VideoLLaMA2
VideoLLaMA2 是一款由达摩院开源的多模态大语言模型,专为深度理解视频内容而设计。它不仅能“看懂”视频中的画面变化,还能“听懂”其中的声音信息,从而实现对视频时空动态与音频语义的综合分析。
传统视频分析模型往往难以同时处理复杂的画面运动轨迹和背景声音,导致在回答涉及时间顺序、动作因果或音画关联的问题时表现不佳。VideoLLaMA2 通过先进的时空建模技术和音频理解模块,有效解决了这一痛点,显著提升了在零样本视频问答、事件推理等任务上的准确率,并在多个权威评测基准中取得了领先成绩。
这款工具非常适合人工智能研究人员、多模态算法开发者以及希望构建智能视频分析应用的技术团队使用。无论是需要探索前沿视频理解理论的研究者,还是致力于开发视频摘要、智能监控或交互式教育产品的工程师,都能从中获益。其独特的技术亮点在于将视觉的空间特征、时间演变与音频信号深度融合,使模型能像人类一样综合视听线索来理解视频故事。项目采用 Apache 2.0 协议开源,提供了预训练模型、演示平台及详细文档,方便用户快速上手实验与二次开发。
使用场景
某电商平台的客服团队每天需处理大量用户上传的“产品使用反馈视频”,这些视频包含用户操作演示和口头抱怨,人工审核效率极低且容易遗漏关键细节。
没有 VideoLLaMA2 时
- 审核人员必须全程观看冗长视频,无法快速定位用户具体在哪个时间点指出了产品缺陷,耗时费力。
- 视频中的背景噪音或用户语速过快导致关键语音投诉(如“按钮没反应”)被忽略,仅靠画面无法理解完整意图。
- 难以区分是用户操作失误还是产品本身的空间结构问题(如接口位置设计不合理),导致误判责任归属。
- 面对海量视频数据,无法批量提取结构化报告,只能依靠人工逐条记录,严重拖慢产品迭代反馈周期。
使用 VideoLLaMA2 后
- VideoLLaMA2 能精准分析时空上下文,自动截取用户指出问题的关键片段,并生成带时间戳的文字摘要,审核效率提升数倍。
- 凭借强大的音频理解能力,它能准确转录并关联用户的语音抱怨与对应画面动作,确保“听得到”也“看得懂”每一条反馈。
- 模型可深入推理空间关系,智能判断是用户操作不当还是产品设计存在空间布局缺陷,提供客观的责任分析建议。
- 支持批量处理视频流,直接输出包含问题分类、严重程度及证据片段的结构化报表,无缝对接产品研发管理系统。
VideoLLaMA2 通过将复杂的视听信息转化为可执行的洞察,彻底重构了视频反馈的处理流程,让产品优化决策从“凭经验猜测”转向“数据驱动”。
运行环境要求
- 未说明
必需 NVIDIA GPU,CUDA 版本 >= 11.8,需支持 flash-attn (通常建议显存 16GB+ 以运行 7B 模型,72B 或 MoE 模型需要更高显存)
未说明

快速开始

VideoLLaMA 2:推进视频大模型中的时空建模与音频理解
如果我们的项目对您有所帮助,请在 GitHub 上给我们点个赞 ⭐,以支持我们。 🙏🙏
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
![]()
![]()
![]()
💡 您可能对我们团队的其他多模态大模型项目感兴趣 ✨。
VideoLLaMA 3:面向图像与视频理解的前沿多模态基础模型
Boqiang Zhang* , Kehan Li* , Zesen Cheng* , Zhiqiang Hu* , Yuqian Yuan* , Guanzheng Chen* , Sicong Leng* , Yuming Jiang* , Hang Zhang* , Xin Li* , Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao



Video-LLaMA:用于视频理解的指令微调音视频语言模型
Hang Zhang, Xin Li, Lidong Bing


VCD:通过视觉对比解码缓解大型视觉-语言模型中的对象幻觉问题
Sicong Leng* , Hang Zhang* , Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, Lidong Bing


多模态的诅咒:评估大型多模态模型在语言、视觉和音频方面的幻觉现象
Sicong Leng, Yun Xing, Zesen Cheng, Yang Zhou, Hang Zhang, Xin Li, Deli Zhao, Shijian Lu, Chunyan Miao, Lidong Bing


突破内存限制:近无限批量规模的对比损失
Zesen Cheng*, Hang Zhang*, Kehan Li*, Sicong Leng, Zhiqiang Hu, Fei Wu, Deli Zhao, Xin Li, Lidong Bing


📰 新闻
- [2025.01.21] 🚀🚀 我们很高兴地正式发布 VideoLLaMA3,它在图像和视频基准测试中性能全面提升,并附带多种易于操作的推理教程。立即试用吧!
