Awesome-RL-VLA
Awesome-RL-VLA 是一个专注于机器人操作领域中“视觉-语言-动作”(VLA)模型强化学习研究的精选资源库。随着大模型在机器人领域的应用日益广泛,如何让机器人不仅“看懂”指令,还能在复杂多变的环境中灵活执行动作,成为研究热点。Awesome-RL-VLA 旨在系统梳理这一前沿方向,为社区提供一份全面、结构化的文献综述与技术指南。
该项目核心解决了 VLA 模型在分布外(OOD)场景下泛化能力不足的问题。通过引入强化学习(RL),机器人能够从环境反馈中不断优化策略,从而适应未见过的任务或环境变化。Awesome-RL-VLA 详细归纳了三种主流训练范式:无需实时交互的“离线 RL-VLA”,适合高风险或资源受限场景;通过与环境持续互动来提升适应性的“在线 RL-VLA”;以及在部署阶段通过轻量级调整实现行为适配的“测试时 RL-VLA”。
这份资源非常适合人工智能研究人员、机器人算法工程师以及对具身智能感兴趣开发者使用。它不仅收录了最新的学术论文,还整理了包括基础 VLA 模型、数据集、基准测试及开发框架在内的实用工具链。其独特亮点在于清晰的分类体系,帮助用户快速定位如策略优化、样本效率提升或训练稳定性等关键研究方向。无论是希望深入了解理论前沿的学者,还是寻求工程落地参考的技术人员,都能从中获得有价值的指引,加速下一代智能机器人操控技术的研发进程。
使用场景
某智能仓储机器人团队正致力于开发一款能理解自然语言指令(如“把那个红色的易碎盒子放到顶层货架”)并执行精细抓取任务的通用机械臂,旨在解决传统自动化无法应对的非结构化分拣难题。
没有 Awesome-RL-VLA 时
- 技术选型迷茫:面对海量的视觉-语言-动作(VLA)论文,研发团队难以厘清离线、在线及测试时强化学习(RL)的具体适用边界,导致技术路线反复摇摆,浪费数月调研时间。
- 泛化能力瓶颈:仅依靠静态数据集训练的模型在遇到未见过的物体或光照变化时(分布外场景 OOD),抓取成功率断崖式下跌,且缺乏有效的 RL 微调策略来提升鲁棒性。
- 试错成本高昂:尝试在线 RL 训练时,由于缺乏成熟的采样效率优化和探索策略参考,机器人在物理环境中盲目试错,不仅训练收敛极慢,还频繁造成硬件损耗。
- 部署适应性差:模型一旦部署便无法适应现场细微的环境变动,重新全量微调算力需求巨大,无法满足实时调整的需求。
使用 Awesome-RL-VLA 后
- 路径清晰高效:通过综述中分类清晰的训练范式(Offline/Online/Test-time RL),团队迅速锁定“离线预训练+在线轻量微调”的混合架构,缩短了 50% 的技术验证周期。
- 突破泛化局限:借鉴列表中关于 OOD 泛化的 SOTA 方法,引入奖励机制优化策略,使机器人在处理陌生物品时的抓取成功率从 60% 提升至 90% 以上。
- 训练稳定安全:参考推荐的主动探索策略与基础设施框架,显著提高了样本效率,减少了物理环境中的无效交互次数,降低了硬件磨损风险。
- 灵活实时适配:利用测试时 RL(Test-time RL)技术,通过价值引导和记忆缓冲机制,让机器人在不更新参数的前提下实时修正动作,完美应对现场突发状况。
Awesome-RL-VLA 为机器人研发团队提供了从理论到实践的系统化导航,极大地加速了具备高泛化能力智能操作系统的落地进程。
运行环境要求
- 未说明
未说明
未说明

快速开始
用于机器人操作的优秀强化学习视觉-语言-动作模型 🤖
[论文]
这是一份精心整理的关于用于机器人操作的**视觉-语言-动作强化学习(RL-VLA)**模型的论文和资源列表。该仓库提供了RL-VLA研究中训练范式、方法论以及最先进方法的全面概述。
📢 最新消息
