rl_games
rl_games 是一款基于 PyTorch 的高性能强化学习开源库,旨在简化并加速智能体的训练过程。它主要解决了传统强化学习框架中 GPU 利用率低、环境适配繁琐以及大规模并行训练困难等问题。
通过提供端到端的 GPU 加速训练管道,rl_games 能够无缝对接 Isaac Gym、Brax 及 MuJoCo 等多种仿真环境。其核心亮点包括支持不对称 Actor-Critic 结构的 PPO 算法、多智能体训练(含去中心化与集中式 Critic)、自博弈模式以及掩码动作支持。此外,它还集成了 EnvPool 引擎以实现极高的环境执行效率,并允许将模型导出为 ONNX 格式以便部署。
对于从事机器人控制、游戏 AI 开发或强化学习算法研究的技术人员来说,它是非常理想的选择。无论是希望在 NVIDIA Isaac Gym 上训练机械臂,还是在星际争霸等多智能体环境中测试策略,rl_games 都能提供稳定且高效的实现方案,帮助团队快速从实验走向落地。
使用场景
某机器人初创公司的算法团队正在开发灵巧手操作任务,需要在仿真环境中快速训练策略并迁移到真机。
没有 rl_games 时
- 需要从零编写强化学习算法代码,调试 PPO 等策略耗时耗力,容易引入 Bug。
- CPU 并行环境数量受限,单卡训练效率低,模型收敛慢,迭代周期长达数周。
- 仿真环境与算法框架耦合紧密,更换物理引擎(如从 Mujoco 换到 Isaac Gym)需重构大量代码。
- 缺乏多智能体协作支持,难以模拟灵巧手指间复杂的协同控制动作。
使用 rl_games 后
- rl_games 内置成熟的 PPO 实现,直接调用即可开始训练,节省大量基础编码时间。
- 利用 GPU 加速和 EnvPool 技术,单卡可并行运行数千个环境,训练速度提升数十倍。
- 原生支持 Isaac Gym 和 Brax,无缝切换不同仿真后端,无需修改核心逻辑。
- 提供多智能体训练接口,轻松实现灵巧手指间的协同控制策略,加速 Sim-to-Real 迁移。
rl_games 通过高性能 GPU 并行与成熟算法库,将机器人策略训练周期从数周缩短至数天。
运行环境要求
- 未说明
推荐 NVIDIA GPU,CUDA 12.1+ (最高性能)
未说明

快速开始
RL Games:高性能强化学习 (RL) 库
注意: 下一个版本将是 2.0.0(未发布)。它将从 gym 完全迁移到 gymnasium,并移除旧的环境集成(envpool, cule)。
Discord 频道链接
论文及相关链接
- Isaac Gym:用于机器人学习的高性能基于 GPU 的物理仿真:https://arxiv.org/abs/2108.10470
- DeXtreme:从仿真到现实的敏捷手中操作转移:https://dextreme.org/ https://arxiv.org/abs/2210.13702
- 将灵巧操作从 GPU 仿真转移到远程真实世界 TriFinger:https://s2r2-ig.github.io/ https://arxiv.org/abs/2108.09779
