from tabgan import ConstraintEngine, RangeConstraint
engine = ConstraintEngine(
constraints=[RangeConstraint("price", min_val=0)],
strategy="fix", # 或 "filter"
)
cleaned_df = engine.apply(generated_df)
隐私度量
在共享合成数据之前,评估其重新识别风险。包括最近邻距离(DCR)、最近邻距离比(NNDR)以及成员推理风险。
from tabgan import PrivacyMetrics
pm = PrivacyMetrics(original_df, synthetic_df, cat_cols=["gender"])
summary = pm.summary()
print(f"总体隐私评分: {summary['overall_privacy_score']}") # 0(有风险)至 1(隐私性强)
print(f"DCR 均值: {summary['dcr']['mean']}")
print(f"NNDR 均值: {summary['nndr']['mean']}")
print(f"成员推理 AUC: {summary['membership_inference']['auc']}") # 接近 0.5 表示更好
度量解释:
| 度量 | 测量内容 | 良好值 |
|---|---|---|
| DCR | 每个合成行与最近真实行的距离 | 越高越隐私 |
| NNDR | 第一/第二近邻距离之比 | 接近 1.0 |
| MI AUC | 分类器能否判断记录是否来自训练数据? | 接近 0.5 表示更好 |
sklearn 管道集成
使用 TabGANTransformer 将合成数据增强插入到 sklearn Pipeline 中:
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from tabgan import TabGANTransformer
pipe = Pipeline([
("augment", TabGANTransformer(gen_x_times=1.5, cat_cols=["gender"])),
("model", RandomForestClassifier()),
])
# fit() 会生成合成数据,并在增强后的数据上训练模型
pipe.fit(X_train, y_train)
适用于任何生成器,并支持约束条件:
from tabgan import TabGANTransformer、GANGenerator 和 RangeConstraint
transformer = TabGANTransformer(
generator_class=GANGenerator,
gen_x_times=2.0,
gen_params={"batch_size": 500, "epochs": 10, "patience": 5},
constraints=[RangeConstraint("age", min_val=0, max_val=120)],
)
X_augmented = transformer.fit_transform(X_train, y_train)
y_augmented = transformer.get_augmented_target()
AutoSynth
不知道哪种生成器最适合您的数据?AutoSynth 会运行所有生成器,并根据质量和隐私评分选出最佳方案:
from tabgan import AutoSynth
result = AutoSynth(df, target_col="label").run()
print(result.report)
# 生成器 状态 评分 质量 隐私 行数 时间 (s)
# 0 GAN (CTGAN) OK 0.847 0.891 0.743 165 12.3
# 1 Forest Diffusion OK 0.812 0.834 0.761 165 45.1
# 2 Random Baseline OK 0.654 0.621 0.732 165 0.1
best_synthetic = result.best_data
print(f"获胜者: {result.best_name}")
