Whisper
Whisper 是一款专为 Windows 系统打造的高性能语音识别工具,能够将音频文件实时转换为文字,甚至支持麦克风直播录音的即时转录与翻译。它源自 OpenAI 的 Whisper 模型,经过 C++ 重构与显卡加速优化,显著解决了原版在 Windows 上依赖庞大、运行速度慢的问题。
相比官方实现,Whisper 无需安装复杂的 Python 环境或数 GB 的运行时库,仅需一个极小的动态库即可运行。其核心亮点在于利用 DirectCompute 技术调用显卡(GPGPU)进行并行计算,在普通 GeForce 显卡上即可实现比 CPU 快数倍的转录速度,同时大幅降低内存占用。此外,它还内置了语音活动检测功能,能自动过滤静音片段,并兼容绝大多数音视频格式。
这款工具非常适合需要在 Windows 本地高效处理语音数据的普通用户、内容创作者及开发者。对于普通用户,提供的桌面版程序界面友好,下载即用;对于开发者,它提供了简洁的 API 和 PowerShell 脚本支持,便于集成到各类应用中。只要你的电脑配备支持 Direct3D 11 的独立显卡(2011 年后主流硬件均符合),就能轻松体验流畅的离线语音转写服务。
使用场景
一位自由职业字幕组译者需要在 Windows 电脑上快速处理大量采访视频,将其转换为带时间轴的中文字幕文件。
没有 Whisper 时
- 环境配置繁琐:部署原版 OpenAI 模型需安装庞大的 Python 环境和 PyTorch 依赖包(约 9.6GB),极易出现版本冲突导致运行失败。
- 转录速度缓慢:在普通 GeForce 显卡上,一段 3 分钟的音频往往需要数分钟才能完成识别,严重拖慢交付进度。
- 实时处理困难:缺乏高效的本地实时语音捕获功能,无法在直播或会议进行中即时生成草稿字幕。
- 硬件资源浪费:难以充分利用 DirectCompute 技术,导致高性能 GPU 闲置,只能依赖低效的 CPU 运算。
使用 Whisper 后
- 开箱即用:直接运行预编译的 WhisperDesktop.exe,仅需下载一个模型文件即可启动,无需任何复杂的运行时依赖。
- 极速推理:利用 DirectCompute 加速,同一段 3 分钟音频的转录时间从数分钟缩短至 19 秒,效率提升显著。
- 实时语音捕获:内置语音活动检测(VAD)功能,可直接通过麦克风录制并实时转写,支持直播字幕生成。
- 轻量高效:核心库仅 400 多 KB,内存占用极低,能在老旧硬件上流畅运行,充分释放显卡算力。
Whisper 通过将复杂的 AI 模型转化为轻量级本地工具,让个人开发者也能在 Windows 上享受工业级的语音识别速度与便捷。
运行环境要求
- Windows
- 必需
- 需要支持 Direct3D 11.0 的 GPU(2011 年后的硬件显卡均支持)
- 针对 NVIDIA 1080Ti、AMD Radeon Vega (集成/独立) 进行了优化
- 不支持仅依赖 CUDA 的环境,而是使用 DirectCompute
未说明(文中提到低内存占用,但未给出具体数值)
快速开始
该项目是 whisper.cpp 实现的 Windows 移植版。
而 whisper.cpp 本身则是对 OpenAI 的 Whisper 自动语音识别(ASR)模型的 C++ 移植。