- 在星际争霸多智能体挑战中,独立学习是唯一的必要条件吗?https://arxiv.org/abs/2011.09533
- Superfast 对抗运动先验 (AMP) 实现:https://twitter.com/xbpeng4/status/1506317490766303235 https://github.com/NVIDIA-Omniverse/IsaacGymEnvs
- OSCAR:面向自适应和鲁棒机器人操作的数据驱动操作空间控制:https://cremebrule.github.io/oscar-web/ https://arxiv.org/abs/2110.00704
- EnvPool:高度并行的强化学习环境执行引擎:https://arxiv.org/abs/2206.10558 和 https://github.com/sail-sg/envpool
- TimeChamber:大规模并行自博弈框架:https://github.com/inspirai/TimeChamber
不同环境中的一些结果



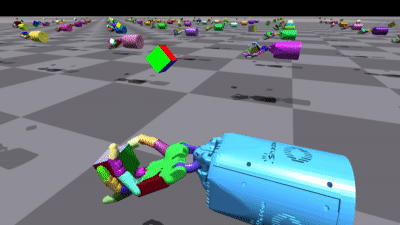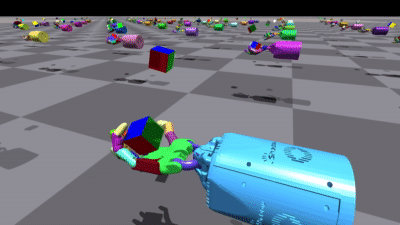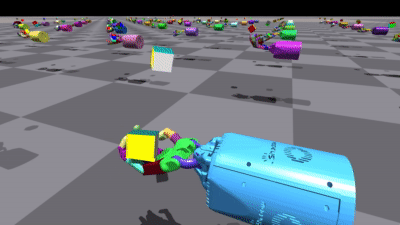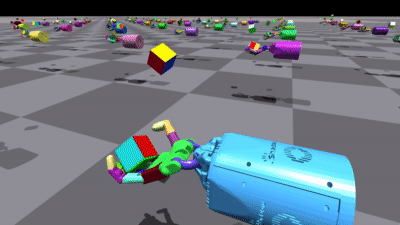


使用 PyTorch 实现:
- 支持非对称 Actor-Critic (演员 - 评论家) 变体的 PPO (近端策略优化)
- 支持使用 Isaac Gym 和 Brax 的端到端 GPU (图形处理器) 加速训练流程
- 支持掩码动作
- 多智能体训练,去中心化和集中式 Critic (评论家) 变体
- 自博弈
使用 TensorFlow 1.x 实现(此版本已移除):
- Rainbow DQN (深度 Q 网络)
- A2C (异步优势演员 - 评论家)
- PPO (近端策略优化)
快速开始:云端 Colab
在 Colab 笔记本中快速轻松地探索 RL Games:
- Mujoco 训练 Mujoco envpool 训练示例。
- Brax 训练 Brax 训练示例,保持所有观测值和动作在 GPU (图形处理器) 上。
- Cartpole 的 ONNX (开放神经网络交换) 离散空间导出示例 envpool 训练示例。
- Pendulum 的 ONNX (开放神经网络交换) 连续空间导出示例 envpool 训练示例。
- 带有 LSTM (长短期记忆网络) 的 Pendulum ONNX (开放神经网络交换) 连续空间导出示例 envpool 训练示例。
安装
为了获得最大的训练性能,强烈建议预先安装 PyTorch 2.2 或更高版本以及 CUDA 12.1 或更高版本:
pip3 install torch torchvision
然后:
pip install rl-games
或者克隆仓库并从源代码安装最新版本:
pip install -e .