- [2024.10.22] 发布 VideoLLaMA2.1-7B-AV 的检查点。音频视觉分支的代码可在此查看:https://github.com/DAMO-NLP-SG/VideoLLaMA2/tree/audio_visual。
- [2024.10.15] 发布 VideoLLaMA2.1-7B-16F-Base 和 VideoLLaMA2.1-7B-16F 的检查点。
- [2024.08.14] 发布 VideoLLaMA2-72B-Base 和 VideoLLaMA2-72B 的检查点。
- [2024.07.30] 发布 VideoLLaMA2-8x7B-Base 和 VideoLLaMA2-8x7B 的检查点。
- [2024.06.25] 🔥🔥 截至6月25日,我们的 VideoLLaMA2-7B-16F 在 MLVU排行榜 上是约70亿参数规模的视频大模型中的第一名。
- [2024.06.18] 🔥🔥 截至6月18日,我们的 VideoLLaMA2-7B-16F 在 VideoMME排行榜 上是约70亿参数规模的视频大模型中的第一名。
- [2024.06.17] 👋👋 更新技术报告,加入最新结果及遗漏的参考文献。如果您有与 VideoLLaMA 2 密切相关但未在论文中提及的工作,请随时告知我们。
- [2024.06.14] 🔥🔥 在线演示 已上线。
- [2024.06.03] 发布 VideoLLaMA 2 的训练、评估和推理代码。
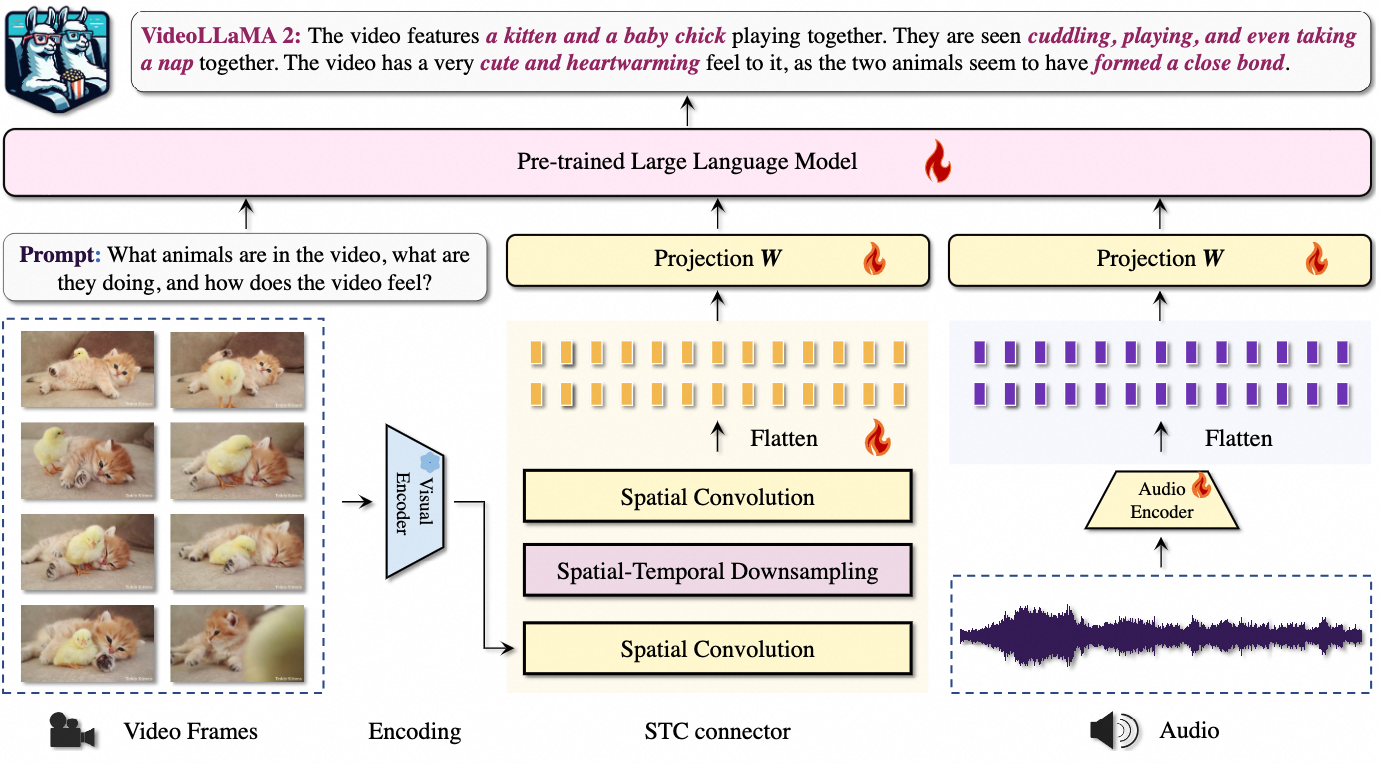
🛠️ 环境要求与安装
基础依赖:
- Python >= 3.8
- Pytorch >= 2.2.0
- CUDA 版本 >= 11.8
- transformers == 4.40.0(用于复现论文结果)