🔥 [2025年11月] 我们的综述论文**“面向机器人操作的视觉-语言-动作模型强化学习综述”**现已在TechRxiv上发布!敬请关注后续更新。
📖 目录
🔍 概述
强化学习训练对于使VLAs能够从大规模预训练数据中泛化到分布外(OOD)场景至关重要。现有的RL-VLA训练范式可以根据智能体如何获取并利用环境反馈分为三类:
- 在线RL-VLA:在训练过程中直接与环境交互
- 离线RL-VLA:从静态数据集中学习,无需进一步的环境交互
- 测试时RL-VLA:模型在部署过程中调整其行为,而不改变参数
🚀 训练范式
离线RL-VLA
离线RL在预先收集的静态数据集上训练VLA模型,使其能够在不依赖环境交互的情况下进行学习。这种范式适用于高风险或资源受限的部署场景。
关键研究方向:
- 数据利用:有效利用静态数据集来改进策略
- 目标修改:为新型架构和数据增强定制强化学习目标
在线RL-VLA
在线RL-VLA通过持续的环境交互实现交互式策略学习,使预训练的VLAs具备适应性闭环控制能力,从而应对现实世界中的OOD环境。
关键研究方向:
- 策略优化:基于环境奖励直接改进策略
- 样本效率:在有限的交互预算内学习有效的策略
- 主动探索:高效的探索策略以获得更高的性能提升
- 训练稳定性:确保策略更新的一致性和收敛性
- 基础设施:可扩展的在线RL-VLA训练框架
测试时RL-VLA
测试时RL-VLA通过轻量级更新在部署过程中调整行为,解决了在现实场景中对整个模型进行微调成本高昂的问题。
关键适应机制:
- 价值引导:使用预训练的价值函数来影响动作选择
- 记忆缓冲区引导:在推理过程中检索相关的历史经验
- 规划引导的适应:对未来动作序列进行显式推理
📚 论文集
图例
- 动作:AR(自回归)、扩散、流(流匹配)
- 奖励:D(密集奖励)、S(稀疏奖励)
- 模型类型:MB(基于模型)、MF(无模型)
- 环境:Sim.(仿真)、Real(真实)
离线RL-VLA
| 方法 | 日期 | 出版物 | 仿真 | 真实 | 基础VLA模型 | 动作 | bel | 算法 | 类型 | 项目 |
|---|---|---|---|---|---|---|---|---|---|---|
| Q-Transformer | 2023年10月 | CoRL23🔗 | ✓ | ✗ | Transformer | AR | S | CQL | MF | 🔗 |
| PAC | 2024年2月 | ICML24🔗 | ✓ | ✓ | Perceiver-Actor-Critic | AR | S | AC | MF | 🔗 |
| GeRM | 2024年3月 | IROS24🔗 | ✓ | ✗ | Transformer-MoE | AR | S | CQL | MF | 🔗 |
| MoRE | 2025年3月 | ICRA25🔗 | ✗ | ✓ | MLLM-MoE | AR | S | CQL | MF | - |
| ReinboT | 2025年5月 | ICML25研讨会🔗 | ✓ | ✓ | ReinboT | AR | D | DT + RTG | MF | 🔗 |
| CO-RFT | 2025年8月 | - | ✗ | ✓ | RoboVLMs | AR | D | Cal-QL + TD3 | MF | - |
| ARFM | 2025年9月 | AAAI26🔗 | ✓ | ✓ | π₀ | Flow | D | ARFM | MF | - |
| $π^*_{0.6}$ | 2025年11月 | - | ✗ | ✓ | $π_{0.6}$ | Flow | D | RECAP | MF | 🔗 |