要运行基于 CPU (中央处理器) 的环境,需要安装 envpool(如果支持)或 Ray:pip install envpool 或 pip install ray
要运行 Mujoco、Atari 游戏或基于 Box2d 的环境训练,需要分别额外安装 pip install gym[mujoco]、pip install gym[atari] 或 pip install gym[box2d]。
运行 Atari 还需要 pip install opencv-python。对于现代的 Gymnasium/ALE Atari 环境,请安装 pip install ale-py。此外,强烈建议安装 envpool 以获得 Mujoco 和 Atari 环境的最大模拟和训练性能:pip install envpool
EnvPool + NumPy 2+ 不兼容问题
重要: 如果使用 EnvPool,您必须使用 NumPy 1.x。NumPy 2.0+ 不兼容 EnvPool 并将导致训练失败(查看问题)。
降级到 NumPy 1.26.4:
pip uninstall numpy
pip install numpy==1.26.4
引用
如果您在研究中使用 rl-games,请使用以下引用:
@misc{rl-games2021,
title = {rl-games: A High-performance Framework for Reinforcement Learning},
author = {Makoviichuk, Denys and Makoviychuk, Viktor},
month = {May},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Denys88/rl_games}},
}
开发环境设置
poetry install
# 安装 cuda 相关依赖
poetry run pip install torch torchvision
训练
NVIDIA Isaac Gym
下载并遵循 Isaac Gym (NVIDIA 强化学习仿真平台) 的安装说明:https://developer.nvidia.com/isaac-gym
以及 IsaacGymEnvs:https://github.com/NVIDIA-Omniverse/IsaacGymEnvs
Ant
python train.py task=Ant headless=True
python train.py task=Ant test=True checkpoint=nn/Ant.pth num_envs=100
Humanoid
python train.py task=Humanoid headless=True
python train.py task=Humanoid test=True checkpoint=nn/Humanoid.pth num_envs=100
Shadow Hand 方块朝向任务
python train.py task=ShadowHand headless=True
python train.py task=ShadowHand test=True checkpoint=nn/ShadowHand.pth num_envs=100
其他
Atari Pong
python runner.py --train --file rl_games/configs/atari/ppo_pong_envpool.yaml
python runner.py --play --file rl_games/configs/atari/ppo_pong_envpool.yaml --checkpoint nn/Pong-v5_envpool.pth
或者使用 Poetry (Python 包管理工具):
poetry install -E atari
poetry run python runner.py --train --file rl_games/configs/atari/ppo_pong.yaml
poetry run python runner.py --play --file rl_games/configs/atari/ppo_pong.yaml --checkpoint nn/PongNoFrameskip.pth
Brax Ant
pip install -U "jax[cuda12]"
pip install brax
python runner.py --train --file rl_games/configs/brax/ppo_ant.yaml
python runner.py --play --file rl_games/configs/brax/ppo_ant.yaml --checkpoint runs/Ant_brax/nn/Ant_brax.pth
实验跟踪
rl_games 支持通过 Weights and Biases (W&B) 进行实验跟踪。
python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --track
WANDB_API_KEY=xxxx python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --track
python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --wandb-project-name rl-games-special-test --track