- tokenizers == 0.19.1
[在线模式] 安装所需包(更适合开发):
git clone https://github.com/DAMO-NLP-SG/VideoLLaMA2
cd VideoLLaMA2
pip install -r requirements.txt
pip install flash-attn==2.5.8 --no-build-isolation
[离线模式] 将 VideoLLaMA2 作为 Python 包安装(更适合直接使用):
git clone https://github.com/DAMO-NLP-SG/VideoLLaMA2
cd VideoLLaMA2
pip install --upgrade pip # 启用 PEP 660 支持
pip install -e .
pip install flash-attn==2.5.8 --no-build-isolation
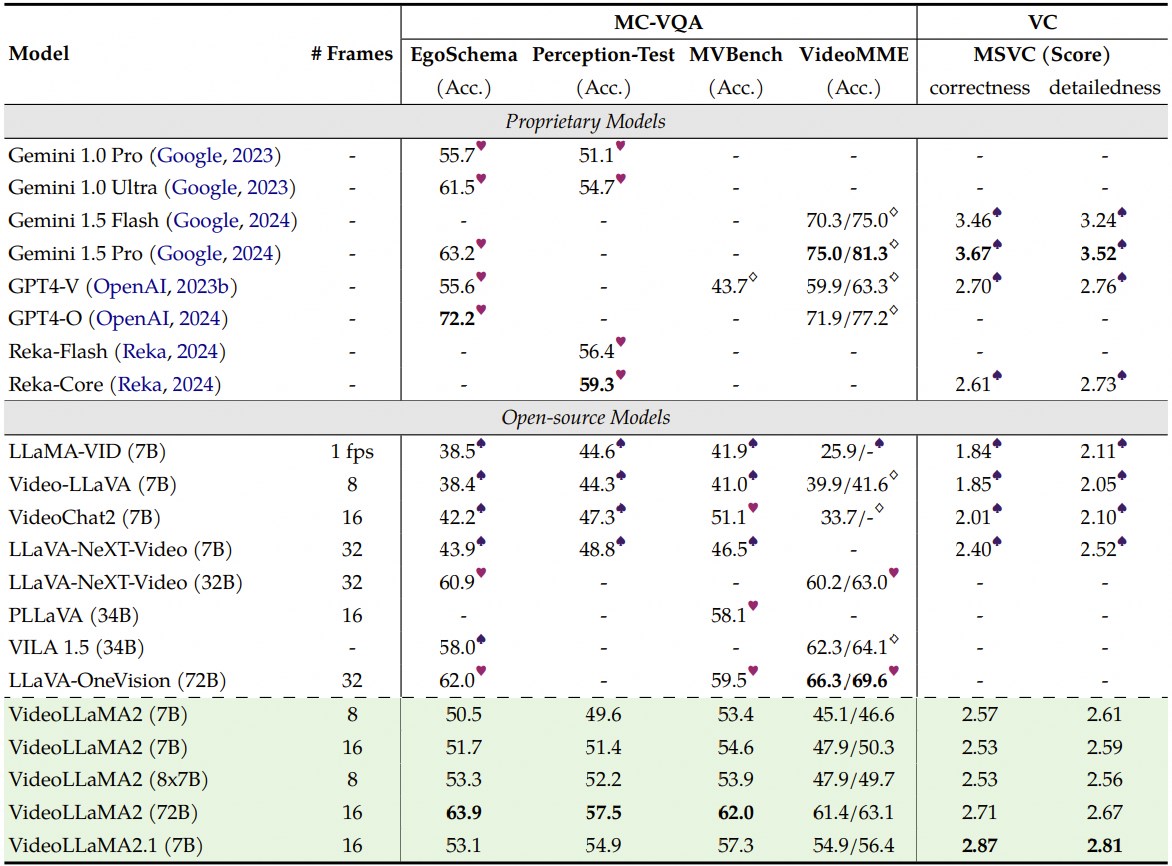
🚀 主要结果
多选题视频问答与视频字幕生成
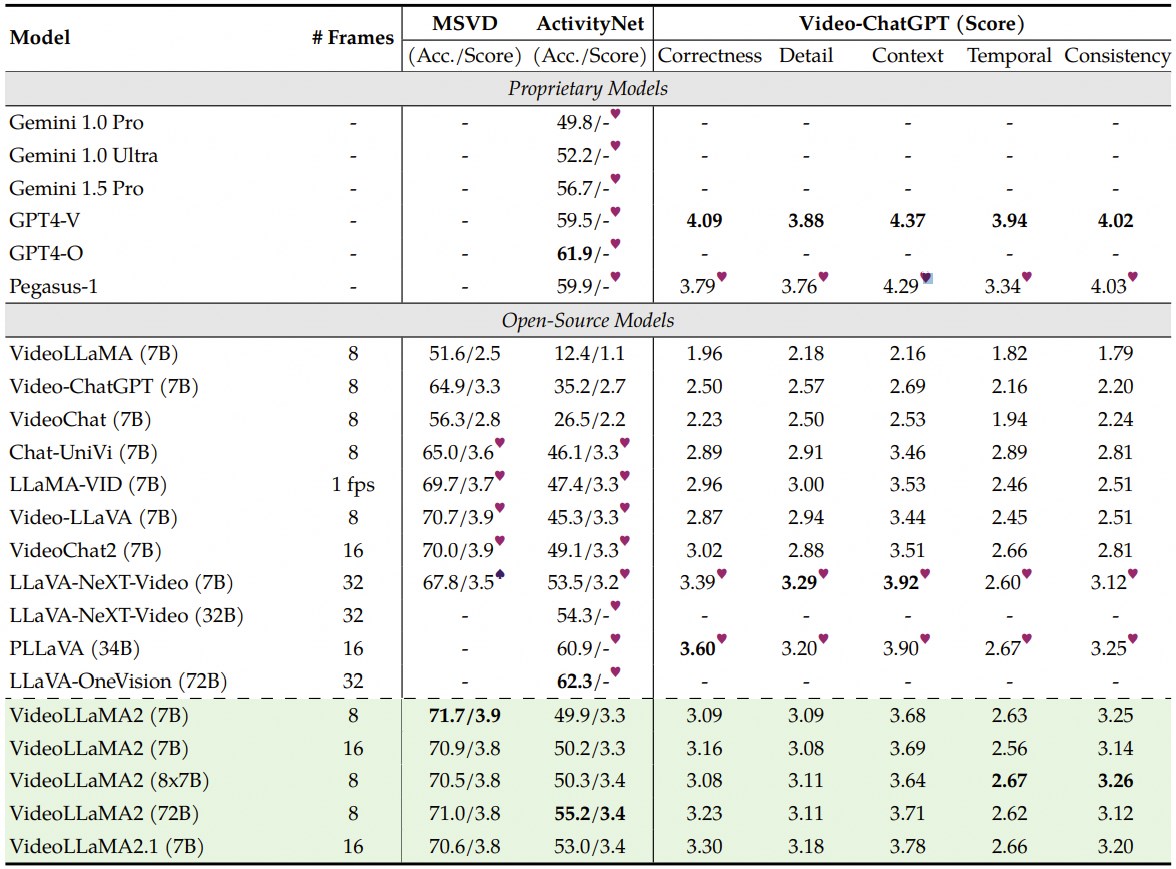
开放式视频问答
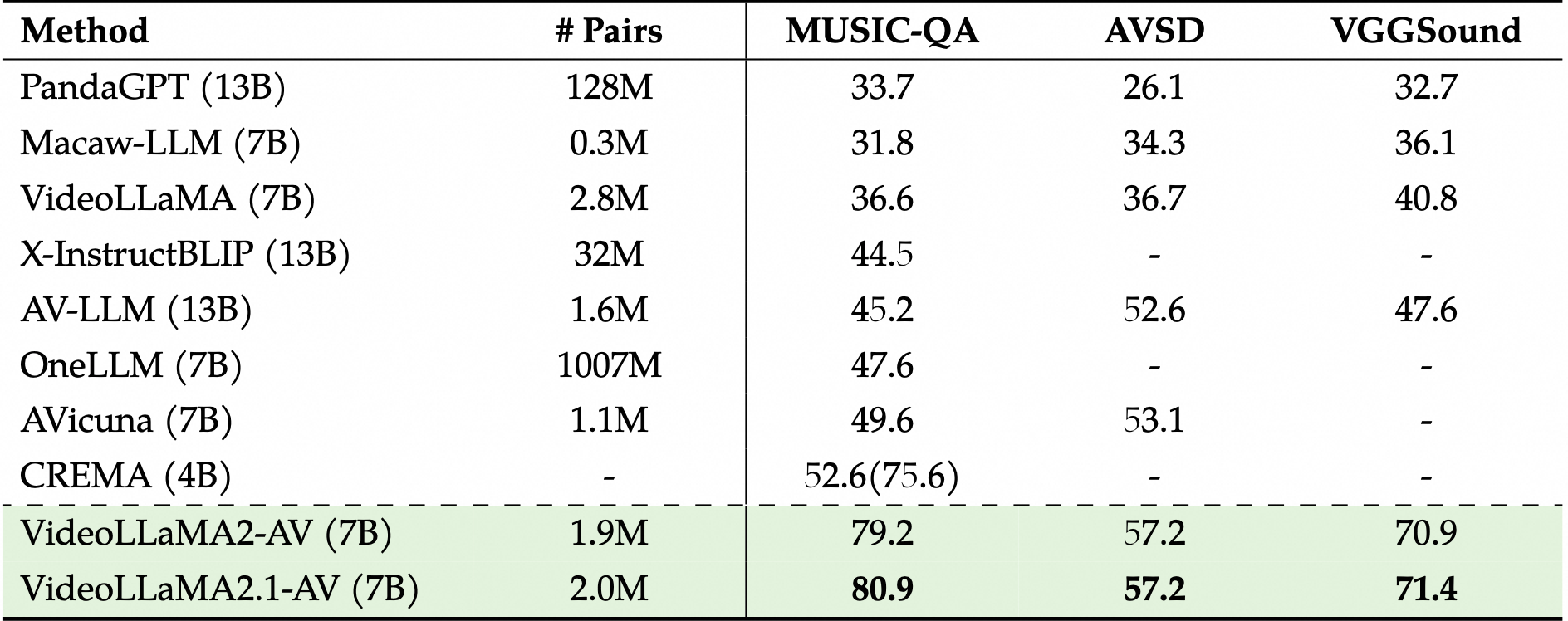
音频问答

音频-视觉问答
:earth_americas: 模型库
仅视觉检查点
音频-视觉检查点
| 模型名称 | 类型 | 音频编码器 | 语言解码器 |
|---|---|---|---|
| VideoLLaMA2.1-7B-AV | 对话版 | 微调后的 BEATs_iter3+(AS2M)(cpt2) | VideoLLaMA2.1-7B-16F |
🤗 演示
强烈建议您先尝试我们的在线演示。