快速入门指南
从本仓库的“Releases”部分下载 WhisperDesktop.zip,解压 ZIP 文件后运行 WhisperDesktop.exe。
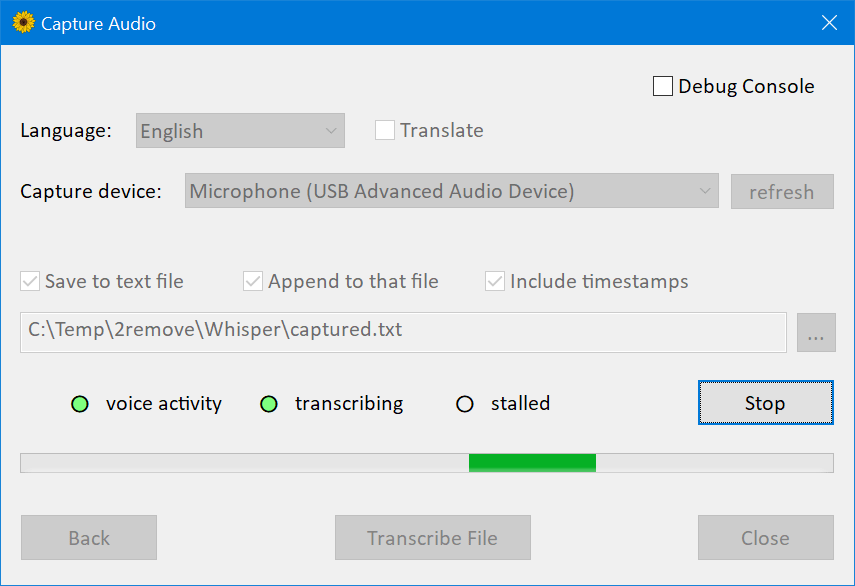
在第一个界面上,程序会提示您下载一个模型。
我推荐使用 ggml-medium.bin(大小为 1.42GB),因为我主要就是用这个模型测试过该软件。
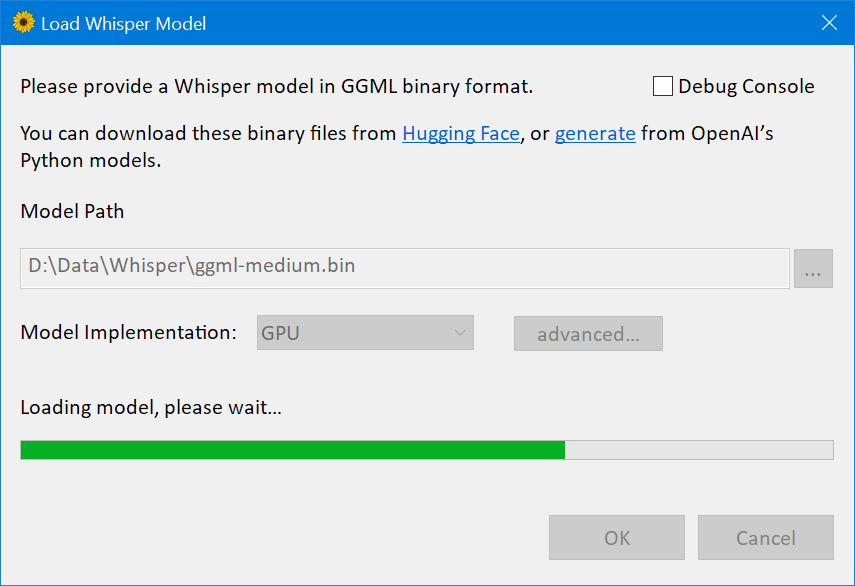
下一个界面允许您转录音频文件。
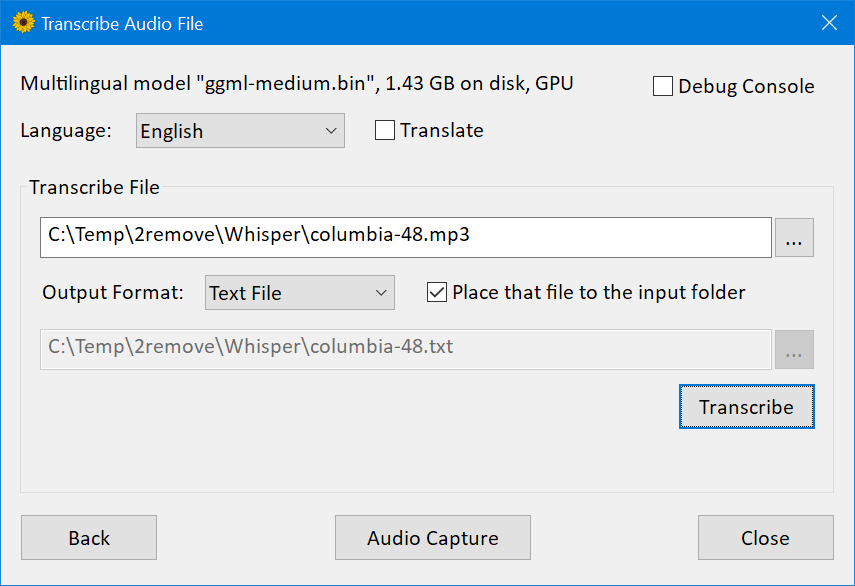
还有一个界面可以捕获并实时转录或翻译来自麦克风的音频。
功能特性
基于 DirectCompute 的厂商无关 GPGPU;该技术也被称为“Direct3D 11 中的计算着色器”。
纯 C++ 实现,除操作系统必备组件外无其他运行时依赖。
比 OpenAI 的原生实现快得多。
在我配备 GeForce 1080Ti 显卡的台式机上, 使用 medium 模型处理一段 3 分 24 秒的语音 时,PyTorch 结合 CUDA 需要 45 秒,而我的实现结合 DirectCompute 仅需 19 秒。
有趣的是:前者需要 9.63 GB 的运行时依赖,而后者仅需 431 KB 的Whisper.dll。混合 F16/F32 精度:Windows 要求支持 D3D 10.0 版本及更高版本中的
R16_FLOAT缓冲区。内置性能剖析器,可测量各个计算着色器的执行时间。
内存占用低。
使用 Media Foundation 处理音频,支持大多数音频和视频格式(Ogg Vorbis 是少数例外), 以及大多数可在 Windows 上使用的音频采集设备(某些专业设备除外,它们仅支持 ASIO API)。
音频采集中的语音活动检测。
该实现基于 Mohammad Moattar 和 Mahdi Homayoonpoor 于 2009 年发表的论文《一种简单但高效的实时语音活动检测算法》。易于使用的 COM 风格 API。C# 封装库已在 nuget 上发布:WhisperNet
版本 1.10 引入了对 PowerShell 5.1 的脚本支持,即预装于 Windows 上的老版“Windows PowerShell”。提供预编译的二进制文件。
目前仅支持 64 位 Windows 系统。
理论上应在 Windows 8.1 或更高版本上运行,但我仅在 Windows 10 上进行了测试。
该库需要支持 Direct3D 11.0 的显卡,而在 2023 年,这几乎等同于任何独立显卡。
最后一款不支持 D3D 11.0 的显卡是 Intel Sandy Bridge 系列,发布于 2011 年。
在 CPU 方面,该库需要支持 AVX1 和 F16C 指令集。
开发者指南
构建说明
克隆本仓库。
在 Visual Studio 2022 中打开
WhisperCpp.sln。我使用的是免费的社区版,版本号为 17.4.4。切换到
Release配置。构建并运行解决方案中