| NORA-1.5 | 2025年11月 | - | ✓ | ✓ | NORA-1.5 | AR / Flow | D | DPO | MB | 🔗 |
在线RL-VLA
| 方法 | 日期 | 发表期刊/会议 | 模拟 | 实际 | 基础VLA模型 | 行动模式 | 奖励函数 | 算法 | 类型 | 项目 |
|---|---|---|---|---|---|---|---|---|---|---|
| FLaRe | 2024.09 | ICRA25🔗 | ✓ | ✓ | SPOC | AR | S | PPO | MF | 🔗 |
| PA-RL | 2024.12 | ICLR25 Workshop🔗 | ✓ | ✓ | OpenVLA | AR | S | PA-RL | MF | 🔗 |
| RLDG | 2024.12 | RSS25🔗 | ✗ | ✓ | OpenVLA / Octo | AR / Diffusion | S | RLPD | MF | 🔗 |
| iRe-VLA | 2025.01 | ICRA25🔗 | ✓ | ✓ | iRe-VLA | AR | S | SACfD + SFT | MF | - |
| GRAPE | 2025.02 | ICRA25 Poster🔗 | ✓ | ✓ | OpenVLA | AR | D | TPO | MF | 🔗 |
| SafeVLA | 2025.03 | NeurIPS25 Poster🔗 | ✓ | ✗ | SPOC | AR | S | PPO | MF | 🔗 |
| RIPT-VLA | 2025.05 | - | ✓ | ✗ | QueST / OpenVLA-OFT | AR | S | LOOP | MF | 🔗 |
| VLA-RL | 2025.05 | - | ✓ | ✗ | OpenVLA | AR | D | PPO | MF | 🔗 |
| RLVLA | 2025.05 | NeurIPS25 Poster🔗 | ✓ | ✗ | OpenVLA | AR | S | PPO / GRPO / DPO | MF | 🔗 |
| RFTF | 2025.05 | - | ✓ | ✗ | GR-MG, Seer | AR | D | PPO | MF | - |
| TGRPO | 2025.06 | - | ✓ | ✗ | OpenVLA | AR | D | GRPO | MF | - |
| RLRC | 2025.06 | - | ✓ | ✗ | OpenVLA | AR | S | PPO | MF | 🔗 |
| ThinkAct | 2025.07 | NeurIPS25 Poster🔗 | ✓ | ✗ | MLLM + DiT | AR / Diffusion | D | GRPO (System 2) | MF | 🔗 |
| SimpleVLA-RL | 2025.09 | ICLR26 Poster🔗 | ✓ | ✓ | OpenVLA-OFT | AR | S | GRPO | MF | 🔗 |
| Dual-Actor FT | 2025.09 | IROS25 Workshop Extended Abstract🔗 | ✓ | ✓ | Octo / SmolVLA | Diffusion | S | QL + BC | MF | 🔗 |
| Generalist | 2025.09 | NeurIPS25 Poster🔗 | ✓ | ✓ | PaLI 3B | AR | D | REINFORCE | MF | 🔗 |