python runner.py --train --file rl_games/configs/atari/ppo_breakout_torch.yaml --wandb-project-name rl-games-special-test -wandb-entity openrlbenchmark --track
多 GPU
我们使用 torchrun (PyTorch 分布式运行工具) 来编排所有多 GPU 运行。
torchrun --standalone --nnodes=1 --nproc_per_node=2 runner.py --train --file rl_games/configs/ppo_cartpole.yaml
配置参数
| Field | Example Value | Default | Description |
|---|---|---|---|
| seed | 8 | None | 随机种子。用于 PyTorch、NumPy 等。 |
| algo | 算法块。 | ||
| name | a2c_continuous | None | 算法名称。可能值为:sac, a2c_discrete, a2c_continuous |
| model | 模型块。 | ||
| name | continuous_a2c_logstd | None | 可能值:continuous_a2c(期望 sigma 为 (0, +inf)), continuous_a2c_logstd(期望 sigma 为 (-inf, +inf)), a2c_discrete, a2c_multi_discrete |
| network | 网络描述。 | ||
| name | actor_critic | 可能值:actor_critic 或 soft_actor_critic。 | |
| separate | False | 是否使用具有相同架构的独立网络作为 Critic(评论家网络)。在几乎所有情况下,如果您归一化价值,最好将其设为 False | |
| space | 网络空间 | ||
| continuous | 连续或离散 | ||
| mu_activation | None | mu 的激活函数。在几乎所有情况下 None 效果最好,但我们也可以尝试 tanh。 | |
| sigma_activation | None | sigma 的激活函数。根据模型的不同,将被视为 log(sigma) 或 sigma。 | |
| mu_init | mu 的初始化器。 | ||
| name | default | ||
| sigma_init | sigma 的初始化器。如果您使用 logstd 模型,好的值是 0。 | ||
| name | const_initializer | ||
| val | 0 | ||
| fixed_sigma | True | 如果为 True,则 sigma 向量不依赖于输入。 | |
| cnn | 卷积块。 | ||
| type | conv2d | 类型:目前支持两种类型:conv2d 或 conv1d | |
| activation | elu | 卷积层之间的激活函数。 | |
| initializer | 初始化器。我参考了一些 TensorFlow 的名称。 | ||
| name | glorot_normal_initializer | 初始化器名称 | |
| gain | 1.4142 | 附加参数。 | |
| convs | 卷积层。与 Torch 中的参数相同。 | ||
| filters | 32 | 滤波器数量。 | |
| kernel_size | 8 | 核大小。 | |
| strides | 4 | 步长 | |
| padding | 0 | 填充 | |
| filters | 64 | 下一个卷积层信息。 | |
| kernel_size | 4 | ||
| strides | 2 | ||
| padding | 0 | ||
| filters | 64 | ||
| kernel_size | 3 | ||
| strides | 1 | ||
| padding | 0 | ||
| mlp | MLP(多层感知机)块。也支持卷积。请参见其他配置示例。 | ||
| units | MLP 层的尺寸数组,例如:[512, 256, 128] | ||
| d2rl | False | 使用来自 https://arxiv.org/abs/2010.09163 的 d2rl 架构。 | |
| activation | elu | 全连接层之间的激活函数。 | |
| initializer | 初始化器。 | ||
| name | default | 初始化器名称。 | |
| rnn | RNN(循环神经网络)块。 | ||
| name | lstm | RNN 层名称。支持 lstm 和 gru。 | |
| units | 256 | 单元数量。 | |
| layers | 1 | 层数 | |
| before_mlp | False | False | 是否在 mlp 块之前应用 rnn。 |
| config | 强化学习配置块。 | ||
| reward_shaper | 奖励塑形器。可以应用简单的变换。 | ||
| min_val | -1 | 您可以应用 min_val, max_val, scale 和 shift。 | |