Tools子文件夹下的CompressShadersC# 项目。 要运行该项目,右键点击项目,在 Visual Studio 中选择“设为启动项目”,然后在主菜单中选择“调试/开始执行(不调试)”。 成功完成后,您将看到一个控制台窗口,显示类似以下内容:
压缩了 46 个计算着色器,从 123.5 KB 减少到 18.0 KB构建
Whisper项目以生成原生 DLL,或构建WhisperNet以获取 C# 封装库和 nuget 包,亦或编译示例程序。
其他说明
如果您使用 Visual C++ 2022 或更高版本开发软件,并计划分发该库,则可能需要以 .msm 合并模块的形式重新分发 Visual C++ 运行时 DLL,
或者使用 vc_redist.x64.exe 二进制文件。
如果是这样,请右键单击 Whisper 项目,选择“属性”,进入“C/C++”->“代码生成”,
将“运行库”设置从 多线程 (/MT) 更改为 多线程 DLL (/MD),
然后重新构建:生成的二进制文件将会更小。
该库集成了 GPU 调试工具 RenderDoc。
当您通过 RenderDoc 启动程序时,按住 F12 键即可捕获计算调用。
如果需要调试 HLSL 着色器,建议使用调试版 DLL,其中包含调试版着色器,这样在调试器中可以获得更好的用户体验。
本仓库还包含许多仅用于开发的代码:
例如几种替代模型的实现、部分计算着色器的 FP64 兼容版本、调试跟踪功能以及用于比较跟踪日志的工具等。
这些内容通常通过预处理器宏或 constexpr 标志进行禁用,我认为保留在这里并无问题。
性能说明
这台电脑上可用的显卡种类有限。
具体来说,我已针对以下硬件进行了优化:nVidia 1080Ti、Ryzen 7 5700G 内置的 Radeon Vega 8,以及 Ryzen 5 5600U 内置的 Radeon Vega 7。
汇总信息请见此处。
对于大型模型,nVidia 显卡的相对速度为 5.8;对于中型模型,则为 10.6。
而 AMD Ryzen 5 5600U 的 APU 在处理中型模型时,相对速度约为 2.2。虽然不算出色,但仍然远超实时速度。
我还测试了 nVidia 1650:其速度虽不及 1080Ti,但仍相当不错,远超实时。
此外,我也在 Core i7-3612QM 内置的 Intel HD Graphics 4000 上进行了测试,结果中型模型的相对速度为 0.14,小型模型为 0.44。
这一速度远低于实时,不过我很高兴地发现,我的软件甚至能在 2012 年推出的集成移动显卡上运行。
目前尚不确定独立 AMD 显卡或集成 Intel 显卡上的性能是否理想,因为我并未专门为此进行优化。
理想情况下,可能需要对几款最耗时的计算着色器——mulMatTiled.hlsl 和 mulMatByRowTiled.hlsl——进行略微不同的编译。
此外,或许还需要调整 Whisper/D3D/device.h 头文件中的 useReshapedMatMul() 参数。
我不太清楚如何准确衡量瓶颈所在,但直觉告诉我,问题主要在于内存带宽,而非计算能力。
Hacker News 上有人 测试 了 3060Ti,该版本配备了 GDDR6 显存。
与 1080Ti 相比,这款显卡的 FP32 浮点运算能力提升了 1.3 倍,但显存带宽却下降至 0.92 倍。结果显示,应用程序在 3060Ti 上的运行速度慢了约 10%。