要在您的设备上运行基于视频的大型语言模型(LLM)Web 演示,您首先需要确保已准备好必要的模型检查点,然后按照以下步骤操作,即可成功启动演示。
单模型版本
- 直接启动 Gradio 应用程序(默认采用 VideoLLaMA2-7B):
python videollama2/serve/gradio_web_server_adhoc.py
多模型版本
- 启动全局控制器
cd /path/to/VideoLLaMA2
python -m videollama2.serve.controller --host 0.0.0.0 --port 10000
- 启动 Gradio Web 服务器
python -m videollama2.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
- 启动一个或多个模型工作节点
# export HF_ENDPOINT=https://hf-mirror.com # 如果无法访问 Hugging Face,请尝试取消注释此行。
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path /PATH/TO/MODEL1
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40001 --worker http://localhost:40001 --model-path /PATH/TO/MODEL2
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40002 --worker http://localhost:40002 --model-path /PATH/TO/MODEL3
...
🗝️ 训练与评估
快速入门
为了便于在我们的代码库基础上进行进一步开发,我们提供了一份快速入门指南,介绍如何使用 VideoLLaVA 数据集训练自定义的 VideoLLaMA2,并在主流视频 LLM 基准测试上评估训练好的模型。
- 训练数据结构:
VideoLLaMA2
├── datasets
│ ├── videollava_pt
| | ├── llava_image/ # 可通过以下链接获取:https://pan.baidu.com/s/17GYcE69FcJjjUM0e4Gad2w?pwd=9ga3 或 https://drive.google.com/drive/folders/1QmFj2FcMAoWNCUyiUtdcW0-IOhLbOBcf?usp=drive_link
| | ├── valley/ # 可通过以下链接获取:https://pan.baidu.com/s/1jluOimE7mmihEBfnpwwCew?pwd=jyjz 或 https://drive.google.com/drive/folders/1QmFj2FcMAoWNCUyiUtdcW0-IOhLbOBcf?usp=drive_link
| | └── valley_llavaimage.json # 可通过以下链接获取:https://drive.google.com/file/d/1zGRyVSUMoczGq6cjQFmT0prH67bu2wXD/view,包含 703K 个视频-文本对和 558K 个图像-文本对
│ ├── videollava_sft
| | ├── llava_image_tune/ # 可通过以下链接获取:https://pan.baidu.com/s/1l-jT6t_DlN5DTklwArsqGw?pwd=o6ko
| | ├── videochatgpt_tune/ # 可通过以下链接获取:https://pan.baidu.com/s/10hJ_U7wVmYTUo75YHc_n8g?pwd=g1hf
| | └── videochatgpt_llavaimage_tune.json # 可通过以下链接获取:https://drive.google.com/file/d/1zGRyVSUMoczGq6cjQFmT0prH67bu2wXD/view,包含 100K 个以视频为中心、625K 个以图像为中心以及 40K 个纯文本对话
- 命令:
# VideoLLaMA2-vllava 预训练
bash scripts/vllava/pretrain.sh
# VideoLLaMA2-vllava 微调
bash scripts/vllava/finetune.sh
- 评估数据结构:
VideoLLaMA2
├── eval
│ ├── egoschema # 官方网站:https://github.com/egoschema/EgoSchema
| | ├── good_clips_git/ # 可通过以下链接获取:https://drive.google.com/drive/folders/1SS0VVz8rML1e5gWq7D7VtP1oxE2UtmhQ
| | └── questions.json # 可通过以下链接获取:https://github.com/egoschema/EgoSchema/blob/main/questions.json
│ ├── mvbench # 官方网站:https://huggingface.co/datasets/OpenGVLab/MVBench
| | ├── video/
| | | ├── clever/
| | | └── ...
| | └── json/
| | | ├── action_antonym.json
| | | └── ...