| VLAC | 2025.09 | - | ✗ | ✓ | VLAC | AR | D | PPO | MF | 🔗 |
| Robo-Dopamine | 2025.12 | CVPR26🔗 | ✓ | ✓ | Pi0.5 | Flow | D | PPO | MF | 🔗 |
| AC PPO | 2025.09 | - | ✓ | ✗ | Octo-small | AR | S | PPO+BC | MF | - |
| VLA-RFT | 2025.10 | - | ✓ | ✗ | VLA-Adapter | Flow | D | GRPO | MB | 🔗 |
| RLinf-VLA | 2025.10 | - | ✓ | ✓ | OpenVLA / OpenVLA-OFT | AR | S | PPO / GRPO | MF | 🔗 |
| FPO | 2025.10 | - | ✓ | ✗ | π₀ | Flow | S | FPO | MF | - |
| ReSA | 2025.10 | - | ✓ | ✗ | OpenVLA | AR | D | PPO + SFT | MF | - |
| π_RL | 2025.10 | - | ✓ | ✗ | π₀ / π₀.₅ | Flow | S | PPO / GRPO | MF | 🔗 |
| PLD | 2025.10 | ICLR26 Poster🔗 | ✓ | ✓ | OpenVLA / π₀ / Octo | AR / Flow | S | Cal-QL + SAC | MF | 🔗 |
| DeepThinkVLA | 2025.10 | - | ✓ | ✗ | π₀-Fast | AR | S | GRPO | MF | 🔗 |
| World-Env | 2025.11 | - | ✓ | ✓ | OpenVLA-OFT | AR | D | PPO | MB | 🔗 |
| RobustVLA | 2025.11 | - | ✓ | ✗ | OpenVLA-OFT | AR | D | PPO | MF | - |
| WMPO | 2025.11 | ICLR26 Poster🔗 | ✓ | ✓ | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| ProphRL | 2025.11 | - | ✓ | ✓ | VLA-Adapter / π0.5 / OpenVLA-OFT(流行动) | Flow | S | FA-GRPO | MB | 🔗 |
| EVOLVE-VLA | 2025.12 | - | ✓ | ✗ | OpenVLA-OFT | AR | D | GRPO | MB(VLAC) | 🔗 |
| SOP | 2026.1 | - | ✗ | ✓ | π0.5 | Flow | S | HG-DAgger / RECAP | MF | 🔗 |
| Green-VLA | 2026.1 | - | ✓ | ✓ | Green-VLA | Flow | S | IQL + actor-critic | MF | 🔗 |
| SA-VLA | 2026.1 | - | ✓ | ✗ | π0.5 | Flow | D | PPO | MF | 🔗 |
| World-Gymnast | 2026.2 | ICLR26 Workshop🔗 | ✓ | ✓ | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| RL-VLA3 | 2026.2 | ICLR26 Workshop🔗 | ✓ | ✓ | π0 / π0.5 / GR00T N1.5 / OpenVLA-OFT | Flow / AR | S | - | MF | — |