| scale_value | 0.1 | 1 | |
| normalize_advantage | True | True | 归一化优势。 |
| gamma | 0.995 | 奖励折扣 | |
| tau | 0.95 | GAE(广义优势估计)的 Lambda。很久以前错误地称为 tau,因为 lambda 是 Python 的关键字 :( | |
| learning_rate | 3e-4 | 学习率。 | |
| name | walker | 将在 TensorBoard 中使用的名称。 | |
| save_best_after | 10 | 在开始保存具有最佳分数的检查点之前要等待多少个 epoch。 | |
| score_to_win | 300 | 如果分数 >= 该值,则训练将停止。 | |
| grad_norm | 1.5 | 梯度范数。如果 truncate_grads 为 True 则应用。好的值在 (1.0, 10.0) 之间 | |
| entropy_coef | 0 | 熵系数。连续空间的较好值为 0。离散空间为 0.02 | |
| truncate_grads | True | 是否应用截断梯度。它有助于稳定训练。 | |
| env_name | BipedalWalker-v3 | 环境名称。 | |
| e_clip | 0.2 | PPO 损失的 clip 参数。 | |
| clip_value | False | 对价值损失应用 clip。如果您使用 normalize_value,则不需要它。 | |
| num_actors | 16 | 运行智能体/环境的数量。 | |
| horizon_length | 4096 | 每个智能体的时间跨度长度。总步数将为 num_actors*horizon_length * num_agents(如果环境不是多智能体,num_agents==1)。 | |
| minibatch_size | 8192 | 小批量大小。总步数必须能被小批量大小整除。 | |
| minibatch_size_per_env | 8 | 每个环境的小批量大小。如果指定,将用 minibatch_size_per_env * nume_envs 的值覆盖默认的小批量大小总数。 | |
| mini_epochs | 4 | 小轮次的数量。好的值在 [1,10] 之间 | |
| critic_coef | 2 | Critic 系数。默认 critic_loss = critic_coef * 1/2 * MSE。 | |
| lr_schedule | adaptive | None | 调度器类型。可以是 None、linear 或 adaptive。对于连续控制任务,Adaptive 是最好的。学习率在每个 miniepoch 都会改变 |
| kl_threshold | 0.008 | 自适应调度的 KL 阈值。如果 KL < kl_threshold/2,lr = lr * 1.5,反之亦然。 | |
| normalize_input | True | 对输入应用运行均值标准差。 | |
| bounds_loss_coef | 0.0 | 连续空间的辅助损失系数。 | |
| max_epochs | 10000 | 运行的最大轮次数。 | |
| max_frames | 5000000 | 运行的最大帧数(环境步数)。 | |
| normalize_value | True | 使用价值运行均值标准差归一化。 | |
| use_diagnostics | True | 向 TensorBoard 添加更多信息。 | |
| value_bootstrap | True | 当回合结束时引导价值。对不同运动环境非常有用。 | |
| bound_loss_type | regularisation | None | 为连续情况添加辅助损失。'regularisation' 是动作平方和。'bound' 是大于 1.1 的动作之和。 |
| bounds_loss_coef | 0.0005 | 0 | 正则化系数 |
| use_smooth_clamp | False | 使用平滑钳制代替常规进行裁剪 | |
| zero_rnn_on_done | False | True | 如果为 False,当环境重置时,RNN 内部状态不会重置(设置为 0)。在某些情况下可能会改善训练,例如当启用域随机化时 |
| player | 玩家配置块。 | ||
| render | True | False | 渲染环境 |
| deterministic | True | True | 使用确定性策略(argmax 或 mu)或随机策略。 |
| use_vecenv | True | False | 使用 vecenv 为玩家创建环境 |
| games_num | 200 | 玩家模式下运行的游戏数量。 | |
| env_config | 环境配置块。它直接传递给环境。此示例取自我的 Atari 包装器。 | ||
| skip | 4 | 跳过的帧数 | |
| name | BreakoutNoFrameskip-v4 | (Atari) Gym 环境的精确名称。例如,取决于训练环境,此参数可能不同。 | |
| evaluation | True | False | 启用训练时的推理评估功能。 |
| update_checkpoint_freq | 100 | 100 | 查找新检查点的步骤频率。 |