│ ├── perception_test_mcqa # 官方网站:https://huggingface.co/datasets/OpenGVLab/MVBench
| | ├── videos/ # 可通过以下链接获取:https://storage.googleapis.com/dm-perception-test/zip_data/test_videos.zip
| | └── mc_question_test.json # 可从以下链接下载:https://storage.googleapis.com/dm-perception-test/zip_data/mc_question_test_annotations.zip
│ ├── videomme # 官方网站:https://video-mme.github.io/home_page.html#leaderboard
| | ├── test-00000-of-00001.parquet
| | ├── videos/
| | └── subtitles/
│ ├── Activitynet_Zero_Shot_QA # 官方网站:https://github.com/MILVLG/activitynet-qa
| | ├── all_test/ # 可通过以下链接获取:https://mbzuaiac-my.sharepoint.com/:u:/g/personal/hanoona_bangalath_mbzuai_ac_ae/EatOpE7j68tLm2XAd0u6b8ABGGdVAwLMN6rqlDGM_DwhVA?e=90WIuW
| | ├── test_q.json # 可通过以下链接获取:https://github.com/MILVLG/activitynet-qa/tree/master/dataset
| | └── test_a.json # 可通过以下链接获取:https://github.com/MILVLG/activitynet-qa/tree/master/dataset
│ ├── MSVD_Zero_Shot_QA # 官方网站:https://github.com/xudejing/video-question-answering
| | ├── videos/
| | ├── test_q.json
| | └── test_a.json
│ ├── videochatgpt_gen # 官方网站:https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/quantitative_evaluation
| | ├── Test_Videos/ # 可通过以下链接获取:https://mbzuaiac-my.sharepoint.com/:u:/g/personal/hanoona_bangalath_mbzuai_ac_ae/EatOpE7j68tLm2XAd0u6b8ABGGdVAwLMN6rqlDGM_DwhVA?e=90WIuW
| | ├── Test_Human_Annotated_Captions/ # 可通过以下链接获取:https://mbzuaiac-my.sharepoint.com/personal/hanoona_bangalath_mbzuai_ac_ae/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking%2FTest%5FHuman%5FAnnotated%5FCaptions%2Ezip&parent=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking&ga=1
| | ├── generic_qa.json # 这三份 JSON 文件可通过以下链接获取:https://mbzuaiac-my.sharepoint.com/personal/hanoona_bangalath_mbzuai_ac_ae/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking%2FBenchmarking%5FQA&ga=1
| | ├── temporal_qa.json
| | └── consistency_qa.json
- 命令:
# MVBench 评估
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/eval/eval_video_qa_mvbench.sh
# Activitynet-qa 评估(需设置 Azure OpenAI 的密钥/端点/部署名称)
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/eval/eval_video_qa_mvbench.sh
数据格式
如果您想使用自己的数据训练视频-LLM,需要按照以下步骤准备视频/图像的SFT数据:
- 假设您的数据结构如下:
VideoLLaMA2
├── datasets
│ ├── custom_sft
│ | ├── images
│ | ├── videos
| | └── custom.json
- 然后您需要按照以下格式重新组织标注好的视频/图像SFT数据:
[
{
"id": 0,
"video": "images/xxx.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\n图片中的公交车是什么颜色?"
},
{
"from": "gpt",
"value": "图片中的公交车是白色和红色的。"
},
...
],
}
{
"id": 1,
"video": "videos/xxx.mp4",
"conversations": [
{
"from": "human",
"value": "<video>\n视频中主要发生了哪些活动?"
},
{
"from": "gpt",
"value": "视频中主要发生的活动包括一名男子在准备摄像设备、一群男子乘坐直升机,以及一名男子划船穿越水面。"
},
...
],
},
...
]
- 修改
scripts/custom/finetune.sh:
...
--data_path datasets/custom_sft/custom.json
--data_folder datasets/custom_sft/
--pretrain_mm_mlp_adapter CONNECTOR_DOWNLOAD_PATH (例如:DAMO-NLP-SG/VideoLLaMA2.1-7B-16F-Base)
...