| World-VLA-Loop | 2026.2 | - | ✓ | ✓ | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| RISE | 2026.2 | - | ✗ | ✓ | π0.5 | Flow | D | RISE | MB | 🔗 |
| WoVR | 2026.2 | - | ✓ | ✓ | OpenVLA-OFT | AR | S | GRPO | MB | 🔗 |
| ALOE | 2026.2 | - | ✗ | ✓ | π₀.₅ | Flow | S | AWR(优势加权回归) | MF | 🔗 |
| TwinRL-VLA | 2026.2 | - | ✗ | ✓ | Octo | Diffusion | S | Actor-Critic | MF | — |
| RL-Co | 2026.3 | - | ✓ | ✓ | OpenVLA / π0.5 | AR / Flow | D | ReinFlow / GRPO | MF | — |
| π_StepNFT | 2026.3 | - | ✓ | ✗ | π₀ / π₀.₅ | Flow | S | NFT | MF | 🔗 |
| ROBOMETER | 2026.3 | - | ✗ | ✓ | π₀ | Flow | D | DSRL | MF | 🔗 |
| AtomVLA | 2026.3 | - | ✓ | ✓ | AtomVLA | Flow | D | GRPO | MB | — |
| NS-VLA | 2026.3 | - | ✓ | ✗ | NS-VLA | AR | D | GRPO | MF | 🔗 |
离线 + 在线 RL-VLA
| 方法 | 日期 | 出版物 | 模拟 | 真实 | 基础 VLA 模型 | 动作 | 奖励 | 算法 | 类型 | 项目 |
|---|---|---|---|---|---|---|---|---|---|---|
| ConRFT | 2025.4 | RSS26🔗 | ✗ | ✓ | Octo-small | 扩散 | S | Cal-QL + BC | MF | 🔗 |
| DiffusionRL-VLA | 2025.9 | - | ✓ | ✗ | π₀ | 流 | S | PPO(DP) + BC(VLA) | MF | - |
| SRPO | 2025.11 | - | ✓ | ✓ | OpenVLA* / π₀ / π₀-Fast | AR / 流 | D | SRPO | MF (MB-奖励但MF-RL) | 🔗 |
| DLR | 2025.11 | - | ✓ | ✗ | π₀ / OpenVLA | 流 / AR | S | PPO(MLP) + SFT(VLA) | MF | - |
| GR-RL | 2025.12 | - | ✗ | ✓ | GR-3 | 流 | S | TD3 / DSRL | MF | 🔗 |
| STARE-VLA | 2025.12 | - | ✓ | ✗ | OpenVLA / π₀.₅ | AR / 流 | D | PPO / TPO / SFT | MF | 🔗 |
| IG-RFT | 2026.2 | - | ✗ | ✓ | π₀.₅ | 流 | D | IG-AWR | MF | — |
测试时 RL-VLA
| 方法 | 日期 | 出版物 | 模拟 | 真实 | 基础 VLA 模型 | 动作 | 奖励 | 算法 | 类型 | 项目 |