| dir_to_monitor | 评估期间搜索检查点的目录。 |
自定义网络示例:
简单测试网络
该网络接收字典形式的观测 (observation)。
要注册它,你可以在你的 init.py 中添加代码
from rl_games.envs.test_network import TestNetBuilder
from rl_games.algos_torch import model_builder
model_builder.register_network('testnet', TestNetBuilder)
额外支持的环境属性和函数
| Field | Default Value | Description |
|---|---|---|
| use_central_value | False | 如果为真,则返回的观测 (obs) 预期为包含 'obs' 和 'state' 的字典 (dict) |
| value_size | 1 | 返回奖励的形状。网络将自动支持多头价值 (multihead value)。 |
| concat_infos | False | 默认的 vecenv (向量环境) 是否应将字典列表转换为列表的字典。如果您想使用 value_bootstrap (价值引导),这非常有用。在这种情况下,您需要始终从环境中返回 'time_outs' : True 或 False,来自环境。 |
| get_number_of_agents(self) | 1 | 返回环境中智能体 (agents) 的数量 |
| has_action_mask(self) | False | 如果环境具有无效动作掩码 (action_mask),则返回 True。 |
| get_action_mask(self) | None | 如果 has_action_mask 为真,则返回动作掩码。一个好的例子是 SMAC 环境 |
发布说明
1.6.5
- 添加了支持可配置模式的
torch.compile(PyTorch 编译)支持。提供 10-40% 的性能提升。需要 torch 2.2 或更高版本。- 默认模式为
reduce-overhead,用于平衡编译时间和运行时性能 - 可通过 yaml 配置(配置文件格式)中的
torch_compile参数配置(true/false/"default"/"reduce-overhead"/"max-autotune") - Actor 和中央价值网络具有独立的编译模式
- 参见 torch.compile 文档 以获取详细的配置和模式选择指南
- 默认模式为
- 修复了非对称 actor-critic(演员 - 评论家架构)(central_value)训练中的关键错误:
- 修复了
update_lr()方法中错误的设备引用 - 修复了遍历数据集时的无限循环问题
- 为
PPODataset类添加了正确的__iter__方法
- 修复了
- 修复了
RunningMeanStd中的方差计算,改用总体方差 - 修复了
get_mean_std_with_masks函数。 - 修复了检查点保存/加载时缺失的中央价值优化器状态
- 添加了 myosuite 支持。
- 添加了辅助损失(auxiliary loss)支持。
- Tacsl 更新:CNN(卷积神经网络)塔处理、critic 权重加载和冻结。
- 修复了 SAC(Soft Actor-Critic)输入归一化。
- 修复了 SAC agent summary writer,使其使用配置的目录而不是硬编码的 'runs/'
- 修复了默认 player 配置中的 num_games 值。
- 修复了每个环境应用 minibatch 大小的问题。
- 为 RNN(循环神经网络)添加了 concat_output 支持。
- SAC 改进:
- 修复了缺失的
gamma_tensor初始化错误 - 移除了硬编码的
torch.compile装饰器(现在遵循 YAML 配置) - 优化了张量操作并移除了不必要的克隆
- 修复了缺失的
- 环境包装器修复:
- 修复了元组/列表观测值的处理,以兼容各种 gym 环境
- 在
cast_obs中添加了正确的 numpy 到 torch 张量的转换 - 修复了 envpool 包装器中缺失的 gym 导入
- Ray(分布式计算框架)集成改进:
- 将 Ray 导入移至延迟加载(仅在使用的
RayVecEnv时) - 添加了带
ray_config参数的可配置 Ray 初始化 - 为 Ray actors 添加了带
close()方法的正确清理 - 默认对象存储内存分配为 1GB
- 将 Ray 导入移至延迟加载(仅在使用的
1.6.1
- 修复了在训练多智能体(multi-agent)环境时发生的 Central Value RNN 错误。
- 添加了 Deepmind Control PPO 基准测试。
- 添加了几种训练价值预测的实验性方法(OneHot、TwoHot 编码以及交叉熵损失代替 L2)。
- 新方法尚未启用。无法从 yaml 文件中开启它。一旦我们找到训练效果更好的环境,就会将其添加到配置中。
- 将 shaped reward 图添加到 tensorboard(可视化工具)。
- 修复了 SAC 不根据 save_frequency 保存权重的错误。
- 为 Isaac Gym(NVIDIA 物理仿真平台)等 GPU 加速训练环境添加了多节点训练支持。无需更改训练脚本。感谢 @ankurhanda 和 @ArthurAllshire 在实现上的协助。