进一步优化建议
我仅用了几天时间来优化这些着色器的性能。
实际上还有很大的提升空间,以下是一些可能的方向:
较新的显卡,如 Radeon Vega 或 nVidia 1650,其 FP16 性能通常高于 FP32,而我的计算着色器目前仍只使用 FP32 数据类型。
精度减半,乐趣加倍当前版本中,FP16 张量通过着色器资源视图将加载值上转换为 FP32,并通过无序访问视图将存储值下转换为 FP16。
或许可以改用 字节地址缓冲区, 直接加载和存储完整的 4 字节数据,然后在 HLSL 中利用f16tof32和f32tof16内建函数进行上下转换。目前所有着色器都是离线编译的,
Whisper.dll文件中包含的是 DXBC 字节码。
HLSL 编译器D3DCompiler_47.dll是操作系统的一部分,且编译速度很快。 对于那些计算密集型着色器,或许更适合分发 HLSL 源代码而不是 DXBC 字节码,并在启动时根据运行环境的特定参数(如D3D_SHADER_MACRO)进行即时编译。将整个项目从 D3D11 升级到 D3D12 也是一个不错的方向。
新 API 虽然使用起来更复杂,但提供了 D3D11 所不具备的一些潜在有用特性: wave 内建函数 以及 显式 FP16 支持。
缺失功能
尚未实现自动语言检测功能。
当前版本在实时音频捕获方面存在较高的延迟。
具体而言,根据语音检测的情况,延迟大约为 5 到 10 秒。
至少在我的测试中,当输入的音频片段过短时,模型表现并不理想。
为了改善用户体验,我暂时提高了延迟,但这并非最佳解决方案。
结语
在我看来,这是一个无偿的业余项目,我在 2022-23 年冬季假期期间完成了它。
代码中可能存在一些错误。
本软件按“原样”提供,不提供任何形式的担保。
感谢 Georgi Gerganov 开发的 whisper.cpp 实现,以及其中以 GGML 二进制格式存储的模型。
我并不擅长 Python 编程,也对机器学习生态系统知之甚少。
如果没有一个优秀的 C++ 参考实现作为对照,我根本不会开始这个项目。
whisper.cpp 项目中有一个示例,使用 同样的 GGML 实现来运行另一款 OpenAI 的模型——GPT-2。
借助本项目中已实现的计算着色器及相关基础设施,支持该机器学习模型应该并不困难。
如果您觉得这个项目有所帮助,恳请您考虑向 “Come Back Alive” 基金会 捐款。
版本历史
1.12.02023/07/221.11.02023/04/031.10.12023/03/201.10.02023/03/181.9.02023/03/141.8.22023/03/111.8.12023/03/111.8.02023/03/101.7.02023/02/071.6.12023/01/301.6.02023/01/291.5.02023/01/241.4.02023/01/201.3.02023/01/191.2.02023/01/181.1.02023/01/161.0.02023/01/16常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。