|---|---|---|---|---|---|---|---|---|---|---|
| V-GPS | 2024.10 | CoRL25🔗 | ✓ | ✓ | Octo / RT-1 / OpenVLA | AR / 扩散 | D | Cal-QL | MF | 🔗 |
| Hume | 2025.6 | - | ✓ | ✓ | Hume | 流 | S | 值引导 | MF | 🔗 |
| VLA-Reasoner | 2025.9 | ICRA26🔗 | ✓ | ✓ | OpenVLA / SpatialVLA / π₀-Fast | AR / 扩散 | D | MCTS | MB | 🔗 |
| VLAPS | 2025.11 | CoRL25 Workshop🔗 | ✓ | ✗ | Octo | 扩散 | S | MCTS | MB | 🔗 |
| VLA-Pilot | 2025.11 | - | ✗ | ✓ | DiVLA / RDT | AR / 扩散 | D | 值导向T | MB(MLLM) | 🔗 |
| TACO | 2025.12 | - | ✓ | ✓ | π₀ / OpenVLA 等。 | 流 | S | CNF估计 | MF | 🔗 |
| TT-VLA | 2026.1 | - | ✓ | ✓ | Nora / OpenVLA / TraceVLA | AR | D | PPO(无价值) | MF | - |
| VLS | 2026.2 | - | ✓ | ✓ | OpenVLA / π₀ / π₀.₅ | 流 | D | 基于梯度的转向 | MB(VLM) | 🔗 |
注: 项目列中的 🔗 符号表示有可用项目页面、GitHub仓库或演示网站的论文。
🔗 有用资源
🎯 RL-VLA 动作优化
不同的 VLA 架构根据其动作生成机制,需要采用不同的 RL 优化策略:
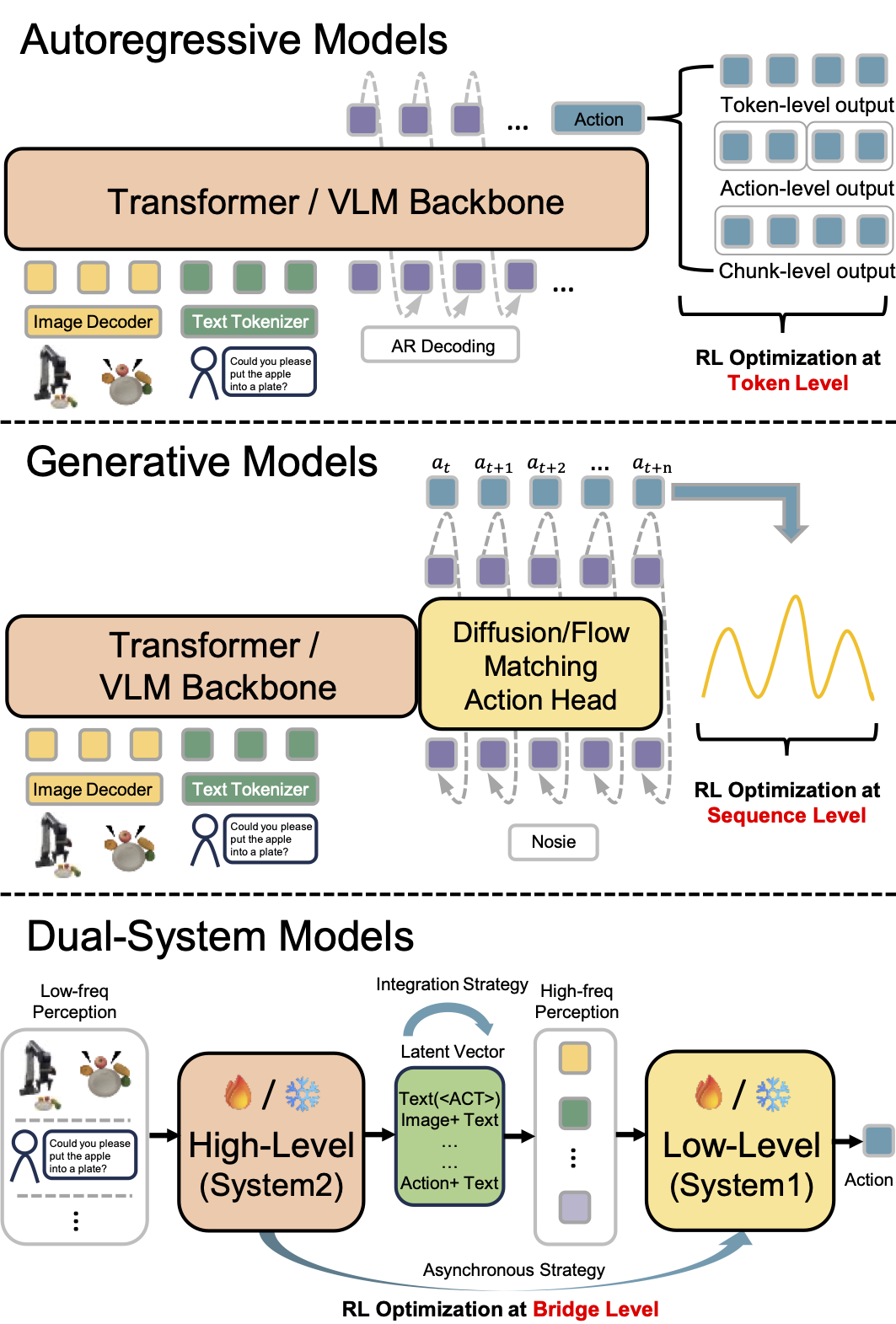
|
|
基础 VLA 模型
数据集与基准测试
- Open X-Embodiment - 大规模机器人数据集
- LIBERO - 长期机器人学习的基准测试
- SimplerEnv - 真实-模拟机器人学习的基准测试
- RoboTwin - 双臂机器人学习的基准测试
- DeepPHY - 物理推理的基准测试
框架与工具
🤝 贡献
我们欢迎对此优秀列表的贡献!请随时:
- 添加新论文: 提交遵循现有格式的新RL-VLA论文PR
- 更新信息: 更正任何错误或更新论文信息
- 提出改进建议: 提出更好的组织方式或新增章节
贡献指南
- 确保论文与RL-VLA研究相关
- 包括论文链接、项目页面(如有)以及关键细节
- 遵循现有表格格式以保持一致性
- 为新范式或重大方法论贡献添加简短描述
📄 引用
如果您觉得本仓库有用,请考虑引用:
@article{pine2025rlvla,
title={A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Manipulation},
author={Haoyuan Deng, Zhenyu Wu, Haichao Liu, Wenkai Guo, Yuquan Xue, Ziyu Shan, Chuanrui Zhang, Bofang Jia, Yuan Ling, Guanxing Lu, and Ziwei Wang},
journal={TechRxiv},
year={2025},
doi={10.36227/techrxiv.176531955.54563920/v1},
note={预印本}
}
⭐ 星标历史
如果您觉得本仓库有帮助,请星标它!