- 添加了训练期间推理的评估功能。启用后,训练过程中的检查点可以自动被推理过程拾取和更新。增强版。
- 添加了用于运行时更新 RL 训练参数的 get/set API。感谢 @ArthurAllshire 提供了快速 PBT 代码的初始版本。
- 修复了 SAC 无法正确加载权重的问题。
- 移除了在不需要的用例中对 Ray 的依赖。
- 添加了警告,提示在使用 RNN 网络的配置中使用已弃用的 'seq_len' 而非 'seq_length'。
1.6.0
- 添加了离散和连续动作空间的 ONNX(开放神经网络交换)导出 Colab(云端笔记本)示例。对于连续情况,也提供了 LSTM(长短期记忆网络)策略示例。
- 改进了连续空间中的 RNN 训练,添加了选项
zero_rnn_on_done。 - 添加了 NVIDIA CuLE 支持:https://github.com/NVlabs/cule
- 添加了 player 配置 everride。Vecenv 用于推理。
- 修复了带有 central value 的多 GPU 训练。
- 修复了 max_frames 终止条件及其与线性学习率的交互:https://github.com/Denys88/rl_games/issues/212
- 修复了 "deterministic" 拼写错误问题。
- 修复了 Mujoco(物理引擎)和 Brax 的 SAC 配置。
- 修复了多智能体环境的统计报告。修复了 Starcraft2 SMAC 环境。
1.5.2
- 为 SAC 添加了观测值归一化。
- 恢复了自适应 KL 旧模式。
1.5.1
- 修复了构建包问题。
1.5.0
- 添加了 wandb(Weights & Biases 实验跟踪工具)支持。
- 添加了 poetry(Python 包管理工具)支持。
- 修复了各种错误。
- 修复了字典类型观测值情况下 CNN 输入未除以 255 的问题。
- 添加了更多 envpool(环境池)mujoco 和 atari 训练示例。部分结果:15 分钟 Mujoco 人形机器人训练,2 分钟 atari pong。
- 添加了 Brax 和 Mujoco 的 Colab 训练示例。
- 添加了 'seed' 命令行参数。如果大于 0,将覆盖配置中的 seed。
- 弃用
horovod(分布式训练框架),转而使用torch.distributed(PyTorch 分布式后端) (#171)。
1.4.0
- 添加了 Discord 频道 https://discord.gg/hnYRq7DsQh :)
- 添加了 envpool 支持及几个 atari 示例。比 ray 快 3-4 倍。
- 添加了 mujoco 结果。比 openai spinning up ppo 结果好得多。
- 添加了 tcnn(Tiny CUDA Neural Networks)(https://github.com/NVlabs/tiny-cuda-nn) 支持。减少 IsaacGym 环境中 5-10% 的训练时间。
- 各种修复和改进。
1.3.2
- 添加了 'sigma' 命令行参数。如果 fixed_sigma 为 True,将覆盖连续空间的 sigma。
1.3.1
- 修复了 SAC 无法工作的问题
1.3.0
- 简化了 RNN 实现。运行稍慢但更稳定。
- 现在如果策略是 RNN,Central Value 可以是非 RNN。
- 从 yaml 文件中移除了 load_checkpoint。现在 --checkpoint 对训练和游玩都有效。
1.2.0
- 添加了 Swish(激活函数)(SILU) 和 GELU(高斯误差线性单元)激活函数,它可以改善某些环境的 Isaac Gym 结果。
- 移除了 tensorflow(深度学习框架)并对旧/未使用的代码进行了初步清理。
- 简化了 runner。
- 现在网络是在 algos 中通过 load_network 方法创建的。
1.1.4
- 修复了 player 在 play(测试)模式下的崩溃问题,当 simulation 和 rl_devices 不同时。
- 修复了各种多 GPU 错误。
1.1.3
- 修复了在 play(测试)模式下运行单个 Isaac Gym 环境时的崩溃问题。
- 添加了配置参数
clip_actions,用于关闭内部动作裁剪和重缩放
1.1.0
- 添加到 PyPI:
pip install rl-games - 添加了报告环境(模拟)步骤 fps,不包含策略推理。改进了命名。
- 为了更好的可读性,重命名 yaml 配置:steps_num 改为 horizon_length 和 lr_threshold 改为 kl_threshold
故障排除
- 部分支持的环境未通过 setup.py 安装,您需要手动安装它们
- 从 rl-games 1.1.0 开始,旧的 yaml 配置将不兼容新版本:
steps_num应更改为horizon_length且lr_threshold更改为kl_threshold
已知问题
- 使用 Isaac Gym 运行单个环境可能导致崩溃,如果发生这种情况,请切换到至少并行模拟 2 个环境
版本历史
v1.6.52026/02/20v1.6.12023/10/06v1.6.02023/02/21v1.0-alpha22020/10/17v1.0-alpha2020/10/17常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。