自定义评分权重:
result = AutoSynth(
df,
target_col="label",
quality_weight=0.5, # 平等权重
privacy_weight=0.5,
).run()
HuggingFace Hub 集成
只需一次调用,即可从 HuggingFace Hub 合成任意表格数据集:
from tabgan import synthesize_hf_dataset
# 自动加载 → 生成 → 评估
result = synthesize_hf_dataset("scikit-learn/iris", target_col="target")
print(result.synthetic_df.head())
print(f"质量: {result.quality_summary['overall_score']}")
# 将合成数据推回 Hub
result = synthesize_hf_dataset(
"scikit-learn/iris",
target_col="target",
push_to_hub=True,
hub_repo_id="your-username/iris-synthetic",
)
命令行界面
tabgan-generate \
--input-csv train.csv \
--target-col target \
--generator gan \
--gen-x-times 1.5 \
--cat-cols year,gender \
--output-csv synthetic_train.csv
流程架构
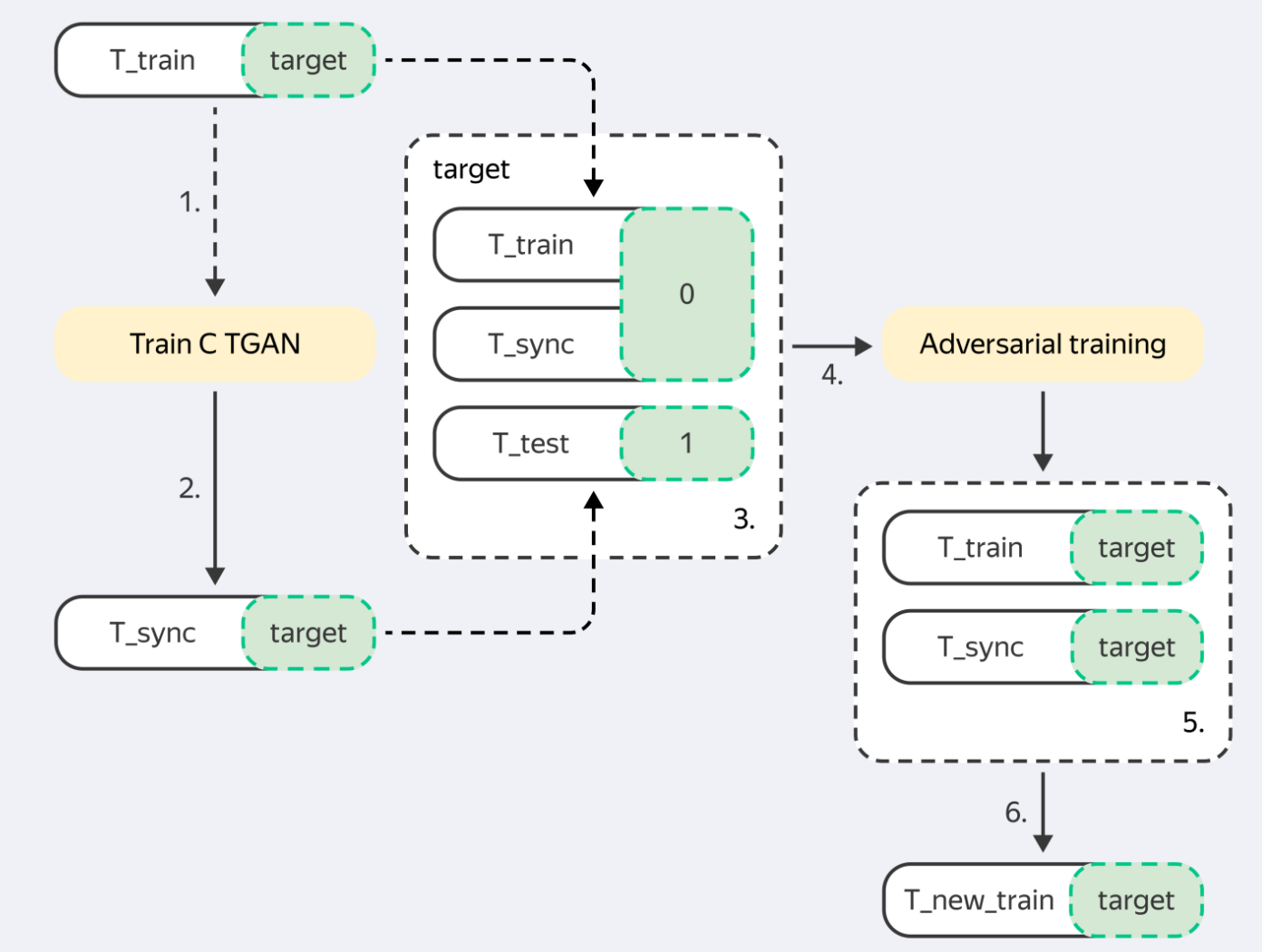
输入(train_df、target、test_df)
|
v
[预处理] --> 验证数据框,准备列
|
v
[生成] --> CTGAN / ForestDiffusion / GReaT LLM / 随机采样
|
v
[后处理] --> 基于分位数的过滤,使其符合测试分布
|
v
[对抗性过滤] --> LightGBM 分类器移除不相似样本
|
v
输出(synthetic_df、synthetic_target)
基准测试结果
归一化 ROC AUC 分数(越高越好):
| 数据集 | 无增强 | GAN | 采样原始数据 |
|---|---|---|---|
| credit | 0.997 | 0.998 | 0.997 |
| employee | 0.986 | 0.966 | 0.972 |
| mortgages | 0.984 | 0.964 | 0.988 |
| poverty_A | 0.937 | 0.950 | 0.933 |
| taxi | 0.966 | 0.938 | 0.987 |
| adult | 0.995 | 0.967 | 0.998 |
## 引用
```bibtex
@misc{ashrapov2020tabular,
title={用于不均衡分布的表格 GAN},
author={Insaf Ashrapov},
year={2020},
eprint={2010.00638},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
参考文献
- 徐亮,维拉马切内尼,K.(2018)。使用生成对抗网络合成表格数据。arXiv:1811.11264。
- 若利库尔-马蒂诺,A.,法特拉斯,K.,卡赫曼,T.(2023)。通过扩散模型和基于流的梯度提升树生成与填补表格数据。SamsungSAILMontreal/ForestDiffusion。
- 徐亮,斯库拉里杜,M.,库埃斯塔-因凡特,A.,维拉马切内尼,K.(2019)。使用条件生成对抗网络建模表格数据。NeurIPS。
- 鲍里索夫,V.,塞斯勒,K.,莱曼,T.,帕韦尔奇克,M.,卡斯内奇,G.(2023)。语言模型是真实的表格数据生成器。ICLR。
许可证
Apache许可证2.0 — 详情请参阅LICENSE文件。
版本历史
v3.2.02026/03/29v3.0.12026/03/282.0.02023/09/301.2.02021/12/261.0.32021/02/18research2020/07/13常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。