版本历史
v0.1.02025/11/25常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。
PaddleOCR
PaddleOCR 是一款基于百度飞桨框架开发的高性能开源光学字符识别工具包。它的核心能力是将图片、PDF 等文档中的文字提取出来,转换成计算机可读取的结构化数据,让机器真正“看懂”图文内容。 面对海量纸质或电子文档,PaddleOCR 解决了人工录入效率低、数字化成本高的问题。尤其在人工智能领域,它扮演着连接图像与大型语言模型(LLM)的桥梁角色,能将视觉信息直接转化为文本输入,助力智能问答、文档分析等应用场景落地。 PaddleOCR 适合开发者、算法研究人员以及有文档自动化需求的普通用户。其技术优势十分明显:不仅支持全球 100 多种语言的识别,还能在 Windows、Linux、macOS 等多个系统上运行,并灵活适配 CPU、GPU、NPU 等各类硬件。作为一个轻量级且社区活跃的开源项目,PaddleOCR 既能满足快速集成的需求,也能支撑前沿的视觉语言研究,是处理文字识别任务的理想选择。
awesome-machine-learning
awesome-machine-learning 是一份精心整理的机器学习资源清单,汇集了全球优秀的机器学习框架、库和软件工具。面对机器学习领域技术迭代快、资源分散且难以甄选的痛点,这份清单按编程语言(如 Python、C++、Go 等)和应用场景(如计算机视觉、自然语言处理、深度学习等)进行了系统化分类,帮助使用者快速定位高质量项目。 它特别适合开发者、数据科学家及研究人员使用。无论是初学者寻找入门库,还是资深工程师对比不同语言的技术选型,都能从中获得极具价值的参考。此外,清单还延伸提供了免费书籍、在线课程、行业会议、技术博客及线下聚会等丰富资源,构建了从学习到实践的全链路支持体系。 其独特亮点在于严格的维护标准:明确标记已停止维护或长期未更新的项目,确保推荐内容的时效性与可靠性。作为机器学习领域的“导航图”,awesome-machine-learning 以开源协作的方式持续更新,旨在降低技术探索门槛,让每一位从业者都能高效地站在巨人的肩膀上创新。
scikit-learn
scikit-learn 是一个基于 Python 构建的开源机器学习库,依托于 SciPy、NumPy 等科学计算生态,旨在让机器学习变得简单高效。它提供了一套统一且简洁的接口,涵盖了从数据预处理、特征工程到模型训练、评估及选择的全流程工具,内置了包括线性回归、支持向量机、随机森林、聚类等在内的丰富经典算法。 对于希望快速验证想法或构建原型的数据科学家、研究人员以及 Python 开发者而言,scikit-learn 是不可或缺的基础设施。它有效解决了机器学习入门门槛高、算法实现复杂以及不同模型间调用方式不统一的痛点,让用户无需重复造轮子,只需几行代码即可调用成熟的算法解决分类、回归、聚类等实际问题。 其核心技术亮点在于高度一致的 API 设计风格,所有估算器(Estimator)均遵循相同的调用逻辑,极大地降低了学习成本并提升了代码的可读性与可维护性。此外,它还提供了强大的模型选择与评估工具,如交叉验证和网格搜索,帮助用户系统地优化模型性能。作为一个由全球志愿者共同维护的成熟项目,scikit-learn 以其稳定性、详尽的文档和活跃的社区支持,成为连接理论学习与工业级应用的最
keras
Keras 是一个专为人类设计的深度学习框架,旨在让构建和训练神经网络变得简单直观。它解决了开发者在不同深度学习后端之间切换困难、模型开发效率低以及难以兼顾调试便捷性与运行性能的痛点。 无论是刚入门的学生、专注算法的研究人员,还是需要快速落地产品的工程师,都能通过 Keras 轻松上手。它支持计算机视觉、自然语言处理、音频分析及时间序列预测等多种任务。 Keras 3 的核心亮点在于其独特的“多后端”架构。用户只需编写一套代码,即可灵活选择 TensorFlow、JAX、PyTorch 或 OpenVINO 作为底层运行引擎。这一特性不仅保留了 Keras 一贯的高层易用性,还允许开发者根据需求自由选择:利用 JAX 或 PyTorch 的即时执行模式进行高效调试,或切换至速度最快的后端以获得最高 350% 的性能提升。此外,Keras 具备强大的扩展能力,能无缝从本地笔记本电脑扩展至大规模 GPU 或 TPU 集群,是连接原型开发与生产部署的理想桥梁。