🤖 推理
视频/图像推理:
import sys
sys.path.append('./')
from videollama2 import model_init, mm_infer
from videollama2.utils import disable_torch_init
def inference():
disable_torch_init()
# 视频推理
modal = 'video'
modal_path = 'assets/cat_and_chicken.mp4'
instruct = '视频里有哪些动物?它们在做什么?这段视频给人什么感觉?'
# 回答:
# 视频中有一只小猫和一只小鸡在一起玩耍。小猫躺在地板上,而小鸡则蹦蹦跳跳地四处走动。两只动物之间互动得很有趣,整段视频给人一种可爱又温馨的感觉。
# 图像推理
modal = 'image'
modal_path = 'assets/sora.png'
instruct = '图中的女士穿了什么?她在做什么?这张图片给人什么感觉?'
# 回答:
# 图中女士身穿黑色外套和太阳镜,正走在被雨水浸湿的城市街道上。画面充满活力与生机,明亮的城市灯光映照在湿漉漉的路面上,营造出一种极具视觉吸引力的氛围。女士的存在为这幅场景增添了时尚与自信的气息,她从容地穿梭于繁忙的都市环境中。
model_path = 'DAMO-NLP-SG/VideoLLaMA2.1-7B-16F'
# 基础模型推理(只需替换model_path)
# model_path = 'DAMO-NLP-SG/VideoLLaMA2.1-7B-16F-Base'
model, processor, tokenizer = model_init(model_path)
output = mm_infer(processor[modal](modal_path), instruct, model=model, tokenizer=tokenizer, do_sample=False, modal=modal)
print(output)
if __name__ == "__main__":
inference()
📑 引用
如果您在研究和应用中使用了VideoLLaMA,请使用以下BibTeX格式引用:
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: 在视频-LLM中推进时空建模和音频理解},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv预印本 arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA:用于视频理解的指令微调视听语言模型},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv预印本 arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}
👍 致谢
VideoLLaMA 2的代码库改编自LLaVA 1.5和FastChat。我们还要感谢以下项目,正是它们促成了VideoLLaMA 2的诞生:
- LLaMA 2、Mistral-7B、OpenAI CLIP、Qwen2、SigLIP、Honeybee。
- Video-ChatGPT、Video-LLaVA。
- WebVid、Panda-70M、LanguageBind、InternVid。
- VideoChat2、Valley、VTimeLLM、ShareGPT4V。
- Magpie、ALLaVA、AVInstruct。
🔒 许可证
本项目采用Apache 2.0许可证发布,具体见LICENSE文件。该服务为研究预览版,仅限非商业用途,同时需遵守LLaMA和Mistral的模型许可、OpenAI生成数据的使用条款以及ShareGPT的隐私政策。如发现任何潜在违规行为,请及时与我们联系。
常见问题
相似工具推荐
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
funNLP
funNLP 是一个专为中文自然语言处理(NLP)打造的超级资源库,被誉为"NLP 民工的乐园”。它并非单一的软件工具,而是一个汇集了海量开源项目、数据集、预训练模型和实用代码的综合性平台。 面对中文 NLP 领域资源分散、入门门槛高以及特定场景数据匮乏的痛点,funNLP 提供了“一站式”解决方案。这里不仅涵盖了分词、命名实体识别、情感分析、文本摘要等基础任务的标准工具,还独特地收录了丰富的垂直领域资源,如法律、医疗、金融行业的专用词库与数据集,甚至包含古诗词生成、歌词创作等趣味应用。其核心亮点在于极高的全面性与实用性,从基础的字典词典到前沿的 BERT、GPT-2 模型代码,再到高质量的标注数据和竞赛方案,应有尽有。 无论是刚刚踏入 NLP 领域的学生、需要快速验证想法的算法工程师,还是从事人工智能研究的学者,都能在这里找到急需的“武器弹药”。对于开发者而言,它能大幅减少寻找数据和复现模型的时间;对于研究者,它提供了丰富的基准测试资源和前沿技术参考。funNLP 以开放共享的精神,极大地降低了中文自然语言处理的开发与研究成本,是中文 AI 社区不可或缺的宝藏仓库。